
Last updated on 12th Apr 2024| 5427
Our BigQuery interview questions cover various aspects of Google BigQuery, including its components, architecture, query optimization techniques, data ingestion methods, security features, and integration with other Google Cloud services. We delve into SQL querying proficiency, understanding of partitioning and clustering strategies for optimizing performance, knowledge of BigQuery ML for machine learning tasks, familiarity with data export and import options, and expertise in managing access controls and permissions within BigQuery datasets.
1. What is BigQuery, and why is it utilized?
Ans:
BigQuery serves as a fully managed, serverless information distribution centre that empowers adaptable investigation over endless datasets utilizing the SQL sentence structure. It’s utilized for speed and effectiveness in handling questions over petabytes of information without the requirement for framework administration. By leveraging Google’s cloud foundation, BigQuery provides an exceedingly versatile and cost-effective arrangement for information analytics. This permits clients to focus on analyzing information to infer bits of knowledge instead of overseeing basic equipment.
2. What components does Google BigQuery include?
Ans:
Google BigQuery includes several key components:
- The BigQuery Engine, which executes SQL queries Storage, for housing data in tables
- The BigQuery Console, providing an interface for query execution and data management
- BigQuery ML, enabling machine learning directly on BigQuery data Integration with other Google Cloud services.
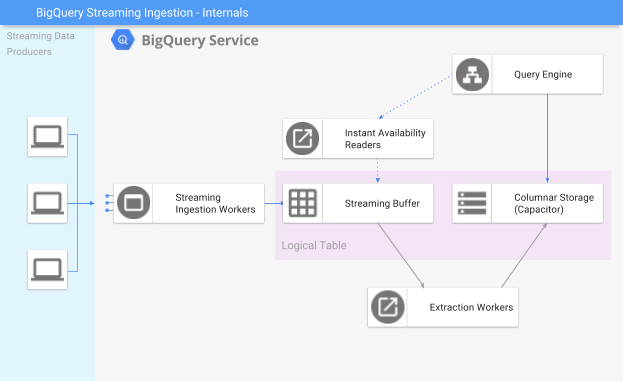
3. Explain the concept of spaces in BigQuery and how they affect inquiry execution.
Ans:
- Openings are units of computational capacity in BigQuery utilized to execute SQL questions. The number of spaces decides the parallelism level and hence influences the speed of inquiry execution; more spaces can lead to speedier inquiry handling times.
- Clients can select between on-demand estimating, where openings are apportioned powerfully, or flat-rate estimating for committed space capacity.
- Effective administration of spaces, particularly in a shared environment, is pivotal for optimizing execution and overseeing costs.
4. What are the most excellent hones for taking a toll control in BigQuery?
Ans:
To control costs in BigQuery, it’s fitting to:
- Utilize divided and clustered tables to decrease the volume of information filtered by questions,
- See inquiry costs utilizing the BigQuery estimating calculator or the –dry_run hail sometime recently execution
- Execute fetched controls and alarms to screen and cap day by day investing
- Use BigQuery’s caching instrument to maintain a strategic distance from re-running the same questions. These procedures offer assistance in successfully overseeing and decreasing BigQuery costs.
5. How does BigQuery guarantee information security?
Ans:
BigQuery guarantees information security through a few components:
- Encryption at rest and in transit.
- Character and Get-to Administration (IAM) for fine-grained access control.
- Integration with Google’s VPC Benefit Controls for segregating assets.
- Ability for clients to specify roles and permissions to control access to datasets and tables.
- Review logs for transparency into access and usage patterns.
- Enhancement of security posture and compliance with data protection regulations.
6. How does BigQuery ML differ from conventional machine learning approaches?
Ans:
| Aspect | |||
| Setup Complexity | Minimal setup required; no need for separate infrastructure. | Requires setup of machine learning environments and infrastructure. | |
| Integration with SQL | Built-in support for machine learning directly within SQL queries. | SQL integration may require additional configuration or custom solutions. | |
| Model Deployment | Models can be deployed directly within BigQuery. | Deployment may involve additional steps and infrastructure outside of the modeling environment. | |
| Data Preprocessing | Provides built-in preprocessing capabilities within SQL queries. | Preprocessing may require separate steps and tools. | |
| Feature Engineering | Supports feature engineering directly within SQL queries. | Feature engineering may require additional tools or frameworks. |
7. Clarify the concept of the dataset in BigQuery and its significance.
Ans:
A dataset in BigQuery acts as a holder for tables sees, and models, serving as an essential organizational structure that permits the administration of controls and information territory. It is basic for organizing and securing your information, empowering you to apply consent at the dataset level to control which clients or groups can access the contained information. Datasets, too, offer assistance in overseeing the information lifecycle, such as setting close times for tables and overseeing capacity costs naturally.
8. What are apportioned tables in BigQuery, and how do they advantage information examination?
Ans:
Apportioned tables in BigQuery are tables that are partitioned into portions, called allotments, based on an indicated column or ingestion time.
- This structure improves inquiry execution and diminishes costs by permitting questions to be checked as if they were significant segments of information.
- They are particularly useful for managing expansive datasets by enabling more productive information organization and speedier, cost-effective get to subsets of information for examination, making them perfect for time-series data investigation.
9. Depict the method of stacking information into BigQuery.
Ans:
Stacking information into BigQuery includes a few strategies: such as counting gushing information in real time, executing bunch loads from Cloud Capacity, or exchanging information from outside sources through BigQuery Information Exchange Benefit. The choice of strategy depends on the data’s root and estimate and the immediacy with which it must be analyzed. It’s pivotal to organize the information accurately and select the suitable construction settings recently to guarantee information astuteness and optimize inquiry execution.
10. How does BigQuery handle information protection and compliance?
Ans:
BigQuery addresses information security and compliance through vigorous information encryption, both at rest and in travel, strictly get-to controls, and nitty-gritty review logs. It complies with major information assurance controls by advertising apparatuses and highlights that offer assistance to organizations in overseeing their information in a compliant way, such as information maintenance arrangements and the capacity to anonymize touchy information utilizing DLP API integration. BigQuery’s commitment to security and compliance makes a difference in organizations’ belief that their information is secure and overseen, agreeing to administrative measures.
11. What is the part of BigQuery GIS in spatial information examination?
Ans:
- BigQuery GIS (Geographic Data Frameworks) expands BigQuery’s capabilities to handle geographic and spatial information examination straightforwardly in SQL.
- It permits clients to store, prepare, and visualize geospatial information proficiently, empowering the examination of location-based information and spatial questions without requiring a specialized geographic program.
- This integration streamlines complex geospatial analytics, making it available to information investigators and researchers for making location-based choices and experiences.
12. Clarify the contrast between outside tables and local tables in BigQuery.
Ans:
Outside tables in BigQuery permit clients to inquire about information specifically from outside sources, such as Google Cloud Capacity, without stacking the information into BigQuery capacity. This contrasts with local tables, where information is put away inside BigQuery. Whereas outside tables offer adaptability and spare capacity costs, they may lead to higher inquiry idleness compared to local tables. Local tables, completely overseen inside BigQuery, provide faster access and execution for information examination, making them reasonable for habitually accessed information.
13. What are the key highlights of BigQuery that separate it from other information stockrooms?
Ans:
- Serverless Engineering: BigQuery’s serverless architecture eliminates the need for database organization and allows scaling without system management.
- High-Speed Querying: Powered by Dremel innovation, BigQuery enables rapid analysis over petabytes of data.
- Integration with Google Cloud Services: BigQuery seamlessly integrates with Google Cloud Platform services, enhancing its capabilities for machine learning, data sharing, and real-time analytics.
- Pay-As-You-Go Pricing: The pay-as-you-go pricing model offers flexibility and cost-effectiveness, making BigQuery suitable for both startups and enterprises.
14. How can you run a BigQuery inquiry on a massive amount of data?
Ans:
To upgrade BigQuery inquiry execution, begin by organizing your inquiries to filter as it were the vital columns and columns, utilizing divided and clustered tables at whatever point conceivable. Leveraging materialized sees can cause cache inquiries to come, essentially decreasing execution times for dreary inquiries. Fine-tuning the query’s structure, such as maintaining a strategic distance from SELECT *, can minimize the sum of information handled. Moreover, consider expanding the accessible spaces on the off chance that you’re on a flat-rate estimating arrangement, as this specifically impacts the parallel handling capacity of your inquiries.
15. Clarify the importance of clustering in BigQuery tables and its effect on inquiries.
Ans:
Clustering in BigQuery organizes information inside each segment based on the values of one or more columns. This can make strides in inquiry execution and decrease costs by constraining the sum of information studied amid inquiry execution. After you inquiry clustered tables, BigQuery can proficiently skip over pieces of information that don’t match the inquiry criteria. Usually particularly advantageous for sifting and conglomeration questions, where clustering keys adjust closely with inquiry predicates, coming about in quicker, more cost-efficient inquiry execution.
16. How BigQuery oversees information consistency and what segregation levels it bolsters?
Ans:
- BigQuery guarantees information consistency by naturally overseeing the execution of inquiries and information adjustments, giving solid consistency for all examined operations after information adjustments. It does this without requiring express exchange administration from the client.
- BigQuery works with a “depiction separation” level for inquiries, permitting clients to inquire a reliable preview of the information at the inquiry beginning time, hence guaranteeing that a query is not influenced by concurrent information adjustments, giving a steady and dependable information investigation environment.
17. Where BigQuery’s unified questioning capability would be especially valuable?
Ans:
BigQuery’s combined questioning capability is especially valuable in scenarios where organizations have their information spread over different capacity arrangements but have to analyze it as if it were all in one put. For illustration, a company might store verifiable information in BigQuery for cost-effective long-term capacity and examination, while more current information dwells in Cloud SQL for value-based purposes. Combined questioning permits examiners to run questions over both these information sources consistently, without the need to continually integrate ETL information into BigQuery, empowering real-time experiences over different datasets.
18. What is the BigQuery Reservation API, and how does it advantage large-scale information operations?
Ans:
The BigQuery Reservation API permits the assignment and administration of BigQuery compute assets through the concept of reservations. This API is particularly advantageous for large-scale information operations because it empowers organizations to buy committed preparing capacity (spaces) for their BigQuery employments. By making and doling out reservations, organizations can guarantee steady inquiry execution, oversee costs by confining and controlling asset utilization among diverse offices or ventures, and prioritize basic workloads by apportioning more assets to high-priority assignments, improving general proficiency and consistency in operations.
19. How does BigQuery’s machine learning integration encourage prescient analytics within the stage?
Ans:
- BigQuery ML democratizes machine learning by enabling data investigators.
- Machine learning models can be created and executed inside BigQuery using SQL.
- No specialized ML expertise is needed.
- Integration facilitates predictive analytics.
- Models can be developed and deployed on large datasets rapidly and efficiently.
- BigQuery ML supports trend forecasting, data classification, and predictions directly on stored data.
20. Depict the method and benefits of utilizing BigQuery for information lake analytics.
Ans:
- BigQuery can directly query external data sources like Google Cloud Storage.
- This ability makes it effective as a query engine for data lake analytics.
- It enables organizations to analyze their data in place, reducing time-to-insight and storage costs.
- BigQuery’s external table feature and powerful analytics engine allow for advanced analyses across the entire data lake.
- This approach provides flexibility in data storage and arrangement.
21. How does Bigquery’s space suggestion include work, and what are its focal points?
Ans:
- BigQuery’s space suggestions include utilizing machine learning to analyze past inquiry execution and suggesting alterations to the number of spaces distributed for your BigQuery reservations.
- This proactive approach makes a difference in optimizing asset assignment, guaranteeing that your inquiries run productively without overprovisioning or underutilizing assets.
- The points of interest incorporate fetched reserve funds by adjusting opening capacity with genuine utilization, progressing inquiry execution through better asset allotment, and streamlined capacity arranging.
22. Clarify the effect of information skew on BigQuery execution and how to relieve it.
Ans:
Information skew alludes to the uneven dissemination of information over segments or inside a clustered table, where certain segments or clusters are essentially bigger than others. This lopsidedness can lead to wasteful inquiry execution, as a few labourers may be overburdened, whereas others stay underutilized, coming about in longer inquiry times and higher costs. To relieve information skew, consider redistributing your information more equitably over-allotments or clusters, choosing a more successful dividing or clustering key that adjusts along with your inquiry designs.
23. What factors decide between BigQuery and Dataflow for data prep?
Ans:
| Factors | ||
| Data Size | Efficient for large datasets. | Suitable for both small and large datasets. |
| Query Complexity | Ideal for ad-hoc queries and simple analytics. | Flexible for complex data processing tasks. |
| Cost | Cost-effective for query-based operations. | Costs may vary based on processing complexity. |
| Real-time Processing | Not suitable for real-time processing. | Supports real-time data processing. |
| Schema Flexibility | Schema-on-read; flexible schema. | Requires explicit schema definition. |
| Scalability | Automatically scales to handle large workloads. | Scalable for parallel processing of data. |
24. How can organizations use BigQuery’s AI capabilities for progressed analytics?
Ans:
- Organizations can use BigQuery’s AI capabilities, outstandingly BigQuery ML, to construct and convey machine learning models straightforwardly inside the database utilizing SQL commands.
- This integration rearranges the machine learning workflow, permitting information investigators and researchers to execute prescient analytics, regression analyses, and classification errands specifically on their datasets without requiring specialized machine learning skills or devices.
- Besides, BigQuery’s AI capabilities are extendable through integration with Google Cloud AI and machine learning administrations, empowering advanced analytics scenarios, such as normal dialect handling and picture acknowledgement, specifically on the information inside BigQuery.
25. Talk about the importance of BigQuery Omni for multi-cloud information analytics.
Ans:
- BigQuery Omni addresses the developing requirement for multi-cloud information analytics by permitting clients to analyze information over Google Cloud, AWS, and Purplish Blue without having to move information between cloud suppliers.
- Fueled by Anthos, it expands BigQuery’s information analytics capabilities to other clouds, empowering a genuinely rationalist approach to information capacity and investigation.
- This can be especially noteworthy for organizations with data and applications conveyed over numerous clouds because it rearranges get to, investigation, and security while keeping up information sway.
- BigQuery Omni upgrades operational proficiency, diminishes complexity, and brings down costs related to multi-cloud information administration and analytics.
26. What is BigQuery Information Exchange Benefit, and how does it streamline workflows?
Ans:
The BigQuery Information Exchange Benefit computerizes the ingestion of information from different Google and outside information sources into BigQuery, streamlining information pipelines and decreasing manual workload. It bolsters planned exchanges and provides a centralized stage for overseeing information ingestion from different sources. This benefit is significant for businesses that depend on opportune information overhauls because it guarantees information freshness with negligible exertion.

Best BigQuery Certification Course with Advanced Concepts from Real Time Experts
Weekday / Weekend BatchesSee Batch Details27. How does a toll administration in BigQuery work and methodologies to optimize investing?
Ans:
Fetched administration in BigQuery spins around understanding and optimizing how information is put away and questioned. Clients can oversee costs by utilizing divided and clustered tables to decrease the sum of information filtered amid questions, setting up fetched controls and alarms to screen investing, and selecting the fitting estimating demonstrate (on-demand or flat-rate) based on their utilization designs. Also, filing or erasing ancient information and leveraging BigQuery’s capacity lifecycle administration can decrease capacity costs altogether. Viable utilization of materialized sees and caching can diminish inquiry costs by minimizing excess computations.
28. How does BigQuery back machine learning ventures, and what are its restrictions?
Ans:
BigQuery ML enables information investigators and researchers to construct and convey machine learning models specifically inside BigQuery utilizing SQL inquiries, encouraging a smooth workflow from information investigation to prescient modelling. This integration permits the quick application of machine learning to endless datasets without broad information development or change. In any case, BigQuery ML may not back all sorts of machine learning calculations and complex show-preparing arrangements accessible in more specialized systems like TensorFlow or PyTorch.
29. What is the centrality of BigQuery’s association with the broader Google Cloud environment?
Ans:
- BigQuery’s tight integration with the Google Cloud biological system upgrades its capability to handle a wide range of information analytics and machine learning errands.
- This association permits consistent information development and examination over administrations like Cloud Capacity, Dataflow, Dataprep, and AI Stage, empowering comprehensive data pipelines from ingestion to knowledge.
- The ecosystem supports progressed analytics scenarios, collaborative information science, and the improvement of end-to-end arrangements leveraging Google’s cloud capabilities.
- This interoperability disentangles complex workflows and permits organizations to use their information more viably over different Google Cloud administrations.
30. In what scenarios is BigQuery, not the perfect arrangement, and what choices could be considered?
Ans:
Whereas BigQuery exceeds expectations at analytics on expansive datasets, it may not be the finest fit for scenarios requiring value-based database capabilities with tall type in throughput and low-latency peruses, such as online transaction preparing (OLTP) frameworks. In such cases, choices like Cloud Spanner or Cloud SQL could be more suitable for advertising social database administrations with exchange back and SQL interfacing. Moreover, for applications requesting real-time information handling with complex event processing capabilities, gushing information stages like Cloud Pub/Sub and Dataflow show better-suited choices.
31. How does apportioning in BigQuery upgrade inquiry execution and diminish costs?
Ans:
Apportioning in BigQuery organizes information into fragments, ordinarily based on a date or timestamp, but can also be based on numbers extended. This structure improves inquiry execution by empowering BigQuery to check as if it were pertinent segments rather than the complete dataset, which is especially useful for time-based questions. Subsequently, this decreases the amount of data handled, leading to lower costs. Apportioning could be a vital choice for overseeing expansive datasets because it optimizes asset utilization and quickens inquiry execution. It is an essential technique for effective information investigation and fetched administration in BigQuery.
32. Clarify the concept of BigQuery GIS and its applications.?
Ans:
- BigQuery GIS (Geological Data Frameworks) amplifies BigQuery’s capabilities to store, prepare, and analyze geospatial information proficiently.
- It permits clients to perform spatial examinations straightforwardly in BigQuery, using familiar SQL sentence structures to oversee and inquire about topographical information.
- This incorporates operations like measuring separations between focuses, deciding regions of interest, and analyzing spatial connections.
- Applications of BigQuery GIS span different divisions, counting coordinations for course optimization, genuine domain for spatial examination of property values, and environmental monitoring for following changes in arrive utilize or common highlights.
33. What are the most excellent hones for organizing information in BigQuery to optimize execution?
Ans:
To optimize execution in BigQuery, organizing information productively is key. Use partitioned and clustered tables to make strides in inquiry efficiency and decrease costs by narrowing down the data filtered. Select a fitting apportioning key and regularly a date column for time-based data to encourage speedier inquiries on specific time slices. Clustering assists in organizing information inside each parcel based on chosen columns, which can be particularly useful for sifting and accumulating questions. Furthermore, normalize information where fitting to diminish redundancy and capacity measure.
34. How do you handle information movement from on-premises databases to BigQuery?
Ans:
Moving information from on-premises databases to BigQuery includes a few steps: counting, surveying the existing information pattern, extricating the information, changing it to coordinate BigQuery’s ideal organization, and stacking it into BigQuery. Instruments like Google’s Cloud Information Transfer Service or third-party ETL devices can computerize much of this handle. Challenges incorporate overseeing huge information volumes, guaranteeing information keenness amid the movement, and optimizing the data pattern for BigQuery’s engineering.
35. How can BigQuery integrate with data visualization tools, and what are its benefits?
Ans:
- BigQuery integrates consistently with information visualization instruments like Google Data Studio, Scene, and Looker, empowering clients to form intelligently reports and dashboards straightforwardly from BigQuery datasets.
- This integration permits real-time information examination and visualization, providing easily accessible knowledge throughout an organization.
- The benefits incorporate the capacity to recognize patterns rapidly, make data-driven choices, and communicate findings effectively to partners.
36. What procedures can be utilized to oversee and optimize BigQuery capacity costs?
Ans:
To oversee and optimize BigQuery capacity costs, consider executing information lifecycle arrangements to erase ancient or superfluous information consequently. Utilize divided tables to organize information by date, which can, at that point, be specifically pruned based on your maintenance necessities. Compress and clean your information. Sometime recently, I stacked it into BigQuery to play down capacity measures. Use BigQuery’s columnar capacity to organize your information pattern to optimize for inquiry get to designs, which can decrease the sum of information put away. Also, routinely survey and chronicle or erase unused tables and datasets.
37. How does BigQuery’s unified inquiry capability advantage information investigation?
Ans:
BigQuery’s combined inquiry permits investigators to inquire about information specifically from outside sources like Google Cloud Capacity, Cloud SQL, and Google Sheets without having to stack the information into BigQuery to begin with. This capability encourages real-time examination of information dwelling in different groups and areas, advertising adaptability and decreasing information development and capacity costs. It empowers a consistent integration of dissimilar information sources for comprehensive analytics, upgrading the skill of data-driven decision-making forms by giving quick get to a wide cluster of information.
38. What part does BigQuery’s machine learning integration play in prescient analytics?
Ans:
BigQuery ML empowers clients to form and execute machine learning models utilizing standard SQL inquiries, specifically inside the BigQuery environment. This integration disentangles the method of applying prescient analytics to large datasets, making it open to information investigators who may not have specialized machine-learning skills. Clients can rapidly construct, prepare, and convey models for errands like estimating classification and clustering, specifically based on their information.
39. Depict how the BigQuery Reservation demonstrates how it works for overseeing costs.
Ans:
The BigQuery Reservation show permits organizations to buy devoted inquiry preparing capacity (spaces) at a level rate, advertising unsurprising estimating and fetched administration for BigQuery utilization. This model is perfect for businesses with reliable inquiry workloads because it empowers them to secure assets at a reduced rate compared to on-demand estimating. Clients can allot spaces to particular ventures or offices, guaranteeing that basic workloads have the essential assets while optimizing by large investing in BigQuery administrations.
40. How do you guarantee information quality and consistency in BigQuery?
Ans:
Guaranteeing information quality and consistency in BigQuery includes:
- Executing approval checks amid information ingestion.
- Keeping up information mappings carefully.
- Utilizing highlights like planned queries for customary information cleaning and change assignments.
Furthermore, leveraging BigQuery’s back for value-based consistency and utilizing best practices for data modelling and construction advancement is vital. Normal observing and inspecting of information, along with establishing clear information administration approaches, play imperative parts in maintaining high information quality and consistency.
41. What contemplations ought to be made when planning a pattern for BigQuery?
Ans:
- When planning a construction for BigQuery, consider how your information will be questioned to optimize execution and fetch. Utilize settled and rehashed areas to diminish the requirement for joins and effectively use BigQuery’s columnar capacity.
- Select suitable information sorts to reduce the capacity measure and fetch and consider apportioning and clustering techniques to improve inquiry execution.
- Designing with versatility in intellect, expect future information development and inquiry complexity to guarantee the pattern remains productive and reasonable over time.
42. Clarify the centrality of clustering in BigQuery and how it compares to apportioning.
Ans:
Clustering in BigQuery organizes information inside a table based on the substance of one or more columns. This can progress inquiry execution and decrease costs by empowering BigQuery to prune information squares effectively amid inquiry execution. Unlike apportioning, which organizes information into separate segments based on a segment key, clustering works inside segments to advance and refine information organization and get to. Combining partitioning and clustering provides an effective way to optimize information storage, query performance, and cost-effectiveness in BigQuery.
43. What is the impact of BigQuery’s serverless design on information analytics?
Ans:
BigQuery’s serverless engineering disposes of the requirement for framework administration, permitting clients to centre on analyzing information instead of overseeing servers. This show scales naturally to meet the requests of the workload, guaranteeing that questions are prepared rapidly, indeed with expansive datasets. The serverless approach streamlines the method of setting up and running analytics at scale, making effective information investigation instruments available to companies of all sizes without the forthright venture into equipment or continuous maintenance
44. Clarify the utilization of wildcard tables in BigQuery and their benefits.
Ans:
Wildcard tables in BigQuery allow clients to request diverse tables utilizing the wildcard characters in table names, empowering the examination of datasets spread over various basically named tables, such as those allocated by time. This incorporates unravellingirequestsests oday-by-daymonth-to-monthonth separated tables, decreasing the complexity of composing and maintairequestsquests. Wildcard tables progress the versatility in addressing time-series data and can lead to more streamlined and capable examination forms.
45. What is the part of BigQuery’s materialized sees in information examination?
Ans:
- Materialized views in BigQuery pre-compute and store the results of complex questions, speeding up information examination by serving these results from the materialized view instead of performing the calculations on the fly.
- They consequently overhaul as basic information changes, ensuring that the put away come about are continuously current.
- By decreasing the computational stack and inquiry time, materialized sees make visit and complex information examination operations much more proficient and cost-effective.
46. How can taken-a-toll control measures be executed in BigQuery?
Ans:
Executing fetched control in BigQuery involves setting up custom standards and cautions to screen and constrain investing. Utilizing apportioned and clustered tables can decrease the volume of data checked by inquiries, bringing down costs. Also, receiving the BigQuery Reservation demonstration for unexpected workloads can offer reserve funds. Frequently checking on and optimizing inquiry execution moreover contributes to fetched control by guaranteeing that assets are utilized productively.

Enroll in BigQuery Certification Course with Advanced Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
47. How does BigQuery back information sharing and collaboration?
Ans:
BigQuery encourages information sharing and collaboration through its integration with Google Cloud IAM (Character and Get to Administration), permitting fine-grained control over who can access particular datasets and tables. Shared datasets can be made accessible over ventures or, indeed, freely, with suitable authorizations. BigQuery, too, bolsters the sharing of questions and results, enabling collaborative investigation and decision-making. This advances a culture of data-driven understanding among groups and organizations.
48. Clarify the process and benefits of utilizing BigQuery’s Information Exchange Benefit.
Ans:
BigQuery’s Information Exchange Benefit computerizes the ingestion of information from various Google administrations (like Google Advertisements and Campaign Chief) and outside sources into BigQuery. It streamlines the method of setting up, planning, and overseeing information exchanges, guaranteeing data is frequently upgraded without manual mediation. This benefit not only spares time but also ensures that datasets in BigQuery are reliably new, supporting up-to-date examination and detailing and improving the proficiency of information workflows.
49. what does Bigquery’s on-demand estimating show from its flat-rate estimating?
Ans:
- BigQuery’s on-demand service estimates charge for the sum of information handled by questions, making it perfect for variable workloads without upfront costs.
- On the other hand, flat-rate estimating offers devoted inquiry handling capacity (openings) for a settled cost. It is suited for predictable, high-volume workloads, giving fetched consistency and possibly lower costs for overwhelming clients.
- The choice between models depends on your inquiry designs. On-demand advertising’s adaptability and flat rate guarantee execution consistency.
50. How do apportioned tables upgrade inquiry execution in BigQuery?
Ans:
Divided tables in BigQuery organize information based on an indicated timestamp, date, or numbers column, which permits proficient inquiry execution by restricting the sum of data scanned to the relevant partitions. This focused on information to speed up questions and decrease costs, especially for time-based inquiries, making apportioned tables an essential feature for overseeing and analyzing expansive datasets over time.
51. What is BigQuery’s bolster for geospatial information and its applications?
Ans:
BigQuery offers local back for geospatial information sorts and capacities, empowering the capacity, inquiry, and examination of topographical information inside the stage. This capability permits clients to perform complex geospatial investigations, such as calculating separations, making geographic visualizations, and recognizing designs or patterns based on the area information. Applications incorporate coordination optimization, location-based administrations, natural observing, and urban arranging.
52. What is the noteworthiness of utilizing Cluster and STRUCT information sorts in BigQuery?
Ans:
The cluster and STRUCT information types in BigQuery empower the capacity of complex, settled information inside a single push. Cluster is utilized for records of values, whereas STRUCT permits the definition of settled information structures with different areas. These sorts encourage the modelling of various levelled information and bolster productive questioning of settled datasets, improving big query’s capability to handle the wide assortment of information modelling scenarios.
53. How does BigQuery’s scripting and storage strategies enhance advanced data analysis?
Ans:
BigQuery’s scripting and put-away strategies permit the straightforward execution of complex, multi-step information changes and examinations inside the stage. Scripting underpins the creation of brief tables and control rationale (such as circles and conditionals), empowering modern information handling workflows. Put away methods of these workflows into callable schedules, advancing code reuse and disentangling support. This usefulness upgrades BigQuery’s flexibility as an information examination instrument, pleasing a wide run of explanatory needs.
54. What are the benefits of utilizing the BigQuery UI for information examination?
Ans:
- BigQuery UI gives a user-friendly interface for composing and executing questions, overseeing datasets, and visualizing inquiry comes about.
- It rearranges the investigation of datasets by advertising highlights like inquiry history, spared questions, and construction browsing.
- The UI moreover coordinates with other Google Cloud administrations for progressed analytics and machine learning, making it simpler for the clients to perform complex information examination errands without profound specialized skills in database administration.
55. How can BigQuery Information Exchange Benefit be utilized for showcasing analytics?
Ans:
- The BigQuery Information Exchange Benefit mechanizes the purport of information from publicizing stages such as Google Advertisements, Campaign Director, and third-party sources into BigQuery.
- This consistent integration empowers marketers to centralize their information for a comprehensive investigation, combining advertisement execution with other trade measurements.
- By computerizing information ingestion, marketers can more productively degree campaign viability, optimize advertisement spend, and pick up a more profound bit of knowledge into client behaviour over the channels.
56. Examine the part of getting to controls in overseeing BigQuery datasets.
Ans:
Get-to controls in BigQuery are basic for overseeing who can see or inquire about datasets, guaranteeing delicate information is ensured and compliance prerequisites are met. BigQuery coordinates with Google Cloud Personality and Get to Administration (IAM) to supply granular authorizations at the dataset, table, or indeed column level. By absolutely controlling get-to, organizations can uphold the guidelines for the slightest benefit, minimizing the hazard of unauthorized information getting to or being presented.
57. How does BigQuery back the examination of non-relational information?
Ans:
BigQuery exceeds expectations in taking care of non-relational (NoSQL) information by supporting the adaptable mappings for semi-structured information sorts, such as JSON and Avro. This permits clients to store and inquire about information without a predefined construction, pleasing the energetic nature of non-relational information. BigQuery’s capacity to naturally gather mappings and its back for settled and rehashed areas made it especially well-suited for analyzing complex information structures commonly found in the NoSQL databases.
58. How does BigQuery encourage integration with information visualization devices?
Ans:
- BigQuery consistently coordinates with different information visualization apparatuses, counting Google Information Studio, Scene, and Looker, empowering clients to make intelligent, intuitive dashboards and reports specifically from their datasets.
- This integration is encouraged through local connectors or big query API, which permits real-time access to motion examination and visualization.
- By rearranging the association to these apparatuses, BigQuery enables clients to communicate complex information experiences in an open and outwardly engaging way, improving decision-making forms.
59. What part does partitioning play in taking a toll optimization in BigQuery?
Ans:
Dividing in BigQuery could be a key methodology for taking a toll optimization because it permits more proficient information questions by narrowing down the sum of information checked to as it were the important segments. Typically, it is especially valuable for time-series information, where questions can be restricted to particular time outlines, altogether diminishing inquiry costs. By organizing information into segments based on a particular column, such as a date, clients can accomplish both execution advancements and take a toll on reserve funds, making BigQuery more prudent for large-scale information examination.
60. How does BigQuery’s columnar capacity arrangement contribute to its performance?
Ans:
BigQuery’s columnar capacity arrangement essentially upgrades its inquiry execution but takes a toll on its effectiveness. By putting away information in columns instead of columns, BigQuery can rapidly get to and filter as if it were the fundamental information for an inquiry, decreasing the sum of information prepared. This organization is especially profitable for explanatory inquiries that regularly get to, as it were, a subset of columns in a table. Also, columnar capacity permits for more viable compression advances, decreasing capacity costs and making strides in inquiry speed by minimizing the I/O required for information recovery.
61. How the effect of BigQuery’s shared spaces highlight on collaborative work situations.
Ans:
- BigQuery’s shared openings feature allows organizations to apportion BigQuery handling capacity (spaces) over different projects and groups, guaranteeing that assets are utilized efficiently and prioritizing workloads concurring with trade needs.
- This adaptability bolsters collaborative work situations by empowering consistent asset sharing, avoiding bottlenecks, and optimizing cost performance across different ventures.
- Shared openings improve the capacity of groups to execute information questions concurrently, making strides in efficiency and empowering more energetic information examination hones.
62. What contemplations ought to be taken under consideration when planning patterns in BigQuery?
Ans:
When planning mappings in BigQuery, it’s vital to consider the nature of your questions and information to get to designs. Organizing your pattern to back productive questions can affect execution and fetch. For occurrence, using nested and rehashed areas can optimize capacity and questioning of complex, hierarchical information. Moreover, choosing the proper information sorts and considering dividing and clustering alternatives can incredibly diminish inquiry times and costs. An astute construction plan is pivotal for leveraging BigQuery’s full potential in handling and analyzing expansive datasets productively.
63. How does BigQuery handle information encryption, and what choices are accessible for clients?
Ans:
BigQuery naturally scrambles all information at rest and in travel, guaranteeing a tall level of security for information put away inside its environment. Users have the alternative to utilize Google-managed keys for encryption or to take advance control by utilizing customer-managed encryption keys (CMEK) for particular ventures or datasets. This adaptability permits organizations to follow their security approaches and compliance requirements, providing an extra layer of security by empowering them to oversee and pivot encryption keys concurring with their security conventions.
64. What is the part of BigQuery’s BI Motor, and how does it enhance analytics?
Ans:
BigQuery’s BI Motor is an effective in-memory examination benefit that quickens information investigation and intelligently examines. By providing sub-second inquiry reaction time and high concurrency, BI Motor improves the execution of information visualization devices and supports a more energetic and responsive expository encounter. This capability is particularly profitable for dashboards and reports that need real-time data interaction, empowering decision-makers to grasp experiences more rapidly and proficiently.
65. What are the benefits of using BigQuery for data warehousing compared to traditional database systems?
Ans:
- BigQuery offers several advantages over conventional database frameworks for information warehousing and counting serverless design.
- It eliminates the requirement for foundation administration and has the capacity to scale naturally to handle petabytes of information.
- Its completely overseen, profoundly versatile, and cost-effective capacity and computing resources, combined with its capable information analytics capabilities, make it perfect for analyzing large volumes of information in real-time.
- Furthermore, BigQuery’s integration with the Google Cloud administrations and third-party instruments encourages a comprehensive information analytics environment.
66. How does BigQuery’s shrewd caching layer progress inquiry execution for rehashed questions?
Ans:
BigQuery upgrades execution for rehashed inquiries through its shrewdly caching layer, which incidentally stores the questions that have already been executed. When an inquiry that matches a cached result is submitted, BigQuery can return the result quickly without reprocessing the information, which will lessen execution time and asset utilization. This highlight is especially useful for dashboards and reports that are revived habitually, guaranteeing clients get fast reactions without bringing about extra costs for information re-computation.
67. Clarify how BigQuery GIS improves spatial information examination and its applications.
Ans:
BigQuery GIS (Geographic Data Frameworks) amplifies BigQuery’s capabilities to incorporate the investigation of geographic and spatial information. It permits clients to store, handle, and visualize geospatial information, specifically inside BigQuery, utilizing a commonplace SQL language structure. This includes a wide run of applications, from mapping and steering to complex geospatial analytics, such as surveying catastrophe impacts or arranging urban frameworks. By joining GIS capabilities, BigQuery empowers more comprehensive information examination, consolidating spatial settings into decision-making forms.
68. What is the reason for BigQuery’s materialized views, and how do they optimize information?
Ans:
BigQuery’s materialized sees are planned to consequently pre-compute and store about of complex inquiries, which essentially quickens information recovery for as often as possible executed questions. By referencing the materialized data instead of computing the inquiry against the complete dataset each time, clients can accomplish speedier execution and decrease the computational fetched. This highlight is especially valuable for the dashboards and announcing apparatuses that require fast get to information, optimizing both productivity and cost-effectiveness of information examination workflows.
69. How does BigQuery’s integration with Information Studio improve detailing capabilities?
Ans:
BigQuery’s integration with Google Data Studio engages clients to interface datasets to form intuitive reports and dashboards straightforwardly. This integration permits the consistent visualization of complex information examinations, empowering partners to investigate experiences through customizable charts, charts, and tables. By encouraging simple get-to-information visualizations, BigQuery and Information Studio together improve the decision-making process, making it easier for groups to share discoveries and collaborate on data-driven methodologies.
70. Is BigQuery accessible in all districts?
Ans:
- BigQuery isn’t accessible in each geological locale but is advertised in various districts over the Americas, Europe, Asia, and Australia to guarantee moo inactivity and that prerequisites for neighbourhood information preparation are met.
- Clients can select from these locales to store and analyze their information, depending on their topographical inclinations and administrative compliance needs. Be that as it may, Google proceeds to grow its services, counting BigQuery, into modern regions to serve its worldwide client base better.
71. What is PaaS?
Ans:
Stage as a Benefit (PaaS) may be a cloud computing advertising that provides clients with a platform permitting them to create, run, and oversee apps without having to deal with the hassle of creating and maintaining the foundation ordinarily associated with creating and propelling an app. PaaS conveys a system for engineers that they can build upon and utilize to form customized applications. This benefit is facilitated within the cloud and is open to designers and clients over the web.
72. What are the four imperative information layers that BigQuery bolsters?
Ans:
Capacity, Ingestion, Examination, and Visualization. The capacity layer proficiently handles expansive volumes of information, utilizing BigQuery’s columnar capacity arrangement. Ingestion includes bringing in information from different sources into BigQuery. The examination layer is where BigQuery’s effective SQL motor comes into play, allowing for complex inquiries. At last, the visualization layer coordinates with instruments like Google Information Studio to create open and noteworthy bits of knowledge.
73. What programming dialects does BigQuery bolster?
Ans:
BigQuery fundamentally bolsters SQL for questioning information, advertising a commonplace and capable sentence structure that’s both adaptable and intuitive for data examiners. Also, to expand BigQuery’s capabilities or join with other administrations, client libraries are accessible in several programming languages, including Java, Python, Node.js, C#, Go, Ruby, and PHP. This bolster permits engineers to associate with BigQuery programmatically, joining it consistently into broader information investigation and application advancement workflows.
74. What are a few utilized cases for BigQuery?
Ans:
BigQuery serves a wide range of tasks, including real-time analytics, business intelligence, information warehousing, and machine learning model improvement. It is exceedingly suited for analyzing gigantic datasets rapidly, empowering organizations to determine experiences from their information in real-time.
BigQuery also bolsters information integration and investigation over different sources, making it a perfect arrangement for undertakings looking to solidify their information analytics operations on a versatile, secure, and cost-effective stage.
75. What is the method for seeing segment subtle elements in BigQuery?
Ans:
To see parcel subtle elements in BigQuery, clients can inquire about the metadata around the table utilizing BigQuery’s built-in INFORMATION_SCHEMA sees by executing a SQL inquiry against the pertinent INFORMATION_SCHEMA.PARTITIONS see that clients can recover data around each segment, counting the segment ID, creation time, final alteration time, and the number of columns. This handle permits the effective administration and optimization of apportioned tables, encouraging better performance and fetched proficiency in information questioning.
76. How do BigQuery clients browse information?
Ans:
BigQuery users can browse information through Google Cloud Support, which gives a user-friendly interface for exploring datasets, tables, and sees. Also, the bq command-line device and the BigQuery REST API offer programmable get to for information browsing and administration. These instruments permit clients to execute SQL questions, see pattern points of interest, and analyze data directly, offering adaptability in how information is accessed and investigated. The integration with Google Cloud’s IAM guarantees secure control of browsing information.
77. What are the two alternatives for making planned inquiries in BigQuery?
Ans:
In BigQuery, planned questions can be made utilizing two primary alternatives:
- The Google Cloud Support and the bq command-line apparatus. Through the Cloud Console, clients can set up scheduled queries with a graphical interface, indicating the SQL inquiry, plan, and goal table for comes about.
- On the other hand, the bq command-line device permits the computerization of planned inquiries via scripting, giving a more adaptable and programmable approach to mechanize information handling and administration assignments on a repeating premise.
78. What is the division of storage and computing in BigQuery?
Ans:
The partition of storage and computing in BigQuery implies that the information capacity framework is decoupled from the computational assets used to query the information. This design permits clients to scale capacity and compute autonomously, optimizing costs and execution based on their needs. Capacity is overseen universally, guaranteeing high accessibility and solidity, whereas computing assets are powerfully distributed to questions, giving adaptable and proficient information preparation. This division upgrades BigQuery’s flexibility and scalability for dealing with huge datasets.
79. What is the extreme esteem of BigQuery?
Ans:
The extreme esteem of BigQuery lies in its capacity to handle endless sums of information at bursting speeds, making it a fundamental apparatus for enormous information analytics and real-time experiences. As a completely overseen, serverless information stockroom, BigQuery disposes of the requirement for framework administration, permitting users to focus on analyzing information rather than overseeing equipment. Its consistent integration with other Google Cloud administrations and progress in analytics and machine learning applications have improved its esteem, making it a comprehensive solution for data-driven decision-making.
80. What are tablets and sees in BigQuery?
Ans:
- In BigQuery, “tables” are organized information capacity units that hold your information in rows and columns, similar to tables in conventional relational databases. “Sees,” on the other hand, are virtual tables made by questioning other tables utilizing SQL.
- Sees do not store information themselves but give energetic result sets that reflect the information within the fundamental tables.
- This refinement permits clients to organize information productively (in tables) and make reusable questions that have unique complexity, encouraging information examination and announcing.
81. What is the perseverance layer in BigQuery?
Ans:
The determination layer in BigQuery is the fundamental framework for storing and overseeing information on Google’s cloud foundation. It guarantees that information is safely stored across different areas, giving it high strength and accessibility. This layer leverages Google’s disseminated record framework and restrictive advances for information capacity, empowering quick access to and examination of huge datasets. The determination layer abstracts the complexities of information capacity, permitting BigQuery to oversee petabytes of information and convey quick inquiry execution effectively.
82. What is the prescribed choice for clump utilize cases in BigQuery?
Ans:
For bunch utilize cases in BigQuery, the prescribed approach is to utilize BigQuery’s clump stacking highlight. This strategy permits the productive and cost-effective uploading of expansive volumes of information by stacking it in bulk. Bunch stacking minimizes the toll related to gushing information and is ideal for scenarios where information accessibility does not require real-time preparation. It is particularly appropriate for day-by-day or less visit upgrades, where the quickness of information ingestion isn’t basic.
83. What is the Cloud Dataflow pipeline in BigQuery?
Ans:
- The Cloud Dataflow pipeline in BigQuery alludes to a completely overseen benefit utilized for stream and group information preparing errands.
- It permits the change and enhancement of information, which has recently been stacked into BigQuery and encourages complex ETL (Extricate, Change, Stack) operations.
- This integration between Dataflow and BigQuery empowers versatile analytics arrangements, handling information in real-time or in clusters and consistently ingesting the handled information into BigQuery for encouraging examination.
84. What is the primary step in getting data into BigQuery?
Ans:
The primary step in getting information into BigQuery is to make a dataset, which serves as a holder for putting away related BigQuery tables and sees. Once a dataset is made, information can be imported into BigQuery utilizing different strategies, such as bunch stacking from Cloud Capacity, spilling embeds for real-time information ingestion, or utilizing Information Exchange Benefit for computerized information moment from outside sources. This introductory setup is pivotal for organizing and overseeing your information viably in BigQuery.
85. What is the suggestion for separating information into ears?
Ans:
The suggestion for dividing information over a long period, especially in BigQuery, is to use apportioned tables based on the date or timestamp columns. This procedure organizes information into segments, making it more reasonable and making strides in inquiry execution by decreasing the sum of information filtered. For time-based information, making a segment for each year can improve proficiency and cost-effectiveness, particularly for expansive datasets where inquiries frequently target particular periods.
86. Which BigQuery work does Safari not utilize for their operations group dashboard?
Ans:
The BigQuery work that Safari’s operations group dashboard does not utilize might shift as the particular work was not at first specified. In a common setting, operations dashboards might not utilize progressed analytical functions like ML.PREDICT or specialized geospatial capacities in case the dashboard centres on clear measurements such as client engagement or substance notoriety.
These progressed capacities are more commonly utilized in prescient analytics or spatial information examination, which might not be pertinent for a standard operations dashboard.
87. How does BigQuery work beneath the hood?
Ans:
- BigQuery operates as a highly flexible, serverless, fully managed data warehouse.
- It separates storage and computing, utilizing distributed architecture for processing queries efficiently.
- Data is stored in a columnar format, enhancing query performance and data compression.
- The underlying infrastructure automatically handles resource allocation and scaling.
- It provides fast analytics insights without the need for manual intervention in managing physical servers or database storage.
88. What is the most extreme estimate of a table that can be made in BigQuery?
Ans:
The greatest estimate of a single table in BigQuery is subject to the accessible capacity in Google Cloud, which basically permits petabyte-scale tables. BigQuery’s engineering and capacity are planned to handle endless sums of information, empowering clients to store and analyze huge datasets without particular limits on table size. This capability encourages the investigation of huge data scenarios, obliging developing information needs without compromising execution.
89. How do you import information into BigQuery?
Ans:
To moment information into BigQuery, will be able to utilize different strategies, counting:
- Upload records specifically through Google Cloud Support, utilize the bq command-line device, use the BigQuery API for automatic access, or gush information in real time.
- For bulk information loads, Google Cloud Capacity is regularly utilized as a mediator, where data records are transferred and then int imported into BigQuery. This strategy supports a wide range of information formats, including CSV, JSON, Avro, Parquet, and ORC.
90. Explain the concept of settled and rehashed areas in BigQuery.
Ans:
They settled and rehashed areas in BigQuery, permitting the capacity of complex, progressive information inside a single table push. Settled areas are utilized to speak to records inside a record, empowering an organized, JSON-like capacity to demonstrate. Rehashed areas are clusters of values of the same sort, permitting different values to be related to a single record. Together, these highlights empower the representation of complex information structures, upgrading BigQuery’s capability to handle different expository utilize cases productively.




