
What is Database Management | Benefits of DBMS | Expert’s Top Picks
Last updated on 26th Dec 2021, Blog, General
Database management refers to the actions a business takes to manipulate and control data to meet necessary conditions throughout the entire data lifecycle.
- Introduction to DBMS Tutorial
- What is Database
- DBMS allows users the following tasks
- Characteristics of DBMS
- Advantages of DBMS
- DBMS Architecture
- Three schema Architecture
- Data Models
- Data model Schema and Instance
- keys
- Conclusion
Introduction to DBMS Tutorial:
DBMS Tutorial provides basic and advanced concepts of databases. Our DBMS tutorial is designed for both beginners and professionals. A database management system is a software used to manage a database. Our DBMS Tutorials covers all the topics of DBMS like Introduction, ER Model, Keys, Relational Model, Join Operation, SQL, Functional Dependencies, Transactions, Concurrent Control etc.
- A database is a collection of interrelated data that is used to retrieve, insert and delete data efficiently. It is also used to organise data in the form of tables, schemas, views and reports etc.
- For example: College databases organise data about admin, staff, students and faculty etc.
- Using a database, you can easily retrieve, insert and delete information.
- A database management system is a software used to manage a database. For example: MySQL, Oracle, etc. are very popular business databases used in various applications.
- DBMS provides an interface to perform various tasks like creating a database, storing data in it, updating data, creating tables in the database andmore. It provides security and security to the database. In case of multiple users, it also maintains data consist.
What is Database:
Database management system:
DBMS allows users the following tasks:
Data Definition: It is used to create, modify and delete the definition that defines the organisation of data in the database.
Data Updation: It is used to insert, modify and delete the actual data in the database.
Data Retrieval: It is used to retrieve data from a database which can be used by applications for various purposes.
User Administration: It is used to register and monitor users, maintain data integrity, enforce data security, deal with concurrency controls, monitor performance, and recover information corrupted by unexpected failure.
- It uses a digital repository installed on the server to store and manage the information.
- It can provide a clear and logical view of the process that manipulates the data.
- DBMS includes automated backup and recovery processes.
- It has ACID properties which maintain the data in a healthy state in case of failure.
- This can reduce the complex relationship between the data.
- It is used to support the manipulation and processing of data.
- It is used to provide security of data.
- It can view the database from different perspectives according to the needs of the user.
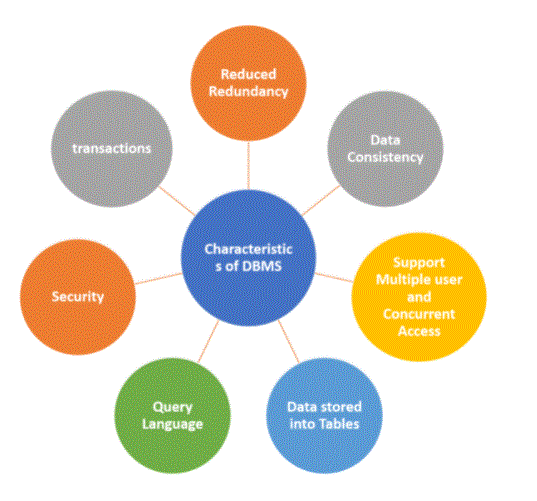
Characteristics of DBMS:
Advantages of DBMS:
Controls database redundancy: It can control data redundancy as it stores all the data in a single database file and the recorded data is kept in the database.
Data sharing: In DBMS, authorised users of an organisation can share data among multiple users.
Ease of Maintenance: Due to the centralised nature of the database system it can be easily maintained.
Reduce time: This reduces development time and maintenance needs.
Backup: It provides a backup and recovery subsystem that creates automatic backup of data from hardware and software failures and restores data if necessary.
Multiple User Interfaces: It provides different types of user interfaces like Graphical User Interface, Application Program InterfaceDisadvantages of DBMS
Hardware and Software Cost: DBMS software requires high speed of data processor and large memory size to run.
Size: It occupies a large space of disk and large memory to run them efficiently.
Complexity: Database system creates additional complexity and requirements.
High impact of failure: Failure affects the database immensely because in most of the organisation, all the data is stored in a single database and if the database gets damaged due to power failure or database corruption then the data can be lost forever.
- DBMS design depends on its architecture. Native client/server architecture is used to deal with a large number of PCs, web servers, database servers, and other network-connected components.
- The client/server architecture consists of multiple PCs and a workstation that are connected via a network.
- The DBMS architecture depends on how the users are connected to the database to fulfil their request.
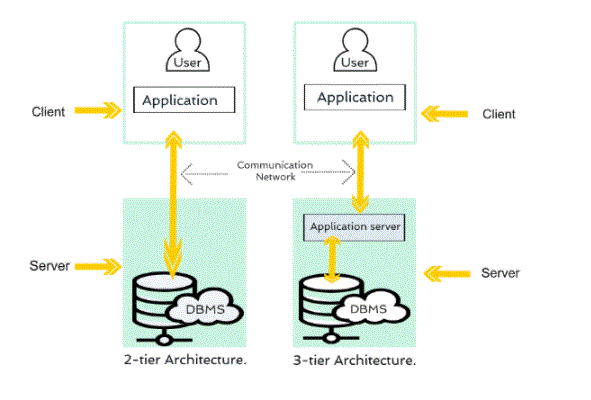
DBMS Architecture:
Types of DBMS Architectures:
Database architecture can be viewed as single tier or multi-tier. But logically, there are two types of database architecture such as: 2-tier architecture and 3-tier architecture.
- Three schema architecture is also called ANSI/SPARC architecture or three-level architecture.
- This framework is used to describe the structure of a typical database system.
- The three schema architecture is also used to separate user applications and physical databases.
- Three schema architecture consists of three-tiers. It divides the database into three different categories.
- It refers to the DBMS architecture.
- Mapping is used to transform request and response between different database tiers of the architecture.
- Mapping is not good for small DBMS as it takes more time.
- External/perceptual mapping requires transforming the request from the external level to the conceptual schema.
- In conceptual/internal mapping, DBMS transforms the request from conceptual to internal level.
- Objectives of three schema architecture
- The main objective of a three tier architecture is to enable multiple users to access the same data with an individual view, while storing the underlying data only once. Thus it separates the user’s perspective from the physical structure of the database.
- For example: B-trees, hashing etc.
- Access path.
- For example: uniqueness, index, pointers and indexing of primary and secondary keys.
- Data compression and encryption techniques.
- Optimization of internal structures.
- Representation of stored fields
- DBMS Three Schema Architecture
- Conceptual schema describes the design of a database at the conceptual level. The conceptual level is also known as the logical level.
- The conceptual schema describes the structure of the entire database.
- The conceptual level describes what data is to be stored in the database and also describes what relationship exists between those data.
- At the conceptual level, internal details such as the implementation of the data structure are hidden.
- Programmers and database administrators work at this level.
- DBMS Three Schema Architecture
- At the external level, a database consists of several schemas sometimes called subschemas. Subschemas are used to describe different views of the database.
- An external schema is also known as a view schema.
- Each view schema describes the database part that a particular user group is interested in and hides the rest of the database from that user group.
- The view schema describes the end user interaction with the database system.
Three schema Architecture:
The three-schema architecture is as follows:

Develop Your Skills with Database Administration Fundamentals Certification Training
Weekday / Weekend BatchesSee Batch DetailsThe internal level usually deals with the following activities:
1. Storage space allocation.
2. Conceptual level
3. Exterior Level
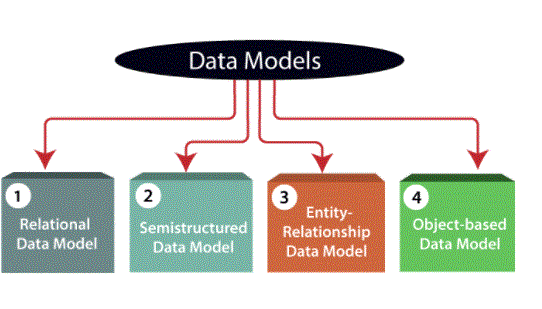
Data Models:
Data model is the modelling of data description, data semantics and consistency constraints of data. It provides conceptual tools to describe the design of a database at each level of data abstraction. Therefore, the following four data models are used to understand the structure of the database:
1) Relational Data Model: This type of model designs the data as rows and columns within a table. Thus, a relational model uses tables to represent data and the relationships between them. Tables are also called relations. This model was initially introduced in 1969 by Edgar F. was described by Codd. Relational data model is a widely used model mainly used by commercial data processing applications.
2) Entity-Relationship Data Model: An ER model is a logical representation of data in the form of objects and relationships between them. These objects are known as entities, and a relation is a linkage between these entities. This model was designed by Peter Chen and published in 1976 Letters. It was widely used in database designing. A set of attributes describe entities. For example, student_name, student_id describes the ‘student’ entity. A set of entities of the same type is known as an ‘entity set’, and a set of relations of the same type is known as a ‘relationship set’.
3) Object-based data model: An extension of the ER model that also includes the notion of functions, encapsulation, and object recognition. This model supports a rich type system that includes structured and collection types. Thus, in the 1980s, various database systems were developed following the object-oriented approach. Here, objects are nothing but data carrying its properties.
4) Semistructured Data Model: This type of data model is different from the other three data models (mentioned above). The semi-structured data model allows data specifications in places where different data items of the same type may have different attribute sets. Extensible Markup Language, also known as XML, is widely used to represent semi-structured data. Although XML was initially designed to contain markup information in a text document, it gained importance because of its application in the exchange of data.
- The data that is stored in the database at a particular point of time is called the instance of the database.
- The overall design of a database is called schema.
- A database schema is the skeletal structure of a database. It represents a logical view of the entire database.
- A schema consists of schema objects such as tables, foreign keys, primary keys, views, columns, data types, stored procedures, etc.
- A database schema can be represented using a visual diagram. That diagram shows the database objects and their relationship to each other.
- A database schema is designed by database designers to help programmers whose software will interact with the database. The process of database creation is called data modelling.
- A schema diagram can display only certain aspects of a schema such as the name of the record type, data type and constraints. Other aspects cannot be specified via schema diagram. For example, the given figure neither shows the data type of each data item nor the relationship between different files.
- In a database, the actual data changes quite frequently. For example, in the given figure, the database changes whenever we add a new grade or add a student.
- The data at a particular point in time is said to be an instance of the database.
Data model Schema and Instance:
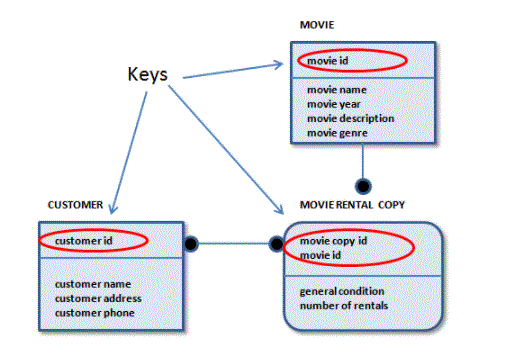
- It is the first key used to uniquely identify one and only one instance of an entity. As we saw in the PERSON table, an entity can have multiple keys. The most appropriate key out of those lists becomes the primary key.
- In employee table, id can be primary key as it is unique for each employee. In the employee table, we can also select license_number and passport_number as primary keys as they are also unique.
- For each entity, the selection of a primary key is based on requirements and developers.
- A candidate key is an attribute or set of attributes that can uniquely identify a tuple.
- The remaining attributes except the primary key are considered as candidate keys. Candidate key is as strong as the primary key.
- For example: In the Employee table, ID is best suited for the primary key. The remaining attributes such as SSN, Passport_Number, and License_Number, etc., are treated as candidate keys.
- Super has a set of attributes that can uniquely identify a tuple. Super key is a superset of candidate key.
- For example: In the above EMPLOYEES table, for (EMPLOEE_ID, EMPLOYEE_NAME) two employees can have the same name, but their EMPLYEE_ID cannot be the same. Therefore, this combination can also be a key.
- The super key would be Employee-ID, (EMPLOYEE_ID, EMPLOYEE-NAME), etc.
- Foreign key is the column of the table which is used to point to the primary key of another table.
- In a company, each employee works in a specific department, and the employee and the department are two separate entities. So we cannot store department information in the employee table. So we link these two tables through the primary key of a table.
- We add the primary key of the DEPARTMENT table, Department_Id, as a new attribute in the EMPLOYEE table.
- Now in the employee table, department_id is the foreign key, and both the tables are related.
keys:
It is used to uniquely identify any record or row of data from the table. It is also used to establish and identify relationships between tables. For example: In the Student table, ID is used as the key because it is unique for each student. In the Person table, passport_number, license_number, ssn are the keys as they are unique for each person.
1. Primary Key
2. Candidate Key
3. Super Key
4. Foreign Keys
Conclusion:
Physically, database servers are dedicated computers that hold the actual database and run only the DBMS and associated software. Database servers are typically multiprocessor computers, with generous memory and RAID disk arrays for stable storage. Hardware database accelerators connected to one or more servers via a high-speed channel are also used in large volume transaction processing environments. DBMS are found at the heart of most database applications. DBMSs can be built around a custom multitasking kernel that has built-in networking support, but modern DBMSs typically rely on a standard operating system to provide these functions.
Since DBMS covers a significant market, computer and storage vendors often take DBMS requirements into account in their development plans. Databases and DBMS can be classified according to the database model(s) they support (such as relational or XML), the computer they run on (from server clusters to mobile phones), the query language(s) of the database (such as SQL or XQuery), and their internal engineering, which affects performance, scalability, flexibility, and security