
Last updated on 11th Apr 2024| 7774
AWS Glue is a managed ETL service for simplifying data preparation and loading for analytics. It automates the process of discovering, cataloging, and transforming data from various sources, enabling users to extract, transform, and load data seamlessly. With Glue’s serverless architecture, users can easily create and manage metadata repositories, track data lineage, and scale processing tasks without managing infrastructure.
1. What is Amazon Glue, and how is it utilized?
Ans:
AWS Glue is a managed ETL solution that makes loading and preparing data for analysis easier. The laborious processes involved in data preparation, such as finding, classifying, cleaning, enriching, and moving data, are automated. The components of Glue include an ETL engine for data processing, a scheduler for scheduling ETL processes, and a data catalog for storing metadata. It has integrations with several AWS services, making cross-platform data transformation and transfer easy.
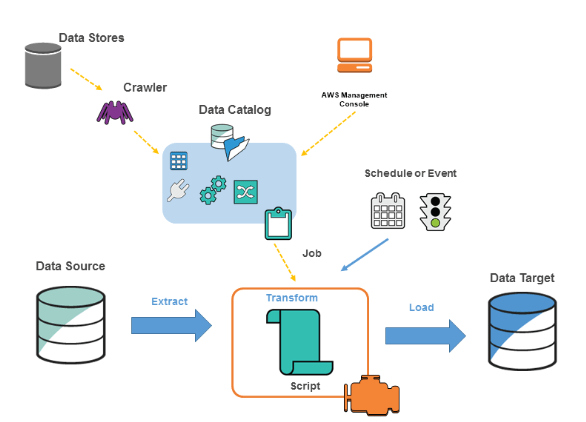
2. Describe the parts of Amazon Glue.
Ans:
- The three primary parts of AWS Glue are the Crawler, Job, and Data Catalog. The principal store for metadata is the Data Catalog.
- The business logic that handles the ETL task is called a job. Crawlers find and classify material and then add metadata to the material Catalog.
- When combined, these elements automate the ETL process, facilitating and expediting the process of preparing data for analytics.
3. Explain the difference between AWS Glue ETL and AWS Data Pipeline?
Ans:
| Feature | AWS Glue ETL | AWS Data Pipeline | |
| Focus |
Data preparation and transformation for analytics |
Orchestration and automation of data workflows | |
| Automation | Automated ETL code generation, data cataloging | Custom workflow definition and task scheduling | |
| Scope |
Specialized for ETL tasks within AWS ecosystem |
Orchestrates workflows across various services and environments | |
| Data Sources | Supports various sources like S3, RDS, Redshift | Compatible with a wide range of data sources including AWS services and on-premises resources | |
| Workflow Definition |
Automatic schema inference, predefined transformations |
Customizable workflows, task dependencies, and scheduling |
4. What is the AWS Glue Data Catalog, and why is it important?
Ans:
- The AWS Glue Data Catalog is a central repository to store structural and operational metadata for all your data assets, making it a critical component for data management in AWS.
- It provides a unified view of your data across AWS services, enabling seamless discovery, exploration, and analysis.
- The Data Catalog also supports compatibility with Apache Hive Metastore, allowing integration with existing ETL jobs and business intelligence tools.
5. How does AWS Glue provide security for data?
Ans:
- AWS Glue ensures data security through various AWS mechanisms, including IAM roles for fine-grained access control to resources, encryption at rest using AWS Key Management Service (KMS), and encryption in transit
- It integrates with Lake Formation for centralized data access and security management, allowing users to specify who has access to what data, ensuring compliance and data protection.
6. What types of data sources can AWS Glue connect to?
Ans:
AWS Glue can connect to various data sources, including Amazon S3, Amazon RDS, Amazon Redshift, and other databases supported through JDBC. It can access data in different formats (JSON, CSV, Parquet, etc.) and has built-in classifiers to recognize and categorize different data types. This flexibility makes AWS Glue a versatile tool for ETL processes across diverse data ecosystems.
7. What is a Glue Job Script, and how is it generated?
Ans:
- A Glue Job Script is a set of Python or Scala code generated by AWS Glue to perform specific ETL tasks.
- It’s created automatically by defining a source, transformation, and target in the AWS Glue console, or it can be written manually for complex transformations.
- The script leverages the power of Apache Spark for distributed data processing, enabling scalable and efficient data transformation.
8. How does AWS Glue integrate with other AWS services?
Ans:
AWS Glue integrates closely with a wide range of AWS services, enhancing its ETL capabilities. It can source data from Amazon S3, RDS, and Redshift, store metadata in the Glue Data Catalog, and output processed data to these storage services. Glue also works with AWS Lambda for event-driven ETL workflows and Amazon Athena for querying transformed data, providing a comprehensive and integrated data processing ecosystem.
9. What advantages does utilizing AWS Glue for ETL procedures offer?
Ans:
- AWS Glue simplifies the ETL process through automation, reducing the time and effort required for data preparation. It offers serverless execution, so you don’t need to provision or manage infrastructure.
- Glue’s integration with the AWS ecosystem allows seamless data movement and transformation across services. Its ability to handle schema evolution and versioning ensures data pipelines are resilient to changes.
- The pay-as-you-go pricing model can also lead to cost savings for many ETL workloads.
10. How is the is the distinction in AWS Glue between a batch job and a trigger?
Ans:
In AWS Glue, a Batch Job is a specific task configured to extract, transform, and load data. It represents a single unit of work that transforms data from a source to a target location. On the other hand, a Trigger in AWS Glue is a mechanism to start ETL jobs based on certain conditions or schedules. Triggers can be time-based, scheduled at specific intervals, or event-based, initiated by a particular event, such as completing another job. While Batch Jobs define the work to be done, Triggers determine when and under what conditions the jobs should be executed, allowing for automated and orchestrated ETL workflows.
11. How does AWS Glue integrate with Amazon Athena?
Ans:
- AWS Glue integrates closely with Amazon Athena, providing a seamless experience for querying and analyzing data.
- The AWS Glue Data Catalog is a central schema repository for both services. It allows Athena to directly query and analyze data using the tables and schemas defined in the Data Catalog. This integration eliminates the need for complex ETL scripts to prepare data for analysis.
- Users can point Athena to the relevant tables in the Data Catalog, enabling them to perform SQL queries directly on raw data stored in Amazon S3 or other supported data stores. This integration facilitates a serverless, highly scalable, and efficient analysis workflow, leveraging the strengths of both services.
12. Discuss the importance of Job Bookmarks in AWS Glue?
Ans:
Job Bookmarks in AWS Glue are a feature designed to handle incremental data loads, making ETL jobs more efficient and reliable. They track the progress of an ETL job, recording which data has already been processed. This enables ETL jobs to resume from where they left off in case of failure or to only process new or changed data since the last job run, avoiding the redundancy of processing the entire dataset each time. Job Bookmarks help optimize ETL processes, reduce computation time and costs, and ensure data consistency by accurately tracking changes over time. They are particularly useful in scenarios with large datasets or streaming data.
13. What are Glue Scripts, and how are they used in AWS Glue?
Ans:
- Glue Scripts are code (written in Python or Scala) generated by AWS Glue or written by the user, used to define the transformation logic of an ETL job.
- These scripts are executed on a managed Apache Spark environment within AWS Glue. Users can customize these scripts to perform specific data transformations, mappings, and enrichments not covered by the built-in transforms.
- The flexibility of Glue Scripts allows users to handle complex data transformation scenarios efficiently. AWS Glue also provides a visual interface to generate and edit these scripts, simplifying the process of script creation and making it accessible to users with different levels of programming expertise.
14. Explain the concept of Development Endpoints in AWS Glue.
Ans:
Development Endpoints in AWS Glue are interactive environments facilitating script development and testing directly in the AWS Glue interface. They bridge your data sources and the interactive programming environment for developing and debugging ETL scripts. Development Endpoints allow data engineers and developers to connect their favorite code editor or data science toolkits, such as Jupyter notebooks, to AWS Glue’s managed Spark environment for exploratory data analysis, script development, and testing.
15. How does AWS Glue simplify data integration tasks?
Ans:
- Because AWS Glue offers a serverless environment that automates a large portion of the labor-intensive ETL processes, it makes data integration jobs simpler. It eliminates manual scripting by finding, cataloging, and preparing data for analytics automatically. Thanks to AWS Glue, users don’t need to manage infrastructure to build and execute ETL processes with ease.
- Additionally, the service easily connects with other AWS services, providing a range of configurable options for data storage, querying, and analysis. The directed acyclic graph (DAG) design and Glue’s visual interface significantly simplify the creation and administration of ETL workflows, increasing the efficiency and intuitiveness of data integration activities.
16. What is the purpose of AWS Glue Studio?
Ans:
The creation, administration, and execution of ETL jobs in AWS Glue are made easier with the help of AWS Glue Studio, an integrated development environment (IDE). Users can visually build ETL workflows by dragging and dropping data sources, transformations, and targets using its graphical interface. For users who may not be comfortable with coding, this visual method makes it easier to establish data flows and transformations. To help with the quick development and iteration of ETL processes, AWS Glue Studio additionally provides templates and previews of data transformations.
17. How does AWS Glue handle data partitioning?
Ans:
- AWS Glue supports data partitioning to optimize ETL job performance and reduce costs by processing only the needed data. It can automatically recognize and work with data source and target partitions, leveraging the Hive partitioning style.
- When Glue Crawlers scan data sources, they can classify data into partitions based on attributes like date, allowing Glue ETL jobs to query and process data by specific partitions efficiently. This capability is crucial for managing large datasets, as it enables more targeted data processing and significantly speeds up ETL operations by minimizing the amount of data read and processed.
18. Can AWS Glue be used with non-AWS data sources?
Ans:
AWS Glue can connect to non-AWS data sources via JDBC connections, enabling it to work with databases hosted on-premises or in other cloud environments. This feature extends the flexibility of AWS Glue, allowing organizations to incorporate a wide range of data sources into their ETL workflows, regardless of where those sources are hosted. By supporting JDBC, AWS Glue ensures businesses can leverage its powerful ETL capabilities without migrating their entire data ecosystems to AWS, facilitating hybrid data integration strategies and making it a versatile tool for diverse data environments.
19. What is DynamicFrame in AWS Glue, and how does it differ from DataFrame?
Ans:
- A DynamicFrame is a data abstraction specific to AWS Glue, designed to handle schema flexibility and data transformation complexities more efficiently than a traditional Spark DataFrame.
- Unlike DataFrames, which require a known schema, DynamicFrames allow for schema discovery and evolution, making them ideal for dealing with semi-structured data or data sources with frequently changing schemas.
- DynamicFrames provide additional resilience in ETL processes by gracefully handling schema mismatches and errors. They offer a suite of operations and transformations specifically tailored for dynamic data and schema environments, enhancing the ease and efficiency of ETL tasks in AWS Glue.
20. Explain the significance of Transformations in AWS Glue.
Ans:
Transformations in AWS Glue are operations applied to data to convert it from one format or structure into another, typically as part of an ETL job. These include operations like mapping, filtering, joining, and aggregating data. Transformations are fundamental to the ETL process, enabling users to cleanse, enrich, and reformat data according to the requirements of their analytics applications. AWS Glue provides built-in transformations and the flexibility to script custom transformations, allowing users to handle various data processing tasks. This capability is critical for preparing raw data for meaningful analysis, ensuring that the data delivered to analytics and business intelligence tools is accurate, consistent, and in the right format for consumption.
21. What is the AWS Glue DataBrew, and how does it relate to AWS Glue?
Ans:
With the visual data preparation tool AWS Glue DataBrew, users can clean and normalize data without knowing how to write code. With its intuitive interface, users may select from more than 250 pre-built transformations to automate operations related to data preparation, including merging datasets, screening anomalies, and changing data formats. DataBrew is an interactive platform for exploring and preparing data for analysis or ETL processing, while AWS Glue is focused on ETL job orchestration and data cataloging.
22. How can you optimize AWS Glue ETL job performance?
Ans:
- Consider several strategies to optimize AWS Glue ETL job performance. First, the number of data processing units (DPUs) should be increased to enhance job execution speed, though this has cost implications. Utilize job bookmarks to avoid reprocessing unchanged data, significantly reducing job runtimes. Optimize your scripts by minimizing data shuffles and using pushdown predicates to filter data early.
- Leverage partitioned data sources and targets to reduce the amount of data processed. Also, the job memory and timeout settings should be adjusted to better match the job requirements. Lastly, continuously monitor job metrics and logs to identify bottlenecks and areas for improvement.
23. What are some common use cases for AWS Glue?
Ans:
AWS Glue supports a variety of data integration and ETL use cases. It’s commonly used for building data lakes and facilitating the storage, discovery, and analysis of large volumes of data from diverse sources. AWS Glue is also employed for data warehousing, enabling businesses to consolidate data into a central repository for advanced analytics. Another use case is log analytics, where AWS Glue can process and transform logs from various sources for monitoring and troubleshooting. Additionally, it supports data migration, helping businesses move data between data stores or into the cloud. Finally, AWS Glue aids in data preparation for machine learning, cleaning, and transforming data for training models.
24. Explain how AWS Glue works with streaming data.
Ans:
AWS Glue can process streaming data using AWS Glue streaming ETL jobs, enabling real-time data processing and analysis. These jobs continuously consume data from streaming sources like Amazon Kinesis Data Streams, Apache Kafka, and Amazon Managed Streaming for Apache Kafka (MSK). AWS Glue streaming ETL jobs clean, transform, and enrich streaming data before loading it into targets such as Amazon S3, Amazon RDS, Amazon Redshift, and more. This capability is crucial for use cases requiring immediate insights from data, such as real-time analytics, monitoring, and event detection. AWS Glue handles schema evolution in streaming data, ensuring that changes in data structure are managed smoothly without interrupting the data flow.
25. What is the purpose of connection in AWS Glue, and how do you use it?
Ans:
A connection in AWS Glue is a reusable configuration allowing ETL jobs, crawlers, and development endpoints to access data sources or targets. Connections store properties like connection type, physical server address, database name, and credentials securely. To use a connection, you define it in AWS Glue with the necessary configuration and then reference it in your ETL jobs or crawlers. This enables your AWS Glue resources to communicate with data sources such as JDBC databases, Amazon Redshift, or Amazon S3. Connections simplify data access management by centralizing and securing database credentials and connection details, reducing the need to hard-code this information in multiple places.
26. How do you handle errors and retries in AWS Glue jobs?
Ans:
- AWS Glue provides several mechanisms to handle errors and retries in ETL jobs. First, you can set job retries through the AWS Glue console or API, specifying the maximum number of times a job should retry after a failure. AWS Glue also supports custom error handling in your ETL scripts, allowing you to catch exceptions and implement your logic for retries or logging.
- AWS Glue’s built-in retry logic automatically attempts to rerun the job for transient errors. Additionally, monitoring tools like Amazon CloudWatch can be used to track job failures and send notifications, enabling quick response. Implementing checkpoints using job bookmarks can also minimize the impact of failures by allowing jobs to resume from the last successful state.
27. Describe how AWS Glue integrates with Amazon Redshift.
Ans:
AWS Glue integrates seamlessly with Amazon Redshift, providing a powerful combination of data warehousing and analytics. Through its ETL jobs, Glue can prepare and load data directly into Redshift tables, enabling scalable and efficient data transformation and loading processes. This integration supports batch and incremental data loads, optimizing data refreshes and availability in the data warehouse. AWS Glue can also use Redshift as a source, allowing for data extraction, which can then be transformed and loaded into other systems or analytics platforms. The Glue Data Catalog can serve as an external schema for Redshift Spectrum, allowing direct data querying in S3 and further enhancing analytical capabilities.
28. What are the benefits of using AWS Glue with Amazon S3?
Ans:
- Using AWS Glue with Amazon S3 offers several data processing and analytics benefits. AWS Glue’s ability to automatically discover, catalog, and process data stored in S3 simplifies the management of large data sets and data lakes.
- This integration allows serverless data transformation and loading, reducing the operational burden and automatically scaling to match the workload. AWS Glue’s ETL capabilities enable the transformation of raw data in S3 into formats suitable for analytics and reporting.
- Additionally, AWS Glue and S3 support a wide range of data analytics and machine learning applications, making extracting insights and adding value to business operations easier.
29. What role does the AWS Glue Data Catalog play in data management?
Ans:
- The AWS Glue Data Catalog is a central metadata repository that stores information about data sources, transforms, and targets, improving data discovery, management, and governance.
- It automates cataloging data across multiple stores, capturing metadata and schema information. This enables seamless integration with other AWS analytics services like Amazon Athena, Amazon Redshift, and Amazon EMR, facilitating easy access to data without manual data mapping.
- The Data Catalog also supports versioning, allowing for tracking schema changes over time.
30. How to secure data processed by AWS Glue?
Ans:
Data security in AWS Glue is achieved through multiple layers, including IAM roles for defining permissions, encryption for data at rest using keys managed by AWS Key Management Service (KMS), and data encryption in transit. You may establish fine-grained access restrictions with AWS Glue to ensure that only services and people with permission can access sensitive data and ETL operations. Can use network isolation mechanisms like VPC endpoints to prevent traffic between the VPC and AWS Glue from traversing the public internet. Logging and monitoring through AWS CloudTrail and Amazon CloudWatch provide visibility into access and operations, further enhancing security.
31. Explain the concept of Crawler in AWS Glue and its significance.
Ans:
Crawlers in AWS Glue are used to automate the discovery and cataloging of metadata from various data sources into the AWS Glue Data Catalog. By scanning data sources, crawlers infer schemas and store metadata, making the data searchable and queryable across AWS analytics services. This automatic schema recognition and cataloging significantly reduce the manual effort in data preparation and integration tasks. Crawlers can be scheduled to run periodically, ensuring the Data Catalog remains up-to-date as the underlying data evolves. This capability is crucial for dynamic data environments, enabling agile and informed decision-making.
32. What is the AWS Glue Schema Registry, and why is it important?
Ans:
- The AWS Glue Schema Registry allows you to manage and share schemas (your data structure) across different AWS services and applications, ensuring data format consistency and compatibility. It is particularly important in streaming data scenarios where ensuring producer and consumer applications agree on the schema is crucial to prevent data processing errors.
- The Schema Registry validates and controls schema evolution, allowing for safe changes without breaking downstream applications. This feature simplifies schema governance and enhances data integrity across microservices, data lakes, and stream-processing applications, making enforcing data quality and compatibility standards easier.
33. How does AWS Glue support job scheduling and monitoring?
Ans:
AWS Glue supports job scheduling through triggers, which can be set based on a schedule (time-based) or event (such as completing another job). This allows for flexible and automated ETL workflows that can operate without manual intervention, optimizing data processing pipelines for efficiency and timeliness. AWS Glue integrates with Amazon CloudWatch for monitoring, providing detailed metrics and logs for ETL jobs. You can set alarms in CloudWatch to notify you of job successes, failures, or performance issues, enabling proactive management and optimization of data processing tasks. This level of automation and visibility is crucial for maintaining reliable and efficient ETL workflows.
34. Can you explain the process of incremental data loading in AWS Glue?
Ans:
Incremental data loading in AWS Glue involves processing only the new or changed data since the last ETL job run instead of reprocessing the entire dataset. This is achieved using job bookmarks, which track the state of data processed across job runs. By enabling job bookmarks in your Glue ETL jobs, you can efficiently process datasets by skipping previously processed records, significantly reducing job runtime and resource usage.
35. What is Amazon Glue Studio, and how does it improve ETL application development?
Ans:
- AWS Glue Studio, an integrated development environment (IDE), makes creating, debugging, and deploying ETL tasks in AWS Glue easier. With its visually driven interface, users with varying levels of technical proficiency may create ETL processes by simply dragging and dropping components.
- Without requiring significant coding, Glue Studio facilitates the quick development, testing, and iteration of ETL scripts, improving the ETL development process. Additionally, it provides developers with visual task monitoring and debugging tools that make finding and fixing problems simple. This decreases the entrance barrier for difficult data integration operations and quickens the ETL development cycle.
36. How does AWS Glue handle schema evolution in data lakes?
Ans:
- AWS Glue handles schema evolution by automatically detecting changes in the source data schema and adapting the schema in the Data Catalog. When crawlers run and detect a new or altered schema, they update the corresponding metadata in the Data Catalog, ensuring that the schema reflects the current structure of the data.
- This feature supports seamless schema migration and evolution without manual intervention, enabling downstream applications to access the most up-to-date schema.
- For applications sensitive to schema changes, AWS Glue Schema Registry can manage schema versions and ensure compatibility, providing a robust solution for managing schema evolution in data lakes.
37. How does AWS Glue DataBrew fit into the process of preparing data?
Ans:
- With the help of AWS Glue DataBrew, scientists and data analysts can visually prepare data and clean and normalize it without writing any code. With a straightforward point-and-click interface, users can carry out a variety of data preparation operations, including merging datasets, filtering anomalies, and changing data formats.
- DataBrew’s integration with the AWS Glue Data Catalog allows easy access to datasets and smooth interaction with other AWS services for additional analysis or machine learning.
- This tool helps users prepare data for analytics and machine learning projects more quickly and easily, boosting productivity and opening the door to more advanced data analysis.
38. What are DynamicFrames in AWS Glue, and how do they differ from DataFrames?
Ans:
DynamicFrames are a data structure provided by AWS Glue, specifically designed to handle the complexities of semi-structured data and schema evolution, which are common in big data and ETL workflows. Unlike DataFrames, which require a known schema upfront, DynamicFrames do not enforce a schema when created, allowing them to manage data with evolving schemas more gracefully. They offer various operations to manipulate data, similar to DataFrames, but with additional flexibility to handle schema mismatches and ambiguities. This makes DynamicFrames particularly useful in ETL processes involving data sources with less structured or constantly changing data formats, enhancing the robustness and scalability of data integration tasks.
39. How can AWS Glue be used for cost optimization in data processing workflows?
Ans:
AWS Glue can optimize costs in data processing workflows through several mechanisms. First, automating data discovery, preparation, and loading tasks reduces the need for manual intervention and the resources associated with these activities. Using serverless architecture, AWS Glue automatically scales resources up and down to match the workload, ensuring you pay only for the compute resources used during job execution. Efficient data processing is further achieved by leveraging job bookmarks for incremental data loads, minimizing the volume of data processed. Optimizing the number of DPUs and managing job concurrency can significantly reduce costs without compromising performance. These strategies collectively enable efficient, cost-effective data processing.
40. Explain the importance of AWS Glue Workflows in orchestrating ETL jobs.
Ans:
AWS Glue Workflows provides a managed orchestration service for complex ETL jobs, allowing you to design and execute a sequence of data processing steps visually. Workflows manage dependencies between tasks, ensuring that each step is implemented in the correct order and only when its prerequisites are met. This simplifies the management of multi-stage ETL pipelines, where the output of one job might serve as the input for another. By automating the coordination of these tasks, workflows eliminate manual scheduling and monitoring, improving efficiency and reliability. They also provide a centralized overview of the ETL process, making debugging and optimizing data processing pipelines easier.

Get JOB AWS Glue Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. Discuss the scalability benefits of using AWS Glue for large-scale data processing.
Ans:
- AWS Glue offers significant scalability benefits for large-scale data processing by leveraging a serverless architecture. This means it automatically allocates and manages the compute resources needed to execute ETL jobs, scaling up to handle large datasets and complex processing tasks without manual intervention.
- The service manages the allocation of Data Processing Units (DPUs), which measure processing power, dynamically adjusting to the workload’s demands. This capability ensures that data processing is efficient and cost-effective, as you only pay for the resources used.
42. How does AWS Glue integrate with other AWS services for a complete data analytics solution?
Ans:
AWS Glue seamlessly integrates with a wide range of AWS services, creating a comprehensive data analytics ecosystem. It connects with Amazon S3 for data storage, Amazon RDS and Amazon Redshift for data warehousing, and Amazon Athena for SQL queries directly against data in S3. AWS Glue’s Data Catalog is a central metadata repository, which these services query to locate and understand data. For analytics and machine learning, integration with Amazon EMR and Amazon SageMaker allows for complex processing and model training. This tight integration across services simplifies data workflows, enabling efficient data discovery, transformation, and analysis within AWS.
43. What mechanisms does AWS Glue provide for error handling in ETL jobs?
Ans:
- AWS Glue provides several mechanisms to handle errors within ETL jobs, ensuring robust data processing. It includes try-catch blocks within the job script to manage exceptions, allowing for custom error handling and logging.
- AWS Glue also supports configuring retry policies and timeout actions for jobs, which can be tailored to manage job failures and partial successes automatically.
- Additionally, CloudWatch can be used to monitor job execution, sending alerts for job failures or anomalies. This comprehensive error handling and monitoring framework enables developers to quickly identify, diagnose, and resolve issues, maintaining high data processing reliability.
44. Can AWS Glue be used for real-time data processing?
Ans:
While AWS Glue is primarily designed for batch processing, it can be integrated with AWS services that support real-time data processing. For instance, AWS Glue can catalog data streams from Amazon Kinesis or Amazon MSK, making the stream data available for querying in services like Amazon Athena. You typically use AWS Lambda or Kinesis Data Analytics for real-time processing, followed by AWS Glue for batch processing tasks such as ETL and data cataloging. This approach allows for a hybrid model, combining real-time processing with the powerful ETL capabilities of AWS Glue for comprehensive data analytics solutions.
45. Explain how AWS Glue optimizes job performance automatically.
Ans:
AWS Glue optimizes job performance through several automated features. It dynamically allocates Data Processing Units (DPUs) based on the job’s complexity and data volume, ensuring efficient resource utilization. AWS Glue also optimizes ETL job scripts by pushing down predicates and projections to the data source, reducing the amount of data transferred and processed. It also provides automatic partitioning, improving query performance and reducing job run times. AWS Glue’s job bookmark feature further optimizes performance by processing only new or changed data, preventing redundant computations. These features collectively ensure that AWS Glue ETL jobs are executed efficiently, saving time and resources.
46. What are some best practices for optimizing costs with AWS Glue?
Ans:
- Consider minimizing the number of DPUs allocated to each job by tuning the job’s resource requirements and using job bookmarks to process only incremental data.
- Schedule jobs during off-peak hours, leveraging AWS Glue’s ability to manage and scale resources dynamically.
- Regularly review and clean up the AWS Glue Data Catalog to avoid unnecessary storage costs.
- Use the AWS Cost Management tools to monitor and analyze your AWS Glue usage and expenses.
Employing these strategies helps manage and reduce the costs associated with running ETL jobs and maintaining a data catalog in AWS Glue.
47. How can AWS Glue support a multi-tenant architecture?
Ans:
- AWS Glue can support a multi-tenant architecture by leveraging AWS account and IAM policies to segregate data and control access.
- Each tenant’s data can be stored in separate S3 buckets or databases, with Glue Crawlers and ETL jobs configured per tenant to process their data independently.
- You can ensure that each tenant can only access their resources and data using resource-level permissions and IAM roles.
- Additionally, AWS Glue’s Data Catalog can be partitioned by tenant using database and table naming conventions or prefixes to isolate further and manage data access securely.
This approach allows for multi-tenancy, ensuring data isolation and security across tenants.
48. Describe the process of transforming data with AWS Glue.
Ans:
Transforming data with AWS Glue involves creating ETL (Extract, Transform, Load) jobs that automatically prepare and load data for analytics. First, AWS Glue Crawlers discover data sources and create or update tables in the Glue Data Catalog. Next, developers create ETL jobs in the Glue Console or Glue Studio, selecting sources, transforms, and targets. AWS Glue provides built-in transforms for data cleaning, joining, filtering, and more. Custom code can also be written in Python or Scala for specific transformations. Once configured, the job is run, transforming the data as specified and loading it into the target data store. This process automates data preparation, making it ready for analysis or reporting.
49. What is the role of AWS Glue in building data lakes?
Ans:
AWS Glue plays a critical role in building and managing data lakes on AWS. It automates the discovery, cataloging, and preparation of data from various sources for analysis. Glue Crawlers scan data sources, extracting schema and metadata to populate the Glue Data Catalog, creating a searchable and queryable central repository. This enables seamless integration with analytics and machine learning services. AWS Glue’s ETL capabilities allow for the transformation and enrichment of data, ensuring it is in the right format and quality for analysis.
50. How does AWS Glue ensure data security and compliance?
Ans:
- AWS Glue provides robust security features that are aligned with AWS’s standard security model. Its interaction with AWS Identity and Access Management (IAM), which regulates access to resources and procedures, enables fine-grained permissions.
- Data processed by AWS Glue jobs is encrypted in transit and at rest, utilizing AWS Key Management Service (KMS) for managing encryption keys. Additionally, AWS Glue complies with various certifications and standards, ensuring adherence to data protection regulations.
- Integration with AWS CloudTrail, which logs activities made by a user, role, or AWS service, makes auditing easier.
51. Explain the concept of Job Bookmarks in AWS Glue.
Ans:
Job Bookmarks in AWS Glue are a feature that helps manage state information, allowing ETL jobs to understand what data has already been processed and what needs processing. This prevents the duplication of work by enabling incremental loads rather than reprocessing the entire dataset each time a job runs. Job Bookmarks track the data processed after each job run by maintaining state information about the files or data partitions. This is particularly useful in ETL workflows where new data is continuously added to data sources, as it ensures efficiency and reduces processing time and cost.
52. What is the AWS Glue Schema Registry, and how does it benefit data streaming applications?
Ans:
The AWS Glue Schema Registry is a feature that allows you to manage schema versions for data streaming applications. It provides a central repository for schema definitions, enabling compatibility checks and schema evolution for applications that consume streaming data. By using the Schema Registry, producers and consumers of data streams can ensure that they are using compatible schemas, preventing issues related to schema mismatches. This is particularly beneficial in complex, real-time applications where data formats may evolve, ensuring data integrity and reducing the need for manual schema reconciliation.
53. How does partitioning improve performance in AWS Glue?
Ans:
- Partitioning data improves performance in AWS Glue by reducing the amount of data scanned during ETL jobs and queries, leading to faster execution and lower costs.
- When data is partitioned based on certain keys (e.g., date, region), AWS Glue can efficiently process and query only the relevant partitions instead of the entire dataset.
- This targeted approach to data processing enhances job speed and efficiency, particularly for large datasets.
- Partitioning is also integrated with the AWS Glue Data Catalog, allowing seamless access to partitioned data across AWS analytics services.
54. Describe the benefits of using Glue DataBrew for data exploration and preparation.
Ans:
With the visual data preparation tool AWS Glue DataBrew, users can clean and normalize data without knowing how to write code. It provides over 250 pre-built transformations to automate data preparation tasks, such as filtering anomalies, converting data types, and handling missing values. DataBrew directly integrates with the AWS Glue Data Catalog, making it easy to discover and access datasets. Its visual interface and point-and-click functionality make it accessible to users with varying technical expertise, significantly accelerating the data preparation process and enabling faster insights.
55. How can AWS Glue handle complex transformations and custom code?
Ans:
AWS Glue supports complex transformations and custom code through its flexible scripting environment. Users can write custom scripts in Python or Scala, leveraging the full power of these programming languages and the Apache Spark framework. This allows for the implementation of complex data processing logic beyond built-in transformations. Additionally, AWS Glue supports custom Python libraries and external jars, enabling the integration of third-party libraries or custom-built utilities into ETL jobs. This flexibility ensures that virtually any data transformation requirement can be met.
56. What strategies can be employed to manage and optimize AWS Glue Data Catalog costs?
Ans:
- To manage and optimize AWS Glue Data Catalog costs, consider regularly cleaning up unused tables and databases, as the Data Catalog charges are based on the number of metadata requests and storage.
- Utilize crawlers efficiently by scheduling them to run only as needed, avoiding excessive metadata updates.
- Also, consolidating smaller datasets into larger ones can reduce the number of objects in the Data Catalog, lowering costs. Implementing fine-grained IAM policies to control access to the Data Catalog helps prevent unauthorized or accidental expensive operations.
- Lastly, using AWS Cost Explorer to monitor and analyze Glue-related expenses can identify opportunities for further cost optimization.
57. Explain the role of AWS Glue in a data warehousing solution.
Ans:
Amazon Glue is essential to any data warehousing system because it automates the extraction, transformation, and loading (ETL) of data from several sources into the data warehouse. Glue crawlers can automatically discover and catalog data from different sources, making it easily accessible for ETL processes. Its serverless architecture allows for scalable and efficient data processing, transforming data into formats suitable for analysis and reporting. AWS Glue integrates seamlessly with Amazon Redshift, enabling optimized data loads into the warehouse.
58. How does AWS Glue support streaming ETL processes?
Ans:
AWS Glue supports streaming ETL processes through its ability to connect with streaming data sources like Amazon Kinesis and Apache Kafka. It can continuously process streaming data, apply real-time transformations, and load the transformed data into targets such as Amazon S3, Amazon RDS, or Amazon Redshift. This capability allows for real-time data processing, enabling timely insights and actions based on the most current data.
59. What is the purpose of the AWS Glue DataBrew visual interface, and who benefits from it?
Ans:
- AWS Glue DataBrew’s visual interface is designed to simplify data preparation without requiring advanced programming skills. It benefits data analysts, data scientists, and business analysts by providing a user-friendly environment for cleaning, normalizing, and transforming data through a point-and-click interface.
- Users can visually explore datasets, apply transformations, and automate data preparation workflows, significantly reducing the time and effort required compared to manual coding. This facilitates preparing data for analytics and machine learning projects for non-technical users.
60. How does AWS Glue’s DynamicFrame differ from Apache Spark’s DataFrame?
Ans:
AWS Glue’s DynamicFrame is an abstraction built on top of Apache Spark’s DataFrame, designed to simplify ETL operations and handle schema evolution and data inconsistencies more gracefully. Because they enable data operations without requiring a defined schema, DynamicFrames offer even more flexibility. This is especially helpful when working with semi-structured data or data sources whose schema may change over time, in contrast to Spark DataFrames, which require a predefined schema. DynamicFrames also offers enhanced capabilities for handling complex nested data structures and cleansing.

61. Can AWS Glue be used with databases not hosted on AWS?
Ans:
AWS Glue can connect to databases not hosted on AWS, including on-premises databases or those hosted on other cloud platforms, as long as they are accessible via JDBC. AWS Glue’s flexibility in connecting to various data sources allows organizations to integrate and transform data across different environments. This capability is crucial for hybrid or multi-cloud data architectures, enabling seamless ETL processes that consolidate data into AWS for analysis and storage. It underscores AWS Glue’s role as a versatile data integration service that supports diverse data ecosystem needs.
62. What are some of the limitations of AWS Glue?
Ans:
- While AWS Glue is a powerful ETL service, it has limitations, including the cold start time for ETL jobs, which may lead to higher execution times for small or infrequent jobs. Another limitation is the cost, especially for high-volume or complex data processing tasks, which can escalate quickly due to the pricing model based on DPUs and job run time.
- Additionally, there’s a learning curve associated with understanding and optimizing Glue scripts and configurations for efficient data processing. Finally, while AWS Glue supports many data sources and targets, compatibility or performance with specific or legacy systems may be limited.
63. How to monitor and log AWS Glue job performance?
Ans:
Integration with AWS CloudWatch and AWS CloudTrail can achieve monitoring and logging for AWS Glue jobs. CloudWatch provides metrics and customizable dashboards to monitor the operational performance and health of Glue jobs, including job run time, success rates, and DPU usage. CloudTrail captures detailed logs of API calls related to AWS Glue, offering insights into job modifications, executions, and user activities. Together, these services enable comprehensive monitoring and logging, facilitating performance optimization, auditing, and troubleshooting of ETL processes.
64. What role does machine learning play in AWS Glue, and how is it implemented?
Ans:
Machine learning in AWS Glue is implemented through AWS Glue ML Transforms, which provides capabilities to perform data matching, deduplication, and merging using machine learning. These transforms allow users to clean and prepare data more effectively by automatically identifying and resolving data quality issues without manual intervention. By leveraging machine learning models, Glue ML Transforms improve the accuracy and efficiency of ETL processes, especially in scenarios involving large datasets with complex or inconsistent data.
65. How do you manage and scale AWS Glue resources effectively?
Ans:
- Managing and scaling AWS Glue resources effectively involves monitoring your ETL job metrics to understand resource utilization and performance bottlenecks.
- Use auto-scaling features to dynamically adjust the number of DPUs based on the workload, ensuring that your jobs run efficiently without over-provisioning. Implement job bookmarks to minimize redundant data processing.
- Organize your ETL scripts and workflows for reusability and maintainability. Lastly, consider using AWS Glue Studio to visually manage and optimize your ETL jobs, making adjustments as your data volume and processing needs evolve.
66. How does AWS Glue handle schema changes in the data?
Ans:
AWS Glue can handle schema changes using schema evolution. When data is processed, and schema changes are detected (like new columns), Glue automatically updates the schema in the Data Catalog. This feature allows downstream applications to read the most current data without manual intervention, ensuring that ETL jobs continue running smoothly despite data structure changes.
67. How does AWS Glue handle schema changes in the data source?
Ans:
AWS Glue can adapt to changes in the source data schema using schema versioning and schema evolution. When Glue crawlers detect a change in the underlying data source, they can create a new version of the table schema in the Glue Data Catalog. This allows ETL jobs to process data using the updated schema without manual intervention. Additionally, for certain file types like Parquet, Glue supports schema evolution directly during job execution, allowing new columns to be added and read seamlessly. This capability ensures that ETL processes remain robust and flexible even as data evolves.
68. What are the security features available in AWS Glue?
Ans:
- AWS Glue provides comprehensive security features to protect your data. Its integration with AWS Identity and Access Management (IAM) allows for finer access control over resources and activities.
- Data processed by Glue can be encrypted at rest using AWS Key Management Service (KMS) keys and in transit using SSL.
- Glue also supports network isolation by allowing ETL jobs and development endpoints to run in a virtual private cloud (VPC). Additionally, Glue’s Data Catalog upholds table- and column-level security, guaranteeing that individuals only access confidential data with permission.
69. Can AWS Glue process streaming data?
Ans:
Yes, streaming data can be processed by AWS Glue streaming ETL jobs. These jobs can prepare and continually load streaming data into data stores. Glue streaming ETL processes support data sources like Amazon Kinesis Data Streams, Apache Kafka, and Amazon Managed Streaming for Apache Kafka (MSK). This feature makes real-time data processing and analysis possible, enabling prompt corporate decision-making based on the most recent data and swift responses to new information.
70. What is AWS Glue Data Catalog, and how does it work?
Ans:
- The AWS Glue Data Catalog stores all of your data assets’ structural and operational metadata in one place. It serves as a single metadata repository for all ETL tasks in AWS Glue, simplifying data management, querying, and searching across AWS services.
- When crawlers operate, the Data Catalog automatically gathers information from data sources and arranges it into databases and tables.
- ETL processes, Amazon Athena, Amazon Redshift Spectrum, and other AWS services may then efficiently query and process data using this metadata.
71. How do you handle large datasets in AWS Glue to ensure job efficiency?
Ans:
Handling large datasets in AWS Glue efficiently requires optimizing your ETL jobs and resource utilization. First, partition your data in Amazon S3 to improve read and write efficiency. Use columnar formats like Parquet or ORC for storage, optimized for fast retrieval and query performance. Scale your DPUs appropriately to match the job’s complexity and data volume. Optimize your scripts to minimize data shuffling across the network. Finally, incremental data processing should be considered, using job bookmarks to process only new or changed data, reducing job run times and costs.
72. Explain the difference between AWS Glue Crawlers and Classifiers.
Ans:
AWS Glue Crawlers are used to scan various data sources to automatically infer schemas and create or update tables in the Glue Data Catalog. They identify the underlying structure of your data, such as column names and data types, and classify the data based on recognized patterns. Classifiers, on the other hand, are used by crawlers to interpret the format of your data. They are rules or algorithms that help crawlers understand the schema of your data, whether it’s in CSV, JSON, XML, or another format. Classifiers guide crawlers in accurately categorizing and understanding the data structure they encounter.
73. What are the purposes of Glue DataBrew recipes?
Ans:
- Users can develop a set of data transformation instructions called Glue DataBrew recipes to clean and normalize data without writing code.
- Every recipe is applied to the datasets in a series of distinct processes, such as filtering anomalies, switching data types, or merging columns.
- These recipes are used in DataBrew projects to automate the data preparation process, and they may be applied to more datasets.
- Data scientists and analysts may quickly share and duplicate data transformation procedures using recipes, guaranteeing efficiency and consistency when preparing data for analytics or machine learning applications.
74. When is it better to use AWS Batch or AWS Glue?
Ans:
With AWS Batch, you can easily and effectively complete any kind of batch computing job on AWS, regardless of the nature of the work. You also have total control and visibility into the computing resources that are being used in your account. It also generates and manages these resources. Amazon Glue is a fully managed ETL solution that operates in the serverless Apache Spark environment and handles all your ETL processes.
75. What are Development Endpoints?
Ans:
Development Endpoints in AWS Glue are interactive environments that allow developers to debug, test, and develop their ETL scripts in a live AWS environment. These endpoints provide a way to connect to AWS Glue using notebook interfaces such as Jupyter, enabling developers to interactively edit, execute, and debug their Glue scripts before deploying them as production jobs. Development Endpoints support direct access to AWS resources, offer the flexibility to install additional libraries and dependencies and facilitate iterative development and testing of ETL scripts, improving efficiency and reducing the development lifecycle.
76. What are AWS Tags in AWS Glue?
Ans:
- AWS Tags in AWS Glue are key-value pairs associated with Glue resources such as jobs, triggers, and crawlers. Tags enable users to organize, manage, and identify resources within AWS Glue and across AWS services.
- They are particularly useful for cost allocation reports, where they help break down costs by project, department, or custom categorization, facilitating better resource management and budget tracking.
- Tags also support access control, where IAM policies can leverage tags to define permissions, enhancing the security and governance of Glue resources.
77. Does AWS Glue use EMR?
Ans:
AWS Glue does not internally use Amazon EMR (Elastic MapReduce) but offers similar capabilities for ETL (Extract, Transform, Load) workloads in a fully managed, serverless environment. While EMR provides a managed Hadoop framework for processing big data in a more hands-on, customizable manner, AWS Glue abstracts the infrastructure management. It delivers a managed ETL service that automatically scales resources. However, AWS Glue and EMR can be complementary; data processed by AWS Glue can be analyzed in EMR, or AWS Glue can catalog data stored in an EMR cluster.
78. Does AWS Glue have a no-code interface for visual ETL?
Ans:
AWS Glue provides a no-code interface for visual ETL through AWS Glue Studio, a graphical interface allowing users to create, run, and monitor ETL jobs without writing code. With Glue Studio, users can visually design their ETL workflows by dragging and dropping data sources, transforms, and targets onto a canvas, configuring them through a graphical UI. This no-code approach makes ETL accessible to users without deep programming skills, accelerates the development of ETL jobs, and simplifies the data preparation, transformation, and loading process.
79. How does AWS Glue update Duplicating Data?
Ans:
- AWS Glue can handle duplicating data using its job bookmarks feature, which tracks data processed by ETL jobs to avoid reprocessing the same data in subsequent runs. When dealing with sources that may contain duplicate records, AWS Glue’s transformation capabilities can be used to identify and manage duplicates.
- For example, you can use the “Deduplicate” transform to remove duplicate records based on specified keys. Additionally, custom Python or Scala scripts within Glue jobs can be written for more complex duplication criteria to implement specific logic for identifying and updating or removing duplicate entries, ensuring that the data in your target datastore is unique and up-to-date.
80. What are the considerations for choosing AWS Glue over other ETL tools?
Ans:
Choosing AWS Glue over other ETL tools involves evaluating factors such as integration with the AWS ecosystem, scalability, and ease of use. AWS Glue’s serverless nature eliminates the need for infrastructure management, making it highly scalable and cost-effective for processing large datasets. Its seamless integration with AWS data storage, analytics, and machine learning services offers a unified platform for data processing workflows. The visual interface and automatic schema discovery simplify ETL job creation and maintenance. However, considerations should also include potential limitations like supported data formats, customization needs, and specific performance requirements.
81. How does AWS Glue handle job failures and retries?
Ans:
- AWS Glue handles job failures by automatically retrying jobs based on the retry policy defined in the job configuration. The maximum number of tries and the interval between tries can be specified.
- AWS Glue offers comprehensive task run logs in Amazon CloudWatch for further in-depth investigation, allowing you to identify and comprehend the primary cause of failure.
- Additionally, you can set up notifications for job state changes, including failures, using Amazon SNS or AWS Lambda to trigger custom alerting or remediation processes. This ensures that you can promptly address issues and maintain the reliability of your ETL workflows.
82. Can AWS Glue be used for data migration tasks? How?
Ans:
AWS Glue can be used for data migration tasks, facilitating the movement of data between different data stores within the AWS ecosystem or from on-premises databases to AWS. To perform data migration, define AWS Glue ETL jobs that extract data from the source, transform it as needed, and load it into the target data store. AWS Glue supports various data sources and targets, including Amazon S3, Amazon RDS, Amazon Redshift, and others, making it versatile for migration scenarios. Its scalable, serverless architecture can handle large volumes of data, while the AWS Glue Data Catalog ensures a smooth schema mapping and transformation process during migration.
83. How does versioning work in the AWS Glue Data Catalog?
Ans:
- Versioning in the AWS Glue Data Catalog ensures that changes to table definitions and schemas are tracked over time. When a table’s schema is modified, AWS Glue retains the previous version, enabling users to view and manage historical schema versions.
- This feature is crucial for data governance and auditing. It allows teams to understand how data structures evolve and ensures that ETL jobs and queries can be adapted or rolled back to align with schema changes.
- Versioning supports data reliability and reproducibility by providing a clear history of schema modifications, facilitating easier debugging and compliance checks.
84. Can you explain the concept of DynamicFrames in AWS Glue?
Ans:
DynamicFrames are a data structure provided by AWS Glue designed to simplify the processing of semi-structured data and data with evolving schemas. Unlike traditional data frames, DynamicFrames are more flexible, allowing for operations on data without requiring a predefined schema. They are particularly useful for handling data sources where the schema might change over time or is not initially known. DynamicFrames support a variety of transformations and can easily convert to and from Apache Spark DataFrames for operations that require specific schema constraints. This flexibility makes them ideal for ETL jobs involving data lakes and varying formats.
85. What strategies can you use to reduce costs in AWS Glue?
Ans:
To reduce costs in AWS Glue, start by optimizing the allocation of DPUs (Data Processing Units) to match the job’s complexity and execution time, ensuring you’re not over-provisioning resources. Utilize job bookmarks to avoid reprocessing unchanged data, reducing job run times and resource usage. Schedule Glue crawlers and jobs efficiently, avoiding unnecessary runs. Consider converting your data into more efficient formats like Parquet or ORC to speed up processing times. Finally, monitor and analyze your AWS Glue usage and costs using AWS Cost Explorer and AWS Glue metrics in Amazon CloudWatch to identify and eliminate inefficiencies.
86. How can AWS Glue facilitate machine learning workflows?
Ans:
- AWS Glue can facilitate machine learning workflows by preparing and transforming data for machine learning models. It can clean, normalize, and enrich datasets, making them suitable for training and inference.
- AWS Glue can also automate the data loading process into Amazon SageMaker, AWS’s machine learning service, streamlining the data pipeline from raw data to model training.
- Additionally, AWS Glue DataBrew provides a visual interface for data scientists to easily preprocess data without writing code, further accelerating the preparation phase of machine learning projects.
- This seamless integration across AWS services simplifies creating and deploying machine learning workflows.
87. Explain partitioning in AWS Glue and its benefits.
Ans:
Partitioning in AWS Glue is a technique to divide data into subsets based on certain columns, such as date, region, or any other key business dimension. This is particularly useful for organizing data stored in Amazon S3 in a way that makes it more manageable and query-efficient. Partitioning benefits include faster data processing and query performance, as jobs and queries can scan only relevant partitions instead of the entire dataset, reducing the amount of data read and processed. This leads to lower computing costs and quicker insights. AWS Glue can automatically detect and create partitions in the Data Catalog, simplifying data management and access.
88. How to debug and troubleshoot AWS Glue ETL jobs?
Ans:
Debugging and troubleshooting AWS Glue ETL jobs involve several steps. First, review the job run history and login to the AWS Glue Console for error messages and warnings. AWS CloudWatch Logs provide detailed execution logs, which can help identify the specific stage where the job failed. Utilizing CloudWatch metrics for monitoring job performance metrics like execution time and memory usage can also highlight potential bottlenecks. Testing your ETL scripts locally using a development endpoint can provide a more interactive debugging environment for more complex issues. Additionally, consider enabling job bookmarks to effectively manage job state and data processing continuity.
89. How does AWS Glue handle incremental data loads?
Ans:
AWS Glue supports incremental data loads using job bookmarks, which track the data already processed in previous job runs. This feature enables Glue ETL jobs to process only the new or changed data since the last run, reducing execution time and resources. Job bookmarks can be used with various data sources, including Amazon S3, relational databases, and more, making it efficient to maintain up-to-date data in your target datastore without reprocessing the entire dataset each time.
90. Can AWS Glue integrate with other AWS services for data analytics?
Ans:
- AWS Glue integrates seamlessly with a wide range of AWS services for data analytics, enhancing its capability as a comprehensive data processing and analysis solution.
- It can directly integrate with Amazon Redshift for data warehousing, Amazon Athena for serverless querying, and Amazon QuickSight for business intelligence.
- AWS Glue also works with Amazon S3 for data storage, Amazon RDS, and Amazon DynamoDB for database services, enabling a fully managed, scalable analytics ecosystem within AWS.




