
Last updated on 10th Feb 2022| 6430
- Introduction to Multilayer Perceptron
- History of Multilayer Perceptron
- Multi-layer Perceptron in TensorFlow
- Compressed lesson On Multi-Layer Perceptron Neural Networks
- For additional subtleties on the MLP, see the post
- Multi-layer perceptron work
- Stepwise Implementation
- Multi-layer Perceptron Neural Networks Examples in Business
- The Advantage of MLP
- Conclusion
- Dissect how to regularize and limit the expense work in a neural organization
- Do backpropagation to change loads in a neural organization
- Investigate combination in a Multi-layer ANN
- Investigate Multi-layer ANN
- Execute forward proliferation in multi-layer perceptron (MLP)
- See how the limit of a model is impacted by underfitting and overfitting
- Multi-layer perceptron characterizes the most mind-boggling engineering of fake neural organizations. It is considerably framed from various layers of the perceptron. TensorFlow is an extremely well-known profound learning structure delivered by, and this note pad will be manual for fabricating a neural organization with this library. To get what is a multi-layer perceptron, we need to create a multi-layer perceptron without any preparation utilizing Numpy.
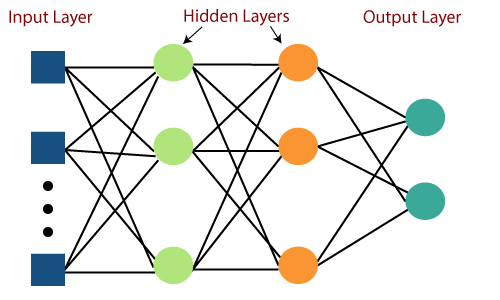
- The pictorial portrayal of multi-layer perceptron learning is as displayed beneath. MLP networks are utilized for administered learning design. An ordinary learning calculation for MLP networks is likewise gotten back to spread’s calculation.
- A Multi-layer perceptron (MLP) is a feed-forward Perceptron neural organization that produces a bunch of results from a bunch of data sources. An MLP is described by a few layers of info hubs associated as a coordinated chart between the information hubs associated as a coordinated diagram between the info and result layers. MLP involves backpropagation for preparing the organization. MLP is a profound learning strategy.
- The structure squares of neural organizations including neurons, loads, and enactment capacities.
- How the structure blocks are utilized in layers to make organizations.
- How organizations are prepared from model information.
- Launch your task with my new book Deep Learning With Python, including bit-by-bit instructional exercises and the Python source code documents for all models.
- Beginning with the info layer, spread information forward to the result layer. This progression is the forward spread.
- In light of the result, compute the mistake (the distinction between the anticipated and known result). The blunder should be limited.
- Backpropagate the blunder. Track down its subordinate regarding each weight in the organization, and update the model.
- Rehash the three stages given above over numerous ages to learn ideal loads.
- At last, the result is taken through a limited capacity to get the anticipated class marks.
- In the initial step, compute the initiation unit al(h) of the secret layer.
- Enactment unit is the consequence of applying an actuation work φ to the z esteem. It should be differentiable to have the option to learn loads utilizing angle plummet. The enactment work φ is regularly the sigmoid (calculated) work.
- It permits nonlinearity expected to tackle complex issues like picture handling.
- Multi-layer perceptron’s, or MLPs for short, are the old-style kind of neural organization.
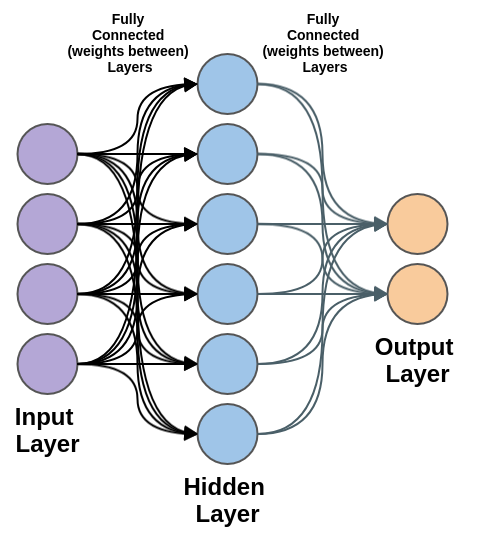
- They have contained at least one layer of neurons. Information is taken care of to the information layer, there might be at least one secret layer giving degrees of reflection, and expectations are made on the result layer, additionally called the noticeable layer.
- Ability to learn non-straight models.
- Ability to learn models continuously (on-line learning).
- MLP with stowed away layers have a non-curved misfortune work where there exists more than one nearby least. In this manner, different irregular weight introductions can prompt different approval precision.
- MLP requires tuning various hyperparameters like the quantity of stowed away neurons, layers, and emphases.
- MLP is touchy to highlight scaling.
- New-age innovations like AI, AI, and profound learning are multiplying at a fast speed. Also, if you wish to get your work, dominating these new advances will be an unquestionable requirement.
- This instructional exercise covered everything about multi-layer Perceptron neural organizations. In any case, on the off chance that you wish to dominate AI and AI, Sampliner’s PG Program in Artificial Intelligence and AI, in organization with Purdue college and as a team with IBM, should be your next stop. Along with Purdue’s top workforce masterclasses and Sampliner’s online Bootcamp, become an AI and AI expert more than ever!
Introduction to Multilayer Perceptron:
A Multi-layer Perceptron is an essential piece of profound learning. What’s more, this example will assist you with an outline of Multi-layer ANN alongside overfitting and underfitting. In addition to that, before the finish of the example you will likewise learn:
Multi-layer Perceptron’s:
1. The field of Perceptron neural organizations is regularly called neural organizations or multi-layer perceptron’s after maybe the most helpful kind of neural organization. A perceptron is a solitary neuron model that was an antecedent to bigger neural organizations.
2. It is a field that examines how straightforward models of organic cerebrums can be utilized to tackle troublesome computational assignments like the prescient displaying errands we find in AI. The objective isn’t to make sensible models of the mind, yet rather to foster strong calculations and information structures that we can use to show troublesome issues.
3. The force of neural organizations comes from their capacity to get familiar with the portrayal in your preparation information and how to best relate it to the result variable that you need to foresee. In this sense, neural organizations become familiar with the planning. Numerically, they are equipped for learning any planning capacity and be an all-inclusive guess calculation.
4. The prescient ability of neural organizations comes from the progressive or multifaceted construction of the organizations. The information design can select (figure out how to address) highlights at various scales or goals and join them into higher-request highlights. For instance, from lines to accumulations of lines to shapes.
History of Multilayer Perceptron:
a) Profound Learning manages to prepare multi-layer fake neural organizations, additionally called Deep Neural Networks. After Rosenblatt perceptron was created during the 1950s, there was an indifference toward neural organizations until 1986, when Dr. Hinton and his associates fostered the backpropagation calculation to prepare a multi-layer neural organization. Today it is a hotly debated issue with many driving firms like Google, Facebook, and Microsoft which put vigorously in applications utilizing profound neural organizations.
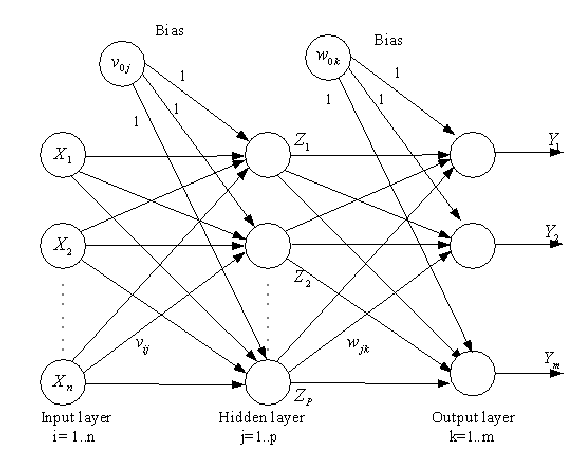
b) It has 3 layers including one secret layer. Assuming it has more than 1 secret layer, it is known as a profound ANN. An MLP is a run-of-the-mill illustration of a feedforward fake neural organization. Here, the ith enactment unit in the lth layer is indicated as ai(l).
c) The number of layers and the number of neurons is alluded to as hyperparameters of a neural organization, and these need tuning. Cross-approval strategies should be utilized to track down ideal qualities for these.
d) The weight change preparation is done using backpropagation. More profound neural organizations are better at handling information. Nonetheless, more profound layers can prompt evaporating slope issues. Extraordinary calculations are expected to tackle this issue.
Multi-layer Perceptron in TensorFlow:
Compressed lesson On Multi-Layer Perceptron Neural Networks:
Fake neural organizations are an interesting area of study, although they can be scary while simply getting everything rolling. There are a ton of specific phrasing utilized while depicting the information designs and calculations utilized in the field. In this post, you will get intense training in the phrasing and cycles utilized in the field of multi-layer perceptron Perceptron neural organizations. After perusing this post, you will know:
What are the MLP Features?
A Multi-layer perceptron (MLP) is a class of feedforward Perceptron neural organization (ANN). A MLP comprises no less than three layers of hubs: an info layer, a secret layer, and a result layer. Except for the information hubs, every hub is a neuron that utilizes a nonlinear enactment work.
What is the reason for multi-layer perceptron?
MLPs are valuable in research for their capacity to take care of issues stochastically, which regularly permits estimated answers for incredibly complex issues like wellness guess.
MLP Learning Procedure:
The MLP learning strategy is as per the following:
Forward Propagation in MLP:
When to Use Multilayer Perceptron’s?
For additional subtleties on the MLP, see the post:
MLPs are reasonable for order forecast issues where sources of info have relegated a class or mark. They are additionally appropriate for relapse expectation issues where a genuine esteemed amount is anticipated given a bunch of information sources. Information is regularly given in a plain configuration, for example, you would find it in a CSV document or a bookkeeping page. Use MLPs for:
1. Even datasets
2. Grouping expectation issues
3. Relapse forecast issues
They are truly adaptable and can be utilized for the most part to gain planning from contributions to yields. This adaptability permits them to be applied to different sorts of information. For instance, the pixels of a picture can be diminished down to one long column of information and taken care of into an MLP. The expressions of a record can likewise be decreased to one long line of information and taken care of to an MLP. Indeed, even the slack perceptions for a period series expectation issue can be diminished to a long column of information and taken care of to an MLP.
In that capacity, assuming your information is in a structure other than an even dataset, like a picture, record, or time series, I would suggest essentially testing an MLP on your concern. The outcomes can be utilized as a benchmark point of correlation with affirming that different models that might show up more qualified add esteem.
Give MLPs A shot:
a) Picture information
b) Text Data
c) Time series information
d) Different kinds of information
Multi-layer perceptron work:
The calculation for the MLP is as per the following:
1. Just as with the perceptron, the sources of info are pushed forward through the MLP by taking the dab result of the contribution with the loads that exist between the information layer and the secret layer (W¬¬¬H). This spot item yields a worth at the secret layer. However, we don’t push this worth forward as we would with a perceptron.
2. MLPs use actuation capacities at every one of their determined layers. There are numerous enactment capacities to examine: amended direct units (ReLU), sigmoid capacity, tanh. Push the determined result at the current layer through any of these enactment capacities.
3. Once the determined result at the secret layer has been pushed through the enactment work, push it to the following layer in the MLP by taking the spot item with the comparing loads.
4. Repeat stages two and three until the result layer is reached.
5. At the result layer, the computations will either be utilized for a backpropagation calculation that compares to the initiation work that was chosen for the MLP (on account of preparing) or a choice will be made in light of the result (on account of testing). MLPs structure the reason for every single neural organization and have significantly worked on the force of PCs when applied to arrangement and relapse issues. PCs are not generally restricted by XOR cases and can learn rich and complex models on account of the multi-layer perceptron.

Develop Your Skills with Deep Learning Certification Training
Weekday / Weekend BatchesSee Batch DetailsStepwise Implementation:
Stage 1: Import the fundamental libraries.
Stage 2: Download the dataset. TensorFlow permits us to peruse the MNIST dataset and we can stack it straightforwardly in the program as a train and test dataset.
Stage 3: Now we will change over the pixels into drifting point values. Stage 4: Understand the design of the dataset
Stage 5: Visualize the information.
Stage 6: Form the Input, stowed away, and yield layers.
Stage 7: Compile the model.
Stage 8: Fit the model.
Stage 9: Find Accuracy of the model.
Multi-layer Perceptron Neural Networks Examples in Business:
a) Information Compression, Streaming Encoding – social media, Music Streaming, Online Video Platforms. In the times of basically limitless plate stockpiling and distributed computing the entire idea of information pressure appears to be extremely odd – what’s the point? Your organization can transfer information without such trade-offs.
b) This mentality comes from the misguided judgment of the expression “pressure” – it isn’t as a matter of fact “making information more modest” yet rebuilding information while holding its unique shape and along these lines utilizing functional assets. The motivation behind information pressure is to make information more open in a particular setting or medium where the full-scale show of information isn’t needed or pointless.
c) To do that, neural organizations for design acknowledgment are applied. The document’s construction and content are investigated and surveyed. Consequently, it is changed to fit explicit prerequisites.
d) Information pressure emerged from a need to abbreviate the hour of moving data starting with one spot then onto the next. In plain terms – more modest things get to the objective quicker. Since the web isn’t sending the information immediately and here and there, that is a significant necessity.
There are two sorts of pressure:
Lossy – inaccurate approximations and halfway information disposing of to address the substance.
Lossless – when the document is compacted as it were, that the specific portrayal of the first record. Nowadays, online media and web-based features are utilizing information pressure the most noticeably. It incorporates all types of media – sound, picture, video.
We should take a gander at them individually:
Instagram is a versatile first application. This implies, its picture encoding is explicitly intended for the best show on the portable screen. This approach permits Instagram to perform lossy pressure of a picture content so the heap time and asset utilization would be as close to nothing and conceivable. Instagram’s video encoding calculation is also intended for portable first and along these lines applies the lossy strategy.
Facebook’s methodology can’t be unique. Since Facebook’s clients are spread similarly over versatile and work area stages – Facebook is involving various sorts of pressure for each show. On account of pictures, this implies that each picture is available in a few varieties explicit to the unique circumstance – Lossless pressure is utilized for full picture screening, while lossy pressure and the incomplete end are utilized in the newsfeed pictures. The equivalent goes for the video. Be that as it may, in this situation, clients can alter the nature of gushing all alone. Regardless of every one of its issues, Tumblr contains probably the most moderate information pressure calculations in the web-based media industry. Like Facebook, Tumblr’s information pressure framework adjusts to the stage on which the application is running. Notwithstanding, Tumblr is involving exclusively lossless pressure for the media content whether or not it is portable or a work area.
Youtube is an intriguing monster with regards to terms of information pressure. Once upon a time, the streaming stage utilized a custom packing calculation on totally transferred recordings. The quality was not good or bad, thus in the late 00s-mid 10s, Youtube executed web-based encoding. Rather than playing previously compacted video – the framework is adjusting the quality with lossy pressure of the video in a hurry as indicated by the set inclinations.
Spotify’s sound pressure calculation depends on Ogg Vorbis (which was at first evolved as a more slender and more upgraded elective for MP3). One of the advantages of Ogg record pressure is broadened metadata that improves the labeling framework and thus facilitates the pursuit and revelation of the substance. Spotify’s main concern is helpful playback.
Netflix is at the very front of web-based video pressure. Very much like Spotify, Netflix focuses on a reliable encounter and smooth playback. Thus, their calculation is all the more intently attached to the client. There is the underlying set of picture quality, and afterward, there is the nature of association that manages the pressure strategy. They will embrace the new norm – Versatile Video Coding (VVC) which extends its element to 360 video and computer-generated reality conditions.
The Advantage of MLP:
Disadvantage of MLP:




