Advanced Hive Concepts and Data File Partitioning Tutorial
Last updated on 24th Jan 2022, Blog, Tutorials
- Introduction
- What is Hive instructional exercise?
- Dynamic and Static Partitioning in a hive
- Static Partitioning in Hive
- A Significant Guideline of HIVEQL is Extensibility
- Underlying Functions of Hive
- Kinds of Hive Built-in Operators
- Administrators on Complex Types
- Important Partitioning
- Hive upholds 2 sorts of tables
- Hive Architecture and its Components
- Features of Hive Services
- Metastore
- Scopes
- Hive Partitioning – Advantages and Disadvantages
- Prerequisite
- Conclusion
- In straightforward terms, Hive is an information distribution centre foundation apparatus that is utilized to deal with organized information in Hadoop.
- However, is that it? There’s a lot more with regards to Hive, and in this illustration, you will get an outline of the parcelling highlights of HIVE, which are utilized to work on the exhibition of SQL inquiries.
- You will likewise find out with regards to the Hive Query Language and how it tends to be stretched out to further develop question execution thus substantially more.
- Allow us to start with information stockpiling in a solitary Hadoop Distributed File System.
Introduction:
What is Hive instructional exercise?
Hive is an information stockroom foundation device to handle organized information in Hadoop. It lives on top of Hadoop to sum up Big Data and makes questioning and dissecting simple. This is a concise instructional exercise that gives an acquaintance on how to use Apache Hive HiveQL with Hadoop Distributed File System.
Dynamic and Static Partitioning in a hive:
Information addition into parceled tables should be possible in two ways or modes: Static apportioning Dynamic dividing You will look further into these ideas in the ensuing segments. We should start with static parceling.
Static Partitioning in Hive:
In the static dividing mode, you can embed or enter the information records exclusively into a parcel table. You can make new parcels depending on the situation, and characterize the new segments utilizing the ADD PARTITION statement. While stacking information, you want to indicate which segment to store the information in. This intends that with each heap, you want to indicate the parcel segment esteem. You can add a parcel to the table and move the information record into the segment of the table.
- Pluggable client characterized capacities
- Pluggable MapReduce scripts
- Pluggable client characterized types
- Pluggable information designs
A Significant Guideline of HIVEQL is Extensibility:
HIVEQL can be stretched out in more than one way:
You will get familiar with client characterized capacities and MapReduce scripts in the resulting segments. Client characterized types and information designs are outside the extent of the illustration.
Underlying Functions of Hive:
Composing the capacities in JAVA scripts makes its own UDF. Hive additionally gives a few inbuilt capacities that can be utilized to stay away from own UDFs from being made.These incorporate Mathematical, Collection, Type change, Date, Conditional, and String. We should check out the models that accommodated each inherent capacity.
1. Numerical: For numerical tasks, you can utilize the instances of the round, floor, etc.
2. Assortment: For assortments, you can utilize size, map keys, etc.
3. Type change: For information type transformations, you can utilize a cast.
4. Date: For dates, utilize the accompanying APIs like a year, datediff, etc.
5. Contingent: For restrictive capacities, use if, case, and blend.
6. String: For string documents, use length, invert, etc
We should check out a few different capacities in HIVE, for example, the total capacity and the table-producing capacity.
- Social Operators
- Math Operators
- Consistent Operators
- String Operators
Kinds of Hive Built-in Operators:
- Exhibits
- Maps
- Structs
Administrators on Complex Types:
The various information types in Hive, which are engaged with the table creation. Every one of the information types in Hive is grouped into four kinds, given as follows:

Section Types: Section types are utilized as segment information sorts of Hive.
Essential Types: The whole number sort information can be determined utilizing indispensable information types, INT. At the point when the information range surpasses the scope of INT, you want to utilize BIGINT and if the information range is more modest than the INT, you use SMALLINT. TINYINT is more modest than SMALLINT

String Types: String type information types can be indicated utilizing single statements (‘ ‘) or twofold statements (” “). It contains two information types: VARCHAR and CHAR. Hive follows C-types to get away from characters.
Association Types: Association is an assortment of heterogeneous information types. You can make an occurrence utilizing make an association
Drifting Point Types: Drifting point types are only numbers with decimal places. By and large, this sort of information is made out of DOUBLE information types.
Decimal Type: Decimal sort information is only drifting point esteem with higher reach than DOUBLE information type. The scope of a decimal kind is around – 10-308 to 10308.
Invalid Value: Missing qualities are addressed by the exceptional worth NULL.
Complex Types: The Hive complex information types are as per the following:
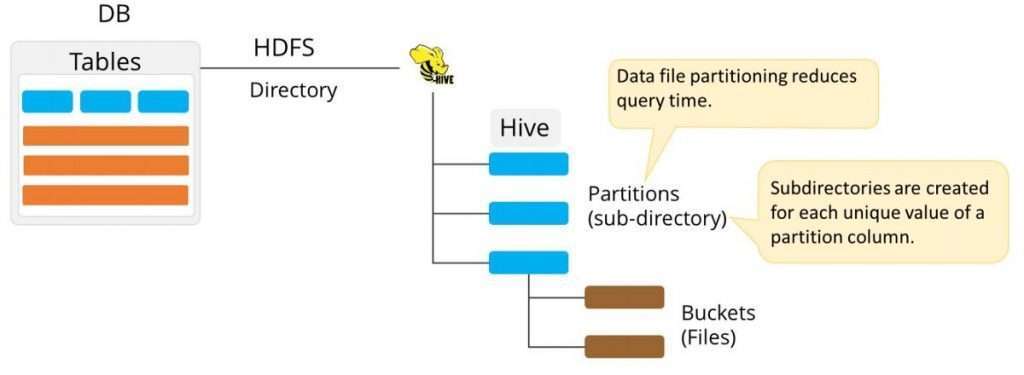
- In the current century, we realize that the immense measure of information which is in the scope of petabytes is getting put away in HDFS. So because of this, it turns out to be extremely challenging for Hadoop clients to question this tremendous measure of information.
- The Hive was acquainted with further down this weight of information questioning. Apache Hive changes over the SQL inquiries into MapReduce occupations and afterward submits it to the Hadoop group. At the point when we present a SQL inquiry, Hive read the whole informational index.
- Along these lines, it becomes wasteful to run MapReduce occupations over a huge table. Consequently, this is settled by making segments in tables. Apache Hive makes this occupation of carrying out segments extremely simple by making allotments by its programmed parcel plot at the hour of table creation.
- In the Partitioning technique, every one of the table information is isolated into different segments. Each parcel compares to a particular value(s) of segment column(s). It is kept as a sub-record inside the table’s record present in the HDFS.
- Subsequently, on questioning a specific table, the fitting part of the table is questioned which contains the inquiry esteem. Consequently, this diminishes the I/O time needed by the question. Consequently speeds up.
Important Partitioning:
- Internal Table/Managed Table:- Overseen Table is only a make table explanation. Notwithstanding, this is the default data set of HIVE. Every one of the information that is stacked is of course put away in the/client/hive/stockroom catalog of HDFS. When the table is erased or dropped, it is impossible to recover this is because the information and its metadata get disappeared.
- External Table:- The outside table is made by involving the catchphrase outer in the make table proclamation. The area of the router table isn’t equivalent to that of the oversaw table. Outer tables are those whose metadata gets erased anyway table information gets safeguarded in the catalog. DDL activities like Drop, Truncate can’t be straightforwardly executed on an outer table. You need to change the situation with the table as interior or figured out how to do as such.
Hive upholds 2 sorts of tables:-
Hive stores the information into 2 distinct kinds of tables as indicated by the need of the client.
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Hive Architecture and its Components:
The accompanying picture portrays the Hive Architecture and the stream where an inquiry is submitted into Hive lastly handled utilizing the MapReduce system:

Get JOB Oriented Python Training for Beginners By MNC Experts
1. Hive Clients:
Hive upholds applications written in numerous dialects like Java, C++, Python, and so on utilizing JDBC, Thrift, and ODBC drivers. Subsequently one can generally compose hive customer applications written in the language of their decision.
2. Hive Services:
Apache Hive offers different types of assistance like CLI, Web Interface, and so on to perform inquiries. We will investigate every single one of them in no time in this Hive instructional exercise blog. Handling structure and Resource Management: Internally, Hive involves the Hadoop MapReduce system as the accepted motor to execute the questions. Hadoop MapReduce structure is a different point in itself and in this manner, isn’t talked about here.
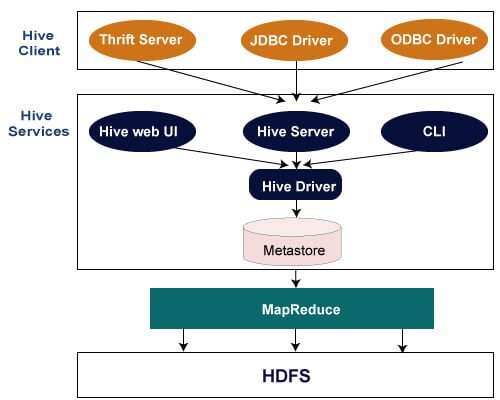
3. Circulated Storage:
As Hive is introduced on top of Hadoop, it involves the basic HDFS for the appropriated stockpiling. You can allude to the HDFS blog to look further into it. Presently, let us investigate the initial two significant parts in the Hive.
- Frugality Clients: As Hive server depends on Apache Thrift, it can serve the solicitation from that large number of programming languages that upholds Thrift.
- JDBC Clients: Hive permits Java applications to interface with it utilizing the JDBC driver which is characterized in the class org. apache.Hadoop. hive.JDBC.HiveDriver.
- ODBC Clients: The Hive ODBC Driver permits applications that help the ODBC convention to interface with Hive. (Like the JDBC driver, the ODBC driver utilizes Thrift to speak with the Hive server.)
Architecture:
Apache Hive upholds various sorts of customer applications for performing inquiries on the Hive. These customers can be sorted into three kinds:
Features of Hive Services:
Hive offers: Many types of assistance as displayed in the picture above.
Hive CLI (Command Line Interface): This is the default shell given by the Hive where you can execute your Hive questions and orders straightforwardly.
Apache Hive Web Interfaces: Apart from the order line interface, Hive likewise gives an electronic GUI to execute Hive inquiries and orders.
Hive Server: Hive server is based on Apache Thrift and subsequently, is additionally alluded to as Thrift Server that permits various customers to submit solicitations to Hive and recover the end-product.
Apache Hive Driver: It is liable for getting the inquiries submitted through the CLI, the web UI, Thrift, ODBC, or JDBC interfaces by a customer. Then, at that point, the driver passes the question to the compiler where parsing, type checking, and semantic investigation happens with the assistance of mapping present in the metastore. In the subsequent stage, an upgraded legitimate arrangement is produced as a DAG (Directed Acyclic Graph) of guide lesson assignments and HDFS undertakings. At long last, the execution motor executes these undertakings in the request for their conditions, utilizing Hadoop.
- An administration that gives metastore admittance to other Hive administrations.
- Disk capacity for the metadata which is discrete from HDFS stockpiling.
- Presently, let us comprehend the various approaches to carrying out Hive metastore in the following segment of this Hive Tutorial.
Metastore:
You can think of metastore as a focal archive for putting away all the Hive metadata data. Hive metadata incorporates different sorts of data like construction of tables and the segments alongside the segment, segment type, serializer, and deserializer which is needed for the Read/Write procedure on the information present in HDFS. The metastore involves two crucial units:
- In SemanticAnalyser.genFileSinkPlan(), parse the info and produce a rundown of SP and DP segments. We likewise produce planning from the information ExpressionNode to the result DP sections in FileSinkDesc.
- We additionally need to keep a HashFunction class in FileSinkDesc to assess segment index names from the information articulation esteem.
- In FileSinkOperator, arrangement the information – > DP planning and Hash in init(). what’s more, decide the result way in the process () from the planning.
- MoveTask: since DP sections address a subdirectory tree, it is feasible to utilize one MoveTask toward the finish to move the outcomes from the impermanent index to the last registry.
- Post executive snare for replication: eliminate all current information in DP before making new segments. We should ensure replication snare perceives every one of the altered segments.
- Metastore support: since we are making various partitions in a DML, metastore ought to have the option to make this large number of allotments. Need to research.
Scopes:
- Dividing in Hive appropriates execution load evenly.
- In segment quicker execution of questions with the low volume of information happens. For instance, the search populace from Vatican City returns extremely quickly as opposed to looking through the whole total populace.
- There is the chance of such a large number of little parcel manifestations an excessive number of catalogs.
- Segment is powerful for low volume information. In any case, certain questions like gathering on the high volume of information consume a large chunk of the day to execute. For instance, the gathering populace of China will consume a large chunk of the day when contrasted with a gathering of the populace in Vatican City.
- There is no requirement for scanning the whole table segment for a solitary record.
- Thus, this was all in Hive Partitions. Trust you like our clarification.
Hive Partitioning – Advantages and Disadvantages:
We should talk about certain advantages and impediments of Apache Hive Partitioning-
a) Hive Partitioning Advantages:
b) Hive Partitioning Disadvantages:
Prerequisite:
The requirement to learn Hive is knowledge of Hadoop and Java.
Conclusion:
Trust this blog will help you a great deal to get what precisely is parcel in Hive, what is Static apportioning in Hive, what is Dynamic dividing in Hive. We enjoy additionally covering different benefits and impediments of Hive dividing.
Assuming you have any inquiry connected with Hive Partitions, if it’s not too much trouble, leave a remark. We will love to address them.