
Last updated on 17th Nov 2021| 6328
Are you looking for the best Informatica Analyst interview questions to help you prepare? Explore some of the most in-depth questions and their extensive answers to improve your preparedness. An essential component of many Informatica systems, Informatica Analyst is a web-based client application that helps business users collaborate on organizational initiatives. Prospective enterprise Informatica Analyst candidates frequently encounter a wide variety of role-specific interview questions. The conversation that follows offers a thorough look at several types of Informatica Analyst interview questions, which may be helpful for candidates preparing for positions in corporate data management.
1. How can Informatica help with ETL procedures and what does it do?
Ans:
One of the best ETL tools for data integration and transformation is Informatica, which makes it easier to load, convert, and extract data between various systems.
2. Describe the importance of an Informatica PowerCenter session.
Ans:
In Informatica PowerCenter, a session is a job that carries out extraction, transformation, and loading of data according to a set of instructions.
3. In Informatica, what is a mapping and how is it distinct from a session?
Ans:
A mapping in Informatica specifies transformations and describes the data flow from source to target. A session is a run of a mapping that controls its execution and data flow according to the logic of the mapping.
4. What are some ways to maximize an Informatica session’s performance?
Ans:
To improve data processing speed, Informatica performance optimization uses segmentation, caching, and appropriate indexing.
5. What distinguishes an unconnected lookup transformation from a connected one?
Ans:
The answer is that an unconnected search is called independently within an expression or transformation, but a connected lookup incorporates the transformation into the data flow.
6. In Informatica, what does a rank transformation accomplish?
Ans:
In Informatica, the Rank transformation is utilized to determine which entries in a group are at the top or bottom depending on predetermined criteria.
7. What function does a repository provide in Informatica PowerCenter?
Ans:
Informatica PowerCenter’s repository serves as a central place for version control and maintenance of metadata, including mappings, sessions, and workflows.
8. In Informatica, what is a reusable transformation?
Ans:
To promote reusability and simplicity of maintenance, a transformation in Informatica that can be applied to numerous mappings is called reusable.
9. Describe how Informatica uses sequence generator transformations.
Ans:
The Sequence Generator from Informatica Transform produces distinct sequential values that are utilized in data transformations, including surrogate keys. It keeps track of a counter that increases with each row that is processed, giving a reliable and distinct identification.
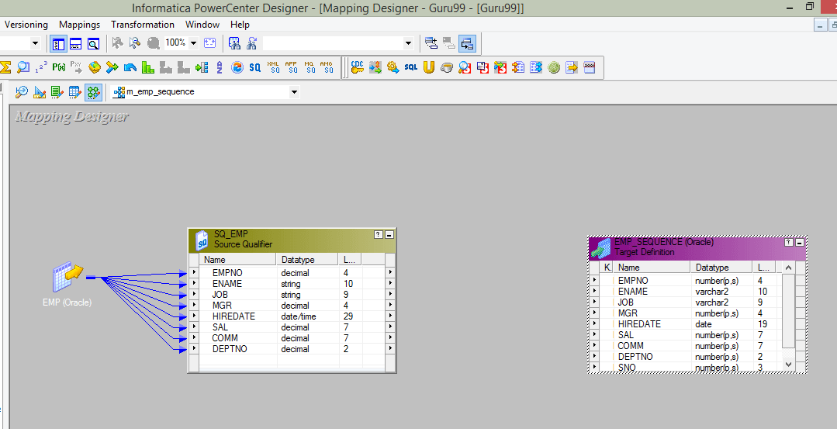
10. In Informatica, how can one manage gradually altering dimensions?
Ans:
The Type 1 (overwrite), Type 2 (historical), or Type 3 (add new attribute) methods in Informatica can be used to handle gradually changing dimensions.
11. Describe the function of an Informatica pre- and post-session command.
Ans:
In short, pre-session commands run before a session and are typically used for activities like creating temporary tables. Post-session commands run after the session and are typically used for duties like notice or cleanup.
12. How Much You Know About Informatica Partition Points?
Ans:
Partition points in Informatica specify the limits of data partitioning inside a mapping. They improve parallel processing and performance by indicating how the data is split across various processing resources. Partition points in mappings are used by Informatica PowerCenter to facilitate effective data processing and distribution among nodes or partitions.
13. How does Informatica’s “Update Strategy” transformation operate?
Ans:
In response, the Update Strategy transformation uses specified business rules to decide which rows are highlighted for insert, update, delete, or reject during the data load procedure.
14. Describe how to utilize Informatica’s “Lookup Transformation Override” option.
Ans:
To customize in particular mapping instances, you may use this option to alter a lookup transformation’s default attributes, including source qualifiers or SQL queries.
15. What does a parameter file mean, and how is it utilized in?
Ans:
In Informatica, a parameter file is a text file with key-value pairs that specify mapping or session parameter values. It offers a method for dynamically configuring attributes, including file locations or database connections, improving flexibility and simplicity of maintenance during ETL operations. The session or mapping refers to the file in order to adjust runtime behavior without changing the process or mapping.
16. In what ways does Informatica’s partitioning enhance session performance?
Ans:
In order to boost performance, partitioning divides the workload among several threads or nodes, enabling the session to process data in parallel.
17. What does an Informatica “Transaction Control” transformation accomplish?
Ans:
In order to ensure data consistency in the event of a failure, the Transaction Control transformation oversees commit and rollback actions during data loading.
18. In Informatica, what is a dynamic lookup and when would you utilize it?
Ans:
The lookup condition may be dynamically changed during a session with a dynamic lookup, which is beneficial.
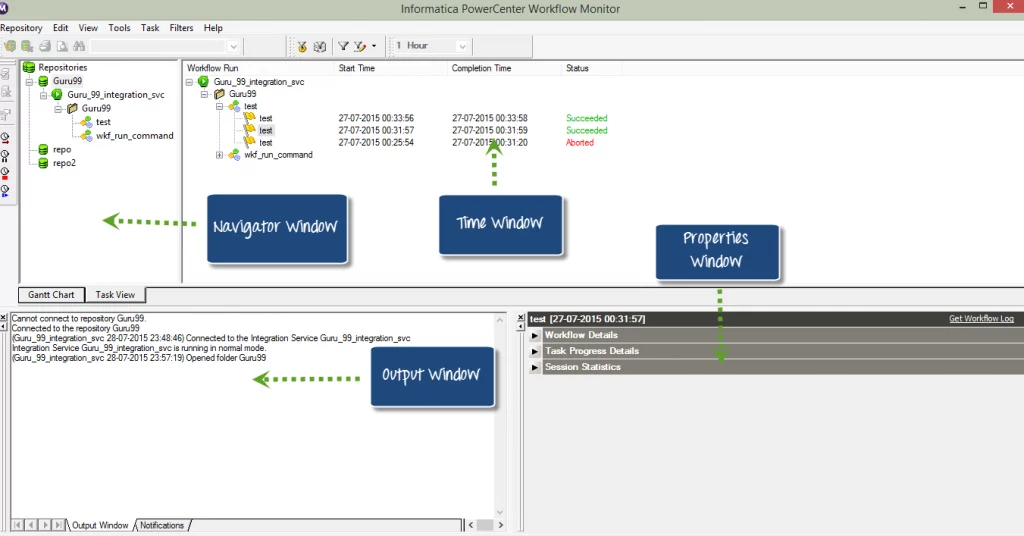
19. Talk about the importance of Informatica’s “Workflow Monitor”.
Ans:
In response, administrators may monitor the progress, status, and specifics of each process execution in real-time using the process Monitor.
20. In a lookup transformation, how many match criteria be handled?
Ans:
To handle complicated matching criteria, use numerous conditions in the lookup transformation and combine them with logical operators such as AND or OR.
21. In Informatica, what is a “Session Log” and why is it significant?
Ans:
To help with troubleshooting and auditing, the Session Log captures information about source and destination rows, transformations, and failures during a session run.
22. How does Informatica operate, and what does it do?
Ans:
Informatica is a software provider for data integration and management. Its Intelligent Data Platform makes metadata management, data quality assurance, and ETL procedures easier. By ensuring reliable, safe, and consistent data from several sources, the platform helps businesses make wise decisions. Informatica also provides massive data processing, real-time data integration, and cloud integration solutions.
23. Describe the distinction between an Informatica router and a filter transformation.
Ans:
An Informatica router is a transformation that routes data to distinct output groups according to predetermined criteria. On the other hand, a filter transformation delivers just the rows that match the criterion to the output after filtering the rows according to predetermined criteria. A filter transformation passes rows only according to one specified criteria, but a router can route data to numerous conditions.
24. What distinguishes a lookup transformation from a joiner transformation?
Ans:
- Data Source Difference: A joiner transformation integrates data from two or more sources inside the same pipeline, whereas a lookup transformation fetches data from a different source based on a condition, frequently a key.
- Static vs. Dynamic: While a joiner executes static joining during mapping execution, a lookup is dynamic and retrieves data during runtime.
- Fallback technique: Joiners do not by default offer a fallback technique to deal with missing values, but lookups may.
25. Describe what an Informatica PowerCenter “session” is.
Ans:
A “session” in Informatica PowerCenter is a job that carries out the Extract, Transform, and Load (ETL) process that is planned out in the mapping. It provides a unit of labor to transfer and process data between source and destination systems, encompassing the data extraction, transformation, and loading procedures. Sessions are essential for controlling and coordinating how ETL jobs are carried out in the PowerCenter environment.
26. What is your approach to Informatica performance tuning?
Ans:
Optimize SQL queries, indexing, and partitioning procedures in source and target databases for optimal Informatica performance adjustment. For effective data extraction, transformation, and loading, further optimize session parameters, cache usage, and parallel processing.
27. Describe the ideas behind aggregate cache and how they relate to aggregator transformation.
Ans:
When the Aggregator transformation is being processed, intermediate results are temporarily stored in Informatica’s aggregate cache. By minimizing the need to continually access and analyze the complete dataset, it enhances performance by making it possible for the Aggregator transformation to carry out computations more quickly.
28. What distinguishes an Informatica static cache from a dynamic cache?
Ans:
A dynamic cache in Informatica may be updated during the session with freshly obtained data, whereas a static cache maintains a fixed set of lookup data throughout the session. While dynamic caches provide dynamic updates depending on changing data throughout the session, static caches are appropriate for lookup tables that are quite stable.
29. Describe what is meant by “Workflow” in Informatica.
Ans:
A “Workflow” in Informatica is a collection of guidelines that specify the ETL procedure and include tasks, sessions, and linkages for carrying out data integration activities. It offers a graphic depiction of the flow of information and commands within the Informatica PowerCenter system.
30. How do you use Informatica for error handling and logging?
Ans:
Error management in Informatica is accomplished by applying error handling transformations, such as the “Transaction Control” and “Error” transformations. Session logs can contain comprehensive information about problems, workflow progress, and performance since logging is controlled by defining session-level parameters.
31. Tell us where the Informatica throughput option is located.
Ans:
The throughput option in Informatica PowerCenter may be found in the session properties. It is located under the session properties under the Config Object tab, where you may adjust session performance and resource use parameters.
32. Describe What a Session Task Is.
Ans:
The throughput option in Informatica PowerCenter may be found in the session properties. It is located under the session properties under the Config Object tab, where you may adjust session performance and resource use parameters.
33. What steps need to be taken in order to complete the session partition?
Ans:
Set the partition type and key in the session properties to finish the Informatica session partitioning process. To optimize data processing over several partitions, make sure the mapping and session are both structured to allow partitioning.
34. Describe what a surrogate key is.
Ans:
A surrogate key is a special identifier that is used in a database table to uniquely identify each record. It is usually an artificially produced or sequentially allocated integer. It acts as a primary key, preserving relational integrity and enabling effective data retrieval.
35. Give an explanation of informatica transformation and list its many forms.
Ans:
A transformation in Informatica is an ETL procedure that applies a rule-based action to incoming data. There are several sorts of data processors and manipulators, such as Source Qualifier, Expression, Aggregator, Filter, Joiner, Lookup, Router, and Target.
36. What does the term “Informatica repository” mean?
Ans:
Metadata and configuration details for Informatica PowerCenter are kept in a centralized database called the Informatica repository. By managing and arranging sessions, workflows, ETL mappings, and other items, it offers a centralized setting for administration and development.
37. Could you describe the various kinds of data that are sent between the Informatica server and the stored procedure?
Ans:
Input parameters transferred from the server to the procedure for processing are among the data exchanged between Informatica and a stored procedure. Output parameters or result sets are produced by the process and sent back to Informatica. During the conversation, error codes and messages may also be conveyed to manage exceptions.
38. How about we talk about source qualifier transformation?
Ans:
The attributes of the source data, including the source table, columns, and filter criteria, are specified using the Source Qualifier transformation in Informatica. It is crucial for providing information about the properties and organization of the source data to the PowerCenter process.
39. Describe what a status code is.
Ans:
A program or system’s status code is a numeric or alphanumeric number that indicates whether an operation was successful or unsuccessful. Status codes, with 0 generally signifying success and non-zero values indicating failures or particular outcomes, are frequently used in programming and scripting to express information about the execution of a task. Status codes are essential to software programs’ ability to handle errors and make decisions.
40. Describe the various Lookup Cache forms.
Ans:
- Informatica offers two types of lookup cache: shared and unshared. Shared cache encourages data reuse for a number of lookup transformations, whereas unshared cache preserves isolation for a single lookup transformation. Furthermore,
- cache has two options: non-persistent, which is cleared at the end of the session, or persistent, which is used again in later sessions.
41. Identify the differences between Workflow Monitor’s ABORT and STOP settings.
Ans:
Setting a session to “ABORT” in Informatica Workflow Monitor instantly ends the session’s execution and modifies its status to aborted. When the session is in “STOP” state, it stops when the current task or transformation is finished, and the session status changes to halted. While the time and effects on the session status are different, both alternatives stop the workflow.

Best Informatica Analyst Certification Course with Advanced Concepts from Real Time Experts
Weekday / Weekend BatchesSee Batch Details42. Which Informatica dimensions go into which categories?
Ans:
- Conformed Dimension: Used consistently throughout an organization’s many data marts.
- Junk Dimension: Consists of insignificant information such as indications and flags to lower the total number of dimensions.
- Degenerate Dimension: Disposes of the necessity for a separate dimension table by representing qualities that are generated from fact table columns.
Three sorts of dimensions are distinguished in Informatica:
43. What are batches and sessions?
Ans:
A “session” in Informatica is a unit of work that symbolizes the completion of an ETL procedure on data as part of a workflow job. A “batch” is a group of sessions that may be executed either simultaneously or sequentially to help coordinate several data integration jobs.
44. How does a Mapplet work?
Ans:
In Informatica, a Mapplet is a reusable object with a collection of transformations that may be used on several mappings. It provides a modular and effective approach to designing ETL operations by encapsulating the logic and capabilities for data translation and manipulation.
45. A data warehouse: what is it?
Ans:
Large amounts of organized and, occasionally, unstructured data from several sources are consolidated and integrated in a data warehouse. In order to facilitate analytical and reporting procedures, it offers a thorough and historical perspective of an organization’s data so that decisions may be made with knowledge. ETL (Extract, Transform, Load) technologies are frequently used in data warehouses to structure and organize data for effective analysis.
46. What are some ways to improve Informatica Aggregator Transformation’s performance?
Ans:
To improve the performance of the Informatica Aggregator Transformation:
- Employ Sorted Input: To improve the efficiency of the transformation’s aggregate computations, sort the input data according to the aggregator key.
- Curtail Aggregate Operations: To cut down on computational overhead, minimize the amount of aggregate functions and utilize them sparingly.
- Modify Cache Size: To strike a balance between memory consumption and processing performance, adjust the cache size based on the resources that the system can provide.
47. Identify the differences between an unconnected and a connected lookup.
Ans:
- Link Lookup: input straight from the pipeline as a component of the data flow. influences the transformation logic when it is linked to a source or target transformation.
- Disconnected Search: functions independently and isn’t attached to the pipeline directly. Returns a single value to the mapping when called by a stored procedure or an expression transformation.
48. Specify the Parameter File and A parameter file may define how many values.
Ans:
- Informatica’s Parameter File: a text file with the values of the parameters and variables needed to execute the session. Without changing the mapping or session attributes, it facilitates the management of dynamic values.
- The quantity of defined values: An infinite number of values for different parameters and variables used in Informatica sessions may be defined in a parameter file.
49. What precisely is DTM, please?
Ans:
The part of Informatica in charge of carrying out the ETL (Extract, Transform, Load) procedures is called the DTM (Data Transformation Manager). It monitors the effective movement and transformation of data inside the PowerCenter workflow, performs data segmentation and parallel processing, and controls the flow of data between transformations. Throughout the data integration process, the DTM is essential in coordinating the way that activities are carried out.
50. Say Regarding The Reusable Conversion.
Ans:
A conversion that is shared by several mappings in Informatica is called a reusable transformation. By encapsulating transformation logic for recurring usage in various ETL processes, it encourages consistency, reusability, and maintenance efficiency.
51. What Does Target Load Order Mean?
Ans:
The order in which data is put into target tables throughout the course of a session in Informatica is known as the target load order. It chooses which target tables to load first, making sure that relationships are preserved and dependencies are satisfied. In order to fulfill business needs and maintain referential integrity, target load order configuration is essential.
52. Informatica PowerCenter explanation.
Ans:
Knowledge Organizations can integrate, convert, and manage massive amounts of data from many sources using PowerCenter, an ETL (Extract, convert, Load) solution. For effective data processing, it provides a visual development environment for creating data processes, mappings, and transformations. Applications for analytics, corporate intelligence, and data warehousing frequently use PowerCenter.
53. What kinds of Informatica ETL applications are there?
Ans:
Applications for Informatica ETL include business intelligence, data migration, and data warehousing. To efficiently analyze and make decisions, these apps extract, convert, and load data using Informatica PowerCenter.
54. The PowerCenter Repository: What Is It?
Ans:
Informatica’s PowerCenter Repository is a centralized database used to hold configuration data and metadata for extract, transform, and load (ETL) operations. It offers a centralized setting for organizing and monitoring data integration projects by acting as a repository for mapping definitions, session setups, and process specifics. Within the Informatica PowerCenter system, the repository helps with information management, version control, and collaboration.
55. What are the choices for direct and indirect loading in sessions?
Ans:
Direct loading in Informatica sessions refers to loading data into the target tables directly; indirect loading, on the other hand, uses a staging table or intermediate file first before loading data into the target. The decision is based on variables such as target database properties, data transformations, and performance needs.
56. Talk about the benefits of having a divided session.
Ans:
Informatica partitioning a session can enhance performance by distributing data processing over several partitions in parallel. Large dataset extraction, transformation, and loading are made possible by its improved scalability and resource optimization. In data warehousing setups with high data processing requirements, divided sessions are especially helpful.57. What distinguishes passive transformation from active transformation?
Ans:
- Dynamic Metamorphosis: changes how many rows go through it, like in the case of filter or aggregator modifications. modifies row counts or data values, necessitating the processing of every incoming row.
- Transformation in Passive: does not alter the amount of rows that are processed, in contrast to transformations such as Expression or Rank. keeps the original data structure and has no effect on the total number of rows during the transformation.
58. Explain the distinctions between a mapping and a mapplet.
Ans:
A mapplet is a reusable object that contains a collection of transformations that may be performed inside numerous mappings, supporting modular design and reusability. In Informatica, a mapping is a set of source and target transformations that define the data flow. Mapplets provide mapping flexibility by encapsulating logic for certain transformations.
59. How may Informatica Aggregator Transformation’s performance be enhanced?
Ans:
- Sorted Input: To increase efficiency, provide sorted input into the Aggregator transformation.
- Cache Size: For effective memory use, maximize the cache size based on the resources that are available.
- Limit Aggregate Functions: To save computing overhead and improve processing performance, minimize the number of aggregate functions.
60. Describe the level of tracing.
Ans:
- Three degrees of tracing are distinguished in Informatica: Verbose, Normal, and Terse. Basic information is provided by Terse, more details such as transformation names are included by Normal, and comprehensive data values are included in Verbose, which offers considerable information. Tracing levels are useful for debugging and identifying problems that arise during the execution of a session.
61. What parts make up an Informatica workflow manager?
Ans:
Tasks, Workflow, and Worklet are the three primary components of the Informatica Workflow Manager. A worklet is a group of reusable tasks inside a workflow, a task is a single unit of work, and a workflow is a collection of tasks determining the execution order. When combined, these elements make it easier to create and carry out ETL processes in Informatica.

Enroll in Informatica Analyst Training with Advanced Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
62. What Transformations are reusable?
Ans:
The Expression, Filter, and Rank transformations are among the many reusable transformations in Informatica. These transformations may be applied to various mappings, encouraging reusability and preserving consistency. They encapsulate particular data processing logic. In ETL procedures, reusable transformations promote modular design and increase development efficiency.
63. In Informatica, how many ways are there to construct a port?
Ans:
- There are three ways to create a port in Informatica: Importing ports from another transformation or source, utilizing the Expression Editor for complicated expressions, or manually inputting the expression or column name. These techniques improve the development process by offering flexibility in port construction and management across different transformations.
64. In aggregator transformation, what is aggregator cache?
Ans:
The aggregator cache in Informatica’s Aggregator transformation is a temporary storage space where data is processed and held during aggregation. It optimizes the efficiency of aggregate functions in the transformation by storing intermediate results and group-wise computations.
65. In Informatica, what is a joiner transformation?
Ans:
A Joiner transformation in Informatica is used to create a unified result set by combining data from two heterogeneous sources according to a join criteria. It makes it easier to include data into a mapping from other tables or databases.
66. Why would Informatica do a Java transformation?
Ans:
For the purpose of executing custom logic or business rules defined in Java code within a mapping, Informatica employs a Java transformation. This makes it possible to carry out intricate computations or transformations that are not possible with conventional transformations. Informatica’s data processing is more extensible and flexible thanks to Java transforms.
67. In Informatica, how is a SQL transformation used?
Ans:
To run custom SQL queries or stored procedures on relational databases within a mapping in Informatica, utilize a SQL transformation. It enables sophisticated data extraction, aggregation, and manipulation right at the database level. By utilizing database processing capabilities, the SQL transformation improves speed and makes interaction with SQL-based systems easier.
68. What does Informatica use a shortcut for?
Ans:
A shortcut is a reusable object in Informatica that may be used to represent a mapping, session, or workflow across several folders or projects. Reusing ETL (Extract, Transform, Load) components across several repository sections facilitates consistency, efficiency, and simpler maintenance. Shortcuts minimize duplication in information management and expedite the development process.
69. How Does an Oracle Sequence Get Imported Into Informatica?
Ans:
Create an Oracle connection in Informatica, define a source with a SQL query collecting the sequence values, then use that source as a source in a mapping to load the data into the destination system in order to import an Oracle sequence into Informatica.
70. What Does Informatica’s Term “Hash Table” Mean to You?
Ans:
An in-memory data structure called a “Hash Table” in Informatica is utilized for effective lookups and transformations. By arranging and indexing data according to hash values, it improves the efficiency of data processing processes and aids in the optimization of join procedures. Hash Tables are used by Informatica in transformations such as the Lookup transformation to enhance data integration procedures.
71. In Informatica, what is the distinction between a mapping and a mapplet?
Ans:
| Feature | |||
| Definition | A mapping is a set of source and target definitions linked by transformations to convert input data into output data. | A mapplet is a reusable object that you create in the Mapplet Designer. It contains a set of transformations that you can use in multiple mappings. | |
| Scope | Typically involves the entire ETL process, from source to target, with multiple transformations. | Used for a specific set of transformations that can be reused across multiple mappings. | |
| Granularity | Larger granularity, involving multiple sources, transformations, and targets. | Smaller granularity, focused on specific transformations that can be reused. | |
| Reusable Component | Not inherently designed for reuse, although transformations within a mapping can be reused. | Specifically designed for reuse, allowing the same set of transformations to be used in multiple mappings. | |
| Editing and Updating | Changes may need to be made directly in the mapping when updates are required. | Changes made in the mapplet are automatically reflected in all mappings using that mapplet, promoting easier maintenance. |
72. Describe a few practical applications using Informatica.
Ans:
For data integration, Informatica is frequently utilized as it facilitates the smooth execution of extraction, transformation, and loading (ETL) procedures from many sources. By combining data from several systems for reporting and analysis, it makes data warehousing easier. Furthermore, Informatica is used in master data management to guarantee correctness and consistency of vital business data throughout an enterprise.
73. Define the shell commands for pre- and post-session.
Ans:
The “Pre-Session Command” session attribute in Informatica is used to specify the pre-session command, usually for operations like environment variable setup. After the session ends, the post-session command—which is specified in the “Post-Session Command” property—is run. It is frequently used for cleanup or extra tasks like alerting stakeholders. The syntax of the two commands is specific to the operating system or shell that powers the PowerCenter session.
74. Describe the many Join Types that Joiner Transformation offers.
Ans:
- Three join types Normal Join, Master Outer Join, and Detail Outer Join—are available via Informatica’s Joiner Transformation. While the Detail Outer Join returns all rows from the detail source and matching rows from the master source, the Normal Join returns matching rows from both sources. Master Outer Join returns all rows from the master source and matching rows from the detail source.
75. Is it the case that Informatica Transformation can only handle aggregate expressions?
Ans:
No, filtering, sorting, and merging data are just a few of the transformations that Informatica Transformation may do in addition to aggregate expressions. Numerous transformations, including expression, lookup, rank, and many more, are supported, enabling a variety of data operations inside a mapping. Informatica’s transformation capabilities extend beyond simple aggregate expressions.
76. Tell us why nature is experiencing the Sorter Transformation.
Ans:
The Sorter Transformation is a phrase exclusive to Informatica; it is not experienced by nature. In Informatica mappings, the Sorter Transformation is used to sort data according to predetermined criteria, improving the effectiveness of downstream operations like joins and aggregations. Sorting is not relevant in the context of computer software data processing; it is not applicable in nature.
77. Describe how the case-sensitive sorting feature of the sorter operates.
Ans:
Case-sensitive sorting in Informatica’s Sorter Transformation treats capital and lowercase characters as separate entities. Because it sorts data according to ASCII values, capital letters are ordered before lowercase characters. When the desired order of the output depends on the case of the characters, this feature guarantees proper sorting.
78. How many different ways may a relational source definition be updated?
Ans:
- Manual Updates: By making changes directly to the database’s schema, tables, or columns, users can manually update a relational source definition.
- programmed Updates: To update the relational source definition, modifications can be programmed using SQL or other database-specific scripts.
- Automated Tools: To maintain efficiency and consistency when changing relational source definitions, specialized data management or integration tools may include automated functions.
79. What does the INFORMATICA Status Code mean?
Ans:
The result of a session or task execution in Informatica PowerCenter is indicated by the INFORMATICA Status Code. While non-zero numbers signal different problem or warning circumstances and help in detecting and debugging difficulties during ETL procedures, a status code of 0 normally indicates successful completion. Users may better comprehend the execution outcome and take relevant action for data integration processes by referencing the code.
80. What sets Informatica Analyst different from the other components of the Informatica platform?
Ans:
Within the Informatica platform, Informatica Analyst is a tool for metadata management, data profiling, and quality evaluation. It is distinct from other components since it is tailored exclusively for data analysts, both business and technical. It offers an easy-to-use interface for activities like data discovery, rule writing, and data quality monitoring, all without requiring a high level of technical expertise. Informatica Analyst is designed for team-based data quality and analysis duties, whereas PowerCenter is more focused on ETL procedures.
81. Describe the Informatica Analyst’s function in the process of integrating data.
Ans:
- Profiling Data: In-depth data profiling is done by Informatica Analysts to evaluate the connections, quality, and structure of datasets.
- Management of Data Quality: It makes it easier to create and maintain data quality rules, giving analysts the ability to specify and implement data quality requirements.
- Management of Metadata: An informatica analyst helps with data lineage and metadata management by offering insights into the data’s origins and transformations during the integration process.
82.Describe the main characteristics of the user interface and the Informatica Analyst tool.
Ans:
- Easy-to-use interface: For data specialists and business analysts, Informatica Analyst provides an intuitive user interface.
- Data Extraction: Strong data discovery capabilities in the program let users examine and comprehend the composition and organization of datasets.
- Defining and Observing Rules: Data integrity may be continuously assessed and improved by analysts through the definition and monitoring of data quality criteria.
83. What are the advantages of managing data quality using the Informatica Analyst tool?
Ans:
- Data Source Difference: A joiner transformation integrates data from two or more sources inside the same pipeline, whereas a lookup transformation fetches data from a different source based on a condition, frequently a key.
- Static vs. Dynamic: While a joiner executes static joining during mapping execution, a lookup is dynamic and retrieves data during runtime.
- Fallback technique: Joiners do not by default offer a fallback technique to deal with missing values, but lookups may.
84. How are data lineage and metadata management supported by Informatica Analyst?
Ans:
By gathering and classifying metadata about data items, transformations, and quality standards, Informatica Analyst facilitates metadata management. By offering insight into the movement and transformation of data, it promotes data lineage and improves comprehension and traceability throughout the integration process.
85. Describe the Informatica Analyst mapping creation and management procedure.
Ans:
- Making Maps: Mappings are made in Informatica Analyst through the definition of source and destination objects, transformation specifications, and data flow connections.
- Modification and Definition of Rules: To guarantee correct data integration and quality management, analysts utilize the tool to specify transformations and data quality guidelines inside mappings.
- Environment of Collaboration: Because of the collaborative nature of the process, business and IT teams may both participate to the creation and administration of the mapping, which helps to build a common understanding of data integration procedures.
86. In the context of Informatica Analyst, describe the importance of reference tables.
Ans:
Reference tables are essential to Informatica Analyst because they provide as a foundation for data validation and standardization, guaranteeing that data adheres to predetermined reference values and enhancing overall data quality. They play a crucial role in keeping data integration procedures accurate and consistent.
87. Describe a particular project where you used Informatica Analyst to effectively solve problems with data quality.
Ans:
In order to ensure a smooth transition and increased data correctness, I used Informatica Analyst to profile, detect, and fix data quality concerns in a data transfer project. The collaborative atmosphere of the platform made it easier for business and IT teams to communicate, which improved the quality of data throughout the company.
88. Talk about Informatica Analyst’s security features and access restrictions.
Ans:
Strong security capabilities in Informatica Analyst enable administrators to manage user access to projects, files, and mappings at several levels. Supporting role-based access restrictions, it makes sure users have the right permissions according to their responsibilities. Additionally, it connects with current authentication systems to improve security for quality control and data profiling. In order to track user actions and modifications, the program further offers audit trails.
89. In what ways does Informatica Analyst support the development and administration of data quality rules?
Ans:
Through the provision of an intuitive interface for the definition, administration, and enforcement of rules throughout the data integration process, Informatica Analyst facilitates the implementation of data quality rules. It enables business and IT teams to work together more easily, enabling them to jointly develop and implement data quality guidelines.
90. Describe the Informatica Analyst procedure for data profiling and data quality evaluation.
Ans:
Data quality evaluation in Informatica Analyst entails finding anomalies and evaluating the general health of the data, whereas data profiling is looking at the structure, trends, and quality of the data. By using the tool, analysts may do these activities quickly, learn more about the features of the data, and guarantee high-quality data integration.
91. What is the significance of data lineage in a data integration project, and how is it handled by Informatica Analyst?
Ans:
In order to provide traceability and comprehension of data flow, data lineage in data integration projects offers visibility into the source, transformation, and destination of data. Data lineage is managed by Informatica Analyst, which records and visualizes data flow and transformation, helps with impact analysis, debugging, and transparency throughout the data integration process.
92.What kind of integration exists between Informatica Analyst and other Informatica tools like Informatica PowerCenter?
Ans:
Informatica Analyst and Informatica PowerCenter interface flawlessly, enabling collaborative development, reuse of mappings, and sharing of information. By utilizing PowerCenter workflows and transformations, analysts may guarantee a unified environment for ETL and data profiling procedures. By streamlining data integration tasks, the integration encourages efficiency and uniformity throughout the Informatica platform.
93. Which of the many profiling options in Informatica Analyst would you utilize and under what circumstances?
Ans:
Reusable transformations in Informatica Analyst are created by first creating and setting up the transformations inside a mapping and then storing them as reusable objects that may be used in other mappings. By enabling analysts to design standardized transformations for consistent data processing, this enhances development efficiency.




