Last updated on 15th Feb 2024| 2250
HBase, a component within the Apache Hadoop ecosystem, is a distributed and scalable database system tailored for managing extensive volumes of structured data across multiple commodity hardware nodes. Engineered for real-time applications, it ensures swift access to data with low latency. Embracing a column-oriented storage approach, HBase incorporates features like automatic sharding, replication, and fault tolerance, rendering it a favored solution for big data scenarios demanding high throughput and scalability.
1. Enumerate the essential HBase critical structures.
Ans:
The row key and Column key are HBase’s primary and most basic vital structures. They are the two main critical structures in HBase. Both can communicate meaning by using the data they store or by using their sorting order. These keys will be used in the ensuing sections to address frequent issues encountered during the design of storage systems. Optimizing data retrieval and guaranteeing optimal performance in HBase require an understanding of how to use row keys and column keys.
2. When might one employ HBase?
Ans:
- Because it can process many operations per second on big data sets, HBase is employed when random read and write operations are required.
- Strong data consistency is provided via HBase.
- On top of a cluster of commodity hardware, it can manage huge tables with billions of rows and millions of columns.
3. How is the get() method used?
Ans:
- The data is read from the table using the get() method. Unlike Hive, HBase uses a database for real-time operations instead of MapReduce jobs.
- HBase partitions the tables and then further divides them into column families.
- Hive is a NoSQL key/value database for Hadoop, whereas HBase is a SQL-like engine used for MapReduce tasks.
4. Explain the distinction between HBase and Hive?
Ans:
| Feature | HBase | Hive |
|---|---|---|
| Purpose | NoSQL distributed database for real-time, random access to large-scale structured data. | Data warehousing infrastructure for running SQL-like queries on large datasets stored in HDFS. |
| Data Model | Column-oriented storage model. | Row-oriented storage model. |
| Query Language | NoSQL (e.g., HBase API). | SQL-like (HiveQL). |
| Latency | Low-latency access to individual records. | Higher latency due to batch processing. |
| Schema | Dynamic schema, schema-on-read. | Static schema, schema-on-write. |
5. Describe the HBase data model.
Ans:
- Column Qualifiers: Within a column family, each column can have multiple qualifiers. This allows for a dynamic schema where new columns can be added without predefined structure.
- Tables: HBase stores data in tables, which are similar to relational databases but more flexible. Each table is identified by a unique name.
- Rows: Data in an HBase table is organized into rows, identified by a unique row key. Row keys are sorted lexicographically, enabling efficient data retrieval.
- Columns: Each row can have multiple columns, organized into column families. Column families group related data together and are stored physically together, which optimizes read and write operations.
6. Enumerate the kinds of filters that Apache HBase offers.
Ans:
- Filters rows based on a specified prefix of the row key, allowing for efficient lookups of related rows.
- Filters columns within a column family based on a specified prefix of the column qualifier.
- Retrieves cells that fall within a specified range of column qualifiers, useful for limiting data.
- Filters rows based on the value of a specific column, allowing for conditional queries.
- Filters rows by allowing multiple prefixes for column qualifiers.
7. Describe the use of the HColumnDescriptor class.
Ans:
The HColumnDescriptor class serves as a crucial container for vital details regarding a column family within HBase. It encapsulates essential attributes like the count of versions, configurations for compression, and various parameters necessary during table creation or column addition. By encapsulating these details, it provides a comprehensive blueprint for managing column families efficiently within the HBase architecture, ensuring optimal performance and data organization.
8. What is Thrift, and how does it facilitate cross-language service development?
Ans:
Thrift is a remote procedure call (RPC) framework developed by Facebook for scalable cross-language services development. It enables efficient communication between different programming languages, facilitating seamless integration across diverse systems. By defining data types and service interfaces in a platform-independent manner, Thrift streamlines the process of building robust and interoperable distributed systems.
9. Define HBase Nagios, and how does it support monitoring HBase clusters?
Ans:
HBase Nagios is a monitoring solution that integrates Nagios with HBase to track the health and performance of HBase clusters. It performs health checks on key components, collects vital metrics like read/write latencies, and sends alerts when thresholds are exceeded. Additionally, it provides customizable checks and visual dashboards, enabling administrators to proactively manage and optimize their HBase environments. By facilitating early detection of issues, HBase Nagios helps maintain system reliability and ensures optimal performance across the cluster.
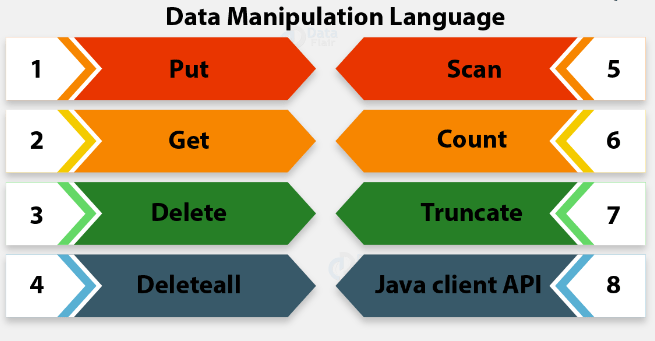
10. What are the HBase instructions for manipulating data?
Ans:
- Put: Used to insert or update data in a table. It adds a value to a specified column within a row.
- Get: Retrieves data from a specific row, allowing users to access one or more columns.
- Delete: Removes specific cells or entire rows from a table, effectively managing data retention.
- Scan: Retrieves a range of rows from a table, optionally applying filters to narrow down results.
- Increment: Increases the value of a specified column atomically, which is useful for counters.
- CheckAndPut: Performs a update based on the current value of a cell, ensuring data integrity.
- CheckAndDelete: Similar to CheckAndPut but used to conditionally delete cells based on their current value.
11. In HBase, what code is used to establish a connection?
Ans:
To establish an HBase connection, use the code below:
- import org.apache.hadoop.hbase.client.Connection;
- import org.apache.hadoop.hbase.client.ConnectionFactory;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.hbase.HBaseConfiguration;
- Configuration config = HBaseConfiguration.create();
- Connection connection = ConnectionFactory.createConnection(config);
This code initializes the HBase configuration and creates a connection using the ‘ConnectionFactory’.
12. Explain what “REST” means in HBase.
Ans:
The acronym REST stands for Representational State Transfer, which provides semantics so that a protocol may be used universally to efficiently identify distant resources. Additionally, it supports a number of message types, making it easy for a client application to communicate with the server. Because RESTful APIs are stateless by design, scalability is improved and every client request is met with all the necessary data by the server. This design promotes interoperability by allowing various applications to interact easily over the web.
13. What occurs in HBase when a delete command is issued?
Ans:
In HBase, a delete command for a cell, column, or column family is not immediately erased. A gravestone marker has been added. In addition to regular data, a tombstone is a type of designated data that is stored. This tombstone hides all of the erased data. The actual data is removed during a significant compaction. HBase combines and recommits a region’s smaller HFiles to a new HFile during considerable Compaction. The same column families are grouped in the new HFile throughout this process.
14. What kind of tombstone markers are there in HBase?
Ans:
- Version Marker: Designates for deletion only one iteration of a column.
- Column Marker: Designates all versions of the column as being marked for deletion.
- Family Marker: Designates all of the columns in the column family as being marked for deletion.
15. What is the fundamental idea behind HBase Fsck?
Ans:
The HBase Fsck class or hack is the sole way to use the tool hack that comes with the database. It is used to examine region consistency, troubleshoot table integrity issues, and fix all HBase-related issues. There are two modes of operation for HBase Fsck:
- A read-only inconsistency identifying the mode
- A read-write repair mode with multiple phases
16. Which command launches the HBase Shell program?
Ans:
The command to launch the HBase Shell program is hbase shell. This command is executed in the terminal or command prompt where HBase is installed. Once run, it opens an interactive shell that allows users to execute various HBase commands for managing tables, inserting data, and performing queries. The HBase Shell provides a convenient interface for interacting with the HBase database. For developers and administrators to carry out tasks and keep an eye on the health of their HBase clusters, this tool is indispensable.
17. How is HBase structured?
Ans:
HBase is designed as a column-oriented, distributed NoSQL database that is integrated into the Hadoop framework. It arranges information into tables with distinct row keys identifying each division. Each table consists of column families, grouping related columns together for efficient storage and retrieval. Within each column family, columns can be dynamically added, allowing for a flexible schema. HBase supports multiple versions of data for each cell, enabling time-based access.
18. What does MSLAB stand for in total?
Ans:
MSLAB stands for MemStoreLAB, which is a memory allocation mechanism within Apache HBase. It optimizes memory usage by allocating contiguous memory blocks for MemStore data structures. This helps reduce memory fragmentation and improves performance by reducing garbage collection overhead. MSLAB is a critical component for enhancing the efficiency and scalability of HBase’s write operations.
19. What is the syntax for the described command?
Ans:
- The basic command is hbase fsck.
- An optional table name can be specified in brackets to check a specific table, e.g., hbase fsck <table>.
- The –verbose option can be added for more detailed output, making it hbase fsck <table> –verbose.
- If no table is specified, the command checks all tables in the HBase cluster.
- This command helps identify inconsistencies and health issues within the HBase data.
20. How can HBase Fsck be automated ?
Ans:
- The hbase fsck command can be scheduled to run at regular intervals using cron jobs.
- Scripts can be developed to execute HBase Fsck programmatically and log the results or send alerts for any detected issues.
- Integration with monitoring tools like Nagios enables real-time notifications based on the results of the Fsck checks.
- Orchestration frameworks such as Apache Oozie can be utilized to manage and schedule the execution of HBase Fsck as part of a larger workflow.
21. How does the PrefixFilter work?
Ans:
- HBase’s PrefixFilter is made to extract rows when the row key starts with a certain prefix.
- Applying it during a scan operation effectively reduces the quantity of data that needs to be processed by restricting the results to only those that match the prefix.
- The amount of rows scanned and returned is reduced by this filter, which enhances query performance.
- It runs in memory, thus even when working with big datasets, quick access speeds are maintained.
- Applications can swiftly retrieve pertinent data by using PrefixFilter instead of having to go through irrelevant rows.
22. Why does HBase utilize the shutdown command?
Ans:
HBase utilizes the shutdown command to safely stop services running on a cluster, ensuring data integrity by allowing ongoing operations to complete and writes to be flushed to disk. This command facilitates a graceful exit for region servers and the master server, helping to maintain cluster stability by properly closing connections and releasing resources. By preventing forced shutdowns that could lead to inconsistencies, the shutdown command is crucial for preserving the health and reliability of the HBase environment during maintenance or upgrades.
23. Why is the tools command in HBase essential to use?
Ans:
The tools command in HBase lists the HBase surgery tools. HBase’s design allows for access to and scaling of petabytes of data over thousands of machines. Massive data sets can also be accessed online using HBase, thanks to the scalability of Amazon S3 and the elasticity of Amazon EC2. Because of these features, HBase is the best option for big data applications that need effective data management across distributed systems and high availability.
24. What is ZooKeeper used for?
Ans:
- The ZooKeeper manages the configuration data and communication between region servers and clients, it notifies server failures so that corrective action can be taken.
- Furthermore, distributed synchronization is offered. Via session communication, it aids in the upkeep of the server state within the cluster.
- Zookeeper receives a continuous heartbeat from each Region Server and HMaster Server at regular intervals, allowing it to determine whether servers are online and operational.
25. In HBase, define catalogue tables.
Ans:
In HBase, catalogue tables are responsible for keeping the metadata up to date. An HBase table consists of multiple regions, which are the fundamental units of work. These regions manage a contiguous range of rows and are essential for distributing data across the cluster. The map-reduce framework uses regions as splits for parallel processing, enabling efficient data processing.
26. What is S3?
Ans:
For effective data management, Amazon Web Services (AWS) offers S3, or Simple Storage Service, a scalable object storage solution that is frequently used in conjunction with HBase.It is perfect for handling enormous datasets in a dispersed setting because of its capacity to store and retrieve tremendous amounts of data over the internet. S3’s high availability and resilience can be leveraged by users to enable easy cloud data retrieval through integration with HBase.
27. How does HBase handle large datasets?
Ans:
- HBase has a distributed design to manage massive datasets, allowing it to scale horizontally over several nodes and effectively handle growing data volumes.
- Tables are divided into smaller, more manageable parts called regions, which can then be spread among different RegionServers to provide better performance and a balanced load.
- Data can be reliably stored throughout a distributed file system by utilizing HDFS for storage, which offers high availability and fault tolerance.
- Features like data compression and bloom filters help optimize storage and retrieval performance, making HBase suitable for handling large-scale applications.
28. In HBase, which filter takes the page size as a parameter?
Ans:
The PageFilter in HBase accepts the page size as an input. By limiting the number of cells that are returned during a scan operation to a predetermined number, this filter essentially permits pagination of results. Users may easily manage and traverse huge datasets by controlling the number of entries returned in each query by adjusting the page size.It is especially helpful in applications, including user interfaces and data dashboards, where it is crucial to display data in digestible bits.
29. List the various operating modes for HBase.
Ans:
- Standalone Mode: Runs HBase without Hadoop, suitable for development and testing.
- Pseudo-Distributed Mode: Operates HBase with Hadoop in a single-node cluster for development and small-scale deployments.
- Fully-Distributed Mode: Deploys HBase across multiple nodes in a cluster, suitable for production environments.
- Backup Mode: Temporarily suspends writes to HBase tables for backup and restore operations.
- Read-only Mode: Restricts HBase to read-only access, useful for maintenance or troubleshooting tasks.
30. What is the use of truncate command?
Ans:
- To rapidly remove every piece of data from a table in HBase while preserving the table structure, use the truncate command.
- The command essentially clears the table by dropping and recreating it, which minimizes the overhead associated with individual deletes.
- This is particularly useful for scenarios where large volumes of data need to be refreshed or when testing with new datasets.
- Compared to a full delete, truncating a table can help recover storage space more effectively.
31. How can joins be implemented in an HBase database?
Ans:
Terabytes of data can be processed in a scalable manner by HBase using MapReduce jobs. Although joins aren’t supported directly, join queries can be used to retrieve data from HBase tables. The best use case for HBase is to store non-relational data that can be retrieved through the HBase API. Can insert, remove, and query data saved in HBase using familiar SQL syntax by using Apache Phoenix, which is frequently used as an SQL layer on top of HBase.
32. How Is the Write Failure Handled by HBase?
Ans:
Large distributed systems frequently experience failures, and HBase is not an anomaly. In the event that the server housing an unflushed MemStore crashes. The information that was stored in memory but did not yet persist is gone. HBase prevents such from happening by writing to the WALL before the write completion. Every server is included in the group. This mechanism enhances data durability and consistency, ensuring that even in the case of a failure, the most recent writes can be recovered.
33. From which three locations is data reconciled during HBase reading before returning the value?
Ans:
- The Scanner searches the Block cache for the Row cell before reading the data. Here are all of the key-value pairs that have been read recently.
- Since the MemStore is the write cache memory, if the Scanner is unable to locate the needed result, it proceeds there. There, it looks for the most current files that haven’t been dumped into HFile yet.
- Lastly, it will load the data from the HFile using block cache and bloom filters.
34. Is Data versioning comprehensible?
Ans:
The term “Data versioning” makes sense because it describes the process of maintaining several versions of data records across time. This enables users to monitor changes, retrieve earlier states when necessary, and access historical data. In databases like HBase, versioning is implemented at the cell level, giving users the ability to choose how many versions of a given data to retain. Because it facilitates auditing, enhances data management, and allows for time-based searches, this functionality is helpful in a variety of applications.
35. Describe Row Key.
Ans:
In HBase, the RowKey serves as a unique identifier assigned to each row in a table. It is used to logically group related cells together, ensuring that all cells with the same RowKey are stored on the same server. This facilitates efficient access and retrieval of data associated with a particular RowKey. Internally, the RowKey is represented as a byte array, which provides flexibility in terms of the types of data that can be used as RowKeys, such as strings, numbers, or composite keys.
36. What are the strongest arguments in favour of using Hbase as the DBMS?
Ans:
- One of Hbase’s strongest features is its scalability in terms of modules and all other factors.
- Users can ensure that a large number of tables are served in a brief amount of time.
- It offers extensive support for all CRUD functions.
- It can handle the same tasks with ease and can store more data.
- Users can maintain a constant pace because the stores are column-oriented and have a huge number of rows and columns available.
37. What is the Block Cache, and how does it function?
Ans:
- To enhance read efficiency, HBase’s Block Cache is an in-memory caching technique that keeps track of frequently requested data blocks.
- It stores HFile blocks, which may be quickly retrieved without reading from disk because they include rows or portions of rows.
- HBase checks the Block Cache first when a read request is made; if the data is there, it is provided straight from memory, greatly reducing access times.
- The cache uses a LRU eviction policy to manage memory efficiently, ensuring that the most frequently accessed data remains available.
- By reducing disk I/O, the Block Cache enhances overall system performance, particularly for read-heavy workloads.
38. Describe a few situations in which plan to use HBase.
Ans:
This method is usually chosen when a whole database needs to be moved. When handling data activities that are too large for a single individual to handle, Hbase may be taken into consideration. Additionally, Hbase is a good option to consider when a lot of functionality, such as transaction maintenance and inner joins, are needed frequently. Big data applications and online analytics are two examples of applications that benefit greatly from HBase’s ability to handle and retrieve enormous datasets quickly.
39. What ways can HBase be considered to provide high availability?
Ans:
- Its distributed architecture replicates data across region servers for redundancy, reducing data loss risk.
- HBase uses ZooKeeper for cluster management and quick region reassignment during server failures.
- The write-ahead log (WAL) records all writes before they are applied, facilitating recovery in case of crashes.
- HBase supports online schema changes and maintenance, reducing downtime during updates.
- Automatic failover and load balancing enhance performance and accessibility, even under heavy workloads.
40. What is decorating Filters?
Ans:
HBase’s decorating filters enable the blending of various filtering parameters to enhance the quality of data retrieval outcomes. These filters increase flexibility for complex inquiries by allowing users to build a chain where one filter is applied to the outcomes of another, as opposed to depending just on a single filter. This functionality allows developers to tailor their queries to meet specific needs while maintaining efficient performance, making it especially useful for applications with diverse data access patterns.

Get JOB HBase Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. List out few key Hbase components that data managers might find helpful?
Ans:
- HMaster: It handles region assignment, schema management, and load balancing.
- RegionServer: The server that stores data and serves read and write requests.
- Regions: Subdivisions of HBase tables. Each region contains a set of rows and is managed by a RegionServer.
- HFiles: The underlying file format used by HBase to store data on HDFS.
- Write Ahead Log (WAL): A log file that records changes before they are applied to the HFiles.
42. Is it possible to remove a call straight from the HBase?
Ans:
In HBase, direct deletion of cells often doesn’t immediately remove the data. Instead, when a cell is deleted, it becomes invisible and is marked with a tombstone marker. These tombstone markers indicate that the data has been logically deleted but still physically exists on the server. Over time, HBase performs compactions, which are processes that clean up and permanently remove these tombstone markers along with the actual deleted data.
43. What is the significance of data management?
Ans:
- In general, businesses must handle large amounts of data.
- When work is organized or managed, it is simple to use or deploy.
- If a task is well-managed, it reduces the total amount of time needed to complete it.
- With well-organized or controlled data, users may effortlessly stay up to date at all times.
- Numerous additional factors also come into play, allowing the consumers to guarantee error-free results.
44. Describe the collection of tables in the Hbase.
Ans:
A protracted arrangement of rows and columns makes up these structures, which are similar to conventional databases. Each table contains rows that represent records and columns that represent attributes of these records. Every table has a unique element known as the primary key, which uniquely identifies each record in the table. This primary key ensures that each row can be individually accessed and managed.
45. What prerequisites must be met to maximize the benefits of HBase?
Ans:
- A well-configured Hadoop Distributed File System (HDFS) as HBase relies on it for storage.
- Sufficient hardware resources, including ample RAM and CPU, for handling high throughput.
- Properly tuned HBase configuration parameters based on workload characteristics.
- Regular maintenance and monitoring to ensure optimal performance and health of the HBase cluster.
46. Is Hbase a method that is independent of the OS?
Ans:
HBase is designed to be platform-independent, as it is built on Java, allowing it to run on any operating system that supports a compatible Java Runtime Environment. However, it typically operates within the Hadoop ecosystem, which is predominantly deployed on Linux due to better performance, stability, and support. While it can technically run on other operating systems, practical implementations usually favor Linux environments for optimal results. This focus on Linux ensures better compatibility with Hadoop’s distributed architecture and related tools.
47. Where in HBase is the compression feature applicable?
Ans:
- HBase supports various compression algorithms for HFiles, which store the actual data on disk, reducing storage space and improving read performance.
- Data in the MemStore, which is the in-memory buffer for writes, can also be compressed before being flushed to HFiles, optimizing memory usage.
- Compression settings can be configured at the column family level, allowing different compression techniques for different types of data based on usage patterns.
- Each region can have its own compression settings, enabling tailored compression strategies for specific data regions within a table.
- During compaction, HBase can apply compression to newly merged HFiles, ensuring that the storage efficiency is maintained as data is updated or deleted over time.
48. List some of the main distinctions between Relational databases and HBase?
Ans:
- The primary distinction is that, unlike relational databases, Hbase is not built on schema.
- Relational databases do not have this feature, whereas Hbase allows for simple automated partitioning.
- Compared to relational databases, Hbase has a more significant number of tables.
- Hbase is a column-oriented data store, whereas it is a row-oriented data store.
49. How to ensure that the cells in an HBase are logically grouped?
Ans:
In HBase, cells can be logically grouped by placing them inside the same row key. Cells can be logically grouped together by preserving consistent row keys for similar data, which makes retrieval and processing processes more efficient. Utilizing appropriate row key designs aligned with the data access patterns further enhances the effectiveness of logical cell grouping in HBase. This design approach streamlines application data management and retrieval procedures while also increasing performance.
50. Describe the process of removing a row from HBase?
Ans:
The best thing about Hbase is that anything written in RAM is automatically saved to disk. There are several that stay the same, barring Compaction. These compactions can be divided into major and minor categories. Small files are restricted from being deleted, but significant compactions can destroy the files with ease. Over time, this automated method maximizes storage efficiency while guaranteeing data permanence.
51. How to export data from HBase to other systems?
Ans:
- Data from HBase can be exported to other platforms in a variety of ways.
- One widely used approach is to use the HBase Export Tool, which allows bulk data exporting to HDFS in a pre-designated format such as CSV or SequenceFiles.
- Another method that provides SQL-like capabilities for HBase data querying and can assist with data export to other file systems or databases is the use of Apache Phoenix.
- Data from HBase can be read by Apache Spark and written to a number of different systems and formats, such as databases, cloud storage, and HDFS.
- Applications can be developed to read data from HBase and transfer it programmatically to other systems for real-time requirements.
52. Is it possible for users to change the block size of the column family?
Ans:
Users can change the block size of a column family in HBase. This can be achieved by altering the column family’s configuration using the `HColumnDescriptor` class. By adjusting the `BLOCKSIZE` parameter, users can modify the block size to suit their requirements. After making the necessary changes, users can update the column family’s configuration to apply the new block size.
53. What is the use of YCSB?
Ans:
The Yahoo! Cloud Serving Benchmark, or YCSB, is a framework for assessing how well cloud databases and data management systems operate. It gives customers a consistent way to evaluate multiple database systems under varying workloads, enabling them to mimic diverse access patterns including mixed, read-heavy, or write-heavy scenarios. This facilitates the discovery of performance bottlenecks, configuration optimization, and application compatibility assurance.
54. What are the various operational commands that are available at the record and table levels?
Ans:
Table-Level Commands:-
- Create Table: Creates a new table with specified column families.
- Delete Table: Deletes an existing table.
- Describe Table: Displays the schema and configurations of a table.
- List Tables: Lists all the tables in the HBase namespace.
- Alter Table: Modifies the schema or properties of an existing table.
Record-Level Commands:-
- Put: Inserts or updates a record in a table.
- Get: Retrieves a specific record based on the row key.
- Scan: Reads a range of rows from a table.
- Delete: Removes a specific column or row from a table.
- Check and Put: Conditionally inserts a record if the specified value matches.
55. What does “region server” mean?
Ans:
- Databases typically have enormous amounts of data to manage.
- It’s only sometimes feasible or required for every piece of data to be connected to a single server.
- There is a central controller, and it should also identify the server on which specific data is stored.
- Also regarded as a file on the system that enables users to see the related defined server names.
56. What is the Hbase’s standalone mode?
Ans:
- This mode can be activated when users don’t require Hbase to access HDFS.
- It essentially functions as Hbase, and users are generally allowed to use it whenever they choose.
- When the user activates this option, Hbase uses a file system instead of HDFS.
- This mode can save a significant amount of time when completing crucial chores.
- During this mode, different temporal constraints on the data can also be applied or removed.
57. What is a shell of Hbase?
Ans:
A command-line interface tool for working with HBase databases is the HBase shell. It offers commands for managing activities including as making tables, adding information, and running queries. Instead of writing bespoke code, users can control HBase by simply executing commands in the shell. Because of its simplicity, database management is made easier for developers and administrators by enabling speedy query prototyping and testing. The shell’s scripting and batch operation capabilities make it more useful for intricate data management jobs.
58. Describe a few salient characteristics of Apache Hbase.
Ans:
Every table on the cluster is dispersed via regions; Hbase can be utilized for a variety of jobs requiring modular or linear scaling. Hbase’s regions automatically expand and split in response to data growth. It supports multiple bloom filters. Block cache usage is fully permitted. When data requirements are complex, Hbase can handle volume query optimization. These features make HBase an ideal choice for applications with large-scale data needs and varying access patterns.
59. What are the top five HBase filters?
Ans:
In Hbase, there are five filters:
- Filtering by Page
- Filter by Family
- Column Separator
- The Row Filter
- All-Inclusive Stop Screen
60. Can users iteratively go through the rows?
Ans:
It is feasible, yes. It is not permitted to complete the same work in reverse order, though. This is due to the fact that column values are typically saved on a disk and that their length needs to be specified in full. Additionally, the value-related bytes must be written after it. These values must be stored one more time to complete this task in reverse order, which may cause compatibility issues and strain the Hbase’s memory.

61. Why is Hbase a database without a schema?
Ans:
- This is so that users won’t have to stress over defining the information before the time.
- Define the column family name. As a result, the Hbase database lacks a schema.
- Developers are not required to follow a schema model to add new data, but they would have to adhere to a rigid schema model in a standard relational database paradigm.
62. How does one go about writing data to Hbase?
Ans:
Any time there is a data modification or change, the information is initially transferred to a commit log, also called WAL. Following this, the information is kept in the memory. Should the data be above the specified threshold, it is stored on the disk in the form of a Hfile. Users can proceed with the saved data and are free to dispose of the commit logs.
63. What does TTL mean in Hbase?
Ans:
- In essence, it is a helpful data retention strategy. It is feasible to grow capacity.
- Unlike RDBMSs, HBase does not require data to fit into a strict schema, which makes it perfect for storing unstructured or semi-structured data.
- HBase can hold billions of rows and millions of columns of data in a table-like manner.
- Row values can be physically distributed over various cluster nodes by grouping columns into “column families.”
64. Without utilizing HBase, what command allows users to retrieve files directly?
Ans:
- Without the need for HBase, users can retrieve files directly from HDFS using the hdfs dfs -get command.
- By moving files from HDFS to the local file system, this operation makes it easy to access data stored in Hadoop.
- The syntax is, for instance, hdfs dfs -get /path/to/hdfs/file /local/path.
- This functionality is essential for managing and retrieving data in a Hadoop environment without utilizing HBase.
65. How is Apache HBase used?
Ans:
When require random, real-time read/write access to big data, Apache HBase is utilized. The purpose of this project is to host huge tables on top of clusters of commodity hardware, with billions of rows and millions of columns. Based on Google Bigtable, Apache HBase is a distributed, versioned, non-relational database that is free and open source Chang et al. present A Distributed Storage System for Structured Data.
66. What characteristics does Apache HBase have?
Ans:
- Scalability both linearly and modularly.
- Rigid consistency in both reading and writing.
- Adaptable and automated table sharding
- Support for automatic failover between RegionServers.
- Bloom filters and block cache for instantaneous queries.
67. How to upgrade from HBase 0.94 to HBase 0.96+ for Maven-managed projects?
Ans:
The project switched to a modular framework in HBase 0.96. Instead of depending solely on one JAR, change the dependencies in project to rely on the HBase-client module or another module as needed. Depending on whatever version of HBase are targeting, can model Maven dependency after one of the following. “Upgrading from 0.96.x to 0.98.x,” and 3.5, “Upgrading from 0.94.x to 0.96.x.”. Maven Dependency for org.apache.hbase.
68. How should an HBase schema be designed?
Ans:
Admin in the Java API or “The Apache HBase Shell” can be used to create or alter HBase schemas.
Disabling tables is necessary for making changes to ColumnFamily, such as:
- 1, 2, 3, 4, 5, 6, 7, 8, and 9Administrator admin = new Admin(conf);
- Configuration config = HBaseConfiguration.create();
- ColumnFamily added: String table = “myTable”;
- admin.disableTable(table); HColumnDescriptor cf1 =…;
- admin.addColumn(table, cf1); //
- admin.modifyColumn(table, cf2); // altering the current ColumnFamily
- admin.enableTable(table); HColumnDescriptor cf2 =…
69. What Does Apache HBase’s Table Hierarchy Mean?
Ans:
- One or two tables Families in Columns Columns Rows >> Cellular
- One or more column families are established as high-level categories for storing data pertaining to an entry in the table during its creation.
- Table. Because HBase is “column-oriented,” all table entries, or rows, have their column family data stored together.
- Multiple columns can be written at the same time as the data is recorded for a specific combination.
- As a result, two rows in an HBase table need to share column families rather than identical columns.
70. How can HBase cluster be troubleshooted?
Ans:
- The master log should always come first (TODO: Which lines?). Usually, it simply prints the same lines repeatedly.
- If not, something needs to be fixed. Should get some results for the exceptions seeing from Google or search-hadoop.com.
- In Apache HBase, errors seldom occur by themselves. Instead, hundreds of exceptions and stack traces from various locations are typically the result of a problem.
- The easiest method to tackle this kind of issue is to walk the log up to the beginning.
71. How Do HBase and Cassandra Compare?
Ans:
- HBase and Cassandra are both distributed NoSQL databases.
- HBase is part of the Hadoop ecosystem, while Cassandra is standalone.
- HBase is consistent and relies on Hadoop’s HDFS, while Cassandra is highly available and uses its own distributed architecture.
- Cassandra offers a decentralized architecture with eventual consistency, while HBase follows a centralized architecture with strong consistency.
72. Describe NoSql.
Ans:
Among the “NoSQL” database types is Apache HBase. The name “NoSQL” refers to any database that isn’t an RDBMS and doesn’t use SQL as its primary access language. There are numerous varieties of NoSQL databases, including: HBase is a distributed database, while BerkeleyDB is an example of a local NoSQL database. HBase is actually more of a “Data Store” than a “Database” technically since it lacks several of the capabilities of an RDBMS, like typed columns, secondary indexes, triggers, and sophisticated query languages.
73. Which Hadoop version is required to operate HBase?
Ans:
Release Number for HBase Hadoop Release Number: 0.16.x, 0.16.x, 0.17.x, 0.18.x, 0.18.x, 0.19.x, 0.20.x, 0.20.x, 0.90.4 (stable as of right now) Hadoop releases are available here. Since the most recent version of Hadoop will have the most bug patches, we advise utilizing it whenever possible. Hadoop-0.18.x can be used with HBase-0.2.x. In order to use Hadoop-0.18.x, must recompile Hadoop-0.18.x, delete the Hadoop-0.17.x jars from HBase, and replace them with the jars from Hadoop-0.18.x. HBase-0.2.x ships with Hadoop-0.17.x.
74. Describe how the HBase and RDBMS data models differ from one another.
Ans:
- HBase is a schema-less data model, whereas RDBMS is a schema-based database.
- While HBase offers automated partitioning,
- RDBMS does not support partitioning internally.
- HBase stores denormalized data,
- while RDBMS stores normalized data.
75. What does a delete marking mean?
Ans:
In databases, a delete marking signifies that a record or entry has been marked for deletion but may still exist in the system. This approach is often used for soft deletes, where data isn’t immediately removed but rather flagged for later removal or archiving. Delete markings facilitate data integrity and allow for potential recovery or audit trails without permanently erasing the data.
76. What are Hbase’s Principal Elements?
Ans:
- Tables: Organize data into rows and columns.
- Rows: Key-based storage units containing column families.
- Column Families: Group columns together for efficient storage.
- Cells: Intersection of rows and columns storing data values.
77. Define HBase Bloom Filter.
Ans:
The sole method to determine whether a row key is a row key Typically, the only method to determine whether a row key is present in a store file is to look up the start row key for each block in the store file using the file’s block index. By acting as an in-memory data structure, bloom filters limit the number of files that need to be read from the disk to just those that are likely to contain that row.
78. What occurs if a row is deleted?
Ans:
When command data is destroyed, it is not actually erased from the file system; instead, a marker is set to make it invisible. Compaction causes physical loss. Three distinct markers—Column, Version, and Family Delete Markers—indicate the removal of a column, a column family, and a version of a column, respectively. These markers ensure data integrity during deletion processes while allowing for potential recovery until compaction occurs.
79. What kinds of grave markings are there in HBase that can be removed?
Ans:
Here are three distinct kinds of tombstone markers that can be removed from HBase:
- Family Delete Marker: This marker designates every column within a family of columns.
- Version Delete Marker: This marker designates a column’s single version.
- Column Delete Marker: This marker designates every iteration inside a column.
80. What is the proper relationship between an Hfile and its owner in an HBase?
Ans:
In my opinion, the proper relationship between an HFile and its owner in HBase is one of ownership and control. The HFile belongs to the HBase system, managed by the HBase storage layer. The owner, typically the HBase RegionServer, maintains control over the HFile for efficient read and write operations, ensuring data integrity and consistency within the HBase ecosystem.
81. What are the main features of HBase, and when should one utilize it?
Ans:
- Scalability: HBase is designed to handle large-scale datasets, making it suitable for applications with massive data storage requirements.
- Fault Tolerance: It offers built-in fault tolerance mechanisms, ensuring data integrity and availability even in the event of node failures.
- Low-Latency Operations: HBase provides low-latency reads and writes, making it ideal for applications requiring real-time data access and processing.
- Linear Scalability: As the dataset grows, HBase scales linearly by adding more nodes, enabling seamless expansion without sacrificing performance.
82. How is HBase evolving with the rise of cloud computing?
Ans:
- With HBase’s enhanced scalability and flexibility, enterprises can easily deploy resources as needed, keeping up with the rapid expansion of cloud computing.
- It can be set up on cloud platforms as a managed service, which lowers operational overhead and simplifies maintenance.
- Cost-effective and effective data management is made possible by integration with cloud storage options, and increased data security features meet privacy and compliance standards.
83. Discuss the impact of emerging technologies on HBase development.
Ans:
The development of HBase has been greatly impacted by emerging technologies, which have improved its functionality and allowed it to integrate with contemporary data processing frameworks. Better scalability and flexibility brought about by the growth of cloud computing enable HBase to take advantage of managed services and cloud storage options for better resource management. Advancements in tools like Apache Spark and Flink have improved HBase data utility for dynamic applications through real-time analytics and complex event processing.
84. What do WAL and HLog signify in HBase?
Ans:
- Write Ahead Log, or WAL, is a log format similar to MySQL’s BIN log.
- It logs every modification made to the data.
- The standard in-memory sequence file for Hadoop that keeps track of the Hockey store is called HLog.
- When a server fails, or data is lost, WAL and HLog are lifesavers.
- In the event that the RegionServer malfunctions or crashes, WAL files ensure that replaying the data changes is possible.
85. List some scenarios in which Hbase can be applied.
Ans:
- Time Series Data Storage: Storing large volumes of timestamped data like sensor readings, logs, or financial transactions where fast read/write access is crucial.
- Ad-hoc Analytics: Supporting real-time or near-real-time analytical queries on massive datasets, such as user behavior analysis or IoT data analysis.
- Hierarchical Data Storage: Storing hierarchical or nested data structures like JSON or XML efficiently, commonly used in social media feeds or product catalogs.
- NoSQL Database for Web Applications: Utilizing HBase as a scalable NoSQL database backend for web applications, handling user profiles, session management, or content management.
86. Define row keys and column families.
Ans:
In HBase, column families make up the fundamental storage units. These are specified when a table is created and kept collectively on the disk, which subsequently permits the use of features like compression. A row key allows cells to be arranged logically. It comes before the combined key, enabling the application to specify the sort order. This allows for the saving of all the cells on the same server that have the same row key. This organization enhances data retrieval efficiency and optimizes storage management within HBase.
87. What resources are recommend for learning HBase?
Ans:
Understanding HBase requires consulting the official Apache HBase documentation, which provides comprehensive instructions and API references.”HBase: The Definitive Guide” by Lars George is a priceless tool that offers in-depth analysis and practical examples. Two online learning sites that combine structured instruction with real-world assignments. YouTube tutorials can also be quite helpful for people who learn best visually. Community forums and mailing lists offer practical guidance and assistance from experienced members.
88. What does an HBase cell consist of?
Ans:
- The minor units in an HBase database are called cells, and they store data as tuples.
- A tuple is a multipartite data structure.
- It is composed of {row, column, version).HBase stores data as a group of values or cells.
- HBase uniquely identifies each cell by a key.
- Using a key, users can look up the data for records stored in HBase very quickly.
- Can also insert, modify, or delete records in the middle of a dataset.
89. Explain what HBase compaction is.
Ans:
HBase compaction is the process of merging smaller HFiles, which are physical files containing sorted key-value pairs, into larger files. This process helps improve read performance by reducing the number of files that need to be scanned. Compaction also helps in reclaiming disk space by removing obsolete or deleted data. It ensures data integrity and maintains optimal performance by organizing data efficiently within HBase tables. Regular compaction prevents fragmentation, which can lead to increased latency during data retrieval.
90. Describe tombstone markers and deletion in HBase.
Ans:
In HBase, tombstone markers are placeholders indicating deleted data. When a row or column is deleted, instead of immediate removal, a tombstone marker is inserted, marking the data as deleted. During compaction, marked data is removed permanently. This approach ensures consistency in distributed systems, supporting rollback and recovery. It also allows applications to manage deletions more efficiently by preventing inconsistencies that could arise from immediate data removal.
91. How does HBase handle large datasets?
Ans:
- With its distributed architecture, which supports horizontal scaling across numerous nodes to accommodate growing data volumes efficiently, HBase manages massive datasets.
- Tables are divided into regions and then dispersed over multiple RegionServers to ensure optimized performance and balanced load.
- HDFS is used by HBase for storage, offering high availability and fault tolerance through dependable data storage over a distributed file system.
- Features like data compression and bloom filters help optimize storage and retrieval performance, making HBase suitable for handling large-scale applications.




