
Last updated on 13th Aug 2025| 3164
- Introduction to Logistic Regression
- Difference Between Linear and Logistic Regression
- Sigmoid Function Explained
- Binary Classification with Logistic Regression
- Assumptions and Conditions
- Model Training and Evaluation Metrics
- Implementation in Python
- Multiclass Logistic Regression
- Advantages and Limitations
- Applications (Healthcare, Marketing, etc.)
- Regularization Techniques
- Summary and Insights
Introduction to Logistic Regression
Logistic Regression is one of the most widely used algorithms in statistical modeling and Machine Learning Training for binary classification problems. Despite the term “regression,” it is primarily used for classification tasks, such as determining whether a customer will purchase a product (yes or no), if an email is spam, or if a patient has a disease. Unlike linear regression, which predicts continuous values, logistic regression predicts the probability that a given input belongs to a certain class. This is made possible by the sigmoid function, which converts linear outputs into a range between 0 and 1. These probabilities can then be mapped to discrete classes. Logistic regression is highly interpretable, efficient to train, and works well on linearly separable datasets, making it a staple in predictive modeling.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Difference Between Linear and Logistic Regression
| Feature | Linear Regression | Logistic Regression |
|---|---|---|
| Output | Continuous values | Probabilities (0–1) |
| Target Variable | Numeric | Categorical (mostly binary) |
| Function | Line equation (y = mx + b) | Sigmoid function |
| Use Case | Regression problems | Classification problems |
| Evaluation Metrics | MSE, RMSE, R² | Accuracy, Precision, Recall, AUC |
Mathematical Representation:
- Linear Regression: y=w0+w1x1+w2x2+⋯+wnxny = w_0 + w_1x_1 + w_2x_2 + \dots + w_nx_n
- Logistic Regression: σ(z)=11+e−z\sigma(z) = \frac{1}{1 + e^{-z}}, where zz is the linear combination above.
Sigmoid Function Explained
The sigmoid (or logistic) function transforms real-valued numbers into values between 0 and 1, which represent probabilities. A threshold value is used in logistic regression to make decisions based on these probabilities. For instance, if the predicted probability is above a certain threshold, such as 0.5, the result is 1. If it’s below, it’s classified as 0. This approach allows for clear and actionable outcomes.
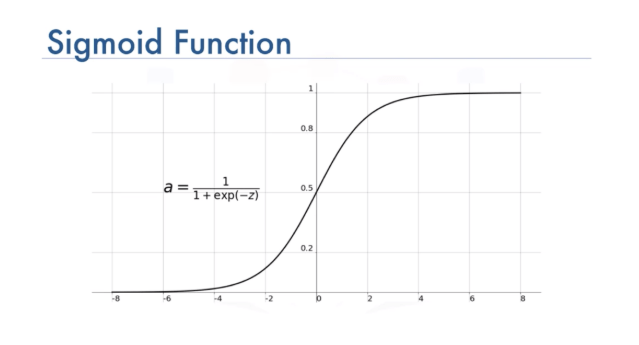
Formula:
- σ(z)=11+e−z\sigma(z) = \frac{1}{1 + e^{-z}}
Where zz is the linear combination of input features.
Properties:
- Output range: (0, 1)
- As z→∞z \rightarrow \infty, σ(z)→1\sigma(z) \rightarrow 1
- As z→−∞z \rightarrow -\infty, σ(z)→0\sigma(z) \rightarrow 0
This makes the sigmoid ideal for binary classification, as we can set a threshold (commonly 0.5) for decision making.
Binary Classification with Logistic Regression
In binary classification, logistic regression in Machine Learning Training assigns the input to either class 0 or class 1 based on the computed probability. Binary classification is named this way because it classifies the data into two results. Simply put, the result will be “yes” (1) or “no” (0).
Decision Rule:
- If P(y=1∣X)>0.5P(y=1|X) > 0.5, predict class 1.
- Else, predict class 0.
Loss Function:
The log loss (binary cross-entropy) is minimized during training:
- J(θ)=−1m∑i=1m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]J(\theta) = -\frac{1}{m} \sum_{i=1}^{m} \left[y^{(i)} \log(h_\theta(x^{(i)})) + (1 – y^{(i)}) \log(1 – h_\theta(x^{(i)}))\right]
Where hθ(x)h_\theta(x) is the output of the sigmoid function.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Assumptions and Conditions
For logistic regression to be effective, certain assumptions must hold true:
- Binary or Multiclass Dependent Variable
- Linearity in the Logit in the relationship between the independent variables and the log odds is linear.
- Independence of Observations
- No Multicollinearity among predictors
- Large Sample Size for stability
While logistic regression is robust, violation of these assumptions can lead to poor performance or biased predictions.
Model Training and Evaluation Metrics
Model Training Steps:
- Initialize: weights.
- Forward Pass: Compute sigmoid probabilities.
- Compute Loss: Use cross-entropy.
- Backpropagation: Compute gradients.
- Update Weights: using optimization (e.g., gradient descent).
Evaluation Metrics:
- Accuracy: (TP + TN) / Total
- Precision: TP / (TP + FP)
- Recall: TP / (TP + FN)
- F1 Score: Harmonic mean of precision and recall
- ROC-AUC: Evaluates classification across thresholds

Implementation in Python
Here’s a simple example using scikit-learn:
- from sklearn.datasets import load_breast_cancer
- from sklearn.linear_model import LogisticRegression
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import classification_report
- # Load data
- X, y = load_breast_cancer(return_X_y=True)
- # Split data
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
- # Train model
- model = LogisticRegression(max_iter=1000)
- model.fit(X_train, y_train)
- # Predict
- y_pred = model.predict(X_test)
- # Evaluate
- print(classification_report(y_test, y_pred))
Multiclass Logistic Regression
Multiclass logistic regression helps us predict one of many possible categories. Instead of deciding between just two options (like in regular logistic regression), we’re training our model to choose among multiple classes. For problems with more than two classes, logistic regression is extended using:
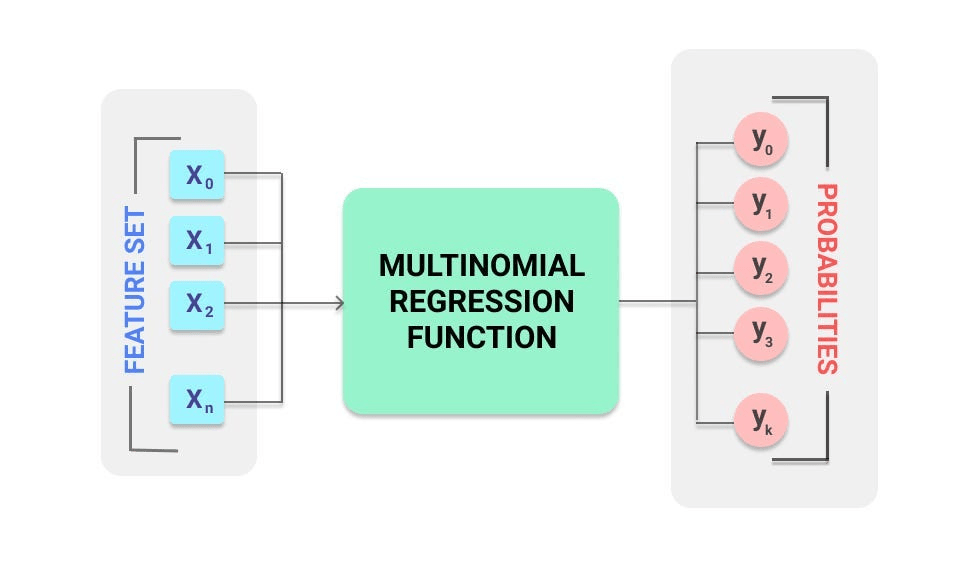
Techniques:
- One-vs-Rest (OvR): Trains one classifier per class.
- Multinomial Logistic Regression: Uses softmax to compute probabilities for each class.
Softmax Function:
- P(y=j)=ezj∑k=1KezkP(y = j) = \frac{e^{z_j}}{\sum_{k=1}^{K} e^{z_k}}
Scikit-learn supports both via:
LogisticRegression(multi_class=’multinomial’, solver=’lbfgs’)
Advantages and Limitations
Advantages:
- Simple and easy to implement
- Interpretable model (especially for feature weights)
- Works well with linearly separable data
- Fast training
Limitations:
- Assumes linear decision boundary
- Poor performance with non-linear data
- Struggles with high-dimensional and highly correlated features
- Sensitive to outliers and noise
Applications (Healthcare, Marketing, etc.)
Logistic Regression is applied in multiple domains:
Healthcare:
- Predicting diseases (diabetes, cancer)
- Hospital readmission likelihood
- Risk assessment models
Marketing:
- Customer churn prediction
- Purchase intent detection
- Campaign response modeling
Finance:
- Credit scoring
- Loan default prediction
- Fraud detection
Web & Tech:
- Spam email detection
- Click-through rate (CTR) prediction
- User engagement analysis
Regularization Techniques
To combat overfitting, Regularization Techniques is applied by adding a penalty to the loss function.
Types:
- L1 Regularization Techniques (Lasso): Promotes sparsity
- L2 Regularization Techniques (Ridge): Penalizes large weights
Updated Cost Function with L2:
- J(θ)=−log loss+λ∑j=1nθj2J(\theta) = -\text{log loss} + \lambda \sum_{j=1}^{n} \theta_j^2
Where λ\lambda is the regularization strength.
In Python:
LogisticRegression(penalty=’l2′, C=0.1)
Note: C is the inverse of regularization strength (lower C = more regularization).
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Summary and Insights
Logistic regression is a foundational classification algorithm that every data scientist must understand. It is not only a strong baseline but also a powerful model for linearly separable data with significant interpretability. Logistic regression in Machine Learning Training not only predicts outcomes but also helps understand which factors are most important for these predictions
Key Takeaways:
- Converts linear models into probabilistic outputs using the sigmoid function.
- Highly efficient and interpretable for binary and multiclass problems.
- Evaluated using classification metrics like accuracy, F1 score, and AUC.
- Easily implemented using libraries like scikit-learn.
- Can be extended to handle multiple classes using softmax or OvR strategies.
As machine learning tasks grow more complex, understanding logistic regression helps lay a solid foundation for learning more advanced models like neural networks, decision trees, and ensemble methods.




