
Last updated on 23rd Aug 2025| 13563
- Introduction to Web Crawlers
- How Web Crawlers Work
- Key Functions of a Web Crawler
- Types of Web Crawlers
- Why Web Crawlers Are Important
- How to Optimize Your Website for Crawling
- Crawling vs. Indexing vs. Ranking
- Web Crawlers and SEO
- Ethical Considerations and Limitations
- Web Crawling Tools and APIs
- Conclusion
Introduction to Web Crawlers
A web crawler is a type of automated software or bot that browses the internet systematically, discovering and indexing web pages. The primary role of a crawler is to collect data about web content so that it can be stored, organized, and later retrieved by a search engine. Think of a crawler like a digital librarian, scanning books (web pages), organizing them (indexing), and helping readers (users) find them efficiently an essential concept explored in Digital Marketing Training, where learners master SEO fundamentals, search engine behavior, and technical optimization strategies to improve online visibility. The term “crawler” comes from the idea that the bot “crawls” across the web, following hyperlinks from page to page, much like a spider navigating its web hence the term “web spider.”
Ready to Get Certified in Digital Marketing? Explore the Program Now Digital Marketing Online Training Offered By ACTE Right Now!
How Web Crawlers Work
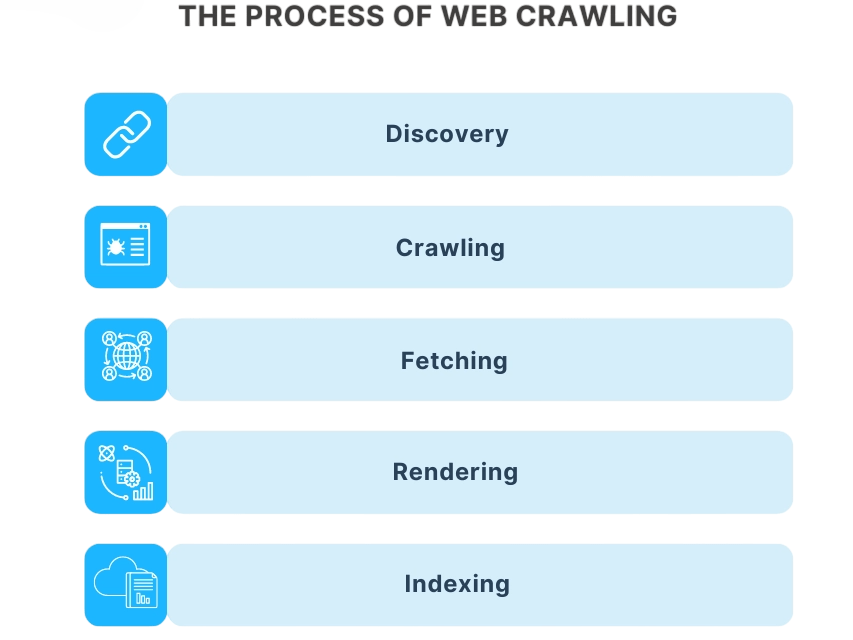
Web Crawlers work as advanced digital explorers that navigate the internet using a three-step process. First, these systems begin with a “seed list” of known URLs; this serves as their starting point a foundational technique in influencer discovery outlined in Social Media Influencers, where data extraction platforms use targeted crawling to identify high-engagement profiles, analyze audience metrics, and build scalable influencer databases optimized for campaign relevance and sponsor alignment. Next, they download and analyze webpage content, parsing HTML to extract important information such as text, metadata, and hyperlinks.
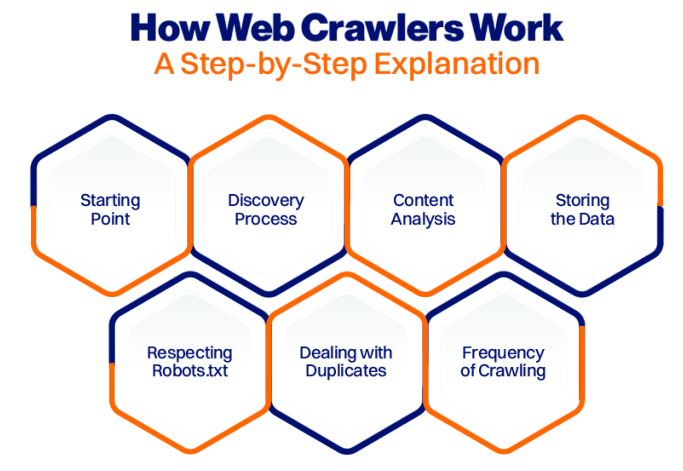
The crawler’s most impressive feature is its ability to follow links continuously. Discovered hyperlinks get added to a queue, which allows for a broad and dynamic exploration of web resources.The Web Crawlers work method aids Web crawlers in precisely and swiftly mapping and indexing the vast online information landscape.
- URL Queue → Fetch Page → Analyze Content → Extract Links → Update Queue → Repeat
Key Functions of a Web Crawler
Web crawlers do more than just collect web pages. Here are their core functions: discovering new URLs, indexing content, following internal and external links, and updating search engine databases technical foundations that support Social Media Marketing Skills to Grow, where marketers learn to align content architecture with crawlability, optimize metadata for visibility, and leverage SEO insights to enhance discoverability across social platforms and search engines alike.
- Discovering new content: Identifying and accessing new or updated pages across the web.
- Extracting data: Pulling out specific elements such as text, images, titles, meta descriptions, and links.
- Following links: Navigating from one page to another via hyperlinks.
- Indexing pages: Sending content to a database or search engine index for future search queries.
- Detecting site structure: Understanding how different pages on a site relate to one another.
- Search Engine Crawlers: Bots like Googlebot, Bingbot, and Baidu Spider index pages for search engines.
- Price Comparison Crawlers: Used by e-commerce platforms to scrape pricing data from competitors.
- Data Crawlers: Extract data from specific websites for academic research, machine learning, or data analysis.
- SEO Crawlers: Tools like Screaming Frog and Ahrefs audit websites for technical SEO.
- Content Monitoring Crawlers: Used to track changes on websites, especially for brand monitoring or legal compliance.
- Crawling: The discovery process.
- Indexing: The storage process.
- Ranking: How search engines decide what order to show pages.
- Optimize title tags and meta descriptions
- Use structured data (Schema.org)
- Maintain a logical site structure
- Build internal links
- Ensure HTTPS security
- Scrapy (Python framework for building custom crawlers)
- BeautifulSoup (Web scraping in Python)
- Octoparse (No-code crawler)
- Screaming Frog (SEO analysis)
- ParseHub (Visual scraper)
- Diffbot (AI-powered web scraping API)
- Google Search API
- Common Crawl (Free datasets of web data)
- SerpAPI (Google Search Results API)
- Apify (Cloud-based crawling and automation platform)
To Explore Digital Marketing in Depth, Check Out Our Comprehensive Digital Marketing Online Training To Gain Insights From Our Experts!
Types of Web Crawlers
Not all crawlers are the same. They vary in purpose and behavior. Here are some common types of Web Crawlers: traditional crawlers for broad indexing, focused crawlers for topic-specific data, vertical crawlers for industry-specific platforms, incremental crawlers for frequent updates, and deep web crawlers for non-indexed content technical distinctions that mirror the strategic divergence in Traditional Marketing vs Digital Marketing, where broad-reach methods like print and broadcast contrast with precision-targeted digital tactics powered by algorithmic discovery and behavioral tracking.

Why Web Crawlers Are Important
Web crawlers are crucial for the internet’s search system. They support basic online interactions that we often overlook. These automated tools help search engines find and index web pages. This allows users to quickly find relevant information and helps website owners attract visitors from platforms like Google and Bing. Web crawlers do more than just basic searches they systematically scan, index, and rank web content, a process thoroughly explored in Digital Marketing Training, where learners master SEO mechanics, crawler behavior, and optimization techniques to boost search visibility and organic traffic. They play an important role in digital strategies by offering valuable insights for market intelligence, data collection, competitive analysis, and trend tracking. By scanning and organizing the vast digital landscape, these tools make sure that information stays accessible, connected, and easy to find. This ultimately helps knowledge flow smoothly across the global internet.
Looking to Digital Marketing Training? Discover the Digital Marketing Expert Masters Program Training Course Available at ACTE Now!
How to Optimize Your Website for Crawling
Optimizing your website for efficient crawling and indexing is essential for successful SEO performance. By submitting an XML sitemap through Google Search Console, you give clear guidance to search engine crawlers about which pages to prioritize a foundational SEO practice explained in What Is Digital Business, where digital-first organizations learn to optimize discoverability, streamline indexing, and ensure that high-value content surfaces in search results through structured data and crawler-friendly architecture. In addition, a well-configured robots.txt file ensures controlled crawler access while keeping content visible. Website speed is also important in this process. Using tools like Google PageSpeed Insights can significantly improve crawling efficiency. Moreover, addressing broken links, ensuring mobile compatibility, and adding canonical tags to prevent duplicate content are key steps in building a strong, crawler-friendly website structure. These technical improvements not only help with search engine indexing but also enhance the overall user experience. This, in turn, boosts your website’s visibility and performance.
Crawling vs. Indexing vs. Ranking
These three terms are often confused but mean very different things an important clarification found in Search Engine Optimization, where distinctions between SEO, SEM (Search Engine Marketing), and PPC (Pay-Per-Click) are clearly defined. SEO focuses on organic visibility through content and technical optimization, SEM encompasses both paid and unpaid strategies to improve search presence, while PPC refers specifically to paid advertising models where businesses pay per click to drive traffic.
Your site must be crawled before it can be indexed, and it must be indexed before it can be ranked.
Preparing for Digital Marketing Job Interviews? Have a Look at Our Blog on Digital Marketing Interview Questions and Answers To Ace Your Interview!
Web Crawlers and SEO
Search engine optimization (SEO) relies heavily on how web crawlers interpret your site.
Search engines allocate a limited “crawl budget” to each site. Large or poorly structured sites might not have all pages crawled.
Ethical Considerations and Limitations
Web crawling is a useful method for collecting data that requires attention to ethical and legal issues. While crawling can offer valuable insights, organizations should prioritize responsible practices by following important guidelines. This means respecting robots.txt protocols, limiting crawl frequency to avoid putting too much strain on servers, and avoiding the collection of sensitive or private information ethical crawling practices increasingly relevant in Digital Marketing Salary, Roles and Responsibilities, where professionals are expected to understand not only campaign strategy and analytics but also technical compliance, data governance, and responsible automation as part of their evolving job scope in a privacy-conscious digital landscape. Additionally, businesses must comply with website terms of service and data privacy laws like GDPR to reduce legal risks. By following these best practices, companies can use web crawling effectively while maintaining integrity, protecting individual privacy, and ensuring responsible digital information gathering.
Web Crawling Tools and APIs
If you’re building your own web crawler or need insights from crawling tools, here are some options:
Popular Tools
APIs and Platforms
Conclusion
Web crawlers are the silent workforce behind search engines and digital data collection. From discovering content and indexing websites to enabling SEO and supporting AI applications, crawlers play a foundational role in today’s internet a technical backbone explored in Digital Marketing Training, where learners master search engine behavior, data indexing, and AI-driven optimization strategies to enhance visibility and performance across digital platforms. Understanding how they work, how to optimize your site for them, and how to use them ethically can provide a significant advantage whether you’re a website owner, SEO expert, developer, or data analyst. As the internet continues to grow and evolve, web crawlers will remain essential in connecting people to the information they need.




