
Last updated on 20th May 2024| 6092
Users may handle structured and semi-structured data using SQL queries thanks to Spark SQL, a component of Apache Spark. In addition to providing seamless SQL integration with intricate data transformations, it delivers sophisticated optimizations. Through effective data processing and smooth interaction with several data sources, Spark SQL enhances the efficiency and scalability of big data applications.
1. Which are Spark SQL’s key features?
Ans:
A potent Apache Spark component made specifically for processing structured data is called Spark SQL. In addition to offering two APIs the DataFrame API and the Dataset API it enables SQL queries. This improves performance and scalability by enabling users to carry out a variety of data manipulation tasks on structured data in a distributed computing environment with efficiency.
2. How does Spark SQL differ from Spark Core?
Ans:
| Aspect | Spark SQL | Spark Core |
|---|---|---|
| Data Handling | Structured and semi-structured data | General-purpose distributed data processing |
| API | Higher-level API with DataFrames and Datasets | Lower-level RDD API |
| Optimization | Includes Catalyst optimizer for query optimization | Manual optimizations and transformations |
| Integration with SQL | Supports direct execution of SQL queries | No direct support for SQL queries |
| Ease of Use | Simplifies operations with higher-level abstractions | Provides more control and flexibility, but with increased complexity |
3. Outline the essential elements of Spark SQL.
Ans:
- The SQL Engine allows users to execute SQL queries against Spark data.
- The DataFrame API offers a domain-specific language (DSL) for working with structured data.
- Catalyst Optimizer improves query tactics for higher effectiveness.
- Unified data access provides access to several data sources, such as HDFS, Hive, JSON, JDBC, Parquet, and more.
4. Elaborate on the framework of Spark SQL.
Ans:
- Data Sources: A variety of data sources, including databases and structured file formats like JSON and Parquet, can be read and written using Spark SQL.
- Logical Plan: Spark SQL creates a logical plan based on the structure of a query that is submitted, with a focus on semantics.
- Catalyst Optimizer: This component uses several principles to increase speed and generates both an optimized logical and physical plan.
- Physical Plan: This plan outlines the data processing that will occur as the technique for executing the query.
- Execution Engine: The Spark cluster’s execution engine implements the physical plan while managing resource allocation and job scheduling.
5. Enumerate the advantages of employing Spark SQL.
Ans:
- Interaction with pre-existing Spark components and applications is made easier using Spark SQL.
- The Catalyst Optimizer improves query execution performance by optimizing both the logical and physical query plans.
- Parquet and ORC, JSON, XML, and other structured and semi-structured data sources can be worked with by Spark SQL on a large variety of external databases.
- It efficiently manages both structured and semi-structured data, providing flexibility in data processing.
- By fusing SQL queries with Spark’s machine learning, streaming, and graph processing features, Spark SQL enables a unified approach to data processing.
6. How does Spark SQL facilitate SQL queries?
Ans:
Working with data is made easier by Spark SQL’s robust SQL engine, which translates SQL queries into Spark actions. SQL queries provide a simple way for users to alter structured data that is stored in Spark. Spark SQL ensures excellent performance and scalability in data processing by optimizing these queries and effectively executing them throughout the whole Spark cluster.
7. Define Catalyst optimizer in Spark SQL.
Ans:
A powerful framework for query optimization, Spark’s Catalyst Optimizer converts logical plans into physically optimal plans for execution. Implementing several optimizations, like join reordering for better performance, constant folding for expression simplification, and predicate pushdown for minimizing data searched by moving filters closer to the data source, it improves query efficiency.
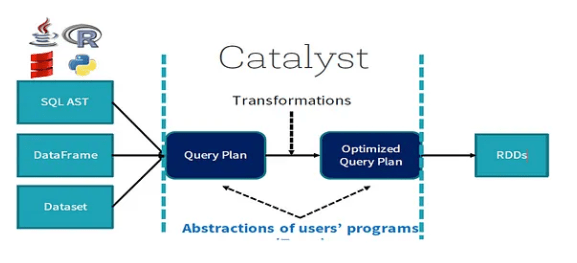
8. Explain the mechanics of Catalyst optimizer in Spark SQL.
Ans:
- Parsing: Generates an abstract syntax tree (AST) from SQL queries.
- Analyzing: Checks type resolves table and column references, and verifies query semantics.
- Logical Optimization: Fits the logical plan with high-level optimizations such as constant folding and predicate pushdown.
- Physical Planning: Several physical execution plans are created, and the most effective one is selected based on cost projections.
9. What purpose does Catalyst Optimizer serve in query optimization?
Ans:
To enhance query performance, the Catalyst Optimizer transforms logical plans into physically optimized plans. Utilizing Spark’s distributed computing capabilities, cutting down on pointless computations, and choosing the best execution approach, improves efficiency. As a result, queries will execute more quickly and effectively throughout the Spark cluster, improving performance optimization and resource usage in the process.
10. Which data sources does Spark SQL support?
Ans:
- Structured data sources: Include Avro, CSV, JSON, Hive, Parquet, ORC.
- Sources of semi-structured data: CSV, Avro, and JSON.
- Streaming Sources: Flume, Kinesis, Kafka.
- External Databases: PostgreSQL, Oracle, MySQL, and other databases that are JDBC compatible.
11. Describe the methods for creating DataFrames in Spark SQL.
Ans:
There are several ways to generate DataFrames with Spark SQL. One popular option is to use the `toDF()` method, which allows column names to be specified to convert an existing RDD. Another way to generate DataFrames directly is to use the `spark.read.csv`, `spark.read.json`, and `Spark. Read. Parquet} methods to read files in CSV, JSON, and Parquet formats, respectively.
12. Differentiate between DataFrame and Dataset in Spark SQL.
Ans:
DataFrames and Datasets are two types of distributed data collections in Spark SQL. DataFrames resemble named-column tables in relational databases but are untyped and lack compile-time type safety. Datasets offer strongly typed and compile-time type safety, enabling improved performance and facilitates better error detection during the development process.
13. Detail the approaches available for executing SQL queries in Spark SQL.
Ans:
With Spark SQL, SQL queries may be executed in a variety of ways. One approach is to write SQL queries as strings and use SparkSession’s SQL function to execute them directly. Users can also take advantage of the Data Frame API, which offers versatility in data processing by enabling queries against DataFrames using operations like join, filter, and select.
14. How is schema inference managed in Spark SQL?
Ans:
- When reading from file formats such as JSON, Parquet, ORC, and Avro, the framework can automatically ascertain the data structure thanks to schema inference in Spark SQL.
- Data loading processes are made simpler by this method, which infers the schema from an analysis of the input data.
- To ascertain the schema, for example, Spark analyses the JSON file when `spark.read.json(“path/to/jsonfile”)` is used.
15. Elucidate the concept of schema-on-read in Spark SQL.
Ans:
A Spark SQL notion known as “schema-on-read” refers to applying the schema to the data as it is being read rather than as it is being written. This method offers flexibility when managing semi-structured data formats like JSON and Parquet. Spark can dynamically adjust to various data architectures since the schema can be either defined or inferred during the reading process.
16. What role does the DataFrame API play in Spark SQL?
Ans:
The Data Frame API, which provides a high-level abstraction for manipulating structured data, is a major component of Spark SQL. It makes complicated data transformations easier by doing operations like filtering, joining, and aggregating. This method improves performance and productivity, making it simpler to handle big datasets effectively and efficiently and meet a range of data analysis requirements.
17. How to generate a data frame from an RDD in Spark SQL?
Ans:
Generate a DataFrame from an RDD in Spark SQL using the toDF method, which allows to specify column names. This approach combines the flexibility of RDDs with the optimizations provided by DataFrames, enabling to leverage the powerful DataFrame API.
- import org.apache.spark.sql.SparkSession
- val spark = SparkSession.builder.appName(“Example”).getOrCreate()
- // Create an RDD val rdd = spark.sparkContext.parallelize(Seq((1, “Alice”), (2, “Bob”)))
- // Convert RDD to DataFrame with specified column names import spark.implicits._ val df = rdd.toDF(“id”, “name”)
- // Show the DataFrame df.show()
This method provides a seamless way to transition from RDDs to DataFrames, taking advantage of the additional functionality and performance optimizations offered by DataFrames in Spark.
18. Compare and contrast DataFrame and RDD in Spark SQL.
Ans:
Within Spark SQL, DataFrames and Resilient Distributed Datasets (RDDs) serve different purposes and offer unique benefits. DataFrames, with their schema-based representation of structured data, provide a high-level API that allows for easier manipulation and analysis of data compared to RDDs. They offer optimizations using Spark’s Catalyst optimizer, which leverages the schema information to optimize query execution plans.
19. How to create a data frame from a CSV file in Spark SQL?
Ans:
Creating a DataFrame from a CSV file using the spark.read.csv method in Spark SQL. This method allows to specify options such as whether to treat the first row as headers and to infer the schema.
- // Import necessary libraries import org.apache.spark.sql.SparkSession
- // Create Spark Session val spark = SparkSession.builder() .appName(“CSV to DataFrame Example”) .getOrCreate()
- // Create DataFrame from CSV file val df = spark.read .option(“header”, “true”) // Use first row as headers .option(“inferSchema”, “true”) // Automatically infer data types .csv(“path/to/csvfile.csv”)
- // Show the DataFrame df.show()
This method simplifies data processing by automatically handling column names and data types, allowing to work with the DataFrame directly.
20. What steps are involved in reading data from a JDBC source in Spark SQL?
Ans:
- Reading Data from a JDBC Source in Spark SQL There are multiple processes involved in reading data from a JDBC source in Spark SQL.
- The JDBC URL and connection properties, including the database credentials, must first be specified.
- As an example,
- val jdbcUrl = “jdbc:postgresql://hostname:port/dbname”
- val connectionProperties = new Properties()
- connectionProperties.put(“user”, “username”)
- connectionProperties.put(“password”, “password”)
- Next, utilize the JDBC format and the `read` function as follows:
- val df = spark.read.jdbc(jdbcUrl, “tablename”, connectionProperties)
21. Explain the procedure for writing data to a JDBC sink in Spark SQL.
Ans:
- In Spark SQL, first prepare DataFrame with the required data, then specify the JDBC sink.
- Configure the URL, table name, and database credentials for the JDBC connection.
- Use the `write.jdbc` method with the appropriate parameters, including the JDBC URL, table name, and connection properties.
- The `mode` argument controls how pre-existing data is handled, with options like “overwrite”, “append”, or “error”.
- This ensures that the DataFrame is written to the specified JDBC table effectively.
22. How does Spark SQL handle null values?
Ans:
Handling Null Values in Spark SQL allows for flexible operations to handle nulls by handling them according to normal SQL principles. Filters for null values include `isNull} and `isNotNull} functions. `df. filter(df(“column”).isNotNull)}, eliminates null values from a DataFrame. The {na} functions offer ways to discard, fill, or replace null values. For example, `df.na.fill(“default_value”, Seq(“column”))} substitutes null values in a given column.
23. Define partitioning in the context of Spark SQL.
Ans:
In Spark SQL, partitioning is the process of breaking a dataset based on particular column values into smaller, easier-to-manage sections called partitions. This technique improves effective data retrieval and parallel processing. For each distinct value in the partition column, the `partitionBy` method can be used to arrange the data into a subdirectory when writing it to a file.
24. Describe partition pruning and its significance in Spark SQL.
Ans:
- Using query filters, partition pruning is an optimization method that enables Spark SQL to skip reading unnecessary partitions.
- Spark only scans the required partitions when a query contains filters on partitioned columns, which minimizes I/O and enhances query performance.
- Spark reads just the pertinent partitions, for instance, when a query seeks data for a particular period range, and the dataset is divided into dates.
25. Elaborate on the concept of bucketing in Spark SQL.
Ans:
Using Spark SQL Bucketing, data is split into a predefined number of buckets by applying a hash function to one or more selected columns. This method greatly enhances query performance by making sure that all data with the same bucket key is kept together in the same bucket. Optimizing join operations and aggregations can lead to faster query performance, which is very beneficial for this particular business.
26. How to perform bucketing in Spark SQL?
Ans:
Bucketing in Spark SQL is a technique used to optimize performance by distributing data across multiple files based on a hash of a specified column. This can improve the efficiency of joins and aggregations.
- import org.apache.spark.sql.SparkSession
- // Create Spark Session val spark = SparkSession.builder() .appName(“Bucketing Example”) .enableHiveSupport() // Enable Hive support for bucketing .getOrCreate()
- // Create a DataFrame (example) val df = spark.createDataFrame(Seq( (1, “Alice”), (2, “Bob”), (3, “Cathy”), (4, “David”) )).toDF(“id”, “name”)
- // Perform bucketing df.write .bucketBy(10, “id”) // Specify number of buckets and the column to bucket by .sortBy(“id”) // Optional: Sort within each bucket .saveAsTable(“bucketed_table”)
This example demonstrates how to implement bucketing effectively in Spark SQL, allowing for improved query performance.
27. Discuss caching in Spark SQL and its utility.
Ans:
In Spark SQL, caching is the process of keeping intermediate results in memory to expedite other operations on the same data. This technique saves the requirement for recalculating or again retrieving data from disk, making it helpful for iterative algorithms or repeated queries on the same dataset. Spark greatly improves speed for tasks that reuse the same data by rapidly accessing the stored data.
28. What methods are available for caching DataFrames in Spark SQL?
Ans:
In Spark SQL, can cache DataFrames using the Cache () and Persist () methods.
- Persist () Method: This method allows to specify different storage levels for caching.
- Cache () Method: This method is a shorthand for Persist () with the default storage level of MEMORY_AND_DISK. It is used to store the DataFrame in memory, and if memory is insufficient, it spills to disk.
- import org.apache.spark.sql.SparkSession
- import org.apache.spark.storage.StorageLevel
- // Create Spark Session val spark = SparkSession.builder() .appName(“Caching Example”) .getOrCreate()
- // Create a DataFrame (example) val df = spark.read.option(“header”, “true”).csv(“path/to/csvfile.csv”)
- // Cache the DataFrame using cache() df.cache()
- // Persist the DataFrame with a specified storage level df.persist(StorageLevel.MEMORY_ONLY)
This explanation provides a clear overview of the methods available for caching DataFrames in Spark SQL, along with an example.
29. Enumerate the different join types supported by Spark SQL.
Ans:
- An inner join returns rows with matching keys in both tables.
- All rows from the left table and any matching rows from the right table are returned via a left (outer) join.
- All rows from the right table and any matching rows from the left table are returned by the right (outer) join.
- Full (Outer) Join: Returns rows in the event that either table contains a match.
- Cross Join: Provides the two tables’ Cartesian product.
- Rows from the left table that match those in the right table are returned via a semi-join.
- Rows from the left table that do not have a match in the right table are returned by an anti-join.
30. Provide a distinction between left join and inner join in Spark SQL.
Ans:
- Inner Join: Returns only the rows with matching keys in both DataFrames.
- Usage: Commonly used when needed only the intersecting data from both datasets.
- Result: Excludes rows without matches in either DataFrame.
- Left Join: Returns all rows from the left DataFrame, and matched rows from the right DataFrame. Unmatched rows from the right DataFrame will contain nulls.
- Usage: Useful when need to keep all records from the left DataFrame regardless of matches.
- Result: Includes all rows from the left DataFrame, with nulls in place where the right DataFrame has no match.
31. How to execute a self-join in Spark SQL?
Ans:
In Spark SQL, a self-join occurs when a DataFrame is joined with itself. This is useful for comparing rows within the same DataFrame, such as identifying pairs of rows that share certain column values.
- import org.apache.spark.sql.SparkSession
- import org.apache.spark.sql.functions._
- // Create Spark Session val spark = SparkSession.builder() .appName(“Self Join Example”) .getOrCreate()
- // Create a DataFrame (example) val df = spark.createDataFrame(Seq( (1, “Alice”, 28), (2, “Bob”, 30), (3, “Cathy”, 28), (4, “David”, 35) )).toDF(“id”, “name”, “age”)
- // Perform self-join val selfJoinedDf = df.as(“a”) .join(df.as(“b”), $”a.age” === $”b.age” && $”a.id” < $"b.id") // Alias for distinguishing instances .select($"a.id", $"a.name", $"b.id", $"b.name", $"a.age")
- // Show the results selfJoinedDf.show()
This example demonstrates how to effectively execute a self-join in Spark SQL, enabling to compare and analyze data within the same DataFrame.
32. Explain the significance of broadcast joins in Spark SQL.
Ans:
Because they maximize join speed especially when one of the tables is small enough to fit into the memory of each worker node broadcast joins are important in Spark SQL. Spark avoids the expensive shuffle process by broadcasting the smaller table to every node, which significantly speeds up join operations and improves overall performance for workloads involving data processing.
33. How to perform a broadcast join in Spark SQL?
Ans:
To perform a broadcast join in Spark SQL, use the broadcast function from the org.apache.spark.sql.functions package. This function allows to efficiently join a smaller DataFrame with a larger one by broadcasting the smaller DataFrame to all worker nodes, thereby avoiding the costly shuffle operation.
- import org.apache.spark.sql.functions.broadcast
- val broadcastedDf = broadcast(smallDf)
- val joinedDf = largeDf.join(broadcastedDf, largeDf(“id”) === broadcastedDf(“id”))
- joinedDf.show()
Broadcasting `smallDf` allows an efficient join with `largeDf` as Spark distributes `smallDf` to all worker nodes, eliminating the need for a shuffle during the join process.
34. What is the role of window functions in Spark SQL?
Ans:
- The Window’s Function Functions in Spark SQL Window functions in Spark SQL are used to carry out operations within a designated window or partition on a group of rows connected to the current row.
- These functions are crucial for activities like sorting, moving averages, cumulative sums, and more.
- In contrast to normal aggregate methods, window functions apply the calculations inside the specified Window while maintaining the original number of rows in the result set.
35. How to utilize window functions in Spark SQL?
Ans:
Provide a window specification and then apply the desired window function to use window functions in Spark SQL. Scala import org. Apache. Spark.sql.expressions.
- Import org. Apache. Spark.sql.functions._ from Window
- Window.partition(“partition column”) var windowSpec = Window.orderBy using “order column”
- pdf.with column(“rank”, rank()) = val resultDf.resultDf.show() over(windowSpec)) {{{
36. Describe the importance of UDFs (User Defined Functions) in Spark SQL.
Ans:
UDFs in Spark SQL are crucial for adding new operations to Spark’s built-in functions that fit particular business logic. They give customers the ability to specify unique calculations and transformations that aren’t available right out of the box. Because of their versatility, UDFs make it possible to incorporate sophisticated operations straight into Spark SQL queries.
37. How to register UDFs in Spark SQL?
Ans:
In Spark SQL, must first declare the function and then register it using the udf function. Here’s an illustration in Scala:
- import org.apache.spark.sql.functions.udf
- val customUdf = udf((input: String) => input.toUpperCase)
- spark.udf.register(“customUdf”, customUdf)
- val resultDf = df.withColumn(“upperColumn”, customUdf(df(“columnName”)))
- var resultDf = customUdf(df(“columnName”), df.withColumn(“upperColumn”)))
- resultDf.show()
This example defines and registers customUdf, which is then applied to a DataFrame column to create a new column upperColumn containing uppercase values.
38. What purpose do accumulator variables serve in Spark SQL?
Ans:
- When a Spark job is executed, accumulator variables in Spark SQL are used to aggregate data across the nodes.
- Their primary function is to perform counting, summarizing, or gathering statistics during transformations and actions.
- Accumulators provide a way to collect metrics or debug information efficiently.
- They are particularly useful for monitoring and diagnosing the performance of Spark jobs by aggregating information from distributed tasks.
39. How to employ accumulator variables in Spark SQL?
Ans:
To use accumulator variables in Spark SQL, first need to define the accumulator and then update it within transformations. Here’s a clear example in Scala:
- val accum = spark.sparkContext.longAccumulator(“My Accumulator”)
- val rdd = spark.sparkContext.parallelize(Seq(1, 2, 3, 4, 5))
- rdd.foreach(x => accum.add(x))
- println(s”Accumulator value: ${accum.value}”)
In this example, accum is a long accumulator that adds the values from each element of the RDD. After the foreach transformation updates the accumulator, the final value is printed.
40. Outline Spark SQL’s approach to schema evolution.
Ans:
- Spark SQL supports schema evolution, enabling schema changes over time without affecting already-existing data.
- This functionality comes in handy when working with Parquet files or managing modifications to the data structure of semi-structured formats like JSON and Avro.
- By enabling the addition of new columns and the updating of existing ones, Spark controls the evolution of the schema.
- Spark can automatically detect schema changes when reading data and adjust.

Get JOB Spark SQL Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. What is the significance of checkpoints in Spark SQL?
Ans:
To guarantee fault tolerance in Spark SQL applications, checkpoints are necessary. Checkpoints help the system recover from mistakes by storing the state of a Data Frame or RDD to dependable storage, such as HDFS. Spark may reload the checkpoint data rather than recalculating it from the source, which greatly reduces recovery time and increases system reliability.
42. How to configure checkpoints in Spark SQL?
Ans:
To configure checkpoints in Spark SQL, use the setCheckpointDir method to specify a directory for storing checkpoint data. Here’s how it can:
- // Set the checkpoint directory spark.sparkContext.setCheckpointDir(“/path/to/checkpoint/dir”)
- // Create a DataFrame and apply the checkpoint val df = spark.read.json(“/path/to/json”).checkpoint()
Make sure to replace “path/to/checkpoint/dir” and “/path/to/json" with actual paths.
43. Discuss the role of shuffle operations in Spark SQL.
Ans:
For operations like join, groupBy, and aggregate, shuffle operations in Spark SQL are crucial for spreading data throughout the cluster. They guarantee correctness by processing records that have the same key together. Shuffles can, however, add overhead and affect speed, therefore it’s critical to optimize queries to reduce them. Shuffles also improve fault tolerance by enabling the rerunning of essential computations in the event of a node failure.
44. Explain how Spark SQL optimizes shuffle operations.
Ans:
Shuffle operations are optimized by Spark SQL using several cutting-edge methods, such as the creation of optimal physical plans and Tungsten’s binary processing. Spark lessens the requirement for intermediate data writes by using pipelined execution. It also improves serialization and data compression techniques, so reducing the amount of shuffle operations required and hence increasing overall speed.
45. Describe the utility of broadcast variables in Spark SQL.
Ans:
Spark SQL broadcast variables make sure that every worker node has a local copy of a read-only variable, which improves efficiency. This reduces the need for pointless data transfers, making it possible for modest lookup tables to be effectively shared between processes. Broadcast variables also lessen memory overhead on the driver node, which speeds up task execution—particularly for processes that need to access the same data frequently.
46. How to utilize broadcast variables in Spark SQL?
Ans:
To use broadcast variables, wrap a variable in sparkContext.broadcast and access it within transformations. For example:
- // Create a broadcast variable val broadcaster = spark.sparkContext.broadcast(Map(1 -> “a”, 2 -> “b”))
- // Create an RDD val rdd = spark.sparkContext.parallelize(Seq(1, 2, 3))
- // Use the broadcast variable in a transformation val result = rdd.map(x => (x, broadcaster.value.getOrElse(x, “unknown”)))
- // Collect and display the outcome result.collect()
This ensures efficient sharing of the lookup table across all worker nodes.
47. Discuss the optimization of Skew joins in Spark SQL.
Ans:
Spark SQL’s optimization of skew joins deals with problems caused by uneven data distribution, in which some nodes process much more data than others. Spark SQL can effectively balance the burden by separating skewed keys into several keys, a technique known as salting, by finding skewed data. During joins, this enhancement improves overall performance.
48. What strategies can be employed for optimizing Skew joins in Spark SQL?
Ans:
- Salting: Add a random number to skewed keys to create several unique keys that balance the load across partitions and more equitably distribute data.
- Broadcast Joins: Broadcast joins can be used with smaller tables to avoid rearranging a lot of data. Join procedures can be accelerated by sending the tiny table to every node in this way.
- Skew Join clues: To alert Spark to the existence of skewed data, use skew join clues. This aids Spark in fine-tuning its execution strategy to better manage the skewed data and enhance performance.
49. Explain the concept of adaptive query execution in Spark SQL.
Ans:
Adaptive Query Execution (AQE) in Spark SQL automatically improves query plans during runtime based on real data facts. This feature enables more accurate optimizations to be made while the query is running, including dynamically re-optimizing joins and aggregations. Consequently, AQE greatly enhances the overall performance and efficiency of queries.
50. How does adaptive query execution enhance Spark SQL’s performance?
Ans:
Adaptive Query Execution (AQE) dramatically improves performance by using real-time data analytics to change query plans. It improves join techniques, minimizes the amount of shuffle partitions, and handles skewed data effectively. These enhancements guarantee better resource usage and overall system performance by facilitating quicker and more effective query execution.
51. Describe the impact of vectorized query execution on Spark SQL’s performance.
Ans:
- Vectorized query execution significantly boosts Spark SQL’s efficiency by processing multiple rows of data simultaneously with a single CPU instruction.
- This approach reduces the number of CPU cycles required and minimizes memory overhead.
- By handling data in larger batches, vectorized execution improves throughput, leading to faster query processing and reduced query execution latency.
- This method is particularly effective for handling large datasets, making Spark SQL more performant and resource-efficient.
52. How does vectorized query execution improve Spark SQL’s performance?
Ans:
- Vectorized query execution significantly boosts Spark SQL’s efficiency by processing multiple rows of data simultaneously with a single CPU instruction.
- This approach reduces the number of CPU cycles required and minimizes memory overhead.
- By handling data in larger batches, vectorized execution improves throughput, leading to faster query processing and reduced query execution latency.
- This method is particularly effective for handling large datasets, making Spark SQL more performant and resource-efficient.
53. Discuss the role of cost-based optimization in Spark SQL.
Ans:
Cost-based optimization (CBO) in Spark SQL uses statistical data associated with the query to improve query execution plans. Through cost estimation and the selection of the most cost-effective plan among multiple execution choices, CBO guarantees improved resource use and notable improvements in query performance. As a result, processing is generally more efficient and runs more quickly.
54. Explain the workings of cost-based optimization in Spark SQL.
Ans:
Cost-Based Optimization in Spark SQL Operates begins by collecting data on table size, row count, and data distribution. Spark SQL uses this data to calculate the price of different query strategies. After optimizing joins, aggregations, and other operations based on the real data properties, the optimizer chooses the plan with the lowest estimated cost.
55. Elaborate on the importance of predicate pushdown in Spark SQL.
Ans:
Predicate pushdown greatly minimizes the amount of data that needs to be read from the storage layer, which is why Spark SQL primarily relies on it. Spark retrieves only the relevant portions of the data from the data source by pushing down filter predicates. By reducing I/O operations, this technique not only increases query speed but also boosts overall performance, resulting in more effective processing.
56. How does predicate pushdown enhance Spark SQL’s performance?
Ans:
- Predicate pushdown reduces data travel between Spark and the storage layer, significantly improving performance.
- When filters are applied directly at the data source, only the necessary data is read and processed by Spark.
- This approach minimizes I/O operations and lowers network latency because less data needs to be transferred between the storage layer and Spark.
- Consequently, query execution speeds up, as Spark can focus on processing a smaller, more relevant subset of data instead of handling the entire dataset.
57. Discuss the use of bloom filters for optimization in Spark SQL.
Ans:
An element’s likelihood of being included in a dataset can be quickly ascertained by using Bloom Filters for optimization in Spark SQL. These filters offer a fast, probabilistic way to determine whether a set exists, which can improve overall performance by drastically lowering the amount of data handled during join operations and other search processes.
58. How does Spark SQL leverage bloom filters for optimization?
Ans:
Bloom filters are used by Spark SQL and are constructed on the join keys of huge tables. By assisting in the early detection of non-matching rows during join operations, these filters enable Spark to bypass the processing of certain rows. This method greatly improves overall query performance while effectively reducing the amount of superfluous data handled.
59. Describe the significance of columnar storage in Spark SQL.
Ans:
Columnar storage arranges data according to columns rather than rows, it is essential for Spark SQL. This storage format allows for better data compression and less input/output, making it especially useful for read-intensive analytical queries. It also facilitates faster patterns of data access, which greatly improves query performance and data processing efficiency overall.
60. How does columnar storage contribute to improved query performance in Spark SQL?
Ans:
Because columnar storage minimizes input/output and enables Spark to read only the particular columns needed by a query, it improves query performance. This format enhances data compression, which reduces the need for memory and storage. Additionally, vectorized execution is a perfect fit for columnar formats, which further improves query performance and data processing efficiency.

Develop Your Skills with Spark SQL Certification Training
Weekday / Weekend BatchesSee Batch Details61. Discuss the challenges posed by data skew in Spark SQL.
Ans:
- Unequal Data Distribution: Some partitions have noticeably more data than others due to an unequal distribution of the data, which causes data skew.
- Resource depletion: Some nodes manage excessively high data volumes, which increases the risk of resource depletion and node failure.
- Extended Processing Times: As a result of the imbalance, tasks involving highly skewed partitions require a notably long time to finish.
- Greater Memory Consumption: A skew partition may result in higher memory usage, which raises the possibility of out-of-memory issues.
- Job Completion Delays: When the slowest tasks impede performance, the overall job completion may be delayed. This can result in wasteful resource use and higher expenses.
62. How to detect and address data skew in Spark SQL?
Ans:
Methods like countByKey or task metrics analysis can be used to study key distribution and detect data skew. Increasing parallelism can effectively mitigate data skew by facilitating more balanced data processing. Salting is a further technique that involves adding random values to skewed keys. Spark can dynamically modify the data distribution during runtime by employing adaptive query execution.
63. Explain the role of statistics in query optimization in Spark SQL.
Ans:
Important details regarding the distribution of data, including table size, number of rows, and distinct values in columns, are provided by statistics in Spark SQL. By using these statistics, the query optimizer may make more educated choices on the best execution strategies, which lowers computational costs and enhances query performance.
64. How does Spark SQL utilize statistics for query optimization?
Ans:
- Spark SQL estimates the cost of various query execution options using gathered statistics.
- By optimizing joins, filters, and aggregations, the optimizer selects the most effective strategy using the information provided.
- Based on the relative sizes of the tables, statistics, for instance, can assist the optimizer in choosing between broadcast joins and shuffle-based joins.
65. Discuss the importance of parallelism in Spark SQL.
Ans:
Because it controls how well the system can employ cluster resources to carry out operations in parallel, parallelism is essential to Spark SQL. Faster query processing is achieved by improved task distribution, which is made feasible by a higher level of parallelism. In the end, this results in a more effective use of CPU and memory resources across the board for the cluster, improving performance.
66. How to manage parallelism in Spark SQL?
Ans:
To maximize efficiency, handling parallelism in Spark SQL requires multiple solutions. Changing parameters such as `spark.sql.shuffle.partitions}, which regulates the number of partitions utilized for shuffle operations, is one efficient way. To maximize parallelism, repartition DataFrames or RDDs by key distributions and modify the number of executor cores as necessary, guaranteeing effective resource use across the cluster.
67. Describe the utility of query plan caching in Spark SQL.
Ans:
- With Spark SQL’s query plan caching feature, the system can save a query’s physical plan and then utilize it again for related queries or subqueries.
- There is less overhead involved in continuously optimizing and preparing similar queries, this results in faster execution times for queries that are run frequently.
- Query plan caching reduces the need for repetitive computation and processing, it can greatly increase resource efficiency by freeing up Spark to concentrate on query execution at a faster pace.
- Modification lowers data processing delay and improves overall system performance.
68. How does query plan caching improve Spark SQL’s performance?
Ans:
Query plan caching lowers the ongoing expenses related to query design and optimization, it dramatically improves Spark SQL performance. By promptly retrieving and executing the cached plan following several query executions, latency can be reduced and system throughput can be increased. As a result, Spark SQL applications operate better overall and process data more effectively.
69. Explain the concept of the cost model in Spark SQL.
Ans:
A cost model serves as a framework for the Spark SQL optimizer, which uses it to determine the computing cost of different query execution options. By taking into account variables like input/output, CPU utilization, memory usage, and network overhead, it forecasts the execution strategy that will function best. This method guarantees that Spark can choose the most effective strategy, improving query performance as a whole.
70. How does Spark SQL estimate query costs using the cost model?
Ans:
To estimate query costs using the cost model, Spark SQL examines metadata and statistics about the data as well as the operations that need to be performed. The optimizer evaluates multiple plans to efficiently run the query; it allocates costs based on expected resource consumption and execution time and selects the plan with the lowest estimated cost. During query execution, this method aids in ensuring peak performance and resource utilization.
71. Discuss the significance of broadcast hints in Spark SQL.
Ans:
- Boost Join Efficiency: When joining with larger DataFrames, they can avoid expensive shuffle operations by telling Spark to broadcast a small DataFrame instead.
- Reduce Latency: By speeding up query processing, this enhancement lowers latency overall.
- Enhance Resource Utilization: By reducing disk and network I/O, they enable more effective cluster resource management.
- Promote Scalability: Broadcast tips aid in preserving performance and scalability as datasets expand.
- Give Users Control: By using their understanding of the properties of the data, users can direct the optimizer.
72. How to apply broadcast hints to optimize queries in Spark SQL?
Ans:
To apply broadcast hints in Spark SQL, use the broadcast function from the org.apacghe.spark.sql.functions package. For example:
- import org.apache.spark.sql.functions.broadcast
- val broadcastedDf = broadcast(smallDf) val joinedDf = largeDf.join(broadcastedDf, “key”) joinedDf.show()
This case, smallDf is broadcasted to all nodes, optimizing the join with largeDf by avoiding costly shuffle operations. This enhances query performance significantly.
73. Explain the optimization of join order in Spark SQL.
Ans:
Rearranging the joins in a Spark SQL sequence to reduce intermediate data sizes and processing expenses is known as join order optimization. Spark may minimize the quantity of data shuffled across the network, reducing resource usage and execution time, by carefully choosing the sequence in which tables are connected. A well-considered join order can minimize the overhead related to managing huge volumes of intermediate data and greatly increase.
74. How does Spark SQL optimize join order?
Ans:
- Spark SQL optimizes join order through cost-based optimization (CBO).
- The optimizer assesses variables like data distribution and table size to identify the most effective join sequence.
- To minimize data movement and processing overhead, it prioritizes smaller joins first and takes into account the cardinality of intermediate results.
75. Describe the optimization technique of column pruning in Spark SQL.
Ans:
- Column trimming is an optimization method in Spark SQL that removes unnecessary columns from query operations.
- By focusing only on the required columns, Spark SQL reduces the volume of data processed and transferred across the cluster.
- This targeted approach minimizes memory usage and network I/O, significantly enhancing overall query performance and efficiency.
76. How does Spark SQL optimize column pruning?
Ans:
To find superfluous columns during the logical optimization stage, Spark SQL optimizes column trimming by examining the query plan. It makes sure that in later stages of execution, only the necessary columns are read from storage and processed. By lowering I/O and increasing resource efficiency, this decrease in data transfer speeds up query execution while simultaneously improving performance.
77. Discuss the importance of expression pushdown in Spark SQL.
Ans:
Expression pushdown in Spark SQL is significant because it processes complex expressions and filters at the source level, minimizing the amount of data transmitted from the data source to Spark. Because less data needs to be transported and processed as a result of this optimization, queries execute more quickly and efficiently, utilizing the data source’s processing capabilities.
78. How does expression pushdown contribute to improved query performance in Spark SQL?
Ans:
- Reduced Data Transfer: Less data is transferred to Spark, reducing network I/O and expediting query execution, by using filters and expressions at the data source.
- Leveraged Source Capabilities: It makes use of the processing capabilities of the data source so that intricate computations can be performed locally on the data rather than in Spark.
- Reduced Processing Overhead: Spark uses fewer resources overall while processing less data, which improves efficiency and query performance.
79. Describe the significance of dynamic partition pruning in Spark SQL.
Ans:
Spark SQL’s dynamic partition pruning is important because it automatically removes superfluous partitions during query execution, improving query performance. By reducing the quantity of data read from disk, this procedure speeds up execution by minimizing I/O operations. Dynamic partition pruning promotes faster query response times and maximizes resource utilization by effectively managing partition data, which improves performance overall.
80. How does dynamic partition pruning optimize queries in Spark SQL?
Ans:
- By excluding non-matching partitions using runtime filter information, dynamic partition pruning improves query performance.
- Spark dynamically prunes partitions based on the join keys when a join condition contains a partitioned column.
- This ensures that only pertinent partitions are read and processed, thereby decreasing I/O and increasing execution speed.
81. Explain the role of query compilation in Spark SQL.
Ans:
Query compilation is essential because it converts high-level SQL queries into efficient execution plans. To ensure that the query is run as efficiently as possible, this approach combines physical planning, optimization, and logical planning. Query compilation allows for efficient execution across distributed data systems, lower resource consumption, and improved performance through the analysis of data statistics and the application of different optimization strategies.
82. How does query compilation enhance query performance in Spark SQL?
Ans:
- Optimization of Execution Plans: It generates optimal physical execution plans by examining the logical query structure, and implementing various optimization techniques including predicate pushdown and column reduction.
- Decreased Overhead: Spark reduces the interpretation overhead during execution by assembling queries into efficient bytecode, which leads to quicker processing.
- Efficient Resource Utilization: The compilation process considers data statistics and system resources, enabling Spark to distribute resources effectively, hence boosting overall execution speed and efficiency.
83. Discuss the use of data skipping for query optimization in Spark SQL.
Ans:
Data skipping in Spark SQL enhances query speed by avoiding superfluous data searches. It uses statistics and metadata to filter out irrelevant files or partitions when selectively reading data. By exploiting column statistics, Spark can skip data blocks that fall outside query criteria, dramatically decreasing I/O operations. This leads to enhanced efficiency, faster reaction times, and better resource use, especially with huge datasets.
84. How does Spark SQL utilize data skipping for query optimization?
Ans:
- Selective File Scanning: Spark determines which data files are pertinent to the query by analyzing metadata and statistics, enabling it to read just the data that is required.
- Column Statistics: To reduce the amount of data analyzed, Spark uses column-level statistics, such as minimum and maximum values, to skip entire data blocks that don’t meet query criteria.
- Better Query Execution: By removing I/O operations and accelerating query execution, this technique improves performance and uses fewer resources overall, especially when working with huge datasets.
85. What are the limitations of Spark SQL?
Ans:
- Compared to standard databases, Spark SQL has less support for advanced SQL features, which is one of its constraints.
- Degradation of performance with very big datasets because of memory limitations.
- Difficulties in query optimization, including intricate transformations or non-SQL source procedures.
- Less support than batch processing for real-time streaming analytics.
86. How to optimize performance in Spark SQL?
Ans:
- Adjusting Spark setups to make the best use of available resources.
- Making use of cost-based optimization, data skipping, and predicate pushdown as query optimization strategies.
- Caching and checkpointing are used to minimize computation overhead.
- Expanding the cluster’s size to accommodate heavier loads.
87. Describe Spark SQL’s approach to handling complex data types.
Ans:
Query compilation is essential because it converts high-level SQL queries into efficient execution plans. To ensure that the query is run efficiently as possible, this approach combines physical planning, optimization, and logical planning. Query compilation allows for efficient execution across distributed data systems, lower resource consumption, and improved performance through the analysis of data statistics and the application.
88. Outline the best practices for deploying Spark SQL in production environments.
Ans:
- Optimizing Spark configurations for the workload and cluster resources.
- Putting indexing and data splitting techniques into practice for effective data access.
- Regularly checking and fine-tuning query performance.
- Putting security mechanisms in place, like authorization, authentication, and encryption.
- Using appropriate cluster configuration and data replication to ensure high availability and fault tolerance.
89. How does Spark SQL integrate with other Spark components?
Ans:
Spark SQL integrates readily with other Spark components, including Spark Core, Spark Streaming, Spark MLlib, and Spark GraphX. Through the creation of a single platform within the Spark ecosystem, this integration improves the overall capabilities of data analysis by facilitating smooth cooperation for a variety of activities, such as machine learning, batch and streaming data processing, graph analytics, and interactive SQL queries.
90. Discuss the security and authentication mechanisms employed by Spark SQL.
Ans:
Mechanisms for Authentication and Security Spark SQL uses Various security and authentication mechanisms to protect the privacy and integrity of data. These mechanisms include User authentication with LDAP, OAuth, and Kerberos. Authorization controls that limit access to resources and data according to the roles and privileges of users. Data encryption to prevent unwanted access while it’s in transit and at rest.




