
Last updated on 19th Jun 2020| 8773
The SQL Server DBA advertise is relied upon to develop to more than $5 billion by 2020, from just $180 million, as per SQL Server DBA industry gauges. In this way, despite everything you have the chance to push forward in your vocation in SQL Server DBA Development. GangBoard offers Advanced SQL Server DBA Interview Questions and answers that assist you in splitting your SQL Server DBA interview and procure dream vocation as SQL Server Developer. A database administrator is responsible for a wide range of tasks of varying complexity having to do with data and data storage. In a business environment that’s driven by high velocity and high volume data of various types, skilled database administrators play a vital role in a company’s overall success and are in high demand. SQL Server DBA Interview Questions and answers are very useful to the Fresher or Experienced person who is looking for a new challenging job from the reputed company. Our SQL Server DBA Questions and answers are very simple and have more examples for your better understanding.
1.What is SQL server dba ?
Ans:
SQL Server DBA refers “Database Administrator” for Microsoft SQL Server, a relational database management system. The DBA’s role is to ensure the optimal performance, integrity, and security of databases.
2. Define DBA.
Ans:
“DBA” stands for “Database Administrator.” A DBA is responsible for maintaining, configuring, securing, and ensuring the optimal performance of databases. They often handle backups, migrations, patches, upgrades, and troubleshooting any issues related to the database system.
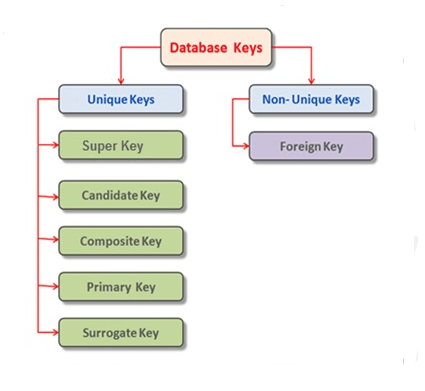
3. What are keys that used in database system ?
Ans:
Fundamental ideas in relational database systems include primary keys and foreign keys. They are essential in creating connections between tables and guaranteeing data integrity.
4. Explain about configuring of SQL server instances.
Ans:
5. How should SQL performs regular database backups and restores.
Ans:
Backups: Use the BACKUP DATABASE command to create full, differential, or log backups. Schedule regular backups using SQL Server Agent or maintenance plans.
Restores: Use the RESTORE DATABASE command to restore from a backup. Ensure you follow the correct sequence when restoring from full, differential, and log backups.
6.How will we monitor system health and performance?
Ans:
Performance Monitor (PerfMon): Use this built-in Windows tool to monitor system and SQL Server metrics.
Dynamic Management Views (DMVs): SQL Server provides DMVs to retrieve server state information to monitor health and performance.
SQL Server Profiler: Trace SQL Server events to identify performance bottlenecks.
7.How will we ensure data integrity and security?
Ans:
Constraints:Use primary keys, foreign keys, unique constraints, and check constraints to ensure data accuracy and consistency.
Encryption: Encrypt data at rest using Transparent Data Encryption (TDE) and in transit using SSL/TLS.
8. What is patches and upgrades.
Ans:
Patches: These are minor updates designed to fix known bugs or vulnerabilities. In the context of SQL Server, this is typically called a “Cumulative Update” or CU.
Upgrades: These involve transitioning from an older version of SQL Server to a newer one. This might introduce new features, improvements, and significant changes.
9. How will we apply patches and upgrades
Ans:
Download: Obtain the required patch from the official Microsoft website or trusted sources.
Maintenance Window: Schedule a time when the impact on users will be minimal.Patches can require downtime.
10.Explain about pre-patching and post-patching or upgrading steps.
Ans:
Pre-Patching/Upgrading Steps:
Backup: Always take a full backup of the databases and system configurations before applying any patches or upgrades.
Read Release Notes: Understand what changes the patch or upgrade brings. This can help in preparing for potential issues.
Post-Patching/Upgrading Steps:
Validate: Ensure all applications, jobs, and tasks are working as expected.
Document: Keep a record of the applied patch or upgrade, including date, time, any issues encountered, and resolutions.
11. What are the roles of rollback and maintenance in SQL server ?
Ans:
Rollback: In case of any critical issues, be prepared to rollback the patch or upgrade. This may involve restoring from backup.
Routine Maintenance: Regularly check for updates and patches to stay updated on any new vulnerabilities or issues. Microsoft releases patches regularly, and being proactive in applying them can prevent potential problems.
12. What is meant by trouble shooting issues?
Ans:
“Troubleshooting issues” refers to the process of diagnosing and fixing faults or malfunctions in a system or equipment. The objective is to discover the fundamental cause of the problem and then take efforts to remedy or minimise it. This word is often used in the IT, electronics, and engineering areas, but it may be applied to nearly any circumstance where a problem has to be addressed.
13.What are the trouble shooting issues in SQL server?
Ans:
Performance Issues: Slow queries, deadlocks, high CPU/memory usage.
Connectivity Issues: Can’t connect to SQL Server, authentication failures.
Database Corruption: Damaged data or log files.
Backup and Restore Failures: Incomplete backups, restore errors.
14. What are the other issues caused in SQL server?
Ans:
- Backup and Restore Issues
- Replication and Mirroring Issues
- Configuration Issues
- Migration Issues
- Integration Problems
- Version Compatibility
15.Define Designing process.
Ans:
The process of designing include creating a strategy or concept for the production of a product or system. Numerous sectors, including but not limited to graphic design, product design, architecture, and software design, may be affected by this. Design is usually done to address an issue, enhance functionality, or enhance aesthetics. Research, ideation, prototyping, testing, and refinement are frequently included in the process.
16. Explain the overview of SQL server design.
Ans:
Instance: Independent setups on a server.
Database Engine: Core for storing and processing data.
Relational Engine: Manages SQL queries.
Storage Engine: Handles database files and transactions.
Buffer Manager: Reduces disk I/O through caching.
Protocols: Enables client-server communication, e.g., TCP/IP.
Services: Includes SQL Server Agent, Reporting Services, etc.
17.Short note on Database maintenance .
Ans:
Database maintenance refers to the tasks and processes aimed at ensuring a database remains efficient, secure, and error-free. This includes:
Backup: Regularly saving copies to prevent data loss.
Update: Applying patches and upgrades to database software.
Optimization: Reorganizing data to enhance performance.
Integrity checks: Ensuring data is accurate and consistent.
18. How should we implement database maintenance ?
Ans:
Backups: Schedule regular full, differential, and log backups.
Indexing: Rebuild or reorganize fragmented indexes.
Statistics: Update database statistics for optimal query performance.
Integrity Checks: Run consistency checks to detect issues.
Cleanup: Purge old logs and unused files.
19. Explain about designing database maintainance.
Ans:
Assessment: Check for database fragmentation, unused indexes, old logs, and outdated statistics.
Backup Strategy: Before changes, establish a backup routine. Decide on frequency, type (full, differential, log), and storage spots.
Integrity Checks: Create checks for data consistency, including corrupted data and broken links
Index Maintenance: Regularly rebuild or reorganize fragmented indexes.
Update Statistics: Regularly refresh statistics for efficient query performance.
20. Define setup high availability.
Ans:
Redundancy: Multiple service instances for failover.
Load Balancing: Evenly distribute requests to prevent server overloads.
Clustering: Servers work together using shared resources.
Replication: Duplicate data in various locations for safety.
Heartbeat Monitoring: Continually check server health; trigger failover if needed.
21. Explain about setting up high availability.
Ans:
Assess: Identify critical services for HA.
Replication: -Use tools like MySQL, PostgreSQL’s Patroni, or GlusterFS.
Load Balancing: Employ HAProxy, Nginx, or AWS solutions.
Clustering: Use Kubernetes or Galera Cluster.
Failover: Implement Keepalived for auto-switching.
Monitoring: Set up tools like Prometheus with alerts.
Backups: Regularly backup and test restores.
22.How will you test and document in HA.
Ans:
Periodically test the failover processes to ensure they work as expected. Conduct “chaos engineering” experiments using tools like Netflix’s Chaos Monkey to simulate failures and test resilience.
Documentation: Document your HA setup, failover procedures, and how to handle different failure scenarios.
23. Explain about disaster recovery in SQL server..
Ans:
Backups: Full,differential and transaction log.
Always On: Database replicas for failover.
Mirroring: (Deprecated) Provides mirrored database.
Log Shipping: Automates backups to a standby server.
Failover Clustering: Swaps to a backup server node if needed.
24. What are the best practices in DA ?
Ans:
Regular Backups: Ensure regular backups of databases, logs, and systems.
Offsite Storage: Store backups in a different physical location or cloud to protect against local disasters.
Automate: Use tools and scripts to automate DR processes.
Documentation: Maintain detailed DR plans and documentation.
Access Control: Limit access to DR tools and backups to authorized personnel only.
25. Brief about SQL server DBA.
Ans:
A SQL Server DBA (Database Administrator) is responsible for the installation, configuration, maintenance, and optimization of Microsoft’s SQL Server databases. Their main duties include:
Installation and Configuration: Setting up new database servers and upgrading existing ones.
Backup and Recovery: Ensuring data integrity by regularly backing up databases and being able to restore them when needed.
Performance Tuning: Optimizing database performance by analyzing queries, creating indexes, and using tools like Profiler and Performance Monitor.
Security: Managing user permissions, roles, and ensuring that the database is protected from unauthorized access.
Migration and Upgradation: Moving databases to newer versions or different locations.
26. What are the core responsibility and area of expertise for SQL server DBA ?
Ans:
Installation & Configuration: Set up SQL Server; optimize settings and update regularly.
Backup & Recovery: Maintain backup strategies; ensure quick data restoration.
Performance Tuning: Monitor and optimize database performance and configuration.
Security: Set roles, permissions, and encryption; apply security updates.
Maintenance: Schedule tasks like consistency checks and index maintenance.
27. What is SQL Server?
Ans:
Microsoft created SQL Server, a relational database management system (RDBMS). It’s used to store, retrieve, and manage data in databases.
28. Differentiate between clustered and non-clustered indexes.
Ans:
| Aspect | Clustered Index | Non-Clustered Index | |
| Data Storage |
Alters data storage |
Stores pointers to data | |
| Common Usage | Often used on primary key | Can be on any column | |
| Retrieval Speed | quicker to retrieve | more slowly retrieved | |
| Insert/Update Speed |
Slower for inserts/updates |
Faster for inserts/updates |
29. What is normalization?
Ans:
Normalization is a systematic approach used in relational database design to ensure that data is organized most efficiently and to eliminate data redundancy and undesirable characteristics like insertion, update, and deletion anomalies. The main goal of normalization is to divide a database into well-structured tables that reduce data duplication and maintain data integrity.
30. What are the different types of normalization?
Ans:
The main normal forms are: 1NF, 2NF, 3NF, BCNF, 4NF, and 5NF. Each subsequent form has stricter requirements.
1NF: Atomic values; no repeating groups.
2NF: Gets rid of secondary key dependencies.
3NF: Eliminates transitive dependencies.
BCNF: Non-trivial dependencies are on superkeys.
4NF: Separates independent multi-valued facts.
5NF: Can reconstruct original table using joins.
31. What distinguishes DELETE and TRUNCATE from one other?
Ans:
DELETE:
- Removes rows one at a time.
- Can have conditions using WHERE.
- Activates triggers.
- Logs individual row deletions.
TRUNCATE:
- Removes all rows in a table quickly.
- Cannot use WHERE.
- Bypasses triggers.
- Less logging, just deallocates data pages.
32. Define a stored procedure.
Ans:
A precompiled group of one or more SQL statements that may be run as a single unit is known as a stored procedure. It can be invoked by applications or users and can accept input parameters and return results. Stored procedures provide a layer of security and can encapsulate logic, thereby promoting code reuse and consistency across applications.
33. What is a view?
Ans:
A view is a virtual table in a database that displays data from one or more tables using a SELECT statement. It doesn’t store data itself but provides a way to access data dynamically from the underlying tables as if it were a single table. Views can simplify complex queries, abstract underlying table structures, and provide a layer of security by limiting data exposure.
34. Describe a join and its types.
Ans:
If there are any configuration problems that prevent the server from starting, you can start an instance of Microsoft SQL Server by using the minimal configuration startup option. This is the startup option -f. Starting an instance of SQL Server with minimal configuration automatically puts the server in single-user mode.
35. Describe a join and its types.
Ans:
A join is a SQL operation that merges rows from two or more tables based on columns that are related.Types include:
FULL JOIN (also known as FULL OUTER JOIN): Returns rows in cases where one of the tables contains a match. Every row in the first table is combined with every row in the second table using a cross join.
SELF JOIN: Joins a table with itself.

Become a Database Administrator By Enrolling SQL Server DBA Certification Course
Weekday / Weekend BatchesSee Batch Details36. What distinguishes UNION and UNION ALL from one another?
Ans:
UNION: Combines the results of two or more SELECT operations into a single result set. The result is sorted by default.
UNION ALL: Combines the output of two or more SELECT operations into a single result set. Retains duplicate rows.
37. What is ACID in databases?
Ans:
The letters ACID stands for Atomicity, Consistency, Isolation, and Durability. It’s a set of properties that ensure reliable processing of database transactions.
Atomicity: A transaction can only be completed if all of its procedures are successful.
Consistency: Transactions changes the database permissible state.
Isolation: Transactions execute as if they are the only ones even when run concurrently.
Durability: Once a transaction commits, changes remain, even after system failures.
38. What is the purpose of the tempdb database?
Ans:
The tempdb database is a system database used to hold temporary tables, temporary stored procedures, table variables, and other intermediate results. It is recreated every time SQL Server is restarted, ensuring no permanent data is stored there.
39. How do you handle a corrupted database?
Ans:
Backup: Save the current corrupted state.
Diagnose: Use tools (e.g., DBCC CHECKDB for SQL Server) to identify corruption.
Assess Severity: Understand the corruption’s extent and affected areas.
Limit Activity: Minimize operations on the corrupted database.
Restore: Use a recent clean backup if available.
Use Repair Tools: Apply built-in or third-party repair utilities.
Manual Fixes: Correct minor issues by manually adjusting data or indexes.
40. What is database mirroring?
Ans:
Database mirroring is a SQL Server feature that provides high availability by maintaining two copies of a single database. One is the principal database, and the other is the mirrored database. When the principal fails, the mirrored database can be quickly made the new principal.
41. Differentiate between a full backup, differential backup, and log backup
Ans:
Full Backup: Backs up the entire database. Basis for differential and log backups.
Differential Backup: Changes since the last complete backup are backed up. Restoring requires the last full backup and the latest differential backup.
Log Backup: Backs up the transaction log, capturing all transactions since the last log backup. Allows point-in-time recovery. Restoring requires the last full backup followed by all subsequent log backups.
42. What is replication? Name the different types of replication in SQL Server.
Ans:
Replication is a feature in SQL Server used to distribute and synchronize data across multiple databases. The main types are Snapshot Replication, Transactional Replication, and Merge Replication.
43. How do you monitor SQL Server performance?
Ans:
Performance Monitor (PerfMon): Windows tool to track system and SQL Server metrics.
Dynamic Management Views (DMVs): SQL Server views that provide server state details, like query stats and execution plans.
SQL Server Profiler: Captures SQL Server events to identify bottlenecks.
SQL Server Management Studio (SSMS) Reports: Built-in reports for performance, server activity, and index usage.
Database Engine Tuning Advisor: Recommends indexes, stats, or partitioning.
Third-party Tools: Tools like SolarWinds, Redgate, or SentryOne provide advanced monitoring capabilities.
44. What is the purpose of the DBCC commands?
Ans:
DBCC stands for “Database Console Commands.” They are used for database maintenance tasks, such as checking database integrity, cleaning cache, and other administrative tasks
45. What are the common reasons for deadlocks, and how would you resolve them?
Ans:
Deadlocks often arise when two or more processes wait for each other to release resources. They can be prevented or resolved by optimizing and ordering database access, using appropriate indexing, reducing transaction duration, or using SQL Server’s deadlock detection and resolution features.
46. What is AlwaysOn Availability Groups?
Ans:
AlwaysOn Availability Groups are a high available and disaster recovery solution that was introduced in SQL Server 2012. It supports database replication over several servers, automatic failover, and read-only replicas for load balancing.
47. How do you upgrade SQL Server?
Ans:
SQL Server can be upgraded by running the SQL Server installation program and choosing the upgrade option. However, before upgrading, one should ensure compatibility, back up all databases, and check for deprecated features.
48. Differentiate between SQL and T-SQL.
Ans:
SQL: It is a standardized language used for querying and manipulating relational databases. Most RDBMSs, including SQL Server, Oracle, MySQL, and PostgreSQL, support SQL with their specific extensions.
T-SQL: It is Microsoft’s proprietary extension of SQL for its SQL Server RDBMS. T-SQL encompasses all of the SQL standard commands and adds procedural programming and local variable support, among other features.
49. What is primary key in database ?
Ans:
Uniqueness: The primary key values must be unique for each row. You cannot have duplicate values in this column or set of columns.
Null Values: Primary key columns cannot have NULL values.
Purpose: It ensures row-level uniqueness and provides a way to identify each record in a table uniquely.
Number in a Table: There can be only one primary key in a table, although the primary key can consist of multiple columns (known as a composite key).
50. What is installing of SQL server ?
Ans:
Installing SQL Server refers to the process of setting up Microsoft’s relational database management system (RDBMS) on a computer or server. This involves:
- Downloading the appropriate SQL Server installation package.
- Running the installation wizard.
- Choosing components to install (e.g., Database Engine, Reporting Services).
- Configuring instance, security, and connectivity settings.
- Completing the installation steps.

Enhance Your Career with SQL Server DBA Training from Certified Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
51. What is foreign key in database system ?
Ans:
foreign key is a column in one table that connects to the main key in another table.
Referential Integrity: The main key’s values must match those of the foreign key, or the foreign key’s values must be NULL.
Purpose: Enables table relationships for joins and data consistency.
Cascade Actions: Defines actions like CASCADE DELETE or UPDATE based on changes in the referenced table’s primary key.
52. What is join and union in SQL?.
Ans:
Both JOIN and UNION are SQL operations used to combine rows from two or more tables, but they do so in different ways and serve distinct purposes.
53. What is join in SQL?.
Ans:
Purpose: Used to merge rows from two or more tables depending on a common column.
Output: Returns columns from both tables, effectively widening the result set
Relationships: JOIN operations are typically used to retrieve data from tables that have some form of relationship, often established through primary and foreign keys.
54. What are the causes of Joins ?
Ans:
Normalization: Combines data split across tables.
Related Data Retrieval: Fetches data spanning multiple tables.
Avoid Cartesian Products: Ensures meaningful row combinations.
Query Flexibility: Allows diverse reports from multiple tables.
Performance: Fetches only relevant data, optimizing speed.
Data Aggregation: Summarizes data across tables.
Data Integrity: Maintains relationships between tables.
55.Describe Union in SQL ?
Ans:
Purpose: Used to combine the result sets of two or more SELECT statements.
Output: Returns rows by stacking one result set on top of the other, effectively increasing the number of rows in the result set.
Conditions: There are a few conditions that must be met for a UNION to work. The number of columns in every SELECT statement inside the UNION must be the same, Similar data types must also be present in the columns.
56. Brief note about normalisation.
Ans:
Normalization is a systematic process of organizing data in a relational database to minimize redundancy and prevent undesirable characteristics like insertion, update, and deletion anomalies. The main goal is to ensure that data is stored logically and in its most coherent form.
57. What are the importance of Normalisation ?
Ans:
Minimize Redundancy: Eliminates repetitive data for better performance and storage.
Data Integrity: Maintains consistent and accurate data.
Efficient Queries: Faster performance due to reduced data.
Flexibility: Adapts to changes and extensions more easily.
Eliminate Anomalies: Prevents unexpected side-effects of operations.
Logical Organization: Reflects clear, intuitive data structure.
58. What are the causes of Normalisation?
Ans:
The cause or motivation behind normalization is to design efficient, reliable, and non-redundant databases. Here are the primary reasons or “causes” that lead to the development and application of normalization:
Avoid Redundancy: Without normalization, the same information can be duplicated in multiple places, leading to waste of storage and potential inconsistencies.
Maintain Data Integrity: By ensuring data is stored in a consistent and organized manner, normalization helps maintain the accuracy and reliability of the data.
59. Explain the other causes of Normalisation.
Ans:
Simplified Queries: Easier data location in structured tables.
Logical Structure: Clear, relationship-based data organization.
Flexibility: Adapts better to evolving requirements.
Efficient Storage: Reduces redundancy, conserving storage resources.
60. What is Eliminate anomalis and explain its types.
Ans:
Anomalies are unintended side-effects of database operations, like insertions, updates, and deletions. Normalization aims to eliminate these to ensure smooth database operations.
Insertion Anomalies: When you cannot insert specific information until some other information is present.
Deletion Anomalies: When deleting a piece of data inadvertently deletes other valuable data.
Update Anomalies: When a piece of data needs to be updated in multiple places.
61. What is ACID property?
Ans:
The ACID properties—Atomicity, Consistency, Isolation, and Durability—are fundamental principles that ensure reliable processing of transactions in relational database management systems, including SQL Server.
62. Describe about atomicity in SQL server.
Ans:
This ensures that a transaction is treated as a single, indivisible unit. It means that either all the operations within the transaction are executed, or none . SQL Server utilizes mechanisms like the transaction log to manage this rollback or commit process.
63. What is consistency in SQL server?
Ans:
This ensures that the database always transitions from one valid state to another valid state.
64. What is Isolation?
Ans:
This ensures that transactions are isolated from one another, meaning the operations of one transaction are not visible to other transactions until they are completed.SQL Server achieves isolation through locking, row versioning, and other concurrency control mechanisms. The system offers different transaction isolation levels (like READ COMMITTED, READ UNCOMMITTED, SERIALIZABLE, etc.) that allow for a balance between performance and strict isolation based on the needs of the application
65. What is Durability?
Ans:
Durability is primarily achieved through the transaction log. When a transaction is committed, its operations are logged. In case of a system failure, SQL Server can use the transaction log during the recovery process to ensure that all committed transactions are persisted and any incomplete transactions are rolled back.
66. Describe about Clustered index.
Ans:
Physical Storage: Data in a table are physically stored in the order specified by a clustered index. In essence, the table’s data rows are saved on the hard drive in the same order as the clustered index key.
Uniqueness: Only one clustered index may be present for each table. If a primary key is supplied for a table but no clustered index is present, SQL Server will create one for you.
Row Locator: Since the clustered index defines the physical storage order of the rows, the index itself is the row locator.
Usage: It’s typically used on columns where the data is accessed sequentially or range queries are frequent, like primary key columns.
67. Describe about non-Clustered index.
Ans:
Physical Storage: Uses a separate structure, typically a B-tree, without altering data’s physical order.
Uniqueness: Multiple can exist on one table.
Row Locator: Points to clustered index key or, in its absence, to the data row.
Usage: Ideal for searched columns, JOIN operations, and sorting/grouping columns.
68. Difference between Clustered and non-Clustered index.
Ans:
The physical arrangement of the data in a table is determined by a clustered index. Each table may only have one clustered index. In contrast, a non-clustered index has a distinct structure that points to the data rows rather than changing the order of the data. There can be more than one non-clustered index in a table.
69. What is Database designing?
Ans:
Database design refers to the process of building a complex model of a database. This model includes all the logical, physical, and physical storage design decisions required to produce a design in a data definition language, which may subsequently be used to establish a database.
70. What are the kind of indexes are in SQL server ?
Ans:
Clustered Indexes: Ensure that tables have an appropriate clustered index, usually on a column with sequentially increasing values to prevent frequent page splits.
Non-clustered Indexes: Create non-clustered indexes on frequently queried or joined columns. However, avoid over-indexing, as it can slow down insert and update operations.
Filtered Indexes: If only a subset of data is frequently queried, consider using filtered indexes.
Columnstore Indexes: For large data warehousing scenarios, columnstore indexes can provide significant performance benefits for aggregate queries.
71. What is meant by Archiving and Purging ?
Ans:
Implement archiving strategies to move older data to archival tables or other storage solutions. Regularly purge data that’s no longer needed.
72. How would you handle large amount of data in SQL server ?
Ans:
Handling large amounts of data in SQL Server requires a combination of architectural decisions, database design strategies, performance optimization techniques, regular maintenance,scaling strategies, monitoring and performance tuning, external storage solutions and etc.
73. Elaborate the performance optimization techniques.
Ans:
Monitoring Tools: Use tools like SQL Server Profiler, Performance Monitor, and Execution Plans to monitor performance and identify bottlenecks.
Optimize Queries: Regularly review and optimize slow-running queries.
Locking and Concurrency: Optimize transaction isolation levels and understand the locking behaviour of your application to reduce contention.
Backup and Restore Strategy: Optimize backup strategies to handle large data volumes. Consider using differential backups, filegroup backups, and backup compression.
74. Explain the essential steps for database designing.
Ans:
Requirement Analysis: Define information storage needs and database purpose.
ERD: Visualize database structure and relationships.
Data Types: Choose appropriate types for each field.
Normalization: Reduce redundancy and enhance data integrity.
Physical Design: Set indexing, partitioning, and clustering.
Security: Define user access levels and permissions.
Testing & Iteration: Ensure performance and functionality; refine as needed.
75. Which kinds of SQL server backups are there?
Ans:
- Full Backup
- Differential backup
- Transaction log backup
- File/Filegroup backup
- Partial backup
- Copy-Only backup
- Snapshot backup
76. Explain about Full backup in SQL server.
Ans:
Captures the entire database. It includes all the data in the database, plus enough of the transaction log to recover the database. Acts as a standalone restoration point and doesn’t require any other backup types to restore.
77. Short note on Differential backup.
Ans:
Captures changes made since the last full backup. Requires a full backup as a base, and you’ll restore the full backup first, followed by the most recent differential backup.
78. What is transaction log backup?
Ans:
Captures the transaction log since the last log backup. Used to restore a database to a specific point in time or to the point of failure. Requires a full backup as a starting point, followed by all subsequent transaction log backups in sequence.
79. What is File/Filegroup Backup ?
Ans:
Captures specific files or filegroups within a database. Useful for very large databases where backup/restore of the entire database isn’t practical.To restore, you’ll typically need a full backup and any differential and/or transaction log backups.
80. What is partial and copy – only backups ?
Ans:
Partial Backup: Captures only a part of the database, specifically the primary filegroup, and any other filegroups specified.Useful when certain portions of a database change less frequently and don’t need regular backups.
Copy-Only Backup: A special type of backup that doesn’t interfere with the regular sequence of standard backups.Useful for scenarios like taking a backup for development or testing without affecting the regular backup chain.
81. Short note on snapshot backup.
Ans:
Not a traditional backup, but a database snapshot creates a static, read-only view of a database at a point in time. Instantaneous, but relies on the source database for its data pages, making it less robust than other backup types.
82. What are stored procedures ?
Ans:
Stored procedures are precompiled collections of one or more SQL statements that are stored under a name and processed as a unit in the database. They can accept parameters, and they can return results.
83. How are stored procedures beneficial ?
Ans:
Performance: Cached plans speed up execution.
Modularity: Centralizes and reuses SQL code.
Security: Restricts data access and prevents SQL injection.
Maintainability: Centralized updates and easier troubleshooting.
Data Integrity: Enforces rules and ensures transaction consistency.
Parameter Handling: Offers dynamic operations.
Network Efficiency: Reduces traffic with concise calls.
Advanced Features: Utilizes RDBMS-specific tools.
84. How the SQL server implements transaction.
Ans:
SQL Server uses a combination of the logging mechanism, lock manager, and versioning to implement transactions.
Logging: Uses Write-Ahead Logging (WAL) for data changes and supports commit or rollback.
Lock Manager: Allocates locks for data consistency and isolation.
Versioning: Provides consistent data views through row versioning for certain isolation levels.
ACID Principles: Ensures transactions are Atomic, Consistent, Isolated, and Durable.
85. Brief note about SQL server transaction.
Ans:
Write-Ahead Logging (WAL): Records changes in the transaction log before updating the database.
Commit & Rollback: Uses logs to finalize or undo changes.
Lock Manager: Ensures transactional consistency and isolation.
Versioning: Uses row versioning for features like Snapshot Isolation.
86. How can you optimize a slow-running query in SQL Server?
Ans:
Analyze Query: Use SQL Server Profiler or SET STATISTICS for execution insights.
Execution Plan: Identify expensive operations like table scans.
Indexes: Check for suggested indexes. Avoid excessive indexes. Maintain by rebuilding or reorganizing.
Optimize Joins: Join on indexed or primary key columns. Filter early and consider join order.
87. How to avoid this slow running query in SQL server?
Ans:
Avoid Functions in WHERE: Can hinder index usage.
Reduce Data: Select only necessary columns and limit returned data.
Parameterized Queries: Enhances execution plan reuse.
Avoid Cursors: Prefer set-based operations.
Optimize TempDB: Use fast storage and multiple files.
Check Server Health: Monitor CPU, memory, and disk I/O.
88. Define Deadlock.
Ans:
In the realm of computer science, a deadlock refers to a specific situation where two or more processes are unable to proceed with their execution because each one is waiting for the other(s) to release a resource they need. When two transactions in a database are waiting for resources that the other has, a deadlock could happen, preventing either transaction from moving further.
89. How to handle SQL server Deadlocks ?
Ans:
Detection: Constantly monitors for potential deadlocks.
Choosing a Victim: If detected, one transaction is selected as a “victim” and rolled back to break the deadlock.
Notifications: Rolled-back transaction receives an error message about the deadlock.
Prevention: Best practices, like consistent resource access and minimizing lock duration, help reduce deadlock occurrences.
90. What is Transaction isolated level ?
Ans:
Transaction isolation levels determine how transactions are isolated from one another in a database system. They help in controlling the visibility of uncommitted changes made by a transaction to other transactions. The primary goals are to ensure data integrity and to decide how to handle contention between simultaneous transactions.
91. How many types of standard transaction levels are there and explain it .
Ans:
Read Uncommitted: Reads uncommitted changes.
Side Effects: Dirty reads, non-repeatable reads, phantom reads.
Read Committed: Reads only committed changes.
Side Effects: Non-repeatable reads, phantom reads.
Repeatable Read: Consistent reads during a transaction.
Side Effects: Phantom reads.
Serializable: Ensures transactions execute as if serially.
92. What are the side effects of transaction isolation level ?
Ans:
Dirty Read: A transaction reads information that was written by another transaction that has not yet been committed. Later, the information could be reversed.
Non-Repeatable Read: A transaction reads a row, another transaction modifies or deletes the row, and the first transaction reads the row again and gets a different value.
Phantom Read: A transaction reads a set of rows, another transaction inserts or deletes some rows, and the first transaction reads the set of rows again and finds additional or missing rows.
93. What is the difference between READ COMMITTED and READ UNCOMMITTED transaction isolation levels?
Ans:
The READ COMMITTED and READ UNCOMMITTED transaction isolation levels are two of the four standard isolation levels defined in the SQL standard. Here are the primary differences:
Dirty Reads: READ UNCOMMITTED: Allows reading of uncommitted changes, which may later be rolled back. READ COMMITTED: Reads only committed changes, preventing dirty reads.
Consistency: READ UNCOMMITTED: Least consistent; may yield unexpected results due to dirty reads.
READ COMMITTED: More consistent but can encounter non-repeatable or phantom reads.
Performance: READ UNCOMMITTED: Faster, minimal lock overhead.
READ COMMITTED: Might wait for transactions to commit, causing some overhead.
94. Define ALWAYSON AVAILABILITY.
Ans:
AlwaysOn Availability Groups is a Microsoft SQL Server feature that enables high availability and disaster recovery for database applications. It was initially introduced in SQL Server 2012 and has since evolved.
95. Explain the overview of alwayson availability.
Ans:
Replicas: One primary (read-write) and up to eight secondary (copies) databases.
Synchronous:Data protection, slower.
Asynchronous:Faster, potential data loss.
Failover: Switches roles between primary and secondary; can be manual or automatic.
Read-Only Routing: Balances read workloads across replicas.
Backup: Performed on secondary replicas to offload primary.
96. What is SQL server memory management?
Ans:
SQL Server’s memory management is quite sophisticated and designed to allow the database to perform efficiently under different workloads and hardware configurations.
97. How does SQL manages memory ?
Ans:
Dynamic Memory Management Buffer Pool Min/Max Server Memory Memory Pressure Memory Clerks and Caches Large Pages Lock Pages in Memory Direct Query Memory Grants Memory-Optimized Tables External Memory Pressure Detection
98. Explain Dynamic memory management.
Ans:
SQL Server adjusts its memory usage dynamically based on the workload and the amount of available system memory. When there’s a lot of memory available and SQL Server needs it, the database engine will consume more. When other processes need memory or when SQL Server’s memory demand decreases, it will release some.
99. Define bufferpool.
Ans:
This is the primary memory store for SQL Server. The buffer pool is used to store data pages, plan caches, and other necessary structures. Data that’s frequently accessed is kept in the buffer pool to avoid expensive disk reads.
100. How to identify External memory pressure detection.
Ans:
SQL Server can detect when the system is under memory pressure not just from its own operations but also from other processes running on the same system.




