
Apache Pig Interview Questions & Answers [GUIDE TO CRACK]
Last updated on 03rd Jul 2020, Blog, Interview Questions
Apache PIG questions and answers with explanation for interview, competitive examination and entrance test. Fully solved examples with detailed answer description, explanation are given and it would be easy to understand. The Apache Pig Online Test is free, and you can practice it multiple times. If you are the kind of an applicant to get nervous before a test, then this Apache Pig Quiz will be useful. Candidates can revise Hadoop concepts with Apache Pig Quiz questions and build-up the confidence in the most common framework of Bigdata. This Apache Pig Online Quiz will cover all the topics of it and contains the Apache Pig Multiple Choice Questions. These Apache Pig free Quiz Questions will test the knowledge of the applicants. To know all the contents of the Apache Pig, the aspirants need to check the below-provided Apache Pig Questions and Answers along with the explanations. Hence, the postulates need to take the Apache Pig Online Test as a practice quiz and learn all the question answers.
1. Define Apache Pig
Ans:
To analyze large data sets representing them as data flows, we use Apache Pig. Basically, to provide an abstraction over MapReduce, reducing the complexities of writing a MapReduce task using Java programming, Apache Pig is designed. Moreover, using Apache Pig, we can perform data manipulation operations very easily in Hadoop.
2. Can you define Pig in 2 lines?
Ans:
Pig is a platform to analyze large data sets that should either structured or unstructured data by using Pig latin scripting. Intentionally done for streaming data, un-structured data in parallel
3. Advantages of Using Pig ?
Ans:
i) Pig can be treated as a higher level language
- Increases Programming Productivity
- Decreases duplication of Effort
- Opens the M/R Programming system to more uses
ii) Pig Insulates against hadoop complexity
- Hadoop version Upgrades
- Job configuration Tunning
4. Why Do We Need Apache Pig?
Ans:
At times, while performing any MapReduce tasks, programmers who are not so good at Java normally used to struggle to work with Hadoop. Hence, Pig is a boon for all such programmers. The reason is:
- Using Pig Latin, programmers can perform MapReduce tasks easily, without having to type complex codes in Java.
- Since Pig uses a multi-query approach, it also helps in reducing the length of codes.
- It is easy to learn Pig when you are familiar with SQL. It is because Pig Latin is SQL-like language.
- In order to support data operations, it offers many built-in operators like joins, filters, ordering, and many more. And, it offers nested data types that are missing from MapReduce, for example, tuples, bags, and maps.
5. How many ways can we run Pig programs?name them
Ans:
There are three ways in which Pig programs or commands can be executed
- Script – Batch Method
- Grunt Shell – Interactive Method
- Embedded mode
6. What are the categories of Pig and which one is most common?
Ans:
Categories of Pig are
- ETL data pipline
- Research on raw data
- Iterative processing
Most common usecase for pig is data pipeline.
7. Tell me few important operators while working with Data in Pig.
Ans:
- Filter: Working with Touples and rows to filter the data.
- Foreach: Working with Columns of data to load data into columns.
- Group: Group the data in single relation.
- Cogroup & Join: To group/Join data in multiple relations.
- Union: Merge the data of multiple relations.
- Split: partition the content into multiple relations.
8. Explain The Difference Between Count_star And Count Functions In Apache Pig?
Ans:
COUNT function does not include the NULL value when counting the number of elements in a bag, whereas COUNT_STAR (0 function includes NULL values while counting.
9. What are the different Relational Operators available in pig language?
Ans:
Relational operators in pig can be categorized into the following list
- Loading and Storing
- Filtering
- Grouping and joining
- Sorting
- Combining and Splitting
- Diagnostic
10. What are the relational operators available related to loading and storing in pig language?
Ans:
For Loading data and Storing it into HDFS, Pig uses following operators.
- LOAD
- STORE
LOADS, load the data from the file system. STORE, stores the data in the file system.
11. Can You Join Multiple Fields In Apache Pig Scripts?
Ans:
Yes, it is possible to join multiple fields in PIG scripts because the join operations takes records from one input and joins them with another input. This can be achieved by specifying the keys for each input and the two rows will be joined when the keys are equal.
12. What is the difference between Pig and SQL?
Ans:
Here are the list of major differences between Apache Pig and SQL.
| PIG | SQL |
|---|---|
| It is a procedural language. | While it is a declarative language. |
| Here, the schema is optional. Although, without designing a schema, we can store data. However, it stores values as $01, $02 etc. | In SQL, Schema is mandatory. |
| In Pig, data model is nested relational. | In SQL, data model used is flat relational. |
| Here, we have limited opportunity for query optimization. | While here we have more opportunity for query optimization. |
13. Explain the architecture of Hadoop Pig.
Ans:
Now, we can see several components in the Hadoop Pig framework. The major components are:
- Parser
- At first, Parser handles all the Pig Scripts. Basically, Parser checks the syntax of the script, does type checking, and other miscellaneous checks. Afterward, Parser’s output will be a DAG (directed acyclic graph). That represents the Pig Latin statements as well as logical operators.
- Basically, the logical operators of the script are represented as the nodes and the data flows are represented as edges, in the DAG (the logical plan).
- Optimizer
Further, DAG is passed to the logical optimizer. That carries out the logical optimizations, like projection and push down.
- Compiler
A series of MapReduce jobs have been compiled from an optimized logical plan.
- Execution engine
At last, these jobs are submitted to Hadoop in a sorted order. Hence, these MapReduce jobs are executed finally on Hadoop, which produces the desired results.
14. What is the difference between Apache Pig and Hive?
Ans:
Basically, to create MapReduce jobs, we use both Pig and Hive. Also, we can say, at times, Hive operates on HDFS as much as Pig does. So, here we are listing a few significant points that set Apache Pig apart from Hive.
| APACHE PIG | HIVE |
|
Pig Latin is a language, Apache Pig uses. Originally, it was created at Yahoo. |
HiveQL is a language, Hive uses. It was originally created at Facebook. |
| It is a data flow language. | Whereas, it is a query processing language. |
|
Moreover, it is a procedural language which fits in pipeline paradigm. |
It is a declarative language. |
|
Also, can handle structured, unstructured, and semi-structured data. |
Whereas, it is mostly for structured data. |
15. What is the difference between Pig and MapReduce?
Ans:
Some major differences between Hadoop Pig and MapReduce, are:
| HADOOP PIG | MAP REDUCE |
| It is a data flow language. | However, it is a data processing paradigm. |
| Pig is a high-level language. | Well, it is a low level and rigid. |
|
In Apache Pig, performing a join operation is pretty simple. |
But, in MapReduce, it is quite difficult to perform a join operation between datasets. |
16. What does FOREACH do?
Ans:
- FOREACH is used to apply transformations to the data and to generate new data items. The name itself is indicating that for each element of a data bag, the respective action will be performed.
- Syntax : FOREACH bagname GENERATE expression1, expression2, …..
- The meaning of this statement is that the expressions mentioned after GENERATE will be applied to the current record of the data bag.
17. How to write ‘foreach’ statement for map datatype in pig scripts?
- for map we can use hash(‘#’)
- bball = load ‘baseball’ as (name:chararray, team:chararray,position:bag{t:(p:chararray)}, bat:map[])
- avg = foreach bball generate bat#’batting_average’;
- machine learning in training,machine learning,machine learning course content
18. How to write ‘foreach’ statement for tuple datatype in pig scripts?
Ans:
for tuple we can use dot(‘.’)
- A = load ‘input’ as (t:tuple(x:int, y:int));
- B = foreach A generate t.x, t.$1;
19. How to write ‘foreach’ statement for bag datatype in pig scripts?
Ans:
when you project fields in a bag, you are creating a new bag with only those fields:
- A = load ‘input’ as (b:bag{t:(x:int, y:int)});
- B = foreach A generate b.x;
- we can also project multiple field in bag
- A = load ‘input’ as (b:bag{t:(x:int, y:int)});
- B = foreach A generate b.(x, y);
20. why should we use ‘filters’ in pig scripts?
Ans:
Filters are similar to where clause in SQL.filter which contain predicate.If that predicate evaluates to true for a given record, that record will be passed down the pipeline. Otherwise, it will not.predicate contain different operators like ==,>=,<=,!=.so,== and != can be applied to maps and tuples.
- A= load ‘inputs’ as(name,address)
- B=filter A by symbol matches ‘CM.*’;
21. What are the different String functions available in pig?
Ans:
Below are most commonly used STRING pig functions
- UPPER
- LOWER
- TRIM
- SUBSTRING
- INDEXOF
- STRSPLIT
- LAST_INDEX_OF
22. What is bag?
Ans:
A bag is one of the data models present in Pig. It is an unordered collection of tuples with possible duplicates. Bags are used to store collections while grouping. The size of bag is the size of the local disk, this means that the size of the bag is limited. When the bag is full, then Pig will spill this bag into local disk and keep only some parts of the bag in memory. There is no necessity that the complete bag should fit into memory. We represent bags with “{}”.
23. What is an outer bag?
Ans:
An outer bag is nothing but a relation.
24. What is an inner bag?
Ans:
An inner bag is a relation inside any other bag.
25. Write a word count program in pig.
Ans:
- lines = LOAD ‘/user/hadoop/HDFS_File.txt’ AS (line:chararray);
- words = FOREACH lines GENERATE FLATTEN(TOKENIZE (line)) as word;
- grouped = GROUP words by word;
- wordcount = FOREACH grouped GENERATE group, COUNT (words);
- DUMP wordcount;
26. What is the purpose of ‘Store’ keyword?
Ans:
- After you have finished processing your data, you will want to write it out somewhere.
- Pig provides the store statement for this purpose. In many ways it is the mirror image of the load statement. By default, Pig stores your data on HDFS in a tab-delimited file using PigStorage.
27. What is the difference between Store and dump commands?
Ans:
Dump command after process the data displayed on the terminal, but it’s not stored anywhere. Where as Store stored in local file system or HDFS and output execute in a folder. In the protection environment most often hadoop developer used ‘store’ command to store data in in the HDFS.
28. why should we use ‘orderby’ keyword in pig scripts?
Ans:
The order statement sorts your data for you, producing a total order of your output data.The syntax of order is similar to group. You indicate a key or set of keys by which you wish to order your data
- input2 = load ‘daily’ as (exchanges, stocks);
- grpds = order input2 by exchanges;
29. What are macros in pig?
Ans:
- Macros are introduced in the later versions of pig. The main intention in introducing macros is to make the pig language modular. Generally in other languages, we create a function to use to multiple times similarly in pig we can create a macro in pig and we can run the macro number of times.
Suppose you have to count the number of tuples in a relation, then use the following code:
- DEFINE row_count (X) RETURNS Z {Y = group $X all; $Z = foreach Y generate COUNT($X);}
- Z will be returned from the macro.
- new_relation = row_count (existing_relation)
- In this way you can create functions in pig to use them repeatedly in many places.
30. What is Kerberos secured cluster in Apache Pig?
Ans:
Kerberos is an authentication system that uses tickets with a limited validity time.

Get Pig Courses with Industry Standard Modules From Expert Trainers
Weekday / Weekend BatchesSee Batch Details31. How do you run Pig scripts on Kerberos secured cluster?
Ans:
As a consequence of running a pig script on a Kerberos secured Hadoop cluster limits the running time to at most the remaining validity time of these Kerberos tickets. When doing really complex analytics this may become a problem as the job may need to run for a longer time than these ticket times allow.
32. Explain Features of Pig.
Ans:
There are several features of Pig, such as:
- Rich set of operators
- In order to perform several operations, Pig offers many operators, for example, join, sort, filer and many more.
- Ease of programming
- Since you are good at SQL, it is easy to write a Pig script. Because of Pig Latin as same as SQL.
- Optimization opportunities
- In Apache Pig, all the tasks optimize their execution automatically. As a result, the programmers need to focus only on the semantics of the language.
- Extensibility
- Through Pig, it is easy to read, process, and write data. It is possible by using the existing operators. Also, users can develop their own functions.
- UDF’s
- By using Pig, we can create User-defined Functions in other programming languages. Like Java. Also, can invoke or embed them in Pig Scripts.
33. What is Pig Storage?
Ans:
In Pig, there is a default load function, that is Pig Storage. Also, we can use pig storage, whenever we want to load data from a file system into the pig. We can also specify the delimiter of the data while loading data using pig storage (how the fields in the record are separated). Also, we can specify the schema of the data along with the type of the data.
34. What Are The Debugging Tools Used For Apache Pig Scripts?
Ans:
- describe and explain are the important debugging utilities in Apache Pig.
- Explaining utility is helpful for Hadoop developers, when trying to debug error or optimize PigLatin scripts. explain can be applied on a particular alias in the script or it can be applied to the entire script in the grunt interactive shell. explain utility produces several graphs in text format which can be printed to a file.
- describe debugging utility is helpful to developers when writing Pig scripts as it shows the schema of a relation in the script. For beginners who are trying to learn Apache Pig can use the describe utility to understand how each operator makes alterations to data. A pig script can have multiple describes.
35. Is it possible to join multiple fields in pig scripts?
Ans:
- Yes, Join select records from one input and join with another input.This is done by indicating keys for each input. When those keys are equal, the two rows are joined.
- input2 = load ‘daily’ as (exchanges, stocks);
- input3 = load ‘week’ as (exchanges, stocks);
- grpds = join input2 by stocks,input3 by stocks;
- we can also join multiple keys
Example:
- input2 = load ‘daily’ as (exchanges, stocks);
- input3 = load ‘week’ as (exchanges, stocks);
- grpds = join input2 by (exchanges,stocks),input3 by (exchanges,stocks);
36. Is it possible to display the limited no of results?
Ans:
Yes, Sometimes you want to see only a limited number of results. ‘limit’ allows you do this:
- input2 = load ‘daily’ as (exchanges, stocks);
- first10 = limit input2 10;
37. What Is A Udf In Pig?
Ans:
If the in-built operators do not provide some functions then programmers can implement those functionalities by writing user defined functions using other programming languages like Java, Python, Ruby, etc. These User Defined Functions (UDF’s) can then be embedded into a Pig Latin Script.
38. While writing evaluate UDF, which method has to be overridden?
Ans:
We have to override the method exec() while writing UDF in the Pig. Whereas the base class can be different while writing filter UDF, we will have to extend FilterFunc and for evaluate UDF, we will have to extend the EvalFunc. EvaluFunc is parameterized and must provide the return type also.
39. What are the different UDF’s in Pig?
Ans:
On the basis of the number of rows, UDF can be processed. They are of two types:
- UDF that takes one record at a time, for example, Filter and Eval.
- UDFs that take multiple records at a time, for example, Avg and Sum.
Also, pig gives you the facility to write your own UDF’s for load/store the data
40. What are the Optimizations a developer can use during joins?
Ans:
- We use replicated join, to perform join between a small dataset with a large dataset. Moreover, in the replicated join, the small dataset will be copied to all the machines where the mapper is running and the large dataset is divided across all the nodes. Also, it gives us the advantage of Map-side joins.
- If your dataset is skewed i.e. if a particular data is repeated multiple times even if you use reduce side join, the particular reducer will be overloaded and it will take a lot of time. Pig itself, calculates skewed join and the skewed key.
- And, if you have datasets where the records are sorted in the same field, you can go for sorted join, this also happens in map phase and is very efficient and fast.
41. What is a skewed join?
Ans:
While we want to perform a join with a skewed dataset, that means a particular value will be repeated many times, is a skewed join.
42. What is Flatten?
Ans:
- An operator in pig that removes the level of nesting, is Flatten. Sometimes, we have data in a bag or a tuple and we want to remove the level of nesting so that the data structured should become even, we use Flatten.
- In addition, each Flatten produces a cross product of every record in the bag with all of the other expressions in the general statement.
43. What Does Flatten Do In Pig?
Ans:
Sometimes there is data in a tuple or a bag and if we want to remove the level of nesting from that data, then Flatten modifier in Pig can be used. Flatten un-nests bags and tuples. For tuples, the Flatten operator will substitute the fields of a tuple in place of a tuple, whereas un-nesting bags is a little complex because it requires creating new tuples.
44. What are the complex data types in pig?
Ans:
The following are the complex data types in Pig:
- Tuple – An ordered set of fields is what we call a tuple.
- Bag – A collection of tuples is what we call a bag.
- Map – A set of key-value pairs is what we call a Map.
45. Why do we use BloomMapFile?
Ans:
- In order to extend MapFile, we use the BloomMapFile. That implies its functionality is similar to MapFile.
- Also, to provide a quick membership test for the keys, BloomMapFile uses dynamic Bloom filters. We use it in HBase table format.
46. How will you explain COGROUP in Pig?
Ans:
In Apache Pig, COGROUP works on tuples. On several statements, we can apply operators, which contains a few relations at least 127 relations at every time. When you make use of the operator on tables, then Pig immediately books two tables and joins them through some of the columns that are grouped.
47. What is the difference between logical and physical plans?
Ans:
Pig undergoes some steps when a Pig Latin Script is converted into MapReduce jobs. After performing the basic parsing and semantic checking, it produces a logical plan. The logical plan describes the logical operators that have to be executed by Pig during execution. After this, Pig produces a physical plan. The physical plan describes the physical operators that are needed to execute the script.
48. Does ‘ILLUSTRATE’ run an MR job?
Ans:
It will pull the internal data, illustrate will not pull any MR. Moreover, illustrate will not do any job on the console. It just shows the output of each stage and not the final output.
49. What Is Illustrate Used For In Apache Pig?
Ans:
- Executing pig scripts on large data sets, usually takes a long time. To tackle this, developers run pig scripts on sample data but there is possibility that the sample data selected, might not execute your pig script properly.
- For instance, if the script has a join operator there should be at least a few records in the sample data that have the same key, otherwise the join operation will not return any results. To tackle these kind of issues, illustrate is used. illustrate takes a sample from the data and whenever it comes across operators like join or filter that remove data, it ensures that only some records pass through and some do not, by making modifications to the records such that they meet the condition. illustrate just shows the output of each stage but does not run any MapReduce task.
50. Is the keyword ‘DEFINE’ as a function name?
Ans:
The keyword ‘DEFINE’ is like a function name. As soon as we have registered, we have to define it. Whatever logic you have written in Java program, we have an exported jar and also a jar registered by us. Now the compiler will check the function in the exported jar. When the function is not present in the library, it looks into our jar.

Enroll in Pig Training & Build Your Skills to Take Your Career Next Level
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
51. Is the keyword ‘FUNCTIONAL’ a User Defined Function (UDF)?
Ans:
The keyword ‘FUNCTIONAL’ is not a User Defined Function (UDF). we have to override some functions while using UDF. Certainly, we have to do our job with the help of these functions only. However, the keyword ‘FUNCTIONAL’ is a built-in function i.e a predefined function, therefore it does not work as a UDF.
52. Why do we need MapReduce during Pig programming?
Ans:
Let’s understand it in this way- Pig is a high-level platform that makes many Hadoop data analysis issues easier to execute. And, we use Pig Latin for this platform. Now, a program written in Pig Latin is like a query written in SQL, where we need an execution engine to execute the query. Hence, when we wrote a program in Pig Latin, it was converted into MapReduce jobs by pig compiler. As a result, MapReduce acts as an execution engine.
53. What are the scalar data types in Pig?
Ans:
In Apache Pig, Scalar data types are:
- int -4bytes,
- float -4bytes,
- double -8bytes,
- long -8bytes,
- char array,
- byte array
54. What are the different execution mode available in Pig?
Ans:
In Pig, there are 3 modes of execution available:
- Interactive Mode (Also known as Grunt Mode)
- Batch Mode
- Embedded Mode
55. What is Pig Latin?
Ans:
Pig Latin is the Scripting Language for the data flow that defines large data sets. A Pig Latin program consists of a series of operations, which is then applied to the input data in order to get the required output.
56. Define Pig Latin Features?
Ans:
- Pig Latin script is made up of a series of operations, or transformations, that are applied to the input data in order to fetch output.
- Programs can be executed either in Interactive mode through Grunt shell or in Batch mode via Pig Latin Scripts.
- Includes operators for a lot of the traditional data operations.
- User Defined Functions (UDF)
- Debugging Environment
57. What is Pig Engine?
Ans:
Pig Engine is the platform to execute the Pig Latin programs. Pig engine converts Pig Latin operators into a series of MapReduce job.
58. Differentiate between Pig Latin and Hive QL?
Ans:
Pig Latin:
- Pig Latin is a Procedural language
- Nested relational data model
- Schema is optional
HiveQL:
- HiveQL is Declarative
- HiveQL flat relational
- Schema is required
59. Whether Pig Latin language is case-sensitive or not?
Ans:
- We can say, Pig Latin is sometimes not case-sensitive, for example, Load is equivalent to load.
- A=load ‘b’ is not equivalent to a=load ‘b’
- Note: UDF is also case-sensitive, here count is not equivalent to COUNT.
60. What is the purpose of ‘dump’ keyword in Pig?
Ans:
- The keyword “dump” displays the output on the screen.
- For Example- dump ‘processed’
61. Does Pig give any warning when there is a type mismatch or missing field?
Ans:
The pig will not show any warning if there is no matching field or a mismatch. However, if any mismatch occurs, it assumes a null value in Pig.
62. What is Grunt shell?
Ans:
Grunt shell is also what we call as Pig interactive shell. Basically, it offers a shell for users to interact with HDFS.
63. How Do Users Interact With The Shell In Apache Pig?
Ans:
Using Grunt i.e. Apache Pig’s interactive shell, users can interact with HDFS or the local file system.
To start Grunt, users should invoke Apache Pig with no command:
- Executing the command “pig –x local” will result in the prompt –
- grunt >
- This is where PigLatin scripts can be run either in local mode or in cluster mode by setting the configuration in PIG_CLASSPATH.
- To exit from grunt shell, press CTRL+D or just type exit.
64. What co-group does in Pig?
Ans:
Basically, it joins the data set by grouping one particular data set only. Moreover, it groups the elements by their common field and then returns a set of records containing two separate bags. One bag consists of the record of the first data set with the common data set, while another bag consists of the records of the second data set with the common data set.
65. What are relational operations in Pig latin?
Ans:
Relational operations in Pig Latin are:
- For each
- Order by
- Filters
- Group
- Distinct
- Join
- Limit
66. I Have A Relation R. How Can I Get The Top 10 Tuples From The Relation R.?
Ans:
TOP () function returns the top N tuples from a bag of tuples or a relation. N is passed as a parameter to the function top () along with the column whose values are to be compared and the relation R.
67. You Have A File Employee.txt In The Hdfs Directory With 100 Records. You Want To See Only The First 10 Records From The Employee.txt File. How Will You Do This?
Ans:
- The first step would be to load the file employee.txt into with the relation name as Employee.
- The first 10 records of the employee data can be obtained using the limit operator – Result= limit employee 10.
68. How is Pig Useful For?
Ans:
There are 3 possible categories for which we can use Pig. They are:
1) ETL data pipeline
2) Research on raw data
3) Iterative processing
69. What Do You Know About The Case Sensitivity Of Apache Pig?
Ans:
It is difficult to say whether Apache Pig is case sensitive or case insensitive. For instance, user defined functions, relations and field names in pig are case sensitive i.e. the function COUNT is not the same as function count or X=load ‘foo’ is not same as x=load ‘foo’. On the other hand, keywords in Apache Pig are case insensitive i.e. LOAD is same as load.
70. What Are Some Of The Apache Pig Use Cases You Can Think Of?
Ans:
- Apache Pig big data tools, is used in particular for iterative processing, research on raw data and for traditional ETL data pipelines. As Pig can operate in circumstances where the schema is not known, inconsistent or incomplete- it is widely used by researchers who want to make use of the data before it is cleaned and loaded into the data warehouse.
- To build behavior prediction models, for instance, it can be used by a website to track the response of the visitors to various types of ads, images, articles, etc.
71. What are the different math functions available in pig?
Ans:
Below are most commonly used math pig functions
- ABS
- ACOS
- EXP
- LOG
- ROUND
- CBRT
- RANDOM
- SQRT
72.What are the different Eval functions available in pig?
Ans:
Below are most commonly used Eval pig functions
- AVG
- CONCAT
- MAX
- MIN
- SUM
- SIZE
- COUNT
- COUNT_STAR
- DIFF
- TOKENIZE
- IsEmpty
73. How Does a Smarter & Bigger Data Hub Architectures Differ from a Traditional Data Warehouse Architectures?
Ans:
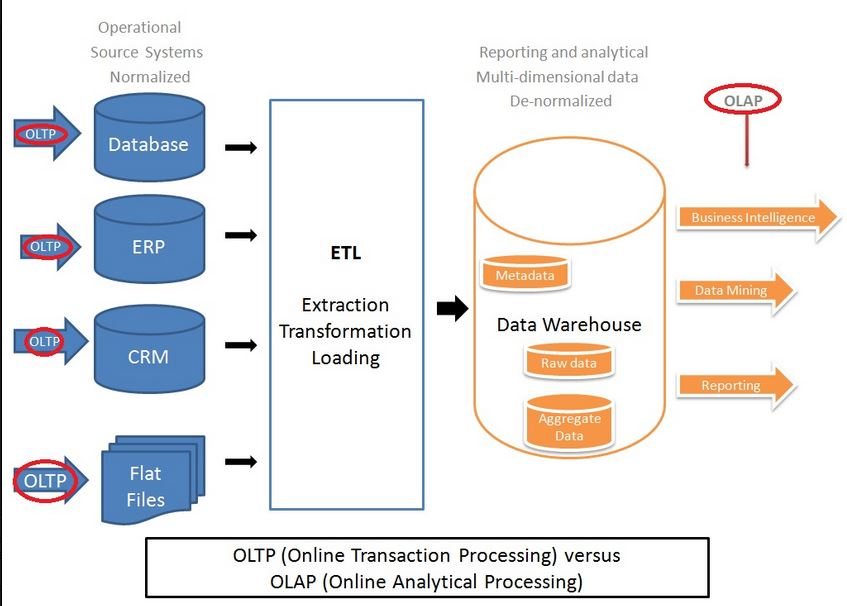
Traditional Enterprise Data Warehouse Architecture
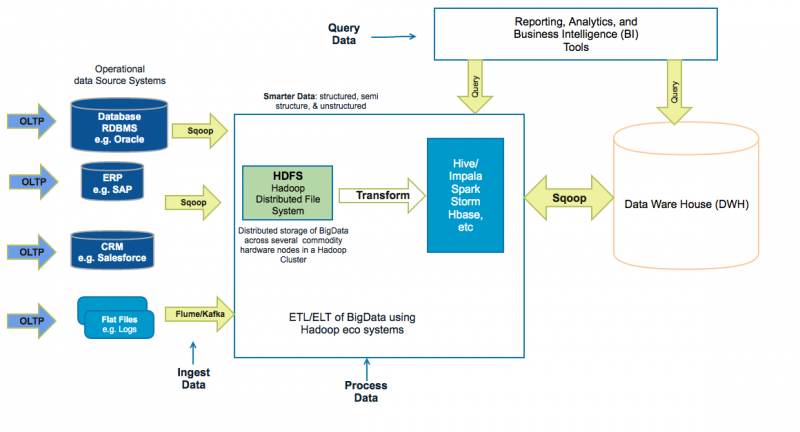
Hadoop-based Data Hub Architecture
74. What Are the Benefits of Hadoop-Based Data Hubs?
Ans:
- Improves the overall SLAs (i.e. Service Level Agreements) as the data volume and complexity grows. For example, “Shared Nothing” architecture, parallel processing, memory intensive processing frameworks like Spark and Impala, and resource preemption in YARN’s capacity scheduler.
- Scaling data warehouses can be expensive. Adding additional high-end hardware capacities and licensing of data warehouse tools can cost significantly more. Hadoop-based solutions can not only be cheaper with commodity hardware nodes and open-source tools, but also can complement the data warehouse solution by offloading data transformations to Hadoop tools like Spark and Impala for more efficient parallel processing of Big Data. This will also free up the data warehouse resources.
- Exploration of new avenues and leads. Hadoop can provide an exploratory sandbox for the data scientists to discover potentially valuable data from social media, log files, emails, etc., that are not normally available in data warehouses.
- Better flexibility. Often business requirements change, and this requires changes to schema and reports. Hadoop-based solutions are not only flexible to handle evolving schemas, but also can handle semi-structured and unstructured data from disparate sources like social media, application log files, images, PDFs, and document files.
75. What Are Key Steps in Big Data Solutions?
Ans:
Ingesting Data, Storing Data (i.e. Data Modelling), and processing data (i.e data wrangling, data transformations, and querying data).
- Ingesting Data
Extracting data from various sources such as:
- RDBMs Relational Database Management Systems like Oracle, MySQL, etc.
- ERPs Enterprise Resource Planning (i.e. ERP) systems like SAP.
- CRM Customer Relationships Management systems like Siebel, Salesforce, etc.
- Social Media feeds and log files.
- Flat files, docs, and images.
- And storing them on data hub based on “Hadoop Distributed File System”, which is abbreviated as HDFS. Data can be ingested via batch jobs (e.g. running every 15 minutes, once every night, etc), streaming near-real-time (i.e 100ms to 2 minutes) and streaming in real-time (i.e. under 100ms).
- One common term used in Hadoop is “Schema-On-Read“. This means unprocessed (aka raw) data can be loaded into HDFS with a structure applied at processing time based on the requirements of the processing application. This is different from “Schema-On-Write”, which is used in RDBMs where schema needs to be defined before the data can be loaded.
- Storing Data
- Data can be stored on HDFS or NoSQL databases like HBase. HDFS is optimized for sequential access and the usage pattern of “Write-Once & Read-Many”. HDFS has high read and write rates as it can parallelize I/O s to multiple drives. HBase sits on top of HDFS and stores data as key/value pairs in a columnar fashion. Columns are clubbed together as column families. HBase is suited for random read/write access. Before data can be stored in Hadoop, you need consider the following:
- Data Storage Formats: There are a number of file formats (e.g CSV, JSON, sequence, AVRO, Parquet, etc.) and data compression algorithms (e.g snappy, LZO, gzip, bzip2, etc.) that can be applied. Each has particular strengths. Compression algorithms like LZO and bzip2 are splittable.
- Data Modelling: Despite the schema-less nature of Hadoop, schema design is an important consideration. This includes directory structures and schema of objects stored in HBase, Hive and Impala. Hadoop often serves as a data hub for the entire organization, and the data is intended to be shared. Hence, carefully structured and organized storage of your data is important.
- Metadata management: Metadata related to stored data.
- Multitenancy: As smarter data hubs host multiple users, groups, and applications. This often results in challenges relating to governance, standardization, and management.
- Processing Data
- Hadoop’s processing framework uses the HDFS. It uses the “Shared Nothing” architecture, which in distributed systems each node is completely independent of other nodes in the system. There are no shared resources like CPU, memory, and disk storage that can become a bottleneck. Hadoop’s processing frameworks like Spark, Pig, Hive, Impala, etc., processes a distinct subset of the data and there is no need to manage access to the shared data. “Sharing nothing” architectures are very scalable as more nodes can be added without further contention and fault tolerant as each node is independent, and there are no single points of failure, and the system can quickly recover from a failure of an individual node.