
Last updated on 13th Jun 2024| 4748
Transact-SQL, or T-SQL, is an extension of SQL that is mostly utilized with Sybase ASE and Microsoft SQL Server. It enhances traditional SQL with procedural programming features like variables, loops, and conditional expressions to enable more sophisticated and effective data processing and querying. Writing and optimizing queries, building stored procedures and triggers, and overseeing transactions in relational databases are all tasks that require knowledge of T-SQL.
1. What is T-SQL, and how does it differ from SQL?
Ans:
T-SQL, or Transact-SQL, is Microsoft’s SQL (Structured Query Language) implementation built expressly for use with Microsoft SQL Server. It provides capabilities that go beyond the ANSI SQL standard, including procedural programming structures, error handling, and transaction management. Additionally, T-SQL allows for the creation of user-defined functions and stored procedures, enhancing code reusability and modularity.
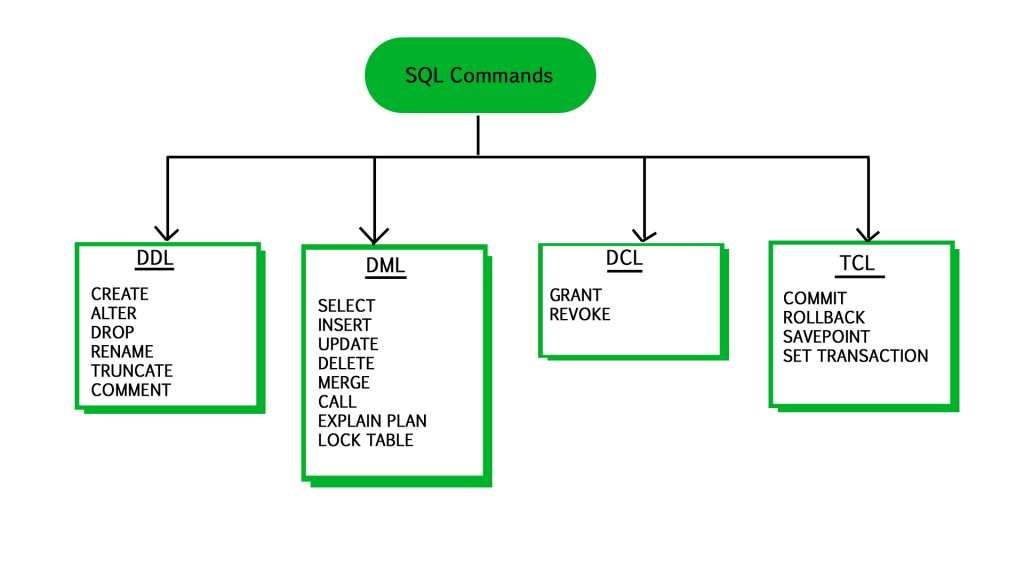
2. What is the distinction between DDL, DML, and DCL commands in T-SQL?
Ans:
DDL (Data Definition Language) instructions are used to create a database’s structure, which includes creating, altering, and removing database objects, including tables, indexes, and views. Data Manipulation Language (DML) instructions are used to access, modify, remove, and add data from database objects. DCL (Data Control Language) instructions are used to manage access to database objects, such as giving and eliminating rights.
3. Explain the role of the SELECT statement in T-SQL.
Ans:
- T-SQL’s SELECT command is fundamental in retrieving data from one or more database tables within Microsoft SQL Server.
- It offers extensive capabilities to tailor query results to specific requirements.
- Beyond simply fetching data, SELECT allows specifying which columns to retrieve, enabling efficient data extraction.
4. Describe the various data types supported in T-SQL.
Ans:
- T-SQL can handle various data types, including numeric, text, date and time, binary, and special-purpose data formats like XML and spatial.
- The numeric data types include INT, BIGINT, DECIMAL, and FLOAT.
- The string data types include CHAR, VARCHAR, and NVARCHAR.
- The date and time data types are DATE, DATETIME, and TIMESTAMP.
5. What are the differences and similarities between CHAR and VARCHAR data types?
Ans:
| Feature | CHAR | VARCHAR |
|---|---|---|
| Type | Fixed-length | Variable-length |
| Storage | Always allocates storage for specified length, pads with spaces if necessary | Allocates storage based on actual data length |
| Storage Size | Fixed (length specified in bytes) | Variable (length of data + 1 or 2 bytes for length information) |
| Performance | Generally faster for retrieval and comparison operations | May require slightly more processing time for retrieval due to variable length |
6. How are NULL values handled in T-SQL?
Ans:
NULL values in T-SQL serve to indicate missing or unknown data within a database. They are distinct from empty strings or zeros and require specific handling to manage effectively. In SQL queries, the presence of NULL values can impact result sets and calculations. T-SQL provides several operators and functions to manage NULL values. The IS NULL and IS NOT NULL operators are used to check explicitly for NULL values in expressions, enabling conditional logic based on the presence or absence of NULLs.
7. Explain the purpose of the WHERE clause.
Ans:
In T-SQL, the WHERE clause is used to filter the results returned by a SELECT operation based on specific criteria. It enables the specification of conditions that must be satisfied for a row to be included in the result set, such as comparisons with column values, logical operators, and expressions. Additionally, the WHERE clause can be combined with other clauses, like GROUP BY and ORDER BY, to further refine the results. Its flexibility allows for complex queries that can target precise subsets of data, enhancing data retrieval efficiency.
8. What is the significance of the ORDER BY clause?
Ans:
- The ORDER BY clause in T-SQL sorts the result set returned by a SELECT operation.
- It lets you choose the columns to sort by and the sort order (ascending or descending).
- The ORDER BY clause is commonly used in combination with the SELECT statement to customize the display of query results.
9. Discuss the functionality of the GROUP BY clause.
Ans:
- In T-SQL, the ORDER BY clause is essential for sorting the results of a SELECT query in either ascending or descending order based on specified columns.
- It arranges rows after retrieval, not for summarization or grouping.
- Conversely, the GROUP BY clause organizes rows into summary groups, enabling the application of aggregate functions (like SUM, AVG, COUNT, MIN, and MAX) to calculate values for each group rather than individual rows.
10. How can duplicate records be managed in T-SQL?
Ans:
Duplicate records may be handled with the DISTINCT keyword, which removes duplicate rows from the result set of a SELECT operation. Alternatively, duplicate entries can be identified and eliminated by using the ROW_NUMBER() method with a common table expression (CTE) or a derived table. This approach allows for more control over which duplicates to keep or remove by assigning a unique sequential integer to each row within a partition of the dataset.
11. Describe the different types of joins available in T-SQL.
Ans:
- Only the rows in both tables with matching values are chosen using an inner join.
- All rows from the left table and any matching rows from the right table are retrieved using a left-join.
- Fetches every row from the right table and any matching rows from the left table using a right join.
- When there is no match, FULL JOIN retrieves all rows from both tables, including NULL values.
12. What distinguishes INNER JOIN from OUTER JOIN?
Ans:
- Differentiating between an INNER and an OUTER JOIN: An INNER JOIN yields rows where the values in the two tables match. All rows from one or both tables are returned by an outer join, with NULL values for any rows that do not match.
- Additionally, OUTER JOINs can be further classified into LEFT, RIGHT, and FULL OUTER JOINs, each defining which table’s rows are prioritized in the result set while including unmatched rows from the other table. This flexibility allows for comprehensive data retrieval from related tables, even when some relationships do not exist.
13. How is a self-join performed in T-SQL?
Ans:
In T-SQL, a self-join is performed by joining a table to itself. This is achieved by aliasing the table with different names in the query and specifying the join condition that relates the rows within the same table. Typically, a self-join involves using the same table in both the FROM and JOIN clauses, often with additional predicates in the ON clause, to establish the relationship between the rows being joined.
14. Explain the use of subqueries.
Ans:
Subqueries in SQL are SELECT statements nested within other SQL statements like SELECT, INSERT, UPDATE, or DELETE. They enable complex queries by using one query’s result as input for another. Subqueries filter data, compute aggregates, or compare results from different queries, enhancing SQL’s capability for data manipulation and retrieval in databases.
15. Differentiate between correlated and non-correlated subqueries.
Ans:
- In SQL, a correlated subquery references columns from the outer query, executing once for each row processed.
- In contrast, a non-correlated subquery executes independently of the outer query, returning a result set that the outer query evaluates.
- Correlated subqueries typically involve correlated conditions with the outer query, while non-correlated subqueries can be precomputed and often provide faster performance for complex queries.
16. How can sub-queries be optimized for performance?
Ans:
- Ensuring the subquery returns a minimal dataset.
- Using appropriate indexing on columns involved in the subquery.
- Rewriting the subquery as a join where feasible.
- Limiting the use of correlated subqueries.
- Testing and comparing different query structures for efficiency.
17. Describe the EXISTS and NOT EXISTS operators.
Ans:
The EXISTS operator in SQL checks for the existence of rows returned by an auxiliary query. If the subquery yields at least one row, it returns true; otherwise, it returns false. For example, `SELECT * FROM Orders o WHERE EXISTS (SELECT 1 FROM Customers c WHERE c.CustomerID = o.CustomerID)`. Conversely, the NOT EXISTS operator returns true if the subquery returns no rows; otherwise, it returns false. For example, `SELECT * FROM Customers c WHERE NOT EXISTS (SELECT 1 FROM Orders o WHERE o.CustomerID = c.CustomerID)`.
18. What is the purpose of the APPLY operator?
Ans:
The APPLY operator in SQL invokes a table-valued function. Each row returned by an outer table expression corresponds to a table-valued function. This operator allows for correlated and cross-applied queries, where the function’s results are joined or correlated with the outer query’s columns. This operator is handy for scenarios requiring complex joins or when performing calculations that depend on values from multiple tables or rows.
19. How does the COALESCE function function in T-SQL?
Ans:
- In T-SQL, the COALESCE function evaluates multiple expressions and returns the first non-null value it encounters.
- It helps manage null values by providing a fallback option if all evaluated expressions are null, streamlining data handling in SQL queries.
- Additionally, COALESCE can be particularly useful in generating meaningful output for reports and dashboards, ensuring that users see valid data instead of null values, which can enhance data readability and interpretation.
- This function is versatile and can be used in various contexts, such as calculations and conditional expressions, to improve query performance and clarity.
20. Discuss the utility of common table expressions (CTEs).
Ans:
- Temporary result sets, or CTEs, are used as references in SELECT, INSERT, UPDATE, and DELETE queries.
- They make complex searches more manageable and readable by segmenting them into smaller ones.
- Additionally, CTEs can be recursive, allowing for the traversal of hierarchical data structures, which is particularly useful for working with organizational charts or nested categories. This recursive capability enhances the flexibility and power of queries, enabling sophisticated data retrieval without cluttering the main query logic.
21. What are aggregate functions, and how are they utilized?
Ans:
Aggregate functions in SQL operate on sets of rows to return a single value that summarizes the data (e.g., SUM, AVG, COUNT). They are used with the SELECT statement and can include DISTINCT to apply the function to unique values. Aggregate functions are crucial for generating summaries, such as calculating totals, averages, or counting occurrences within a dataset, providing valuable insights into the data’s overall characteristics without needing to examine each row individually.
22. Explain the role of the COUNT function.
Ans:
- The COUNT function’s role is to count the rows in a result set that satisfies particular requirements.
- COUNT(*) counts all rows, and COUNT(column_name) counts non-NULL values in the specified column. It can be used with or without a column specified.
- Additionally, COUNT can be combined with GROUP BY to provide aggregated counts for each group, allowing for detailed analysis of data distributions across different categories. This makes it a valuable tool for generating reports and insights from data sets, enhancing decision-making processes.
23. How is the SUM function used?
Ans:
The SUM function in SQL computes the total sum of values from a designated column or expression within a SELECT query. It aggregates numerical data to yield a consolidated result. When coupled with GROUP BY, it facilitates the calculation of sums for distinct groups of rows, enabling efficient data summarization based on specified categories. Furthermore, it integrates seamlessly with other aggregate functions such as AVG, COUNT, and MAX, enhancing its utility in comprehensive data analysis and reporting scenarios.
24. Differentiate between COUNT(*) and COUNT(column_name).
Ans:
COUNT(*) and COUNT(column_name) are separated by:
- COUNT(*), which ignores NULL values, counts every row in a result set.
- COUNT(column_name) counts how many values in the specified column are not NULL.
25. Discuss the purpose of the AVG function.
Ans:
The AVG function in SQL determines a numeric column’s average value in a database table. It computes the sum of all values in the specified column and divides it by the total number of rows. This function is handy for obtaining statistical insights, such as determining the average salary, average age, or average sales amount across a dataset. It simplifies the process of obtaining aggregate data and facilitates analysis by providing a single metric representing the central tendency of numerical data.
26. How are NULL values handled with aggregate functions?
Ans:
NULL values in aggregate functions are typically ignored during computation. Functions that aggregate data, such as SUM(), AVG(), COUNT(), etc., exclude rows containing NULL values from their calculations. This behavior ensures that the results reflect meaningful computations based only on non-NULL values within the dataset. Handling NULL values in this manner helps maintain the accuracy and relevance of aggregate function results in SQL queries.
27. Describe the functionality of the GROUP BY clause.
Ans:
The GROUP BY clause in SQL aggregates data based on specified columns. Rows with the same values are grouped to create summary rows, and this is typically used with aggregate functions like SUM, COUNT, AVG, etc. This clause divides the result set into groups, where each group represents a unique combination of values from the specified columns. It is essential for performing operations that require data summarization or analysis across distinct categories or criteria within a dataset.
28. How is the HAVING clause applied alongside GROUP BY?
Ans:
- Use of the HAVING Clause with GROUP BY: Following grouping operations, the HAVING clause filters groups according to predetermined conditions.
- While it works with pooled data instead of individual rows, it acts similarly to the WHERE clause.
- Additionally, the HAVING clause is essential for scenarios where aggregate functions, such as SUM or AVG, need to be applied to the grouped data, allowing for more refined insights and analyses.
- This enables the identification of groups that meet specific criteria based on their aggregated values, further enhancing data analysis capabilities.
29. Explain the concept of window functions.
Ans:
Window functions in SQL allow the computation of values across a set of rows related to the current row without grouping the rows into a single output row. They operate within the context of a “window” of rows defined by a partition and an optional ordering of rows. Window functions enable advanced analytical queries by performing calculations such as ranking, cumulative sums, averages, and more without the need for self-joins or subqueries.
30. What benefits do window functions offer compared to traditional aggregates?
Ans:
Window functions offer benefits over traditional aggregates by allowing computations across a set of rows related to the current row without grouping or reducing the result set. They provide flexibility in calculations, such as ranking, cumulative sums, and moving averages, while retaining individual row details. This capability enhances analytical queries by enabling complex aggregations and comparisons within the dataset without the need for self-joins or subqueries, thus improving query clarity and performance.
31. Define stored procedures and outline their advantages.
Ans:
- Stored procedures are precompiled SQL statements stored in a database.
- They offer advantages such as improved performance by reducing network traffic, enhanced security through controlled data access, simplified maintenance with centralized logic, and increased productivity by promoting code reuse across applications.
- Additionally, they facilitate better scalability and provide a layer of abstraction for database operations.
32. How is a stored procedure created in T-SQL?
Ans:
To create a stored procedure in T-SQL:
- Use the `CREATE PROCEDURE` statement followed by the procedure name and parameters.
- Inside the method, write SQL statements to perform desired operations.
- Optionally, include input and output parameters for flexibility.
- Use `BEGIN` and `END` to enclose the procedure body, ensuring proper scope and execution flow.
33. What methods are available for parameter passing in stored procedures?
Ans:
In stored procedures, parameters can be passed using different methods: positional parameters, named parameters (where supported), default parameters (with predefined values), output parameters (for returning values), and table-valued parameters (for passing multiple rows of data as a single parameter). These methods allow procedures to receive input, return values, and interact effectively with databases and applications.
34. What is the significance of the OUTPUT parameter?
Ans:
In SQL, the OUTPUT parameter is significant as it allows capturing and returning data modified by Data Manipulation Language (DML) statements like INSERT, UPDATE, and DELETE. It provides a way to retrieve affected rows, such as newly inserted IDs or updated columns, facilitating auditing, logging, or subsequent processing. This parameter enhances transactional Control by enabling developers to handle data changes more effectively within the scope of a single operation, ensuring data integrity and traceability.
35. What distinguishes scalar functions from table-valued functions?
Ans:
- Table-Valued Functions vs Scalar Functions Differentiation: A single value, such as a string or numeric value, is returned by scalar functions.
- As a result, table-valued functions return a table that can be used in queries just like any other table.
- Additionally, table-valued functions are particularly useful for encapsulating complex queries and can simplify code by allowing the reuse of logic in multiple locations, enhancing maintainability.
- They also allow for the passing of parameters, enabling dynamic results based on input values, making them more versatile for various data manipulation tasks.
36. Describe the process of creating a user-defined function (UDF).
Ans:
- Define Function: Specify the function name, parameters, and return type using the CREATE FUNCTION statement.
- Body Implementation: Write the logic or computations the function will perform inside the function body.
- Parameterization: Assign input parameters and define their data types, which determine how the function interacts with external queries.
- Testing and Validation: Validate the function’s behavior with sample data and ensure it produces the expected results.
37. What are the benefits and limitations of UDFs (User-Defined Functions)?
Ans:
- Modularity: Encapsulate complex logic into reusable functions, promoting code organization and maintainability.
- Code Reusability: Reduce redundancy by allowing functions to be called multiple times across queries or procedures.
- Performance: Improve query performance by pushing computations closer to the data, leveraging SQL engine optimizations.
- Abstraction: Abstract complex operations behind a simple interface, enhancing readability and understanding of queries.
38. Differentiate between deterministic and non-deterministic functions.
Ans:
Deterministic functions always produce the same result when given the same input parameters, ensuring predictability and consistency in their outputs. They do not rely on external factors or hidden states during execution. Non-deterministic functions, on the other hand, can yield different results for the same input parameters due to factors like random number generation, current time, or data changes external to the function. External conditions influence their output and can vary across different executions.
39. Explain the usage of the EXECUTE AS clause.
Ans:
The EXECUTE AS clause in SQL Server executes a module (such as a function, stored procedure, or trigger) under a security context different from the caller’s. It allows specifying a specific user or login account whose permissions will be used during execution, overriding the caller’s default security context. This feature is valuable for managing permissions and ensuring that sensitive operations are performed with appropriate access rights, enhancing security and Control over database operations.
40. How are errors managed within stored procedures?
Ans:
- Error Handling Within Stored Procedures: TRY…CATCH blocks can be used to handle exceptions when handling errors within stored procedures.
- Use system procedures such as ERROR_MESSAGE(), ERROR_NUMBER(), and so on to retrieve error data.
- Additionally, it’s beneficial to include logging mechanisms within the CATCH block to record error details for further analysis, helping to identify recurring issues and improve overall system reliability.

Get JOB T-SQL Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. Define a transaction and its properties.
Ans:
A series of actions handled as a single unit that guarantees complete completion or complete rollback are referred to as transactions. This type of system has the characteristics of atomicity, which ensures that all operations are carried out; consistency, which maintains a state of consistency; isolation, which keeps transactions apart from one another; and durability, which makes committed changes permanent.
42. Discuss the functionalities of BEGIN TRANSACTION and COMMIT TRANSACTION.
Ans:
A transaction starts with the phrase “BEGIN TRANSACTION,” allowing multiple SQL statements to be grouped together. If no errors occur, COMMIT TRANSACTION permanently saves all changes made by the transaction to the database, ensuring data consistency. If any errors arise during the transaction, a ROLLBACK TRANSACTION can be executed to undo all changes made since the transaction began, preserving the integrity of the database.
43. How are exceptions handled and transactions rolled back?
Ans:
- Exception Handling and Transaction Rollback: Using TRY CATCH blocks, exceptions are managed to detect and handle errors that arise throughout the transaction.
- Any modifications made during a transaction can be undone by rolling back the transaction using the ROLLBACK statement found in the CATCH block.
44. Describe the isolation levels for transactions.
Ans:
- Transaction Isolation Levels: The degree to which transactions are isolated from one another affects concurrency and data consistency. Isolation levels define this.
- A few typical levels include SERIALIZABLE, REPEATABLE READ, READ COMMITTED, and READ UNCOMMITTED.
- Each isolation level offers a different balance between data consistency and performance, with higher levels generally providing greater consistency but potentially reducing concurrency.
- Understanding these levels is crucial for database design, as choosing the appropriate isolation level can significantly impact the behavior of applications and the accuracy of data retrieval in multi-user environments.
45. What constitutes a deadlock, and how can it be avoided?
Ans:
Transactions may become deadlocked when they wait for each other’s locks. Prevention strategies include reducing transaction time, designing transactions effectively, and implementing deadlock detection techniques. Using a consistent locking order can also minimize deadlock chances. Regular monitoring of transaction behavior and applying timeout strategies help identify and resolve potential deadlocks. These practices ensure smoother database operations and improved performance.
46. Explain the purpose of the LOCK hint.
Ans:
The LOCK hint in SQL specifies the locking behavior for table access during query execution. It directs the database management system to apply a specific type of lock, such as shared (SHARED LOCK) or exclusive (EXCLUSIVE LOCK), to ensure data consistency and concurrency control. This hint helps control how concurrent transactions interact with data, preventing issues like lost updates or inconsistent reads.
47. How is the scope of a transaction defined?
Ans:
The scope of a transaction in database management is defined by its boundaries, which encompass all operations that are treated as a single unit of work. This includes all reads and writes performed within the transaction. The scope begins with the first database operation and concludes with a commit or rollback statement, ensuring that either all operations within the transaction are completed successfully and permanently saved or none are, maintaining data consistency and integrity.
48. What are the differences and similarities between optimistic and pessimistic locking?
Ans:
- Comparing Pessimistic and Optimistic Locking: Pessimistic locking delays resource locking until commit time, assuming that conflicts between transactions occur seldom.
- When resources are accessed, they are locked by pessimistic locking, which keeps them locked until it is released.
- In contrast, optimistic locking allows multiple transactions to proceed without locking resources, validating changes only at commit time; if a conflict is detected, the transaction may be rolled back.
- This approach can enhance concurrency and performance in scenarios with low contention, making it suitable for applications where conflicts are rare.
49. How are locking issues monitored and resolved?
Ans:
Locking issues in databases are monitored using tools that track current locks and their durations. Resolving these issues typically involves:
- Identifying conflicting transactions.
- Optimizing queries to reduce lock contention.
- Adjusting transaction isolation levels.
- The database schema could be redesigned to minimize locking conflicts.
50. What is the purpose of the SET TRANSACTION ISOLATION LEVEL?
Ans:
- The current transaction or session’s isolation level is set with the command SET TRANSACTION ISOLATION LEVEL.
- It allows users to manage transaction consistency and concurrency, which impacts how transactions and data updates interact.
- By adjusting the isolation level, users can control phenomena such as dirty reads, non-repeatable reads, and phantom reads, balancing the trade-offs between data accuracy and system performance.
- This flexibility enables developers to tailor the behavior of transactions based on the specific requirements of their applications and the expected workload characteristics.
51. How do indexes enhance query performance?
Ans:
Indexes enhance query performance by facilitating rapid data retrieval. They work by creating a sorted structure of data, making it possible for the database engine to find rows matching a query’s conditions without scanning the entire table. This optimization reduces the number of disk I/O operations needed, resulting in faster query execution times. Additionally, indexes support efficient sorting and grouping operations, enhancing overall database performance.
52. Describe the different types of indexes supported in T-SQL.
Ans:
- Clustered Index: Utilizes the index key to arrange and store data rows in the database.
- Non-clustered Index: Builds a distinct structure with pointers to match data rows and index fundamental values.
- Guarantees that the values in indexed columns are unique with a unique index.
- A subset of rows is indexed using a filtered index, which is based on specific filter constraints.
- The spatial index optimizes queries using spatial data types.
53. Explain the process of index creation.
Ans:
Index creation in databases involves selecting one or more columns from a table to optimize query performance. This process creates a data structure that allows the database management system (DBMS) to quickly locate rows that match specified criteria, such as a WHERE clause. Indexes improve data retrieval speed but can impact insert and update operations due to the additional overhead of maintaining index structures.
54. What is the purpose of the INCLUDE clause in index creation?
Ans:
The INCLUDE clause in index creation is used to include non-key columns in a non-clustered index. These columns are not part of the index key but are stored at the leaf level of the index. Including columns in this manner can improve query performance by covering more queries, reducing the need to access the base table for data retrieval. It helps optimize query execution by allowing the index to cover more query scenarios without unnecessarily increasing the size of the index key.
55. How are the appropriate columns determined for indexing?
Ans:
The decision to index columns in a database involves identifying frequently queried columns in SELECT, JOIN, and WHERE clauses. Columns that are interested in filtering, sorting, or joining large datasets should be considered for indexing to improve query performance. However, indexing every column can lead to overhead, so it’s crucial to balance indexing benefits with the cost of maintaining indexes during data modifications like INSERTs, UPDATEs, and DELETEs.
56. Discuss the impact of indexes on data modification operations.
Ans:
- The Effect of Indexes on Data Modification Activities: Because indexes require maintenance to remain synced with underlying data, they might slow down data modification activities (INSERT, UPDATE, DELETE).
- Overindexing can cause storage overhead to rise and data modification activities to perform less well.
- Additionally, while indexes can significantly improve read performance by speeding up query execution, the trade-off in modification performance necessitates careful consideration of which indexes are truly beneficial for specific use cases.
57. What are the advantages and disadvantages of clustered indexes?
Ans:
Advantages:
- Fast Retrieval: Clustered indexes physically order data rows, leading to speedier retrieval times for range queries and ordered scans.
- Avoidance of Extra Storage: No additional storage space is required since the index structure mirrors the table’s physical order.
Disadvantages:
- Insert and Update Overhead: Inserting or updating data may require reordering of physical data, leading to performance overhead.
- Increased Fragmentation: High insert/update activity can cause fragmentation, impacting performance.
58. How are indexes rebuilt or reorganized?
Ans:
- Index Rebuilding or Reorganization: To rebuild an index, use the ALTER INDEX REBUILD command or the REBUILD option in index maintenance plans.
- The ALTER INDEX restructure statement can also be used to restructure indexes in order to defragment index pages.
- Additionally, regular index maintenance is crucial for maintaining optimal database performance, as it helps to reduce fragmentation and improve query efficiency over time.
- Monitoring index usage and performance metrics can guide decisions on when to rebuild or reorganize indexes, ensuring that database operations remain efficient and responsive.
59. Describe the role of index statistics.
Ans:
Index statistics in database management systems play a crucial role in optimizing query performance. They provide metadata about the distribution and cardinality of values in indexed columns, allowing the query optimizer to make informed decisions on query execution plans. By analyzing index statistics, the optimizer can choose the most efficient index to access data, determine join order, and estimate the cost of different query execution strategies.
60. How is query performance monitored and optimized?
Ans:
- Tracking and Improving Query Performance: SQL Server Profiler and Query Store are two tools that may be used to track and improve query performance.
- Optimization techniques include index tweaking, query refining, and database schema reorganization to improve query execution performance.

61. Define views and elucidate their purpose.
Ans:
- Views in databases function as virtual tables that display information that has been pulled from one or more underlying tables.
- Their goals are to provide a layer of abstraction, streamline complex searches, and control data access by limiting what users can see in terms of columns and rows.
- Additionally, views can simplify query writing by encapsulating complex joins and calculations, allowing users to interact with a more straightforward representation of the data without needing to understand the underlying complexities.
62. How is a view created in T-SQL?
Ans:
A view is created using the CREATE VIEW command, which specifies columns and a SELECT query that defines the data to be presented. Additional options, such as WITH CHECK OPTION, can enforce rule enforcement for data modification. Views can simplify complex queries by encapsulating them, allowing users to interact with data in a more intuitive manner. Moreover, they can enhance security by restricting direct access to underlying tables, enabling users to see only the data that is relevant to them while maintaining the integrity of the database structure.
63. What are the advantages and limitations of views?
Ans:
Benefits include:
- Faster query creation.
- Better speed is due to the storage of frequently used queries.
- More security through data abstraction.
Among the drawbacks are constraints on view complexity, potential cost from runtime query execution, and performance consequences for complicated views.
64. Explain the functionality of an INSTEAD OF trigger.
Ans:
- An INSTEAD OF trigger is a specific kind of trigger that fires on a view instead of an INSERT, UPDATE, or DELETE operation.
- It allows complex data manipulation by allowing custom logic to be executed in place of the view’s default data modification action.
- Additionally, INSTEAD OF triggers can help enforce business rules by validating or transforming data before any modifications are applied, ensuring that only the desired changes occur within the underlying tables.
65. How are triggers created in T-SQL?
Ans:
- Triggers are created by executing the CREATE TRIGGER statement, which includes the table, triggering event (INSERT, UPDATE, DELETE), timing (BEFORE or AFTER), and trigger name.
- The logic that is carried out upon trigger activation is contained in the trigger body.
- Additionally, triggers can be used for enforcing business rules, maintaining audit trails, or performing cascading actions, such as automatically updating related records or logging changes.
- However, care must be taken when using triggers, as they can introduce complexity and may impact performance if not designed efficiently, particularly in high-transaction environments.
66. Describe the types of triggers available.
Ans:
Trigger Types Available: AFTER triggers (INSERT, UPDATE, DELETE) run following the triggering operation. BEFORE triggers execute actions prior to the triggering operation, allowing for data alteration before persistence. Additionally, instead of relying solely on triggers, stored procedures can also be employed to encapsulate complex logic and facilitate more controlled data modifications.
67. How are errors managed within triggers?
Ans:
Errors within triggers are typically managed using error handling constructs such as TRY-CATCH blocks in SQL Server or EXCEPTION blocks in Oracle. When an error occurs during trigger execution, these constructs capture the error, allowing for controlled responses like rolling back transactions, logging errors, or performing corrective actions. Effective error management ensures data integrity and maintains robustness in database operations.
68. Explain the concept of trigger recursion and its mitigation.
Ans:
- An explanation and mitigation of the phenomenon: Trigger recursion is the outcome of one trigger initiating another, creating a recursive loop.
- Recursive depth checks, trigger restructuring, or temporary trigger disabling are examples of mitigation techniques.
- Additionally, using flags or state variables can help track whether a trigger has already executed, preventing unwanted recursion.
- Careful design and thorough testing of triggers are essential to ensure that recursion does not lead to performance issues or unintended consequences in database operations.
69. What are the recommended practices for using views and triggers?
Ans:
- Views: Use views to simplify complex queries and abstract underlying data structures and enforce security by granting appropriate permissions.
- Triggers: Employ triggers cautiously to enforce data integrity rules and audit changes, as well as automate complex database operations to maintain consistency.
- Performance: Ensure views and triggers are optimized to avoid performance bottlenecks, especially in high-volume transactional environments.
- Documentation: Document views and triggers thoroughly to aid maintenance and understanding of their purpose and functionality.
70. When are dynamic SQL and cursors appropriate?
Ans:
Dynamic SQL and cursors are suitable for dynamic or iterative processing requirements, such as dynamic query construction or result set iteration. However, due to the potential performance overhead and security vulnerabilities, they should be used sparingly. It is essential to validate and sanitize any user input in dynamic SQL to prevent SQL injection attacks. Additionally, wherever possible, consider using set-based operations instead of cursors, as they tend to offer better performance and scalability in handling large datasets.
71. Define dynamic SQL and its application.
Ans:
Dynamic SQL refers to SQL statements that are constructed and executed at runtime within a program or script rather than being predefined. It allows for the generation of SQL queries based on variable conditions or inputs, enhancing flexibility in database operations. Applications include:
- Generating complex queries based on user inputs.
- Creating dynamic reports.
- Implementing conditional logic within stored procedures or application code.
72. How are dynamic SQL statements constructed?
Ans:
Dynamic SQL statements in SQL are constructed by concatenating strings with variables or expressions that hold SQL commands or fragments. This approach allows for flexibility in generating SQL queries at runtime based on varying conditions or user inputs. Care must be taken to handle potential security risks such as SQL injection by validating and sanitizing inputs before incorporating them into dynamic SQL constructs.
73. What are the advantages and disadvantages of dynamic SQL?
Ans:
- Among the advantages are the ability to create queries on the fly, adaptability to changing requirements, and possible performance gains through query plan caching.
- Cons include less readable code, more complexity, and security flaws related to SQL injection.
- Additionally, dynamic SQL can lead to debugging challenges, as errors may only surface at runtime, making it harder to trace issues compared to static queries. Careful management and testing are crucial to mitigate these drawbacks while leveraging the benefits of dynamic SQL.
74. What is the significance of cursors?
Ans:
Cursors in SQL are significant as they enable sequential processing of result sets, allowing row-by-row operations within a database context. They are helpful for complex data manipulation tasks where set-based operations are impractical, such as iterative processing, procedural logic, and handling transactional data with specific ordering requirements.
75. Describe the different types of cursors.
Ans:
- SCROLL: Allows for both forward and backward scrolling.
- STATIC: Provides a static image of the result set that records modifications made by other users when navigating the cursor.
- DYNAMIC: This may cause concurrency problems, although it reflects modifications made by others during cursor traversal.
76. How is a cursor declared and utilized?
Ans:
In SQL, a cursor is declared using the ‘DECLARE’ statement, specifying the query that defines the result set. The cursor is then opened to execute the query and rows are fetched sequentially. Each ‘FETCH’ retrieves the current row, which can be processed using statements within a loop. Finally, the cursor is closed to release resources after processing all rows. Proper management of cursors is essential to ensure efficient resource utilization and to avoid memory leaks in database applications.
77. Explain the steps involved in processing a cursor.
Ans:
- Declare the Cursor: Define the cursor with a SELECT statement to specify the result set.
- Open the Cursor: Initialize the cursor and populate it with data from the result set.
- Fetch Data: Retrieve individual rows from the cursor into variables or a result set.
- Process Rows: Perform necessary operations on the fetched data row by row.
- Close and Deallocate: Close the cursor to release the memory and deallocate it to clean up resources.
78. What measures are taken to optimize cursor performance?
Ans:
- Minimize Cursor Use: Avoid using cursors where set-based operations can be used instead.
- Efficient Fetching: Use the FETCH NEXT option to process rows incrementally, reducing memory usage.
- Appropriate Cursor Types: Based on the task’s specific needs, choose the right cursor type (e.g., static, dynamic, or forward-only).
- Indexing: Ensure proper indexing on the tables being accessed to speed up row retrieval.
79. What alternatives exist to using cursors?
Ans:
Alternatives to using cursors in SQL include set-based operations like JOINs and subqueries, which process data in bulk rather than row-by-row. Window functions, such as ROW_NUMBER(), RANK(), and DENSE_RANK(), provide ways to perform calculations across rows of a result set without using cursors. Additionally, Common Table Expressions (CTEs) can simplify complex queries and improve readability by allowing for recursive queries or hierarchical data processing.
80. In what circumstances are dynamic SQL and cursors recommended?
Ans:
- When queries need to change dynamically based on runtime circumstances, dynamic SQL is preferred.
- Cursors are useful when set-based operations are not feasible and row-level processing or sequential access to query results is needed.
- Additionally, dynamic SQL can be advantageous in scenarios where user input dictates the structure of the query, allowing for greater flexibility and responsiveness to varying data retrieval requirements.
- However, both dynamic SQL and cursors should be implemented judiciously to balance their benefits with potential performance impacts and security considerations.
81. Describe the mechanisms for error handling in T-SQL.
Ans:
- The @@ERROR variable, TRY…CATCH blocks and error-raising methods like RAISERROR or THROW are just a few of the error-handling techniques available in T-SQL.
- With the help of these tools, developers can adequately handle problems and manage exceptions inside their code.
- Additionally, logging errors to a dedicated table or using error-handling procedures can enhance the monitoring of application performance and facilitate troubleshooting by providing detailed information about issues as they occur. This proactive approach helps maintain data integrity and improves overall system reliability.
82. How are custom errors raised?
Ans:
To raise custom errors in many programming languages, integrated error-handling systems can be utilized. In languages like Python, the ‘raise’ statement is used with an exception class, optionally passing a custom error message. In Java, a new exception can be thrown using an exception object and the ‘throw’ keyword. Similarly, in C#, the ‘throw’ keyword is used with an exception instance.
83. Explain the TRY…CATCH construct.
Ans:
The TRY…CATCH construct in SQL gracefully handles exceptions and errors within a transaction. The TRY block contains code that may throw an error, while the CATCH block contains code to handle the error if it occurs. If an error arises, control is transferred from the TRY block to the CATCH block, where error-handling logic can be implemented. This approach allows for the separation of normal processing logic from error-handling logic, enhancing code readability and maintainability.
84. What is the difference between RAISERROR and THROW.
Ans:
- RAISERROR vs. THROW: RAISERROR is an earlier technique that allows you to create error states, severity levels, and error messages. It is used to generate bespoke errors in T-SQL.
- Introduced in SQL Server 2012, THROW offers a more recent option with improved error-handling capabilities and a simpler syntax.
- Additionally, THROW automatically preserves the original error state, making it easier to propagate errors up the call stack without losing important context, enhancing debugging and error tracking.
85. How are error details captured within a CATCH block?
Ans:
System functions like ERROR_NUMBER(), ERROR_MESSAGE(), and ERROR_STATE() provide error information, including the error number, message, severity, state, and line number in a CATCH block. Leveraging these functions enables developers to gain insights into the error’s nature, facilitating effective debugging and resolution. Additionally, combining this information with logging mechanisms creates comprehensive error reports, allowing teams to analyze patterns over time and implement preventative measures to enhance application reliability.
86. Describe the role of @@ERROR in error handling.
Ans:
In SQL Server, the `@@ERROR` function is used to handle errors. It returns the error number of the last Transact-SQL statement executed. If the statement executes successfully, `@@ERROR` returns 0. This function allows for checking and responding to errors immediately after each SQL statement, enabling the implementation of conditional logic to handle the mistakes appropriately within T-SQL scripts and stored procedures.
87. How are errors logged and managed in production environments?
Ans:
- Error Logging and Management in Production Environments: Errors that arise in production environments are usually logged to error or event logs for analysis and resolution.
- It is possible to configure a variety of monitoring and alerting systems to immediately warn administrators about severe issues, allowing for timely mitigation.
- Additionally, implementing a structured error management process that categorizes and prioritizes errors can help teams address critical issues more effectively while ensuring that less severe problems are monitored and resolved systematically, thereby maintaining overall system stability and performance.
88. What are the best practices for debugging T-SQL code?
Ans:
- To display variable values for debugging purposes, use the PRINT or SELECT statements.
- For organized error management and gentle recovery, use TRY…CATCH blocks.
- For more advanced debugging features, use debugging tools like SQL Server Profiler or the debugger included in SQL Server Management Studio (SSMS).
89. Explain the functionality of SQL Server Profiler.
Ans:
- SQL Server Profiler’s functionalities: SQL Server Profiler is a tool for monitoring and recording events within SQL Server.
- Logging events such as query executions, errors, and locks helps developers track database activity, evaluate query performance, and debug problems.
- Additionally, it enables users to create customized traces, allowing for the filtering of specific events or data, which can help focus analysis on particular issues or areas of interest.
- This targeted approach enhances performance tuning efforts and aids in optimizing SQL queries and overall database efficiency.
90. How is query performance troubleshot and optimized?
Ans:
Tools like SQL Server Profiler, SQL Server Management Studio (SSMS) Execution Plan, and Dynamic Management Views (DMVs) are necessary for troubleshooting and optimizing query performance. Optimization approaches include index tuning, query refining, schema redesign, and database setup changes to improve query execution performance.




