Last updated on 03rd Jul 2020| 2951
HBase, short for Hadoop Database, is an open-source, distributed NoSQL database system designed for handling vast volumes of data. It operates within a distributed architecture, leveraging the Hadoop Distributed File System (HDFS) to store and manage data across multiple nodes in a cluster. Unlike traditional relational databases, HBase stores data in a columnar format, optimizing it for read-heavy workloads and analytical queries. One of its standout features is schema flexibility, allowing effortless addition or modification of columns without impacting existing data. HBase also offers strong consistency for operations within a single row, making it suitable for applications requiring data integrity. Its scalability is horizontal, enabling seamless expansion by adding nodes as data volumes increase.
Moreover, HBase excels in low-latency random reads and writes, rendering it ideal for applications necessitating rapid data access. Automatic sharding, the use of Bloom filters, and integration with the broader Hadoop ecosystem further enhance its capabilities. With applications spanning time-series data, IoT, real-time analytics, and backend storage for web services, HBase is a robust choice for managing and querying large-scale, semi-structured, or unstructured data in distributed environments.
1. What is HBase?
Ans:
HBase is an open-source, distributed, scalable, and NoSQL database system intended for managing and storing massive amounts of structured and semi-structured data. It is part of the Apache Hadoop ecosystem and provides real-time read and write access to Big Data, making it suitable for applications requiring high-speed data access.
2. Explain the key features of HBase
Ans:
HBase’s key features include horizontal scalability, automatic sharding, high availability, fault tolerance, low-latency reads and writes, strong consistency, schema flexibility, and easy integration with other Hadoop ecosystem tools. It offers a distributed and decentralized architecture to handle large datasets efficiently.
3. How does HBase differ from traditional relational databases?
Ans:
HBase differs from traditional relational databases primarily in terms of schema flexibility, horizontal scalability, and data distribution. Unlike relational databases, HBase does not require a fixed schema and can adapt to changing data structures. It horizontally scales by distributing data across multiple servers and allows for automatic sharding. Additionally, HBase is optimized for high-volume, low-latency read and write operations.
4. What is the data model in HBase?
Ans:
The data model in HBase is a sparse, multi-dimensional, and distributed table. Data is organized into tables where each row has a unique row key, and each row can have multiple columns grouped into column families. Columns within families are stored together on disk for efficiency, and columns themselves can be added or modified without altering the entire table schema.
5. What is the difference between HBase and HDFS?
Ans:
HBase and Hadoop Distributed File System (HDFS) are both part of the Hadoop ecosystem but serve different purposes. A distributed file system called HDFS is made to store huge files., mainly for batch processing. In contrast, HBase is a distributed NoSQL database built on top of HDFS, providing real-time random read and write access to data. HBase uses HDFS for storing its data.
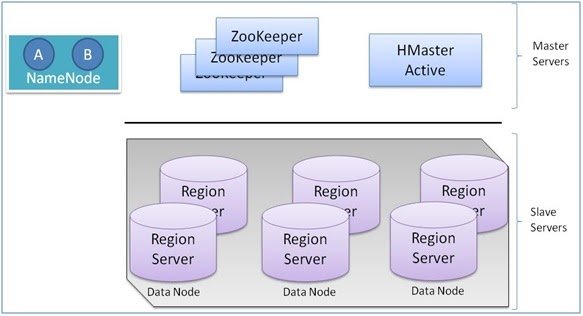
6. Describe the architecture of HBase.
Ans:
HBase follows a master-slave architecture. It consists of a single HBase Master server responsible for administrative tasks like table creation and region assignment. RegionServers manage data storage and serve read and write requests. HBase also relies on ZooKeeper for coordination and metadata storage.
7. What is the role of the HBase Master server?
Ans:
The HBase Master server is responsible for coordinating and managing the HBase cluster. It assigns regions to RegionServers, handles schema changes, and keeps track of the cluster’s overall health. However, it is not involved in serving data requests directly.
8. What is the role of RegionServers in HBase?
Ans:
RegionServers are responsible for serving data requests from clients. They manage one or more regions, which are horizontal partitions of a table. RegionServers handle data storage, reads, writes, and compactions. They continuously communicate with the HBase Master for coordination.
9. Explain the purpose of the HBase ZooKeeper ensemble.
Ans:
The HBase ZooKeeper ensemble provides distributed coordination and management services for HBase. It maintains crucial metadata and configuration information, such as the location of RegionServers, table schema, and region assignment. ZooKeeper helps ensure consistency and high availability in the HBase cluster.
10. What are the components of the HBase write path?
Ans:
The HBase write path involves the following components:
- Client: Initiates the write request.
- HBase Client Library: Communicates with ZooKeeper to locate the correct RegionServer.
- RegionServer: Accepts the write request, validates it, and writes the data to the MemStore.
- MemStore: In-memory data structure where data is temporarily stored before being flushed to HFiles on disk.
- HFiles: On-disk storage files where data is stored in a sorted, columnar format.
11. What is a table in HBase?
Ans:
A table in HBase is a collection of rows organized for efficient storage and retrieval of data. Each table has a unique name and consists of one or more column families.
12. How are rows and columns organized in an HBase table?
Ans:
Rows in an HBase table are identified by unique row keys and are organized lexicographically. Columns are grouped into column families, allowing efficient storage and retrieval of related data together.
13. Explain the concept of column families in HBase.
Ans:
Column families are logical groupings of columns within an HBase table. Columns within the same family are stored together on disk and typically represent related data. Defining column families helps optimize storage and retrieval in HBase.
14. What is a cell in HBase?
Ans:
A cell in HBase is the intersection of a row and a column, identified by its row key, column family, column qualifier, and timestamp. It stores a single value and can have multiple versions based on timestamps.
15. Can you have a table in HBase without a column family?
Ans:
No, every table in HBase must have at least one column family. Column families serve as a fundamental unit of data organization and storage in HBase.
16. How is data versioning handled in HBase?
Ans:
HBase supports data versioning by allowing multiple versions of a cell to be stored. Each version is associated with a timestamp, which provides temporal data access and retrieval.
17. What is the purpose of timestamps in HBase?
Ans:
Timestamps in HBase allow multiple versions of data to be stored for a cell. They enable historical data retrieval and are useful for applications requiring versioned data or point-in-time queries.
18. How does HBase handle column qualifiers?
Ans:
Column qualifiers, along with the column family, uniquely identify a cell within a row. They are used to distinguish different columns within the same column family, enabling efficient data access.
19. What is a row key in HBase, and why is it important?
Ans:
A row key in HBase is a unique identifier for each row within a table. It is crucial because it determines the row’s physical storage location and is used for fast data retrieval. Careful selection of row keys is essential for optimizing HBase performance and data access.
20. How do you create a table in HBase?
Ans:
To create a table in HBase, you use the create command in the HBase shell or HBase Java API, specifying the table name and column families along with optional configuration settings.
21. What is the command to put data into an HBase table?
Ans:
To insert data into an HBase table, you use the put command in the HBase shell or the Put operation in the HBase Java API, providing the table name, row key, column family, column qualifier, and value.
22. How do you delete a row in HBase?
Ans:
You can delete a row in HBase using the delete command in the HBase shell or the Delete operation in the HBase Java API, specifying the table name and row key to be deleted.
23. Explain the difference between a Get and a Scan operation in HBase.
Ans:
A Get operation retrieves a specific row by its row key, returning the row with all its columns. In contrast, a Scan operation scans multiple rows within a specified range, returning selected columns for each matching row.
24. What is the purpose of the Delete operation in HBase?
Ans:
The Delete operation in HBase is used to remove data from a table. It can delete specific cells, entire rows, or even a range of versions of a cell, allowing data cleanup and retention control.
25. How can you perform atomic operations in HBase?
Ans:
Atomic operations in HBase are achieved using techniques like Check-and-Put or Check-and-Delete. These operations ensure that a write is only executed if a certain condition (e.g., the existing value matches a given criterion) is met, ensuring data consistency.
26. Describe the process of modifying the schema of an existing HBase table.
Ans:
Modifying the schema of an existing HBase table involves disabling the table, altering its configuration (e.g., adding or removing column families), and then re-enabling the table. It’s important to plan schema modifications carefully to avoid data loss or disruption.
27. What is compaction in HBase, and why is it necessary?
Ans:
Compaction in HBase is the process of merging and cleaning up HFiles to optimize storage and performance. It is necessary to reclaim space, improve data locality, and reduce the number of files for efficient data retrieval.
28. How do you perform a bulk import of data into HBase?
Ans:
To perform a bulk import of data into HBase, you can use tools like ImportTsv or custom MapReduce jobs. These tools allow you to efficiently load large volumes of data from external sources into an HBase table.
29. What is the HFile format in HBase?
Ans:
HFile is a file format used by HBase for efficient storage of data on disk. It stores key-value pairs sorted by key, providing fast random access and efficient compression.
30. Explain the process of data write amplification in HBase.
Ans:
Data write amplification occurs in HBase when data is initially written to a MemStore in-memory buffer, then flushed to HFiles on disk during compaction. This results in more disk I/O than the original write but optimizes data storage and retrieval.

Get Practical Oriented HBase Certification Course By Experts Trainers
Weekday / Weekend BatchesSee Batch Details31. How does HBase handle data distribution and load balancing?
Ans:
HBase automatically splits tables into regions based on row key ranges to distribute data across RegionServers. Load balancing ensures an even distribution of regions among servers, optimizing resource utilization.
32. What is the purpose of the Write-Ahead Log (WAL) in HBase?
Ans:
The Write-Ahead Log (WAL) in HBase is used to record all data modifications before they are applied to the MemStore. It provides durability and crash recovery by allowing data to be reconstructed in case of server failures.
33. How are the regions split in HBase?
Ans:
Regions in HBase are split based on the configured region split policy or manually by an administrator. Automatic splits occur when a region grows beyond a predefined size, splitting it into two smaller regions.
34. What is the MemStore in HBase, and how does it work?
Ans:
The MemStore is an in-memory buffer where recently written or updated data is temporarily stored before being flushed to HFiles on disk during compaction. It accelerates read operations by avoiding disk reads for frequently accessed data.
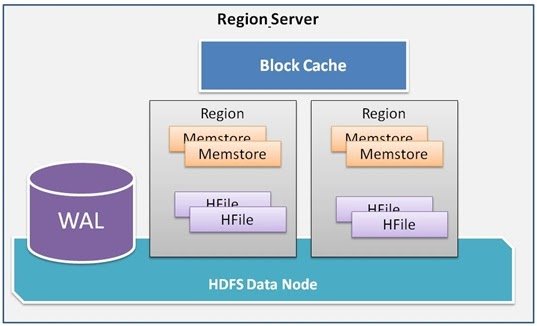
35. Describe the concept of block caching in HBase.
Ans:
Block caching in HBase involves storing frequently accessed HFile blocks in memory to reduce disk I/O. It improves read performance by serving data directly from memory, reducing latency for frequently accessed data.
36. How does HBase handle data compression?
Ans:
HBase supports data compression at the block level within HFiles. It uses compression algorithms like Snappy or LZO to reduce storage space requirements and improve read and write performance. Compression can be configured per column family in a table.
37. What are the key factors that can affect HBase performance?
Ans:
Key factors affecting HBase performance: Factors include hardware resources, data modeling, schema design, region distribution, compaction settings, and cluster size. Efficient management of these factors is crucial for optimal HBase performance.
38. How can you optimize read operations in HBase?
Ans:
Optimizing read operations in HBase: Optimize reads by using appropriate data modeling, caching, and filter mechanisms. Implement techniques like block caching, bloom filters, and column projections to reduce latency and improve read efficiency.
39. What strategies can be used to improve the write performance of HBase?
Ans:
Strategies to improve write performance in HBase: Enhance write performance by batch loading data, optimizing schema design to minimize writes, increasing RegionServer count, using Write-Ahead Logs (WAL) judiciously, and tuning HBase configuration parameters for write-heavy workloads.
- HBase Snapshots: Create a snapshot of the table using the snapshot command, which allows for efficient and consistent backups.
- Backup Tools: Several third-party backup tools, such as Apache HBase Backup and Restore, can automate and simplify the backup process.
40. Explain the role of Bloom Filters in HBase performance optimization.
Ans:
Role of Bloom Filters in HBase performance optimization: Bloom Filters reduce disk I/O by checking whether a requested data block might contain the desired data. They reduce read amplification and improve query performance by reducing unnecessary disk access.
41. How can you monitor and analyze the performance of an HBase cluster?
Ans:
Monitoring and analyzing HBase cluster performance: Use monitoring tools like Hadoop Metrics, JMX, and third-party solutions to track key metrics such as request latency, RegionServer health, and resource utilization. Analyze logs and metrics to identify bottlenecks and make informed performance improvements.
42. What is the importance of region sizing in HBase performance tuning?
Ans:
Importance of region sizing in HBase performance tuning: Proper region sizing is essential for balanced resource utilization. Smaller regions minimize hotspots and improve parallelism but may increase metadata overhead. Larger regions reduce metadata but may lead to uneven distribution and performance issues. Fine-tuning region sizing optimizes HBase performance.
43. How does HBase handle authentication and authorization?
Ans:
HBase uses Apache Hadoop’s security mechanisms for authentication and authorization. Authentication is typically handled through Kerberos or other authentication providers. Authorization is managed using Access Control Lists (ACLs) and privileges associated with HBase tables and data.
44. What is the difference between HBase cell-level security and table-level security?
Ans:
| Aspect | Cell-Level Security | Table-Level Security | |
| Scope | Granular, per cell | Uniform, entire table | |
| Flexibility | Fine-grained control | Coarse-grained control | |
| Use Cases | Sensitive cell data | Uniform access needs | |
| Overhead | Potentially higher | Typically lower | |
| Administration | Complex | Simplified |
45. Explain how Access Control Lists (ACLs) work in HBase.
Ans:
ACLs in HBase are a set of rules that define permissions for users or groups at the table or cell level. ACLs grant or deny actions like read, write, and administrative privileges. HBase checks these ACLs during access attempts to determine whether the operation is allowed.
46. What is the purpose of HBase visibility labels?
Ans:
Purpose of HBase visibility labels: HBase visibility labels are used for data labeling and access control in multi-level security environments. Labels can be assigned to data cells to restrict visibility based on user clearances, ensuring sensitive data is only visible to authorized users.
47. How can you secure the communication between HBase clients and servers?
Ans:
Securing communication between HBase clients and servers: To secure communication, HBase clients and servers can use mechanisms like SSL/TLS encryption. Clients can enable secure mode to communicate with secure clusters, while servers can be configured with SSL certificates to ensure data privacy and integrity during transit. Proper configuration and certificate management are essential for securing the communication channel.
48. How can you back up an HBase table?
Ans:
To back up an HBase table, you can use various methods:
- HBase Export: Use the export command or the HBase Export API to create a copy of the table data in HFiles, which can be stored in a separate HDFS location.
49. What is the procedure for restoring an HBase table from a backup?
Ans:
Procedure for restoring an HBase table from a backup: To restore an HBase table from a backup, follow these general steps:
- Use the appropriate method to import or copy the backup data back into HBase.
- Restore snapshots using the clone_snapshot or restore_snapshot commands if you used HBase snapshots for backup.
- Ensure that the schema and configurations match the original table.
- If necessary, disable and re-enable the table to ensure consistency.
50. Explain the importance of Write-Ahead Logs (WALs) in recovery.
Ans:
Importance of Write-Ahead Logs (WALs) in recovery: Write-Ahead Logs (WALs) play a crucial role in HBase recovery. They record all changes before they are applied to MemStores and HFiles. In case of server failures, WALs are used to replay and reconstruct the data, ensuring durability and consistency during recovery.

Get Experts Curated HBase Training with Industry Trends Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
51. What is the role of snapshots in HBase backup and recovery?
Ans
Role of snapshots in HBase backup and recovery: HBase snapshots provide point-in-time, read-only views of tables, making them useful for backups. Snapshots allow for efficient and consistent backups without disrupting ongoing writes. In the event of data corruption or loss, snapshots can be used to restore the table to a specific point in time, ensuring data integrity and recovery capabilities.
52. What are some best practices for designing schema in HBase?
Ans:
Best practices for designing schema in HBase:
- Row Key Design: Choose a meaningful and evenly distributed row key to avoid hotspots and enable efficient data retrieval.
- Column Family Usage: Group related columns into column families to optimize storage and access.
- Avoid Wide Tables: Limit the number of columns per row to prevent wide tables, which can lead to performance issues.
- Data Denormalization: Denormalize data where necessary to minimize join operations.
- Compression: Apply appropriate compression algorithms to reduce storage space.
- Optimized Filters: Use filters efficiently to narrow down scan results.
- Versioning: Control data versioning by specifying appropriate timestamps.
53. How can you avoid hotspotting in HBase?
Ans:
How to avoid hot-spotting in HBase:
- Row Key Design: Distribute row keys evenly across regions to prevent hotspots. Use techniques like salting, pre-splitting, or hash-based keys.
- Randomize Writes: For time-series data, randomize row key components, like timestamp, to distribute writes evenly.
- Dynamic Row Key Assignment: Implement dynamic row key assignment strategies to balance load dynamically.
54. What are the common challenges and issues faced in HBase deployments?
Ans:
Common challenges and issues in HBase deployments:
- Region Hotspotting: Unevenly distributed data causing hotspots.
- Data Model Design: Poorly designed data models lead to inefficiencies.
- Hardware Constraints: Inadequate hardware resources affecting performance.
- Data Skew: Skewed data distributions cause performance imbalances.
- Compaction Overhead: Frequent compactions impacting write performance.
- Schema Evolution: Handling changes in table schemas gracefully.
- Monitoring and Diagnosis: Lack of comprehensive monitoring and diagnosis tools.
55. How do you handle schema evolution in HBase?
Ans:
Handling schema evolution in HBase:
- Use column families for flexibility when adding new columns.
- Employ versioning to maintain historical data.
- Modify existing schema gradually, ensuring compatibility with existing data.
- Maintain a schema evolution plan and test changes thoroughly.
56. What is the HBase Write Path bottleneck, and how can it be addressed?
Ans:
HBase Write Path bottleneck and mitigation:
- The Write Path bottleneck often occurs during the MemStore write and flush phases.
- To address it, optimize writes by tuning MemStore settings, optimizing compaction, and ensuring sufficient hardware resources.
- Distribute writes across multiple RegionServers, and monitor performance to detect bottlenecks early, allowing for proactive adjustments.
57. How do you set up an HBase cluster?
Ans:
How to set up an HBase cluster:
- Install Hadoop HDFS (Hadoop Distributed File System) for data storage.
- Install HBase on each node of the cluster.
- Configure HBase properties, such as HDFS and ZooKeeper integration, in the hbase-site.xml file.
- Start HBase services, including HMaster and RegionServers.
- Verify the cluster status using the HBase shell or web-based UIs.
58. What are the hardware requirements for an HBase cluster?
Ans:
Hardware requirements for an HBase cluster:
- CPU: Multi-core processors (e.g., quad-core) for adequate parallelism.
- RAM: Sufficient memory to accommodate RegionServers and data caching.
- Disk: SSDs or high-speed HDDs for storing HFiles and Write-Ahead Logs (WALs).
- Network: High-speed interconnect for efficient data transfer.
- Multiple nodes: HBase typically runs on a cluster of nodes for fault tolerance and scalability.
59. Explain the process of adding and removing RegionServers from an HBase cluster.
Ans:
Process of adding and removing RegionServers from an HBase cluster:
- To add a RegionServer, install HBase on a new node, configure it, and start the HBase service. HBase will automatically detect and integrate the new RegionServer into the cluster.
- To remove a RegionServer, decommission it gracefully through HBase’s administrative tools. Data will be moved to other RegionServers to maintain data availability.
60. What is the purpose of the HBase Balancer?
Ans:
Purpose of the HBase Balancer:
- The HBase Balancer is responsible for distributing regions evenly across RegionServers in the cluster. It helps maintain balanced workloads, preventing hotspots and ensuring efficient resource utilization.
61. How can you perform rolling restarts of RegionServers in HBase?
Ans:
Performing rolling restarts of RegionServers in HBase:
- To perform rolling restarts, stop one RegionServer at a time gracefully, allowing HBase to migrate regions to other RegionServers.
- After the first RegionServer is stopped, wait for the regions to redistribute.
- Repeat the process for each RegionServer in a controlled manner to minimize service disruption while ensuring balanced data distribution.
62. What is the role of HBase in Hadoop’s ecosystem?
Ans:
Role of HBase in Hadoop’s ecosystem:
- HBase serves as a distributed, scalable NoSQL database within Hadoop’s ecosystem.
- It complements Hadoop’s batch processing capabilities with real-time, random read and write access to data.
- HBase is commonly used for storing and serving data for applications like online analytics, sensor data processing, and real-time data processing, enabling a wide range of use cases within the Hadoop ecosystem.
63. How can you perform bulk data import/export between HBase and Hadoop?
Ans:
Performing bulk data import/export between HBase and Hadoop:
- Bulk Import: You can use the HBase ImportTsv utility or custom MapReduce jobs to import data into HBase. It loads data from HDFS files into an HBase table efficiently.
- Bulk Export: Exporting data from HBase can be done using the Export utility or custom MapReduce jobs. It extracts data from HBase tables and writes it to HDFS or other storage formats compatible with Hadoop.
64. What factors should you consider when designing an HBase data model?
Ans:
Factors to consider when designing an HBase data model:
- Row Key Design: Carefully choose the row key to optimize data access and distribution. It should be meaningful, evenly distributed, and avoid hotspots.
- Column Family Design: Group related columns into column families to optimize storage and retrieval.
- Denormalization: Denormalize data to minimize joins and enable efficient queries.
- Compression: Apply appropriate compression techniques to reduce storage requirements.
- Versioning: Decide on the level of data versioning required and manage timestamps.
- Filtering: Use filters judiciously to limit scan results.
- Schema Evolution: Plan for changes in data schema over time to maintain compatibility.
65. How can you handle relationships between data entities in HBase?
Ans:
Handling relationships between data entities in HBase:
- Embedded Entities: Use nested structures within cells or column families to represent relationships between data entities.
- Composite Row Keys: Incorporate references or identifiers to related entities within the row key to enable efficient joins during retrieval.
- Secondary Indexes: Create secondary indexes to facilitate the lookup of related entities based on specific criteria.
66. What is the recommended approach for time-series data modeling in HBase?
Ans:
Recommended approach for time-series data modeling in HBase:
- Row Key with Timestamp: Use a row key that incorporates a timestamp component to organize time-series data chronologically.
- Column Family for Metrics: Create a column family for each metric or data type to efficiently store and query related data.
- Versioning: Leverage HBase’s versioning capabilities to store historical data and support time-based queries.
- TTL (Time-to-Live): Apply Time-to-Live settings to automatically expire old data to manage data retention.
67. Explain the different types of compaction in HBase.
Ans:
Different types of compaction in HBase:
- Minor Compaction: Minor compaction is the process of compacting a small subset of HFiles within a single column family. It merges multiple small HFiles into a larger one and removes obsolete versions, improving read performance and reducing the number of files on disk.
- Major Compaction: Major compaction, also known as a ‘HBase compaction,’ involves compacting all HFiles in a column family. It results in a single, consolidated HFile per column family, reducing storage overhead and optimizing read performance.
68. How does HBase decide when to perform minor and major compactions?
Ans:
How HBase decides when to perform minor and major compactions:
- Minor Compaction: Minor compactions are triggered automatically when the number of HFiles in a column family or the number of versions of a cell exceeds predefined thresholds. It helps maintain efficient data access for frequently used data.
- Major Compaction: Major compactions are typically user-initiated and can be scheduled as needed. They consolidate all HFiles within a column family, usually triggered during maintenance windows to optimize storage and improve overall read performance.
69. What are the benefits of compaction?
Ans:
Benefits of compaction in HBase:
- Storage Optimization: Compaction reduces storage overhead by consolidating smaller HFiles into larger ones, minimizing disk space usage.
- Improved Read Performance: Compact HFiles are more efficient for reads, as data is organized sequentially, reducing the need for disk seeks.
- Version Cleanup: Compactions remove obsolete or outdated versions of data, helping to manage data retention and reducing query overhead.
- Mitigation of Write Amplification: By merging smaller files, compactions mitigate write amplification, where multiple small writes result from data modifications.
70. What are HBase coprocessors, and why are they used?
Ans:
HBase Coprocessors and their use:
- HBase Coprocessors are custom code modules that can be loaded into HBase RegionServers to provide custom processing, filtering, and aggregation of data.
- They are used to extend HBase’s functionality and perform operations close to the data, reducing data transfer and improving performance.
71. Provide examples of scenarios where coprocessors can be useful.
Ans:
Scenarios where coprocessors can be useful:
- Data Validation: Coprocessors can validate data as it’s written to HBase, ensuring data integrity and consistency.
- Secondary Indexing: They can help maintain secondary indexes for efficient querying of data.
- Aggregation: Coprocessors can aggregate data on the server side, reducing the need for expensive client-side operations.
- Access Control: Implement custom access control logic for fine-grained security.
- Real-time Data Processing: Execute real-time processing and analytics on incoming data.
72. List some commonly used HBase shell commands.
Ans:
Commonly used HBase shell commands:
- create: Create a new table.
- list: List all tables in the cluster.
- get: Retrieve data for a specific row.
- put: Insert or update data for a specific row.
- scan: Perform a scan operation on a table.
- delete: Delete data or tables.
- disable: Disable a table.
- enable: Enable a previously disabled table.
73. How do you create and delete tables using the HBase shell?
Ans:
Creating and deleting tables using the HBase shell:
- To create a table, use the create command followed by the table name and column family definitions. For example: create ‘mytable’, ‘cf1’, ‘cf2’.
- To delete a table, first disable it if it’s enabled using the disable command, then delete it with the delete command. For example: disable ‘mytable’ followed by delete ‘mytable’.
74. How does HBase maintain data consistency?
Ans:
How HBase maintains data consistency:
- HBase maintains data consistency through the use of Write-Ahead Logs (WALs) and a strict ordering of writes.
- All write operations are first recorded in WALs, ensuring durability and the ability to recover from crashes.
- The underlying HDFS storage layer provides fault tolerance and data replication.
- Read and write operations follow a strict sequence to maintain linearizability and consistency.
75. What is the concept of “eventual consistency” in HBase?
Ans:
Concept of “eventual consistency” in HBase:
- HBase offers strong consistency guarantees for read and write operations within a region but provides eventual consistency across the entire cluster.
- Eventual consistency means that after a write, it may take some time for all RegionServers to update and reflect the change uniformly.
- Users may experience temporary inconsistencies during this period, but the system eventually converges to a consistent state.
76. What are some real-world use cases for HBase?
Ans:
Real-world use cases for HBase:
- Time-Series Data Storage: Storing and querying time-series data, such as sensor data, log files, and financial data.
- Online Analytical Processing (OLAP): Supporting real-time OLAP queries for analytics and business intelligence.
- Content Management Systems (CMS): Managing content metadata, user profiles, and access control for web applications.
- IoT Data Ingestion: Collecting and processing large volumes of data from Internet of Things (IoT) devices.
- Recommendation Systems: Building personalized recommendation engines for e-commerce and content platforms.
77. How is HBase used in time-series data storage and analysis?
Ans:
How HBase is used in time-series data storage and analysis:
- HBase is well-suited for time-series data due to its efficient storage and retrieval capabilities.
- Time-series data is often organized with timestamps in the row key, allowing for easy chronological retrieval.
- HBase’s versioning feature allows for efficient storage of historical data, enabling queries for specific time ranges and trend analysis.
- HBase can be integrated with tools like Apache Phoenix and Apache Spark for real-time analytics on time-series data, making it a valuable solution for applications like IoT, monitoring systems, and financial analytics.
78. How do you perform regular maintenance tasks on an HBase cluster?
Ans:
Performing regular maintenance tasks on an HBase cluster:
- Monitoring: Regularly monitor cluster health, resource usage, and performance metrics.
- Backup: Implement a backup and restore strategy to protect data integrity.
- Compaction: Schedule and manage compaction tasks to optimize storage and performance.
- Logs and Monitoring: Rotate and manage logs, and use monitoring tools for proactive issue detection.
- Software Updates: Apply patches and updates as needed to maintain security and performance.
- Scaling: Adjust cluster capacity by adding or removing nodes to accommodate changing workloads.
79. What is the procedure for upgrading an HBase cluster to a newer version?
Ans:
Procedure for upgrading an HBase cluster to a newer version:
- Review the release notes and documentation for the new version.
- Perform a backup of the HBase data.
- Create a test cluster to test the upgrade process.
- Upgrade HBase components on a non-production cluster first.
- Validate and test the upgrade for compatibility and performance.
- Plan a scheduled downtime for the production cluster.
- Upgrade each node in the production cluster one by one.
- Test the cluster thoroughly after the upgrade.
- Update any client applications if necessary.
- Monitor the cluster for any issues post-upgrade
80. How can you achieve high availability in an HBase cluster?
Ans:
Achieving high availability in an HBase cluster:
- Replication: Enable data replication across multiple data centers or clusters for fault tolerance and data redundancy.
- Failover: Configure automatic failover mechanisms to redirect client requests to healthy RegionServers in case of node failures.
- Load Balancing: Distribute data evenly across RegionServers to avoid hotspots and improve availability.
- ZooKeeper Quorum: Ensure a reliable ZooKeeper quorum, as ZooKeeper plays a critical role in cluster coordination and leader election.
- Hardware Redundancy: Use redundant hardware components (e.g., power supplies, network connections) to minimize single points of failure.
81. Explain the role of ZooKeeper in HBase high availability.
Ans:
Role of ZooKeeper in HBase high availability:
- ZooKeeper is used for distributed coordination and leader election within an HBase cluster.
- It helps maintain metadata consistency, tracks active RegionServers, and handles failover scenarios.
- ZooKeeper ensures that the HBase Master and RegionServers remain coordinated and maintain high availability during cluster operations and node failures.
82. What tools are available for monitoring HBase performance?
Ans:
Tools for monitoring HBase performance:
- HBase Web UI: Provides real-time cluster status, region server metrics, and more.
- Ganglia and Ambari Metrics: Integrates with HBase for cluster monitoring and resource utilization.
- JMX Metrics: Exposes detailed Java Management Extensions (JMX) metrics for fine-grained monitoring.
- Hadoop Metrics: Hadoop’s built-in metrics system can be used to track HBase performance.
- Third-party solutions: Tools like Prometheus, Grafana, and Nagios can be integrated for advanced monitoring and alerting.
83. How can you set up alerting for HBase performance issues?
Ans:
Setting up alerting for HBase performance issues:
- Configure monitoring tools to track key metrics and thresholds.
- Define alerting rules based on metric deviations or specific conditions.
- Integrate alerting solutions like email notifications or paging systems (e.g., PagerDuty).
- Regularly review and adjust alerting thresholds to minimize false positives.
84. What is HBase data replication, and why is it used?
Ans:
HBase data replication and its use:
- HBase data replication involves replicating data from one HBase cluster (the source) to another (the destination) for data redundancy, disaster recovery, and off-site backup purposes.
- It is used to maintain data availability in case of cluster failures, region server crashes, or other unexpected outages.
85. Explain the HBase replication architecture.
Ans:
HBase replication architecture:
- HBase replication uses a Master-Slave architecture.
- The source cluster replicates data to the destination cluster using the ReplicationService.
- Write-Ahead Logs (WALs) are transmitted to the destination and replayed to keep the destination cluster in sync.
- A separate replication peer for each destination cluster is configured in the HBase Master.
86. How can you archive data in HBase for long-term storage?
Ans:
Archiving data in HBase for long-term storage:
- To archive data, create archival tables and use data copying mechanisms, like MapReduce jobs, to move data from live tables to archival tables.
- Set up retention policies to control the data to be archived.
- Adjust compaction policies and TTL settings to ensure data is archived before deletion.
87. What are the benefits of data archiving in HBase?
Ans:
Benefits of data archiving in HBase:
- Cost Savings: Archived data reduces storage costs on primary storage.
- Compliance: Ensures data retention for regulatory compliance.
- Historical Analysis: Allows historical data analysis and reporting.
- Performance: Improves the performance of live tables by reducing data volume.
88. How is HBase used for storing and analyzing IoT and sensor data?
Ans:
Using HBase for storing and analyzing IoT and sensor data:
- HBase provides real-time data ingestion and retrieval for IoT and sensor data.
- It supports time-series data modeling and efficient querying based on timestamps.
- Challenges include managing high ingestion rates, data volume, and retention policies.
89. What are the challenges in managing large volumes of IoT data in HBase?
Ans:
Challenges in managing large volumes of IoT data in HBase:
- High Ingestion Rate: Efficiently handling a high rate of incoming data.
- Data Retention: Managing and purging old data to control storage costs.
- Data Model Design: Creating effective data models for different types of IoT data.
- Scalability: Ensuring HBase clusters can scale to accommodate IoT data growth.
90. How can you optimize HBase for IoT use cases?
Ans:
- There are two main catalog tables in HBase which are ROOT and META. The purpose of the ROOT table is to track META table, and the META table is for storing the regions in HBase system.
- Are you a fresher aspired to make a career in Hadoop? Read our previous blog that will help you to start learning Hadoop for beginners.
91. What are the tombstones markers in HBase and how many tombstones markers are there in HBase?
Ans:
When a user deletes a cell in HBase table, though it gets invisible in the table but remains in the server in the form of a marker, which is commonly known as tombstones marker. During compaction period the tombstones marker gets removed from the server.
There are three tombstones markers :
- Version delete
- Family delete
- Column delete
92. Mention about a few scenarios when you should consider HBase as a database?
Ans:
Here are a few scenarios :
- When we need to shift an entire database
- To handle large data operations
- When we need frequent inner joins
- When frequent transaction maintenance is a need.
- When we need to handle variable schema.
- When an application demands for key-based data retrieval
- When the data is in the form of collections
93. What is the difference between HBase and Hive?
Ans:
Apache HBase and Apache Hive have a quite very different infrastructure which is based on Hadoop.
- Apache Hive is a data warehouse that is built on top of Hadoop whereas Apache HBase is a data store which is No SQL key/value based and runs on top of Hadoop HDFS.
- Apache Hive allows querying data stored on HDFS via HQL for analysis which gets translated to Map Reduce jobs. On the contrary Apache HBase operations run on a real-time basis on its database rather than as Map Reduce jobs.
- Apache Hive can handle a limited amount of data through its partitioning feature whereas HBase supports handling of a large volume of data through its key/value pairs feature.
- Apache Hive does not have versioning feature whereas Apache HBase provides versioned data.
94. Name some of the important filters in HBase.
Ans:
Column Filter, Page Filter, Row Filter, Family Filter, Inclusive Stop Filter
95. What is the column family? What is its purpose in HBase?
Ans:
Column family is a key in HBase table that represents the logical deviation of data. It impacts the data storage format in HDFS. Hence, every HBase table must have at least one column family.
96. What is BlockCache?
Ans:
HBase BlockCache is another data storage used in HBase. It is used to keep the most used data in JVM heap. The main purpose of such data storage is to provide access to data from HFiles to avoid disk reading. Each column family in HBase has its own BlockCache. Similarly, each Block in BlockCache represents the unit of data whereas an Hfile is a sequence of blocks with an index over those blocks.