
Last updated on 04th Jul 2020| 3881
Elasticsearch is a potent distributed search and analytics engine that can handle massive amounts of data quickly and nimbly. It is intended to offer almost instantaneous search capabilities for both structured and unstructured data. Elasticsearch allows for flexibility in data feeding and querying since it uses a JSON (JavaScript Object Notation) document storage without schemas. It is frequently utilized for full-text search, log analytics, and other use cases that call for quick data retrieval and analysis.
1. What is Elasticsearch, and how does it work?
Ans:
An open-source search engine called Elasticsearch is designed for horizontal scalability, real-time search, and high availability. Elasticsearch stores data as JSON documents, and each document is indexed to create an inverted index. This allows for speedy full-text searches. It works by receiving data through RESTful APIs, indexing the data, and providing powerful search and analytics capabilities over large volumes of data.
2. What is an Elasticsearch cluster?
Ans:
An Elasticsearch cluster is a group of one or more nodes that work together to store and search data. Each cluster is identified by a unique name, which is used by nodes to join the cluster. The cluster distributes data and search tasks across all nodes, providing redundancy and high availability. If a node fails, the cluster can redistribute tasks and data to ensure continued operation without data loss.
3. Describe what a node is in Elasticsearch.
Ans:
- Each node belongs to a cluster and is responsible for storing data and participating in the cluster’s indexing and search functions.
- Nodes can have different roles, a controller node manages cluster-wide settings and states, a data node stores data and executes search and aggregation operations, and an ingest node preprocesses documents before indexing.
- Nodes communicate with each other and work collaboratively to manage the data and distribute the search load.
4. What are shards in Elasticsearch?
Ans:
- Shards are fundamental units of storage in Elasticsearch. Each index is divided into multiple shards, and each shard is an individual Apache Lucene index.
- This division allows Elasticsearch to scale horizontally by distributing shards across various nodes. Primary shards hold the original data, while replica shards are copies of primary shards and provide redundancy.
- By distributing shards across nodes, Elasticsearch ensures that data is balanced and queries can be parallelized, improving performance and fault tolerance.
5. What are replica shards?
Ans:
Replica shards are copies of primary shards and are used to provide high availability and fault tolerance in an Elasticsearch cluster. If a node hosting a primary shard fails, the corresponding replica shard can be promoted to a primary shard to ensure continued access to the data. Replicas also help to distribute the search load, as queries can be executed on both primary and replica shards, improving performance.
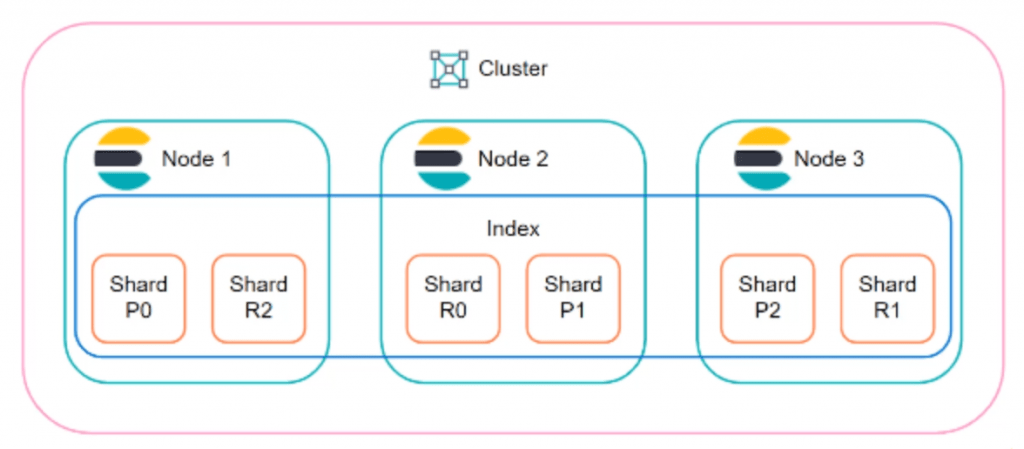
6. How does Elasticsearch handle data distribution across nodes?
Ans:
Elasticsearch handles data distribution across nodes by using shards. When an index is created, it is divided into a specified number of primary shards. Elasticsearch then distributes these primary shards across different nodes in the cluster. Each primary shard can have one or more replica shards, which are also distributed across nodes. The Elasticsearch controller node is responsible for managing shard allocation, ensuring that both primary and replica shards are evenly distributed and that no node holds a primary and its replica.
7. What is an Elasticsearch index?
Ans:
- An index in Elasticsearch is a collection of documents that are related to each other and are stored together.
- It is analogous to a database in a traditional relational database system.
- Each index is identified by a unique name and is used to organize and manage the data.
- Within an index, data is stored in the form of JSON documents, and each document is assigned to a type.
- Indexes enable efficient data retrieval and management, aggregations, and analyses on the grouped data.
8. Describe what a document is in Elasticsearch.
Ans:
- A document in Elasticsearch is a basic unit of information that is stored in JSON format.
- Each document is composed of fields, which are key-value pairs representing the data.
- Documents are indexed and stored within an index, and they can represent a variety of entities.
- Elasticsearch uses the contents of documents to create inverted indexes, enabling fast.
9. What is a type in Elasticsearch?
Ans:
In Elasticsearch versions prior to 6.0, a type was a logical partition within an index used to group documents with similar structures. Each type had its mapping, defining the structure of the papers and their fields. This allowed users to store different kinds of documents within a single index. However, types were deprecated in Elasticsearch 6. x and removed in Elasticsearch 7. x later due to issues with mapping conflicts and complexity.
10. What is the difference between a primary and a replica shard?
Ans:
| Aspect | Primary Shard | Replica Shard |
|---|---|---|
| Role | Holds the original data and handles indexing. | Holds a copy of the primary shard for redundancy. |
| Function | Handles all write operations (indexing, updating, deleting). | Provides fault tolerance and improves read performance. |
| Number per Index | Exactly one per index. | Configurable (zero or more per primary shard). |
| Data Storage | Contains the primary copy of the data. | Contains identical data as its primary shard counterpart. |
11. What is an index that is inverted?
Ans:
- A data structure called an inverted index is utilized by search engines, including Elasticsearch, to optimize the search process.
- It maps terms to the documents that contain them rather than mapping documents to the terms they contain, like a traditional forward index.
- This structure allows for fast full-text searches. When a document is indexed, Elasticsearch breaks it down into terms and adds these terms to the inverted index.
- Each term points to a list of documents (or positions within documents) where it appears, making it efficient to retrieve documents matching a query.
12. How to create an index in Elasticsearch?
Ans:
- HTTP Request: Use `PUT /index_name` to create an index named `index_name.`
- Settings: To control index behavior, provide optional settings like `’ number_of_shards` and `’ number_of_replicas.’
- Mappings: Optionally, define mappings to specify field types and properties for documents.
- Example Request:
- PUT /my_index
- {
- “settings”: {
- “number_of_shards”: 1,
- “number_of_replicas”: 1
- },
- “mappings”: {
- “properties”: {
- “field1”: { “type”: “text” },
- “field2”: { “type”: “keyword” }
- }
- }
- }
13. How to delete an index in Elasticsearch?
Ans:
- Use Elasticsearch to remove an index. RESTful API with a DELETE request. Here’s an example using `curl`: DELETE “http://localhost:9200/my_index” with curl -X.
- This command deletes the index named `my_index.` Deleting an index will remove all documents and metadata associated with it, so it should be done with caution.
14. How to add a document to an Elasticsearch index?
Ans:
To add a document to an Elasticsearch index, can use the Index API. Make a POST HTTP request to Elasticsearch. Cluster with the index name, document ID (optional), and the document content in JSON format. For example:
- POST /index_name/_doc
- {
- “field1”: “value1”,
- “field2”: “value2”
- }
Replace index_name with index’s name and provide the appropriate fields and values for document. This API call will add the document to the specified index in Elasticsearch.
15. How to delete a document from an index?
Ans:
- To delete a document from an index in Elasticsearch, can use the RESTful API with a DELETE request. Here’s an example using `curl`: curl -X DELETE “http://localhost:9200/my_index/_doc/1”
- This command deletes the document with an ID of `1` from the `my_index` index. The document is removed from the index and will no longer appear in search results.
16. What is a document ID in Elasticsearch?
Ans:
A document ID in Elasticsearch is a unique identifier for a document within an index. It is used to retrieve, update, or delete a specific document. When index a document, can either specify a custom document ID or let Elasticsearch generate one . The document ID helps efficiently manage and access individual documents within an index. Having a well-structured document ID scheme can enhance data organization and facilitate easier integration with other systems.
17. Explain what an analyzer is.
Ans:
- It consists of a tokenizer and zero or more token filters. An analyzer is responsible for converting the text into a stream of tokens (terms) that can be indexed and searched.
- During indexing, the analyzer processes the text field of documents, breaking it down into terms, normalizing them, and removing unwanted characters or stop words.
- Different analyzers can be used for various fields depending on the specific requirements of text processing, such as language-specific analysis or case normalization.
18. What is the purpose of a tokenizer?
Ans:
- A tokenizer in Elasticsearch is a component of an analyzer that breaks down text into individual tokens. The purpose of the tokenizer is to create a stream of terms that can be indexed and searched.
- It reads the text and divides it into smaller, manageable pieces based on specific rules, such as whitespace, punctuation, or particular characters.
- Different tokenizers can be used depending on the type of text data and the desired tokenization rules, such as standard tokenizers, whitespace tokenizers, or custom tokenizers for specific use cases.
19. How does the Elasticsearch query language work?
Ans:
The Elasticsearch query language, also known as Query DSL (Domain Specific Language), is an effective and adaptable method for looking up and analyzing data in Elasticsearch. There are two primary contexts in Query DSL: query context and filter context. In query context, queries are used to retrieve documents based on relevance scoring (e.g., `match,` `multi_match`). In filter context, queries are used to filter documents without affecting relevance scoring (e.g., `term,` `range`).
20. Explain the role of the controller node.
Ans:
In an Elasticsearch cluster, the controller node is responsible for managing the cluster state and performing administrative tasks. It keeps track of all nodes in the cluster, manages shard allocation, creates and deletes indices, and maintains the metadata and mappings of all indices. The controller node is also responsible for cluster-wide settings and ensuring the cluster’s health and stability. Although every node can potentially become a controller node, typically, only one node is elected as the active master at any given time.
21. What are dynamic mappings in Elasticsearch?
Ans:
- Dynamic mappings in Elasticsearch allow the system to automatically determine and apply the appropriate data types for new fields in documents that are indexed.
- When Elasticsearch encounters a new field in a document, it dynamically assigns a data type based on the content it finds.
- For example, if a new field contains a string of text, Elasticsearch will assign it a `text` type.
- Dynamic mappings make it easy to work with unstructured data and rapidly evolving schemas by removing the need for upfront schema definition.
22. How to create custom mappings for an index?
Ans:
To create custom mappings for an index in Elasticsearch, can define the mappings when create the index. Here is an example of how to create custom mappings:
- PUT /my_index
- {
- “mappings”: {
- “properties”: {
- “name”: {
- “type”: “text”
- },
- “age”: {
- “type”: “integer”
- },
- “email”: {
- “type”: “keyword”
- },
- “joined_date”: {
- “type”: “date”,
- “format”: “yyyy-MM-dd”
- }
- }
- }
- }
23. How to update mappings for an existing index?
Ans:
Updating mappings for an existing index in Elasticsearch is limited in scope. Cannot change the type of an existing field, but can add new fields or update specific settings. To add a new field to the mappings of an existing index, use the `PUT` mapping API. Here’s an example:
- PUT /my_index/_mapping
- {
- “properties”: {
- “new_field”: {
- “type”: “text”
- }
- }
- }
24. Explain the concept of full-text search.
Ans:
- Unlike traditional database searches that might be limited to exact matches or simple wildcard searches, full-text search analyzes the text and indexes it in a way that allows for robust, complex searches.
- This includes searching for individual words, phrases, prefixes, and even similar words. Full-text search in Elasticsearch uses analyzers to break down the text into tokens (e.g., words), which are then indexed.
- This allows for flexible and efficient searching, including relevancy scoring, stemming, and synonym matching.
25. What is the purpose of filters within Elasticsearch?
Ans:
- Elasticsearch filters limit search results according to particular standards without changing the relevance score of the results.
- They are primarily used to refine query results by including or excluding documents that match certain conditions.
- Filters are more efficient than queries for certain operations because they can be cached and reused, leading to faster performance for repeated search conditions.
- Filters are often used in combination with queries to optimize and structure search requests.
26. How to perform a filter in Elasticsearch?
Ans:
To perform a filter in Elasticsearch, typically use the `bool` query with the `filter` clause. Here’s an example:
- GET /my_index/_search
- {
- “query”: {
- “bool”: {
- “must”: {
- “match”: {
- “title”: “Elasticsearch”
- }
- },
- “filter”: {
- “term”: {
- “status”: “published”
- }
- }
- }
- }
- }
27. What are aggregations in Elasticsearch?
Ans:
Aggregations in Elasticsearch are powerful tools used for summarizing and analyzing data. They enable to carry out intricate computations and data transformations, such as computing statistics, building histograms, and generating summaries. Aggregations can be nested and combined in various ways to provide detailed insights into data. They are often used to create reports, dashboards, and analytics.
28. Explain the different types of aggregations.
Ans:
- Metric Aggregations: Compute metrics like average, sum, min, max, and statistical measures on numeric fields. Examples include `avg,` `sum,` `min,` `max,` and `stats.`
- Bucket Aggregations: Create buckets or groups of documents based on specific criteria. Examples include `terms,` `range,` `histogram,` `date_histogram,` and `filters.`
- Pipeline Aggregations: Aggregate the results of other aggregations. Examples include `derivative,` `moving_avg,` and `cumulative_sum.`
- Matrix Aggregations: Perform computations on multiple fields. Examples include `matrix_stats.`
29. How do users perform a term aggregation?
Ans:
The term aggregation is used to group documents by the unique values of a field. Here’s an example of performing a term aggregation:
- GET /my_index/_search
- {
- “size”: 0,
- “aggs”: {
- “status_count”: {
- “terms”: {
- “field”: “status”
- }
- }
- }
- }
30. What is a range aggregation?
Ans:
A range aggregation is used to group documents into ranges based on a numeric field. It allows to define custom ranges and count the number of documents that fall into each range. Here’s an example:
- GET /my_index/_search
- {
- “size”: 0,
- “aggs”: {
- “price_ranges”: {
- “range”: {
- “field”: “price”,
- “ranges”: [
- { “to”: 100 },
- { “from”: 100, “to”: 200 },
- { “from”: 200 }
- ]
- }
- }
- }
- }
31. What is a histogram aggregation?
Ans:
- A histogram aggregation is a method used in data analysis to summarize and display the distribution of numerical data into discrete bins or intervals.
- Each bin represents a range of values, and the histogram shows the frequency or count of data points falling within each bin.
- This visualization helps identify patterns, outliers, and the overall shape of the data distribution, aiding in statistical analysis and decision-making processes.
32. What is a date histogram aggregation?
Ans:
A date histogram aggregation in Elasticsearch is a way to group and analyze data based on time intervals, such as hours, days, or months. It breaks down documents into buckets corresponding to specified time intervals, counting documents or aggregating values within each interval. This aggregation is useful for visualizing trends over time and understanding patterns in time-series data efficiently.
33. Explain the concept of nested objects.
Ans:
- Nested objects in Elasticsearch are a way to handle arrays of objects that want to query as a single entity.
- When use nested objects, Elasticsearch indexes each object within the array as a separate document but keeps them linked to the original parent document.
- This allows to perform more complex queries, such as querying for documents where an array contains an object that meets specific criteria.
- The nested type is proper when dealing with hierarchical data structures and ensures that each nested object is treated independently during queries.
34. How to handle parent-child relationships?
Ans:
- Parent-child relationships in Elasticsearch allow to establish hierarchical relationships between documents in the same index.
- This is useful when have entities with one-to-many relationships. To set up a parent-child relationship, define a parent type and a child type within the same index.
- Each child document references its parent by including a `_parent` field. This relationship enables to perform join-like queries, such as querying for parents with specific children or vice versa.
- However, it’s important to note that the parent-child feature adds complexity and can impact performance, so it should be used judiciously.
35. What are bulk operations in Elasticsearch?
Ans:
Bulk operations in Elasticsearch allow to perform multiple index, update, delete, or create actions in a single API call. This is highly efficient compared to performing individual operations one by one, as it reduces the overhead associated with multiple network round-trips and can significantly enhance performance, mainly when working with sizable datasets. Bulk operations are essential for efficiently managing data in Elasticsearch, particularly during initial data ingestion, reindexing, or batch updates.
36. How to use the _bulk API?
Ans:
The `_bulk` API in Elasticsearch is used to perform multiple operations in a single request. To use the `_bulk` API, send a POST request to the `_bulk` endpoint with a payload that includes multiple action-and-meta-data lines followed by the corresponding source data. Each action-and-meta-data line specifies the operation (index, create, update, delete) and the target index and document.
37. What is the purpose of aliases?
Ans:
Aliases in Elasticsearch are used to create an abstraction over one or more indices, allowing to refer to them using a single name. Aliases can be used for several purposes, such as:
- Simplifying index management by abstracting the underlying index names.
- Enabling zero-downtime reindexing by pointing an alias to a new index.
- Creating filtered aliases to restrict access to specific documents based on query criteria.
- Managing multiple indices as a single entity for search and indexing operations.
38. How to create and manage aliases?
Ans:
To create and manage aliases in Elasticsearch, use the `_aliases` endpoint. Can add, remove, or update aliases using a JSON payload that specifies the actions to be performed. For example, to create an alias:
- POST /_aliases
- {
- “actions”: [
- { “add”: { “index”: “index1”, “alias”: “my_alias” } }
- ]
- }
39. What is the _reindex API used for?
Ans:
The `_reindex` API in Elasticsearch is used to copy data from one index to another. This can be useful for various scenarios, such as:
- Changing the mappings or settings of an index.
- Upgrading an index to a new version.
- Filtering and transforming data during the reindexing process.
- Splitting or merging indices.
40. How does versioning work in Elasticsearch?
Ans:
Versioning in Elasticsearch is used to manage concurrent updates to documents. Each document has a version number, which increments with each update. When perform an update, can specify the version number to ensure that are modifying the correct version of the document. This helps to prevent conflicts and ensures data consistency. If the version number provided in the update request does not match the current version of the document, the update will be rejected.

Get JOB Elasticsearch Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. What are scripted updates?
Ans:
Scripted updates in Elasticsearch allows to update documents using a script. This is useful for complex updates that cannot be achieved with a simple partial update. Scripts can be written in Painless, a scripting language designed specifically for Elasticsearch. Scripted updates provide flexibility by allowing to modify fields, add new fields, or remove fields based on custom logic.
42. How to perform an update by query?
Ans:
To perform an update by query in Elasticsearch, use the `_update_by_query` API. This API allows to update multiple documents that match a query condition. The update is performed using a script that modifies the matching documents. For example, to increment a field for all documents that match a specific condition:
- POST /my_index/_update_by_query
- {
- “script”: {
- “source”: “ctx._source.counter += params.increment”,
- “params”: {
- “increment”: 1
- }
- },
- “query”: {
- “term”: {
- “status”: “active”
- }
- }
- }
43. What is a snapshot?
Ans:
- A snapshot in Elasticsearch is a backup of an index or the entire cluster state stored in a repository. Snapshots can be stored in various repositories, such as shared filesystems, Amazon S3, and other cloud storage services.
- Snapshots are used to protect against data loss and can be restored to recover data. Snapshots are incremental, meaning that only the data that has changed since the last snapshot is stored, which saves space and speeds up the backup process.
44. How to take and restore snapshots?
Ans:
To take a snapshot, navigate to the SAP system’s snapshot functionality and select “Create Snapshot,” providing a name and description. Confirm the operation to save the system state. To restore a snapshot, go to the snapshot management section, select the desired snapshot, and choose “Restore.” Confirm the restoration process to revert the system to the snapshot state.
45. How to check the health of a cluster?
Ans:
Can check the health of an Elasticsearch cluster using the `_cluster/health` API. This API provides information about the cluster’s status, number of nodes, number of data nodes, active shards, relocating shards, initializing shards, and unassigned shards. It returns a status indicator (green, yellow, or red) to quickly assess the overall health of the cluster. Additionally, monitoring this health regularly can help identify potential issues before they impact performance or data availability.
46. What are index templates?
Ans:
- Index templates in Elasticsearch are configurations that allows to define settings, mappings, and aliases for indices that match a specific pattern.
- Templates are applied automatically when a new index is created, ensuring consistent configurations across indices.
- Templates are helpful in managing multiple indices with similar structures and for enforcing best practices.
47. How to use index templates?
Ans:
- Index templates in Elasticsearch are used to automate the creation of new indices with predefined settings and mappings.
- By defining templates based on index patterns, mappings, and settings, Elasticsearch automatically applies these configurations when new indices match the defined patterns.
- This ensures consistency across indices and simplifies management, especially in environments with frequent index creation.
48. Explain the purpose of index lifecycle management (ILM).
Ans:
Index Lifecycle Management (ILM) in Elasticsearch automates the management of indices over their lifecycle. ILM policies define actions to be taken at different phases of an index’s life, such as rollover, shrink, delete, or migrate to varying tiers of storage. ILM helps optimize resource usage, manage storage costs, and ensure that indices are managed according to predefined rules and schedules.
49. How to configure ILM policies?
Ans:
To configure ILM policies, create a policy that specifies the phases (hot, warm, cold, delete) and the actions to be taken in each phase. For example:
- PUT /_ilm/policy/my_policy
- {
- “policy”: {
- “phases”: {
- “hot”: {
- “actions”: {
- “rollover”: {
- “max_size”: “50GB”,
- “max_age”: “30d”
- }
- }
- },
- “delete”: {
- “min_age”: “90d”,
- “actions”: {
- “delete”: {}
- }
- }
- }
- }
- }
50. What are the lifecycle phases in ILM?
Ans:
- Hot phase: For active indices that are being written to and queried frequently. Actions can include rollover, set priority, and more.
- Warm phase: This is for indices that are no longer being written to but are still queried. Actions can include shrinking, allocating to specific nodes, and setting priority.
- Cold phase: For indices that are infrequently accessed. Actions can involve allocating to less performant nodes, freezing, and setting priority.
- Delete phase: This is for indices that are no longer needed. The main action is to delete the index to free up resources.
51. What is cross-cluster search?
Ans:
Cross-cluster search allows to search across multiple Elasticsearch clusters as if they were a single cluster. This feature is helpful for organizations that need to query data spread across different geographic locations or data centers, ensuring scalability and fault tolerance. Cross-cluster search works by configuring a local cluster to connect to remote clusters, enabling users to run queries on indices that span these clusters.
52. How to implement cross-cluster replication?
Ans:
- Set Up Remote Clusters: Use the remote cluster settings’ to configure the follower cluster to recognize the leader cluster.
- Create Follower Indices: Use the `follow` API to create follower indices that replicate the leader indices.
- Replication Process: Elasticsearch continuously streams changes from the leader index to the follower index, ensuring data consistency.
- Monitor Replication: Use CCR APIs to monitor replication’s status and ensure that it is running smoothly.
53. Explain the concept of the Elastic Stack (ELK Stack).
Ans:
- The Elastic Stack, commonly known as the ELK Stack, consists of three primary open-source tools Elasticsearch, Logstash, and Kibana.
- An analytics and search engine that is distributed and RESTful for storing, searching, and analyzing big data instantly available.
- An application for exploring and visualizing data that provides an interface to visualize data stored in Elasticsearch, create dashboards, and generate reports.
54. How does Elasticsearch integrate with Logstash?
Ans:
Elasticsearch integrates with Logstash as part of the Elastic Stack to provide a seamless data ingestion and indexing pipeline. Logstash collects data from various sources (like logs, metrics, or web applications), processes it (such as filtering, parsing, and transforming the data), and then sends it to Elasticsearch for indexing. This integration enables real-time data analysis and visualization, facilitating quick insights and decision-making based on the ingested data.
55. How does Elasticsearch integrate with Kibana?
Ans:
Elasticsearch integrates with Kibana to provide robust data visualization and exploration capabilities. Kibana acts as the front-end interface for Elasticsearch, enabling people to view and work with data that is stored in Elasticsearch indices. The integration works as follows:
- Data Exploration
- Dashboards
- Reporting
- Alerts
56. What are index patterns in Kibana?
Ans:
- They allow Kibana to identify the indices to search and display in the Discover tab.
- Visualizations in Kibana use index patterns to know which indices to query for data.
- Dashboards in Kibana aggregate visualizations that rely on specific index patterns.
- Setting up index patterns is a crucial step in configuring Kibana to work with Elasticsearch data.
57. How to secure an Elasticsearch cluster?
Ans:
- Authentication and Authorization: Implement user authentication using built-in security features or external systems like LDAP or Active Directory.
- TLS/SSL Encryption: Enable Transport Layer Security (TLS) to encrypt data in transit between nodes and between clients and the cluster.
- Network Security: Restrict access to the cluster by configuring firewalls, using private networks, or setting up virtual private clouds (VPCs). Use IP filtering to allow only trusted IP addresses.
58. What is X-Pack?
Ans:
X-Pack is an extension of the Elasticsearch stack that provides additional features such as security, monitoring, alerting, reporting, graph capabilities, and machine learning. Developed by Elastic, X-Pack integrates seamlessly with Elasticsearch, Kibana, and Logstash, adding critical enterprise-level functionality to the Elastic Stack. Monitoring and alerting help maintain cluster health and notify administrators of issues. X-Pack’s machine learning capabilities provide anomaly detection and predictive analytics.
59. How to set up user authentication?
Ans:
To set up user authentication, configure a centralized authentication method such as LDAP or Active Directory within SAP system. Define user roles and permissions based on organizational needs. Implement strong password policies and multi-factor authentication for enhanced security. Regularly review and update user access rights to ensure compliance and minimize risks. Conduct training sessions for users on secure authentication practices.
60. Explain role-based access control (RBAC).
Ans:
Role-Based Access Control (RBAC) in Elasticsearch is a security feature that restricts access to the cluster, indices, and documents based on the roles assigned to users. A role is a collection of permissions that specify the actions that a user is able to do and on which resources. RBAC aids in enforcing the least privileged. Ensure that users have access only to the necessary tasks. Permissions can include operations like read, write, delete, and manage.

Develop Your Skills with Elasticsearch Certification Training
Weekday / Weekend BatchesSee Batch Details61. How do users monitor an Elasticsearch cluster?
Ans:
- Use Elasticsearch’s built-in APIs like Cluster Health and Node Stats for real-time status and performance metrics.
- Utilize monitoring tools such as Elastic Stack’s Kibana Monitoring or third-party solutions like Prometheus and Grafana.
- Monitor key metrics like cluster health, node availability, CPU and memory usage, disk space, and indexing rates.
- Set up alerts for thresholds to proactively manage issues and ensure cluster stability.
62. What are some common performance tuning strategies?
Ans:
- Proper Sharding: Balance the number of primary and replica shards according to cluster size and workload. Avoid too many or too few shards.
- Indexing Optimization: Use bulk indexing to improve indexing speed. Disable replicas during heavy indexing and re-enable them afterward.
- Query Optimization: Where possible, use filters instead of queries, as filters are cached. Avoid complex and nested queries.
- Memory Management: Allocate sufficient heap size to Elasticsearch JVM (but at most 50% of available RAM). Monitor and optimize garbage collection.
63. How to handle large-scale data?
Ans:
Handling large-scale data involves several key steps: first, ensuring robust data storage and retrieval systems are in place; second, employing efficient data processing techniques such as parallel computing and distributed systems; third, implementing data compression and indexing strategies to optimize storage and access times; fourth, utilizing scalable cloud-based solutions for elastic computing and storage capabilities; and finally, employing data cleaning and preprocessing techniques to ensure data quality and reliability for analysis and decision-making purposes.
64. What are the best practices for indexing large datasets?
Ans:
- Use Bulk API: Index data in bulk to improve performance and reduce overhead.
- Optimize Mappings: Define mappings explicitly to prevent dynamic mapping overhead. Use appropriate field data types.
- Disable Replicas Temporarily: Disable replicas during the bulk indexing process and re-enable them afterward to speed up indexing.
- Tune Refresh Interval: Increase the `refresh_interval` bulk indexing in order to lower the frequency of index refreshing.
65. Explain zero downtime reindexing.
Ans:
Zero downtime reindexing is a process in database management where indexes are rebuilt or optimized without interrupting access to the database. This method ensures continuous availability of the database for users and applications while enhancing performance by improving index efficiency. It typically involves techniques such as online index rebuilds or using secondary indexes temporarily during the reindexing process to maintain operations without downtime.
66. How to handle schema evolution?
Ans:
- Backward Compatibility: Ensure that new fields added to the schema do not break compatibility with existing documents and queries.
- Dynamic Mappings: Use dynamic mappings carefully to allow Elasticsearch to accommodate new fields without manual intervention.
- Reindexing: If significant changes are needed, create a new index with the updated schema and reindex data from the old index.
- Index Templates: Use index templates to manage and version mappings consistently across indices.
67. What is the Elasticsearch SQL plugin?
Ans:
The Elasticsearch SQL plugin allows users to interact with Elasticsearch using SQL queries. This plugin translates SQL queries into Elasticsearch’s Query DSL, enabling users to leverage their SQL knowledge to perform searches and aggregations. It supports numerous SQL operations, including SELECT statements, WHERE clauses, JOINs, and aggregations, simplifying the process of querying Elasticsearch data for users who are familiar with SQL.
68. How to perform SQL queries in Elasticsearch?
Ans:
In Elasticsearch, SQL queries can be performed using the SQL REST API or through the SQL query endpoint provided by Elasticsearch’s SQL plugin. This allows to write SQL-like queries against Elasticsearch indices, leveraging familiar syntax for querying and aggregating data. Results are returned in JSON format, enabling seamless integration with Elasticsearch’s capabilities while simplifying querying for those familiar with SQL.
69. What is a term query?
Ans:
- A term query in Elasticsearch is a type of query used to search for documents that contain precisely the specified term in a given field.
- It is not analyzed, meaning it does not process the input term through the analyzer used in indexing.
- This makes it suitable for exact matches, such as searching for specific keywords, IDs, or tags.
- For example, a term query searching for the term “OpenAI” in a “company” field will only return documents where the “company” field exactly matches “OpenAI.”
70. What is a match query?
Ans:
A match query in Elasticsearch is a type of query that searches for documents that match the given text after analyzing the text with the standard analyzer. This means the input text is tokenized and processed (e.g., lowercase, stemmed), allowing for more flexible and comprehensive searches. It is suitable for full-text search scenarios. For example, a match query searching for “Elasticsearch tutorial” in a “description” field will return documents containing terms related to both “Elasticsearch” and “tutorial” after analysis.
71. Explain geospatial queries.
Ans:
- Geo Shape Queries: Search for documents based on shapes like points, lines, polygons, etc., using the `geo_shape` query.
- Geo Distance Queries: Find documents within a certain distance from a specified point using the `geo_distance` query.
- Geo Bounding Box Queries: Retrieve documents that fall within a specified bounding box using the `geo_bounding_box` query.
- Geo Polygon Queries: Search for documents that intersect with a specified polygon using the `geo_polygon` query.
72. What is the coordinate map in Elasticsearch?
Ans:
A coordinate map in Elasticsearch is a specialized visualization that displays geographic data on a map. It uses the geo-point data type to plot individual points based on latitude and longitude coordinates stored in documents. Coordinate maps allow users to visualize spatial data directly within Kibana, facilitating geographical analysis and insights.
73. What are geo-point data types?
Ans:
Geo-point data types are specific data structures used to store geographic coordinates such as latitude and longitude. They enable accurate location-based querying and spatial analysis in databases. These data types are crucial for applications requiring location-aware features, such as mapping, navigation, and geo-fencing. Geo-point data can be indexed for efficient spatial searches, supporting proximity-based queries and geospatial calculations.
74. How to use the _cat APIs?
Ans:
- `_cat/indices`: Provides a summary of indices, including health, status, number of documents, and disk space usage.
- `_cat/shards`: Displays information about shard allocation across nodes, including primary and replica shard details.
- `_cat/nodes`: Lists all nodes in the cluster along with their roles, IP addresses, and other details.
- `_cat/allocation`: Shows disk space allocation details for shards on nodes.
75. What is the _cat indices API?
Ans:
The `_cat/indices` API in Elasticsearch provides a concise overview of all indices in the cluster. It returns information such as index name, health status (`green,` `yellow,` or `red`), number of primary and replica shards, number of documents, disk space usage, and more. This API is helpful for administrators and developers to monitor index health, track index size growth, and troubleshoot issues related to index performance or configuration.
76. What is the _cat shards API?
Ans:
The `_cat/shards` API in Elasticsearch provides detailed information about shard allocation across nodes in the cluster. It lists all shards for each index, including primary and replica shards, along with their current state, node assignments, and recovery status. This API helps administrators monitor shard distribution, identify unassigned shards, and troubleshoot issues related to shard allocation and recovery.
77. What is the _cluster/stats API?
Ans:
- Nodes: Number of nodes, roles (master, data, ingest), JVM heap usage, CPU and memory usage.
- Indices: Count of indices, shards, and documents, as well as disk usage statistics.
- Filesystem: Disk space usage and available capacity on each node.
- Transport and HTTP Metrics: Metrics related to network communication between nodes and clients.
78. Explain search templates.
Ans:
Search templates in Elasticsearch allow users to define reusable queries with placeholders for dynamic values. They enable parameterized searching, where the same query structure can be applied with different input values. Search templates are helpful for scenarios where queries need to be customized based on user input or application requirements without modifying the query itself. Templates are stored in the cluster and can be executed using the `_search/template` API endpoint, providing flexibility and efficiency in query execution.
79. How do users create and use search templates?
Ans:
To create and use search templates effectively, start by defining detailed search criteria within application or tool. Save these criteria as reusable templates for quick access and consistency. When performing searches, simply select the appropriate template to automatically populate the search fields with predefined settings, optimizing search process and ensuring accurate results aligned with specific needs.
80. What is the painless scripting language?
Ans:
Painless is a lightweight, secure scripting language designed for use in Elasticsearch. It is built explicitly for Elasticsearch and is used primarily for scripted fields, queries, aggregations, and updates. Painless scripts are executed in a sandboxed environment within Elasticsearch, providing a balance between flexibility and security. The language is optimized for performance, allowing for efficient execution of scripts even on large datasets. Painless supports a variety of data types and operations, making it a versatile tool for enhancing queries and analytics.
81. How do users use painless scripts in queries?
Ans:
Painless scripts in Elasticsearch can be used within queries to customize how documents are scored or filtered based on complex logic. They are included in the `script` field of a query.
Example:
- {
- “query”: {
- “script_score”: {
- “query”: {
- “match”: {
- “content”: “Elasticsearch”
- }
- },
- “script”: {
- “source”: “doc[‘popularity’].value 2.”
- }
- }
- }
- }
82. How do users use painless scripts in aggregations?
Ans:
Painless scripts can be used in aggregations to perform calculations or transformations on the aggregated data.
Example:
- {
- “aggs”: {
- “total_sales”: {
- “sum”: {
- “field”: “sales”
- }
- },
- “discounted_sales”: {
- “bucket_script”: {
- “buckets_path”: {
- “totalSales”: “total_sales”
- },
- “script”: “params.totalSales 0.9”
- }
- }
- }
- }
83. What data types are supported in Elasticsearch?
Ans:
- String Types: `text,` `keyword`
- Numeric Types: `long,` `integer,` `short,` `byte,` `double,` `float,` `half_float,` `scaled_float.`
- Date Type: `date`
- Boolean Type: `boolean`
- Binary Type: `binary`
84. Explain the difference between text and keyword data types.
Ans:
- Text: Used for full-text search. The field values are analyzed, meaning they are tokenized and indexed, allowing for operations like searching for individual words within the text. Suitable for large, unstructured texts like articles or descriptions.
- Keyword: Used for exact match search and aggregations. The field values are not analyzed, meaning they are indexed as a single term. Suitable for structured data like IDs, email addresses, or tags where exact matching is required.
85. How to use index lifecycle management (ILM) API?
Ans:
- Define policies for index management, including phases like hot, warm, cold, and delete.
- Apply these policies to indices based on conditions like age or size.
- Monitor and adjust policies using APIs to automate index lifecycle.
- Ensure compliance with retention and access requirements.
- Improve cluster efficiency by automating index management tasks.
86. How to manage ILM policies?
Ans:
Managing ILM policies involves defining data retention periods, specifying archival and deletion rules, ensuring compliance with regulatory requirements, automating data movement between storage tiers based on policies, and regularly reviewing and updating policies to align with business needs and legal obligations. Effective communication and training for stakeholders are essential to ensure that all team members understand and adhere to the established policies, fostering a culture of compliance and data stewardship within the organization.
87. What is the Elasticsearch Curator?
Ans:
- Deleting Old Indices: This function automatically removes indices based on age or size, ideal for time-series data like logs or metrics.
- Creating Snapshots: Automates the creation of backups to a remote repository, ensuring data safety.
- Applying Index Lifecycle Policies: Enforces policies for different index stages (hot, warm, cold, delete), optimizing storage and accessibility.
- Rollover Indices: Automates index rollover based on conditions like age or size, maintaining cluster performance.
88. How to use the Elasticsearch curator to manage indices?
Ans:
- Install Curator using pip (`pip install elasticsearch-curator`).
- Create a Curator configuration file defining actions like deleting, closing, or optimizing indices based on conditions.
- Schedule tasks using cron or Windows Task Scheduler to execute Curator actions regularly.
- Execute Curator commands (`curator –config <config_file.yaml> <action_file.yaml>`) to automate index management tasks.
89. How to optimize search performance?
Ans:
- Proper Sharding: Choose an appropriate number of shards and replicas based on data volume and query load.
- Efficient Queries: Use filters instead of queries where possible, and prefer term and match queries over full-text queries when exact matches are needed.
- Indexing Strategy: Use bulk indexing, optimize mappings, and set appropriate `refresh_interval` values.
- Hardware Resources: Ensure sufficient CPU, memory, and fast storage (SSD).
90. What are the differences between Elasticsearch and traditional relational databases?
Ans:
- Elasticsearch uses a schema-less JSON document model, while relational databases use a structured, schema-based table model.
- Elasticsearch uses its Query DSL for searches, whereas relational databases use SQL. Elasticsearch is optimized for full-text search and analytics, offering powerful search capabilities.
- Elasticsearch is designed for horizontal scalability and distributed architectures, whereas relational databases often scale vertically and require complex sharding for horizontal scaling.
- Relational databases are not inherently designed for full-text search but can support it with additional modules or extensions.




