
Last updated on 12th Nov 2021| 4997
Welcome to the arena of Hadoop administration! As enterprises deal with huge datasets, the function of Hadoop Administrator becomes critical. This specialist is in charge of planning, deploying, and maintaining Hadoop clusters, guaranteeing the dependability and performance required to extract useful insights. From cluster configuration to security implementation and performance optimization, the Hadoop Admin is critical to realizing the potential of Big Data. In this interview, we will discuss critical duties and insights into the abilities required for efficient Hadoop administration.
1. Explain the key components of Hadoop.
Ans:
- Hadoop Distributed File System (HDFS): A distributed file system that stores data across multiple nodes in a Hadoop cluster.
- MapReduce: A programming model and processing engine for distributed computation of large datasets.
- Hadoop Common: Shared utilities and libraries required by other Hadoop module
- Hadoop YARN (Yet Another Resource Negotiator): A resource management layer responsible for managing and scheduling resources in a Hadoop cluster.
2. How do you configure Hadoop for optimal performance
Ans:
- Adjusting block size in HDFS based on the type of data and workload.
- Fine-tuning the memory settings for Hadoop daemons.
- Configure the number of maps and reduce slots based on cluster resources
- Optimising the network settings for efficient data transfer.
3. What is Hadoop High Availability (HA)?
Ans:
Hadoop High Availability is a configuration that ensures continuous operation of the Hadoop cluster even in the presence of hardware or software failures. It typically involves setting up redundant NameNodes and using technologies like ZooKeeper for coordination.
The primary goal of Hadoop HA is to minimize downtime and data loss by providing redundancy and failover mechanisms. The core components of Hadoop, such as the Hadoop Distributed File System (HDFS) and the Hadoop MapReduce engine, are critical for data storage and processing.
4. What is the role of a Hadoop Administrator?
Ans:
A Hadoop Administrator is responsible for the installation, configuration, maintenance, and overall management of a Hadoop cluster. This includes monitoring cluster health, performance tuning, security setup, and ensuring data reliability and availability.
- Cluster Planning and Deployment
- Configuration and Optimization
- Security Management
- Monitoring and Troubleshooting
- Backup and Recovery
- Capacity Planning
5. How do you secure a Hadoop cluster?
Ans:
- Enable authentication and authorization mechanisms.
- Encrypt data in transit and at rest.
- Set up firewalls and restrict network access.
- Regularly update and patch Hadoop components.
- Implement audit logging and monit ● o’ring for security events.
6. What is Hadoop Rack Awareness?
Ans:
- Rack Awareness is a feature in Hadoop that ensures data is stored across multiple racks in a data centre. This helps improve fault tolerance by avoiding a single point of failure at the rack level.A rack in this context refers to a network switch or a physical grouping of nodes within the data center.
- Hadoop Rack Awareness is a feature in the Hadoop Distributed File System (HDFS) that aims to improve the fault tolerance and performance of the Hadoop cluster by considering the physical network topology, specifically the arrangement of nodes into racks
7. How will you install a new component or add a service to an existing Hadoop cluster?
Ans:
Adding a new component or service to an existing Hadoop cluster typically involves several steps. Let’s take the example of adding Apache Hive, a data warehouse infrastructure built on top of Hadoop, to an existing Hadoop cluster.
Always refer to the specific documentation of the component you are adding to get detailed and accurate instructions. The steps can vary based on the component’s requirements and the version of Hadoop being used in the cluster.
8. Configure capacity scheduler in Hadoop?
Ans:
The CapacityScheduler is one of the scheduling options available in Hadoop’s ResourceManager, allowing you to allocate resources to different queues based on configured capacities.
- Navigate to the Configuration Directory.
- Edit the capacity-scheduler.xml file.
- Configure Queues and Capacities.
- Save and Close the File.
- Restart ResourceManager.
9. What is Hadoop YARN?
Ans:
A key element of the Apache Hadoop ecosystem is Hadoop YARN (Yet Another Resource Negotiator). It acts as a layer for resource management in a Hadoop cluster, facilitating the effective distribution of resources (CPU, memory) amongst apps. Hadoop becomes a flexible distributed computing platform when it comes to processing engines beyond MapReduce, thanks to YARN’s support for numerous application frameworks.
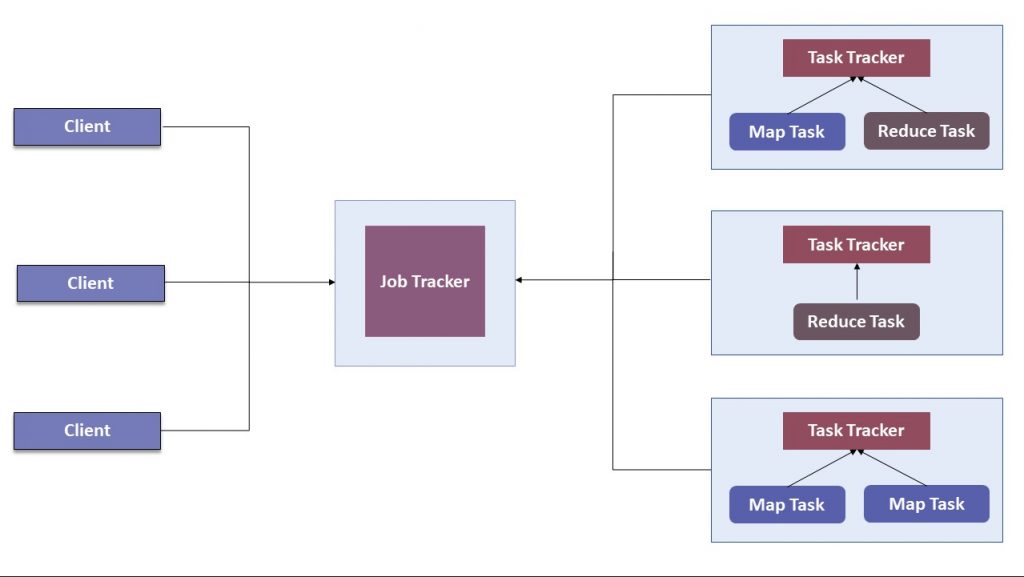
10. Explain the importance of Hadoop configuration files.
Ans:
| Configuration Property | Hadoop Version | Description | |
| mapred.tasktracker.map.tasks.maximum |
Hadoop 1.0 |
Maximum number of Map tasks that a TaskTracker can run. | |
| mapred.tasktracker.reduce.tasks.maximum | Hadoop 1. | 0Maximum number of Reduce tasks that a TaskTracker can run. | |
| mapreduce.jobtracker.maxtasks.per.job |
Hadoop 1.0 |
Maximum number of tasks (both Map and Reduce) per job. | |
| mapreduce.tasktracker.map.tasks.maximum | Hadoop 2.0 | Maximum number of Map tasks that a TaskTracker can run. | |
| mapreduce.tasktracker.reduce.tasks.maximum |
Hadoop 2.0 |
Maximum number of Reduce tasks that a TaskTracker can run. | |
| mapreduce.job.maps |
Hadoop 2.0 |
Total number of Map tasks across all TaskTrackers. |
11.When configuring Hadoop manually, which property file should be modified to configure slots?
Ans:
When configuring Hadoop manually, you typically modify the mapred-site.xml file to configure slots. The number of map and reduce slots can be controlled using the following properties in the mapred-site.xml file:
12. Which tool have you used in your project for monitoring clusters and nodes in Hadoop?
Ans:
- Ambari:Apache Ambari is an open-source management and monitoring tool designed for Apache Hadoop clusters.
- Ganglia: It is often used in Hadoop environments to monitor performance metrics of nodes and clusters.
- Prometheus:Agios is a widely-used open-source monitoring system that can be extended to monitor Hadoop clusters.
- Datadog is a cloud-based monitoring and analytics platform that can be used to monitor Hadoop clusters. It provides real-time insights into the performance of clusters and allows for alerting based on specific metrics.
- Grafana:Grafana is a popular open-source platform for monitoring and observability.
13. How will you manage a Hadoop system?
Ans:
Managing a Hadoop system involves various tasks related to installation, configuration, monitoring, maintenance, and troubleshooting. Here’s a comprehensive guide on managing a Hadoop system:
- Installation and Configuration.
- Cluster Planning and Scaling.
- Hadoop Distributed File System (HDFS) Management.
- Security Management.
- Resource Management with YARN.
- Security Audits.
14. Can you create a Hadoop cluster from scratch?
Ans:
Creating a Hadoop cluster from scratch involves several steps, and the process can be complex. Here is a high-level overview of the steps you would typically follow. Note that the specific details may vary based on the Hadoop distribution you choose (e.g., Apache Hadoop, Cloudera, Hortonworks, etc.)Keep in mind that this is a simplified overview, and the actual steps may vary based on your specific requirements and the Hadoop distribution you are using.
15.How many NameNodes can you run on a single Hadoop cluster?
Ans:
In a standard Hadoop architecture, there is traditionally only one active NameNode at any given time.
The NameNode is a critical component in Hadoop’s Hadoop Distributed File System (HDFS) and manages the metadata for the file system, such as the namespace tree and the mapping of blocks to DataNodes.
16. What is a Hadoop balancer, and why is it necessary?
Ans:
The Hadoop balancer is a utility provided by Apache Hadoop to balance the distribution of data across the nodes in a Hadoop Distributed File System (HDFS) cluster.
Its primary purpose is to ensure that data is evenly distributed among the DataNodes, preventing imbalances that can occur over time due to the dynamic nature of data storage and processing in a Hadoop environment.It ensures optimal data distribution, prevents performance bottlenecks, and contributes to the overall efficiency and reliability of the Hadoop environment.
17. Main Components of Hadoop?
Ans:
Hadoop Distributed File System (HDFS):
- NameNode: Manages metadata and coordinates access to data stored in HDFS.
- DataNode: Stores actual data and responds to read and write requests from the Hadoop File System.
- JobTracker: Manages and schedules MapReduce jobs submitted to the cluster.
- TaskTracker: Executes tasks on nodes, such as running map and reduce tasks.
- ResourceManager: Manages resources in the cluster, including resource allocation to applications. NodeManager: Manages resources on individual nodes and monitors application containers.
- Hive: Data warehouse infrastructure for querying and managing large datasets.
- HBase: Distributed, scalable, and NoSQL database for real-time read/write access to large datasets.
MapReduce:
Yet Another Resource Negotiator (YARN):
Hadoop Common:
18. Why do we need Hadoop?
Ans:
Scalability: Hadoop is designed to scale horizontally, allowing organizations to add more nodes to the cluster as their data grows.
Cost-Effective Storage:Hadoop Distributed File System (HDFS) provides a cost-effective way to store large datasets by distributing data across commodity hardware.
Fault Tolerance:Hadoop is fault-tolerant. It replicates data across multiple nodes, ensuring that if one node fails, data can be retrieved from its replicas on other nodes.
Parallel Processing:The MapReduce programming model allows for parallel processing of data across the nodes in a Hadoop cluster.
Diverse Data Processing:Hadoop can handle a variety of data types, including structured and unstructured data.
19 . What are the modes in which Hadoop runs?
Ans:
Local (or Standalone) Mode:
In Local Mode, Hadoop runs on a single machine as a single Java process. It is primarily used for development, testing, and debugging purposes on a local machine.
Cluster (or Distributed) Mode:
In Cluster Mode, Hadoop runs on a distributed cluster of machines, where each machine contributes resources to the processing and storage capabilities of the Hadoop ecosystem.
20. What is Hadoop streaming?
Ans:
Hadoop Streaming is a utility that allows developers to use any programming language to write MapReduce jobs for Hadoop.MapReduce jobs are written in Java, but Hadoop Streaming enables the use of scripting languages, such as Python, Perl, Ruby, and others, for writing Map and Reduce tasks.
The concept behind Hadoop Streaming is to treat input and output for Map and Reduce tasks as streams of data. This allows developers to use scripts as the mapper and reducer programs, and data is passed between these programs via standard input and output streams.
21. Explain what sqoop is in Hadoop ?
Ans:
Sqoop (SQL to Hadoop) is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured data stores such as relational databases.
It is part of the Hadoop ecosystem and provides a command-line interface and connectors to facilitate data transfer between Hadoop and various relational databases.Using Sqoop data can be transferred from RDMS like MySQL or Oracle into HDFS as well as exporting data from HDFS file to RDBMS.
22. Mention the data components used by Hadoop.
Ans:
Hadoop Distributed File System (HDFS):
- Storage Formats
- Apache HBase
- Apache Hive
- Apache Pig
- Apache Spark
- Apache Kafka
23.Suppose Hadoop spawned 100 tasks for a job, and one of the tasks failed. What will Hadoop do?
Ans:
In Hadoop, when a task fails during the execution of a job, the framework employs several mechanisms to handle the failure and ensure the successful completion of the overall job. Here’s what typically happens:
Task Retry
● Speculative Execution
● Task Failure Tolerance
● JobTracker Monitoring
● Speculative Execution Timeout
24.Explain the purpose of RecordReader in Hadoop.
Ans:
In Hadoop, a RecordReader is a crucial component within the MapReduce framework that plays a significant role in the Map phase of a MapReduce job. The primary purpose of the RecordReader is to read and parse input data from a particular source, typically a file or a data store converted into key-value pairs that the Map task can process.
25. What is “speculative execution” in Hadoop?
Ans:
Speculative Execution” is a feature in Apache Hadoop that aims to improve the efficiency and reliability of data processing jobs, particularly in MapReduce tasks. The hypothetical execution mechanism addresses situations where a task takes longer than expected due to various factors, such as hardware issues, network latency, or other resource contention. The goal of speculative execution is to improve the robustness of Hadoop jobs in the face of varying execution times for tasks.
26. What is a sequence file in Hadoop?
Ans:
A SequenceFile is a binary file format in Hadoop designed to store key-value pairs efficiently and efficiently. It is a flexible and extensible file format used for serializing complex data structures and is commonly employed as an intermediate format in Hadoop MapReduce jobs.
27.What is the Job Tracker role in Hadoop?
Ans:
In Hadoop’s MapReduce framework (versions 1. x and earlier), the JobTracker is a critical component responsible for managing and coordinating the execution of MapReduce jobs in a Hadoop cluster.
The JobTracker performs various tasks to ensure the successful execution of MapReduce jobs, including job scheduling, task assignment, and monitoring. It’s important to note that the architecture described above is specific to Hadoop MapReduce versions 1. x and earlier.
28.How does Spark use Hadoop?
Ans:
Apache Spark is often used with the Hadoop ecosystem, leveraging Hadoop’s storage system (Hadoop Distributed File System – HDFS) and sometimes integrating with other Hadoop components. While Spark can operate Independent of Hadoop, integrating with Hadoop brings benefits such as data locality, scalability, and the ability to leverage existing Hadoop investments.
29. How do you handle security in Hadoop?
Ans:
Hadoop provides security features such as Kerberos authentication, Access Control Lists (ACLs), and encryption. Kerberos is commonly used for authentication, while ACLs help control access to files and directories. Encryption can be applied to data at rest and in transit for enhanced security. By implementing these security measures and best practices, organisations can create a robust and secure Hadoop environment that protects data, maintains compliance, and mitigates potential risks.
30.What is the role of MapReduce in Hadoop?
Ans:
MapReduce is a programming model and processing engine for distributed processing of large datasets. It consists of two phases: the Map phase, which processes and transforms input data into intermediate key-value pairs, and the Reduce phase, which aggregates and produces the final output.t is a core component of the Apache Hadoop framework, which is an open-source framework for distributed storage and processing of large data sets using a cluster of commodity hardware.
31. Explain the role of the Hadoop Distributed File System (HDFS) in Hadoop.
Ans:
HDFS is the primary storage system used by Hadoop. It divides extensive data sets into smaller blocks and distributes them across a cluster of machines. It provides high fault tolerance and reliability by replicating data across multiple nodes.
The Hadoop Distributed File System (HDFS) is a core component of the Hadoop ecosystem, designed to store vast amounts of data across distributed nodes in a Hadoop cluster. HDFS plays a pivotal role in enabling Hadoop’s distributed data processing capabilities.
32.What are the key components of Hadoop?
Ans:
The key components of Hadoop include the Hadoop Distributed File System (HDFS) for storage and MapReduce for processing. Other essential components are Hadoop Common, YARN (Yet Another Resource Negotiator), and Hadoop MapReduce. Hadoop is an open-source framework designed for distributed storage and processing of large-scale data across clusters of commodity hardware.
33. How do you handle data node failures in Hadoop?
Ans:
Hadoop’s HDFS is designed to handle data node failures. When a data node fails, HDFS replicates the data on that node to other nodes, ensuring data availability. The NameNode manages metadata, knows the healthy data nodes, and redirects tasks to them. Handling data node failures in Hadoop is crucial to ensure data availability, reliability, and fault tolerance in the Hadoop cluster.
34.What is a DataNode in HDFS?
Ans:
DataNode is an agent node in HDFS that is responsible for storing the actual data. It manages the storage attached to the node and performs read and write operations as instructed by the NameNode.
The HDFS architecture is designed to distribute large files across multiple nodes in a Hadoop cluster for efficient storage and processing.DataNodes work in collaboration with the central controller server, which is known as the NameNode.
35. How do you monitor the performance of a Hadoop cluster?
Ans:
Hadoop administrators use tools like Ambari, Cloudera Manager, and Ganglia to monitor cluster performance. They analyse metrics related to resource usage, job completion times, node health, and overall cluster activity to identify and address performance issues.
36. What is speculative execution in Hadoop?
Ans:
Speculative execution is a feature in Hadoop that allows the system to launch duplicate tasks on other nodes if a particular task takes longer than expected.
The first task to complete is used, and the others are killed, preventing one slow task from significantly affecting job completion time. It is primarily aimed at addressing the issue of task execution skewness within a Hadoop cluster.
37. What are the challenges that you faced when implementing Hadoop projects?
Ans:
As a language model AI, I don’t implement projects, but I can provide information on common challenges that organisations or individuals might face when implementing Hadoop projects.
Implementing Hadoop projects can be complex, and challenges can arise at various stages. Despite these challenges, many organisations have successfully implemented Hadoop projects and derived significant value from big data analytics.
38. What is your favourite tool in the Hadoop ecosystem?
Ans:
As a machine learning model created by OpenAI, I don’t have personal preferences, opinions, or favourites. However, I can provide information about various tools in the Hadoop ecosystem based on their popularity and everyday use cases.
- Apache Hive
- Apache Pig
- Apache HBase
- Apache Spark
- Apache Sqoop
- Apache Flume
39. What problem is the company trying to solve, Apache Hadoop?
Ans:
Apache Hadoop was created to address the challenges of processing and analysing large volumes of data, especially unstructured and semi-structured data. The critical problem that Apache Hadoop aims to solve is the efficient storage and processing of massive datasets using a distributed and fault-tolerant approach.
40. What is the size of the giant Hadoop cluster company X operates?
Ans:
The size of Hadoop clusters can vary widely among different organisations based on their specific needs, data processing requirements, and infrastructure capabilities. However, the exact size can change as companies scale their infrastructure to meet evolving demands. Additionally, industry reports or news articles provide insights into the cluster sizes of prominent organisations. It is advisable to check the company’s latest announcements, publications, or official statements.
41. Explain Hadoop. List the core components of Hadoop
Ans:
Hadoop is an open-source framework designed for the distributed storage and processing of large data volumes across commodity hardware clusters. It provides a scalable, fault-tolerant, cost-effective solution for big data handling. Hadoop is particularly well-suited for storing and processing data in a parallel and distributed manner.
- Hadoop MapReduce (v2)
- Hadoop Distributed File System (HDFS)
- YARN (Yet Another Resource Negotiator)
- Hadoop Common
- Hadoop MapReduce (v2)
42. Explain the Storage Unit In Hadoop (HDFS).
Ans:
In Hadoop, the primary storage unit is the Hadoop Distributed File System (HDFS). HDFS is designed to store and manage large datasets by distributing them across a cluster of commodity hardware. Here are the critical aspects of the storage unit in HDFS:
- Blocks
- Replication
- NameNode
- DataNode
- Data Rack Awareness
43. What are the Limitations of Hadoop 1.0?
Ans:
Hadoop 1.0, also known as Hadoop MapReduce version 1 (MRv1), had Several limitations led to the development of Hadoop 2.0 (YARN – Yet Another Resource Negotiator) to address these challenges.
- Single Point of Failure – JobTracker
- Limited Scalability
- Resource Management Challenges
- Fixed Map and Reduce Slots
- Limited Support for Different Workloads
44. Explain Hadoop MapReduce.
Ans:
Hadoop 1.0 primarily supported batch processing workloads through its MapReduce programming model. Real-time and interactive processing were challenging due to the limitations of the JobTracker.
- Map PhaseInput: The input data is divided into splits, and a Mapper task processes each split. The input data can be stored in the Hadoop Distributed File System (HDFS).
- Map Function: The Map function is a user-defined function that processes the input data and produces a set of intermediate key-value pairs. The Map function is applied independently to each split in parallel across the cluster.
- Shuffle and Sort: The intermediate key-value pairs from multiple Map tasks are shuffled and sorted by key. This process ensures that all values associated with the same critical end up together. The goal is to organise the data to make it easier for the Reducer tasks to process.
45. What is Apache Pig?
Ans:
Apache Pig is a high-level scripting platform built on top of the Hadoop ecosystem, specifically designed to simplify the development of complex data processing tasks. Yahoo developed Pig! and later contributed to the Apache Software Foundation. However, Pig remains a valuable tool in the Hadoop ecosystem for users looking for a high-level abstraction for data processing tasks.
46. What is an Apache Hive?
Ans:
Apache Hive is a data warehousing and SQL-like query language system built on the Hadoop ecosystem. It provides a high-level interface for managing and querying large datasets stored in Hadoop Distributed File System (HDFS) or other compatible file systems.
- Integration with Hadoop Ecosystem
- HiveQL (HQL)
- Data Definition Language (DDL) and Data Manipulation Language (DML)
- Schema on Read
47. List the YARN components.
Ans:
- ResourceManager (RM)
- NodeManager (NM)
- ApplicationMaster (AM)
- Container
- Resource Scheduler
- Resource Manager Web UI
- NodeManager Web UI
- Timeline Server
48. List Hadoop HDFS Commands.
Ans:
- Creating a Directory
- Copying from Local File System to HDFS
- Copying from HDFS to Local File System
- Listing Files and Directories
- Viewing File Contents
- Moving or Renaming a File/Directory
- Removing a File
- Checking Disk Usage
- Getting Help
49. How can you skip the bad records in Hadoop?
Ans:
In Hadoop, you can skip bad records during data processing to handle and filter out records that may cause errors or exceptions. Always refer to the documentation of the tools or frameworks you are working with for more detailed and context-specific information. The tools you use and the programming languages involved in your Hadoop ecosystem.
50. Explain the actions followed by a Jobtracker in Hadoop.
Ans:
The concept of a JobTracker is specific to Hadoop 1.0, and it was a critical component in the MapReduce framework before the introduction of YARN (Yet Another Resource Negotiator) in Hadoop 2.0.
In Hadoop 1.0, the JobTracker was responsible for managing and coordinating the execution of MapReduce jobs across the Hadoop cluster.YARN provides a more flexible and scalable architecture for managing resources and executing various applications beyond MapReduce.

Develop Your Skills with Hadoop Admin Certification Training
Weekday / Weekend BatchesSee Batch Details51. What applications are supported by Apache Hive?
Ans:
Apache Hive is a data warehousing and SQL-like query language system built on the Hadoop ecosystem. It provides a high-level interface for managing and querying large datasets stored in Hadoop Distributed File System (HDFS) or other compatible file systems.
While Hive was initially developed to work with MapReduce, it has evolved to support various data processing engines, making it a versatile tool within the Hadoop ecosystem.
52. What is Apache Flume in Hadoop?
Ans:
Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating and moving large volumes of log data from various sources to a centralised
data store. It is part of the Apache Hadoop project. It is designed to simplify ingesting and transporting streaming data into Hadoop ecosystems, such as Hadoop Distributed File System (HDFS) or Apache HBase.
53. Explain the architecture of Flume
Ans:
Apache Flume follows a modular and extensible architecture designed to efficiently collect, aggregate, and transport large volumes of log data from various sources to a centralised data store.
- Agent
- Source
- Channel
- Sink
- Interceptor
54. What do you understand about fsck in Hadoop?
Ans:
In Hadoop, fsck stands for File System Check. It is a command-line tool used to check the consistency and health of the Hadoop Distributed File System (HDFS). The fsck tool examines the file system metadata and helps identify any issues, inconsistencies, or corruption in the HDFS file system.
55. Can you explain some of the essential features of Hadoop?
Ans:
Certainly! Hadoop is a distributed computing framework designed to
process and store large volumes of data in a scalable and fault-tolerant manner. Some of the essential features of Hadoop include:
- Distributed Storage
- Distributed Processing
- Scalability
- Fault Tolerance
- Data Locality
- Open Source
56. In what modes can Hadoop be run?
Ans:
- Local (Standalone) Mode: Hadoop runs on a single machine as a single Java process in local mode. This mode is primarily used for development and testing purposes on a local machine.
- Pseudo-Distributed Mode: Pseudo-distributed mode simulates a multi-node cluster on a single machine. Each Hadoop daemon runs in a separate Java process, and they communicate with each other locally.
- Cluster (Fully Distributed) Mode: Hadoop is deployed on a real multi-node cluster in fully distributedmode.
- Hadoop on Cloud Platforms: Hadoop clusters on the cloud can be configured to use cloud storage services (e.g., Amazon S3, Azure Blob Storage) as the underlying file system.
- Containerized Deployments: Hadoop can be containerized using container orchestration tools like Docker and Kubernetes.
57. What are the real-time industry applications of Hadoop?
Ans:
Hadoop is used across various industries for real-time or near-real-time big data processing, analytics, and insights. Some of the notable industry applications of Hadoop include:
- Financial Services
- Telecommunications
- Healthcare
- Media and Entertainment
- Cybersecurity
- Government and Public Sector
58. Can you list the components of Apache Spark?
Ans:
Apache Spark is an open-source distributed computing system that provides fast and general-purpose data processing for big data analytics.
- Spark Core
- Spark SQL
- Spark Streaming
- MLlib (Machine Learning Library):
- Catalyst Optimizer
- PySpark
59. What is the Hadoop Ecosystem?
Ans:
The Hadoop ecosystem is a collection of open-source software projects that work together to solve significant data processing and storage challenges. These projects are designed to extend the capabilities of the Apache Hadoop framework, providing a comprehensive ecosystem for various data processing needs.
The Hadoop ecosystem continually evolves, adding new projects and tools to address emerging challenges and requirements in the ample data space.
60. Name the different configuration files in Hadoop.
Ans:
Hadoop uses several configuration files to manage various aspects of its
configuration.
- Core-site.xml:
- Hdfs-site.xml:
- Mapred-site.xml:
- Yarn-site.xml:
- Hadoop-env. Sh:
61. Can you skip the bad records in Hadoop? How?
Ans:
Yes, in Hadoop, you can skip or handle bad records during data processing to ensure that the processing job continues without failing due to issues in specific records.
Missing bad records is especially useful when data quality issues or corrupt records may be present in the input data.
62. What are the most common input formats in Hadoop?
Ans:
Here are some of the most common InputFormats used in Hadoop:
- TextInputFormat
- CombineFileInputFormat
- SequenceFileInputFormat
- KeyValueTextInputFormat
- DBInputFormat
63. What is a SequenceFile in Hadoop?
Ans:
In Hadoop, a SequenceFile is a binary file format for storing key-value pairs. It is a standard and efficient file format for intermediate data storage in MapReduce jobs. SequenceFiles are compact, splittable (can be split into multiple input splits for parallel processing), and support compression.
Critical features of SequenceFiles in Hadoop include:
- Key-Value Pairs
- Serialization Format
- Splittable
- Compression
- Block Compression
64. What is the role of a JobTracker in Hadoop?
Ans:
In Hadoop’s MapReduce framework, the JobTracker is a central component responsible for coordinating and managing the execution of MapReduce jobs across a Hadoop cluster. The JobTracker plays a crucial role in the overall functioning of the MapReduce processing framework.
- Job Submission
- Task Assignment
- TaskTracker Coordination
- Monitoring and Fault Tolerance
- Scheduling
- Data Locality Optimization
65. Why does Hive not store metadata in HDFS?
Ans:
Apache Hive, a data warehousing and SQL-like query language system built on. On top of Hadoop, it stores its metadata in a relational database rather than in Hadoop Distributed File System (HDFS). This choice depends on the specific requirements and preferences of the organization deploying Hive.
66. Which companies use Hadoop?
Ans:
Since my last knowledge update in January 2022, many large enterprises and organizations across various industries have adopted Hadoop for big data processing and analytics.
- Yahoo
- Netflix
- Amazon
67. What daemons are needed to run a Hadoop cluster?
Ans:
A Hadoop cluster comprises several daemons, each serving a specific role in the distributed storage and processing of data. Collectively, these daemons form the core components of a Hadoop ecosystem.
The required daemons depend on the specific services and components you deploy in your Hadoop cluster. Always refer to the documentation of the Hadoop distribution and version you use for the most accurate and up-to-date information.

Get JOB Oriented Hadoop Admin Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
68. Which OS is supported by Hadoop deployment?
Ans:
Hadoop is designed to be platform-independent and can be deployed on various operating systems. However, Linux is the primary and most widely used operating system for Hadoop deployments.
Additionally, cloud-based solutions such as Amazon EMR, Google Cloud Dataproc, and Microsoft Azure HDInsight provide managed Hadoop services, abstracting the underlying operating system from the user.
69. What modes can Hadoop code be run in?
Ans:
Hadoop code can be run in different modes, and its operation mode affects how the Hadoop cluster is utilized. The primary modes in which Hadoop code can be run are:
- Local (Standalone) Mode
- Pseudo-Distributed Mode
- Cluster (Distributed) Mode
70. What happens when the NameNode is down?
Ans:
The NameNode in Hadoop is a critical component that manages the
Hadoop Distributed File System (HDFS) metadata. If the NameNode goes down or becomes unavailable, it has significant implications for the Hadoop cluster. The unavailability of the NameNode is a critical event in a Hadoop cluster that affects HDFS operations and MapReduce jobs.
71. Is there any standard method to deploy Hadoop?
Ans:
Deploying Hadoop involves setting up a distributed computing environment that includes various components such as the Hadoop Distributed File System (HDFS), ResourceManager, NodeManager, and others.
While there isn’t a single “one-size-fits-all” method for deploying Hadoop, common approaches and tools are widely used in the Hadoop ecosystem.
72. Name some essential Hadoop tools for working with big data practically.
Ans:
The Hadoop ecosystem comprises many tools and frameworks designed to handle various big data processing and analytics aspects. Here are some essential Hadoop tools commonly used for practical considerable data work.
These tools, among others, contribute to the rich and diverse Hadoop ecosystem, providing solutions for various aspects of ample data storage, processing, analytics, and management.
73. What are the essential features of Hadoop?
Ans:
Hadoop is an open-source framework for the distributed storage and processing of large datasets. It comprises several core features that make it suitable for big data analytics and handling massive amounts of information.
While the ecosystem has evolved with the introduction of new technologies, Hadoop remains a foundational framework in the extensive data landscape.
74. Explain what NameNode is in Hadoop.
Ans:
In Hadoop, the NameNode is a critical component of Hadoop.
Distributed File System (HDFS). It plays a central role in managing and maintaining the metadata for the files and directories stored in HDFS. The metadata includes information such as the file names, directory structures, permissions, and the mapping of data blocks to their corresponding data nodes.
Its availability, reliability, and efficient management of data block locations are essential for the overall performance and reliability of Hadoop clusters.
75. Explain what WebDAV is in Hadoop.
Ans:
WebDAV, which stands for Web Distributed Authoring and Versioning, is a set of extensions to the HTTP (Hypertext Transfer Protocol) that enables collaborative editing and managing files on remote web servers. In the context of Hadoop, WebDAV can be used to access and interact with the Hadoop Distributed File System (HDFS) over the web.
Sers and administrators should evaluate whether WebDAV aligns with their specific use cases, requirements, and security considerations.
76. Mention the data storage component used by Hadoop.
Ans:
Hadoop uses the Hadoop Distributed File System (HDFS) as its primary data storage component. HDFS is a distributed, scalable, and fault-tolerant file system designed to store and manage large volumes of data across a cluster of commodity hardware.
It is an essential component of the Apache Hadoop framework and is specifically designed to handle big data workloads.
- Distributed Storage
- Scalability
- Fault Tolerance
- High Throughput
- Data Locality
77. how will you write a custom partitioner for a Hadoop job?
Ans:
In Hadoop MapReduce, a custom partitioner can be implemented to control how the output of the map tasks is distributed among the reduced tasks. The partitioner determines which reducer a particular key-value pair should use based on the key.
- Create a Custom Partitioner Class
- Implement Custom Logic in get partition Method
- Configure the Custom Partitioner in the Job Configuration
78. Explain what a “map” is and what a “reducer” is in Hadoop.
Ans:
In Hadoop, the “map” operation refers to the first phase of the MapReduce programming model. The map phase processes input data in parallel across a distributed Hadoop cluster.
In Hadoop, the “reducer” is the second phase of the MapReduce programming model. The reducer phase takes over after the “map” phase processes input data and produces intermediate key-value pairs.
79. Explain what a Task Tracker is in Hadoop.
Ans:
A Task Tracker is a component of the Hadoop MapReduce framework responsible for executing tasks on the nodes of a Hadoop cluster.
The Task Tracker runs on each DataNode in the cluster and manages and performs individual tasks assigned to it by the JobTracker.YARN provides a more flexible and scalable architecture for resource management and job execution in Hadoop clusters.
80. Explain what the purpose of RecordReader in Hadoop is.
Ans:
In Hadoop, a RecordReader is a crucial component of the Hadoop
MapReduce framework that plays a key role in reading and parsing input data during the map phase.
The purpose of the RecordReader is to break down the input data into key-value pairs that the Mapper can process. It defines how input data is read, parsed, and transformed into key-value pairs that the Mapper can process.
81. What happens when two clients try to access the same file in the HDFS?
Ans:
In the Hadoop Distributed File System (HDFS), when two clients try to
access the same file simultaneously, the behavior depends on the nature of the access and the operations being performed. HDFS is designed to support concurrent access by multiple clients, but the specific outcome can vary based on the operations being executed. Clients need to implement coordination mechanisms to avoid conflicts and maintain data consistency.
82. Explain “Distributed Cache” in a “MapReduce Framework.”
Ans:
In the context of the Hadoop MapReduce framework, the Distributed Cache is a feature that efficiently distributes small, read-only files or archives (such as libraries, configuration files, or lookup tables) to all the nodes in a Hadoop cluster. This feature helps improve the performance of MapReduce jobs by making necessary files or resources available to all the nodes where the tasks are running. This, in turn, reduces the need for repetitive data distribution and improves the overall performance of MapReduce jobs.
83. What is Avro Serialization in Hadoop?
Ans:
Avro is a data serialization framework developed within Apache. Hadoop project. Avro provides a compact binary serialization format designed to be fast and efficient for the serialization and deserialization of data, making it particularly suitable for use in Hadoop and other distributed systems.it is a popular choice for tasks such as data storage, data interchange, and communication between components in a Hadoop cluster.
84. What is a Checkpoint Node in Hadoop?
Ans:
As of my knowledge cutoff in January 2022, there is no specific concept known as a “Checkpoint Node” in the standard Hadoop architecture. However, Hadoop has several vital components, some of which are critical for the overall functioning of the Hadoop Distributed File System (HDFS). there might be custom configurations of elements called “Checkpoint Nodes.” Always consult the documentation specific to the version and distribution of Hadoop you are working with for accurate information.
85. What are Writables, and explain their importance in Hadoop?
Ans:
Writables are a set of data types and a serialization framework used for efficient and compact serialization and deserialization of data. The concept of Writables is primarily associated with the Hadoop MapReduce framework and Hadoop Distributed File System (HDFS). Their compact binary format and support for custom data types contribute to optimizing data storage, transfer, and processing in distributed computing environments.
86. What is the purpose of Distributed Cache in a MapReduce Framework?
Ans:
The Distributed Cache in a MapReduce framework is a feature designed to efficiently distribute read-only data or files to all nodes in a Hadoop cluster.
This feature plays a crucial role in enhancing the performance of MapReduce jobs by making necessary files or resources available locally to each node where tasks are executed.
87. What is the use of SequenceFileInputFormat in Hadoop?
Ans:
SequenceFileInputFormat is a specific input format in Hadoop designed to read data stored in the SequenceFile format. The SequenceFile format is a binary file format used in Hadoop to store key-value pairs. It is a compact and efficient format, especially suitable for large-scale data processing in the Hadoop ecosystem. The SequenceFileInputFormat is set as the input format for the MapReduce job, indicating that the input data is in the SequenceFile format.
88. Where does Hive store table data in HDFS?
Ans:
A data warehouse infrastructure built on Hadoop stores table data in Hadoop Distributed File System (HDFS). The location in HDFS where Hive stores the data for a table is determined by the LOCATION clause specified during table creation or modification. The actual data files are stored in subdirectories within the selected location.
89. What happens when the NameNode on the Hadoop cluster goes down?
Ans:
The NameNode is a critical component in the Hadoop Distributed File System (HDFS) and is responsible for managing metadata and maintaining the file system’s namespace.
It can have significant implications for the availability and accessibility of the entire file system. Implementing an HA setup is recommended for critical production environments to ensure continuous availability and fault tolerance in the face of NameNode failures.
90.Which is the best operating system to run Hadoop?
Ans:
Hadoop is designed to be platform-independent, and it can run on various operating systems. The choice of the operating system for running Hadoop often depends on factors such as the specific requirements of your environment, team expertise, and organizational preferences. Linux, in particular, remains the dominant choice for large-scale Hadoop deployments in production environments.
91. What is the role of a Secondary NameNode in Hadoop?
Ans:
The Secondary NameNode in Hadoop is a misleading term, as it does not serve as a backup or secondary NameNode in the event of the primary NameNode failure.
Instead, the Secondary NameNode plays a role in performing periodic checkpoints to help reduce the startup time of the primary NameNode and improve the overall reliability of the Hadoop Distributed File System (HDFS).
92. What will happen if two users try to access the same file in HDFS?
Ans:
Hadoop Distributed File System (HDFS) is designed to support multiple users’ concurrent read access to the same file. However, write operations are typically not supported simultaneously by various users for the same file. It’s important to note that Hadoop’s typical use case involves batch processing and large-scale data processing, where multiple users may be reading and writing to different files or directories concurrently.
93. How can we check whether the Hadoop daemons are running?
Ans:
You can use various commands and methods to check whether Hadoop daemons are running. Choose the method that best suits your needs and the specific information you seek. Combining these approaches can help you effectively monitor the status of Hadoop daemons in your cluster.
94. Why is HDFS Fault-Tolerant?
Ans:
Hadoop Distributed File System (HDFS) is designed to be fault-tolerant to ensure data reliability and availability in large-scale distributed storage environments.
The fault-tolerance mechanisms in HDFS address the challenges of hardware failures, data corruption, and other issues that can occur in a distributed system.
95. How can Native Libraries be Included in YARN Jobs?
Ans:
To include native libraries in YARN (Yet Another Resource Negotiator) jobs, you must follow specific steps to ensure the required native libraries are available on the nodes where the YARN containers will run. Native libraries are typically platform-specific and may need to be distributed to the nodes along with your YARN application. Consider the security and permissions required to distribute and execute native libraries on the cluster.




