
Last updated on 08th Jul 2024| 5570
Toad (Tool for Oracle Application Developers) is a robust database management tool widely used by database administrators, developers, and data analysts. It streamlines SQL development, database management, and performance optimization for Oracle databases. Toad offers a comprehensive suite of features, including code debugging, query building, data modeling, and real-time collaboration. These capabilities enhance productivity, ensure high-quality database applications, and facilitate efficient administration.
1. What is Toad?
Ans:
Toad (Tool for Oracle Application Developers) is a database management tool. It boosts productivity for database administrators, developers, and analysts. Toad provides an easy-to-use interface for database interaction. It supports various databases like Oracle, SQL Server, and MySQL. The tool streamlines tasks such as SQL scripting, query execution, and database management. Toad offers robust features for database development and administration.
2. What role does Toad play in Oracle?
Ans:
Toad for Oracle is designed to manage and develop Oracle databases efficiently. It offers tools for writing and debugging PL/SQL code, optimizing SQL queries, and managing database objects. The tool increases productivity by automating repetitive tasks. Toad provides detailed diagnostics and performance tuning for databases. It also supports schema comparison and synchronization. Users can generate comprehensive reports and documentation. Toad simplifies Oracle database administration and development.
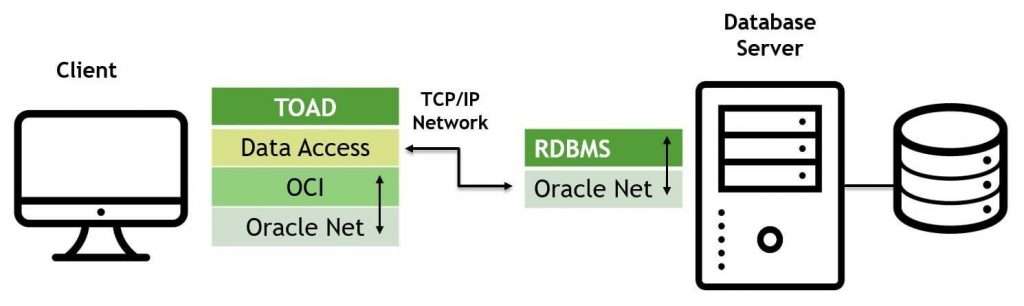
3. List the platforms supported by Toad.
Ans:
- Microsoft Windows
- macOS (using virtualization or compatibility layers)
- Linux (using virtualization or compatibility layers)
- Oracle databases
- Microsoft SQL Server
- MySQL
- PostgreSQL
4. What are the advantages of using Toad?
Ans:
- Boosts productivity with an intuitive interface.
- Automates routine database tasks.
- Provides advanced SQL optimization and tuning tools.
- Facilitates database performance monitoring and diagnostics.
- Supports detailed reporting and documentation.
- Enables efficient schema management.
5. What is Toad Data Point?
Ans:
Toad Data Point is a tool for data integration and analysis. It connects to various data sources, including databases and cloud services. The tool supports data profiling, cleansing, and transformation. Toad Data Point offers advanced analytics and reporting features. Users can create and share interactive dashboards. The tool blends data from multiple sources. Toad Data Point is designed for data analysts and business users.
6. How can DBMS_OUTPUT be enabled in Toad for Oracle?
Ans:
- Connect to the Oracle database in Toad.
- Open the “Editor” window.
- Navigate to the “DBMS Output” tab located at the bottom.
- Click “Turn On” to enable DBMS_OUTPUT.
- Write and execute PL/SQL code using DBMS_OUTPUT.PUT_LINE.
- View the output in the DBMS Output tab.
- Ensure the buffer size is set appropriately to capture all output.
7. List the significant features of Toad.
Ans:
- SQL and PL/SQL editing with syntax highlighting.
- SQL optimization and performance tuning.
- Database schema browsing and management.
- Data modelling and design.
- Advanced database diagnostics and monitoring.
- Automation of database tasks and workflows.
- Integration with version control systems.
8. What is a Toad Data Modeler?
Ans:
Toad Data Modeler is a tool for designing and managing database schemas. It allows users to create, modify, and analyze data models. The tool supports both logical and physical data modelling. It can reverse-engineer existing databases. It provides features to generate SQL scripts for database creation. Users can visualize database structures through diagrams. The tool supports multiple database platforms.
9. What is the difference between inner join and outer join in SQL?
Ans:
| Criteria | Inner Join | Outer Join |
|---|---|---|
| Definition | Returns rows when there is a match in both tables. | Returns all rows from one table and the matched rows from the other table. |
| Result Set | Only the matched rows are returned. | Includes matched rows plus unmatched rows from one or both tables. |
| Types | Only one type. | Three types: Left Outer Join, Right Outer Join, Full Outer Join. |
| Usage | Used when only matching records are needed. | Used when all records from one or both tables are needed, regardless of a match. |
10. How can debugging be enabled in Toad?
Ans:
- First, open Toad and connect to the database.
- Navigate to the session browser or SQL editor where the code needs to be debugged.
- Set breakpoints at desired lines of code by clicking in the left margin.
- Execute the script in debug mode using the appropriate toolbar button or menu option. As execution reaches breakpoints, Toad will pause and allow inspection of variables and step-by-step code execution.
11. What are the features of Data Modeler?
Ans:
Data Modeler offers visual data modelling, database design, and schema management. It supports forward and reverse engineering, allowing for easy transitions between logical and physical models. The tool provides an intuitive drag-and-drop interface for creating entity-relationship diagrams. It includes robust validation features to ensure model accuracy and integrity. Data Modeler supports multiple database platforms, enhancing its versatility.
12. How to Install Toad for SQL Server?
Ans:
- Download the Toad for SQL Server installer from the Quest website. Launch the setup and adhere to the prompts displayed on the screen.
- Select the installation directory and accept the license agreement. Then, select the components to install, such as the core application and additional features.
- Once “Install” is selected, watch for the installation procedure to finish. Once installed, launch Toad for SQL Server and configure the initial setup. Connect to SQL Server instances to start using Toad.
13. Does Toad work with SQL Server?
Ans:
- Yes, Toad works with SQL Server. It provides comprehensive tools for database development, management, and optimization.
- Toad supports various versions of SQL Server, including on-premises and cloud-based instances. It offers features like SQL editing, debugging, and performance tuning.
- Toad’s intuitive interface enhances database administrators’ and developers’ productivity. It also includes data visualization and reporting tools. Integration with version control systems ensures smooth collaboration.
14. What is a Toad client?
Ans:
A Toad client is a software application used for database development and management. It provides tools for querying, editing, and managing databases across different platforms. Toad clients are designed to improve database administrators’ and developers’ productivity. They offer features such as SQL editing, schema comparison, and performance tuning. Toad clients support various databases, including Oracle, SQL Server, and MySQL. The software includes an intuitive interface and robust automation capabilities.
15. What is Toad Edge?
Ans:
Toad Edge is a lightweight, flexible database management tool designed for open-source databases. It supports databases like MySQL, MariaDB, and PostgreSQL. Toad Edge offers features for database development, management, and DevOps processes. It provides an intuitive interface for SQL development, schema comparison, and data synchronization. The tool supports containerized environments and cloud databases. It includes automation features to streamline repetitive tasks.
16. What is toad DB2?
Ans:
- Toad for DB2 is a comprehensive database management tool specifically for IBM DB2 databases. It provides features for database development, administration, and performance tuning.
- The tool includes SQL editing, debugging, and optimization capabilities. Toad for DB2 supports schema management, data import/export, and query building.
- It offers robust automation features to streamline routine tasks. The software enhances productivity for DB2 database administrators and developers.
17. What is toad automation?
Ans:
- Toad automation refers to the automation features available in Toad products for streamlining database tasks.
- These features allow users to automate routine processes like backups, data imports/exports, and report generation. Toad automation helps reduce manual effort and minimize errors.
- It includes a visual automation designer for creating workflows without writing code. Users can schedule automated tasks to run at predetermined times or intervals.
- The automation capabilities enhance efficiency and consistency in database management.
18. Define Toad for SAP solutions.
Ans:
Toad for SAP Solutions is a database management tool designed for SAP databases like SAP HANA. It provides features for SQL development, database administration, and performance tuning. The tool includes an intuitive interface for managing SAP database objects and executing queries. Toad for SAP Solutions supports data visualization and reporting to enhance insights. It offers automation capabilities to streamline routine database tasks. The software improves productivity for SAP database administrators and developers.
19. What is the CAP theorem in database systems?
Ans:
Brewer’s theorem, another name for the CAP theorem, states that in distributed database systems, it is impossible to achieve Consistency, Availability, and Partition Tolerance simultaneously. Ensuring consistency guarantees that every node views the same data simultaneously. Availability ensures that every request is answered, even if it fails. Partition tolerance refers to the system’s ability to function even when a network partition occurs. The theorem implies trade-offs, where achieving two of the three properties is possible but only some of the three.
20. Describe the distinction between an index that is clustered and one that isn’t.
Ans:
- A clustered index determines the actual arrangement of the data in a table, meaning the table rows are stored in the index’s order. Each table may only have one clustered index.
- A non-clustered index, on the other hand, is a separate structure that references the table data without altering its physical order. Non-clustered indexes can exist in multiple instances per table.
- Clustered indexes are generally faster for retrieving ranges of data. Non-clustered indexes are better for lookups that do not require the data to be in order.
21. How does ACID compliance ensure data integrity in databases?
Ans:
- ACID compliance ensures data integrity by enforcing four principles: Atomicity, Consistency, Isolation, and Durability. Atomicity ensures that each component of a transaction completes successfully, or none do.
- Consistency ensures the database transitions between valid states. Transactions cannot interfere with one another while they are isolated.
- Durability means committed transactions persist despite system failures. These principles work together to prevent data corruption and ensure reliable transactions.
22. What are NoSQL databases, and when would one be chosen over a traditional SQL database?
Ans:
NoSQL databases are non-relational and designed for large-scale data storage and real-time web applications. They offer flexibility with dynamic schemas, scalability, and high performance for unstructured data. You might choose NoSQL over SQL when dealing with large, varied data sets, requiring horizontal scaling, or needing fast development cycles. They are ideal for applications like social media, big data, and real-time analytics but may need more ACID transactions of SQL databases.
23. Describe the concept of database normalization.
Ans:
Database normalization organizes a database to minimize redundancy and enhance data integrity. It involves dividing large tables into smaller, related ones and defining relationships. Normalization follows standard forms (1NF, 2NF, 3NF, etc.), each addressing specific redundancy and dependency types. It ensures efficient data storage, reduces anomalies during data operations, and improves performance. The goal is to balance normalized structure with practical query efficiency.
24. What is a stored procedure? How is it different from a function?
Ans:
A collection of precompiled SQL statements is kept in a stored procedure in the database and is used to perform specific tasks like modifying data or managing transactions. A database object that returns a single value is called a function or table, and it is used primarily within queries. The critical difference is that functions must return a value and cannot change the database state, while stored procedures can perform actions like transactions and return multiple results.
25. How does indexing improve database performance?
Ans:
- Indexing improves database performance by creating a data structure that speeds up data retrieval.
- Indexes allow quick access to records, reducing the need to scan the entire table.
- They are typically created on columns frequently used in query conditions, enhancing the speed of SELECT, JOIN, and WHERE operations.
- However, indexes consume additional storage, Which may cause INSERT, UPDATE, and DELETE data change processes to lag.
26. What are some alternatives to Toad for Oracle?
Ans:
- Oracle SQL Developer
- DBeaver
- SQL Workbench/J
- Navicat for Oracle
- Aqua Data Studio
- PL/SQL Developer
- DbVisualizer
27. Explain the purpose of the GROUP BY clause in SQL.
Ans:
The GROUP BY clause in SQL groups rows into summary rows that have the same values in the designated columns. It’s often used with aggregate functions like COUNT, SUM, AVG, MAX, or MIN to perform calculations on each group. GROUP BY simplifies data analysis by organizing data into meaningful summaries, such as sales totals per region or average scores per student. It ensures efficient aggregation of large datasets for reporting and analysis.
28. What is a subquery, and could an example of its usage be provided?
Ans:
A subquery, or inner query, is a query nested within another SQL query to perform operations dependent on the results of the external inquiry. Subqueries are applicable to WHERE, FROM, SELECT, and or HAVING clauses. For example, to find employees with salaries above the average, use:
- SELECT name FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
The subquery calculates the average salary, and the outer query retrieves names of employees earning more than this average.
29. What are the methods to optimize a SQL query for better performance?
Ans:
- Use indexes on frequently queried columns.
- Specify only needed columns, avoiding SELECT *.
- Prefer joins over subqueries where possible.
- Limit wildcards and avoid starting patterns with them.
- Break complex queries into simpler ones or use temporary tables.
- Regularly update statistics for the query optimizer.
- Ensure proper database normalization to reduce redundancy and improve efficiency.
30. What are triggers in a database, and in what scenarios would they be used?
Ans:
Triggers are automated procedures executed in response to specific events on a table or view, such as INSERT, UPDATE, or DELETE. They enforce business rules, maintain audit trails, and ensure data integrity by executing predefined actions automatically. For instance, a trigger can automatically record the modification date when an employee’s record is updated. Triggers are useful for logging changes, enforcing complex constraints, and synchronizing tables, though excessive use can impact performance.
31. Describe the advantages and disadvantages of using ORM (Object-Relational Mapping).
Ans:
Advantages:
- Simplifies database interactions by using objects.
- Reduces the necessity for writing SQL in application code.
- Provides a standardized API across different databases.
Disadvantages:
- This can lead to performance issues with complex queries.
- It may obscure important details of database interactions.
- Has a steep learning curve for newcomers.
32. What part do transactions serve in database administration?
Ans:
Transactions treat several activities as a single unit, ensuring data integrity. They follow ACID properties (Atomicity, Consistency, Isolation, Durability). If any operation within a transaction fails, the entire transaction rolls back, preventing partial updates. Transactions manage concurrent data access effectively. They maintain a stable state in case of errors. Critical for applications like banking and inventory management. Transactions provide a reliable way to manage database changes.
33. Explain the concept of database sharding.
Ans:
Database sharding splits an extensive database into smaller, manageable pieces called shards. Each shard functions as an independent database, managing a subset of the data. Sharding improves performance and scalability by distributing the load across multiple servers, which is beneficial for high-traffic applications. Shards can be divided based on criteria like user ID ranges or geographic location. It allows for horizontal scaling and efficient data management and accelerates data access.
34. How does replication work in database systems?
Ans:
- Replication copies data from a primary server (master) to one or more secondary servers (enslaved people).
- The enslaved people mirror changes made to the master, Ensuring data consistency. Replication can be synchronous (real-time updates) or asynchronous (delayed updates).
- It enhances data availability and reliability. Replication helps balance the load by distributing read operations across servers.
- Failover mechanisms can switch to a replica if the master fails. Replication is crucial for disaster recovery and backups.
35. What distinguishes constraints using unique keys from those using primary keys?
Ans:
- Every record in a table is uniquely identified by its primary key, which is non-NULLable. Each table may only have one primary key.
- It ensures that each record is unique and facilitates indexing. A unique key also enforces uniqueness but can include NULL values.
- Multiple unique keys can exist in a table. Both keys ensure data integrity. Primary keys often establish relationships between tables.
36. Describe the benefits of using database views.
Ans:
Views simplify complex queries by combining several complicated queries into one virtual table. They enhance security by restricting access to specific data. Views can represent aggregated or calculated data, reducing redundant calculations. They help maintain a consistent and simplified user interface. Views support reusability and hide the complexity of underlying data structures. They improve query readability and maintainability. Views can also optimize performance through pre-computed results.
37. What is the purpose of the HAVING clause in SQL queries?
Ans:
Following the use of the GROUP BY clause, the HAVING clause filters the results. It specifies conditions on aggregated data, unlike WHERE, which applies to individual rows. HAVING restricts the output of grouped records. It is helpful in filtering groups based on aggregate functions like COUNT, SUM, or AVG. Ensures only relevant group results are returned. Enhances SQL queries involving groupings. Provides additional filtering capabilities post-aggregation.
38. What are the best practices for handling NULL values in SQL?
Ans:
- NULL values represent missing or undefined data in SQL. They are handled using IS NULL and IS NOT NULL conditions in queries.
- Functions like COALESCE or IFNULL provide default values for NULLs. Aggregate functions like COUNT, SUM, or AVG can be adapted to handle NULLs appropriately.
- Proper indexing strategies optimize queries involving NULL values. Handling NULLs ensures accurate query results and data integrity. Careful NULL management is essential for robust SQL development.
39. Explain the difference between OLAP and OLTP.
Ans:
- OLAP (Online Analytical Processing) is designed for complex queries and data analysis, typically in data warehousing. OLTP (Online Transaction Processing) handles transactional data with high speed and availability.
- OLAP supports multi-dimensional queries and data aggregation. OLTP manages numerous short transactions like inserts, updates, and deletes.
- OLAP is optimized for read-heavy operations, while OLTP is for write-heavy operations. OLAP systems assist in decision-making through data insights. OLTP systems ensure real-time data processing for daily operations.
40. What benefits come with utilizing a columnar database?
Ans:
Instead of storing data in rows, columnar databases store it in columns, optimizing read performance for analytical queries. They minimize I/O operations by reading only necessary columns. Columnar storage enables efficient data compression, reducing storage space. It is ideal for OLAP applications with complex queries and large datasets. Columnar databases enhance query performance through better cache utilization. They support faster aggregation and indexing operations.

Get JOB Toad Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. How does database partitioning improve performance?
Ans:
Database partitioning improves performance by splitting an extensive database into smaller, more manageable parts. Each partition can be stored on different disks, reducing I/O contention. Queries run faster by accessing smaller data sets. Parallel processing of partitions enhances speed. It helps with load balancing and maintenance tasks like backups. Partitioning isolates hot spots for better data management. It ultimately leads to more efficient database operations.
42. Describe the concept of database denormalization and when it is appropriate to use.
Ans:
- Database denormalization merges tables to reduce the need for joins, speeding up read operations. It’s suitable when read performance is prioritized overwrite performance.
- This method is helpful in reporting and data warehousing, where complex queries require quick results.
- Denormalization increases data redundancy and storage costs. It’s beneficial in read-heavy applications, and when frequently needed, precomputed values are involved.
43. What is the role of a database administrator (DBA)?
Ans:
- A Database Administrator (DBA) manages database installation, configuration, and maintenance.
- They ensure data integrity, security, and availability. DBAs optimize database performance and conduct tuning.
- They handle backup and recovery tasks. Managing user access and permissions is part of their role.
- They monitor database performance and resolve issues. DBAs also plan for database growth and scalability.
44. What are the steps involved in handling a database migration from one server to another?
Ans:
First, evaluate the current database setup and develop a migration plan. Backup the existing database to prevent data loss. Set up the new server environment and install the necessary database software. Restore the backup on the new server. Test the new setup for data integrity and performance—update application connection strings to the new server. Monitor the new server after migration to ensure stability.
45. Explain the concept of ACID properties in database transactions.
Ans:
The letters ACID stand for Isolation, Atomicity, Consistency, and Durability. Atomicity ensures all transaction parts are completed or none are applied. Consistency maintains database validity before and after transactions. Concurrent transactions cannot influence one another while they are isolated. Durability ensures committed transactions remain permanent even in system failures. These properties ensure reliable transaction processing. They maintain data integrity and consistency.
46. What is the purpose of a database index, and how does it work?
Ans:
- A database index speeds up data retrieval operations. It functions like a book index, allowing quick access to rows based on critical values.
- Indexes are created on columns frequently used in search conditions and joins. They reduce the data scanned by the database engine.
- However, indexes add overhead during data modifications. Indexes can be single-column or multi-column.
- They are vital for performance optimization in large databases.
47. What are the techniques to optimize SQL queries for better performance?
Ans:
- First, analyze the query execution plan to identify issues. Use indexing on columns in WHERE, JOIN, and ORDER BY clauses.
- Avoid using SELECT *; specify only necessary columns. Normalize the database to reduce redundancy.
- Use joins instead of subqueries when possible. Break down complex queries into simpler parts. Update statistics frequently to support the query optimizer.
48. Describe the distinction between an index that is clustered and one that is not.
Ans:
A clustered index, with only one allowed per table, determines the actual arrangement of the data in a table. It is efficient for range queries since data is stored in order. A non-clustered index creates a separate structure from the data rows, with pointers to the actual data. Multiple non-clustered indexes can exist per table. Non-clustered indexes are helpful for specific value searches. Clustered indexes enhance data retrieval speed based on indexed columns.
49. What is database normalization, and why is it important?
Ans:
Database normalization organizes data to reduce redundancy and improve integrity. It involves dividing data into tables and defining relationships between them. Each piece of data is stored only once, maintaining consistency. Normalization simplifies database structure, making maintenance easier. It improves query performance by minimizing redundant data. In order to develop databases that are scalable and efficient, normalization is essential.
50. What are the best practices for handling database transactions?
Ans:
- Begin a transaction using BEGIN TRANSACTION. Execute the necessary SQL commands within the transaction.
- Complete each step successfully before proceeding to the next one. If all operations succeed, commit the transaction using COMMIT to finalize changes.
- If any operation fails, use ROLLBACK to revert changes. Implement proper error handling and logging. This process ensures data consistency and integrity.
51. What are the different types of SQL joins?
Ans:
- The main types of SQL joins include INNER JOIN, LEFT JOIN (LEFT OUTER JOIN), RIGHT JOIN (RIGHT OUTER JOIN), FULL JOIN (FULL OUTER JOIN), CROSS JOIN, and SELF JOIN.
- INNER JOIN returns rows with matching values in both tables. All rows from the left table and matching rows from the right table are returned by an LEFT JOIN.
- All rows from the right table and matching rows from the left table are returned via a RIGHT JOIN. FULL JOIN returns all rows in either table that have matches.
- The tables’ Cartesian product is generated via CROSS JOIN. A table is joined to itself via SELF JOIN.
52. What is the difference between DELETE and TRUNCATE statements?
Ans:
DELETE removes rows one by one and logs each deletion, allowing for a WHERE clause and rollback. TRUNCATE removes all rows at once without logging individual deletions, making it faster but not recoverable. DELETE can use conditions and triggers, while TRUNCATE resets identity columns and can’t use conditions. DELETE is a DML command, whereas TRUNCATE is a DDL command. TRUNCATE is used to clear a table quickly. DELETE is suitable for selective row removal.
53. How does SQL injection work, and how can it be prevented?
Ans:
SQL injection involves inserting malicious SQL code into an input field, which the database then executes, potentially compromising data. To prevent it, use prepared statements and parameterized queries to separate SQL code from data inputs. Implement input validation and sanitization to ensure that only expected inputs are processed. Utilize ORM frameworks, apply the principle of least privilege for database accounts, and conduct regular code reviews. Avoid dynamically generating SQL from user input.
54. Explain the concept of a foreign key in a database.
Ans:
- A foreign key is a column or collection of columns in a foreign key table that references the primary key of another table.
- It enforces referential integrity by ensuring the values in the foreign key column match the primary fundamental values in the referenced table.
- This helps maintain data consistency and allows for cascading updates or deletions. Foreign keys are crucial in relational database design for establishing relationships between tables.
55. What are the advantages and disadvantages of NoSQL databases compared to relational databases?
Ans:
NoSQL databases offer advantages such as scalability, flexible data models, and better performance for specific workloads, especially with large or unstructured data. They are ideal for real-time web applications and distributed data storage. Disadvantages include:
- Less mature querying capabilities a.
- Lack of ACID transactions in some NoSQL systems.
- Potential challenges with data consistency and management.
56. What considerations are important when designing a database schema for an e-commerce website?
Ans:
Designing a database schema for an e-commerce website involves creating tables for products, users, orders, order items, categories, reviews, and payments. Each table should have primary keys and foreign keys to establish relationships. For instance, the orders table references users and payment methods, while order items reference products and orders. Normalize data to minimize redundancy and ensure efficient querying. Add indexes on frequently searched fields and optimize for read-heavy workloads.
57. What are the best practices for backing up and restoring databases?
Ans:
Best practices for backing up databases include performing regular full, incremental, and differential backups. Keep backups off-site or in different locations, such as cloud storage, to protect against localized disasters. Automate backup processes and periodically test backup integrity. Encrypt backup files for security. Regularly test restore procedures to ensure they work and document the steps clearly. Maintain an updated disaster recovery plan. Ensure backups cover all critical data and configurations.
58. What methods are used to monitor and optimize database performance?
Ans:
- Track metrics such as query response time, CPU usage, memory usage, disk I/O, and network traffic.
- Use database monitoring tools and performance counters.
- Optimize performance by analyzing and optimizing queries, creating appropriate indexes, and updating statistics. Partition large tables and use caching where necessary.
- Adjust database configuration settings based on workload patterns.
59. What is the difference between a view and a materialized view in databases?
Ans:
- A view is a virtual table created by a query joining one or more tables, showing current data from underlying tables without storing it physically.
- A materialized view stores the query result physically and can be refreshed periodically or on-demand.
- Views simplify complex queries and enhance security by restricting access to specific data.
- Materialized views improve query performance by precomputing and storing results but require additional storage and maintenance.
60. What are the best practices for handling database transactions in a distributed environment?
Ans:
In a distributed environment, transactions are handled using techniques like two-phase commit (2PC) to ensure all databases either commit or roll back changes together. Distributed transactions maintain ACID properties across multiple databases, with a transaction coordinator managing the prepare and commit phases. Another approach is using distributed databases that support multi-document ACID transactions. Ensure robust logging, fault tolerance, and recovery mechanisms.

61. What is the purpose of database locking, and how does it work?
Ans:
The purpose of database locking is to ensure data consistency and integrity during concurrent access by multiple users or processes. They are locking works by restricting access to data items when they are being read or modified. There are different types of locks, such as shared locks for read operations and exclusive locks for write operations. Locks prevent conflicting operations from co-occurring, thus avoiding data anomalies. The lock manager within the database system handles the acquisition and release of locks.
62. Describe the concept of database replication and its types.
Ans:
- Master-Slave Replication: One server (master) handles writes, and others (enslaved people) replicate data for reads.
- Master-Master Replication: Multiple servers handle both reads and writes, synchronizing changes among them.
- Snapshot Replication: Data is copied at a specific point in time.
- Transactional Replication: Changes are continuously replicated as transactions occur. Replication improves fault tolerance and scalability but requires careful conflict resolution and consistency management.
63. What are the advantages and disadvantages of using database triggers?
Ans:
Advantages:
- Automatic Execution: Triggers automatically enforce rules and constraints, ensuring data integrity.
- Consistency: They maintain consistency across related tables by performing related actions.
Disadvantages:
- Performance Overhead: Triggers can slow down database operations due to additional processing.
- Complexity: Managing and debugging triggers can be complex, especially with multiple triggers on the same table.
64. What are the methods for troubleshooting performance issues in a database?
Ans:
- Identify Symptoms: Look for slow queries, high CPU usage, memory bottlenecks, or I/O wait times.
- Examine Execution Plans: Analyze query execution plans to find inefficient operations.
- Check Indexes: Ensure appropriate indexing and identify any missing or redundant indexes.
- Monitor Resource Usage: Use database monitoring tools to track resource consumption and identify hotspots.
- Analyze Logs: Review database logs for errors, long-running queries, and deadlocks.
65. Explain the concept of database schema and its importance.
Ans:
A database schema is a structure that defines how data is organized in a database. It includes definitions of tables, columns, data types, indexes, relationships, and constraints. The database is designed according to the schema. Guiding how data is stored, accessed, and manipulated. It ensures data integrity by enforcing rules and restrictions like foreign keys and primary keys. A well-designed schema improves performance through efficient data retrieval and storage. It also facilitates more manageable maintenance and scalability by providing a clear structure.
66. What are the strategies for ensuring data consistency across distributed databases?
Ans:
Use distributed transactions with two-phase commit protocols to ensure ACID properties across multiple databases. Implement data replication and synchronization techniques for consistency across distributed nodes. Use versioning or timestamp-based conflict resolution mechanisms for concurrent updates. Design schemas with partitioning strategies to minimize distributed data access latency. Employ consensus algorithms like Paxos or Raft for distributed coordination and consistency.
67. How does indexing impact write operations in a database?
Ans:
- Indexing significantly improves read operations by providing faster data retrieval but can negatively impact write operations.
- When data is inserted, updated, or deleted, the corresponding indexes must also be updated to reflect these changes.
- This additional maintenance can lead to increased CPU and I/O overhead, slowing down write performance. Inserting new rows requires updating all relevant indexes, which can be time-consuming.
- Similarly, updates to indexed columns need index adjustments.
68. Describe the role of indexing in database query optimization.
Ans:
Indexing plays a crucial role in database query optimization by significantly speeding up data retrieval. A data structure called an index offers a rapid lookup mechanism for accessing rows in a table based on the values of one or more columns. Upon query execution, the database might make use of indexes to find the required rows without scanning the entire table. This reduces the number of I/O operations and improves query performance.
69. What is the difference between a SQL database and a NoSQL database?
Ans:
- Data Model: SQL databases use a structured schema with tables, rows, and columns, while NoSQL databases use various models, such as document, key-value, column-family, and graph.
- Query Language: SQL databases use Structured Query Language (SQL) for data manipulation, while NoSQL databases often use more flexible, API-based querying.
- Scalability: SQL databases are vertically scalable, meaning they can be expanded by adding more power to a single server. NoSQL databases are horizontally scalable, allowing them to expand by adding more servers.
- ACID Compliance: SQL databases prioritize ACID properties for transactional consistency. NoSQL databases may sacrifice some of these properties for performance and scalability.
70. How does ACID compliance ensure data integrity in database systems?
Ans:
- A transaction’s atomicity guarantees that every component is finished; if any part fails, the entire transaction is reverted.
- Consistency: Ensures that a transaction preserves database constraints and rules while moving the database from one legitimate state to another.
- Isolation: Prevents problems like dirty reads and missed updates by making sure that concurrent transactions don’t interact with one another.
- Durability: Makes sure that a transaction is persistent even in the case of a system failure after it has been committed.
71. What are the common database design patterns, and how are they applied?
Ans:
Common database design patterns include the Singleton, Factory, and Repository patterns. The Singleton ensures a single instance of a database connection. The Factory pattern offers a database object creation interface. Database objects. The Repository pattern separates business logic from data access logic. Other patterns include the Data Mapper, which moves data between objects and a database. The Active Record pattern combines data access and domain logic.
72. Explain the concept of database partitioning and its benefits.
Ans:
Database partitioning divides an extensive database into smaller, more manageable pieces. It can be horizontal, where rows are split into different tables, or vertical, where columns are split. Partitioning decreases the quantity of data examined, which enhances query performance. It enhances manageability by isolating data in different partitions. Partitioning can also improve availability by allowing operations on one partition without affecting others.
73. What are the key practices to ensure data security and integrity in a database?
Ans:
- Implement access controls and encryption for sensitive data.
- Regularly update and patch database systems to prevent vulnerabilities.
- Use robust authentication mechanisms and enforce strict password policies.
- For data integrity, use constraints like primary keys, foreign keys, and unique constraints.
- Implement transactions to ensure atomicity, consistency, isolation, and durability (ACID).
74. Describe the process of database normalization and its goals.
Ans:
- Normalization organizes a database to reduce redundancy and improve data integrity.
- It involves decomposing tables into smaller, related tables. The process follows normal forms: The First Normal Form (1NF) eliminates duplicate columns.
- The Second Normal Form (2NF) removes subsets of data that apply to multiple rows.
- The Third Normal Form (3NF) removes columns not dependent on the primary key. Higher standard forms further refine the structure.
75. What is denormalization, and in what scenarios would it be applied in database design?
Ans:
Combining normalized tables is the process of denormalization, which enhances read performance. It introduces redundancy for the sake of speed, trading off some normalization benefits. Use denormalization when read-heavy operations cause performance bottlenecks in a highly normalized database. It can also simplify query complexity, reducing the need for complex joins. Consider it when the database design is more complex than the application’s data access patterns.
76. What are the techniques for optimizing database performance in read-heavy workloads?
Ans:
Optimize read-heavy workloads by using indexing to speed up query retrieval times. Denormalize the database to reduce the complexity of joins and improve read efficiency. Use caching methods to keep data that is often retrieved in memory. Implement read replicas to distribute read traffic across multiple servers. Optimize query performance by rewriting inefficient queries and avoiding whole table scans. Divide up big tables to cut down on data scanned during queries. Regularly monitor and tune database performance parameters.
77. What is database clustering, and when is it used?
Ans:
- Database clustering involves multiple database servers working together as a single system. Distributing data across nodes offers high availability and fault tolerance.
- Clustering improves performance by load-balancing queries across multiple servers. It’s used when applications require continuous availability and cannot tolerate downtime.
- Clustering is beneficial for handling large-scale applications with heavy workloads. It also enhances scalability by allowing the addition of more nodes. Clustering supports failover mechanisms in case of node failures.
78. Explain the difference between horizontal and vertical scaling in databases.
Ans:
- Horizontal scaling (scaling out) adds more servers to handle increased load, distributing data across multiple machines.
- It improves performance by balancing the load and providing fault tolerance. Vertical scaling (scaling up) involves adding more resources (CPU, RAM) to an existing server.
- It enhances performance by increasing the capacity of a single machine. Horizontal scaling is more complex but offers better long-term scalability.
- Vertical scaling is more straightforward but has hardware limitations. Both approaches can be used together for optimal performance.
79. What factors should be considered when choosing a DBMS for an application?
Ans:
Consider data model requirements (relational vs. NoSQL), scalability needs, and data consistency requirements. Evaluate performance metrics like throughput, latency, and concurrency capabilities. Assess deployment options (on-premises vs. cloud) and integration with existing systems. Consider security features, compliance requirements, and vendor support. Evaluate licensing costs, maintenance overhead, and community support for the DBMS.
80. How does database replication work, and what are its benefits?
Ans:
Database replication involves copying data from one database server to another. It can be synchronous, ensuring all copies are updated simultaneously, or asynchronous, where updates occur with a delay. Replication increases fault tolerance and data availability by providing multiple data copies. It enhances read performance by distributing read operations across replicas. Replication supports disaster recovery by maintaining backups in different locations. It enables load balancing and reduces latency for geographically distributed applications.
81. What are the benefits of using stored procedures in a database?
Ans:
- Stored procedures enhance performance by reducing network traffic and improving execution speed.
- They promote code reusability and modularity, enhancing maintenance and security.
- Stored procedures also provide a layer of abstraction for database operations, ensuring consistent business logic execution.
- Additionally, they can optimize access to data by utilizing indexes effectively and reducing the overhead of query compilation.
82. What key factors should be considered in designing a database schema for a social media platform?
Ans:
- Designing a schema involves creating tables for users, posts, comments, and relationships. Use normalization to minimize redundancy and ensure data integrity.
- Implement indexing on frequently queried fields like user IDs and timestamps. Consider scalability with partitioning and sharding strategies.
- Include features for user authentication, authorization, and privacy settings.
- Utilize NoSQL for flexible schema requirements and handle large volumes of unstructured data efficiently.
83. What are the considerations when designing a database for high availability?
Ans:
Ensure redundancy with replication across multiple servers or data centres. Use load balancing and clustering for fault tolerance and automatic failover. Implement robust backup and restore procedures with minimal downtime. Optimize network and storage performance to handle peak loads. Monitor health metrics proactively and automate recovery processes. Test failover mechanisms regularly to ensure reliability during critical operations.
84. Describe the role of indexing in optimizing database queries.
Ans:
Indexes speed up query execution by enabling rapid data retrieval based on specified columns. They reduce the need for full table scans, improving overall database performance. Properly indexed tables enhance data retrieval efficiency and support complex query operations. However, over-indexing can lead to increased storage and maintenance overhead. Regular index maintenance is crucial to ensure optimal query performance as data evolves.
85. What are the best practices for handling schema changes in a production database?
Ans:
- Implement changes during scheduled maintenance windows to minimize impact on operations.
- Use version control and migration scripts to track and apply schema modifications systematically. Before deploying, carry out extensive testing in a staging environment changes to production.
- Ensure rollback procedures are in place in case of unforeseen issues.
- Communicate changes to stakeholders and monitor system performance closely post-deployment to detect any anomalies promptly.
86. Explain the concept of database snapshots and their use cases.
Ans:
- Database snapshots provide read-consistent views of data at a specific point in time without affecting ongoing transactions.
- They are used for reporting, backup, and data recovery purposes. Snapshots allow for quick data access for analytical queries without locking operational data.
- They support point-in-time recovery by providing a reference for restoring databases to previous states.
- However, snapshots consume storage space, and their performance impact should be monitored in production environments.
87. What is database caching, and how does it improve performance?
Ans:
Database caching keeps frequently requested information in RAM for faster retrieval and reduced latency. It improves application response times by minimizing disk I/O operations. Caching mechanisms like query result caching and object caching optimize data access for applications. However, cache invalidation strategies are critical to ensure data consistency. Caching also requires careful memory management to avoid resource contention and performance degradation.
88. Describe the benefits and challenges of using cloud databases.
Ans:
Cloud databases offer scalability, flexibility, and cost efficiency by eliminating the need for on-premises infrastructure. They provide high availability with built-in redundancy and automated backups. Cloud databases support global distribution and disaster recovery with geo-replication capabilities. However, data security, compliance, and vendor lock-in are concerns that require careful consideration. Performance may also vary based on network latency and service-level agreements (SLAs).
89. What are the critical differences between MongoDB and MySQL?
Ans:
- MongoDB is a NoSQL database known for its flexibility, schema-less structure, and horizontal scalability.
- MySQL is a traditional relational database with a predefined schema, ACID compliance, and strong support for complex queries.
- MongoDB uses BSON (binary JSON) for data storage, while MySQL relies on structured tables with SQL querying capabilities.
- MongoDB is suited for large-scale applications with unstructured or rapidly evolving data, while MySQL is ideal for structured data and transactional applications.
90. What methods are commonly used to monitor database performance and identify bottlenecks?
Ans:
Monitor metrics like query execution time, throughput, and resource utilization (CPU, memory, disk). Use database-specific monitoring tools and performance counters. Analyze query execution plans and optimize indexes for frequently accessed queries. Implement database profiling to identify slow queries and resource-intensive operations. Use alerts and thresholds to detect performance degradation and bottlenecks early. Continuously tune database configurations and hardware resources based on monitoring insights.
91. What is the role of a database administrator (DBA) in an organization?
Ans:
DBAs manage and maintain databases to ensure data availability, integrity, and security. They optimize database performance through indexing, query optimization, and resource allocation. DBAs implement backup and recovery strategies to prevent data loss and ensure business continuity. They handle schema changes, user access control, and database migrations. Additionally, DBAs monitor database health, diagnose issues, and collaborate with developers to optimize database design and application performance.




