
Last updated on 05th Jun 2024| 5021
A data engineer is a professional responsible for designing, constructing, and maintaining the infrastructure and systems needed to collect, store, process, and analyze large volumes of data. Work with various data sources and formats, ensuring data is reliable, scalable, and accessible for analytical and operational purposes. Include developing and optimizing data pipelines, integrating data from different systems, ensuring data quality and security, and collaborating with data scientists and analysts.
1. What’s ETL, and why is it essential in data engineering?
Ans:
ETL stands for Extract, Transform, cargo. It’s a critical process in data engineering that involves rooting data from various sources, transubstantiating it into a usable format, and loading it into a destination system, frequently a data storehouse. This process ensures data thickness, trustability, and availability, which are essential for accurate analysis and decision- timber.
2. What methods can be implemented to ensure data integrity and quality in data channels?
Ans:
- Ensuring data quality and integrity involves enforcing several strategies, similar to data confirmation checks, error running mechanisms, and data profiling.
- Regular checkups and anomaly discovery algorithms help identify and amend inconsistencies.
- Using standardized data formats and schemas prevents disagreement.
- Automated testing of data channels ensures that data metamorphoses maintain delicacy.
- Also, establishing data lineage provides transparency and traceability, which are pivotal for keeping data responsible over time.
3. Explain the difference between batch processing and sluice processing.
Ans:
Batch processing involves recycling large volumes of data at listed intervals, which is suitable for operations that do not bear real-time data analysis, similar to end-of-day reporting. Stream processing, on the other hand, deals with nonstop data input and processes it in real-time or near-real-time, making it ideal for time-sensitive operations like fraud discovery and live analytics.
4. What common challenges arise with big data, and how can they be addressed?
Ans:
- Handling large volumes of data.
- Ensuring data quality.
- Maintaining effective data processing pets.
To address these, using distributed calculating fabrics like Apache Hadoop and Spark is essential. Enforcing robust ETL processes helps manage data quality. Scalability is achieved through pall platforms that give flexible storehouse and cipher coffers.
5. How to approach designing a data storehouse?
Ans:
Designing a data storehouse starts with understanding business conditions and data sources. The coming step involves choosing a suitable armature, similar to the star or snowflake schema, to ensure influential data association and reclamation. ETL processes are also designed to integrate and transfigure data from various sources into the storehouse. Data partitioning, indexing, and normalization strategies are enforced to optimize performance.
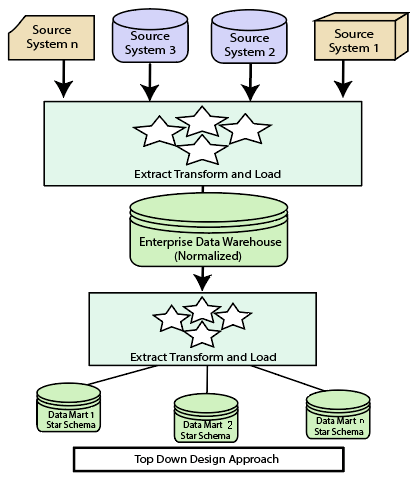
6. What tools and technologies are generally used for data engineering tasks?
Ans:
Tools and technologies include Apache Hadoop and Apache Spark for big data processing and Apache Kafka for real-time data streaming. ETL tools like Apache NiFi and Talend grease data integration workflows. Pall platforms like AWS, Azure, and Google Cloud give scalable storehouses and cipher coffers. SQL and NoSQL databases, similar to PostgreSQL and MongoDB, are used for structured and unstructured data operations independently.
7. What is data partitioning, and why is it essential in significant data surroundings?
Ans:
- Data partitioning involves dividing a large dataset into lower, more manageable pieces, frequently grounded on specific criteria like date, region, or user ID.
- This practice enhances query performance and parallel processing by allowing operations to be executed on lower data parts.
- In significant data surroundings, partitioning is pivotal for optimizing storehouses, reducing query quiescence, and perfecting the effectiveness of data reclamation.
- It also aids in balancing the workload across distributed systems, ensuring that processing coffers are used effectively.
8. How to handle schema elaboration in a data storehouse?
Ans:
Handling schema elaboration involves enforcing strategies to acclimatize to changes in the data structure without dismembering ongoing processes. Interpretation control mechanisms and backward-compatible changes help manage this elaboration easily. Using schema-on-read approaches allows for inflexibility in interpreting data as it evolves.
9. Explain the CAP theorem and its applicability to distributed databases.
Ans:
- The CAP theorem, proposed by Eric Brewer, states that a distributed database can only simultaneously achieve two out of three parcels: thickness, Vacuum, and Partition Forbearance.
- In the environment of distributed databases, understanding the CAP theorem helps masterminds make informed trade-offs grounded on operation conditions, ensuring optimal system design and trustability.
10. What are the crucial differences between relational databases and NoSQL databases?
Ans:
| Feature | Relational Databases | NoSQL Databases |
|---|---|---|
| Data Model | Structured, tabular (rows and columns) | Flexible, can be document, key-value, graph, or column-family |
| Schema | Fixed schema, predefined before data entry | Dynamic schema, can evolve without downtime |
| Scalability | Vertical scaling (adding more power to existing machines) | Horizontal scaling (adding more machines to the pool) |
| Query Language | SQL (Structured Query Language) | Varies by database type (e.g., JSON-based queries, CQL for Cassandra) |
11. How to optimize SQL queries for better performance?
Ans:
Optimizing SQL queries involves several ways similar to indexing, which speeds up data reclamation by creating a fast lookup path. Query optimization also includes:
- Jotting effective joins.
- Avoiding gratuitous columns in SELECT statements.
- Using WHERE clauses to sludge data beforehand.
Regularly streamlining statistics ensures the database machine has the most data distribution information, abetting in better query planning.
12. What’s the part of data governance in a data engineering design?
Ans:
Data governance involves establishing programs and procedures to ensure data quality, security, and compliance. It provides a frame for managing data means, defining data power, and enforcing norms for data operation and storehouse. It also includes monitoring and auditing data processes to describe and address issues instantly. Data engineering design, robust governance practices grease dependable data operation.
13. How to ensure data security in data channels?
Ans:
Ensuring data security involves enforcing encryption both in conveyance and at rest to protect sensitive data from unauthorized access. Access controls and authentication mechanisms circumscribe data access to authorized labour force only. Regular checkups and monitoring help describe and respond to security breaches. Secure rendering practices and regular vulnerability assessments alleviate implicit pitfalls.
14. Describe a situation involving troubleshooting a complex data channel issue.
Ans:
- In a former design, I encountered a data channel that was intermittently failing due to inconsistent data formats from one of the sources.
- Enforcing data confirmation checks at various stages of the channel helped insulate the problematic data entries.
- After coordinating with the source data platoon to amend the format issues, I streamlined the ETL scripts to handle similar inconsistencies more gracefully in the future.
- Nonstop monitoring assured the channel’s stability post-fix, significantly reducing time-out.
15. What strategies are used for data backup and disaster recovery?
Ans:
For data backup, regular shots of the data are taken and stored in geographically dispersed locales to help prevent data loss due to localized failures. Incremental backups are listed to minimize storehouse costs and speed up the backup process. Disaster recovery strategies include creating a comprehensive recovery plan that outlines the way to restore data and continue operations snappily.
16. How to handle real-time data processing in systems?
Ans:
Handling real-time data processing involves using tools like Apache Kafka for sluice processing and Apache Flink or Spark Streaming for real-time analytics. Data is ingested through streaming platforms and reused incontinently to give up-to-date perceptivity. Enforcing windowing operations allows aggregation and analysis over specific time frames. Ensure high Vacuity and low quiescence are critical, so the structure is designed to gauge horizontally.
17. How to handle indistinguishable data in a dataset?
Ans:
- Handling indistinguishable data involves relating and removing spare entries to maintain data integrity and delicacy.
- Data profiling tools can help identify duplicates by comparing crucial attributes.
- In ETL processes, deduplication can be enforced during the metamorphosis phase.
- Regular checkups and data quality checks ensure that duplicates are detected and addressed instantly, therefore conserving the trustability of the dataset for analysis.
18. What are the benefits of using a pall- ground data storehouse like Amazon Redshift or Google BigQuery?
Ans:
Pall-ground data storages like Amazon Redshift and Google BigQuery offer scalability, allowing businesses to handle growing data volumes without significant structure investments. Due to their distributed architecture, they provide high performance and fast query prosecution. Managed services reduce the functional outflow of conservation and updates.
19. Explain the conception of a data lake and how it differs from a data storehouse.
Ans:
The data lake is the storehouse depository that holds vast quantities of raw, unshaped, or semi-structured data in the native format until it demands analysis. Unlike a data storehouse, which stores reused and structured data, a data lake accommodates different data types, including logs, vids, and images. This inflexibility allows data scientists to run various analytics and machine literacy models on the raw data.
20. How to apply and manage data versioning in data engineering systems?
Ans:
- Data versioning involves shadowing changes to datasets and ensuring that different performances of the data are accessible for analysis and auditing.
- Enforcing interpretation control can be achieved through data operation tools that support snapshotting and time trip features, similar to Delta Lake or Apache Hudi.
- These tools allow for rollback capabilities and give a literal view of the data. Also, maintaining detailed metadata and change logs helps in tracking the elaboration of the dataset.
- Versioning ensures data thickness and reproducibility, which is critical for data-driven decision- timber and nonsupervisory compliance.
21. What are some stylish practices for designing scalable data channels?
Ans:
Designing scalable data channels involves modularizing the channel into separate, applicable factors that can be individually developed and gauged. Exercising distributed processing fabrics like Apache Spark ensures the channel can handle large data volumes efficiently. Enforcing robust error running and monitoring mechanisms allows for quick identification and resolution of issues.
22. What part does data listing play in data engineering?
Ans:
Data listing involves creating a comprehensive force of data means, furnishing metadata and environment to grease data discovery, governance, and operation. A data roster helps data masterminds and judges understand data lineage, track data sources, and assess data quality. It promotes data democratization by making data means accessible and accessible across the association.
23. How to manage the transfer of data between several platforms or systems?
Ans:
- The process of preparing and carrying out the transfer of data from one system to another while ensuring data integrity and minimum time-out.
- The process starts with assessing source and target systems, mapping data structures, and developing a migration strategy.
- ETL tools grease data metamorphosis and transfer, ensuring comity with the target system.
- Post-migration checkups confirm that data has been rightly transferred and integrated.
24. Explain the concept of data sharding and its benefits.
Ans:
Data sharding involves partitioning a database into lower, more manageable pieces called shards, each hosted on separate servers. This vertical scaling fashion enhances performance by distributing the cargo across multiple machines, enabling the resemblant processing of queries. Sharding reduces contention and improves response times for high-business operations.
25. List out objects created by creating statements in MySQL.
Ans:
- Database
- Index
- Table
- User
- Procedure
26. What is the significance of data normalization in database design?
Ans:
Data normalization is the process of organizing data to minimize redundancy and facilitate data integrity. This is achieved by dividing a database into tables and defining connections between them according to normalization rules. Normalization enhances data thickness and reduces the threat of anomalies during data operations like insertions, updates, and elisions. It also optimizes storehouse effectiveness and simplifies database conservation.
27. How to manage and cover data channel performance?
Ans:
Managing and covering data channel performance involves using criteria and tools to ensure adequate data inflow and processing. Crucial performance pointers( KPIs) similar to outturn, dormancy, and error rates are tracked to assess channel health. Monitoring tools like Prometheus, Grafana, and ELK Stack give real-time perceptivity and caution for anomalies.
28. What approach ensures data sequestration and compliance in data engineering systems?
Ans:
Managing and covering data channel performance involves using criteria and tools to ensure adequate data inflow and processing. Crucial performance pointers( KPIs) similar to outturn, dormancy, and error rates are tracked to assess channel health. Monitoring tools like Prometheus, Grafana, and ELK Stack give real-time perceptivity and caution for anomalies. Enforcing logging and tracing helps diagnose issues and optimize performance.
29. What’s the significance of data modelling in data engineering?
Ans:
Data modelling is pivotal for defining the structure, connections, and constraints of the data to be stored in databases, ensuring thickness and clarity. It facilitates effective data reclamation and manipulation by furnishing an explicit schema. Effective data modelling supports scalability, as it allows for the accommodation of unborn data conditions without expansive rework.
30. How to handle missing data in datasets?
Ans:
Handling missing data involves strategies like insinuation, where missing values are replaced with estimates grounded on other data. Ways are similar to mean, standard, or mode insinuation, and more sophisticated styles like k- nearest neighbours or retrogression insinuation can be applied. Relating patterns in missing data can also give perceptivity to underpinning issues.
31. What’s Apache Kafka, and how is it used in data engineering?
Ans:
- Apache Kafka is a distributed event streaming platform used for erecting real- time data channels and streaming operations.
- It’s designed to handle high outturn, low quiescence, and fault-tolerant data aqueducts.
- In data engineering, Kafka is used to ingest, process, and transport large volumes of data from various sources to different destinations, similar to data lakes, storage, and analytics platforms.
- Kafka’s capability to cushion data allows for the decoupling of data directors and consumers, enhancing system scalability and trustability.
32. Explain the part of unity tools like Apache Airflow in managing data workflows.
Ans:
Orchestration tools like Apache Airflow are essential for automating, cataloging, and covering data workflows. Tailwind allows data masterminds to define workflows as Directed Acyclic Graphs( DAGs), making complex data channels manageable and ensuring task dependencies are executed in the correct order. With features like dynamic task generation, retries, and waking, Tailwind helps maintain the trustability and robustness of data channels.
33. What’s the significance of data warehousing in a business terrain?
Ans:
Data warehousing creates a single repository for data from several sources. Centralized depository, enabling comprehensive analysis and reporting. This centralized approach supports better decision-making by furnishing a unified view of business operations and client geste. Data storages are optimized for query performance, allowing complex logical queries to be executed efficiently.
34. How to handle schema changes in a product database?
Ans:
Handling schema changes in a product database involves careful planning and prosecution to minimize disruptions. Interpretation control tools and migration fabrics, such as Liquibase or Flyway, help manage schema changes completely. Changes are generally applied in a phased approach, including development, testing, and carrying surroundings before product deployment.
35. What are some common data engineering challenges, and how to overcome them?
Ans:
- Common data engineering challenges include handling large data volumes, ensuring data quality, and maintaining channel trustability.
- Prostrating these involves using scalable technologies like Pall platforms and distributed processing fabrics.
- Enforcing robust data confirmation and cleaning processes ensures high data quality.
- Using robotization tools for monitoring and managing data channels helps maintain trustability and resolve issues quickly.
36. Describe the experience with real-time data analytics.
Ans:
My experience with real-time data analytics includes designing and enforcing data channels that reuse streaming data using tools like Apache Kafka and Spark Streaming. These channels ingest, process, and dissect data in near real-time, furnishing timely perceptivity for operations similar to fraud discovery and client geste analysis. I’ve enforced windowing functions, aggregations, and joins to decide meaningful perceptivity from nonstop data aqueducts.
37. How to ensure the scalability and performance of a data storehouse?
Ans:
Ensuring the scalability and performance of a data storehouse involves optimizing query performance through indexing, partitioning, and proper schema design. Using pall- grounded data storages like Amazon Redshift or Google BigQuery allows for dynamic scaling of cipher and storehouse coffers grounded on demand. Enforcing data hiding and materialized views can significantly reduce query prosecution times.
38. What’s a Data Lake, and how does it differ from a traditional data storehouse?
Ans:
A Data Lake is a storehouse depository that can hold vast quantities of raw data in its native format, whether structured,semi-structured, or unshaped, unlike a traditional data storehouse, which stores reused, Properly organized data that has been enhanced for reporting and querying. This inflexibility allows data scientists to perform advanced analytics, including machine literacy, on raw data.
39. How to apply data security in data engineering systems?
Ans:
- Enforcing data security involves encryption of data both in conveyance and at rest to cover sensitive information.
- Regular security checkups and compliance checks help maintain adherence to regulations like GDPR and HIPAA.
- Employing data masking and anonymization ways protects particular data.
- Monitoring and logging all access and conditioning give a trail for auditing and relating implicit security breaches.
- Enforcing these measures inclusively ensures robust data security and sequestration.
40. What’s data lineage, and why is it important?
Ans:
Data lineage refers to the shadowing of data as it moves through various stages and metamorphoses within a system. It provides visibility into the data’s origin, metamorphoses, and destination, offering a complete inspection trail. This transparency is pivotal for debugging, auditing, and ensuring data quality, as it helps trace crimes back to their source.

Get JOB Data Engineer Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. Describe a situation in which a slow-performing query required optimization.
Ans:
- The query involved multiple joins and aggregations on large tables.
- To optimize it, Anatomized the query prosecution plan to identify backups. Also created applicable indicators on the columns used in joins and where clauses, which significantly bettered performance.
- Also partitioned the tables to reduce the quantum of data scrutinized.
- After these optimizations, the query prosecution time was reduced from several twinkles to just a few seconds, ensuring timely report generation.
42. What’s a Data Mart, and how is it different from a Data Warehouse?
Ans:
A Data Mart is a subset of a data storehouse concentrated on a specific business area or department, similar to deals, finance, or marketing. While a data storehouse serves as a centralized depository for the entire association, adding up data from multiple sources, a data emporium provides targeted data for a particular group of users. This concentrated approach allows for more effective and applicable data analysis for specific business functions.
43. How to handle real-time data ingestion and processing?
Ans:
Handling real-time data ingestion and processing involves using streaming platforms like Apache Kafka to collect and stream data continuously. Tools like Apache Flink or Spark Streaming process the data in real time, allowing for immediate perceptivity and conduct. Enforcing windowing ways summations data over specific intervals, making it suitable for real-time analytics.
44. What is schema-on-read, and in what scenarios is it used?
Ans:
- Schema-on-read is a data processing strategy where the schema is applied to the data only when it’s read, not when it’s written.
- This approach is generally used in data lakes, allowing raw data to be ingested without administering a predefined schema.
- It provides inflexibility to accommodate different data formats and structures, supporting exploratory data analysis and machine literacy.
- Schema-on-read is helpful when dealing with unshaped or semi-structured data, enabling judges to define the schema grounded on the specific conditions of their queries.
45. How to manage and gauge ETL processes?
Ans:
Managing and spanning ETL processes involves using robust ETL fabrics and tools like Apache NiFi, Talend, or AWS Cohere that support distributed processing. Automating ETL workflows with unity tools like Apache Airflow ensures effective and dependable prosecution. Enforcing resemblant processing and data partitioning enhances performance and scalability. Regular monitoring and logging help describe and resolve issues instantly.
46. What strategies are used in optimizing data storehouse and reclamation?
Ans:
Optimizing data storehouse and reclamation involves using effective data partitioning and indexing ways to reduce query response times. Choosing the proper storehouse format, similar to Parquet or ORC for a columnar storehouse, improves contraction and query performance. Enforcing data caching strategies ensures that constantly penetrated data is readily available. Using denormalization ways where applicable can reduce the need for complex joins.
47. What are some crucial considerations when designing a data armature for a new design?
Ans:
Designing a data armature involves understanding the design’s data conditions, such as data volume, variety, and haste. It’s pivotal to choose applicable storehouse results, like relational databases for structured data or data lakes for unshaped data. Scalability and inflexibility should be prioritized to accommodate unborn growth and changes. Data governance and security measures must be integrated to ensure compliance and cover sensitive information.
48. How to approach testing and validating in data channels?
Ans:
- Testing and validating data channels involve setting up unit tests to check individual factors, similar to metamorphoses and data integrity checks.
- Integration tests ensure that different corridors of the channel work together seamlessly.
- Data confirmation checks, including schema confirmation and null checks, ensure data quality.
- Automated testing fabrics can be used to streamline the testing process and ensure thickness across deployments.
49. What’s the part of metadata in data engineering?
Ans:
Metadata provides critical information about data, including its source, structure, metamorphosis processes, and operation. It enhances data discoverability, allowing users to find and understand the data they need snappily. Metadata operation helps maintain data quality and thickness by tracking data lineage and metamorphoses. It supports data governance by establishing data power, access warrants, and compliance conditions.
50. Explain the conception of data deduplication and its significance.
Ans:
Data deduplication involves relating and removing indistinguishable records from a dataset to ensure data quality and storehouse effectiveness. This process reduces storehouse costs by barring spare data and improves the delicacy of data analysis and reporting. Deduplication ways can be enforced during data ingestion, metamorphosis, or as a periodic conservation task.
51. What’s the difference between batch processing and sluice processing?
Ans:
- Batch processing involves recycling large volumes of data at listed intervals, generally used for tasks like end-of-day reporting and data warehousing.
- It’s effective for handling large datasets that take time to process. Stream processing, on the other hand, deals with nonstop data aqueducts in real-time, enabling immediate analysis and response to data events.
- This approach is ideal for operations like fraud discovery, real-time analytics, and monitoring.
- While batch processing focuses on output and effectiveness, sluice processing prioritizes low quiescence and timely perceptivity.
52. How to manage interpretation control for data and data models?
Ans:
Managing interpretation control for data and data models involves using versioning systems and tools that track changes and updates. Data versioning tools like Delta Lake or Apache Hudi allow for time trip queries and literal data analysis. Enforcing automated migration scripts ensures harmonious updates across surroundings. Regular reviews and checkups ensure that interpretation control practices are stuck to and effective.
53. What are the benefits of using a columnar storehouse format like Parquet or ORC?
Ans:
Columnar storehouse formats like Parquet and ORC offer significant benefits for data storehouse and query performance. They allow for effective contraction, reducing storehouse costs by garbling data within columns rather than rows. Columnar formats enable faster query performance by allowing data processing machines to check only the applicable columns demanded for a query, reducing I/ O operations.
54. Describe pall-grounded data results?
Ans:
My experience with pall- ground data results include using platforms like AWS, Google Cloud, and Azure for data storehousing, processing, and analytics. I have enforced scalable data channels using services like AWS Cohere for ETL, Amazon Redshift for data warehousing, and Google BigQuery for real-time analytics. Pall storehouse results like Amazon S3 give cost-effective and durable storehouses for large datasets.
55. How to handle data metamorphosis and sanctification?
Ans:
- Data metamorphosis and sanctification involve converting data into a suitable format and correcting inaccuracies to ensure data quality.
- Transformation tasks include homogenizing, adding up, and joining data from different sources to fit a unified schema.
- Sanctification involves detecting and amending crimes, similar to removing duplicates, filling in missing values, and correcting data types.
- Automated scripts and confirmation rules help maintain data thickness and delicacy.
56. How to ensure data thickness in distributed systems?
Ans:
Ensuring data thickness in distributed systems involves enforcing strategies like distributed deals, agreement algorithms, and data replication. Ways like the Two-Phase Commit( 2PC) protocol and Paxos or Raft algorithms help achieve agreement across bumps. Using eventual thickness models allows systems to handle high vacuity and partition forbearance while ensuring data confluence over time.
57. What are some common data channel design patterns have used?
Ans:
- Common data channel design patterns include the ETL( Excerpt, transfigure, cargo) pattern, which is used for batch processing to consolidate data from multiple sources.
- The ELT( Extract, cargo, transfigure) pattern is another, where data is loaded into a data lake or storehouse before metamorphosis, enabling further inflexibility in data processing.
- Stream processing patterns, using tools like Apache Kafka and Apache Flink, handle real-time data ingestion and analysis.
- Using micro-batch processing with tools like Apache Spark Streaming offers a balance between batch and real-time processing.
58. How to use indexing to ameliorate query performance?
Ans:
Indexing improves query performance by creating data structures that allow quick reclamation of records without surveying the entire table. Indicators, similar to B- B-trees or hash indicators, enable effective lookups, sorting, and filtering grounded on listed columns. Choosing the right columns to indicator, generally those used in WHERE clauses and joins, significantly enhances query speed.
59. How does a data storehouse differ from a functional database?
Ans:
A data storehouse is specifically designed for analysis and reporting. It summates data from multiple sources and organizes it into a format that’s optimized for querying and data reclamation, frequently using denormalized structures to speed up read operations. In discrepancy, a functional database (or OLTP database) is designed for real-time sale processing, handling a large number of short deals that bear immediate thickness.
60. separate between a Data mastermind and a Data Scientist?
Ans:
- A Data mastermind primarily focuses on erecting structure and armature for data generation, collection, and storehouse.
- They design, construct, install, test, and maintain vastly scalable data operation systems.
- This includes ensuring that data flows between servers and operations with high performance and trustability.
- In discrepancy, a Data Scientist analyzes and interprets complex digital data to help a company in its decision- timber.

Develop Your Skills with Data Engineer Certification Training
Weekday / Weekend BatchesSee Batch Details61. What happens when the Block Scanner detects a spoiled data block?
Ans:
When the Block Scanner in a Hadoop terrain detects a spoiled data block, it initiates several processes to ensure data trustability and system integrity. First, it reports the corruption to the NameNode, which also marks the spoiled block and removes it from the list of available blocks for processing. The NameNode also requests that other DataNodes holding clones of the spoiled block corroborate their copies.
62. What are the two dispatches that NameNode gets from DataNode?
Ans:
The two primary dispatches that a NameNode receives from a DataNode in the Hadoop ecosystem are Twinkle and Blockreport. Jiffs are transferred periodically by each DataNode to inform the NameNode that it’s still performing and available to perform data operations. This communication helps the NameNode maintain a list of active DataNodes. All of the blocks are listed in the block report.
63. How can emplace a significant data result?
Ans:
- Planting a significant data result involves several critical ways, starting with defining specific business objects and data requirements.
- It would help if also chose an applicable big data frame(e.g., Hadoop, Spark) and structure, which could be on- demesne or in the pall, depending on scalability requirements and cost considerations.
- Configuring and tuning the system to optimize performance for specific tasks is essential.
64. separate between list and tuples?
Ans:
In Python, sequence data structures like lists and tuples can both hold a collection of particulars. Each has different characteristics suited to specific use cases. Lists are variable, meaning they can be modified after their creation; particulars can be added, removed, or changed. Lists are generally used for data that are intended to be altered during program prosecution.
65. Explain the conception of eventual thickness and its trade-offs.
Ans:
Eventual thickness is a thickness model used in distributed systems where, given enough time, all clones of a data item will meet the same value. It allows for advanced vacuity and partition forbearance, as systems can continue to operate indeed if some bumps are temporarily inconsistent. The trade-off is that read operations return banal data once the system converges, which may only be suitable for some operations.
66. What are the advantages and disadvantages of using NoSQL databases?
Ans:
NoSQL databases offer several advantages, including scalability, inflexibility in handling different data types, and high performance for certain types of queries. They’re designed to handle large volumes of unshaped or semi-data, making them ideal for extensive data operations. NoSQL databases can be gauged horizontally by adding further servers, furnishing a cost-effective result for growing datasets.
67. What’s the CAP theorem, and how does it apply to distributed databases?
Ans:
- The CAP theorem states that in a distributed data system, it’s insolvable to achieve thickness, Vacuity, and Partition forbearance contemporaneously.
- Thickness ensures that all bumps see the same data at the same time, Vacuity guarantees that every request receives a response, and partition forbearance denotes that the system keeps running even when the network fails.
- For illustration, systems like Amazon DynamoDB prioritize vacuity and partition forbearance, accepting eventual thickness.
68. What are the benefits of using containerization for data engineering tasks?
Ans:
Containerization, using tools like Docker, offers significant benefits for data engineering tasks, including thickness, scalability, and portability. Containers synopsize operations and their dependencies, ensuring that they run constantly across different surroundings. This thickness reduces issues related to terrain differences and simplifies deployment processes.
69. What’s the significance of data normalization, and when it would denormalize data?
Ans:
- Data normalization organizes data to minimize redundancy and reliance by dividing large tables into lower, related tables.
- This process enhances data integrity and reduces storehouse conditions, making it easier to maintain and modernize data.
- Still, normalization can lead to complex queries with multiple joins, impacting performance.
- Denormalization involves combining tables to reduce joins and perfecting query speed at the expense of increased redundancy.
70. How to ensure compliance with data sequestration regulations similar to GDPR and CCPA?
Ans:
Ensuring compliance with data sequestration regulations like GDPR and CCPA involves enforcing robust data governance and protection measures. Data encryption, both at rest and in conveyance, protects sensitive information from unauthorized access. Access controls and auditing mechanisms ensure that only the authorized labour force can pierce or modify data.
71. What are the benefits and challenges of using a data mesh armature?
Ans:
Data mesh armature decentralizes data power and operation, promoting sphere-acquainted data stewardship and enhancing scalability. Each sphere platoon owns and manages its data, enabling brisk, more effective data delivery and reducing backups. This approach fosters collaboration and aligns data products with business requirements, perfecting data quality and applicability.
72. What are the benefits of using a microservices armature for data engineering?
Ans:
- A microservices armature decomposes a data engineering system into lower, independent services, each running specific tasks similar to data ingestion, metamorphosis, and storehouse.
- This modular approach allows brigades to develop, emplace, and scale services singly, enhancing agility and reducing time to vend.
- Microservices can be optimized and gauged according to their specific workloads, perfecting overall system performance and resource application.
- Fault insulation ensures that issues in one service don’t impact the entire system, enhancing trustability.
73. How to approach capacity planning for data storehouse and processing?
Ans:
Capacity planning for data storehouse and processing involves soothsaying future data growth and resource needs to be grounded on literal data and business protrusions. Regularly covering operation patterns and performance criteria helps identify trends and anticipate demand. Enforcing scalable storehouse results, similar to pall-grounded services with elastic capabilities, ensure that coffers can be acclimated as demanded.
74. Explain the features of Hadoop.
Ans:
Hadoop is a robust frame designed for the distributed storehouse and processing massive data volumes utilizing basic programming concepts across computer clusters. Its core factors include Hadoop Distributed Train System( HDFS) for high-outturn access to operation data and MapReduce for resemblant processing of vast volumes of data. Hadoop’s ecosystem includes fresh tools like Apache Hive, HBase, and Pig to grease data processing and operation.
75. Explain the Star Schema.
Ans:
- Star schema is a traditional database schema used in data warehousing and business intelligence operations.
- It features a central fact table containing quantitative data( criteria ) and girding dimension tables containing descriptive attributes related to the requirements.
- The fact table holds the keys to each dimension table, easing effective querying.
76. Explain FSCK?
Ans:
FSCK, or train System Check, is a tool used to check the integrity of the filesystem in Unix and Unix- like operating systems. It examines and repairs inconsistencies in train systems to help prevent corruption and ensure regular system operation. FSCK checks for a variety of train system problems, including directory inconsistencies, lost clusters, orphaned lines, and incorrect train sizes.
77. Explain the Snowflake Schema.
Ans:
The snowflake schema is a more complex interpretation of the star schema used in data warehousing. In it, dimension tables are regularized and unyoked into fresh tables to exclude redundancy and facilitate data integrity. This schema type reduces the quantum of data storehouse needed compared to the star schema but can lead to more complex queries due to the fresh joins demanded.
78. Distinguish between the Star and Snowflake Schema.
Ans:
The star and snowflake schemas are both used in data warehousing but differ in their structure and complexity. The star schema has a single fact table connected to multiple dimension tables with no normalization, making it simple and fast for querying. In discrepancy, the snowflake schema involves normalization of the dimension tables, breaking them into lower, related tables.
79. Explain the Hadoop Distributed Train System.
Ans:
The star and snowflake schemas are both used in data warehousing but differ in their structure and complexity. The star schema has a single fact table connected to multiple dimension tables with no normalization, making it simple and fast for querying. In discrepancy, the snowflake schema involves normalization of the dimension tables, breaking them into lower, related tables.
80. List various modes in Hadoop.
Ans:
Hadoop can operate in three different modes grounded on its configuration and deployment conditions Standalone( Local) Mode, Pseudo-Distributed Mode, and Completely Distributed Mode. Standalone mode is the dereliction, where Hadoop runs on a single machine without using HDFS or network connectivity, exercising the original train system.
81. What Is Twinkle in Hadoop?
Ans:
- In Hadoop, a twinkle is a signal used by the DataNodes to report their status to the NameNode at regular intervals. This medium is pivotal for maintaining the overall health of the Hadoop cluster.
- The twinkle signals that a DataNode is performing rightly and connected to the network.
- This ensures data vacuity and trustability in the distributed terrain.
82. What’s FIFO Scheduling?
Ans:
FIFO Scheduling, or First– First- Scheduling, is one of the simplest forms of job scheduling used in Hadoop’s MapReduce frame. In FIFO, jobs are executed in the order they’re submitted to the job line, without any prioritization. Each job occupies the line and accesses the system coffers until it’s wholly executed, following which the coming job in the line is reused.
83. What data is stored in NameNode?
Ans:
The NameNode in Hadoop’s armature stores the metadata of the Hadoop Distributed Train System( HDFS). This metadata includes the directory tree of all lines in the train system and tracks where, across the cluster, the train data is kept, including a record of the locales of all the blocks of each train. The NameNode also maintains information about the replication situations of blocks, warrants, and other details.
84. What is meant by rack mindfulness?
Ans:
- Rack mindfulness is a concept used in the Hadoop ecosystem to ameliorate network performance and data trustability.
- It refers to the system’s capability to understand the physical layout of the cluster in terms of rack and knot locales.
- By knowing how bumps are distributed across racks, Hadoop can optimize data placement and minimize network business between racks, which is slower and more expensive than business within the same rack.
- When data is written to HDFS, Hadoop places clones of data blocks on different racks.
85. What are the functions of Secondary NameNode?
Ans:
The Secondary NameNode in Hadoop doesn’t serve as a backup to the Primary NameNode but instead assists in managing the train system namespace. Its central part is to periodically consolidate the namespace image stored in the NameNode by downloading the current filesystem image and the rearmost edits log, incorporating them locally, and also transferring this fresh image back to the NameNode.
86. Define Hadoop streaming.
Ans:
Hadoop Streaming is a mileage that allows users to produce and run Chart/ Reduce jobs with any executable or script as the mapper and reducer. It’s used primarily for creating Hadoop operations in languages other than Java, similar to Python or Perl. Hadoop Streaming works by passing data between the Hadoop frame and the external programs via standard input and affair aqueducts, converting these aqueducts into data that the MapReduce frame can reuse.
87. Explain the principal liabilities of a data mastermind.
Ans:
Data masterminds are primarily responsible for designing, erecting, and maintaining the armature used for data generation, collection, storehouse, and analysis. This includes creating and managing large-scale processing systems and databases. They also develop, construct, test, and maintain vastly scalable data operation systems, ensuring that all data results are erected for performance and fault forbearance.
88. How to achieve security in Hadoop?
Ans:
- Achieving security in Hadoop involves several layers, starting with authentication, using Kerberos, which is the most robust system for securing against unauthorized access.
- Authorization must be managed through tools like Apache Ranger or Apache Sentry, which give a way to set fine- granulated access control on data stored in Hadoop.
- Data encryption, both at rest and in conveyance, ensures data is undecipherable to unauthorized users, exercising HDFS encryption and SSL/ TLS for data transmitted over the network.
89. List necessary fields or languages used by the data mastermind.
Ans:
Data masterminds use a variety of programming languages and technologies depending on their specific tasks. Critical programming languages include Python and Java for writing data recycling jobs and scripts. SQL is pivotal for data manipulation and reclamation. For significant data surroundings, knowledge of Hadoop ecosystem technologies similar to Hive, Pig, and Spark is essential.
90. What’s Metastore in Hive?
Ans:
- The Metastore in Hive is a central depository of metadata for Hive tables and partitions, including schema and position information, as well as the metadata for Hive’s structured data.
- It serves as a critical element that allows Hive to manage and query large datasets abiding in distributed storehouses efficiently.
- The Metastore can run in a bedded mode where it resides within the Hive service itself, or it can be configured as a standalone service backed by a relational database similar to MySQL, PostgreSQL, or Oracle, which allows multiple users and operations to manage and pierce the metadata coincidently.




