
Last updated on 17th Apr 2024| 2744
Apache Storm, an open-source distributed real-time computation system, is tailored for processing extensive data streams swiftly and efficiently. It boasts scalability, fault tolerance, ease of use, and extensibility, featuring streaming topologies comprising spouts (data sources) and bolts (processing units). Additionally, it offers Trident for stateful processing and enjoys robust community support while seamlessly integrating with diverse systems.
1. What is Apache Storm?
Ans:
Apache Storm is a distributed real-time computation system for processing large data streams in real-time. It allows for scalable and fault-tolerant processing of data streams in real-time, making it suitable for applications like real-time analytics, machine learning, and ETL (Extract, Transform, Load) processes. Apache Storm is designed to process large data streams with low latency and high reliability. It works by distributing data processing across a cluster of machines, enabling parallel processing and fault tolerance.
2. What are the key components of Apache Storm?
Ans:
- Spouts: Components that emit data streams into the topology.
- Bolts: Units that process the data and produce output.
- Topologies: Directed acyclic graphs (DAGs) defining the structure and flow of data between spouts and bolts.
- Nimbus: The master server responsible for task distribution and cluster monitoring.
- Supervisor: Nodes that handle the execution of spouts and bolts on individual machines.
3. What is a Spout in Apache Storm?
Ans:
A Spout is a source of data stream in Apache Storm. It emits streams of tuples into the topology. It acts as the source of data streams, emitting tuples (data points) into the topology for processing by downstream components such as bolts. Spouts can fetch data from various sources such as Kafka, Twitter, or databases and continuously emit tuples as long as the topology is running.
4. What is a Bolt in Apache Storm?
Ans:
A Bolt is a processing unit in Apache Storm. It receives input tuples from Spouts or other Bolts, processes them, and emits new tuples as output. In Apache Storm, a bolt is a processing unit responsible for receiving and processing tuples (data points) emitted by spouts or other bolts. Bolts perform tasks like filtering, transforming, aggregating, or storing data before emitting it to other bolts or sinks. Think of them as the processing nodes in a Storm topology.
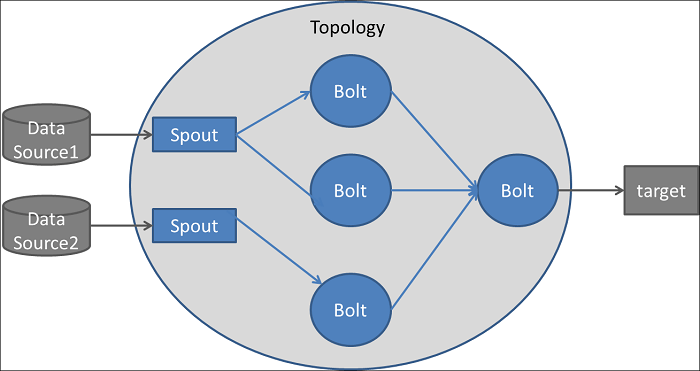
5. Explain the Topology in Apache Storm.
Ans:
A Topology in Apache Storm is a computation graph specifying how data should be processed. Spouts and Bolts are connected in a directed acyclic graph (DAG). Spouts and bolts are connected in a directed acyclic graph (DAG). Spouts are responsible for ingesting data into the topology, while bolts perform processing tasks on that data. Topologies define the data flow and processing logic, enabling scalable and fault-tolerant stream processing in Storm.
6. What is the role of Nimbus in Apache Storm?
Ans:
- Nimbus is the controller node in Apache Storm. It is responsible for distributing code across the cluster, assigning tasks to Supervisor nodes, and monitoring the cluster.
- Nimbus is the central coordinating daemon in Apache Storm. Its primary role is to distribute code across the cluster, assign tasks to supervisors, monitor task execution, and manage resources efficiently.
- Essentially, Nimbus is responsible for orchestrating and managing the execution of topologies within the Storm cluster.
7. What are Supervisor nodes in Apache Storm?
Ans:
- Supervisor nodes are worker nodes in Apache Storm. They are responsible for executing tasks assigned by Nimbus, such as running Spouts and Bolts.
- They are responsible for launching and monitoring worker processes, ensuring the assigned tasks are correctly executed, and reporting failures to the Nimbus daemon.
- Supervisor nodes also handle the distribution of resources and coordination of worker processes across the cluster. Essentially, they play a crucial role in the distributed execution of Storm topologies.
8. How does Apache Storm ensure fault tolerance?
Ans:
Apache Storm ensures fault tolerance through several mechanisms. It uses worker process supervision to monitor and restart processes if they fail. Message acknowledgement confirms that tuples have been processed successfully, while reliable tuple processing guarantees data integrity. Topology replication provides redundancy by duplicating the processing topology across multiple nodes. Continuous monitoring by Nimbus and Supervisor nodes maintains overall system health and performance.
9. Explain Acknowledgements in Apache Storm.
Ans:
Acknowledgments are used in Apache Storm to ensure that tuples are processed successfully. Spouts emit tuples with unique IDs, and Bolts emit acknowledgments once they process a tuple successfully. Acknowledgments in Apache Storm refer to the mechanism used to ensure message reliability between spouts and bolts. When a spout emits a tuple, it waits for confirmation or acknowledgment from the downstream bolt(s), indicating that it has been successfully processed.
10. Explain the difference between Trident and the traditional Apache Storm API.
Ans:
| Feature | Traditional Apache Storm API | Trident |
|---|---|---|
| Stateful Processing | Limited support for stateful processing. | Robust support for stateful stream processing |
| Abstraction Level | Low-level, manual management of state and tuples | Higher-level abstraction, simplifies state management |
| Transactional Guarantees | Does not inherently provide transactional guarantees. | Provides transactional guarantees for processing |
| Ease of Use | More boilerplate code and manual configuration. | Simpler API and constructs for easier usage |
11. How does Apache Storm achieve parallelism?
Ans:
Apache Storm achieves parallelism by running multiple instances of Spouts and Bolts in various worker nodes in the cluster. Apache Storm achieves parallelism through its distributed and fault-tolerant architecture. It utilizes a master-slave architecture where a controller node (Nimbus) distributes tasks to multiple worker nodes (Supervisors). Each worker node can execute tasks in parallel, and Storm manages parallelism through the concept of streams and spouts/bolts.
12. Explain the concept of stream grouping in Apache Storm.
Ans:
- Shuffle Grouping: Randomly distributes tuples across all bolt tasks.
- Fields Grouping: Sends tuples with the same field values to the same bolt task.
- All Grouping: Sends all tuples to all bolt tasks.
- Global Grouping: Sends all tuples to one bolt task.
- Direct Grouping: Sends tuples directly to a specific bolt task.
13. What is Shuffle grouping in Apache Storm?
Ans:
- Shuffle grouping in Apache Storm randomly distributes tuples among Bolts in a topology.
- Shuffle grouping in Apache Storm is a stream grouping strategy where tuples emitted by a spout or bolt are randomly distributed across all the tasks of a downstream bolt.
- Each tuple is sent to a random task, ensuring an even distribution of data processing load among the bolt tasks.
14. How does Apache Storm handle message processing guarantees?
Ans:
Apache Storm provides three message processing guarantees: at most, at least once, and exactly once. These guarantees can be achieved using Acknowledgements, Anchoring, and Transactional topologies. Apache Storm ensures message processing guarantees through tuple acknowledgment, tuple replay, and tuple anchoring mechanisms, providing configurable levels of reliability, such as at-least-once or at-most-once processing semantics.
15. Explain the message processing guarantee in Apache Storm at most once.
Ans:
In most one message processing guarantee, each tuple is processed by the topology at most once. There is no guarantee that every tuple will be processed. In Apache Storm, the “at most once” message processing guarantee means that each tuple is processed by the topology at most once. It is not replayed if a tuple fails during processing or due to a worker failure. This approach prioritizes low latency and minimizes duplicate processing but may result in potential data loss if processing failures occur.
16. Explain at least once the message processing guarantee in Apache Storm.
Ans:
In at least one message processing guarantee, each tuple is processed by the topology at least once. This ensures that no tuple is lost but may result in duplicate processing. In Apache Storm, the “at least once” message processing guarantee ensures that each tuple is processed by the topology at least once. Tuples are replayed if they fail during processing or due to worker failures, ensuring that no data is lost. While this approach ensures data integrity, it may result in duplicate processing and potentially higher latency.
17. Explain exactly what the message processing guarantee is in Apache Storm.
Ans:
- In a precisely one message processing guarantee, the topology processes each tuple exactly once. This ensures that no duplicates occur and that every tuple is processed.
- In Apache Storm, achieving an “exactly once” message processing guarantee involves ensuring that each tuple is processed precisely once without duplicates or losses, even during failures or retries.
- This requires careful coordination between message processing, acknowledgment, and state management mechanisms within the Storm topology to guarantee fault tolerance and data consistency.
18. How can exactly-once processing be achieved in Apache Storm?
Ans:
- Utilize idempotent processing logic.
- Implement transactional topologies.
- Use external state management systems.
- Anchor tuples to ensure replay consistency.
- Integrate with message queues supporting exactly-once semantics.
19. What is Trident API in Apache Storm?
Ans:
Trident is a high-level abstraction over Apache Storm that provides precise once-processing semantics and a more declarative way of defining topologies. Trident is a high-level abstraction API built on top of Apache Storm that simplifies stream processing and provides higher-level constructs for stateful stream processing. It offers features like exactly-once processing, state management, and complex event processing, making it easier to develop and maintain robust and scalable stream processing applications in Storm.
20. Explain the role of backpressure in Apache Storm.
Ans:
Backpressure is a mechanism in Apache Storm that controls the rate at which tuples are emitted into the topology, preventing overload and ensuring smooth processing. In Apache Storm, backpressure is a mechanism that regulates data flow through the topology to avoid overload and maintain stability. It allows Storm to control the rate at which tuples are emitted by spouts and processed by bolts based on the processing capacity of the downstream components.
21. How does Apache Storm handle stateful computations?
Ans:
- Apache Storm offers various methods for maintaining state in Bolts, including in-memory databases and distributed key-value stores. Stateful computations are managed through the Trident API, which provides a high-level abstraction for complex stateful processing.
- Additionally, stateful bolts use instance variables to track and manage state during processing. Integration with external systems allows for persistent state storage, and transactional topologies ensure data consistency and reliability throughout the processing pipeline.
22. What is the difference between Apache Storm and Apache Spark Streaming?
Ans:
Apache Storm is a real-time stream processing system that continuously processes data as it arrives, offering low-latency data handling and immediate insights. In contrast, Apache Spark Streaming operates on a micro-batch processing model, handling data in small, fixed-size batches processed at regular intervals. While Storm excels in scenarios requiring real-time analytics with minimal delay, Spark Streaming provides robust processing capabilities with fault tolerance and scalable batch processing.
23. Explain the architecture of Apache Storm.
Ans:
The architecture of Apache Storm includes several key components: Nimbus, Supervisor nodes, ZooKeeper, and worker processes. Nimbus is the central controller, managing the overall cluster and distributing tasks. Supervisor nodes are responsible for managing worker processes on individual machines. ZooKeeper facilitates coordination and configuration management among the nodes. Worker processes execute the core components of Storm, namely Spouts and Bolts, which handle data processing and streaming.
24. What are the different types of Bolts in Apache Storm?
Ans:
- Elemental Bolts: These are the simplest type of bolts and are used for primary processing tasks.
- Windowed Bolts: These bolts operate on tuples within a time window, allowing for operations like windowed aggregations or computations.
- Tick Bolts: Tick bolts emit tuples at regular intervals, which can be used for time-based operations or to trigger specific actions periodically.
- Stateful Bolts: Stateful bolts maintain state across tuples, allowing for operations that require stateful processing
25. Explain Basic Bolts in Apache Storm.
Ans:
Elemental Bolts are the simplest type of Bolts in Apache Storm. They process incoming tuples individually and emit new tuples as output. In Apache Storm, BasicBolts are the simplest bolts for processing tuples. They implement the IBasicBolt interface, which requires implementing a single method: void execute(Tuple input, BasicOutputCollector collector). This method defines the processing logic for incoming tuples and emits new tuples using the collector.
26. Explain Rich Bolts in Apache Storm.
Ans:
Rich Bolts are similar to Basic Bolts but provide additional features such as access to configuration and external resources. Rich Bolts can efficiently manage resources such as files, database connections, and external services. They offer greater flexibility and control over the processing logic by allowing developers to initialize resources during bolt startup and release them during shutdown. This makes them suitable for tasks requiring more complex state management, external interactions, or custom configuration.
27. Explain Windowed Bolts in Apache Storm.
Ans:
- Windowed Bolts in Apache Storm process tuples within a fixed time window or based on other criteria. Windowed Bolts typically operate on data streams grouped into windows based on time or other characteristics.
- They allow developers to define how data is partitioned into windows and specify the processing logic for each window. This enables tasks such as time-based aggregations, windowed joins, and computations.
28. What is the role of the tuple tree in Apache Storm?
Ans:
- The tuple tree in Apache Storm represents the data flow through the topology. It consists of tuples emitted by Spouts and processed by Bolts. In Apache Storm, the tuple tree represents the data flow through the system.
- It’s a data structure that encapsulates the tuples and their relationships as they move through the processing topology. Each tuple in the tree carries data, and the tree structure helps organize and route the tuples efficiently through the topology for processing.
29. How does Apache Storm handle data serialization?
Ans:
Apache Storm uses serialization mechanisms such as Kryo or Java serialization to serialize data between Spouts and Bolts. It converts data into easily transmitted and reconstructed formats. It supports various serialization formats such as JSON, Thrift, and Protocol Buffers. Storm provides built-in serializers for common data types, and users can also implement custom serializers if needed.
30. Explain the role of serialization buffers in Apache Storm.
Ans:
Serialization buffers in Apache Storm buffer serialized tuples before they are sent over the network, reducing the overhead of serialization and network communication. In Apache Storm, serialization buffers are crucial in efficiently serializing and deserializing data as it moves through the system. These buffers hold the serialized data temporarily during transmission between different components of the Storm topology, such as spouts and bolts.
31. What is the role of message brokers in Apache Storm?
Ans:
Message brokers such as Apache Kafka or RabbitMQ are used to ingest data into Apache Storm from external sources and buffer data between topology components. In Apache Storm, message brokers serve as a communication layer between components, facilitating the exchange of data streams. They help distribute messages across the processing topology, ensuring efficient and reliable data flow between spouts and bolts. Popular message brokers used with Apache Storm include Apache Kafka and Apache ActiveMQ.
32. How does Apache Storm handle backpressure from message brokers?
Ans:
- Apache Storm can handle backpressure from message brokers by controlling the rate at which tuples are consumed by the message broker using mechanisms such as Kafka spout throttling. It also employs various strategies such as tuple acknowledgment, parallelism tuning, and dynamic scaling.
- Storm can throttle or buffer incoming tuples when backpressure occurs, adjust processing rates dynamically, and scale resources such as worker nodes to balance the workload and prevent overload.
33. Explain the concept of tuple anchoring in Apache Storm.
Ans:
- Tuple anchoring is a mechanism in Apache Storm that allows Bolts to anchor incoming tuples to ensure that they are processed in the correct order and that downstream Bolts receive them only after they have been processed.
- In Apache Storm, tuple anchoring refers to associating tuples with specific input tuples, ensuring that processing guarantees are maintained throughout the topology.
- When a tuple is emitted from a spout or a bolt, it can be anchored to one or more input tuples. This anchoring ensures that if the tuple fails during processing, the associated input tuples are also replayed to maintain consistency and correctness in data processing.
34. What is the role of metrics in Apache Storm?
Ans:
Metrics in Apache Storm are used to monitor the performance and health of the cluster, including metrics such as throughput, latency, and resource utilization. Metrics in Apache Storm play a crucial role in monitoring and optimizing the performance of the topology. They provide insights into various aspects of the system, including throughput, latency, resource utilization, and error rates. By collecting and analyzing metrics, users can identify bottlenecks, tune configurations, and troubleshoot issues to improve the overall efficiency and reliability of the Storm cluster.
35. How can Apache Storm clusters be monitored?
Ans:
Apache Storm clusters can be monitored using various tools to ensure optimal performance and reliability. The Storm UI provides a dashboard for real-time visualization of cluster metrics and topology statuses. JMX (Java Management Extensions) allows for detailed JVM performance and resource usage monitoring. Additionally, third-party monitoring solutions offer advanced analytics and alerting features. Custom monitoring scripts can be developed for tailored monitoring needs, enhancing visibility and control over cluster operations.
36. Explain the role of the Apache Storm UI.
Ans:
- The Apache Storm UI provides a web-based interface for monitoring the health and performance of Apache Storm clusters, including information about topologies, workers, and metrics.
- The Apache Storm UI provides a web-based interface for monitoring and managing Storm clusters. It displays real-time information about topologies, worker stats, component metrics, and logs.
- Users can use it to monitor the health and performance of their Storm clusters, troubleshoot issues, and optimize resource utilization.
37. What is the significance of the “Storm. yaml” configuration file in Apache Storm?
Ans:
- The “storm.yaml” file serves as Apache Storm’s primary configuration file, detailing essential settings for the cluster’s operation. It specifies the Nimbus host, which acts as the cluster’s master node, and lists the ZooKeeper servers that coordinate communication between cluster nodes.
- Additionally, this file includes other crucial configurations that affect the entire cluster. Both Nimbus and Supervisor nodes rely on the information in “storm.yaml” to properly configure and perform their designated roles within the cluster. Proper setup of this file is vital for ensuring the smooth functioning and management of the Storm cluster.
38. How does Apache Storm handle failures in the processing pipeline?
Ans:
Apache Storm handles failures through tuple acknowledgments and retries. When a tuple fails to be processed by a Bolt, it can be replayed based on the configured retry policy. Additionally, Apache Storm ensures that tuples are processed in a reliable and fault-tolerant manner by tracking their processing status and retrying failed tuples when necessary.
39. What is the role of the Apache Storm Transactional API?
Ans:
The Apache Storm Transactional API enables the handling of data streams with transactional guarantees, ensuring reliable processing. By defining transactional topologies, developers can achieve “exactly-once” processing semantics, ensuring that each data tuple is processed precisely once without duplication. This is crucial for applications requiring high reliability and accuracy in stream processing. The API provides mechanisms to manage state and checkpoints, allowing for robust fault tolerance and recovery.
40. What is the role of ZooKeeper in Apache Storm?
Ans:
ZooKeeper is used for coordination and synchronization in Apache Storm. Nimbus uses it for leader election and by Supervisor nodes for coordination.ZooKeeper in Apache Storm is a distributed coordination service for maintaining configuration information, providing distributed synchronization, and facilitating group services. Storm uses ZooKeeper for various tasks, including leader election, distributed locks, and maintaining cluster state information.
41. What are the benefits of using Trident over the traditional Apache Storm API?
Ans:
- Using Trident offers several benefits over the traditional Apache Storm API.
- Simplified development
- Exactly once processing
- State management
- Windowed computations

Get JOB Apache Storm Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
42. How does Apache Storm ensure data locality and minimize network traffic?
Ans:
Apache Storm enhances data locality by scheduling tasks on Supervisor nodes that already hold the required data. This approach ensures that tasks are executed close to their data sources, reducing the need for extensive data transfer across the network. By minimizing network traffic, Storm significantly boosts performance and operational efficiency. This method also helps lower latency and optimize resource utilization, leading to more responsive and scalable data processing.
43. Explain the role of the Apache Storm UI in monitoring and managing topologies.
Ans:
The Apache Storm UI provides a web-based interface for monitoring and managing topologies running in the Storm cluster. It lets users view detailed information about running topologies, including their status, throughput, latency, and resource utilization. Additionally, the UI provides tools for managing topologies, such as killing or rebalancing them as needed.
44. What does Apache Storm support the different deployment modes?
Ans:
- Apache Storm supports several deployment modes, including local, remote, and cluster modes. In local mode, Storm runs entirely within a single JVM for development and testing purposes. In remote mode, Storm runs on a cluster of machines managed by Nimbus and Supervisor nodes.
- Cluster mode is similar to remote mode but typically involves running Storm in a production environment with multiple nodes for scalability and fault tolerance.
45. How does Apache Storm handle stateful processing across failures and restarts?
Ans:
- Apache Storm offers mechanisms for managing state within Bolts, utilizing in-memory databases like Redis or distributed key-value stores such as Apache HBase. This approach allows for the persistence of state outside the immediate processing pipeline.
- By externalizing state storage, Storm guarantees that state is maintained even in the event of failures or restarts. Consequently, computations can continue seamlessly without data loss. This robust state management feature ensures reliability and continuity in distributed stream processing environments.
46. What is the role of serializers and deserializers in Apache Storm?
Ans:
Serializers and deserializers (SerDes) are crucial for converting data into a binary format for efficient network transmission and then reverting it to its original form upon receipt. In Apache Storm, SerDes facilitate handling different data formats by converting data for processing and storage. Supported formats include Kryo for high-performance serialization, JSON for human-readable text data, and Avro for compact and fast data exchange.
47. How does Apache Storm handle load balancing across tasks and nodes?
Ans:
Apache Storm uses a combination of load-aware scheduling and rebalancing mechanisms to distribute tasks evenly across Supervisor nodes and ensure optimal resource utilization. By monitoring the load on individual nodes and redistributing functions as needed, Storm maintains a balanced workload and prevents any single node from becoming overwhelmed.
48. Explain the concept of message anchoring and its importance in Apache Storm.
Ans:
- Message anchoring is a mechanism in Apache Storm that ensures tuples are processed in the correct order and prevents downstream Bolts from receiving tuples until they have been fully processed.
- By anchoring tuples to their source, Storm guarantees that processing occurs sequentially and that all tuples are processed exactly once, even in the presence of failures or retries.
49. What are the considerations for scaling Apache Storm clusters?
Ans:
- Scaling Apache Storm clusters involves adjusting the number of nodes to align with varying workload demands. When expanding a cluster, it’s crucial to account for hardware capacity, network bandwidth, and overall resource utilization to maintain peak performance and reliability.
- Proper scaling ensures that the system can handle increased data throughput efficiently. Additionally, rebalancing topologies may be required to evenly distribute tasks and optimize performance across the enlarged cluster.
50. How does Apache Storm handle message ordering and windowing in stream processing?
Ans:
Apache Storm maintains message ordering within streams by processing tuples sequentially and respecting the order in which Spouts emitted them. To implement windowing, Storm uses time-based or count-based windowing strategies to group tuples into fixed-size or time-based windows for aggregate computations, enabling tasks such as sliding window analysis or sessionization.
51. What is the role of a tuple in Apache Storm?
Ans:
In Apache Storm, a tuple is the fundamental data structure that transfers data between different topology components. It represents a data record as a list of values, where a field name identifies each value. Tuples flow through the topology from spouts to bolts, enabling data processing and transformation. They ensure data is passed efficiently and in the correct format throughout the processing pipeline. Proper handling and processing of tuples are essential for the accurate and timely execution of Storm topologies.
52. Explain the concept of stream partitioning in Apache Storm.
Ans:
- Stream partitioning in Apache Storm governs how tuples are distributed among Bolts within a topology. It supports several strategies, including shuffle, fields, global, all, direct, and custom partitioning.
- The shuffle strategy distributes tuples randomly, while fields partitioning directs tuples based on specific fields. Global partitioning sends all tuples to a single Bolt, and all partitioning sends a copy of each tuple to all Bolts.
53. How does Apache Storm handle resource allocation and scheduling in a multi-tenant environment?
Ans:
Apache Storm employs a resource-aware scheduler to effectively manage CPU, memory, and network bandwidth for various topologies within a cluster. This scheduler evaluates resource availability and task priorities, ensuring demand drives resource allocation and constraints. Storm optimizes resource distribution by considering these factors to prevent bottlenecks and maintain performance. It facilitates fair utilization across multiple topologies, enhancing overall system efficiency in multi-tenant environments.
54. What is the role of tuple trees in Apache Storm’s internal data representation?
Ans:
- Tuple trees represent the hierarchical structure of data flow within a topology. In Apache Storm, tuples are emitted by Spouts and processed by Bolts in a directed acyclic graph (DAG).
- Tuple trees track the lineage of tuples as they propagate through the topology, ensuring correct ordering and fault tolerance.
55. Explain the concept of reliable messaging in Apache Storm.
Ans:
- Reliable messaging ensures that tuples are processed exactly once and in the correct order, even in the presence of failures or retries.
- Apache Storm achieves reliable messaging through mechanisms such as tuple anchoring, tracking, and packing, guaranteeing that each tuple is processed successfully and acknowledged by downstream Bolts.
56. How does Apache Storm handle state synchronization and consistency across distributed nodes?
Ans:
Apache Storm uses distributed state management techniques to synchronize and maintain state consistency across multiple nodes in the cluster. By replicating state information and implementing consistency protocols such as distributed locking or consensus algorithms, Storm ensures that state updates are propagated reliably and consistently across the cluster.
57. What are the advantages of Apache Storm for real-time stream processing?
Ans:
- Low-latency processing: Storm can process data in near real-time, enabling fast response times for time-sensitive applications.
- Scalability: Storm’s distributed architecture allows it to scale horizontally to handle large volumes of data and high throughput.
- Fault tolerance: Storm’s fault-tolerant design ensures that data processing continues uninterrupted even in the event of node failures or network partitions.
58. What is the role of task parallelism in Apache Storm?
Ans:
Task parallelism in Apache Storm involves running multiple tasks simultaneously within a single Bolt instance. This approach enhances resource utilization by leveraging concurrency, allowing for more efficient data stream processing. By parallelizing tasks, Storm can more effectively handle high-throughput scenarios and large volumes of data. This capability is crucial for optimizing performance across distributed nodes within a Storm cluster.
59. How does Apache Storm handle data skew and hotspots in stream processing?
Ans:
- Apache Storm employs load-aware scheduling and partitioning strategies to mitigate data skew and hotspots in stream processing.
- By dynamically redistributing tasks and data partitions based on load metrics and workload characteristics, Storm ensures that processing resources are evenly balanced and hotspots are alleviated, improving overall system performance and reliability.
60. Explain the role of message timeouts and retries in ensuring data reliability in Apache Storm.
Ans:
In Apache Storm, message timeouts and retry mechanisms are crucial for managing processing failures and delays. Timeouts are configured to detect when a tuple has not been processed within a specified duration, triggering a retry if needed. Retry policies determine how often a failed tuple should be reprocessed before being considered permanently lost. This approach helps address issues with slow-processing Bolts and ensures data integrity by allowing the system to recover from transient failures.

Develop Your Skills with Apache Storm Certification Training
Weekday / Weekend BatchesSee Batch Details61. What is the role of tuple routing and grouping strategies in Apache Storm?
Ans:
Tuple routing and grouping strategies determine how tuples are routed between Bolts in the topology and how they are grouped for processing. Apache Storm supports routing and grouping strategies such as shuffle, fields, all, global, direct, and custom grouping, allowing developers to control data flow and task parallelism based on specific requirements and data characteristics.
62. Explain the role of the Apache Storm Core API and its key components.
Ans:
The Apache Storm Core API provides a low-level programming interface for building real-time stream processing applications. Its key components include Spouts for emitting data streams, Bolts for processing tuples, Topologies for defining data processing logic, and Streams for representing data flows between components. The Core API offers fine-grained control over topology configuration, task execution, and fault tolerance, making it suitable for building custom stream processing pipelines and complex data processing workflows.
63. How does Apache Storm handle tuple packing and failover recovery in distributed environments?
Ans:
- Apache Storm uses tuple packing and failover recovery mechanisms to ensure data reliability and fault tolerance in distributed environments.
- When a Bolt processes a tuple successfully, it emits an acknowledgment (ack) to signal successful processing. If a tuple fails to be processed or times out, it can be retried or replayed based on the configured retry policy.
- By tracking tuple acknowledgments and retries, Storm guarantees that data is processed exactly once and in the correct order, even in the presence of failures or node crashes.
64. Explain the role of tuple routing and partitioning strategies in Apache Storm’s parallel processing model.
Ans:
- Tuple routing and partitioning strategies determine how tuples are distributed among Bolts in the topology and how they are partitioned for parallel processing.
- Apache Storm supports routing and partitioning strategies such as shuffle, fields, all, global, direct, and custom partitioning, allowing developers to control data flow and task parallelism based on specific requirements and data characteristics.
65. What are key factors for optimizing Apache Storm performance in production?
Ans:
- Resource Allocation: Ensure adequate CPU, memory, and network resources are allocated to Storm components for handling workloads efficiently.
- Topology Optimization: Adjust configurations of spouts, bolts, and parallelism to balance the load and enhance processing efficiency.
- Data Management: Optimize data throughput and message processing reliability by fine-tuning timeout and retry settings.
66. Explain the role of Apache Storm’s task scheduler in optimizing resource utilization and task allocation.
Ans:
Apache Storm’s task scheduler allocates CPU, memory, and network bandwidth resources to different tasks running on the cluster. By considering factors such as task priorities, resource availability, and workload characteristics, the task scheduler optimizes resource utilization and task allocation to maximize throughput and minimize latency. The scheduler dynamically adjusts task assignments.
67. What is the role of the Apache Storm Multilang protocol?
Ans:
The Apache Storm Multilang protocol allows developers to write components (Sprouts or Bolts) in languages other than Java, such as Python, Ruby, or Node.js. It enables communication between the JVM-based Storm framework and external processes written in different programming languages, allowing for greater flexibility and interoperability in building Storm topologies.
68. How does Apache Storm handle stateful stream processing?
Ans:
- Apache Storm provides mechanisms for managing state within Bolts to support stateful stream processing.
- Bolts can store state in memory, external databases, or distributed key-value stores such as Redis or Apache Cassandra.
- By maintaining state across tuple processing, Storm enables tasks to retain information and perform computations that depend on historical data or context.
69. Explain the role of tuple anchoring in Apache Storm’s reliability model.
Ans:
Tuple anchoring is a mechanism in Apache Storm that ensures tuple processing and reliability by anchoring tuples to their source Spouts. By anchoring tuples, Storm guarantees that tuples are processed in the correct order and that downstream Bolts receive tuples only after the topology has fully processed them. This ensures data reliability and consistency, even during failures or retries.
70. What is the role of the Apache Storm UI extension in monitoring and managing topologies?
Ans:
- The Apache Storm UI extension provides additional monitoring and management capabilities for Apache Storm clusters. It enhances the default Storm UI by adding real-time metrics visualization, topology debugging tools, and advanced monitoring dashboards.
- The UI extension enables users to gain deeper insights into cluster performance, identify bottlenecks, and troubleshoot issues more effectively, improving overall cluster management and operational efficiency.
71. Explain the concept of backpressure and its impact on stream processing systems like Apache Storm.
Ans:
Backpressure is how a stream processing system like Apache Storm regulates data flow through the processing pipeline to prevent overload and resource exhaustion. When a downstream component (e.g., Bolt) cannot keep up with the incoming data rate, it signals backpressure to upstream components (e.g., Spouts) to reduce the data rate. Backpressure allows the system to maintain stability and prevent performance degradation by throttling data flow and balancing processing throughput across components.
72. How does Apache Storm guarantee message processing in distributed environments?
Ans:
Apache Storm ensures message processing guarantees (e.g., at least once, at least once, exactly once) through mechanisms such as tuple anchoring, tracking, and acknowledgments. By anchoring tuples to their source Spouts and tracking their processing status through the topology, Storm can guarantee message processing semantics and ensure data reliability and consistency, even in distributed environments with failures or retries.
73. Explain the role of message timeouts in Apache Storm’s reliability model.
Ans:
Message timeouts are used in Apache Storm to detect and handle processing delays or failures. When a tuple fails to be processed within a specified time threshold, it is considered timed out, and the system can take appropriate action, such as retrying the tuple, logging an error, or performing custom error handling logic. Message timeouts help ensure data reliability and prevent processing bottlenecks or hangs in the topology.
74. What is the role of serializers and deserializers in Apache Storm’s data processing pipeline?
Ans:
- Serializers and deserializers (SerDes) are used in Apache Storm to convert data between its internal binary format and external data representations (e.g., JSON, Avro).
- Serializers encode data into a binary format for transmission over the network, while deserializers decode binary data back into its original form for processing by Bolts.
- Storm enables interoperability with external data sources and systems by supporting various serialization formats and codecs, facilitating seamless data integration and processing.
75. How does Apache Storm handle resource contention and task conflicts?
Ans:
- Apache Storm uses a resource-aware scheduler and load-aware scheduling algorithms to manage resource contention and task scheduling conflicts in distributed environments.
- By monitoring resource utilization, task priorities, and workload characteristics, Storm dynamically adjusts task assignments, redistributes tasks across nodes, and resolves scheduling conflicts to optimize resource utilization, maintain system stability, and ensure fair allocation of resources across components.
76. Explain the role of message brokers such as Apache Kafka in Apache Storm’s data ingestion process.
Ans:
Message brokers like Apache Kafka are used in Apache Storm to ingest data streams from external sources and buffer data between components of the processing pipeline. Kafka acts as a distributed pub/sub messaging system, allowing Spouts to consume data from Kafka topics and emit tuples into the topology for Bolts to process. By decoupling data ingestion from processing and providing fault-tolerance and scalability features, Kafka enhances the reliability and scalability of the overall data processing system.
77. What is the role of ZooKeeper in Apache Storm’s cluster coordination and management?
Ans:
- ZooKeeper is used in Apache Storm for cluster coordination, configuration management, and distributed synchronization. It is a centralized repository for storing cluster metadata, configuration settings, and leader election information.
- Nimbus and Supervisor nodes use ZooKeeper for coordination and communication, enabling tasks such as leader election, distributed locking, and failover handling in a distributed and fault-tolerant manner.
78. Explain the concept of exactly-once processing semantics in Apache Storm.
Ans:
Apache Storm’s exactly-once processing semantics guarantee that each tuple is processed exactly once and in the correct order, even in the presence of failures or retries. Storm achieves exactly-once processing by anchoring tuples, tracking their processing status, and using transactional mechanisms to ensure atomicity and idempotence in tuple processing. This guarantees data reliability and consistency, making Storm suitable for mission-critical applications with stringent data integrity requirements.
79. How does Apache Storm handle dynamic topology changes and rebalancing in distributed environments?
Ans:
- Apache Storm supports dynamic topology changes and rebalancing through dynamic scaling, rolling upgrades, and topology rebalancing.
- When topology changes occur (e.g., adding or removing components, updating configuration settings), Storm dynamically adjusts task assignments, redistributes tasks across nodes, and rebalances resource allocation to maintain system stability and ensure uninterrupted processing.
80. How does Apache Storm ensure that message processing is guaranteed?
Ans:
Apache Storm ensures message processing guarantees through tuple anchoring, tracking acknowledgments, and implementing retry mechanisms. It also uses features like packing, guaranteed message processing, and configurable reliability settings to ensure message processing guarantees. It uses a concept called “tuple tree” to trace the lineage of every tuple, ensuring that every tuple is processed at least once.
81. What are the different types of grouping strategies in Apache Storm?
Ans:
- Shuffle Grouping: Randomly distributes tuples across bolts to balance the load evenly.
- Fields Grouping: Routes tuples according to specific field values, maintaining grouping for related data.
- All Grouping: Delivers each tuple to every instance of the target bolt, ideal for broadcasting.
- Global Grouping: Sends all tuples to one instance of the target bolt, ensuring sequential processing.
82. Explain the role of Apache Storm’s transactional topologies.
Ans:
- Apache Storm’s transactional topologies guarantee exact once-processing semantics by using transactions to ensure atomicity and idempotence in tuple processing.
- They provide exact-once processing semantics, ensuring that each tuple is processed exactly once, even during failures.
- They achieve this by leveraging features such as tuple tracking, anchor tuples, and commit/acknowledge mechanisms.
83. How does Apache Storm handle data serialization and deserialization?
Ans:
Apache Storm supports serialization formats such as Kryo, JSON, and Avro for converting data between its internal binary format and external representations. Apache Storm allows users to define their own serialization and deserialization logic for data processing. Typically, this is done using third-party libraries such as Apache Avro, Google Protocol Buffers, or Apache Thrift. Users can implement custom serializers and deserializers tailored to their specific data formats and requirements.
84. What is the significance of backpressure in Apache Storm?
Ans:
- Backpressure in Apache Storm regulates data flow to prevent overload and resource exhaustion by throttling data emission based on downstream processing capacity.
- It is crucial to ensure the system can handle data streams efficiently without overwhelming downstream components. It regulates data flow between different processing stages, preventing bottlenecks and resource exhaustion.
- By applying backpressure, Storm allows components to communicate their processing capacity to upstream components, enabling dynamic adjustment of data rates and maintaining system stability.
85. Explain the purpose of message timeouts in Apache Storm.
Ans:
Message timeouts in Apache Storm detect and handle processing delays or failures by triggering retries or error-handling logic when tuples exceed a specified processing time threshold. They also ensure reliable message processing by setting a time limit for how long a tuple is allowed to be in the processing pipeline. If a tuple exceeds its defined timeout without being successfully processed, Storm considers it failed and triggers appropriate error handling mechanisms such as tuple replay or failure notification.
86. What is the role of ZooKeeper in Apache Storm’s cluster coordination?
Ans:
ZooKeeper is used for cluster coordination, leader election, and distributed synchronization in Apache Storm, ensuring consistency and fault tolerance in cluster management.ZooKeeper plays a crucial role in Apache Storm’s cluster coordination by managing the distributed state of the Storm cluster. It helps in leader election, synchronization, and configuration management, ensuring fault tolerance and reliability in the distributed environment.
87. How does Apache Storm handle dynamic topology changes?
Ans:
Apache Storm dynamically adjusts task assignments and rebalances resources to accommodate topology changes such as component additions, updates, or removals, ensuring uninterrupted processing. Apache Storm handles dynamic topology changes through its rebalancing mechanism. When a topology change occurs, such as adding or removing bolts or spouts, Storm dynamically rebalances the workload across the cluster to ensure an even distribution of processing tasks.
88. What are the benefits of using Apache Storm Trident API?
Ans:
- Fault tolerance: Trident provides robust fault tolerance mechanisms for stream processing.
- Exactly-once processing: It ensures that each event is processed exactly once, even in the face of failures.
- High throughput: It offers high throughput for processing large volumes of streaming data.
- Ease of use: Trident simplifies complex stream processing tasks with its high-level API.
89. Explain the role of serializers and deserializers in Apache Storm.
Ans:
Serializers and deserializers in Apache Storm convert data between its internal binary format and external representations, enabling interoperability with external systems and data sources. They are crucial in converting data between its internal representation and external formats. Serializers encode data from Storm’s internal format into a format transmitted over the network or stored in a database.
90. How does Apache Storm handle fault tolerance?
Ans:
- Reliable messaging: Once processed, messages are asked (acknowledged), ensuring they’re not lost if a component fails.
- Task reassignment: Failed tasks are reassigned to other workers.
- Worker heartbeat mechanism: Detects when workers are unresponsive and reallocate tasks.
- Topology redeployment: Entire topologies can be redeployed in case of failure.
91. How do message brokers like Apache Kafka impact Apache Storm’s data ingestion?
Ans:
Message brokers like Apache Kafka ingest data streams from external sources, buffering and decoupling data ingestion from processing in Apache Storm, enhancing reliability and scalability in stream processing pipelines. Message brokers like Apache Kafka play a crucial role in Apache Storm’s data ingestion process by acting as a buffer between data producers and consumers.
92. What is the purpose of tuple packing in Apache Storm? –
Ans:
Tuple packing signals the successful processing of tuples within the topology, ensuring data reliability and consistency by acknowledging tuple processing status. Tuple packing, or acknowledgment in Apache Storm, ensures data reliability and fault tolerance within the processing topology. When a tuple (a unit of data) is emitted by a spout or processed by a bolt in a Storm topology, the tuple is considered “in flight” until all subsequent bolts in the topology successfully process it.
93. How does Apache Storm handle resource allocation and scheduling?
Ans:
Apache Storm uses a resource-aware scheduler to allocate CPU, memory, and network resources to tasks based on workload characteristics and resource availability. Apache Storm handles resource allocation and scheduling through its resource manager, who manages the assignment of computational resources (e.g., CPU, memory) to different components of the Storm topology, such as spouts and bolts.
94. Explain the concept of message anchoring in Apache Storm.
Ans:
- Message anchoring ensures tuple processing order and reliability by anchoring tuples to their source Spouts, preventing downstream Bolts from receiving tuples until they have been fully processed.
- In Apache Storm, message anchoring refers to associating a tuple (a unit of data) with a particular message or event it represents. When a spout emits a tuple, it can optionally anchor it to the original message or event from which it was derived.
95. What are the advantages of using Apache Storm for real-time analytics?
Ans:
- Low Latency: Storm processes data in real-time, providing near-instantaneous analytics results.
- Fault Tolerance: It ensures data processing reliability even in the event of node failures.
- Scalability: Storm scales horizontally, handling increasing data volumes effortlessly.
- Ease of Use: Its simple programming model makes it accessible for developers.
- Integration: Seamlessly integrates with other big data tools like Hadoop, Kafka, etc.
96. Explain the role of Nimbus and Supervisor nodes in an Apache Storm cluster.
- Nimbus node: Coordinates and manages the cluster, including distributing code, assigning tasks to Supervisor nodes, and monitoring overall performance.
- Supervisor node: Executes tasks assigned by the Nimbus node, manages worker processes, and reports to Nimbus about their status.




