
Last updated on 17th Nov 2021| 8888
Neo4j is a leading graph database management system designed for efficiently storing, managing, and querying highly interconnected data. Unlike traditional relational databases, Neo4j is specifically tailored for graph-based data models, where relationships between entities are as crucial as the entities themselves. It employs a property graph model, allowing nodes to represent entities and relationships to convey connections between them, each capable of holding key-value pairs. Neo4j’s query language, Cypher, facilitates expressive and intuitive graph querying.
1. What is Neo4J?
Ans:
Neo4j is an open-source, scalable graph database management system that organizes, stores, and retrieves data in graph structures, excelling in complex relationships and network management applications due to its Cypher query language.
2. Where is Neo4J used?
Ans:
Neo4j is utilized in various industries for risk management, fraud detection, e-commerce, healthcare, and social networks. Its graph database structure allows efficient data traversal and analysis, and is used in knowledge graphs for dataset organization.
3. Which IP address do we utilize to get into the Neo4J environment?
Ans:
- Usually, the web browser is used to provide access to the Neo4j environment.
- When Neo4j is operated locally, its web interface can be accessed by default at http://localhost:7474.
- The IP address or domain of the server is used for remote access, with port 7474 being the default.
4. Mention a few of Neo4J’s key characteristics.
Ans:
Neo4j is a popular graph database that excels in managing complex relationships, with a native graph storage model for easy data representation and querying. It ensures data consistency through ACID compliance and offers Cypher, a versatile query language, making it ideal for relationship-centric data scenarios.
5. What is stored on a Neo4J graph node?
Ans:
Neo4j is a database system where a graph node represents an entity and stores properties and labels. Properties provide key-value pairs, while labels categorize nodes into groups or types. These labels aid in efficient organization and querying. Nodes also store relationships, forming the structure of the graph.
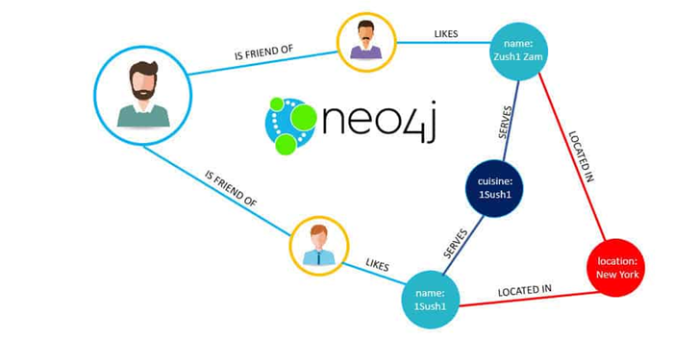
6. What Query Language Does Neo4J Use?
Ans:
Neo4j utilizes the Cypher query language, designed for handling graph data and graph patterns. It allows users to retrieve, add, edit, and remove nodes and network interconnections, making it easier to work with complex topologies.
7. In what category is CQL a language?
Ans:
- The query languages used with Apache Cassandra, a distributed NoSQL database, include CQL, or Cassandra Query Language.
- It is made especially for dealing with and maintaining data in Cassandra, sharing grammatical similarities with SQL (Structured Query Language).
- It offers a strong and effective way to carry out database operations within the Cassandra ecosystem.
8. In Neo4J, how do you query language?
Ans:
The Cypher query language is used in Neo4j to perform queries. With Cypher, you can describe graph patterns, retrieve data, and operate on nodes and relationships—all of which are tailored for graph databases. Cypher’s user-friendly syntax makes it easier to navigate and query the intricate relationships found in Neo4j graph databases.
9. Provide an example to show the structure of the Neo4J query language.
Ans:
- MATCH (n:Person)-[:FRIEND]->(friend)
- WHERE n.name = ‘John’
- RETURN n, friend
In this query:
- `MATCH` defines the pattern of nodes and relationships to retrieve.
- `(n:Person)-[:FRIEND]->(friend)` specifies nodes labeled as “Person” connected by a “FRIEND” relationship.
- `WHERE` filters the results based on a condition (here, where the name of the person is ‘John’), and `RETURN` specifies what data to retrieve and display (both` n `and `friend`).
10. What are some other well-known graph databases that are out there?
Ans:
- Amazon Neptune
- Microsoft Azure Cosmos DB
- JanusGraph
- ArangoDB
- OrientDB
- AllegroGraph
11. Which Neo4J commands do you frequently use?
Ans:
MATCH: Used to specify patterns to be matched in the graph.
12. What is the purpose of the REMOVE command?
Ans:
To remove properties from nodes or relationships in the graph, use Neo4j’s `REMOVE` command. By enabling users to remove particular features on a selective basis, the graph data can be updated or cleaned up. When it’s necessary to change current nodes or relationships by eliminating specific attributes without erasing the entire object, this command comes in handy.
13. What distinguishes the DELETE and REMOVE commands from one another?
Ans:
- DELETE: Deletes nodes, relationships, or entire patterns from the graph.Used for removing entire entities and their connections.
- REMOVE: Removes specific properties from nodes or relationships without deleting the entire entities. Useful for selectively updating or cleaning up data by eliminating certain attributes while retaining the structure of nodes or relationships.
14. What does Neo4J’s object cache mean?
Ans:
Neo4j’s object cache, also known as the “object cache layer,” is a memory-based database component that caches frequently requested graph data, such as relationships and nodes, to improve query efficiency, reduce disk access frequency, and enhance traversal operations and graph searches.
15. Which kinds of object caches are available in Neo4J?
Ans:
Node Cache: To increase the speed at which frequently requested nodes can be retrieved, complete nodes are cached.
Relationship Cache: Improves traversal and query performance of graph relationships by caching relationships between nodes.
16. Is there a command to add new properties to an existing relationship or update current properties?
Ans:
In Neo4j, you can use the SET clause to add new properties or update existing ones on a relationship. For example:
17. What separates Neo4j and MongoDB from one another?
Ans:
| Feature | Neo4j | MongoDB |
|---|---|---|
| Data Model | Graph Database | Document Database |
| Query Language | Cypher | MongoDB Query Language (JSON-based) |
| Schema | Schema-based | Schema-less |
| Relationships | First-class citizens, explicitly defined | Implicit relationships, no schema |
18. A brief CQL LIMIT clause for Neo4j?
Ans:
In Neo4j’s Cypher Query Language (CQL), the `LIMIT` clause is used to restrict the number of results returned by a query. For instance:
19. What is the syntax for the IN Operator?
Ans:
`IN` operator is used to filter nodes or values based on a set of predefined values. The syntax involves specifying the target property and a list of values within parentheses.
20. What is the purpose of CREATE UNIQUE?
Ans:
Nodes and relationships are only created using the `CREATE UNIQUE` clause in Neo4j’s Cypher Query Language if they do not already exist in the graph. By ensuring uniqueness according to the given pattern, it stops duplicate entities from being created.
21. Which handles graphs more quickly, Neo4j or MySQL?
Ans:
Neo4j is generally more efficient than MySQL at handling queries and traversals related to graphs. Compared to conventional relational databases like MySQL, Neo4j’s native graph database architecture is optimized for managing relationships, which makes it a good choice for jobs involving graphs.
22. Which architecture supports a server located remotely?
Ans:
A remote server is supported by a client-server architecture. In this model, clients use a network to send requests to a centralized server, which then processes them to grant access to resources or services. Distributed computing and remote access to server-based operations are made easier by this design.
23. In Neo4j, how are difficult joins handled?
Ans:
- Neo4j’s native graph database model makes complex joins naturally simpler.
- A natural and effective technique to manage complex joins is to traverse relationships in a graph, doing away with the necessity for laborious join operations that are frequently encountered in relational databases.
- This improves the efficiency and intuitiveness of exploring intricate network structures and querying relationships in Neo4j.
24. In Neo4j, how would you model hierarchical data?
Ans:
A tree-like structure, with each node representing a level and associations showing parent-child connections, can be used in Neo4j to model hierarchical data. This enables effective hierarchical information retrieval and traversal in a native graph database style.
25. Could you clarify the distinction between Neo4j’s depth-first and breadth-first traversals?
Ans:
Deep relationship-friendly, depth-first traversal in Neo4j investigates a path to the greatest extent possible before retracing. By exploring surrounding nodes first, breadth-first traversal, on the other hand, is more appropriate for finding several pathways of comparable length that branch off from the initial node.
26. Could you please explain how collections and aggregates are used in Cypher?
Ans:
In Cypher, collections like lists and aggregates like `COLLECT` are used to manipulate and aggregate data. For example, `COLLECT `can group results into a list, while `UNWIND` can be used to transform a list into individual rows for further processing.
27. Could you explain the idea behind the graph engine in Neo4j and how it allows for transaction management and graph processing?
Ans:
- The graph engine of Neo4j is made for effective graph processing and transaction management.
- It is ideal for managing complicated, linked data because it use a property graph model to represent and traverse relationships.
- This architecture enables ACID-compliant transactions and optimized graph algorithms.
28. How can labels help with performance optimization in Neo4j? What is their function?
Ans:
Neo4j uses labels as a categorization technique that helps with speed optimization by enabling effective node filtering based on assigned labels. This reduces the scope of operations and improves the overall speed of graph traversals and searches by enabling more focused queries and indexing.
29. How would you approach full-text searching in Neo4j if you needed to?
Ans:
You can utilize third-party plugins like the Neo4j Elasticsearch Integration or the `fulltext` index offered by the APOC library to achieve full-text searches in Neo4j. By indexing and querying textual material within nodes or relationships in the graph database, these technologies facilitate effective text-based searches.
30. How can social network analysis be done with Neo4j? Could you provide us an example?
Ans:
Social network analysis in Neo4j involves leveraging its graph database capabilities to model and query relationships. For example, identifying influential users or communities can be achieved by analyzing node centrality measures like degree or betweenness centrality, using Cypher queries like `MATCH (u)-[r]-(v) RETURN u, count(r) AS degree ORDER BY degree DESC LIMIT 10`.

Get JOB Apache Mahout Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
31. What language is Neo4J written in?
Ans:
Neo4j is mostly implemented in Java, making use of its powerful features to handle graphs quickly. Neo4j’s primary engine is Java-based, but it also offers language drivers and APIs in other languages, making it easier for programmers of different languages to integrate and interact with the database.
32. What use do construction elements like properties, labels, relationships, and nodes serve in Neo4J?
Ans:
- Nodes: Represent entities in the graph, serving as fundamental building blocks.
- Relationships: Define connections between nodes, encapsulating the nature of associations.
- Properties: Store key-value pairs associated with nodes and relationships, providing details about entities.
33. How does Neo4J store files?
Ans:
Neo4j doesn’t keep files on its end. Rather, it concentrates on effectively utilizing its own graph database architecture for the storage and querying of graph data. When it comes to files, Neo4j can store references or metadata about them as properties within nodes or relationships in the graph. Files are normally kept externally.
34. Explain the meaning of relationships within the Neo4j framework.
Ans:
Neo4j’s relationships are node-to-node connections that define linkages and describe their characteristics in the graph. They provide rich context through type, optional characteristics, and direction, enabling exploration of complex patterns and efficient navigation of the graph.
35. How is data consistency and transaction management handled in Neo4j?
Ans:
- Neo4j uses the ACID properties—atomic, consistent, isolated, and durable—to guarantee data consistency.
- Every transaction is handled as an indivisible single entity, ensuring total success or total rollback.
- Durability is preserved by preserving changes to disk after transaction commit, and isolation eliminates interference between transactions.
36. Is it possible to combine Neo4j with additional programming languages?
Ans:
Neo4j supports integration with Java, Python, and JavaScript programming languages, allowing developers to work with graph data in their preferred language, enhancing compatibility with diverse application ecosystems and facilitating seamless communication with Neo4j databases.
37. Which applications does Neo4j have?
Ans:
- Applications like knowledge graph management, fraud detection, recommendation engines, and social network analysis frequently employ Neo4j.
- Because of its superior handling of linked data, its graph database concept finds use in situations where relationships are crucial.
38. How is scalability handled by Neo4j?
Ans:
Neo4j leverages clustering and sharding strategies to enhance scalability. Clustering creates a distributed graph database, enhancing speed and supporting dataset expansion, while sharding divides the graph across multiple servers, ensuring efficient scalability.
39. In Neo4j, what is a traversal?
Ans:
The traversal procedure of eo4j entails moving throughout the graph by tracking node interactions in order to find patterns or get to particular nodes. This is essential for navigating between nodes in the graph database according to predetermined criteria or relationships and for browsing and querying related data.
40. Could you describe the distinction in Neo4j between a labeled and an unlabeled node?
Ans:
In Neo4j, a labeled node has one or more labels assigned to categorize it, providing a way to organize and query nodes based on their type. Unlabeled nodes, on the other hand, lack such categorization and are not explicitly associated with specific types or classes.
41. How does it manage schema differently from conventional relational databases?
Ans:
- Unlike traditional relational databases with their strict schema frameworks, Neo4j allows for flexible data modeling without having a specified schema.
- Because of its adaptability, changing graph architectures may be supported without being restricted to certain data types or connections.
42. In Neo4j, what does an Index Provider do?
Ans:
In Neo4j, an Index Provider determines how indexes are stored and queried, influencing the efficiency of lookups on indexed properties. It plays a crucial role in optimizing the performance of queries involving specific properties within the graph database.
43. What are some ways to improve the performance of Cypher queries?
Ans:
Use suitable indexes on frequently requested attributes and, when practical, restrict result size to improve Cypher query efficiency in Neo4j. Optimize query patterns as well to take use of the graph database’s advantages for quickly navigating relationships.
44. What is the Neo4j Bolt protocol used for?
Ans:
- Clients and the Neo4j server can communicate effectively and quickly because of the low-overhead, binary Neo4j Bolt protocol.
- It improves speed by giving clients an easier method to communicate with the graph database.
45. Describe how a property graph works in Neo4j.
Ans:
Neo4j Bolt protocol’s low-overhead, binary format improves speed by ensuring effective communication between clients and the server. This protocol optimizes overall communication by giving clients a straightforward and efficient way to interact with the graph database.
46. How is data versioning handled by Neo4j?
Ans:
Neo4j does not allow native versioning, so developers often use additional methods or resources within the database to handle versioned data according to their specific needs, rather than using predetermined graph pictures or temporal characteristics.
47. What function does the Neo4j Import Tool serve?
Ans:
With its ability to import massive amounts of data from external sources in CSV and JSON formats, the Neo4j Import Tool ensures compatibility with a wide range of datasets and streamlines the data import procedure for Neo4j database.
48. Could you describe a graph algorithm in Neo4j?
Ans:
Large amounts of data may be easily imported into Neo4j databases from external sources in CSV and JSON formats thanks to the robust Neo4j Import Tool, which also ensures compatibility with a variety of datasets.
49. How does Neo4j employ a blend of pessimistic and optimistic locking to handle concurrency?
Ans:
Neo4j primarily employs an optimistic locking strategy for handling concurrency, maintaining data consistency, and preventing conflicts in concurrent write operations. Each node has a version property, and transactions check this version before committing changes to identify conflicts. While explicit pessimistic locking is not a core feature, developers can implement custom pessimistic locking mechanisms using explicit transactions.
50. What role does the Neo4j Aura platform play?
Ans:
- The Neo4j Aura platform is a fully managed cloud service that simplifies Neo4j deployment by handling infrastructure management.
- It provides scalability and ease of use, allowing users to focus on working with their graph data without the need for server administration.
51. How is geographical data supported by Neo4j?
Ans:
Neo4j is a powerful tool for location-based data applications like mapping and GIS analysis due to its built-in indexing and spatial types, making it ideal for efficient storage, retrieval, and querying of geographical data, allowing developers to model and query connections in geospatial settings.
52. In Neo4j, what are triggers and how are they used?
Ans:
Neo4j doesn’t have built-in triggers. Instead, users can leverage procedures and custom code to implement event-driven logic in response to changes in the graph database, achieving similar functionality to traditional triggers in relational databases.
53. Describe how a Neo4j Extension works.
Ans:
- A Neo4j Extension is a specially designed plugin or module that incorporates additional custom processes, methods, or endpoints to increase Neo4j’s capability.
- It expands the capabilities of the graph database and is usually written in Java or another supported language.
54. How are data backup and recovery handled by Neo4j?
Ans:
Neo4j enables users to generate consistent backups of the graph database using both online and offline backup techniques. Recovery from data loss includes replaying transaction logs, applying incremental backups as necessary, and recovering the database from a backup.
55. What does a Neo4j Sandbox entail?
Ans:
- A cloud-based environment known as a Neo4j Sandbox gives customers an easy-to-use, pre-configured platform to explore and learn Neo4j without requiring local installs.
- It provides users with a short-term, private area to test out Neo4j features, sample datasets, and different use cases.
56. In Neo4j, how may time-based data be modeled?
Ans:
Date attributes on nodes or relationships in Neo4j may be used to depict time-based data by representing discrete points or periods of time. In order to facilitate effective time-based pattern searching, temporal information can also be recorded using distinct time tree structures or specific date-time data types.
57. What is the operation of the Neo4j Graph Data Science library?
Ans:
- Graph analytics: Uses pathfinding, community identification, and centrality techniques to extract insights.
- Graph Embeddings: Facilitate machine learning integration by producing vectors that represent nodes and connections.
- Graph Projection: Facilitates virtual graphs, increasing flexibility and streamlining analysis by concentrating on particular features of the data.
58. How is Neo4j different from conventional relational databases?
Ans:
Neo4j traversal API allows programmatic traversal of nodes and associations based on predefined criteria, facilitating fast network research. By navigating the graph, looking for patterns, and retrieving pertinent data, developers may optimize graph traversal activities by using this API. It makes it easier to create unique algorithms in Neo4j for specialized graph exploration and analysis.
59. In the context of Neo4j, what do the ACID qualities mean?
Ans:
- Atomicity (A): Transactions are all-or-nothing; the transaction is rolled back in its entirety if any component fails.
- Consistency (C): Transactions preserve preset limitations and guidelines when they move the database from one legitimate state to another.
- Isolation (I): Independent operation of transactions keeps concurrent transactions from interfering with one another.
- Durability (D): Data recovery and persistence are ensured by committed transactions, which endure system failures and are permanent.
60. List the situations in which Neo4j is a better option than alternative databases.
Ans:
Graph-based searches, real-time suggestions, hierarchical data modeling, and schema-free flexibility are just a few of Neo4j’s strong points; it performs very well in scenarios with heavily linked data. With its enhanced traversal capabilities and Cypher query language, it excels in applications that call for pathfinding, complicated data linkages, scalability for workloads that include a lot of reading, and fraud detection
Get JOB Apache Mahout Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
61. How are transactions maintained in Neo4j, and what is their purpose?
Ans:
Transactions in Neo4j are preserved via the ACID qualities (Atomicity, Consistency, Isolation, Durability), which guarantee that a sequence of operations either succeeds totally or fails totally. The goal of transactions is to provide consistency and dependability even in the face of failures by offering a dependable and predictable mechanism for managing changes to the graph database.
62. In a distributed context, how can Neo4j guarantee data consistency?
Ans:
Neo4j uses the Raft consensus algorithm to guarantee data consistency in a distributed environment. Raft keeps the database’s state consistent by ensuring that every node in the distributed Neo4j cluster agrees on the sequence and execution of transactions. This helps to prevent inconsistent behavior in the distributed environment by ensuring that all committed transactions are replicated and applied consistently.
63. How is the processing and analysis of large-scale graph data handled by Neo4j?
Ans:
Engines for processing graphs: Neo4j uses graph processing engines to optimize the execution of complicated graph queries by traversing and analyzing large-scale graph data in an effective manner. In parallel operation: Neo4j facilitates query execution in parallel, making use of multi-core computers to speed up the processing of massive graph data sets. Enhanced Caching and Indexing: Neo4j improves large-scale graph data retrieval and analysis by reducing query response times through efficient indexing and caching algorithms.
64. In a graph database, how is versioning and schema evolution handled by Neo4j?
Ans:
- Neo4j accommodates versioning and schema evolution through its schema-less architecture, allowing nodes and relationships to adapt dynamically.
- Nodes and relationships can evolve with added or modified properties, while labeling and indexing support efficient querying on evolving graph structures.
- Neo4j’s flexibility in schema management, along with migration scripts and temporal data modeling, enables seamless handling of versioning and evolving graph schemas.
65. What is the Neo4j traversal API used for, and why is it used?
Ans:
Neo4j traversal API allows programmatic exploration and navigation of graph structures by allowing the traversal of nodes and associations according to predefined criteria. It is used in graph databases to effectively extract pertinent data, identify trends, and evaluate intricate relationships.
66. How can Neo4j be integrated with other technologies or databases?
Ans:
- Neo4j Connectors and Drivers: Use official Neo4j connectors (Java, Python, .NET) for seamless communication, enabling your app to execute Cypher queries and interact with the graph database.
- RESTful API: Access Neo4j through its RESTful API over HTTP, allowing interoperability across programming languages and platforms for CRUD operations on the graph via standard HTTP requests.
- ETL Tools for Data Integration:Employ ETL tools like Apache Kafka, NiFi, or Talend to extract, transform, and load data into Neo4j, ensuring smooth integration with existing pipelines.
67. Explain the function of privileges and roles in the access control system of Neo4j.
Ans:
Advantages within Neo4j: Read, write, create, and execute actions on relationships, nodes, and properties that are mapped to roles to provide fine-grained user access control. Positions within Neo4j: User permissions are streamlined by named collections. Roles with defined privileges were assigned by users, streamlining regular assignments for organization and scalability. Role Inheritance and Hierarchy: Allows users to inherit privileges by arranging roles in a hierarchical fashion. creates more specialized roles with extra permissions and overarching roles with shared privileges to streamline access control.
68. How can nodes be ranked in Neo4j using the PageRank algorithm?
Ans:
- To determine PageRank scores for nodes, use the gds.pageRank.write procedure.
- In the procedure, specify the graph, node projection, and relationship projection.
- Using a Cypher query, retrieve PageRank scores. Then, order the scores by score to obtain the ranking.
69. Talk about the importance of Neo4j’s community detection algorithms.
Ans:
Finding Groups: Neo4j’s algorithms for community detection, such as Louvain and Label Propagation, unveil organic clusters, unveiling significant connections and configurations that are difficult to discern through manual means. Improving Systems for Analysis and Recommendations: By classifying nodes and exposing those that share similar characteristics, community detection enhances graph analysis and recommendation systems by improving prediction accuracy for individualized recommendations.
70. How is multiversion concurrency control (MVCC) supported by Neo4J?
Ans:
Isolation of a Snapshot: Transactions can function on a consistent snapshot of the graph at the beginning of the transaction thanks to Neo4j’s implementation of MVCC through snapshot isolation.
Versioning of Nodes: Multiple transactions can operate independently of one another without interfering with one another thanks to the maintenance of node and relationship versions.
Devote and Clear Up: Data consistency is ensured by handling conflicting updates from concurrent transactions during the commit process, which applies changes atomically.
71. Describe how Neo4j uses temporal types and functions.
Ans:
- Temporal Types: Neo4j supports temporal types like` LocalDate`,` LocalTime`, and `DateTime` to represent date, time, and timestamp values respectively.
- Temporal Functions: Temporal functions like `date()`, `time()`, and `datetime()` allow manipulation and extraction of temporal components from nodes or relationships.
- Temporal Indexing: Temporal indexing enables efficient querying based on temporal conditions, facilitating temporal data analysis and retrieval in Neo4j.
- Temporal Range Queries: Neo4j allows temporal range queries using functions like`FROM`, `TO`, and `DURING` for precise retrieval of data within specified time intervals
72. How can data be imported into Neo4j from a CSV file?
Ans:
- CSV Format: Prepare the data in CSV format, where each row represents a node or relationship, and columns represent properties.
- Cypher LOAD CSV: Use the Cypher `LOAD CSV` clause to import the CSV file into Neo4j, mapping columns to nodes/relationships and defining any necessary transformations during the import.
73. Talk about Neo4j’s application to social network analysis.
Ans:
- Modeling Graphs: Neo4j is a social network analysis tool that excels at representing relationships as first-class citizens for intuitive navigation through intricate social structures.
Inquiries and Suggestions: Efficient analysis of social graphs is made possible by Neo4j’s graph algorithms and Cypher queries, which make it easier to accomplish tasks like community detection in social networks and friend recommendations.
74. What uses does Neo4j have in recommendation systems?
Ans:
Graph-Oriented Suggestions: Neo4j plays a key role in recommendation systems by efficiently traversing graph relationships to provide personalized recommendations based on user behavior.
Identifying Patterns: Neo4j’s cipher queries facilitate intricate pattern matching, which makes it possible to find pertinent connections and improve the precision of recommendations across a range of domains.
75. Describe Neo4j’s function in fraud detection.
Ans:
Graph Pattern Detection: Neo4j aids fraud detection by representing complex relationships, enabling the identification of suspicious patterns in large datasets.
- Anomaly Detection: Neo4j’s graph algorithms, including centrality measures, contribute to detecting anomalies by identifying nodes with unusual behavior in the network.
- Behavior Analysis: Neo4j facilitates behavior analysis through graph traversal, uncovering intricate relationships and assisting in identifying fraudulent activities or networks.
- Real-Time Analysis: With real-time graph analysis capabilities, Neo4j enhances fraud detection systems by swiftly identifying and responding to evolving fraudulent patterns.
76. How are user-defined functions (UDFs) in Neo4j created, and what is their purpose?
Ans:
- In Neo4j, custom procedures or queries are defined using the Cypher query language to create user-defined functions (UDFs).
- The goal of UDFs is to extend the capabilities of Cypher by enabling users to define and repurpose unique computations, aggregations, or procedures that are suited to particular application requirements.
- UDFs improve Cypher queries’ flexibility and reusability by allowing programmers to encapsulate intricate calculations, logic, or data transformations inside the graph database.
77. Describe how the apoc library is used in Neo4j and some of its standard features.
Ans:
The apoc Library’s usage:
Neo4j’s `apoc` library adds more capabilities by way of a set of processes and functions that improve graph algorithms, data import/export, and other features while offering more tools for intricate queries.
Common Elements:
Neo4j’s capabilities are greatly enhanced by the standard features of the `apoc` library, which include procedures for graph algorithms, spatial operations, data transformation, and utilities like batch processing.
78. How does the Raft consensus algorithm fit into the Neo4j clustering scheme?
Ans:
Raft’s Function in Neo4j Clustering Neo4j clustering uses the Raft consensus algorithm as its coordination protocol, which guarantees distributed consensus and dependable data replication among cluster nodes. and Fault Tolerance and Leader Election Raft contributes to a stable and reliable distributed system in Neo4j clusters by facilitating leader election, log replication, and fault tolerance.
79. Talk about the factors and procedures related to establishing a Neo4j cluster.
Ans:
- Factors for Setup: Neo4j cluster setup considers network connectivity, hardware specifications, and the right number of instances for optimal performance.
- Procedures: Configuring instances, implementing Raft, defining cluster members, and ensuring shared settings facilitate seamless communication and coordination.
- Consistent Setup: Consistent configurations, security measures, and addressing network latency are critical for a stable and fault-tolerant Neo4j cluster.
80. What tactics can be used to maximize Neo4j’s read performance?
Ans:
Limitations and Indexing:
- Increase the read performance of Neo4j by strategically locating and retrieving nodes and relationships using constraints and indexes.
Query Optimization for Cyphers:
- To improve overall read efficiency in Neo4j, optimize Cypher queries, examine execution plans using the EXPLAIN keyword, and take denormalization or caching strategies into consideration.
81. What are some effective ways to import big datasets into Neo4j using the neo4j-admin tool?
Ans:
Importing Data Offline: For effective offline imports, make use of the `neo4j-admin import` tool, which uses parallelism and optimizations to manage big datasets when it’s not connected to an active Neo4j instance.
CSV File Format: To ensure a quick and easy import process into Neo4j, prepare data in CSV format, make use of header mappings, and use the `neo4j-admin import` tool with the right flags.
82. Talk about the importance of the graph analysis tool known as the Connected Components algorithm.
Ans:
Identifying Components:
- The Connected Components algorithm in Neo4j is crucial for identifying distinct clusters or groups of nodes that share direct or indirect relationships, providing insights into the underlying structure of the graph.
Graph Organization:
- By revealing cohesive subgraphs, the Connected Components algorithm aids in understanding the organizational patterns within the graph, facilitating analysis in diverse applications, from social networks to infrastructure management.
83. How can the shortest path between two nodes with weighted relationships be found in Graph Algorithms library?
Ans:
In Neo4j’s Graph Algorithms library, the Shortest Path algorithm is a powerful tool for finding the shortest paths between two nodes in a graph with weighted relationships. To utilize this algorithm, one can use the Cypher query language with `gds.alpha.shortestPath`. In the query, specify the source and target nodes, and assign numerical weights to relationships, reflecting the desired criteria such as distance, cost, or time. The algorithm then efficiently calculates the shortest path based on the assigned weights, providing an optimized traversal for determining the quickest route between the specified nodes.
84. What insights does Neo4j’s Betweenness Centrality algorithm offer, and how does it operate?
Ans:
Neo4j’s Betweenness Centrality algorithm quantifies a node’s contribution to shortest paths among other nodes in the graph, thereby offering insights into the node’s importance.It functions by figuring out the percentage of shortest paths that go through each node, highlighting important bridges or connectors in the graph that are essential to network resilience or information flow.
85. Describe the applications of the Label Propagation algorithm in graph analysis.
Ans:
The Label Propagation algorithm is a valuable tool in graph analysis for community detection, network clustering, and identifying cohesive structures. It iteratively propagates labels among connected nodes, revealing natural groupings and communities based on inherent connectivity patterns, making it useful for social network analysis and fraud detection.
86. Describe the distinctions between a sparse and dense graph. How might these variations affect the way you model in Neo4j?
Ans:
- Graph Sparse: A sparse graph has a lower density of relationships because its nodes are connected to each other less frequently.
- Dense Graph: Nodes in a dense graph have a higher density of relationships between them and are more interconnected. In Neo4j modeling, it may be more efficient to represent only relationships that already exist for sparse graphs, while relationships that are strategically used to optimize storage and traversal are beneficial for dense graphs.
87. Talk about the function of spatial indexing in Neo4j and how location-based queries are affected by it.
Ans:
- Indexing by Space: Neo4j’s spatial indexing improves location-based queries by effectively classifying and locating nodes according to their geographic coordinates.
- Effect on Inquiries: Spatial indexing greatly improves location queries, such as locating nodes within a given radius or area, making it possible to retrieve spatially related data in Neo4j more quickly and accurately.
88. How does the Neo4j Bloom tool improve the graph analysis process, and where would you use it?
Ans:
Neo4j Bloom is a tool that enables non-technical users to interactively and collaboratively explore complex graph data through an intuitive interface. It is particularly useful for large and complex graphs, aiding in fraud detection, network analysis, and relationship discovery in various datasets.
89. Explain the variations between an undirected and directed relationship in Neo4j.
Ans:
- Relationship Without Direction: An undirected relationship is bidirectional because there is no clear direction for the connection between the nodes. An example would be a mutually beneficial friendship on a social media platform.
- Oriented Partnership: There is a defined path between two nodes in a directed relationship. Example: A social network follower relationship where the direction denotes the flow from follower to follow.
90. What are the factors when removing data from a graph, and how can a node or relationship be deleted in Neo4j using Cypher?
Ans:
Remarks on Deletion:
In Neo4j, take into account cascading effects, possible effects on connected nodes, and the need to preserve graph integrity while deleting data from a graph.
Removal in the Cypher:
To ensure that connected relationships are deleted along with nodes, use Cypher’s `DETACH DELETE`. Alternatively, use `DELETE` to perform conditional removal based on predefined criteria while controlling potential side effects on the overall graph structure.




