
Last updated on 03rd Jul 2020| 6078
These hadoop Interview Questions have been designed specially to get you acquainted with the nature of questions you may encounter during your interview for the subject of Hadoop.during your interview,normally questions start with some basic concept of the subject and later they continue based on further discussion and what you answer.we are going to cover top 100 Hadoop Interview questions along with their detailed answers. We will be covering Hadoop scenario based interview questions, Hadoop interview questions for freshers as well as Hadoop interview questions and answers for experienced.
1. What is Big Data?
Ans:
Big Data refers to large, complex datasets that traditional data processing methods struggle to manage, process, and analyze due to their volume, velocity, and variety.
2. Define Hadoop and its components.
Ans:
Hadoop is an open-source framework for storing, processing, and analyzing Big Data across distributed clusters. Its components include Hadoop Distributed File System (HDFS), MapReduce, and YARN.
3. What is HDFS?
Ans:
HDFS is the Hadoop Distributed File System, providing distributed storage for large datasets across clusters of commodity hardware. It ensures fault tolerance and scalability by replicating data blocks across multiple nodes.
4. How does MapReduce work?
Ans:
MapReduce is a programming model for parallel processing of large datasets in Hadoop. It operates in two phases: the Map phase, where data is processed and transformed in parallel, and the Reduce phase, where intermediate results are aggregated and combined.
5. Explain Hadoop’s fault tolerance mechanism.
Ans:
Hadoop ensures fault tolerance primarily through data replication in HDFS. Data is divided into blocks, which are replicated across multiple DataNodes. If a DataNode or block becomes unavailable, Hadoop can retrieve the data from other replicas.
6. Differentiate between Hadoop 1.x and Hadoop 2.x.
Ans:
Hadoop 1.x uses the MapReduce framework for both processing and resource management, while Hadoop 2.x introduces YARN (Yet Another Resource Negotiator) for improved resource management, enabling multiple processing models beyond MapReduce.
7. What are NameNode and DataNode in HDFS?
Ans:
NameNode is the master node in HDFS that manages metadata and coordinates file access. DataNode is a worker node responsible for storing and managing data blocks, as well as performing read and write operations.
8. Describe the role of ResourceManager in YARN.
Ans:
ResourceManager in YARN is responsible for managing resources across the Hadoop cluster. It allocates resources to various applications, tracks resource utilization, and schedules tasks to run on available cluster resources, ensuring efficient resource management and allocation.
9. What is a Secondary NameNode?
Ans:
The Secondary NameNode in Hadoop periodically merges the edits log with the fsimage file to prevent it from growing too large. It assists the NameNode in maintaining metadata consistency and provides a backup mechanism, but it does not act as a standby NameNode.
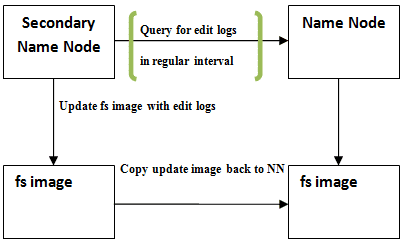
10. How does Hadoop ensure data locality?
Ans:
Hadoop ensures data locality by scheduling tasks on nodes where data resides. This minimizes data transfer across the network by bringing computation to the data, improving performance and efficiency.
11. Explain Hadoop streaming.
Ans:
Hadoop streaming is a utility that allows users to create and run MapReduce jobs with any executable or script as the mapper and reducer. It enables developers to use programming languages like Python, Perl, and Ruby for MapReduce tasks.
12. What is Apache Hive used for?
Ans:
Apache Hive is a data warehouse infrastructure built on top of Hadoop. It provides a SQL-like query language called HiveQL to query and analyze data stored in Hadoop’s HDFS or other compatible file systems. Hive is commonly used for data warehousing, data summarization, ad-hoc querying, and analysis.
13. Describe Apache Pig’s architecture.
Ans:
Apache Pig simplifies MapReduce tasks via its high-level scripting language, Pig Latin. It consists of a compiler translating Pig Latin scripts into MapReduce jobs, a runtime environment for execution, and built-in operators for data manipulation.
14. What is HBase and how does it differ from HDFS?
Ans:
HBase is a distributed NoSQL database built on Hadoop, offering real-time access to structured data. Unlike HDFS, optimized for large-scale storage and batch processing, HBase provides random, real-time access, along with features like strong consistency and row-level transactions.
15. Explain Apache ZooKeeper’s role in Hadoop.
Ans:
Apache ZooKeeper serves as a centralized service for maintaining configuration information, naming, and providing distributed synchronization in Hadoop. It ensures consistency and reliability in a distributed environment, managing and coordinating distributed applications.
16. What is Apache Spark and its advantages over MapReduce?
Ans:
Apache Spark, an open-source distributed computing system, offers faster execution than MapReduce by performing most operations in memory. It optimizes task execution through a Directed Acyclic Graph (DAG) engine, supports various APIs, and provides a unified platform for batch, streaming, machine learning, and graph processing tasks.
17. How does Apache Sqoop help in Hadoop?
Ans:
Apache Sqoop streamlines data transfer between Hadoop and relational databases, facilitating import/export tasks and simplifying data integration processes.
18. Describe data partitioning in Hadoop.
Ans:
Data partitioning in Hadoop involves dividing datasets into smaller partitions based on specific criteria, optimizing data processing and improving performance.
19. How does Hadoop handle data security?
Ans:
Hadoop ensures data security through authentication, authorization, encryption, and auditing mechanisms, safeguarding data confidentiality and integrity across the platform.
20. What is speculative execution in Hadoop?
Ans:
Speculative execution in Hadoop involves re-executing tasks that are taking longer than expected on different nodes, ensuring timely completion and preventing job slowdowns due to stragglers.
21. How does Hadoop ensure scalability?
Ans:
Hadoop ensures scalability by distributing data and processing across a cluster of commodity hardware, allowing seamless addition of nodes to handle increasing data volumes and computational requirements.
22. Compare Hadoop with traditional relational databases.
Ans:
Hadoop is designed for distributed storage and processing of large-scale, unstructured data, while traditional relational databases excel in structured data management. Hadoop’s scalability and fault tolerance make it suitable for Big Data, while relational databases are typically used for transactional and structured data.
23. Explain the shuffle phase in MapReduce.
Ans:
The shuffle phase in MapReduce is the process of redistributing and sorting intermediate key-value pairs produced by map tasks before passing them to reduce tasks. It involves data transfer between nodes, optimizing data locality for efficient processing.
24. What is input split in Hadoop?
Ans:
Input split in Hadoop is a chunk of data from a larger dataset that is processed independently by a single map task. Input splits are determined by the underlying file system and serve as the unit of work for parallel execution in the MapReduce framework.
25. How does Hadoop handle unstructured data?
Ans:
Hadoop handles unstructured data by storing it in its distributed file system (HDFS) without requiring predefined schema. MapReduce and other processing frameworks can then analyze and extract insights from this data using custom algorithms.
26. Describe Hadoop performance optimization best practices.
Ans:
Hadoop performance optimization involves techniques like data partitioning, tuning hardware configurations, optimizing data serialization, caching, and using compression. Additionally, optimizing job scheduling, memory management, and reducing network overhead contribute to improved performance.
27. How does Hadoop handle data skewness?
Ans:
Hadoop addresses data skewness, where certain keys or partitions hold significantly more data than others, through techniques like data repartitioning, combiners, and custom partitioning strategies. These approaches redistribute data more evenly across tasks, preventing performance bottlenecks.
28. Explain different Hadoop deployment modes.
Ans:
Hadoop supports different deployment modes, including standalone mode (ideal for learning and development), pseudo-distributed mode (single-node cluster), and fully-distributed mode (production-grade cluster spanning multiple nodes). Each mode offers varying levels of scalability, fault tolerance, and resource utilization.
29. What are Apache Kafka’s use cases in Hadoop?
Ans:
Apache Kafka serves critical roles in Hadoop, facilitating real-time data ingestion, log aggregation, and event streaming. It acts as a distributed messaging system, seamlessly integrating diverse data sources with Hadoop’s processing capabilities. Kafka’s scalability and fault tolerance make it ideal for building robust data pipelines within the Hadoop ecosystem.
30. Compare Apache Storm with Apache Hadoop.
Ans:
Apache Storm is a real-time stream processing framework focused on low-latency processing of continuous data streams, whereas Apache Hadoop is a distributed batch processing framework optimized for processing large-scale datasets in a batch-oriented manner. Storm excels in processing real-time data with minimal latency, while Hadoop is preferred for processing massive datasets in scheduled batch jobs.

31. Describe Apache Flink’s architecture.
Ans:
Apache Flink employs a distributed stream processing engine with components like data sources, operators, and sinks. It utilizes a Directed Acyclic Graph (DAG) for execution planning and offers fault tolerance, high throughput, and low-latency processing. Supporting both batch and stream processing, Flink enables complex event-driven applications within a single framework.
32. What is Apache Mahout’s purpose in Hadoop?
Ans:
Apache Mahout serves as a scalable machine learning library on Hadoop, enabling the development of distributed machine learning applications. It offers implementations of popular algorithms like clustering, classification, and collaborative filtering, leveraging Hadoop’s distributed computing capabilities for processing large-scale datasets, and empowering predictive analytics and data-driven applications.
34. How does Hadoop handle data compression?
Ans:
Hadoop employs various compression codecs like Gzip, Snappy, or LZO to compress data before storage in HDFS. This reduces storage requirements and speeds up data transfer across the cluster, enhancing overall performance. Decompression occurs transparently during data processing.
35. Explain speculative execution in Hadoop.
Ans:
Speculative execution in Hadoop involves re-executing tasks that are taking longer than expected on different nodes, ensuring timely completion by redundant execution. It prevents job slowdowns caused by straggler tasks and improves overall job completion time.
36. Compare Hadoop with Spark SQL.
Ans:
Hadoop is a distributed batch processing framework, while Spark SQL is a component of Apache Spark, offering a SQL interface for data querying and processing. Spark SQL provides faster data processing than Hadoop’s MapReduce due to in-memory computation and optimized query execution.
37. How does Hadoop support batch processing?
Ans:
Hadoop supports batch processing through its MapReduce framework, which divides large datasets into smaller chunks processed in parallel across a distributed cluster. MapReduce executes batch jobs by processing data in a series of map and reduce tasks, offering fault tolerance and scalability for large-scale data processing.
38. Describe Apache Drill’s architecture.
Ans:
Apache Drill’s architecture is based on a distributed execution engine that processes queries across various data sources. It includes components like the Drillbit, which executes queries locally, and the Drill client, which submits queries and receives results. Drill’s schema-free design enables it to query diverse data sources, including Hadoop Distributed File System (HDFS), NoSQL databases, and cloud storage.
39. What is the significance of YARN’s ResourceManager and NodeManager?
Ans:
YARN’s ResourceManager is the master daemon responsible for managing resource allocation and scheduling in a Hadoop cluster. It coordinates job execution across multiple NodeManagers, which are responsible for managing resources on individual cluster nodes. Together, they ensure efficient resource utilization and job execution in a distributed environment.
40. How does Hadoop ensure data reliability?
Ans:
Hadoop ensures data reliability through replication and fault tolerance mechanisms. Data stored in Hadoop Distributed File System (HDFS) is replicated across multiple nodes to prevent data loss due to node failures. Additionally, Hadoop’s framework, such as MapReduce, provides fault tolerance by rerunning failed tasks on different nodes.
41. Explain block replication in HDFS.
Ans:
Block replication in HDFS involves duplicating data blocks across multiple DataNodes in a Hadoop cluster. By default, each data block is replicated three times for fault tolerance. This ensures that even if one or more DataNodes fail, the data remains accessible, maintaining data reliability and availability in the Hadoop ecosystem.
42. What are the benefits of using Hadoop in a cloud environment?
Ans:
Hadoop’s speculative execution addresses slow-running tasks by launching duplicate copies, ensuring timely completion.
43. Describe Apache Oozie’s architecture.
Ans:
Apache Cassandra in Hadoop is employed for real-time data processing, log analysis, and high-volume data storage.
44. How does Hadoop handle schema evolution?
Ans:
Hadoop handles schema evolution by supporting various file formats like Avro and Parquet, which allow for schema evolution without data migration. Additionally, tools like Hive and Impala provide schema-on-read capabilities, enabling flexibility in querying evolving data schemas.
45. Compare Hadoop with traditional data warehouses.
Ans:
Hadoop is a distributed processing framework designed for storing and processing large volumes of structured and unstructured data across commodity hardware. In contrast, traditional data warehouses are centralized, relational database systems optimized for structured data processing, offering strong consistency, transactional support, and predefined schemas. Hadoop provides scalability, cost-effectiveness, and flexibility for processing diverse data types, while traditional data warehouses excel in transactional processing, complex querying, and strict data consistency.
46. What is a data lake?
Ans:
A data lake is an centralized repository that stores structured, semi-structured, and unstructured data at scale. It allows organizations to store raw data in its native format, enabling various analytics, processing, and exploration tasks without the need for upfront schema definition.
47. Explain the concept of job chaining in hadoop.
Ans:
Job chaining in Hadoop refers to the process of executing multiple MapReduce jobs sequentially, where the output of one job serves as the input to the next. It enables complex data processing workflows and dependencies, allowing users to orchestrate and coordinate the execution of multiple jobs in a coherent manner.
48. Describe the architecture of Apache Beam.
Ans:
Apache Beam’s architecture is based on a unified programming model for batch and stream processing. It consists of SDKs in multiple programming languages (Java, Python, etc.), a set of APIs for defining data processing pipelines, and runners that execute these pipelines on various distributed processing frameworks like Apache Spark, Apache Flink, or Google Cloud Dataflow.
49. What is the purpose of HCatalog in Hadoop?
Ans:
HCatalog simplifies metadata management in Hadoop by providing a centralized repository for metadata about data stored in HDFS. It ensures interoperability between Hadoop ecosystem tools like Hive, Pig, and MapReduce.
50. How does Hadoop handle large-scale data processing?
Ans:
Hadoop distributes data and computation across a cluster, utilizing HDFS for storage and frameworks like MapReduce or Spark for parallel processing. This enables efficient processing of massive datasets by dividing them into smaller chunks and processing them in parallel across multiple nodes.
51. What are the key features of Apache NiFi?
Ans:
Apache NiFi offers data flow management capabilities, including data routing, transformation, and mediation. It provides real-time and batch processing support, visual data flow design, data provenance, security features, and extensibility through custom processors.

Build Your Big data Hadoop Skills with Hadoop Training By Real Time Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
52. Explain the concept of record-level transformations in Hadoop.
Ans:
Record-level transformations involve modifying individual records within datasets during processing. This includes operations such as filtering, sorting, aggregating, or transforming individual records based on specified criteria. Record-level transformations are fundamental in data processing tasks performed using Hadoop’s MapReduce paradigm or other processing frameworks like Apache Spark or Apache Flink.
53.How does Hadoop support near real-time data processing?
Ans:
Hadoop supports near real-time data processing through frameworks like Apache Spark and Apache Flink, offering low-latency stream processing capabilities. These frameworks enable processing of data streams in near real-time, allowing for quick analysis and response to incoming data.
54. Describe the architecture of Apache Kylin.
Ans:
Apache Kylin’s architecture revolves around a pre-calculated cube model, offering OLAP (Online Analytical Processing) capabilities on large-scale datasets stored in Hadoop. It consists of metadata storage, query engine, and storage engine components. Kylin leverages distributed computing and storage to provide high-performance, scalable, and interactive analytics capabilities.
55.What is the role of Apache Phoenix in Hadoop?
Ans:
Apache Phoenix serves as a relational database layer on top of HBase in Hadoop, enabling SQL query capabilities for Hadoop’s NoSQL database. It allows users to interact with HBase using standard SQL queries, providing a familiar interface for data exploration, querying, and analysis.
56. Explain how Hadoop integrates with machine learning algorithms.
Ans:
Hadoop integrates with machine learning algorithms through frameworks like Apache Mahout, Apache Spark MLlib, and TensorFlow on Hadoop. These frameworks provide libraries and APIs for building, training, and deploying machine learning models on large-scale datasets stored in Hadoop. Leveraging distributed computing and parallel processing capabilities, they enable efficient execution of machine learning algorithms across Hadoop clusters for tasks such as classification, regression, clustering, and recommendation.
57. What are the key advantages of using Hadoop for big data processing?
Ans:
Scalabilityn : Hadoop efficiently handles large data volumes by distributing computation across clusters.Cost-effectiveness : It uses commodity hardware, reducing storage and processing costs.Fault tolerance : Hadoop ensures data redundancy and fault tolerance, minimizing the risk of data loss.Flexibility : It supports diverse data types and formats, enabling versatile data processing tasks.
58. Explain the differences between HDFS and traditional file systems.
Ans:
| Aspect | HDFS | Traditional File Systems | |
| Architecture |
Distributed across a cluster of nodes |
Typically single-node. | |
| Fault Tolerance | Achieved through data replication | Relies on backup systems or RAID configurations | |
| Scalability | Highly scalable to petabytes/exabytes | Limited scalability. |
59. What are the key advantages of using Hadoop for big data processing?
Ans:
Scalability : Hadoop efficiently handles large data volumes by distributing computation across clusters.
Cost-effectiveness : It uses commodity hardware, reducing storage and processing costs.
Fault tolerance : Hadoop ensures data redundancy and fault tolerance, minimizing the risk of data loss.
Flexibility : It supports diverse data types and formats, enabling versatile data processing tasks.
60. Explain the differences between HDFS and traditional file systems.
Ans:
- HDFS is designed for distributed storage and processing across clusters, unlike traditional file systems for single-server environments.
- HDFS provides fault tolerance through data replication and checksumming, while traditional file systems rely on RAID or backup solutions.
- HDFS optimizes for large files and sequential access, whereas traditional file systems focus on random access and file locking mechanisms.
61. Explain the process of job scheduling and resource management in Hadoop.
Ans:
- Hadoop’s resource management is typically handled by YARN (Yet Another Resource Negotiator).
- YARN manages resources by allocating containers to tasks across the cluster based on resource requirements.
- Job scheduling involves submitting MapReduce or other job requests to the ResourceManager, which assigns resources and schedules tasks on available nodes.
62. Describe the use cases of Hadoop in real-world applications.
Ans:
Hadoop is used in various industries for data processing, analytics, and insights generation.
In finance, Hadoop is employed for fraud detection, risk analysis, and customer segmentation.
In healthcare, it aids in genomic analysis, personalized medicine, and patient data management.
E-commerce platforms use Hadoop for recommendation systems, customer behavior analysis, and inventory management.
63. How does Hadoop address security concerns in distributed environments?
Ans:
- Hadoop provides several security features to protect data in distributed environments.
- Kerberos authentication ensures secure access control by authenticating users and services within the Hadoop ecosystem.
- Access control lists (ACLs) and file permissions restrict unauthorized access to data stored in HDFS.
64. Discuss the role of YARN in Hadoop’s resource management.
Ans:
- YARN is Hadoop’s resource management framework responsible for allocating and managing resources in a distributed environment.
- It decouples resource management from job execution, enabling multiple data processing frameworks to run on the same cluster.
- YARN consists of ResourceManager, which manages cluster resources, and NodeManager, which oversees resources on individual nodes.
- YARN’s resource scheduler efficiently allocates resources to applications based on their resource requirements and priorities, ensuring optimal resource utilization and fair resource sharing among competing applications.
65. What is the role of ZooKeeper in Hadoop’s ecosystem?
Ans:
ZooKeeper manages configurations, synchronization, and naming in Hadoop clusters. It ensures coordination among distributed processes and maintains cluster state consistency. ZooKeeper also facilitates leader election, fault detection, and recovery in Hadoop’s distributed environment.
66. Explain the differences between batch processing and real-time processing in Hadoop.
Ans:
Batch processing involves processing data in scheduled batches or jobs for offline analysis. Real-time processing, on the other hand, analyzes data as it arrives, enabling immediate insights and responses to streaming data. While batch processing is suitable for historical analysis, real-time processing is ideal for scenarios requiring timely insights and actions.
67. How does Hadoop handle data locality optimization during processing?
Ans:
Hadoop optimizes data locality by scheduling tasks to run on nodes where data is stored. It prioritizes processing data locally to minimize network overhead. This strategy ensures efficient data processing by maximizing the use of local resources and reducing data transfer across the network.
68. Describe the significance of fault tolerance mechanisms like speculative execution in Hadoop.
Ans:
Fault tolerance mechanisms like speculative execution play a crucial role in Hadoop’s reliability. Speculative execution involves running multiple copies of the same task in parallel and accepting the result from the first task to complete. This approach mitigates the impact of slow or failed tasks by ensuring that the job completes within a reasonable time frame. It enhances the overall resilience of Hadoop clusters, enabling them to handle node failures and performance bottlenecks effectively.
69. Discuss the impact of data skewness on Hadoop’s performance and how it can be mitigated.
Ans:
Data skewness can lead to uneven distribution of processing tasks, causing certain nodes to handle disproportionately large amounts of data, which can degrade performance. To mitigate this, techniques like data partitioning, combiners, and custom partitioners can be used. Additionally, advanced algorithms for task scheduling and data replication can help balance the workload across the cluster.
70. Explain the concept of data partitioning and sharding in Hadoop.
Ans:
Data partitioning involves dividing datasets into smaller, manageable partitions based on certain criteria, such as keys or ranges, to distribute them across nodes in a Hadoop cluster. Sharding is a similar concept used in distributed databases, where data is horizontally partitioned across multiple nodes. Both techniques improve parallelism and scalability by distributing data processing tasks across the cluster.
71. What are the key considerations for optimizing Hadoop clusters for performance?
Ans:
- Hardware optimization to ensure sufficient resources and balanced configurations.
- Software tuning by adjusting Hadoop configuration parameters for efficient resource utilization.
- Data locality optimization to minimize network traffic and improve processing speed.
- Monitoring and performance tuning to identify bottlenecks and optimize cluster performance iteratively.
72. Describe the process of Hadoop cluster deployment and configuration.
Ans:
- Planning the hardware infrastructure and software requirements based on workload and data size.
- Installing and configuring Hadoop components, including NameNode, DataNode, ResourceManager, and NodeManager, on cluster nodes.
- Fine-tuning Hadoop configuration settings to optimize performance and resource utilization.
- Integrating with other systems and tools as needed for data ingestion, processing, and analysis.
73. How does Hadoop handle concurrency and resource contention among multiple jobs?
Ans:
Hadoop uses resource management frameworks like YARN (Yet Another Resource Negotiator) to handle concurrency and resource contention. YARN efficiently allocates resources to different jobs based on their requirements, ensuring fair sharing of resources among multiple concurrent jobs.
74. Differentiate Hadoop from traditional relational databases in terms of data storage and processing.
Ans:
- Hadoop stores data in a distributed file system (HDFS) across a cluster of commodity hardware, offering scalability and fault tolerance. Traditional databases use structured storage models like tables and indexes on a single server.
- Hadoop processes data in parallel using distributed computing, suitable for unstructured and semi-structured data. Traditional databases use SQL for data processing, optimized for structured data with ACID compliance.
75. Explain the role of Hadoop ecosystem components like Hive, Pig, and HBase in data processing.
Ans:
Hive : SQL-like interface for querying and analyzing data in Hadoop.
Pig : High-level scripting language for data transformations and ETL workflows.
HBase : NoSQL database for real-time random read and write access to large datasets.
76. Describe the benefits and limitations of using Hadoop for ETL (Extract, Transform, Load) processes.
Ans:
Benefits : Scalability, fault tolerance, cost-effectiveness for handling massive datasets.Limitations : Longer latencies, complexity requiring specialized skills, challenges with real-time ETL operations.
77. How does Hadoop support data governance and metadata management?
Ans:
- Hadoop facilitates data governance through metadata management, access control, and data lineage tracking.
- Tools like Apache Atlas enable metadata management, allowing users to define and enforce data governance policies.
- Hadoop’s distributed file system (HDFS) maintains metadata about files and directories, supporting data lineage tracking and auditing.
- It offers mechanisms for managing metadata, access control, and ensuring data lineage, crucial for enforcing data governance policies.
78. Explain the use cases and advantages of using Hadoop in cloud environments.
Ans:
- Data serialization formats like Avro and Parquet optimize data storage and processing in Hadoop.
- Avro provides a compact binary format and schema evolution support, making it suitable for data exchange and storage.
- Parquet offers efficient columnar storage, compression, and predicate pushdown for analytics workloads in Hadoop.
- Both formats improve data processing performance and enable interoperability between different Hadoop ecosystem tools
79. Explain the Hadoop ecosystem and its components
Ans:
Hadoop ecosystem comprises various tools and frameworks for big data processing. Key components include HDFS for storage, MapReduce for processing, YARN for resource management, and others like HBase, Hive, and Spark for additional functionalities.
80. What are the key features of Hadoop MapReduce?
Ans:
Hadoop MapReduce allows parallel processing of large datasets across distributed clusters, fault tolerance through data replication, scalability to handle massive volumes of data, and flexibility to process various types of data formats.
81. Describe the differences between MapReduce and Spark.
Ans:
While both are big data processing frameworks, Spark offers in-memory processing, making it faster than MapReduce which relies on disk storage. Spark supports a wider range of processing models like batch, interactive, streaming, and machine learning, while MapReduce primarily focuses on batch processing.
82. Explain the concept of Hadoop Streaming.
Ans:
Hadoop Streaming is a utility that enables users to create and run MapReduce jobs with any executable or script as the mapper and reducer functions. It facilitates integration with programming languages like Python, Perl, or Ruby, allowing developers to leverage their preferred language for MapReduce tasks.
84. How does data replication work in HDFS?
Ans:
HDFS replicates data blocks across multiple DataNodes in the cluster to ensure fault tolerance and high availability. The default replication factor is usually three, meaning each block is replicated thrice, with copies stored on different nodes.
85. Explain the concept of data locality in Hadoop.
Ans:
Data locality refers to the principle of moving computation close to where the data resides. In Hadoop, this means scheduling tasks on nodes where the data blocks are stored, minimizing data transfer over the network and improving performance.
86. What is the purpose of the MapReduce shuffle phase?
Ans:
The shuffle phase in MapReduce is responsible for transferring the output of the map tasks to the appropriate reducer nodes. It involves sorting and shuffling the intermediate key-value pairs based on keys, ensuring that all values associated with the same key are sent to the same reducer.
87. What are the different ways to access Hadoop data?
Ans:
Hadoop data can be accessed through various methods including :
- Hadoop Command Line Interface (CLI) tools like Hadoop fs and Hadoop fsck.
- Programming APIs such as Java MapReduce API, Hadoop Streaming API, and Hadoop File System (FS) API.
- Higher-level abstractions like Apache Hive for SQL querying, Apache Pig for data processing, and Apache Spark for in-memory data processing.
- Visualization tools and BI platforms integrated with Hadoop, such as Apache Zeppelin, Tableau, or Apache Superset.
88. What is the significance of the Reducer in MapReduce?
Ans:
Reducers aggregate and process output from Mappers in MapReduce, reducing data volume and generating final output. They play a crucial role in optimizing storage and network usage.
89. How does Hadoop handle failures in the cluster?
Ans:
Hadoop ensures fault tolerance through data replication, task redundancy, heartbeat mechanism, and recovery mechanisms in resource managers. These features help maintain system reliability and job completion.
90. Explain the use case of HBase in the Hadoop ecosystem.
Ans:
HBase, a NoSQL database on Hadoop, facilitates real-time read/write access to large datasets. It’s suitable for low-latency applications, real-time analytics, and time-series data storage in IoT or monitoring systems.




