
Last updated on 19th May 2025| 9473
- Introduction to Natural Language Processing (NLP)
- Setting Up an NLP Development Environment
- Sentiment Analysis on Social Media Data
- Text Summarization Using NLP
- Named Entity Recognition (NER) Project
- Spam Email Detection with NLP
- Future Scope of NLP in AI
- Conclusion
Introduction to Natural Language Processing (NLP)
Natural Language Processing (NLP) is a subfield of artificial intelligence that focuses on the interaction between computers and human language. It enables machines to read, understand, and generate text, facilitating communication between humans and computers. NLP combines computational linguistics, machine learning, and deep learning techniques to analyze and manipulate natural language. Its applications span across various domains, including healthcare, finance, customer service, and entertainment, as covered in Data Science Training. As NLP continues to advance, it is shaping the future of AI-driven communication systems. NLP has evolved significantly over the years, from rule-based linguistic models to sophisticated deep learning frameworks. Early NLP systems relied heavily on manually crafted rules and heuristics. However, with the advent of statistical methods and neural networks, NLP has seen remarkable progress. Today, pre-trained models like GPT, BERT, and T5 have transformed the field, allowing for applications ranging from automated translations to chatbots and sentiment analysis. The future of NLP promises even greater advancements with improved contextual understanding, multimodal learning, and personalized AI interactions.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Setting Up an NLP Development Environment
To work on NLP projects, setting up a development environment is crucial. The first step is to install a programming language, with Python being the most commonly used due to its extensive libraries. Popular NLP libraries include NLTK, SpaCy, and Transformers by Hugging Face. Additionally, Jupyter Notebook or Google Colab provides an interactive platform for experimenting with NLP models. Setting up virtual environments using tools like Anaconda or pip helps manage dependencies efficiently in Artificial Intelligence Present and Future projects. With these tools in place, developers can build and experiment with NLP applications seamlessly. A robust NLP development environment should also include cloud-based platforms like AWS, Google Cloud, or Azure for handling large-scale NLP tasks.
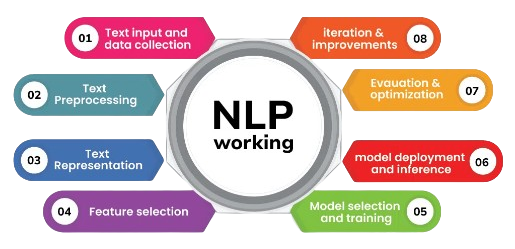
These platforms offer pre-trained models, APIs, and computing resources for training deep learning models. Additionally, version control systems like Git and platforms like Hugging Face Model Hub provide repositories for sharing and reusing models. By setting up an efficient development environment, NLP practitioners can accelerate research, experimentation, and deployment of NLP solutions.
Sentiment Analysis on Social Media Data
- Real-Time Monitoring: Businesses and analysts use sentiment dashboards for live tracking of public sentiment during events, product launches, or crises.
- Applications: Sentiment analysis supports brand monitoring, political analysis, market research, and customer feedback interpretation, driving strategic decision-making.
- Overview and Importance: Sentiment analysis is a key NLP technique used to determine the emotional tone behind text. On social media platforms like Twitter, Facebook, and Instagram, it helps gauge public opinion, brand perception, and customer satisfaction in real time.
- Data Collection: Social media data is collected through APIs (e.g., Twitter API) or web scraping for analysis and modeling using Bayesian Networks in AI.
- Text Preprocessing: Social media text is often informal and noisy. Preprocessing includes removing URLs, emojis, hashtags, mentions, and stopwords, as well as normalizing text through tokenization, stemming, or lemmatization.
- Sentiment Classification: Posts are classified into categories such as positive, negative, or neutral. Machine learning algorithms like Naive Bayes, SVM, and logistic regression, or deep learning models like LSTM and BERT, are commonly used for this task.
- Feature Engineering: NLP techniques such as TF-IDF, word embeddings (e.g., Word2Vec, GloVe), or Transformer embeddings are used to convert text into numerical features for model training.
- Algorithms and Techniques: Traditional methods include frequency-based techniques, TF-IDF scoring, and graph-based algorithms like TextRank.
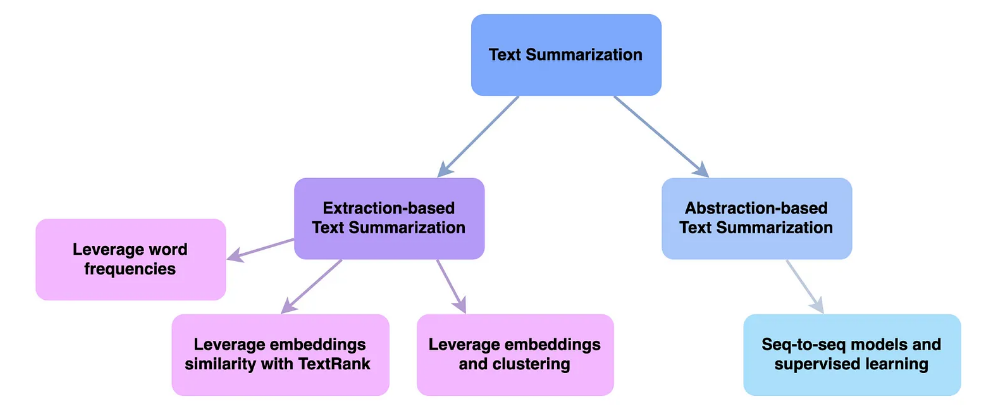
- Definition and Purpose: Text summarization is an NLP task that involves generating a concise and coherent version of a longer text while retaining its key information, highlighting Why is Data Science Important in extracting value from large volumes of information.
- Types of Summarization: There are two main approaches extractive summarization, which selects key sentences or phrases directly from the original text, which generates new sentences that convey the core ideas using natural language understanding.
- Text Preprocessing: Cleaning the input text is essential. This involves removing unnecessary characters, stopwords, and performing tokenization and normalization to prepare the text for analysis or modeling.
- Training Data: Summarization models are trained on large datasets like CNN/DailyMail, which contain pairs of articles and human-written summaries to help the model learn summarization patterns.
- Applications: Summarization is widely used in news aggregation, academic research, legal document analysis, and customer reviews.
- Challenges and Future Scope: Maintaining factual accuracy, coherence, and context are ongoing challenges, with future improvements expected through more advanced AI models and larger training corpora.
- Text Preprocessing: The first step in spam detection involves cleaning the email text by removing noise such as punctuation, HTML tags, and stopwords.
- Evaluation Metrics: Models are assessed using accuracy, precision, recall, and F1-score to ensure reliable detection and minimize false positives.
- Real-Time Detection: Trained models can be integrated into email systems to flag or filter spam emails automatically in real time.
- Continuous Learning: Regular updates and retraining with new data help improve accuracy as spam tactics evolve over time, showcasing the adaptability of Machine Learning Algorithms.
- Feature Extraction: NLP techniques convert textual content into numerical features using methods like Bag of Words (BoW), TF-IDF (Term Frequency-Inverse Document Frequency), or word embeddings.
- Labeling and Dataset Preparation: Labeled datasets with examples of both spam and ham (non-spam) emails are essential for training. Public datasets like the Enron Spam dataset or SMS Spam Collection are commonly used for building and evaluating models.
- Model Training: Machine learning algorithms such as Naive Bayes, Support Vector Machines, or logistic regression are trained on the extracted features to classify emails as spam or not.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Text Summarization Using NLP

Named Entity Recognition (NER) Project
Named Entity Recognition (NER) is a fundamental task in Natural Language Processing (NLP) that focuses on identifying and classifying key entities within a text such as person names, organizations, locations, dates, and monetary values. This process transforms unstructured data into structured insights, making it highly valuable across multiple industries. NER plays a crucial role in applications like automated customer support, legal document analysis, medical data extraction, and news categorization. Popular NLP libraries such as SpaCy, Stanford NER, and Hugging Face’s Transformers offer pre-trained NER models that can be used out-of-the-box or fine-tuned for specific domains in Data Science Training. These tools allow developers to build applications that understand context and extract relevant information more accurately. Advanced deep learning techniques, including Bi-directional LSTM (BiLSTM) networks and Transformer-based models like BERT, have significantly improved NER performance by capturing nuanced language patterns and contextual relationships. Custom NER models trained on domain-specific data sets further enhance precision, making them indispensable in specialized fields such as finance, healthcare, genomics, and cybersecurity. In today’s data-driven world, implementing NER enables businesses and researchers to unlock critical insights from vast volumes of text data efficiently and effectively.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Spam Email Detection with NLP
Future Scope of NLP in AI
The future of Natural Language Processing (NLP) in Artificial Intelligence (AI) is incredibly promising, as advancements continue to enhance how machines understand and interact with human language. NLP is rapidly evolving from basic tasks like sentiment analysis and text classification to more complex applications such as real-time language translation, emotion detection, and conversational AI. With the integration of deep learning and large language models like GPT and BERT, NLP systems are becoming more context-aware, fluent, and human-like in their responses. In the near future, NLP will play a critical role in areas such as healthcare, where it can assist in analyzing patient records, generating medical summaries, and improving diagnostics—much like how you can Master Excel Formulas for Smarter Data Analysis to uncover insights efficiently. In education, intelligent tutoring systems powered by NLP will provide personalized learning experiences. Moreover, in customer service, AI-driven chatbots will become more natural and efficient, handling complex queries with ease. As multilingual and low-resource language support improves, NLP will also drive inclusivity and global communication. The combination of NLP with other AI domains like computer vision and robotics will unlock new possibilities in automation and human-computer interaction, making NLP a cornerstone of next-generation AI systems.
Go Through These Data Science Interview Questions & Answer to Excel in Your Upcoming Interview.
Conclusion
Natural Language Processing (NLP) is an exciting and rapidly evolving field that bridges the gap between human language and machines. For beginners, diving into NLP projects is a practical way to apply theoretical knowledge and build hands-on experience. Starting with simple projects like sentiment analysis, chatbot development, text summarization, or spam detection allows you to understand core concepts such as tokenization, stemming, lemmatization, and part-of-speech tagging. These beginner-friendly projects in Data Science Training not only strengthen your programming skills, particularly in Python, but also familiarize you with essential NLP libraries like NLTK, spaCy, and Hugging Face’s Transformers. As you progress, you’ll learn how to clean and preprocess text data, work with vector representations like TF-IDF or word embeddings, and apply machine learning algorithms for classification or prediction. Moreover, these projects can serve as excellent portfolio pieces to showcase your abilities to potential employers or collaborators. The key is to start small, stay consistent, and keep experimenting. With time and practice, you’ll be ready to tackle more advanced NLP challenges and contribute meaningfully to real-world language-based applications. NLP is a journey, and every project helps you take one step forward.




