
Last updated on 17th Nov 2021| 6792
We have collected the most commonly asked Greenplum Interview Questions and Answers will assist you to prepare for the Greenplum viva questions and answers that an interviewer might ask you during your interview. There are a lot of opportunities from many reputed companies in the world. According to research, Greenplum has a market share of about 3.25%. So, You still have opportunities to move ahead in your career in the Greenplum certification guide. ACTE offers advanced Greenplum Interview Questions that help you in cracking your interview & acquiring your dream career as a Greenplum Developer. This complete guide of Greenplum interview questions will encourage you to crack your Job interview easily.
1. Define Database Manager (DBA)
Ans:
The person in charge of managing, coordinating, and running a database management system is known as a database administrator (DBA.. A primary duty is to maintain, secure, and take care of the database systems. Authorizing access to the database, capacity planning, installation, and usage monitoring, as well as the procurement and collection of software and hardware resources. Additionally, they play different roles in setup, security, migration, database design, troubleshooting, backup, and data recovery.
2. How to verify the test table sales distribution policy?
Ans:
The distribution data are displayed in the described table sales.
3. Define Types of Database Administrators (DBA)
Ans:
- Administrative DBAs: Their responsibility is to keep the server operating and maintained. They are worried about things like data migration, replication, security, and troubleshooting.
- Data Warehouse DBA: Previously assigned but responsible for combining data from different sources into the data warehouse.
- Cloud DBA: Businesses nowadays prefer to store their work in the cloud. Because it adds a layer of data security and integrity and lowers the possibility of data loss.
- Development DBAs: They create and modify stored procedures, queries, and other systems to satisfy the demands of businesses or organizations. Their programming skills could be better.
- Application DBAs: In particular, they oversee all specifications for interdependent application components.
4. Define the Roles and Duties of a Database Administrator
Ans:
- Decides on hardware: They select affordable gear that best fits the organization’s needs while taking into account factors like cost, performance, and efficiency. The interface that connects end users to the database is hardware.
- Controls data security and integrity: Since data integrity prevents and limits illegal usage, it must be properly verified and maintained. To preserve data integrity, DBAs focus on the relationships within the data.
- Database Accessibility: Permission to access data stored in the database is the exclusive responsibility of the database administrator. Additionally, it verifies who is authorized to alter the content.
- Database design: The external model, logical and physical design, integrity and security control, and external model design are all under the purview of the DBA.
5. What is the number of schemas in a database?
Ans:
User schemas are there in the database. Use” dn” at the psql prompt. A database may contain one or more schemas, but a schema can only be a part of one database. A schema can include an unlimited number of objects.
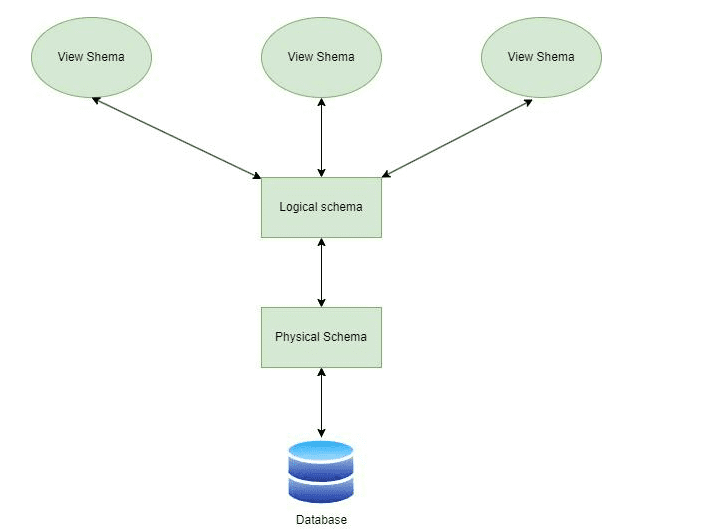
6. How can I measure a table’s dimensions?
Ans:
- Level of Table: <psql> select pg_size_pretty(pg_relation_size(‘schema. table name..; Substitute your search table for the schema—table name.
- Index and Table: enter psql> select pg_size_pretty(pg_total_relation_size(‘schema. table name..; substitute your search table for the schema—table name.
7. How is the Schema size checked?
Ans:
A schema is a group of tables having rows and columns that may be queried independently, much like a database. In MySQL, a schema is a template. They describe an information grouping, its size, and its nature. Database objects like tables, views, and privileges are part of the schemas.
- Schema Level: psql>select schemaname,round(sum(pg_total_relation_size(schemaname||’.’../1024/1024. “Size_MB” from pg_tables where schemaname=’SCHEMANAME’ group by 1;
8. Define GUC.
Ans:
Grand Unified Configuration (GUC. variables are another name for the database parameters that are displayed on the DB Configuration tab. Either use the option or the SQL query catalog to connect to the GPDB database. As an example, gpdb# display <GUC_NAME>; or gpdb# select name,setting from pg_settings where name=’GUC’
9. What distinguishes clustering from mirroring?
Ans:
A Comparison of Mirroring, Replication, and Clustering. While replication permits data dissemination and scalability, mirroring guarantees real-time synchronization and instantaneous failover, while clustering improves fault tolerance and performance. Every strategy includes advantages and disadvantages, enabling firms to meet their needs.
10. How is GP detective run in Greenplum, and what does it define?
Ans:
The detective tool generates a bzip2-compressed tar output file after gathering data from an active Greenplum Database system. When diagnosing Greenplum Database issues or system malfunctions, this output file is helpful.
11. What are the DCA Modules for Greenplum?
Ans:
The GPDB, DIA, and GP HD modules make up the Greenplum DCA.
- GPDB: The Greenplum Database, which is a group of servers, is hosted on these modules. In a DCA, GPDB is always the first module. The first GPDB module includes two extra servers that are referred to as Masters.
- DIA: The loading servers in these modules have a high capacity. Greenplum’s gpfdist and gp load software comes pre-configured on the DIA servers to make data loading into GPDB modules simple.
- GP HD: Equipped with Greenplum’s Hadoop distribution, these modules are prepared for high-volume, high-performance queries on unstructured data.
12. What is DCA Greenplum?
Ans:
A self-contained data warehouse solution, the Greenplum DCA incorporates all of the servers, switches, and database software required to carry out big data analytics. For the analysis of large data sets, the DCA is a turn-key, easily installed data warehouse solution with exceptional query and loading performance. The DCA combines computing, storage, and network components with Hadoop, the Greenplum database, and data-loading software. It is delivered, racked, and ready for instantaneous query execution and data loading.
13.DefineEMC DCA?
Ans:
- An adaptable and modular approach to data analysis is provided by the EMC Data Computing device (DCA., a unified data analytics device. Designed to be a fully integrated appliance as well as a flexible platform, the EMC Data Computing Appliance (DCA.
- The first massively parallel data warehouse available to the public is called Pivotal Greenplum. It expedites data analysis within a single appliance, resulting in reduced integration risks and total cost as well as a quicker time to value. Your company can optimize security, availability, and performance for Greenplum with the EMC DCA—all without the hassles and limitations of proprietary hardware.
14. Why does Greenplum care about ETL?
Ans:
Greenplum is prepared to handle enormous data sets, sometimes reaching petabyte levels, as a data warehouse product of the future. However, Greenplum cannot produce such a range of data on its own. Usually, a large number of users or embedded devices generate data. In an ideal world, Greenplum would get data directly from all data sources. However, this is only feasible if the information is a company’s most valuable asset. Greenplum is just one tool among many that will be utilized to extract value from data assets.
15. What distinguishes gp_dump from pg_dump?
Ans:
| gp_dump | pg_dump |
|---|---|
| Specific to Greenplum Database. | General-purpose utility for PostgreSQL. |
| Distribution-aware backup and restore utility designed for Greenplum Database’s MPP architecture. | Standard PostgreSQL backup and restore utility. |
| Leverages parallel processes to back up and restore data across Greenplum segments efficiently. | Supports parallel dump and restore for individual tables. |
16. What does “start/stop db in admin mode” mean?
Ans:
- Admin mode: When the database is started with the upstart option (-R., it enters restricted mode, allowing only super users to connect to the database.
- Utility mode: When using gpstart -m to initiate utility mode, you can connect to specific segments only.
- For instance, to connect to the controller instance exclusively, enter PGOPTIONS=’-c gp_session_role=utility’ psql.
17. What’s Analyze and the way Frequency ought to I Run This?
Ans:
- Analyze gathers statistics on the information’s tables and stores the results in the system table pg statistic. The question planner then uses these statistics to help confirm the most cost-effective query execution strategies.
- It is a sincere strategy to ANALYZE infrequently or just whenever significant modifications are made to a table’s contents. Accurate data can speed up the question procedure by helping the question set to select the most pertinent question plan. One common tactic is to run VACUUM and ANALYZE once a day during a period of low consumption.
18. Describe the vacuum and how it should run.
Ans:
Storage that deleted tuples occupy is recovered by VACUUM. Tuples that are removed or rendered outdated by an Associate in Nursing update do not appear to be physically separated from their table in a standard GPDB procedure. They remain present on the disk till the end of a vacuum. Consequently, it’s imperative to attempt VACUUM occasionally, especially on regularly updated tables.
19. What distinguishes Greenplum from PostgreSQL?
Ans:
Greenplum manages the system’s parallel processing components Because of its robustness and complexity, while PostgreSQL can handle single processing. Greenplum and PostgreSQL differ from one another in that Greenplum may use append-optimized data storage, while PostgreSQL may not.
20. How would you apply compression and describe the different methods of compression?
Ans:
For append-only tables in the Greenplum Database, there are two kinds of in-database compression available:
- A table as a whole is compressed at the table level.
- A particular column receives the application of column-level compression. Various column-level compression algorithms can be used for various columns.
21. How would you go about compiling data for the database?
Ans:
On big, dispersed Greenplum Database tables, a VACUUM FULL will recover all expired row space. Still, it is an extremely costly operation that can take an inordinately long time to complete. In the event that the free space map does overrun, it might be more expedient to drop the previous table and establish a new one using an established TABLE AS statement. It is not advised to use a vacuum full in the Greenplum Database.
22. What are the advantages of Greenplum?
Ans:
Some benefits of using Greenplum include:
- Scalability: Greenplum’s MPP architecture enables it to scale horizontally by adding more nodes to the cluster.
- High performance: Greenplum is optimized for querying and analyzing large datasets.
- Support for multiple data formats: Greenplum can handle a variety of formats.
23. What kinds of backups are available in the OS?
Ans:
Backup Types
- Full backup: Sending all data to a different place is the most basic and thorough backup technique.
- Incremental backups: They include all the files that have changed since the last backup.Only copies of all files that have changed since the last complete backup are backed up using a differential backup.
24. Define DDL for an SQL table.
Ans:
The part of SQL that adds, modifies and removes database objects is called data definition language, or DDL. Schemas, tables, views, sequences, catalogs, indexes, variables, masks, permissions, and aliases are some examples of these database objects. A schema provides a logical grouping of SQL items.
25. What is gp_toolkit
Ans:
For the system status information, you can query the system catalogs, log files, and operating environment using the administrative schema named gp_toolkit, which Greenplum Database provides. It can use SQL statements to access various views that are contained in the gp_toolkit schema.
26. What are resource queues?
Ans:
A resource queue, which limits the amount of computing resources that can be used concurrently, is a first-in, first-out (FIFO. queue. The utilization of the computer group’s virtual CPUs (vCPUs. and virtual GPUs (vGPUs., which are service-level resources, is restricted by a resource queue.
27. What distinguishes a vacuum from a vacuum full?
Ans:
- Use VACUUM rather than VACUUM FULL unless you need to return space to the OS so that other tables or other components of the system can use it.
- Only tables with a large percentage of their contents erased—that is, tables with largely dead rows—need to use VACUUM FULL.
- There’s only use in using VACUUM FULL if you know for sure that the table won’t ever expand to its previous size or that you desperately need that disk space back for other uses. It is ineffective to utilize it for routine maintenance or table optimization.
28. Which endpoint is used by default for database mirroring?
Ans:
The mirrored endpoints are set up on TCP port 5022 by default. Endpoints of type DATABASE_MIRRORING must be created if none already exist. Every server needs a principal, mirror, and witness server as its endpoint for mirroring.
29. What is mirroring in DB?
Ans:
A database mirror is a complete backup of the database that can be used if the primary database fails. Transactions and changes to the primary database are transferred directly to the mirror and processed immediately, so the mirror is always up-to-date and available as a “hot” standby.
30. What is a mirror array?
Ans:
Using the Mirror Array procedure, you can set every logical drive in the array to RAID 1 or RAID 1+0 and double the number of data disks in the array.
31. How can an invalid segment be recovered?
Ans:
The gprecoverseg tool identifies the segments that require recovery and starts the recovery process.
3.3.x:
- Without the “-F” option, the first files will be compared, the difference will be identified, and only the different files will be synced (provided there are enough files in the data directory; this initial stage may take a while to complete.
- With the “-F” option, the entire data directory will be resynched.
4.0.x:
- The change tracking log will be delivered and applied to the mirror if the “-F” option is not present.
- The entire data directory will be resynched when the “-F” option is used.
32. How can we determine a table’s dimensions?
Ans:
- Level of Table: <psql> select pg_size_pretty(pg_relation_size(‘schema. table name; Substitute your search table for schema—table name.
- Index and Table:enter psql> select pg_size_pretty(pg_total_relation_size(‘schema.tablename’..; substitute your search table for schema.tablename.
33. How is the database size checked?
Ans:
- psql> select pg_size_pretty(pg_database_size(‘DATBASE_NAME’..; to view the size of the particular database
- For instance, gpdb=# pg_size_pretty = select pg_database_size(‘gpdb’..; pg_size_pretty, 24 MB in one row
- psql> select date name,pg_size_pretty(pg_database_size(date name.. from pg_database; to view all database sizes
34. How do you view the Greenplum DB function list that is available?
Ans:
Pdf schema name. function name (both schema name and function name support wildcard characters.
A list of the functions
- Schema | Name | Data type of result | Data types of arguments
- public | test | boolean |
- integer public | test | void |
- public | bugtest | integer | public | test |
35. How can I determine if the Greenplum server is operational?
Ans:
Check Greenplum Status:
- Run the command: gpstate -s
- Verify that the Greenplum segments and master are all in the “up” state.
Connectivity Test:
- Attempt to connect to the Greenplum database using a client tool or command-line interface.
- Example: psql -h <hostname> -p <port> -d <database> -U <username>
Review Logs:
- Check Greenplum logs for any error messages or warnings.
- Common log locations: /data/master/gpseg-1/pg_log/ for master and /data1/primary/gpseg0/pg_log/ for segments.
Query Execution:
- Execute a simple SQL query to check if data can be retrieved.
- Example: SELECT * FROM <table> LIMIT 1;
36. How is a database created?
Ans:
- Choose a Database Management System (DBMS): Select a DBMS such as MySQL, PostgreSQL, or SQLite.
- Install the DBMS: Install the chosen DBMS software on your server or computer.
- Access DBMS Interface: Use a command-line tool or a graphical interface to connect to the DBMS.
- Create a Database: Execute a SQL command like CREATE DATABASE dbname
;to create a new database. - Define Tables and Schema: Specify the structure of the database by creating tables and defining their fields.
- Insert Data: Optionally, insert initial data into the tables using INSERT
37. Define GPG check.
Ans:
GPGcheck refers to the process of verifying signatures using its central database. It can be confident in the security if the signature verification process is successful. GPGcheck asks for signature verification if its value is set to 1; otherwise, it doesn’t. The example of gpgkey RHEL-RPM-GPG-KEY-redhat-releases .
38. How can I remove a standby?
Ans:
- Use the following command in the master solely to remove the standby master host that is currently set from your Greenplum Database system: #gpinitstandby -r
- A standby server is a backup database server that maintains communication with the main production system. The Standby Server can be brought up to replace the primary server with the least amount of data loss in the case of hardware or network problems.
39. How is a standby resynchronized?
Ans:
If your primary and backup master hosts’ data has to be synchronized and you already have a standby master configured, use this option. There won’t be any updates to the Greenplum system catalog tables. # resynchronize using gpinitstandby -n
40. What distinguishes Greenplum from PostgreSQL?
Ans:
With robustness and complexity, Greenplum manages the system’s parallel processing components, while PostgreSQL can handle single processing. Greenplum and PostgreSQL differ from one another in that Greenplum may use append-optimized data storage, while PostgreSQL lacks.

Learn AWS Certified Big Data Specialty Online Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details41. What size are the tools available in Greenplum that need to be restored and backed up?
Ans:
In the case of non-parallel backups:
- Make use of the Postgres utilities (pg_restore, pg_dumpall, and pg_dump for restore..
- The COPY to command is another useful tool for extracting information from info.
Regarding concurrent backups:
- gp_restore is the restore technique, whereas gp_dump and gpcrondump are for backups.
42. How is data kept in Greenplum, desire?
Ans:
- Data is held on the chosen field(s. that are supported and utilized for delivery. The values of the Distribution Key are passed through a Hash Formula once they have a Distribution Key by Hash. T
- he row is then distributed to the appropriate section using a map. Values go to the same section because the formula is meant to be consistent.
- Hash function logical segment list , physical segment list storage When the Greenplum receives data, it is hashed using a hash function according to the field or fields.
43. Which environmental factors are related to Greenplum?
Ans:
The following environmental variables are necessary:
- PATH, MASTER_DATA_DIRECTORY,
- LD_LIBRARY_PATH,
- GPHOME
- PGAPPNAME,
- PGHOST,
- PGUSER,
- PGPASSWORD,
- PGDATABASE,
- PGHOSTADDR,
- PGPASSFILE,
- PGDATESTYLE, PGTZ, PGCLIENTENCODING
44. What has been added to Pivotal Greenplum 5.2.0?
Ans:
These are the new features of Pivotal Greenplum 5.2.0.
- Enhancement of Partitioned Tables for External Tables
- Resource Groups for Utility Enhancement and Partition Elimination Improvement in GPORCA
- Framework for Greenplum Platform Extension (PXF.
- DCA Support Password Check Module for Dell EMC
45. How is gpcheckperf IO/netperf executed?
Ans:
gpcheckperf is a Greenplum Database utility used to evaluate the I/O and network performance of the Greenplum system. Here’s a brief overview of how gpcheckperf with the IO and netperf options is executed:
Command Syntax:
- To check I/O performance: gpcheckperf -i
- To check network performance: gpcheckperf -n
Execute the Command:
- Run the gpcheckperf command with the appropriate options on the Greenplum master host.
IO Test:
- If running I/O tests (
-i), the utility performs sequential and random I/O tests on each segment instance to evaluate disk performance.
Netperf Test:
- If running network tests (
-n), the utility performs network performance tests between segments to assess communication speed.
Results Display:
- The tool displays summary results, including throughput, latency, and other relevant metrics.
Analyze Results:
- Review the generated report to assess the I/O and network performance of the Greenplum system.
46. Describe how to connect to the Greenplum system without being prompted for a password.
Ans:
Assign the values to the environmental variables in Greenplum and use Bash Shell to export the value. The statement below can be entered into the bashrc file located in the user’s $HOME directory. Each time you log into the system, values will be reset.

Get JOB Oriented AWS Certified Big Data Specialty Online Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
47. What is DCA Greenplum?
Ans:
A self-contained data warehouse solution, the Greenplum DCA incorporates all of the servers, switches, and database software required to carry out big data analytics. For the analysis of large data sets, the DCA is a turn-key, easily installed data warehouse solution with exceptional query and loading performance. The DCA combines computing, storage, and network components with Hadoop, the Greenplum database, and data-loading software. It is delivered, racked, and ready for instantaneous query execution and data loading.
48. Define EMC DCA ?
Ans:
An adaptable and modular approach to data analysis is provided by the EMC Data Computing device (DCA., a unified data analytics device. Designed to serve as a fully integrated and modular appliance for Pivotal Greenplum, the world’s first open-source massive parallel data warehouse, the EMC Data Computing Appliance (DCA. is a platform. It expedites data analysis within a single appliance, resulting in reduced integration risks and total cost as well as a quicker time to value. Your company can optimize security, availability, and performance for Greenplum with the EMC DCA—all without the hassles and limitations of proprietary hardware.
49. What does Greenplum Interconnect mean?
Ans:
The networking layer of the Greenplum database is called the interconnect. Processes are started on each segment to handle the task of a query once a user connects to a database and issues one. In addition, because this communication depends on the network architecture, the term “interconnect” also refers to the inter-process communication between the segments. A standard ten gigabit Ethernet change fabric is used for the connectivity.
50. What does gp_toolkit mean?
Ans:
- This database schema has numerous tables, views, and methods to help you administer the Greenplum Database more effectively when it’s up. It was called gp_jetpack in an older 3—x version.
- To obtain system status information, you can query the system catalogs, log files, and operating environment using the administrative schema named gp_toolkit, which Greenplum Database provides. You can use SQL statements to access various views that are contained in the gp_toolkit schema.
51. Describe the Greenplum segment.
Ans:
In the Greenplum system, database instances are referred to as segments. Segment performs query processing and data storage. Each segment in Greenplum distributed systems holds a different subset of the data.
52. What distinguishes gp_dump from pg_dump?
Ans:
- pg_dump is a non-parallel backup tool that requires a large file system because it creates backups on the controller node alone.
- gp_dump: A tool for parallel backups. A backup of the master and segment file systems will be made.
53. Why does Greenplum care about ETL?
Ans:
Greenplum is prepared to handle enormous data sets, sometimes reaching petabyte levels, as a data warehouse product of the future. However, Greenplum cannot produce such a range of data on its own. Usually, a large number of users or embedded devices generate data. In an ideal world, Greenplum would get data directly from all data sources. However, this is only feasible if the information is a company’s most valuable asset. Greenplum is just one tool among many that will be utilized to extract value from data assets. Using an intermediary system to store all the data is one typical solution.
54. What does the term PgAdmin mean?
Ans:
- A free, open-source graphical front-end tool for managing PostgreSQL databases is called PgAdmin. One of the most popular uses for this web-based GUI application is PostgreSQL database management.
- It helps with many intricate PostgreSQL and EDB database systems, as well as their management and monitoring. PgAdmin is used to perform operations such as creating, executing, and gaining access to quality testing protocols.
55. Explain what Write-Ahead logging is.
Ans:
- One method used to guarantee the data integrity of PostgreSQL databases is Write-Ahead Logging. It supports preserving the database’s dependability and robustness.
- Write-ahead logging is a technique in which modifications and activities within the database are recorded in a transaction log before the database is updated or modified.
- This feature aids in presenting the database change log in the event of a database crash. Furthermore, it facilitates the user’s ability to pick up where they left off following the crash.
56. Define Multi-version Control?
Ans:
By managing concurrency in PostgreSQL databases, a technique known as Multi-version Concurrency Control, or MVCC, can improve database performance. It prevents the locking of databases. MVCC reduces the delay time that users face while logging into their accounts and comes into action when someone else is accessing the contents of the account.
57. What do you mean by the CTID field in PostgreSQL?
Ans:
- In PostgreSQL, CTIDs serve as unique identifiers for each record within a table. The CTID field enables the precise location of physical rows based on their offset and block positions, facilitating the effective distribution of data across the table. By the CTID fields, users can gain insights into the actual storage positions of rows within the database table.
- Inconsistency occurs when multiple transactions try to access the same piece of information. It takes concurrency control to maintain data consistency.
58. What are the Greenplum databases?
Ans:
Announcing Data Warehousing with the Greenplum Database .The architecture of the Greenplum database. The architecture used by the Greenplum Database is shared-nothing. This indicates that every cluster node or server has a separate operating system (OS., memory, and storage system.
60. Define DAC in the Greenplum database.
Ans:
All of the servers, switches, and database software needed to handle workloads involving data analytics at the enterprise level are integrated within the DCA, a self-contained data warehouse system. The DCA is supplied, racked, and prepared for query execution and data loading right away. The DCA operates the Greenplum Database RDBMS.
61. In what way does the Greenplum database store data?
Ans:
Polymorphic Data StorageTM, which allows for both row- and column-oriented storage inside of databases and includes adjustable compression, was first made available by Greenplum Database. This feature is expanded with the Greenplum Database to enable data to be stored on particular kinds of storage, like SSD media or NAS archive stores.
62. Define gpcc?
Ans:
Database administrators need to use the Greenplum Command Center (GPCC. as one program to oversee and operate Pivotal Greenplum. Either the standby coordinator host or the coordinator host for the Greenplum Database powers the GPCC web server Configuring the port number occurs during installation.
63. In DBMSs, what does disk space management mean?
Ans:
- The system component that manages the allocation and deallocation of pages among the various database files is called the disk space manager.
- Additionally, it reads and writes pages to and from the disk. A database is implemented as a single UNIX file in Minibase.
64.How is pg_hba.conf managed?
Ans:
The controller instance’s pg_hba.conf file manages client login and access to your Greenplum system. For information on adding to or editing the contents of this file, consult the Greenplum Administrator’s Guide.
65. How can a new user be added to the database?
Ans:
- To create users, use the create user tool. To learn more, see create user –help.
- To create users, you can also use SQL instructions in the SQL prompt.
- As an illustration: CREATE A ROLE OR USER
66. What does Analyze mean, and how do you use it?
Ans:
- The system table pg_statistic contains the statistics that ANALYZE gathers regarding the data in the database’s tables. The query planner then uses these statistics to assist in identifying the most effective query execution strategies.
- Running ANALYZE on a regular basis or shortly after making significant modifications to a table’s contents is a good idea. Precise data will aid the query planner in selecting the best query plan, which will accelerate the execution of queries. One popular tactic is to use ANALYZE and VACUUM once a day at a time of day when there is less consumption.
67. How do resource queues work?
Ans:
- Greenplum database workload management is handled using resource queues. Resource queues can be used to prioritize all users and queries.
- The CREATE RESOURCE QUEUE SQL query creates resource queues, which are database objects in English. They can be used to control the maximum memory and CPU consumption allotted to each type of query, as well as the number of active queries that can run concurrently.
68. Describe the gp_toolkit.
Ans:
A database schema called gp_toolkit has numerous tables, views, and methods that help you administer the Greenplum Database more effectively when it’s up. It was called gp_jetpack in 3.x older versions.
69. What does ppgsql mean?
Ans:
- With its extensive feature set, PL/pgSQL offers far more procedural control than SQL, including the usage of loops and other control structures.
- You can invoke functions written in the PL/pgSQL language using SQL statements and triggers.
70. What is the language structure of PL pgSQL?
Ans:
- Code in PL/pgSQL is arranged into code blocks. This kind of coding pattern is called block-organized code.
- The PostgreSQL database’s PL/pgSQL function is created by entering code blocks within a SQL CREATE FUNCTION call.
71. Define An MPP database.
Ans:
- Your primary computer may begin to struggle to handle the sheer volume of complicated data—also known as big data—that it must process in order to generate your analytics results.
- Many businesses think about implementing an MPP database in order to meet this demand for speedier processing and faster outcomes. The MPP System, or massively parallel processing The MPP system uses a shared-nothing architecture to manage several tasks at once.
72. Define Query Optimization.
Ans:
- A cost-based query optimizer is included in Greenplum for large-scale big-data applications. As we discussed before, Greenplum leverages performance to extend analytics in both batch and interactive modes to petabyte sizes without compromising query performance.
- Greenplum can divide the load among its various segments and process a query using all of the system’s resources simultaneously, thanks to the cost-based query optimizer.
73. Describe Data Storage using Polymorphism
Ans:
Greenplum’s polymorphic data storage allows you to freely execute and compress files within it at any moment, and you can configure your table and partition storage as you see fit. Choose between column-oriented or row-oriented data when creating a table in Greenplum, giving you control over the orientation. Generally speaking, row orientation works better for quick scans or lookups, whereas column orientation works better for thorough scans.
75. Pivotal Greenplum – Version Commercial?
Ans:
The open-source database, which is available in a commercial version to assist with Greenplum deployment and management both on-premise and in the cloud, was created by Pivotal Greenplum, which is now known as VMware Tanzu. Pivotal Greenplum has various benefits, including the capacity to safeguard data integrity, optimize availability, and manage streaming and cloud data with simplicity.
76. What is VMware Greenplum?
Ans:
- Driven by the open-source Greenplum Database, VMware Tanzu Greenplum is a fully functional Massively Parallel Processing .
- Data Warehouse platform that is available for purchase. It offers quick and effective analytics on petabyte-scale data volumes.
77. How is data stored in Greenplum dba?
Ans:
Polymorphic Data StorageTM, which allows for both row- and column-oriented storage inside of databases and includes adjustable compression, was first made available by Greenplum Database. This feature is expanded with the Greenplum Database to enable data to be stored on particular kinds of storage, like SSD media or NAS archive stores.
78. Which three categories of parameters are there?
Ans:
Particularly, three categories of parameters or parameter modes can be distinguished: input parameters, output parameters, and input/output parameters; these are commonly represented by the symbols in, out, and in out or in out.
79. Define the MPP database.
Ans:
- Massively parallel processing, or MPP, is the abbreviation for a storage structure made to manage various tasks at once by several processing units.
- With a dedicated memory and operating system, every processing unit functions independently in this kind of data warehouse design.
80. What advantages does the MPP database offer?
Ans:
Massive databases handling vast volumes of data operate faster thanks to MPP. Complex searches on big data sets take less time when more servers, or nodes, are added. Additionally, MPP databases have nearly infinite scalability, which enables even faster data access and query results acceleration.
81. What purpose does a trigger serve in a database?
Ans:
Database triggers are procedural codes that are automatically run when specific events occur on a specific table or view within a database. The primary purpose of the trigger is to preserve the accuracy of the data stored in the database.
82. What are Oracle and PostgreSQL’s advantages and disadvantages?
Ans:
Both Oracle and PostgreSQL are reliable database management systems with unique advantages. Open-source PostgreSQL is a well-known RDBMS for its robust security, an abundance of functionality, and ease of use. Conversely, Oracle shines in terms of enhanced security, scalability, customization, performance, and dependability.
83. Which variables are associated with the environment?
Ans:
The maintenance of the island’s rich marine biodiversity is ensured by the presence of supportive environmental factors at optimal levels, including temperature, pH, salinity, transparency, and turbidity.
84. explain how to log in to the Greenplum system without a password.
Ans:
Assign the value in Bash Shell to the environmental variables for Greenplum and export the value.
85. Describe the Greenplum segment.
Ans:
- In the Greenplum system, database instances are referred to as segments.
- Segments do the query processing and store the data.
- Each system in the green plum distributed system contributes a different portion of the data.
86. Describe the Greenplum tools that are available for backup and restore.
Ans:
Typically, gpcrondump—a wrapper for gp_dump and pg_dumpall—is used to automate backups. A Greenplum database’s contents can be backed up as SQL utility files using the gp_dump utility. Later on, the gp_restore tool can be used to restore the database structure and user data.
87. Describe Greenplum interconnect in MPP.
Ans:
The networking layer of the MPP design, known as Greenplum Interconnect, controls communication between the master host network infrastructure and the Greenplum segments.
88. Define OLAP in greenplum?
Ans:
- High concurrency SQL, machine learning, artificial intelligence, reporting, analytics, and analytics are all supported by the open-source, massively parallel database program Greenplum.
- The PostgreSQL open-source database technology and MPP architecture serve as the foundation for the Greenplum Database, which is referred to as big data technology.
89. What separates Snowflake and Greenplum from one another?
Ans:
The 5 Key Dissimilarities Between Greenplum and Snowflake | Hevo
- For the purpose of handling massive analytical Data Warehousing and Business Intelligence workloads, Greenplum is an open-source database built on the PostgreSQL platform.
- A cloud-based data warehouse technology is available for a business license, Snowflake handles both structured and semi-structured data.
90. Describe the Greenplum warehouse.
Ans:
Three main objectives were to be achieved by creating an analytical data warehouse: quick query response, quick data loading, and quick analytics by bringing the analytics closer to the data. It is crucial to understand that Greenplum is not a transactional relational database but rather an analytical data warehouse.




