
Last updated on 11th Apr 2024| 4173
Azure Databricks is a cloud-based data analytics platform offered by Microsoft Azure, designed to simplify and accelerate big data processing and machine learning tasks. It’s built on top of Apache Spark, a powerful open-source distributed computing framework known for its speed and versatility in processing large-scale data sets. By leveraging Spark’s capabilities, Azure Databricks provides a unified platform for various data processing tasks, including batch processing, streaming analytics, machine learning, and graph processing.
1. What is Azure Databricks?
Ans:
The analytics platform Azure Databricks is designed to work best with the Microsoft Azure cloud services platform. The partnership between Microsoft and Databricks makes an Apache Spark-based analytics platform that is quick, simple, and collaborative possible. It allows business analysts, data engineers, and data scientists to collaborate in a safe and engaging environment. Azure Databricks offers faster processes and an interactive workspace that facilitates the collaborative development of machine learning models and data analytics solutions.
2. How do Azure Databricks integrate with Azure services?
Ans:
- Azure Databricks’ usability and functionality are improved by its easy integration with other Azure services.
- Azure Event Hubs and Azure IoT Hub for real-time data intake, Azure SQL Data Warehouse for analytics and data warehousing, Azure Data Lake Storage for scalable and secure data storage, and Azure Machine Learning for developing and deploying machine learning models are all compatible with it.
3. What are Databricks notebooks, and how are they used?
Ans:
Azure Databricks uses Databricks notebooks, which are web-based collaborative interfaces for tasks related to data processing, visualization, and machine learning. They enable team members to collaborate in their preferred language by supporting a variety of programming languages, such as Python, Scala, R, and SQL. ETL pipeline and machine learning model construction, as well as interactive data exploration and visualization, are all done in notebooks.
4. Explain the role of Apache Spark in Azure Databricks.
Ans:
- The distributed computing system Apache Spark is available as open-source software and offers an interface for programming whole clusters with implicit fault tolerance and data parallelism.
- Spark is the fundamental engine in Azure Databricks, processing massive datasets across multiple clustered computers. It makes high-speed analytics and data processing possible for workloads involving streaming, machine learning, and batch processing.
5. Explain the difference between Azure Databricks and HDInsight.
Ans:
| Feature | Azure Databricks | HDInsight |
|---|---|---|
| Architecture | Fully managed Apache Spark-based analytics platform | Managed cloud-based service offering various open-source big data technologies |
| Ease of Use | Provides a unified and collaborative workspace, interactive notebooks, and easy-to-use APIs | Requires more manual configuration and management of clusters |
| Use Cases | Well-suited for data exploration, interactive analytics, machine learning, and real-time processing | Suitable for batch processing, ETL pipelines, data warehousing, and real-time stream processing |
| Integration | Seamlessly integrates with Azure services like Azure Blob Storage, Azure Data Lake Storage, Azure SQL Database, and Azure Cosmos DB | Integrates with Azure services for data storage and processing |
6. How do Azure Databricks handle security and compliance?
Ans:
Azure Databricks comes with a plethora of security and compliance solutions designed to protect data and comply with regulatory requirements. These include network security via the Azure Virtual Network integration, data encryption both in transit and at rest, identity and access management with Azure Active Directory, and compliance certifications for global standards.
7. Explain cluster management in Azure Databricks.
Ans:
- Azure cluster management The process of building, setting up, overseeing, and growing virtual machine clusters that run Apache Spark and Databricks applications is referred to as Databricks. Users have the option to establish the clusters manually or to automate the process using job scheduling.
- Features like auto-scaling, which modifies the number of virtual machines based on Workload, and cluster termination policies, which automatically shut down clusters to save money, are two ways that Databricks optimizes cluster usage.
8. What are the main components of Azure Databricks?
Ans:
Databricks Workspaces, Databricks Notebooks, Databricks Clusters, and Databricks Jobs are the primary parts of Azure Databricks. Workspaces provide engineers, analysts, and data scientists with a collaborative setting. Code, narrative writing, and data visualization may all be seen in interactive notebooks. Using optimized or standard virtual machines (VMs), clusters offer processing capability that can automatically grow to meet workload demands.
9. How do Azure Databricks support real-time data processing?
Ans:
With the help of structured streaming, an Apache Spark API that offers a quick, reliable, and scalable stream processing engine, Azure Databricks facilitates real-time data processing. This makes it possible to analyze real-time data streams coming from IoT devices, Azure Event Hubs, and Kafka. Similar to writing batch queries, users may create streaming queries that are conducted on moving data. This makes it easier for firms to infer machine learning models, create dashboards, and do real-time analytics, allowing them to act quickly and use the most recent data.
10. Explain the concept of Databricks MLflow and its use in Azure Databricks.
Ans:
- In Azure Databricks, MLflow integrates seamlessly, allowing users to track experiments, package code into reproducible runs, and share and collaborate on machine learning models.
- It supports logging parameters, code versions, metrics, and output files, making it simpler to compare different models. MLflow also facilitates the deployment of machine learning models to production, either on Databricks clusters or external platforms, streamlining the transition from development to deployment.
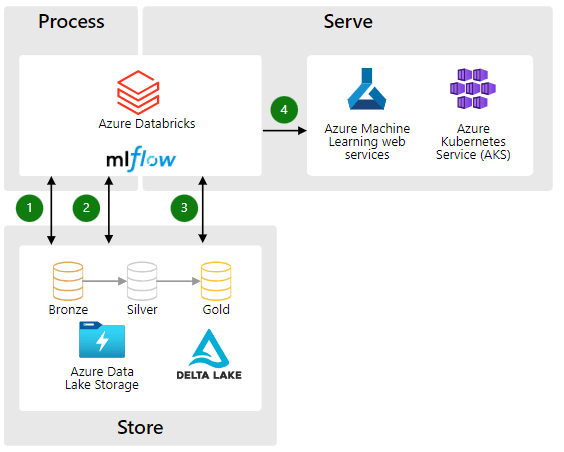
11. What is Autoloader in Azure Databricks, and what are its benefits?
Ans:
The Azure Databricks feature called Autoloader makes it easier to gradually and effectively load data into Delta Lake from cloud storage. It effectively processes new data files as they are received in storage sites such as Azure Data Lake Storage and Amazon S3 by utilizing file notification services and directory listing algorithms.
- Automating data loading activities to increase productivity.
- Lowering infrastructure costs by optimizing data input.
- Handling complicated ETL patterns with ease.
12. Discuss the significance of partitioning in Azure Databricks.
Ans:
Partitioning is the main concept for optimizing the speed of data processing tasks in Azure Databricks. The dataset may be divided into separate parts that may be handled in parallel, speeding up reads, writes, and query processing. The most effective partitioning strategies depend on the dataset and the types of queries that are utilized. Partitioning by date, for example, may greatly improve query speed for time-series data.
13. How does Azure Databricks optimize for cost management?
Ans:
Cost management may be optimized using several options offered by Azure Databricks. Clusters may dynamically scale up or down in response to workloads thanks to autoscaling, which guarantees resource efficiency and lowers over-provisioning expenses. Resource use restrictions can be put in place by cluster regulations to avoid unforeseen expenses. It is possible to schedule jobs during off-peak times to benefit from cheaper costs.
14. What role does Azure Databricks play in a data lakehouse architecture?
Ans:
- Azure Databricks plays a pivotal role in implementing the data lakehouse architecture, which combines the best elements of data lakes and data warehouses. With its native support for Delta Lake, Databricks enables a lakehouse by providing a transactional storage layer that ensures data reliability and quality.
- This allows for the scalability and flexibility of a data lake in handling large volumes of raw data and the governance, performance, and ACID transactions typically associated with data warehouses.
15. How do Azure Databricks facilitate collaborative data science and engineering?
Ans:
Azure Databricks offers a unified analytics workspace that supports numerous languages and frameworks, fostering cooperation amongst data scientists, engineers, and analysts. Teamwork is made easier with the collaborative notebooks feature, which enables members to write, run, and exchange code and results in real-time. Moreover, version control and continuous integration/continuous deployment (CI/CD) processes are supported by integration with GitHub and Azure DevOps, which boosts productivity.
16. What is the role of Azure Databricks in the modern data warehouse architecture?
Ans:
Azure Databricks is a potent data processing and transformation technology that powers high-speed analytics and artificial intelligence (AI) capabilities in contemporary data warehouse architectures. Large volumes of data from several sources can be ingested, prepared, and transformed before being loaded into Azure Synapse Analytics (previously SQL Data Warehouse) for additional analysis and reporting.
17. Explain how Azure Databricks handles data versioning and governance.
Ans:
Azure Databricks offers strong data versioning and governance features thanks to its interaction with Delta Lake. In order to guarantee data consistency and integrity between reads and writes, Delta Lake provides ACID transactions. Additionally, it enhances data governance by supporting data versioning, which enables users to access and return to prior versions of data for audits or to replicate results.
18. Discuss the scalability of Azure Databricks Azure.
Ans:
- Because of its scalability, Databricks can handle workloads of any size. It dynamically distributes resources by utilizing Azure’s global infrastructure, ensuring that data processing and analysis can adapt to demand.
- The platform supports cluster autoscaling, which dynamically modifies the cluster’s node count based on Workload. This improves both cost and performance. The platform’s scalability allows it to perform complex analytics, run machine learning models, process data in batches and in real-time, and all without the need for manual infrastructure management participation.
19. What is the significance of the Databricks Runtime, and how does it enhance performance?
Ans:
Specifically designed for Azure Databricks, the Databricks Runtime is a high-performance engine built on top of Apache Spark. It contains improvements and optimizations such as improved caching, execution optimizations, and optimized input/output for cloud storage systems that boost the efficiency of Spark processes. For high-performance data processing and ACID transactions, the runtime also interfaces with Delta Lake.
20. How do Azure Databricks support machine learning and AI workflows?
Ans:
Azure With integrated tools and APIs that make model construction, training, and deployment easier, Databricks supports machine learning and AI processes. The platform makes machine learning lifecycle management easier by including MLflow for model administration, experiment tracking, and deployment. Databricks further offers interaction with well-known frameworks like TensorFlow and PyTorch, as well as scalable machine learning libraries like MLlib for Spark.
21. What are the benefits of using Delta Lake with Azure Databricks?
Ans:
- Delta Lake improves Azure Databricks by offering a dependable and effective data storage layer that facilitates unified data processing, scalable metadata management, and ACID transactions.
- By guaranteeing data integrity through concurrent reads and writes and permitting rollback to earlier states for data auditing and compliance, it improves the quality and dependability of data in data lakes.
- Additionally, Delta Lake improves the efficiency of large data processing by optimizing query speed through data indexing and caching.
22. How do Azure Databricks ensure data privacy and compliance?
Ans:
Data privacy and compliance are given top importance in Azure Databricks, which integrates several security measures and regulatory requirements. By offering audit trails for forensic analysis and monitoring in compliance with the most important international privacy laws and regulations, Azure Databricks assists companies in meeting their compliance requirements.
23. Explain the process of data ingestion in Azure Databricks.
Ans:
Azure Databricks supports batch and real-time data processing requirements with many data intake options. Using Spark’s built-in data source APIs, data may be ingested for batch processing from Azure Blob Storage, Azure Data Lake Storage, or other cloud storage providers. Databricks uses Structured Streaming to enable a streaming data intake from sources such as Azure Event Hubs, Kafka, and IoT Hubs for real-time processing.
24. Describe the process of optimizing Spark jobs in Azure Databricks
Ans:
- Several techniques are used to optimize Spark tasks in Azure Databricks in order to boost efficiency and use fewer resources. Effective data partitioning allows users to reduce data shifting over the network and maximize parallel processing. It is possible to accelerate repeated access by keeping interim datasets in memory.
- Parquet and Delta’s effective compression and encoding algorithms are two examples of data formats that may drastically cut down on input/output time.
25. What strategies can be used for cost optimization in Azure Databricks?
Ans:
Effective resource management and use in Azure Databricks can lead to cost optimization. By adjusting resources in response to workload needs, autoscaling clusters can assist in avoiding over-provisioning. Another way to cut expenses related to idle compute resources is to use work clusters that end when tasks are completed. Scheduling work during off-peak hours might result in reduced charges. Spark job execution time and resource utilization may be decreased by optimizing the task to execute more effectively.
26. What methods are used for error logging and monitoring in Azure Databricks?
Ans:
- Integrated tools and third-party services may be used to handle error recording and monitoring in Azure Databricks. Errors and system events are captured via Databricks’ integrated logging features, which may be accessed programmatically using APIs or through the workspace interface.
- Comprehensive monitoring, alerting, and visualization of metrics and logs from Databricks clusters and apps are made possible by integration with Azure Monitor and Log Analytics.
27. Explain the role of UDFs (User-Defined Functions) in Azure Databricks.
Ans:
- By creating unique functions in languages like Python, Scala, or Java that can be used in Spark SQL queries, users may expand the capabilities of Spark SQL by utilizing UDFs (User-Defined Functions) in Azure Databricks.
- UDFs come in handy when handling sophisticated data processing tasks that are difficult or impossible to accomplish with regular Spark SQL methods.
- They allow business logic to be packaged into reusable parts that can be used in Databricks notebooks or workflows and applied to different datasets and dataframes.
28. What are Databricks notebooks and how do they support collaboration?
Ans:
- Databricks notebooks are web-based interactive interfaces that facilitate the use of narrative prose, code, and data visualization.
- Within the same notebook, they support several programming languages, such as Python, Scala, R, and SQL. Data scientists, engineers, and business analysts may collaborate more easily by co-editing, exchanging ideas, and making comments in real-time while using notebooks.
- Changes may be monitored and examined thanks to version control capability, which is made possible by connecting with Bitbucket, GitHub, and Azure DevOps.
29. What is Delta Lake, and what is its significance in Azure Databricks?
Ans:
The open-source storage layer known as a Delta Lake enhances data lakes with performance, security, and reliability. It provides ACID transactions, scalable metadata management, and the capacity to integrate batch and streaming data processing into a unified system. A crucial part of Azure Databricks, Delta Lake helps expedite data analytics and machine learning workflows, simplify the construction of data pipelines, and increase data quality and reliability.
30. Discuss the benefits of using Azure Databricks for machine learning projects.
Ans:
- Azure Databricks offers collaborative notebooks to facilitate seamless teamwork, making it a potent platform for machine learning applications.
- It can be integrated with MLflow to manage models, keep track of trials, and streamline the machine learning process. Optimized machine learning libraries are part of the Databricks runtime, which speeds up the training and assessment of models.
- With Databricks’ AutoML capabilities, choosing and fine-tuning models is made easier, opening up machine learning to a wider audience.
31. What strategies ensure efficient data processing with large datasets in Azure Databricks?
Ans:
- There are several ways to process huge volumes of data efficiently in Azure Databricks. Appropriate data partitioning guarantees that the Workload is dispersed uniformly among clusters, augmenting parallel processing.
- Scalable metadata management is made possible by using Delta Lake, which also improves data layout. Selecting a file format that optimizes efficiency and compression—like Parquet or Delta—reduces the amount of I/O operations.
32. What is MLflow, and how does it integrate with Azure Databricks?
Ans:
The open-source platform MLflow is made to oversee every step of the machine learning lifecycle, including central model registry management, deployment, reproducibility, and experimentation. MLflow is easily linked with Azure Databricks, including tools for monitoring experiments, logging and comparing parameters and outcomes, and bundling ML code into repeatable runs. A single location for managing the lifespan of MLflow models, including model versioning, stage transitions, and annotations, is provided via the MLflow model registry.
33. Describe the role of Databricks Delta Engine and how it improves upon Apache Spark.
Ans:
- Built on top of Apache Spark, the Databricks Delta Engine is a high-performance query engine intended to maximize the execution of SQL and data frame operations, especially for data kept in Delta Lake.
- It greatly outperforms Apache Spark by offering improved performance enhancements over Apache Spark, such as quicker query execution through sophisticated caching and indexing techniques and adaptive query execution for runtime Spark plan optimization.
34. Explain AutoML in Azure Databricks and its benefits.
Ans:
AutoML in Databricks simplifies model development by automatically selecting the optimal model and adjusting hyperparameters based on the dataset. It supports various machine learning tasks, including clustering, regression, and classification. AutoML accelerates experimentation, improves model performance, and democratizes machine learning, allowing users of all skill levels to effectively develop and implement models.
35. How do Azure Databricks handle real-time data analytics?
Ans:
- Structured streaming, an Apache Spark API that allows for scalable and fault-tolerant stream processing of real-time data streams, is how Azure Databricks manages real-time data analytics.
- With the help of structured streaming, users can handle complicated data transformations and aggregations on streaming data just as easily as they can with batch da processing, thanks to the high-level abstraction known as a data frame.
36. Discuss the integration capabilities of Azure Databricks with Azure Data Factory.
Ans:
A complete solution for data engineering and data integration processes is offered by the seamless integration of Azure Databricks and Azure Data Factory (ADF). Azure Databricks offers a potent analytics engine for complicated data processing and machine learning activities, while ADF serves as the orchestration layer, overseeing data transportation and transformation procedures.
37. What are the advantages of using Delta Lake with Azure Databricks?
Ans:
- First, it ensures data integrity by leveraging ACID transactions for both reads and writes, making it suitable for complex, concurrent data pipelines.
- Second, it facilitates schema evolution and enforcement, allowing safe and regulated changes to the data schema without disrupting ongoing operations.
- Third, Delta Lake accelerates data searches through data indexing and caching. Fourth, it simplifies data management by fusing streaming and batch data processing.
38. How can query performance be optimized in Azure Databricks?
Ans:
- Azure Databric’s query speed may be optimized using a number of techniques:
- First, use Delta Lak’s efficient file management system and caching features for storage.
- Secondly, to improve data read operations, divide data effectively.
- Thirdly, to guarantee parallelism and lessen data shuffle, maximize the size and quantity of divisions.
- Fourth, to reduce data shuffle, use broadcast joins for both big and small table joins. Fifth, minimize file scans by using Z-Order optimization on frequently requested columns.
39. Describe the process of scaling up and down in Azure Databricks and its impact on cost management.?
Ans:
Scaling up and down in Azure Databricks refers to adjusting the number of nodes in a Databricks cluster based on Workload. The ability of Databricks to autoscale, which adds or removes worker nodes in accordance with workloads to optimize resource utilization and running costs, makes this feasible. In order to handle spikes in demand for data processing, scaling up boosts computing capacity while scaling down decreases resource use during periods of low demand.
40. What is the role of Apache Spark’s Catalyst Optimizer in Azure Databricks?
Ans:
Apache Spark’s Catalyst Optimizer is a crucial component of the Spark SQL engine that enhances the SQL query and DataFrame performance in Azure Databricks. The Catalyst Optimizer uses a variety of rule-based and cost-based optimization techniques to generate an efficient execution plan for a particular query. These opt mizations include logical plan optimizations, such as constant folding and predicate pushdown, as well as physical plan optimizations, such as selecting the optimal join methods and data partitioning.

Get JOB Azure Databricks Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. How does Azure Databricks support streaming analytics?
Ans:
- Azure Databricks provides streaming analytics using structured streaming, an Apache Spark API that enables high-throughput, fault-tolerant stream processing of real-time data streams.
- Users may construct streaming tasks in the Databricks notebooks that allow complex data transformations and aggregations on streaming data, similar to batch processing using Spark SQL or the DataFrame API.
- Databricks integrates with a range of streaming data sources and sinks, including Azure Event Hubs, Azure IoT Hubs, and Kafka, to enable real-time data input, processing, and analysis.
42. Discuss the security features of Azure Databricks that protect data and manage access.
Ans:
Azure Databricks offers an extensive collection of security measures created to safeguard data and manage access. Single sign-on functionality and safe authentication are guaranteed via integration with Azure Active Directory (AAD). Position-based access control, or RBAC, ensures that users only have access to the resources required for their position by enabling fine-grained permissions for notebooks, clusters, tasks, and data.
43. How can Az re Databricks be used for predictive maintenance?
Ans:
Azure Databricks’ machine learning and large data processing powers may be applied to predictive maintenance. Databricks is a tool that data scientists may use to ingest, clean, and aggregate data from a variety of sources, including operations logs, historical maintenance records, and IoT devices. Databricks notebooks may be used to find trends and anomalies that may be signs of impending equipment breakdowns by using machine learning techniques.
44 . How do Azure Databricks facilitate collaboration among data teams?
Ans:
- Azure Databricks facilitates collaboration among data teams by providing shared workspaces that make notebooks, libraries, and datasets easily accessible and shared.
- Multiple users may collaborate in real-time on notebooks with the platform’s support for code, comments, and troubleshooting.
- Teams may manage notebook versions and monitor changes using integrated version control, which prevents work from being lost and enables them to go back to earlier iterations when necessary.
45. What strategies can be employed to manage costs in Azure Databricks?
Ans:
In Azure Databricks, managing expenses can be optimized through several approaches. Utilizing autoscaling allows for dynamic adjustment of resources based on workload, ensuring that payment is only made for the resources actually used. Selecting the appropriate instance types, whether memory- or compute-optimized, can also significantly impact costs depending on specific requirements. For non-critical tasks, employing spot instances offers a cost-saving opportunity, albeit with the risk of termination.
46. Describe deploying a machine learning model in Azure Databricks.
Ans:
- Deploying the machine learning model in Azure Databricks involves many essential processes: First, a model is created and trained using Databricks notebooks and libraries like TensorFlow, PyTorch, or Scikit-learn.
- The model is assessed after training to ensure it meets the necessary performance measures.
- After validation, the model may be packed with MLflow, which offers a uniform deployment format. MLflow streamlines model versioning and maintenance by making it easier to monitor experiments, models, and parameters.
47. How can Azure Databricks be integrated with Azure Synapse Analytics?
Ans:
Big data and data warehousing are integral to the analytics solution provided by integrating Azure Databricks and Azure Synapse Analytics. This integration allows data scientists and engineers to create complex ETL processes in Databricks and transfer the results to Synapse for further reporting and analysis. Integration methods include using Azure Data Factory for direct data transfer, JDBC for direct access to Synapse SQL Data Pool from Databricks notebooks, or utilizing Azure Data Lake Storage (ADLS) Gen2 for seamless data exchange.
48. Explain how Azure Databricks supports geospatial data analysis.
Ans:
- Geographic data processing and visualization are made possible by libraries and integrations offered by Azure Databricks, which facilitate geographic data analysis.
- With Databricks notebooks, geographical data may be worked with, and operations like spatial joins, overlays, and charting can be carried out using libraries like Ge Pandas for Python.
49. Discuss the use of Azure Databicks for IoT data analysis?
Ans:
Azure Databricks is a highly useful solution for IoT data analysis since it offers the real-time processing capability to manage the massive volumes of data created by IoT devices. Databricks can use structured streaming to ingest streaming data for real-time analytics from a variety of sources, including Azure IoT Hub. Through the utilization of Azure Databricks’ expandable computational capabilities, enterprises may handle billions of occurrences daily, permitting intricate analysis of Internet of Things data.
50. What are Databricks Delta Live Tables and their benefits?
Ans:
- Bricks of data The architecture for creating dependable, tested, and maintainable data pipelines in Azure Databricks is called Delta Live Tables. Offering declarative pipeline definitions, where developers express what they want to achieve rather than how abstracts away the difficulty of developing data pipelines.
- Using Delta Live Tables improves data dependability with integrated quality controls, streamlines pipeline administration, and increases productivity by cutting down on the time and labor needed to create and maintain data pipelines
51. How can Azure Databricks be used to enhance business intelligence (BI) and reporting?
Ans:
Azure Databricks may enhance business intelligence (BI) and report by providing insights that are not achievable with traditional BI solutions by processing and analyzing enormous volumes of data in real-time. In order to get deeper insights, it may process data using sophisticated analytics and machine learning by connecting to a variety of data sources, including real-time streams. By integrating Databricks with well-known BI tools like Tableau and Microsoft Power BI, users can generate interactive dashboards and report straight from the processed data.
52. Describe how Azure Data Ricks supports custom visualization tools.
Ans:
- Through its connection with more libraries and APIs, Azure Databricks offers custom visualization tools, allowing data scientists and analysts to produce detailed and interactive representations.
- With Databricks notebooks, users may create plots and charts from their data using well-known Python visualization tools like Matplotlib, Seaborn, and Plotly.
- Furthermore, Databricks notebooks enable HTML, JavaScript, and D3.js, which can be used to develop unique web-based visualizations that are more flexible and interactive than traditional visualizations.
53. What is DBU?
Ans:
- When billing Azure Databricks services, a Databricks Unit (DBU) is a measurement of processing capabilities expressed in terms of hours.
- It stands for the computing and processing capacity needed to carry out tasks and activities in the Databricks environment. The price of DBUs varies according to the size, particular capabilities (like CPU and memory), and kind of Databricks cluster (like interactive or automated).
54. What are the various types of clusters present in Azure Databricks?
Ans:
Azure Databricks provides several types of clusters to accommodate various needs. Interactive clusters are designed for ad-hoc exploration and development, offering an interactive workspace for running notebooks. Job clusters are used for executing automated jobs and are terminated once the job is complete. All-purpose clusters support general use cases, allowing multiple users and workloads. High-concurrency clusters are optimized for environments with many users, enabling shared use with minimal interference.
55. What is caching?
Ans:
To reduce the need to continually request or compute data from slower storage levels, frequently accessed data or intermediate results can be stored in a fast-access storage layer. This technique is known as caching in the context of Azure Databricks. This procedure minimizes I/O operations and computing burdens, which greatly enhances the performance of interactive analyses and data processing jobs. Caching is very helpful in iterative algorithms and interactive data exploration sessions when the same data is retrieved repeatedly.
56. What is autoscaling?
Ans:
- Over-Provisioning: If the scaling criteria are not correct, autoscaling may overprovision resources, which may increase expenses.
- Under-Provisioning: If the Workload grows unexpectedly, there may not be enough scalability, which might affect performance.
- Scaling Delays: Temporary resource shortages or inefficiencies may result in delayed scaling activities.
- Complexity in Configuration: It might be difficult to configure autoscaling settings accurately without first analyzing the workload patterns.
57. What use is Kafka for?
Ans:
- Apuana Kafka: Apuana Kafka is a distributed streaming platform that facilitates the development of real-time streaming applications and pipelines for data.
- Data Ingestion: Gathering vast amounts of fast-moving data in real-time from several sources.
- Event streaming: Event streaming allows for real-time data stream processing and analysis, providing quick decisions and responses.
58. What use is the Databricks file system for?
Ans:
The distributed file system mounted within the Azure Databricks workspace is called the Databricks File System. It is utilized for data storage and allows for the easy storage of datasets, notebooks, and libraries on Azure Databricks. It is enabling collaborative work by facilitating the exchange of files and data across notebooks and clusters through data sharing.
59. What steps are taken to troubleshoot issues related to Azure Databricks?
Ans:
- Consulting Logs: Check the cluster, job, and audit logs for errors or warnings that indicate the cause of the issue.
- Monitoring Resources: Track resource usage and performance indicators using the Databricks environment’s monitoring capabilities to spot bot necks or resource shortages.
- Verifying Setups: To make sure everything is configured correctly, double-check the cluster parameters, library dependencies, and access rights.
60. Can Azure Key Vault serve as a good substitute for Secret Scopes?
Ans:
Azure Key Vault might be a useful alternative to Azure Databricks’ Secret Scopes for securely managing secrets like passwords, keys, and tokens. Robust security features provided by Azure Key Vault include:
- Fine-grained access controls.
- Hardware security modules (HSMs) for cryptographic operations.
- Authentication connectivity with Azure Active Directory.

Develop Your Skills with Azure Databricks Certification Training
Weekday / Weekend BatchesSee Batch Details61. How is Databricks code managed when working in a team with TFS or Git?
Ans:
Databricks notebooks are combined with Git repositories to manage Databricks code using TFS or Git. This integration enables version management of notebooks and allows team members to collaborate on development projects directly within the Databricks workspace. The Databricks UI facilitates fetching updates, submitting changes, and handling conflicts, ensuring that code changes are monitored and managed systematically.
62. What languages are supported by Azure Databricks?
Ans:
Python, SQL, and R are among the languages supported by Azure Databricks for data science and engineering activities. Python’s strong ecosystem of machine learning and data science packages makes it a popular programming language. In order to take advantage of Apache Spark’s built-in large data processing features, Scala is recommended. SQL is used to manipulate and analyze data, giving consumers the ability to query data using a familiar syntax.
63. Is it possible to use private cloud infrastructure with Databrick?
Ans:
- Yes, Databricks on Amazon Web Services PrivateLink, Azure Private Link, or Google Cloud Private Service Connect may be used in a private cloud environment.
- With the help of these services, access to Databricks from within a private network can be safely achieved, preventing data from traveling over the open Internet. This configuration provides additional protection, making it particularly beneficial for businesses with stringent privacy and data security policies.
64. What capabilities does PowerShell offer for administering Databricks?
Ans:
Azure Databricks can be administrated using PowerShell by utilizing the Azure Databricks REST API or Azure PowerShell cmdlets, which are part of the larger Azure ecosystem and indirectly control Databricks resources. Provisioning and managing Databricks workspaces, clusters, tasks, and other resources can be automated with PowerShell scripts. This involves making REST API calls to Databricks using the ‘Invoke-RestMethod’ PowerShell cmdlet, enabling automation and integration with additional Azure services.
65. In Databricks, what distinguishes an instance from a cluster?
Ans:
- In Databricks, a virtual machine (VM) that is a component of a cluster is referred to as an instance. In contrast, a cluster is an assembly of virtual machines (VMs) that co-labor to distribute and handle data.
- The computational resources known as instances carry out the duties that are delegated to them by the cluster manager. Depending on the cluster design, each instance in a cluster has a certain purpose, such as a worker or driver node. Worker nodes get tasks from the driver node, which they subsequently carry out.
66. How can a private access token be generated for Databricks?
Ans:
To generate a private access token in the Databricks workspace area of Azure Databricks, navigate to the user settings. Select the “Generate New Token” button, provide a description if desired, and optionally specify an expiration date. Once created, the token will be displayed for copying. As it will not be shown again, it should be saved securely. These tokens facilitate API authentication, allowing scripts or apps to communicate safely with the Databricks environment.
67. How does one go about removing a private access token?
Ans:
To delete a private access token from Azure Databricks, navigate to the “Access Tokens” section in the user settings of the Databricks workspace. This area displays a list of all current tokens, including their descriptions and expiration dates. Click the “Revoke” button next to the token that needs to be removed. Confirm the revocation when prompted. This action instantly invalidates the token, preventing its use for making API requests or accessing the Databricks workspace.
68. What is the management plane in Azure Databricks?
Ans:
- The management plane in Azure Databricks handles provisioning and maintaining Databricks workspaces, controlling user access, and integrating Databricks workspaces with other Azure services.
- It functions at the Azure resource level, Utilizing Azure Active Directory for authentication and Azure role-based access control (RBAC) for authorization. Administrators use the management plane to set up security and compliance standards, manage pricing, and customize workspace settings.
69. What does Azure Databricks’ control plane do?
Ans:
- The operational components of the Databricks environment are coordinated and managed via the Azure Databricks control plane.
- This covers notebook, job, and cluster management. It responds to queries to schedule jobs, start and stop clusters, and control notebook execution.
- The control plane manages resources to satisfy computational needs while ensuring these processes are carried out safely and effectively.
70. In Azure Databricks, what is the data plane?
Ans:
The layer of Azure Databricks where data processing and analysis take place is called the data plane. It is made up of the real Databricks cluster, which handles data by running Spark tasks. With its isolation from the control and management planes, the data plane is only concerned with carrying out data tasks. To ingest, analyze, and store data, it communicates with a variety of data sources and sinks, including Azure Data Lake Storage, Azure SQL Database, and Cosmos DB.
71. What is the purpose of the Databricks runtime?
Ans:
A highly optimized version of Apache Spark, the Databricks Runtime has improved to include the dependability and speed used by Databricks. It has features and performance enhancements that are not included in the open-source Spark version. The Databricks Runtime is designed to give data processing, streaming, and machine learning users a ready-to-use, scalable environment. With support for many data science and data engineering workflows, users may complete their tasks more quickly and effectively.
72. In Databricks, what purpose do widgets serve?
Ans:
- Databricks widgets are used to create dynamic, interactive notebooks. They let users set parameters that may be used to dynamically change the behavior of the notebook’s visualizations, data frame actions, and SQL queries.
- Widgets allow users to modify MD parameters or data analysis settings without changing the underlying code by supporting various input formats, including text, dropdown menus, and sliders.
- This promotes team collaboration by making notebooks more interactive and user-friendly, particularly for non-technical users.
73. What is a secret with Databricks?
Ans:
In Databricks, a secret is a safe way to store private data used in notebooks and tasks, such as passwords, API keys, or database connection strings. Secrets are programmatically accessible within Databricks notebooks or tasks and are safely saved in a Databricks-backed secret scope, protecting private information from being revealed in plain text. They are using best practices for security and compliance to aid in the central, safe management of credentials and sensitive data.
74. What is Big data?
Ans:
Large datasets that are challenging to handle, evaluate, and store using conventional database and software methods are referred to as “big data.” It includes information from a range of sources, including social media, sensors, mobile devices, and more, and comes in three different forms: structured, semi-structured, and unstructured.
The three V’s of big data are:
- Variety (the range of data kinds and sources).
- Velocity (the pace at which it is created).
- Volume (the amount of data).
75. Why is big data technology needed?
Ans:
To meet the problems presented by the enormous amount, diversity, and velocity of data created in the digital age, big data technology is required. Conventional databases and data processing techniques are insufficient for effectively managing such enormous volumes of complicated data. Large datasets may be distributedly stored, processed, and analyzed across computer clusters thanks to big data technologies like Hadoop and Spark.
76. What is the Apache Spark ecosystem?
Ans:
The Apache Spark ecosystem consists of a collection of libraries for large data processing and analysis as well as a unified analytics engine. It consists of MLlib for machine learning, Spark Streaming for real-time data processing, Spark Core for distributed data processing, Spark SQL for structured data processing, and GraphX for graph processing. This ecosystem may operate in a range of settings, including cloud services and standalone clusters.
77. What is Azure Data Practice?
Ans:
Azure Data techniques are the collective term for the methods, frameworks, and tools used for data management and analytics on the Microsoft Azure cloud platform. They include employing Azure’s data services for data gathering, storage, processing, analysis, and visualization. Important components include Azure HDInsight for managed Hadoop and Spark services, Azure Synapse Analytics for big data and data warehousing solutions, Azure Databricks for big data analytics and machine learning, and Azure Data Lake for scalable data storage.
78. What is the serverless feature in Azure Databricks?
Ans:
- Because of the serverless feature, users may run Spark operations on Azure Databricks without worrying about maintaining the underlying infrastructure.
- Thanks to this functionality, data scientists and engineers may concentrate only on their data analytics workloads, isolating the cluster administration and scaling decisions.
- Serverless computing allows Azure Databricks to automatically calculate computer resources when a job is finished and provide them when a job is launched.
79. What are connectors in Azure Databricks?
Ans:
- Azure Databricks connectors are intended to make it easy and effective to integrate data with a range of other data sources and services.
- They facilitate smooth data import and export between the Databricks and data warehouses such as Azure Synapse Analytics, Azure Data Lake Storage, Azure Blob Storage, and Azure Cosmos DB. Connectors offer straightforward APIs and interfaces for data operations, abstracting the complexities of data access and transmission.
80. How do Azure Databricks scale up or down the cluster?
Ans:
With its autoscaling capability, Azure Databricks automatically scales clusters up or down according to the demands of the Workload. Databricks automatically adds new nodes (servers) to the cluster to manage the increasing demand when a task or query needs more resources to satisfy its computing requirements. On the other hand, Databricks eliminates the nodes from the cluster to cut down on wasteful spending as demand declines.
81. What are the preconfigured environments in Azure Databricks?
Ans:
Ready-to-use runtime environments with preconfigured libraries and tools for various data processing, machine learning, and analytics activities are available in Azure Databricks. Databricks Runtimes, which are specialized versions of these environments, can include Databricks Runtime for Machine Learning, which is pre-installed with well-known ML modules and frameworks. Additional instances include runtimes tailored for processing genomic data.
82. What file system does Azure Databricks use instead of HDFS?
Ans:
- Rather than Hadoop Distributed File System (HDFS), Azure Databricks employs Azure Data Lake Storage (ADLS) and Azure Blob Storage as its primary file systems.
- These cloud storage alternatives offer safe, affordable, and scalable data storage choices that work well with Azure Databricks.
- Users may access data from anywhere and experience improved performance and dependability by utilizing Azure’s cloud storage, which eliminates the constraints associated with conventional HDFS clusters.
83. Can Spark use local files in Azure Databricks?
Ans:
- Sure, but there are several things to keep in mind when using local files with Apache Spark in Azure Databricks. A Spark job running in a cluster has access to files kept on the driver node’s local file system.
- Using local files on the driver node is appropriate for brief storage needs or tiny, non-distributed workloads. The best practice is to use Azure’s cloud storage services for applications that require high availability and scalability, such as processing massive datasets.
84. What is the service launch workspace in Azure Databricks?
Ans:
Azure Databricks provides a deployment mechanism called the Service Launch Workspace for managing multiple Databricks workspaces at scale, making it ideal for large businesses and service providers. This feature allows administrators to automate and centrally manage workspaces, streamlining provisioning, management, and operational tasks. Additionally, it supports customized deployments, enabling organizations to enforce governance, security, and compliance across all Databricks environments.
85. How was the new cluster created in Azure Databricks?
Ans:
- To create a new cluster in Azure Databricks, navigate to the “Clusters” section of the Databricks workspace.
- To create a cluster, click on the “Create Cluster” button to open a form for entering the cluster’s configuration details. This includes specifying the Databricks runtime version, selecting the type and size of machines for the cluster nodes, and configuring any auto-scaling options or advanced settings. These advanced settings encompass Spark configurations and environment variables.
86. What is Azure Data Fix Terminal?
Ans:
There isn’t a well-known product or service in the Azure ecosystem called “Azure Data Fix Terminal” that is connected to Azure Databricks. The word may pertain to a particular tool, feature, or outside service intended for data management, repair, or troubleshooting in Azure or Azure Databricks settings. Alternatively, it may be a misinterpretation of the service’s name. It is recommended that you refer to the official Azure documentation or get in touch with Azure support for correct and current information
87. What is short blob storage?
Ans:
Short blob storage does not specifically refer to any one Azure service. In contrast, Azure Blob Storage provides storage options for massive volumes of unstructured data, such as text or binary data, which may be what “short blob storage” refers to. Large volumes of data, including papers, photos, and media files, may be stored in blob storage, which has three layers (Hot, Cool, and Archive) to control storage costs depending on access frequency and storage length.
88. How are permissions managed in Azure Blob Storage?
Ans:
A variety of access control mechanisms are used to manage permissions in Azure Blob Storage. These mechanisms include access keys for storage account-level authentication and authorization, shared access strategies (SAS) for fine-grained temporary access, and Azure Active Directory (AAD) integration for identity-based access control. Azure also uses role-based access control, or RBAC, to specify the operations that particular users or groups are permitted to carry out on blob storage resources.
89. What is geo-redundant storage in Azure Blob Storage?
Ans:
- Azure Blob Storage’s geo-redient storage replicates data to a secondary region hundreds of miles distant from the source region in order to offer high availability and disaster recovery.
- To guard against regional outages or calamities, GRS automatically duplicates data to a second location and keeps multiple copies across two regions.
- In contrast to locally redundant storage (LRS), which only stores data inside a single region, this replication makes sure that in the event that the primary region becomes inaccessible, data may still be accessed from the secondary region.
90. What is the access to Azure Blob Storage?
Ans:
- In Azure Blob Storage, the term access tier refers to a particular data storage tier designed to control access performance and expenses according to the frequency of data access. The three access tiers available for Azure Blob Storage are Hot, Cool, and Archive.
- The Hot tier offers reduced access rates but higher storage costs since it is designed for data that is accessed of en. The Cool tier, which has reduced storage costs but higher access charges, is meant for data that is accessed rarely.




