
Last updated on 19th Mar 2025| 6252
- Introduction to AWS Athena
- How AWS Athena Works
- Use Cases for AWS Athena
- AWS Athena vs Traditional Databases
- Integrating AWS Athena with S3
- Security Features in AWS Athena
- AWS Athena vs. AWS Glue vs. Amazon Redshift
- Common Challenges and Troubleshooting in AWS Athena
- Getting Started with AWS Athena (Hands-on Guide)
- Conclusion
Excited to Achieve Your AWS Certification? View The AWS Online course Offered By ACTE Right Now!
Introduction to AWS Athena
AWS Athena is a serverless, interactive query service that enables users to analyze data stored in Amazon S3 using standard SQL queries. It eliminates the need for complex ETL processes and infrastructure management, making data analysis more accessible and cost-effective. With Athena, you can run ad-hoc queries and perform complex analytics on structured and semi-structured data without provisioning or managing servers. Built on Presto, an open-source distributed SQL engine, Athena is optimized for high-performance, low-latency queries on large datasets. It seamlessly integrates with AWS services such as AWS Glue, AWS Lake Formation, Amazon QuickSight, and AWS CloudTrail, making it a powerful tool for log analysis, security analytics, business intelligence (BI), and data exploration. Athena, as covered in Amazon Web Services Training, supports various file formats including CSV, JSON, Avro, ORC, and Parquet, and leverages features like schema-on-read, partitioning, and federated queries to enhance performance and efficiency. Additionally, its robust security and compliance features—such as IAM-based access control, data encryption, and integration with AWS CloudTrail for auditing—ensure that data remains protected. Because Athena follows a pay-per-query pricing model, users are charged only for the data scanned during queries, making it a cost-efficient solution for organizations of all sizes. Its scalability, ease of use, and deep integration with AWS services make it an excellent choice for businesses looking to derive insights from their data without the overhead of managing infrastructure.
How AWS Athena Works
AWS Athena allows users to run SQL queries against data stored in Amazon S3 without moving the data into a traditional database or data warehouse. Here’s how the process works:
- Data Storage: Data is stored in Amazon S3 in various formats, such as CSV, JSON, Parquet, ORC, or Avro.
- Schema Definition: You define the schema for your data in Athena, linking the structured data in S3 to tables in the Athena service. This process is called data cataloging, where the metadata (such as column names, types, etc.) is specified.
- Query Execution: Athena uses the Presto engine to parse and process the data directly in Amazon S3 Bucket, executing SQL queries to analyze it.
- Results: Query results are returned quickly; you can download them as CSV or other file formats. You can also store the results back in Amazon S3.
Use Cases for AWS Athena
- Log Analysis: Log files are commonly used to analyze the log files stored in S3. Logs from applications, web servers, and other systems can be queried for insights.
- Ad-Hoc Querying: Athena enables fast, ad-hoc querying of large datasets without the need to prepare or ingest the data into a database.
- Data Exploration and Analysis: Data scientists and analysts use Athena to explore large datasets directly in S3 and perform exploratory analysis without moving data into a separate system.
- Business Intelligence: Amazon Athena can be integrated with Amazon QuickSight and other BI tools to visualize and report on data stored in S3.
- Data Lake Analytics: Athena allows querying across different data formats and supports S3 as a data lake, enabling companies to perform analytics directly on their raw data.
- Use Columnar Formats (Parquet, ORC): Columnar formats like Parquet and ORC are more efficient than row-based formats like CSV, as they allow Athena to read only the required columns.
- Use Compression: Compressing your data reduces the amount of data scanned, which can significantly lower costs and improve performance.
- Limit Data Scanned: Use the WHERE clause to limit the data scanned, avoiding unnecessary full-table scans.
- Query Optimization: Use query optimization techniques such as reducing the number of joins or avoiding nested queries when possible.
- AWS Athena: Best suited for ad-hoc querying of data stored in S3 without managing infrastructure. Serverless and cost-effective for occasional or on-demand queries.
- AWS Glue: Primarily used for ETL (Extract, Transform, Load) operations. Glue helps prepare data before querying or loading it into services like Redshift.
- Amazon Redshift: A fully managed data warehouse for large-scale, complex queries and analytics. It is ideal for highly structured, persistent datasets and requires the provisioning of resources.
- Create an S3 Bucket: Store your data in an S3 bucket. Make sure the data is in a supported format (CSV, JSON, Parquet, etc.).
- Set Up Athena: Navigate to Athena in the Aws VPC (Virtual Private Cloud), and select your S3 bucket as the location for query results.
- Create a Database and Table: Define a database and table in Athena, linking the schema to the data stored in S3.
- Run Queries: Start running SQL queries on your data. Use the console to view query results or save them back to S3.
- Optimize and Monitor: Use Athena’s Query Execution History to monitor and optimize your queries for better performance and cost savings.
Excited to Obtaining Your AWS Certificate? View The AWS Training Offered By ACTE Right Now!
AWS Athena vs Traditional Databases
| Feature | AWS Athena | Traditional Databases |
|---|---|---|
| Data Storage | Uses Amazon S3 for data storage. | Data is stored in database servers. |
| Infrastructure | Serverless and fully managed | Requires management of database servers |
| Scaling | Automatically scales based on query volume. | Requires manual scaling (vertical or horizontal) |
| Cost | Pay only for the queries run. | Pay for compute resources and storage. |
| Data Format Support | Supports a variety of formats (CSV, JSON, Parquet, ORC, etc.). | Typically supports fewer formats. |
| Performance | Optimized for large, distributed data but slower for transactional workloads. | Faster for transactional workloads. |
| Setup and Management | No setup or maintenance required | Requires setup and maintenance. |
In summary, AWS Athena is suited for large-scale, ad-hoc analytics on data stored in S3, while traditional databases excel in transactional applications that require complex queries and fast read-write operations.

Integrating AWS Athena with S3
One of the main advantages of AWS Athena is its seamless integration with Amazon S3. Here’s how integration works Your data must reside in S3, in various formats (CSV, JSON, Parquet, ORC, etc.). In Athena, you define a schema to map the structure of your data. This schema is stored in the Aws Glue Data Catalog or can be defined directly within Athena. After defining the schema, you run SQL queries on the data stored in S3. Athena reads the data directly from S3, executes the query, and returns results. Query results are stored back in S3 (typically in a CSV format), or you can specify an output location.
Athena provides a serverless experience, eliminating the need for complex ETL (Extract, Transform, Load) processes to move data into databases.
Thinking About Earning a Master’s Degree in AWS? Enroll For AWS Masters Program by Microsoft Today!
Security Features in AWS Athena
AWS Athena integrates with various AWS security services to ensure your data is secure. Data in S3 can be encrypted at rest using S3 server-side encryption or managed encryption keys from AWS KMS. Use AWS Identity and Access Management (IAM) to control who can access Athena and which datasets they can query. Athena can be run within a Aws VPC (Virtual Private Cloud) for additional network-level security. Athena can integrate with AWS CloudTrail to log all actions, ensuring the full auditability of queries that run in your environment. AWS Lake Formation allows you to implement fine-grained access control for Athena queries, ensuring users have the least privilege necessary. By integrating with AWS Lake Formation or using AWS Glue Data Catalog, you can restrict access at the column or row level based on user roles. You can use AWS Glue Data Catalog with Lake Formation to implement data masking techniques to hide sensitive information. AWS Macie helps detect sensitive data (such as PII) in your S3 buckets, ensuring Athena queries don’t expose confidential information. Use S3 bucket policies to limit access to Athena query results, ensuring only authorized users can retrieve them. Athena allows you to encrypt query results stored in S3 using AWS KMS-managed keys for additional security.
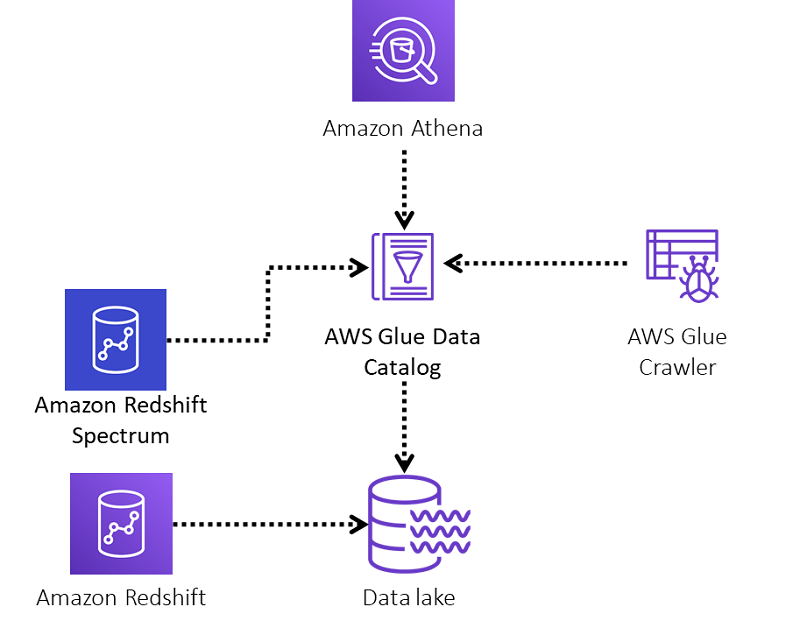
AWS Athena vs. AWS Glue vs. Amazon Redshift
Set to Ace Your AWS Job Interview? Check Out Our Blog on AWS Interview Questions & Answer
Common Challenges and Troubleshooting in AWS Athena
Large query results can slow down performance. Solution: Limit the number of rows returned or filter the data more efficiently. Incorrect data formats or schema mismatches can cause query failures. Solution: Ensure your data is stored in the correct format (CSV, Parquet, etc.) and the schema matches the data structure. It can become costly if queries scan large datasets unnecessarily. Solution: Use partitioning, compression, and efficient querying techniques. Due to large datasets, long-running queries may time out. Solution: Optimize your questions or use data partitioning to reduce the amount of scanned data. Large query results can slow down performance and increase execution time. This can lead to unnecessary data transfer costs and impact user experience. Queries may fail if the data is stored in an incorrect format, if there are schema mismatches, or due to a lack of proper AWS Training. Inconsistent data formats across different sources can also lead to parsing errors. Running queries on large datasets without optimization can significantly increase costs. Unnecessary full-table scans and uncompressed data storage contribute to higher expenses. Queries processing large amounts of data may take too long and eventually time out. This can happen due to inefficient query design, missing partitions, or excessive data scanning. Changes in schema, such as adding new columns or modifying data types, can cause compatibility issues. This may lead to query failures or incorrect data retrieval if the schema is not updated properly. Poorly optimized queries can result in slow execution times and increased resource usage. Lack of partitioning, improper joins, and large dataset scans are common factors affecting performance.
Getting Started with AWS Athena (Hands-on Guide)
Conclusion
In conclusion, AWS Athena is a powerful and cost-effective service designed to query large datasets stored in Amazon S3 without the need to manage infrastructure. Its serverless architecture enables users to run queries efficiently while only paying for the queries executed, making it an ideal solution for analyzing big data at scale. By understanding its core features, such as support for standard SQL queries, integration with other AWS services, and the ability to handle various data formats, you can fully leverage Athena for diverse data analysis tasks. Employing query optimization techniques, such as partitioning data, using columnar formats, and managing query performance as covered in AWS Training also ensures faster and more cost-effective querying. With its flexibility and ease of use, AWS Athena is an invaluable tool for organizations looking to unlock insights from large datasets in a streamlined and cost-efficient manner.




