
Last updated on 11th Dec 2021| 1987
Data mining is the process of analyzing enormous amounts of information and datasets, extracting (or “mining”) useful intelligence to help organizations solve problems, predict trends, mitigate risks, and find new opportunities. Data mining is like actual mining because, in both cases, the miners are sifting through mountains of material to find valuable resources and elements.
- Introduction of Data Mining
- Basic Data Mining Tasks
- Data Mining VS KDD(Knowledge Discovery in Database)
- Data Mining Applications
- Tools for Data Mining
- Data Mining Algorithms
- What Are the Benefits of Data Mining?
- Conclusion
- Predictive model
- Descriptive model
Introduction of Data Mining:-
“Data Mining”, that mines the data. In simple words, it is defined as finding hidden insights(information) from the database, extract patterns from the data.
There are different algorithms for different tasks. The function of these algorithms is to fit the model. These algorithms identify the characteristics of data. There are 2 types of models.
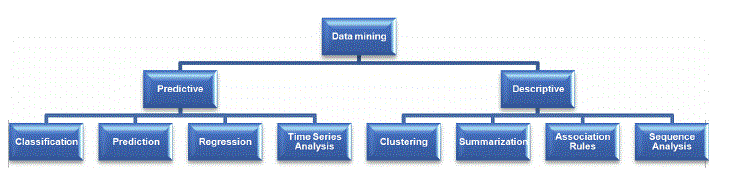
Basic Data Mining Tasks:
Under this section, we are going to see some of the mining functions/tasks.
1)Classification
This term comes under supervised learning. Classification algorithms require that the classes should be defined based on variables. Characteristics of data define which class belongs to. Pattern recognition is one of the types of classification problems in which input(pattern) is classified into different classes based on its similarity of defined classes.
2)Prediction
In real life, we often see predicting future things/values/or else based on past data and present data. Prediction is also a type of classification task. According to the type of application, for example, predicting flood where dependant variables are the water level of the river, its humidity, raining scale, and so on are the attributes.
3)Regression
Regression is a statistical technique that is used to determine the relationship between variables(x) and dependant variables(y). There are few types of regression as Linear, Logistic, etc. Linear Regression is used in continuous values(0,1,1.5,….so on) and Logistic Regression is used where there is the possibility of only two events such as pass/fail, true/false, yes/no, etc.
4) Time Series Analysis
In time series analysis, a variable changes its value according to time. It means analysis goes under the identifying patterns of data over a period of time. It can be seasonal variation, irregular variation, secular trend, and cyclical fluctuation. For example, annual rainfall, stock market price, etc.
5) Clustering
Clustering is the same as classification i.e it groups the data. Clustering comes under unsupervised machine learning. It is a process of partitioning the data into groups based on similar kinds of data.

Learn Advanced Data Science Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details6) Summarization
Summarization is nothing but characterization or generalization. It retrieves meaningful information from data. It also gives a summary of numeric variables such as mean, mode, median, etc.
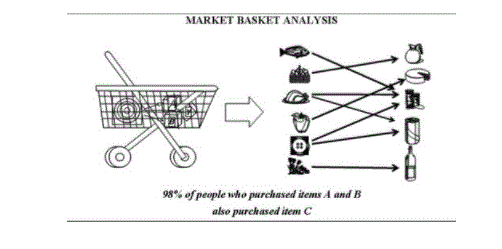
7) Association Rules
It’s the main task of Data Mining. It helps in finding appropriate patterns and meaningful insights from the database. Association Rule is a model which extracts types of data associations. For example, Market Basket Analysis where association rules are applied to the database to know that which items are purchased together by the customer.
8) Sequence Discovery
It is also called sequential analysis. It is used to discover or find the sequential pattern in data. Sequential Pattern means the pattern which is purely based on a sequence of time. These patterns are similar to found association rules in database or events are related but its relationship is based only on “Time”. Up to this point, we have seen all the basic functions or tasks of Data Mining. Let’s go-ahead to know more about Data Mining.
Data Mining VS KDD(Knowledge Discovery in Database):
Data Mining: Process of use of algorithms to extract meaningful information and patterns derived from the KDD process. It is a step involved in KDD.
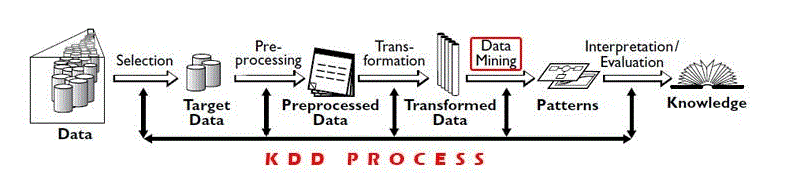
KDD: It is a significant process of identifying meaningful information and patterns in Data. The input is given to this process is data and output gives useful information from data.
KDD process consists 5 steps:
Selection: Need to obtain data from various data sources, databases.
Preprocessing: This process of cleaning data in terms of any incorrect data, missing values, erroneous data.
Transformation: Data from various sources must be converted, encoded into some format for preprocessing.
Data Mining: In this process, algorithms are applied to transformed data to achieve desired output/results.
Interpretation/evaluation: Has to perform some visualizations to present data mining results which are very important.
Data Mining Applications:
1) E-Commerce
E-commerce is one of the real-life applications of it. E-commerce companies are like Amazon, Flipkart, Myntra, etc. They use data mining techniques to see the functionality of every product in such a way that “which product is viewed most by the customer also what they also liked other”.
2) Retailing
It is another application of data mining from the retail market. Retailers find the pattern of “Freshness, Frequency, Monetary(In terms of Currency)”. Retailers keep the track of sales of products, transactions.
3) Education
Education is an emerging, trending field nowadays. It concerns knowledge discovery from educational data. The main goal of this application is to study or identify the student’s behavior pattern in terms of future learning, effects of study, advanced knowledge of learning, etc. These data mining techniques are used by institutions to take accurate decisions and also predict appropriate results.
- KNIME
- WEKA
- ORANGE
Tools for Data Mining:
- K-means clustering
- Support vector machines
- Apriori
- KNN
- Naive Bayes
- CART and many more.
- These are few algorithms.
- – Apriori:
- from apyori import apriori
- – K-means clustering:
- from kneed import KneeLocator
- from sklearn.datasets import make_blobs
- from sklearn.cluster import KMeans
- from sklearn.metrics import silhouette_score
- from sklearn.preprocessing import StandardScaler
- – Support Vector Machines:
- from sklearn import svm
- -Naive Bayes:
- from sklearn.naive_bayes import GaussianNB
- -CART:
- from sklearn.tree import DecisionTreeRegressor
- -KNN:
- from sklearn.neighbors import KNeighborsClassifier
- So here are few libraries that to be installed while performing the algorithm.
Data Mining Algorithms:
Now I am going to give you information about the required libraries below.
- It helps companies gather reliable information
- It’s an efficient, cost-effective solution compared to other data applications
- It helps businesses make profitable production and operational adjustments
- Data mining uses both new and legacy systems
- It helps businesses make informed decisions
- It helps detect credit risks and fraud
- It helps data scientists easily analyze enormous amounts of data quickly
- Data scientists can use the information to detect fraud, build risk models, and improve product safety
- It helps data scientists quickly initiate automated predictions of behaviors and trends and discover hidden patterns
What Are the Benefits of Data Mining?
Since we live and work in a data-centric world, it’s essential to get as many advantages as possible. Data mining provides us with the means of resolving problems and issues in this challenging information age. Data mining benefits include:
Conclusion
In the future, data mining will include more complex data types. In addition, for any model that has been designed, further refinement is possible by examining other variables and their relationships. Research in data mining will result in new methods to determine the most interesting characteristics in the data.




