
Last updated on 09th Nov 2021| 4817
Apache Storm is a real-time stream processing system designed for distributed data processing. It consists of spouts, bolts, and topologies, enabling scalable and fault-tolerant applications. The master node, Nimbus, manages code distribution and computation across the Storm cluster. Storm is well-suited for real-time analytics, event processing, and continuous handling of streaming data. It offers a flexible, extensible framework with components like Trident, simplifying the development of complex, stateful processing topologies. This comprehensive set of interview questions helps prepare for challenging discussions on Apache Storm.
1. What is Apache Storm?
Ans:
Apache Storm is free and open-source distributed stream processing framework composed predominantly in the Clojure. Founded by Nathan Marz and unit at BackType, project open-sourced following its acquisition by a Twitter. Storm makes it simple to dependably process unbounded streams of information, producing a real-time processing in place of what Hadoop did for the batch processing. Storm is uncomplicated, can be utilized with the several programming languages.
2. What is “spouts” and “bolts”?
Ans:
Apache Storm utilizes the custom-created “spouts” and “bolts” to describe the information origins and manipulations to provide the batch, distributed processing of streaming data.
3. Where would use Apache Storm?
Ans:
Storm is used for:
- Stream processing: Apache Storm is adopted to processing of a stream of data in the real-time and update numerous databases. The processing rate must balance that of input data.
- Distributed RPC: Apache Storm can parallelize the complicated query, enabling its computation in real-time.
- Continuous computation: Data streams are the continuously processed, and Storm presents results to customers in the real-time. This might need the processing of every message when it reaches or building it in the tiny batches over a brief period. Streaming trending themes from a Twitter into web browsers is an illustration of the continuous computation.
- Real-time analytics: Apache Storm will interpret and respond to the data as it arrives from the multiple data origins in real-time.
4. What are characteristics of Apache Storm?
Ans:
- It is the speedy and secure processing system.
- It can manage the huge volumes of data at tremendous speeds.
- It is an open-source and a component of Apache projects.
- It aids in the processing big data.
- Apache Storm is horizontally expandable and a fault-tolerant.
5. How would one split a stream in Apache Storm?
Ans:
One can use the multiple streams if one’s case requires that, which is not really splitting, but will have a lot of flexibility, and can use it for content-based routing from the bolt.
Example: Declaring a stream in the bolt
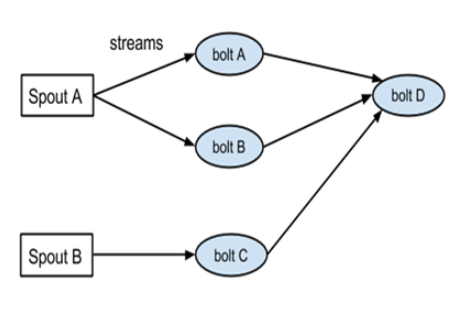
6. What is directed acyclic graph in Storm?
Ans:
Storm is the topology in the form of a directed acyclic graph (DAG) with spouts and bolts serving as a graph vertices. Edges on the graph are called streams and forward data from a one node to the next. Collectively, topology operates as the data alteration pipeline.
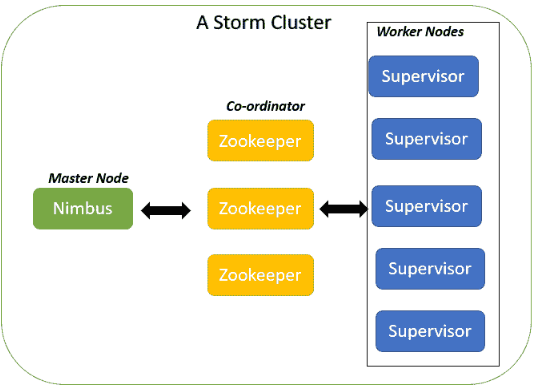
7. What is Nodes?
Ans:
The two classes of nodes are Master Node and Worker Node. The Master Node administers the daemon Nimbus which allocates jobs to devices and administers their performance. The Worker Node operates the daemon known as Supervisor, which distributes responsibilities to the other worker nodes and manages them as per requirement.8. What are Elements of Storm?
Ans:
Storm has a three crucial elements, viz., Topology, Stream, and Spout. Topology is the network composed of Stream and Spout. The Stream is a boundless pipeline of tuples, and Spout is origin of the data streams which transforms a data into the tuple of streams and forwards it to a bolts to be processed.
9. What are Storm Topologies?
Ans:
The philosophy for the real-time application is inside a Storm topology. A Storm topology is comparable to the MapReduce. One fundamental distinction is that MapReduce job ultimately concludes, whereas the topology continues endlessly , A topology is the graph of spouts and bolts combined with the stream groupings.
10. What is TopologyBuilder class?
Ans:
TopologyBuilder displays a Java API for defining a topology for Storm to administer. Topologies are the Thrift formations in the conclusion, but as the Thrift API is so repetitive, TopologyBuilder facilitates a generating topologies.
11. How do Kill topology in Storm?
Ans:
storm kill topology-name [-w wait-time-secs]
Kills topology with the name: topology-name. Storm will initially deactivate topology’s spouts for a span of the topology’s message timeout to let all messages currently processing the finish processing. Storm will then shut down the workers and clean up state. And can annul the measure of time Storm pauses between the deactivation and shutdown with the -w flag.
12. What transpires when Storm kills topology?
Ans:
Storm does not kill topology instantly. Instead, it deactivates all spouts so they don’t release any more tuples, and then Storm pauses for Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS moments before destroying all the workers. This provides topology sufficient time to finish the tuples it was processing while it got destroyed.
13. What is suggested approach for writing integration tests for Apache Storm topology in Java?
Ans:
Can utilize the LocalCluster for integration testing. Tools want to use are the FeederSpout and FixedTupleSpout. A topology where all the spouts implement the CompletableSpout interface can be run until fulfillment using the tools in Testing class. Storm tests can also decide to simulate time which implies a Storm topology will idle till call LocalCluster.advanceClusterTime. This can allow to do asserts in between the bolt emits, for example.
14. What does swap command do?
Ans:
A proposed feature is to achieve the storm swap command that interchanges the working topology with the brand-new one, assuring minimum downtime and no risk of both the topologies working on the tuples simultaneously.
15. How do monitor topologies?
Ans:
The most suitable place to monitor the topology is utilizing the Storm UI. The Storm UI gives a data about errors occurring in tasks, fine-grained statistics on the throughput, and latency performance of the every element of every operating topology.
16. How do rebalance tnumber of executors for bolt in running Apache Storm topology?
Ans:
Continually need to have larger (or equal number of) jobs than the executors. As the quantity of tasks is fixed, need to define a larger initial number than initial executors to be able to scale up number of executors throughout a runtime. And can see the number of tasks, like maximum number of executors:
#executors <= #numTasks
17. What are Streams?
Ans:
A Stream is a core concept in Storm. A stream is the boundless series of tuples that are processed and produced in the parallel in a distributed manner. Define the Streams by a schema that represents a fields in stream’s records.
18. What can tuples hold in Storm?
Ans:
By default, tuples can include the integers, longs, shorts, bytes, strings, doubles, floats, booleans, and byte arrays. And can further specify the serializers so that custom varieties can be utilized natively.
19. How do check for httpd.conf consistency and errors in it?
Ans:
check the configuration file by using:
httpd -S
The command gives the description of how Storm parsed configuration file. A careful examination of IP addresses and servers might help in uncovering configuration errors.
20. What is Kryo?
Ans:
Storm utilizes the Kryo for serialization. Kryo is the resilient and quick serialization library that provides the minute serializations.
21. What are Spouts?
Ans:
A spout is an origin of streams in the topology. Generally, spouts will scan tuples from the outside source and release them into topology. Spouts can be reliable or unreliable. A reliable spout is able to replay tuple if it was not processed by a Storm, while an unreliable spout overlooks a tuple as soon as it is emitted. Spouts can emit more than a one stream.
22. What are Bolts?
Ans:
All processing in the topologies is done in bolts. Bolts can do everything from a filtering, aggregations, functions, talking to schemas, joins, and more. Bolts can perform a simplistic stream transmutations. Doing the complicated stream transformations usually demands the multiple actions and hence added bolts.
23. What are scenarios in which want to use Apache Storm?
Ans:
Storm can be used for t following use cases:
Stream processing:
Apache Storm is used to process stream of data in a real time and update several databases. This processing takes place in a real time, and processing speed must match that of input data speed.
Continuous computation:
Apache Storm can process the data streams continuously and deliver results to clients in real time. This could require the processing each message when it arrives or creating in the small batches over the short period of time.
Real-time analytics:
Apache Storm will analyze and react to data as it comes in the from various data sources in a real time.
24. What are features of Apache Storm?
Ans:
- It is fast and reliable processing system.
- It can handle the large amounts of data at high speeds.
- It is open source and part of Apache projects.
- It helps to process a big data.
- Apache Storm is horizontally scalable, fault tolerant.
25. How is Apache Storm different from Apache Kafka?
Ans:
There is little difference between the Apache Storm and Apache Kafka.Apache Kafka is the distributed and strong messaging system that has potential to handle big data and is responsible for passing the message from one terminal to other.Apache Storm is the system for processing messages in a real-time. Data is fetched by the Apache storm from Apache Kafka and adds the required manipulations.
26. What is Real-time Analytics in Apache Storm?
Ans:
The usage of all enterprise data that is available, as per need is Real-Time Analytics. It involves the vigorous analysis and also involves reporting which is based on data that is put in a system. Less then 60 seconds or minute is taken before real-time use. Real-time analytics is also known by the other terms such as real-time data analytics and a real-time intelligence.
27. What is importance of real-time Analytics?
Ans:
The real-time analytics is important and need is growing significantly. It is observed that application provides fast solutions with the real-time analytics. It has wide range including retail sector, telecommunication, and banking sector. Many frauds are filed in a sector of banking. One of frauds that are very often heard is a fraud transactions. Such frauds are happening on the regular basis and real-time analytics helps in the detecting and identifying the frauds. It also has its application in circle of social networks such as a Twitter.
28. What is Zookeeper in Storm?
Ans:
Zookeeper is used in a storm for coordination of cluster. It’s not the duty of zookeeper to pass the messages, which makes a load on it lighter. Zookeeper clusters of single node are good and can do most tasks. But for deploying the storm clusters that are large, it might need a larger zookeeper clusters. Zookeeper should be run carefully for the reason being process will get excited if zookeeper encounters an error case.
29. What are three distinct layers of Codebase in Storm?
Ans:
- Storm’s codebase consists of the three distinct layers.
- First, a storm can run with use of any language. This is due to thrift structures. The storm is compatible to go with all languages.
- Second, all interfaces of the storm are specified as interfaces of Java. All the users have to go with the API of Java which implies that always all storm’s features are accessible through the Java.
- Third, Clojure has large implementation of the storm. Half of storm is Clojure code and other half is Java code, with the Clojure code being more expressive.
30. When Cleanup method is called in Apache Storm?
Ans:
When the bolt is going to be shut down and that the opened resources need to be cleaned, then Cleanup is called.Its not sure for the Cleanup method to be called on cluster.
31. Why SSL is not included in Apache?
Ans:
SSL is not included in the Apache due to the some significant reasons. Some governments don’t allow import, export and do not give the permission for using the encryption technology which is required by SSL data transport. If SSL would included in the Apache then it won’t available freely due to various legal matters. Some technology of SSL which is used for talking to current clients is under the patent of RSA Data Security and it does not allow usage without license.
32. Mention how storm application beneficial in financial services.
Ans:
- Securities fraud
- Order routing
- Pricing
- Compliance Violations
33. Explain how message is fully processed in Apache Storm.
Ans:By calling nextTuple procedure or method on Spout, Storm requests the tuple from the Spout. The Spout avails SpoutoutputCollector given in the open method to discharge tuple to one of its output streams. While discharging the tuple, the Spout allocates “message id” that will be used to recognize tuple later. After that, tuple gets sent to the consuming bolts, and storm takes charge of the tracking tree of messages that is produced.
34. How data is stream flow in Apache Storm?
Ans:
Storm provides the two types of components that process input stream, spouts, and bolts. Spouts process the external data to produce streams of tuples. Spouts produce the tuples and send them to bolts. Bolts process tuples from input streams and produce the some output tuples.
35. How can Apache storm used for streamlining log files?
Ans:
The spout can be configured and then by an emitting every line as the log is read, for reading a log files.
Then, the bolt should be provided with output for the analyzing.
36. Explain Server Type directive in server of Apache.
Ans:
In server of Apache, server type directive determine whether Apache should keep all things in one process for it shall spawn as the child process. In Apache 2.0, server type directive is not found because not available in it. It is however available in the Apache 1.3 for compatibility of background with Apache of version based on the UNIX.
37. Which components are used for stream flow of data?
Ans:
- Bolt
- Spout
- Tuple
38. What are key benefits of using Storm for Real Time Processing?
Ans:
- Easy to operate : Operating storm is a quiet easy.
- Real fast : It can process the 100 messages per second per node.
- Fault Tolerant : It detects fault automatically and re-starts a functional attributes.
- Reliable : It guarantees that each unit of data will executed at least once or exactly once.
- Scalable : It runs the across cluster of machine.
39. Does Apache act as Proxy server?
Ans:
Yes, It acts as a proxy also by using the mod_proxy module. This module implements the proxy, gateway or cache for Apache. It implements the proxying capability for AJP13 (Apache JServ Protocol version 1.3), FTP, CONNECT (for SSL),HTTP/0.9, HTTP/1.0, and (since Apache 1.3.23) HTTP/1.1. The module can be configured to connect to the other proxy modules for these and other protocols.
40. What is ZeroMQ?
Ans:
ZeroMQ is the library which extends standard socket interfaces with the features traditionally provided by a specialized messaging a middleware products.Storm relies on the ZeroMQ primarily for a task-to-task communication in running Storm topologies.
41. How many distinct layers are of Storm’s Codebase?
Ans:
First: Storm was designed from very beginning to be compatible with the multiple languages. Nimbus is the Thrift service and topologies are defined as Thrift structures. The usage of the Thrift allows Storm to be used from any language.
Second: All of Storm’s interfaces are specified as a Java interfaces. So even though there’s lot of Clojure in Storm’s implementation, all the usage must go through Java API. This means that each feature of Storm is always available by Java.
Third: Storm’s implementation is largely in the Clojure. Line-wise Storm is about the half Java code, half Clojure code. But Clojure is more expressive, so in reality great majority of the implementation logic is in the Clojure.
42. When do call the cleanup method?
Ans:
The cleanup method is called when the Bolt is being shutdown and should cleanup any resources that were opened. There’s no guarantee that this method will be called on a cluster: For instance, if machine the task is running on blows up, there’s no way to invoke method.
The cleanup method is intended when run topologies in local mode (where a Storm cluster is simulated in the process), and want to be able to run and kill many topologies without suffering the any resource leaks.
43. What is combinerAggregator?
Ans:
A CombinerAggregator is used to combine the set of tuples into a single field. Storm calls the init() method with every tuple, and then repeatedly calls combine()method until the partition is processed. The values are passed into the combine() method are the partial aggregations, result of combining the values returned by a calls to init().
44. What are common configurations in Apache Storm?
Ans:
There are the variety of configurations can set per topology. A list of all configurations can set can be found here. The ones prefixed with the “TOPOLOGY” can be overridden on the topology-specific basis (other ones are cluster configurations and cannot be overridden).
- Config.TOPOLOGY_WORKERS:
- Config.TOPOLOGY_ACKER_EXECUTORS:
- Config.TOPOLOGY_MAX_SPOUT_PENDING:
- Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS :
- Config.TOPOLOGY_SERIALIZATIONS :
45. Is it necessary to kill topology updating running topology?
Ans:
Yes, to update a running topology, only option currently is to kill a current topology and resubmit a new one. A planned feature is to implement the Storm swap command that swaps the running topology with the new one, ensuring a minimal downtime and no chance of both the topologies processing tuples at a same time.
46. How Storm UI can used in topology?
Ans:
Storm UI is used in the monitoring the topology. The Storm UI provides an information about errors happening in tasks and fine-grained stats on the throughput and latency performance of every component of each running topology.
47. Why does not Apache include SSL?
Ans:
SSL (Secure Socket Layer) data transport requires an encryption, and many governments have the restrictions upon the import, export, and use of encryption technology. If Apache included the SSL in the base package, its distribution would involve all the sorts of legal and bureaucratic issues, and it would no longer be freely available. Also, some of technology required to talk to the current clients using SSL is patented by RSA Data Security, who restricts its use without a license.
48. Does Apache include any sort of database integration?
Ans:
Apache is the Web (HTTP) server, not an application server. The base package does not include the any such functionality. PHP project and mod_perl project allow to work with the databases from within Apache environment.
49. While installing, why does Apache have three config files – srm.conf, access.conf and httpd.conf?
Ans:
The first two are the remnants from the NCSA times, and generally should be fine if delete the first two, and stick with httpd.conf.
- srm.conf: This is a default file for ResourceConfig directive in httpd.conf. It is processed after the httpd.conf but before access.conf.
- access.conf: This is a default file for the AccessConfig directive in the httpd.conf.It is processed after the httpd.conf and srm.conf.
- httpd.conf:The httpd.conf file is a well-commented and mostly self-explanatory.
50. How to check for httpd.conf consistency and any errors in it?
Ans:
httpd –S this command will dump out the description of how Apache parsed configuration file. Careful examination of IP addresses and server names may help uncover a configuration mistakes.

Best Apache Storm Certification Course with Advanced Concepts from Real Time Experts
Weekday / Weekend BatchesSee Batch Details51. Explain when to use field grouping in Storm.
Ans:
Field grouping in storm uses the mod hash function to decide which task to send the tuple, ensuring which task will be processed in a correct order. For that, don’t require any cache. So, there is a no time-out or limit to known field values.
The stream is partitioned by fields specified in grouping. For example, if the stream is grouped by “user-id” field, tuples with same “user-id” will always go to a same task, but tuples with the different “user-id”‘s may go to the different tasks.
52. What is mod_vhost_alias?
Ans:
This module creates the dynamically configured virtual hosts, by allowing IP address and/or the Host: header of HTTP request to be used as part of path name to determine what files to serve. This allows for the easy use of a huge number of virtual hosts with the similar configurations.
53. Is running apache as a root is security risk?
Ans:
- No. Root process opens a port 80, but never listens to it, so no user will actually enter a site with root rights.
- If kill the root process, and will see the other roots are disappear as well.
54. What is Multiviews?
Ans:
MultiViews search is enabled by a MultiViews Options. It is general name given to the Apache server’s ability to provide the language-specific document variants in response to the request. This is documented quite thoroughly in content negotiation description page.
55. Explain how can streamline log files using Apache storm.
Ans:
To read from a log files, can configure the spout and emit per line as it read the log.
The output then can be assign to the bolt for analyzing.
56. Mention how storm application can beneficial in financial services.
Ans:
Securities fraud:
Perform a real-time anomaly detection on known patterns of the activities and use learned patterns from a prior modeling and simulations.
Correlate the transaction data with the other streams (chat, email, etc.) in the cost-effective parallel processing environment.
Reduce query time from the hours to minutes on the large volumes of data.
Build the single platform for operational applications and analytics that reduces a total cost of ownership (TCO).
Order routing:
Order routing is a process by which an order goes from end user to an exchange. An order may go directly to exchange from the customer, or it may go first to the broker who then routes order to the exchange.
57. Can use Active server pages(ASP) with Apache?
Ans:
ASP: Apache ASP provides an Active Server Pages port to a Apache Web Server with Perl scripting only, and enables the developing of dynamic web applications with the session management and embedded Perl code. There are also more powerful extensions, including the XML taglibs, XSLT rendering, and new events not originally part of ASP AP.
58. What is Toplogy_Message_Timeout_secs in Apache storm?
Ans:
It is a maximum amount of time allotted to topology to fully process a message released by the spout. If the message in not acknowledged in a given time frame, Apache Storm will fail message on the spout.
59. Differentiate between a tuple and a stream in Apache Storm.
Ans:
| Feature | Tuple | Stream | |
| Definition | A tuple is a single data structure in Storm | A stream is a sequence of tuples in a Storm topology | |
| Nature of Data | Represents a single piece of data | Represents a continuous flow of data | |
| Size of Data | Contains a specific set of values | Contains an ordered series of tuples | |
| Processing Unit | Handled by bolts in the Storm topology | Conceptually represents a channel for data movement | |
| Grouping and Processing | Tuples are grouped based on fields or keys | Streams provide a way to organize and process tuples based on grouping | |
| Use Cases | Tuples are the fundamental data unit for processing within bolts | Streams provide a higher-level abstraction for organizing and managing data flow |
60. In which folder Java Application stored in Apache?
Ans:
Java applications are not stored in the Apache, it can be only connected to the other Java webapp hosting webserver using mod_jk connector. mod_jk is a replacement to elderly mod_jserv. It is the completely new Tomcat-Apache plug-in that handles communication between the Tomcat and Apache.
61. What are reliable or unreliable Spouts?
Ans:
Spouts can either be reliable or unreliable. A reliable spout is a capable of replaying the tuple if it failed to be processed by Storm, whereas unreliable spout forgets about the tuple as soon as it is emitted.
62. What are built-in stream groups in Storm?
Ans:
- Shuffle grouping
- Fields grouping
- Partial Key grouping
- Global grouping
- None grouping
- Direct grouping
- Local or shuffle grouping
63. What are Tasks?
Ans:
Each spout or bolt executes as the many tasks across the cluster. Each task corresponds to the one thread of execution, and stream groupings define how to send tuples from a one set of tasks to the another set of tasks. set the parallelism for each spout or bolt in a setSpout and setBolt methods of TopologyBuilder.
64. What are Workers?
Ans:
Topologies execute across the one or more worker processes.
Every worker process is the physical JVM and executes the subset of all the tasks for the topology.
65. How many types of built-in schedulers are in Storm?
Ans:
- DefaultScheduler
- IsolationScheduler
- MultitenantScheduler
- ResourceAwareScheduler
66. What happens when worker dies?
Ans:
When the worker dies, the supervisor will restart it.
If it continuously fails on the startup and is unable to heartbeat to the Nimbus, Nimbus will reschedule the worker.
67. What happens when Nimbus or Supervisor daemons die?
Ans:
- The Nimbus and Supervisor daemons are designed to fail-fast and stateless.
- The Nimbus and Supervisor daemons must be run under the supervision using the tool like daemon tools or monit. So if Nimbus or Supervisor daemons die, they restart like a nothing happened.
- Most notably, no worker processes are the affected by death of Nimbus or the Supervisors. This is in contrast to the Hadoop, where if JobTracker dies, all the running jobs are the lost.
68. Is Nimbus a single point of failure?
Ans:
If lose the Nimbus node, the workers will still continue to the function. Additionally, supervisors will continue to the restart workers if they die. However, without Nimbus, workers won’t be reassigned to the4 other machines when necessary.
69. What makes running topology: worker processes, executors and tasks?
Ans:
Storm distinguishes between following three main entities that are used to actually run the topology in a Storm cluster:
- Worker processes
- Executors (threads)
- Tasks
A worker process executes the subset of a topology. A worker process belongs to the specific topology and may run one or more executors for a one or more components (spouts or bolts) of this topology. A running topology consists of many such processes running on the many machines within a Storm cluster.
70. How does Storm handle message processing guarantees?
Ans:
Storm provides the at-least-once message processing guarantees. Tuples are the acknowledged by Bolts after processing, and in case of the failures, Storm can replay tuples to ensure processed at least once. Users can implement the idempotent processing logic in the Bolts to handle potential duplicates.

Enroll in Apache Storm Certification Training with Advanced Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
71. Explain concept of windowing in Apache Storm.
Ans:
Windowing in the Apache Storm refers to ability to group and process data overc a specific time intervals. It allows the users to perform operations on batches of data within defined windows, enabling a temporal analysis. Windowing is useful for the scenarios where data needs to be analyzed the over time, such as computing rolling averages or the aggregations.
72. How does Apache Storm integrate with other components of Hadoop ecosystem?
Ans:
Apache Storm can integrate with the various components of Hadoop ecosystem, like HDFS, HBase, and Kafka. It can read and write data to the HDFS, interact with the HBase for a real-time database operations, and consume a data from Kafka for the seamless integration with the distributed messaging systems.
73. How Storm handles data partitioning and parallelism?
Ans:
Storm achieves parallelism by dividing processing tasks into the multiple worker nodes. Every worker node executes a subset of topology’s tasks. Storm provides a data partitioning through the stream groupings, allowing for efficient distribution of data across the worker nodes to enable the parallel processing.
74. Differences between “ack” and “fail” methods in Apache Storm.
Ans:
In Apache Storm, ‘ack’ method is used by a Bolts to acknowledge the successful processing of tuple. If the tuple fails to be processed, the ‘fail’ method is invoked, indicating that tuple needs to be replayed. Together, these methods are ensure reliable and fault-tolerant message processing.
75. How does Apache Storm ensure data reliability in presence of failures?
Ans:
Storm provides the reliability by tracking lineage of tuples. If a tuple fails to be processed, Storm can replay it by reconstructing a data lineage. Additionally, the use of the acking and retries, combined with the data replication and task parallelism, contributes to overall reliability of the system.
76. Explain tuple anchoring in Apache Storm.
Ans:
Tuple anchoring is the mechanism in Apache Storm where Bolts can anchor processed tuples to incoming tuples. This ensures that if tuple fails and needs to be replayed, its downstream dependencies are also replayed. Tuple anchoring is a crucial for maintaining a data consistency and integrity in topology.
77. How does Apache Storm handle backpressure in a topology?
Ans:
Backpressure in the Apache Storm occurs when Bolt is unable to keep up with the incoming data rate. Storm handles the backpressure by slowing down the emission of tuples from a Spouts. This ensures that Bolts have the sufficient time to process incoming tuples without overwhelming system.
78. Explain Storm Trident in comparison to core Storm API.
Ans:
Storm Trident is higher-level abstraction built on top of core Storm API. It provides the more declarative and functional programming style for building topologies. Trident introduces the concepts like micro-batching, stateful processing, and transactional guarantees, making it simpler to develop a complex and fault-tolerant real-time applications.
79. How does Storm handle tuple routing and grouping in distributed fashion?
Ans:
Storm uses the stream groupings to determine how tuples are the routed from Spouts to Bolts in the distributed manner. The choice of grouping strategy, such as shuffle grouping or the fields grouping, affects how tuples are distributed across the worker nodes. This enables the parallel processing of data in a distributed Storm topology.
80. Explain state in Apache Storm and how it is managed.
Ans:
State in Apache Storm refers to information that needs to be maintained between the processing steps, allowing Bolts to store and retrieve data. Storm provides both the non-transactional and transactional state mechanisms. Non-transactional state is a suitable for read-only operations, while transactional state ensures the consistency in state updates across the topology.
81. How does Storm ensure message processing semantics in terms of “at-least-once” and “at-most-once”?
Ans:
Storm provides the at-least-once processing semantics by tracking acknowledgment of tuples. Tuples are the acknowledged by Bolts upon successful processing, and in case of failures, Storm can replay tuples to ensure processed at least once. At-most-once semantics can be achieved by avoiding the tuple re-emission in case of failures, but this may lead to the potential data loss.
82. Discuss Apache Storm Multilang protocol.
Ans:
The Apache Storm Multilang protocol enables integration of non-JVM languages with Storm. It allows implementation of Bolts and Spouts in the languages like Python or Ruby. The protocol facilitates communication between Storm runtime and external processes written in the supported languages, enabling a diverse range of language choices for the developing Storm components.
83. Discuss Storm HDFS Bolt and its use in integrating Storm with Hadoop.
Ans:
The Storm HDFS Bolt is used for an integrating Apache Storm with the Hadoop Distributed File System (HDFS). It allows storing of processed data in HDFS, enabling seamless integration with broader Hadoop ecosystem. The HDFS Bolt provides the reliable and scalable mechanism for a persisting data processed in a Storm topology.
84. Explain Apache Storm Trident framework.
Ans:
Apache Storm Trident is the higher-level abstraction that simplifies the development of the complex topologies. It introduces high-level primitives for a stateful stream processing, transactional guarantees, and micro-batching. Trident enhances ease of development for a real-time applications by providing a more declarative and a functional programming model.
85. Discuss Storm Supervisor in Storm cluster architecture.
Ans:
A Storm Supervisor is responsible for the launching and managing worker processes on the individual machines in Storm cluster. It receives assignments from Nimbus master node and ensures that tasks specified in the assignments are executed on worker nodes. Supervisors play the key role in maintaining the distributed and parallel nature of the Storm processing.
86. How does Apache Storm handle schema evolution in data streams?
Ans:
Storm does not enforce the rigid schema for data streams, allowing for a flexibility in handling schema evolution. Tuples in Storm can carry data in the loosely structured format, and Bolts can be designed to adapt to the changes in incoming data schema. This flexibility is advantageous when dealing with the evolving data sources.”
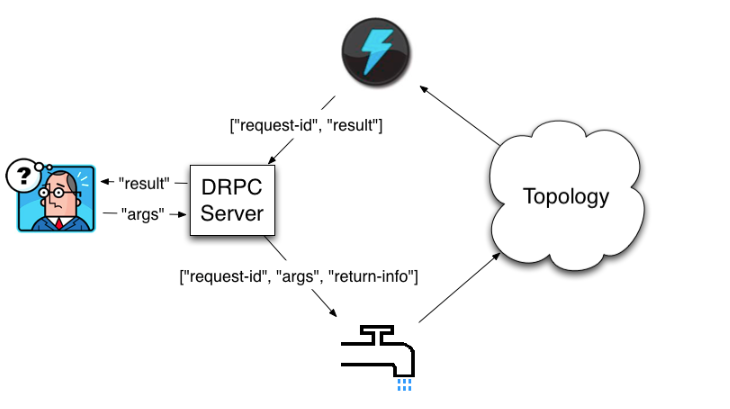
87. Explain DRPC (Distributed Remote Procedure Call) service.
Ans:
The Storm DRPC service allows the clients to submit distributed computations to the Storm cluster. It enables execution of remote procedures across the cluster and returns the results to a client. DRPC provides the powerful mechanism for building the real-time, interactive applications on top of Storm framework.
88. How can monitor and troubleshoot performance issues in Storm cluster?
Ans:
Monitoring a Storm cluster involves using the tools like the Storm UI, logging, and metrics to track status of topologies, resource utilization, and task performance. Troubleshooting performance issues may include for analyzing worker logs, examining topology metrics, and adjusting the configuration parameters to optimize the resource usage and mitigate bottlenecks.
89. Discuss impact of message ordering and timestamp extraction in Storm topologies.
Ans:
Message ordering and timestamp extraction are the important considerations in a Storm topologies. Message ordering ensures that tuples are the processed in the correct sequence, while timestamp extraction are allows Bolts to make a temporal decisions based on arrival time of tuples. These mechanisms are crucial for applications require accurate and time-sensitive processing of data streams.
90. How does Storm ensure data locality?
Ans:
Storm ensures data locality by scheduling a tasks on worker nodes where a data is located, reducing the need for a data movement across the network. This is important in the distributed processing to minimize network overhead and enhance the overall performance. Data locality contributes to be efficient resource utilization and faster processing times in the Storm cluster.




