
Last updated on 12th Jul 2020| 2576

We live in a start of a revolutionized era due to development of data analytics, large computing power, and cloud computing. Machine learning will definitely have a huge role there and the brains behind Machine Learning is based on algorithms. This article covers 10 most popular Machine Learning Algorithms which are used currently.
These algorithms can be categorized into 3 main categories.
- Supervised Algorithms: The training data set has inputs as well as the desired output. During the training session, the model will adjust its variables to map inputs to the corresponding output.
- Unsupervised Algorithms: In this category, there is not a target outcome. The algorithms will cluster the data set for different groups.
- Reinforcement Algorithms: These algorithms are trained on taking decisions. Therefore based on those decisions, the algorithm will train itself based on the success/error of output. Eventually, my experience algorithm will be able to give good predictions.
The following algorithms are going to be covered in this article.
- Linear Regression
- SVM (Support Vector Machine)
- KNN (K-Nearest Neighbors)
- Logistic Regression
- Decision Tree
- K-Means
- Random Forest
- Naive Bayes
- Dimensional Reduction Algorithms
- Gradient Boosting Algorithms
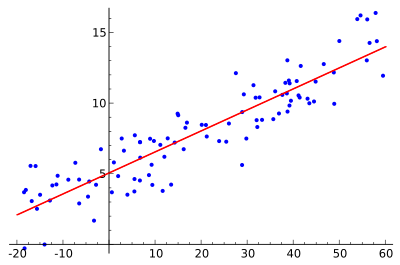
1. Linear Regression
Linear Regression algorithm will use the data points to find the best fit line to model the data. A line can be represented by the equation, y = m*x + c where y is the dependent variable and x is the independent variable. Basic calculus theories are applied to find the values for m and c using the given data set.
Linear Regression has 2 types as Simple Linear Regression where only 1 independent variable is used and Multiple Linear Regression where multiple independent variables are defined.
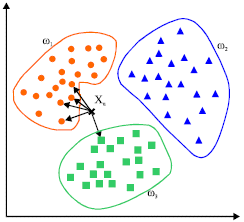
2. SVM (Support Vector Machine)
This belongs to classification type algorithms. The algorithm will separate the data points using a line. This line is chosen such that it will be furthermost from the nearest data points in 2 categories.
furthermost from the nearest data points in 2 categories.
3. KNN (K-Nearest Neighbors)
This is a simple algorithm that predicts unknown data points with its k nearest neighbors. The value of k is a critical factor here regarding the accuracy of prediction. It determines the nearest by calculating the distance using basic distance functions like Euclidean.
4. Logistic Regression
Logistic Regression is used where a discrete output is expected such as the occurrence of some event (Ex. predict whether rain will occur or not). Usually, Logistic regression uses some function to squeeze values to a particular range.
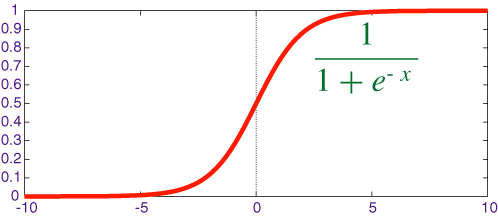
Logistic function “Sigmoid” (Logistic function) is one of such functions which has an “S” shape curve used for binary classification. It converts values to the range of 0, 1 which is interpreted as a probability of occurring in some event.
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
Above is a simple logistic regression equation where b0, b1 are constants. While training values for these will be calculated such that the error between prediction and actual value becomes minimum.
5. Decision Tree
This algorithm categorizes the population for several sets based on some chosen properties (independent variables) of a population. Usually, this algorithm is used to solve classification problems. Categorization is done by using some techniques such as Gini, Chi-square, entropy etc.
Let’s consider a population of people and use a decision tree algorithm to identify who like to have a credit card. For example, consider the age and marital status of the properties of the population. If age>30 or a person is married, people tend to prefer credit cards much and less otherwise.
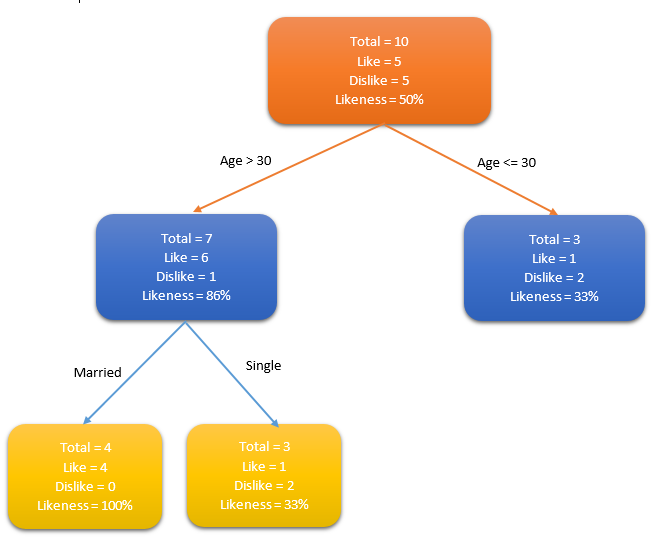
This decision tree can be further extended by identifying suitable properties to define more categories. In this example, if a person is married and he is over 30, they are more likely to have credit cards (100% preference). Testing data is used to generate this decision tree.
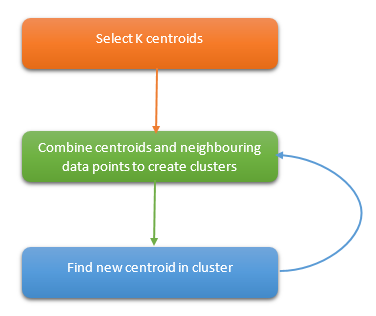
6. K-Means
This is an unsupervised algorithm that provides a solution for clustering problems. The algorithm follows a procedure to form clusters which contain homogeneous data points.
The value of k is an input for the algorithm. Based on that, the algorithm selects k number of centroids. Then the neighboring data points to a centroid combines with its centroid and creates a cluster. Later a new centroid is created within each cluster. Then data points near to the new centroid will combine again to expand the cluster. This process is continued until centroids do not change.

Get In-Depth Practical Oriented Machine Learning Training from Industry Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
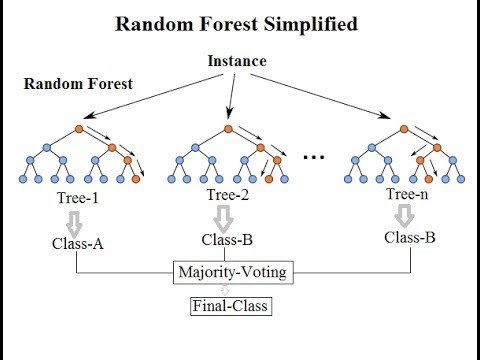
7. Random Forest
Random forest can be identified as a collection of decision trees as its name says. Each tree tries to estimate a classification and this is called a “vote”. Ideally, we consider each vote from every tree and choose the most voted classification.
8. Naive Bayes
This algorithm is based on the “Bayes’ Theorem” in probability. Due to that Naive Bayes can be applied only if the features are independent of each other since it is a requirement in Bayes’ Theorem. If we try to predict a flower type by its petal length and width, we can use Naive Bayes approach since both those features are independent.
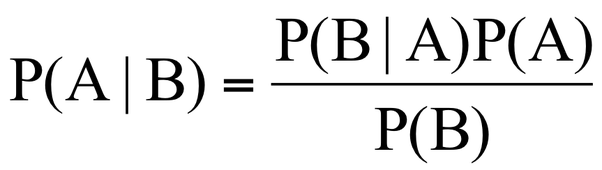
Naive Bayes algorithm also falls into classification type. This algorithm is mostly used when many classes exist in the problem.
9. Dimensional Reduction Algorithms
Some datasets may contain many variables that may be very hard to handle. Especially nowadays data collecting in systems occurs at a very detailed level due to the existence of more than enough resources. In such cases, the data sets may contain thousands of variables and most of them can be unnecessary as well.
In this case, it is almost impossible to identify the variables which have the most impact on our prediction. Dimensional Reduction Algorithms are used in this kind of situation. It utilizes other algorithms like Random Forest, Decision Tree to identify the most important variables.
10. Gradient Boosting Algorithms
Gradient Boosting Algorithm uses multiple weak algorithms to create a more powerful accurate algorithm. Instead of using a single estimator, having multiple will create a more stable and robust algorithm.
There are several Gradient Boosting Algorithms.
- XGBoost — uses liner and tree algorithms
- LightGBM — uses only tree-based algorithms




