
Last updated on 04th Jul 2020| 6877
Data modeling involves structuring data in a way that reflects real-world entities and their relationships. It aims to define the blueprint for databases and systems, ensuring data is organized, understandable, and efficient for storage and retrieval. By creating clear data models, organizations can improve data management, enhance decision-making processes, and support various business functions with accurate and consistent information.
1. What is data modeling?
Ans:
data modeling is the process of creating a model for the data to be stored in a database. It involves conceptualizing the rules, relationships, and data objects themselves. data modeling examines the relationships between data objects, and ETL applies those rules, checks the data for irregularities, and puts the data into a data warehouse or data mart. Data must be kept in a data warehouse in order to be accurately modelled.
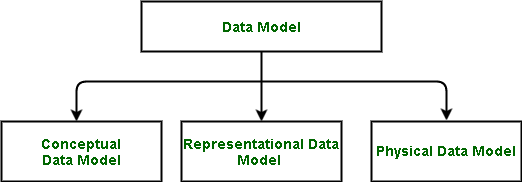
2. Describe the different kinds of data models.
Ans:
- Conceptual: What should be included in the system is specified by the conceptual data model. Data architects and business stakeholders usually create this model.
- Logical: This outlines the best way to implement the system, irrespective of the DBMS. Data architects and business analysts usually develop this model to produce a technical map of rules and data structures.
- Physical: This data model explains the exact DBMS system that will be used to implement the system. This model, which is utilized for the actual database implementation, is usually created by DBAs and developers.
3. Explain the factors to be taken into account when selecting a data modeling strategy.
Ans:
- Project requirements: Examine complexity, future scalability, and data demands (transactions, analytics).
- Database type: Take into account the features and constraints of the selected database management system.
- User requirements: Make sure users who will interact with the data can quickly grasp and comprehend the model.
4. List the different data modeling design schemas.
Ans:
- Entity-Relationship (ER) Schema: Shows entities and their interrelationships.
- Star Schema: Features a central fact table linked to various dimension tables for analysis.
- Snowflake Schema: A normalized variant of the star schema with subdivided dimension tables.
- Galaxy Schema: Integrates multiple star schemas to handle complex analysis.
5. When should Denormalization be taken into account?
Ans:
When getting data from a table that is heavily involved, Denormalization is employed. It’s used in the building of data warehouses. Generally speaking, data normalization is utilized when there are numerous Update, Delete, and Insert actions on the data, and connecting between tables is less expensive. Denormalization, on the other hand, is helpful when databases contain a large number of expensive join queries.
6. Describe the property and dimension.
Ans:
Qualitative data, like product, class, plan, etc., is represented by dimensions. There are descriptive or textual elements in a dimension table. Two attributes of the product dimension table are, for instance, the product name and category. Specific traits or qualities of an object, such as size or colour, are referred to as attributes. Conversely, dimensions are discrete categories of characteristics, just as colour and size are distinct categories of characteristics.
7. Which fact is the least important?
Ans:
- A table is a factless fact. They need a fact-measuring system. Only the dimension keys are contained in it.
- These tables are referred to as “Factless Fact tables.” For instance, a factless fact table contains only the product key and date key, with no measurements included.
- However, you can still obtain the quantity of goods sold over some time. Summaries tables are commonly used to refer to fact tables that have combined facts.
8. What is analytics stored in memory?
Ans:
The practice of caching the database in RAM is referred to as in-memory analytics. In this approach, an application keeps all its data within the computer system’s main memory rather than relying on disk storage. This method significantly speeds up data retrieval and processing by reducing the latency associated with disk access. In-memory analytics utilizes powerful computer clusters to maintain data in memory, enabling rapid query responses and real-time data analysis.
9. How are OLTP and OLAP different from one another?
Ans:
| Feature | OLTP (Online Transaction Processing) | OLAP (Online Analytical Processing) |
|---|---|---|
| Purpose | Manage real-time transactional data | Query and analyze historical data |
| Data Operations | Large number of short transactions | Few but complex queries |
| Query Type | Simple queries (insert, update, delete) | Complex queries and data mining |
| Data Model | Highly normalized | De-normalized (star or snowflake schema) |
| Focus | Speed and data integrity | Data retrieval and analysis |
10. Describe a table.
Ans:
- A table consists of several rows and columns. There is a datatype for each column. Related data is presented tabularly in a table.
- A table is a type of data structure used in computer programming that is intended to arrange data precisely as it would be on paper. Computer-related tables come in a variety of forms and function differently.
- The kind of data being assembled determines which type of table is utilized, as well as what kind of analysis is required.
11. What kind of column is it?
Ans:
- A vertical data arrangement with linked information is called a column or field. A group of cells arranged vertically in a table is called a column.
- A field, like the received field, is an element where a single piece of information is maintained.
- A table’s columns typically hold the values of a single field.
- However, by utilizing a Formula or Combination field, you can display many fields in a column.
12. What is data sparsity?
Ans:
Data sparsity refers to the condition where a substantial portion of data in an entity or dimension of a model is either missing or set to zero. This occurs when many cells within a database table remain empty or unfilled. Essentially, data sparsity indicates that most of the data points are absent or non-existent, leading to a sparse representation of the dataset. This can affect the quality and usability of the data, impacting analyses and decision-making processes.
13. What is the primary composite key?
Ans:
When more than one table column is used in the primary key, the situation is referred to as a composite primary key. A composite primary key involves combining two or more columns to create a unique identifier for a table, ensuring the uniqueness of each row based on the combined values of these columns. This is particularly useful in scenarios where a single column is not sufficient to uniquely identify a record.
14. What is the main access point?
Ans:
- A column, or set of columns, known as the primary key, gives each table row its unique identity.
- The primary key’s value cannot be null.
- There must be one primary key in each table. Known by another name, a primary keyword or critical key is in another table, creating a connection between the two.
15. Describe metadata.
Ans:
- Data about data is described via metadata. It displays the kind of data that is genuinely kept in the database system.
- Sorting or locating particular documents is made easier for the user by metadata, which facilitates data retrieval and manipulation.
- The following are a few instances of basic metadata: author, creation and modification dates, and file size.
- Unstructured data, including pictures, videos, spreadsheets, web pages, etc., can also be represented by metadata.
16. What is a data mart?
Ans:
A data mart is a streamlined form of a data warehouse created for a particular department, group, or user base inside an organization, like marketing, sales, finance, or human resources. It is a mechanism for storing data that has details unique to A business unit within an organization. It contains a limited and chosen portion of the data that the business keeps on file in a more extensive storage system.
17. Describe OLTP.
Ans:
Online handling of transactions OLTP, also abbreviated as a three-tier architecture that facilitates transaction-oriented applications. An organization or company’s daily operations are managed via OLTP. Online transaction processing, or OLTP, is a kind of data processing that includes carrying out several simultaneous operations, such as text messaging, order entry, online banking, shopping, and order input.
18. What OLTP system examples are there?
Ans:
OLTP system examples are:
- Transmitting a text message
- Put a book in your shopping basket.
- Booking airline tickets online
- Online money exchange
- Order submission
19. What is the constraint on checks?
Ans:
- Constraints on checks are used to confirm a column’s range of values.
- The CHECK constraint limits the value range that can be entered into a column. A column will only accept specific values if a CHECK constraint is defined for it.
- A table’s CHECK constraint might restrict values in particular columns according to values in other columns within the row.
20. What are the various forms of normalization?
Ans:
Boyce-Codd’s fourth, fifth, and first standard forms, as well as the second, third, and fourth standard forms, are the several types of normalizations. The process of organizing data in a database is called normalization. It entails building tables and figuring out how those tables relate to one another using rules that were both to safeguard the information and increase the database’s flexibility by getting rid of redundant information and inconsistent dependencies.
21. What is data engineering that is forward?
Ans:
The technical phrase for the process of automatically converting a logical model into a physical implement is “forward engineering.” It is the process of taking a physical model and turning it into a database schema. When physical modifications are made to the data model, including adding, deleting, or altering fields, entities, indexes, physical names, and relationships, forward engineering allows the data model and database to be in sync.
22. What is PDAP?
Ans:
- It’s a data cube that holds summary data. It facilitates rapid data analysis for the user. The manner in which the data in PDAP is kept makes reporting simple.
- Persistent dentoalveolar pain condition is one type of nonodontogenic toothache (PDAP).
- In the absence of clinical and radiographic evidence of dental pathology or other pertinent hard or soft tissue pathology, it has been characterized as tooth pain or discomfort in the location where a tooth once stood.
23. Describe the database design of the snowflake schema.
Ans:
- A fact table and a dimension table arranged together is called a snowflake schema.
- Both tables are typically divided into additional dimension tables. A logical table structure in a multidimensional database that produces an entity relationship diagram that resembles a snowflake form is known as a snowflake schema or snowflake model in computing.
- Centralized fact tables that are coupled to several dimensions serve as the representation of the snowflake schema.
24. Describe the analysis service.
Ans:
The analysis service delivers a unified view of data for OLAP or data mining purposes, enabling comprehensive business insights. It leverages VertiPaq, a robust analytical data engine, to enhance corporate analytics and support decision-making processes. This service provides enterprise-grade semantic data models, which can be utilized in client applications such as Excel and Power BI. It also supports corporate reporting needs by offering detailed and reliable data models.
25. What is an algorithm for sequence clustering?
Ans:
- Sequences of data with events and paths that are related to one another are gathered by the sequence clustering technique.
- Updating the means one sample at a time instead of all at once is another technique to alter the k-means process.
- This approach is especially appealing when instances are obtained gradually, allowing for a more controlled and efficient process.
26. What do continuous and discrete data mean?
Ans:
Discrete information is limited or specified data, such as phone numbers and gender. Data that is organized and changes consistently is referred to as continuous data—for instance, age. Information with discernible intervals between values is called discrete data. Information that appears in a constant series is called continuous data. Values that are discrete or distinct makeup discrete data. Conversely, continuous data comprises all values falling inside a range.
27. What is the algorithm for time series?
Ans:
A time series algorithm is one technique for forecasting continuous values of data in a table. One worker could, for instance, predict the profit or influence. Using just a known history of target values, a time series is a machine-learning technique that predicts target values. It is an advanced type of regression referred to in the literature as auto-regressive modelling. A series of goal values is the input used in time series analysis.
28. What is intelligence in business?
Ans:
- Business intelligence, or BI, is a collection of procedures, frameworks, and tools that transform unstructured data into insightful knowledge that informs successful business decisions.
- It is a collection of tools and services for turning data into knowledge and information that can be put to use.
- Additionally, BI facilitates the monitoring and analysis of key performance indicators (KPIs), helping organizations track progress and make data-driven decisions.
29. Describe a bit-mapped index.
Ans:
A specific kind of database index that uses bitmaps (bit arrays) is called a bitmap index. It must perform bitwise operations to respond to inquiries. In actuality, bitmap indexing is always recommended for systems where data is not updated regularly by numerous concurrent systems—distinct values (a potential primary key column). Like a B-tree index, it is equally efficient.
30. Describe data warehousing in great depth
Ans:
- The process of gathering and organizing data from several sources is called data warehousing. It offers significant insightful business information.
- Data from disparate sources are often connected and analyzed via data warehousing.
- The central component of the BI system is designed for reporting and data analysis.
31. What is the size of the junk?
Ans:
Two or more related cardinalities are combined into one dimension to create the garbage dimension. Usually, it’s flag values or Boolean values. A dimension table that has attributes not found in the fact table or any of the other dimension tables is called a garbage dimension. These characteristics typically take the form of text or different flags, such as unique remarks or straightforward yes/no or true/false indications.
32. What is the data structure?
Ans:
A data scheme is a diagrammatic description of the relationships and structures found in data. The whole relational database’s logical and visual setup is referred to as the database schema. Tables, functions, and relations are common groupings and displays for database items. A schema specifies the relationships between different tables and how data is arranged and stored in a database.
33. Describe the frequency of data gathering.
Ans:
- Gathering Information from Many Sources: This phase involves collecting data from diverse sources, including databases, spreadsheets, and external feeds, to ensure a comprehensive dataset.
- Changing: In this stage, data is transformed and adapted to fit the required format or structure for analysis, which may involve reformatting or aggregating data.
- Purifying: Data cleansing is performed to correct errors, remove duplicates, and ensure consistency and accuracy, improving the quality and reliability of the dataset.
34. What is cardinality in a database?
Ans:
A numerical characteristic of the connection between two entities or entity sets is called cardinality. A database’s cardinality is the arrangement of its constituent elements in rows and tables. It also describes the counting that is done to determine the amount of values in the tables, the links between the tables, and the elements that make up a set.
35. What kinds of cardinal correlations are there?
Ans:
There are various kinds of crucial cardinal relationships, such as:
- Individual Partnerships
- One-to-Many Connections
- Numerous-to-One Connections
- Many-to-Many Connections
36. Describe the four types of Critical Success Factors.
Ans:
- Sector CSFs: These are essential factors specific to an industry, such as regulatory compliance and market demand. They guide organizations in aligning strategies with industry requirements and challenges.
- Methodology CSFs: These involve effective methodologies for project management and operational efficiency. Successful application of these methods enhances organizational performance and results.
- CSFs Related to the Environment: These include external factors like economic conditions and regulatory changes. Adapting to these influences helps organizations navigate external challenges and opportunities.
37. Describe data mining.
Ans:
Utilizing machine learning, statistics, artificial intelligence, and database technology, data mining is a multidisciplinary talent. Finding the unexpected or previously unknown is the key—connections between the information. The practice of looking for patterns and extracting relevant information from a sizable batch of raw data is called data mining. Businesses use data mining software to get additional client information. They can use it to lower expenses, boost revenue, and create more successful marketing plans.
38. What distinguishes the Snowflake model from the Star schema?
Ans:
Denormalization and redundancy are used in a star schema, which enhances read efficiency but may result in dimension tables requiring more storage. Snowflake schema offers a bottom-up method based on data that has been normalized. Users will find it easier to compare data points and drill down for information as a result.
39. What is the relationship that identifies you?
Ans:
In DBMSs, entity relationship identification is used to pinpoint a connection between two entities: a weak entity and a strong entity. An instance of a child entity can be recognized by virtue of its affiliation with a parent company in an identifying relationship between two entities. This implies that the child entity is dependent on the parent entity for its existence and cannot exist without it.
40. What is a relationship that is self-recursive?
Ans:
- A stand-alone column in a table that is linked to the primary key of the same table is the recursive relationship.
- Recursive relationships represent self-referencing or involuting relationships.
- This may sound not very easy, but it just means that there is a parent-child hierarchy—possibly on multiple levels.

Get JOB Data Modeling Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. Describe the modelling of relational data.
Ans:
- A normalized representation of an object in a relational database is called relational data modeling.
- According to the relational paradigm, the logical data structures, such as data tables, views, and indexes, are isolated from the physical storage structures.
- Because of this division, database managers can control the physical storage of data without compromising the logical structure of that data’s accessibility.
42. What are analytics for predictive modelling?
Ans:
Validating or testing a model is a process that would be utilized to forecast the results of testing and validation. It can be applied to statistics, artificial intelligence, and machine learning. A mathematical method called predictive modelling looks for trends in a given collection of input data to forecast future events or outcomes. As a crucial component of predictive analytics, a subset of data analytics that forecasts activity, behaviour, and trends using both historical and present data.
43. What distinguishes a physical data model from a logical data model?
Ans:
- Process workflows can be visually represented in a technically structured way using logical data models.
- Understanding how various business systems interact and integrate with each other, including their dependencies and data flows. This knowledge helps in optimizing processes and improving overall system efficiency.
- A physical data model, on the other hand, explains the arrangement of data in real database tables.
44. What kinds of limits are there?
Ans:
Unique, null values, foreign keys, composite key check constraints, etc., are examples of other types of constraints. SQL allows for several sorts of constraints, including Primary Key, Foreign Key, NOT NULL, UNIQUE, CHECK, DEFAULT, and INDEX restrictions. How is a constraint added to a SQL table? The CREATE TABLE statement can be used to add constraints, or the ALTER TABLE statement can be used to add constraints after the table has already been established.
45. What is a tool for data modeling?
Ans:
Software that aids in creating data flow and the relationships between data is called a data-modelling tool. Borland Together, Altova DatabaseSpy, Casewise, Case Studio 2, and other similar programs are examples of such tools. Software tools for data modeling are programs that assist you in building database architectures using a transparent, visually appealing data model that serves as a road map for how your company will organize and handle data moving ahead in order to meet its goals.
46. What is a hierarchical database management system?
Ans:
- The model data is arranged in a tree-like structure within the hierarchical database, which is kept in an organized hierarchy.
- Data is represented as a relationship between a parent and a child. In a hierarchical database management system, a parent may have several children, but each child only has one parent.
47. What disadvantages does the hierarchical data model have?
Ans:
The following are the hierarchical data model’s shortcomings:
- Since it takes time to adjust to the shifting needs of the business, it must be more adaptable.
- In vertical communication, inter-agency communication, and inter-departmental communication, the structure presents a problem.
- There are issues with hierarchical data models.
48. What drawbacks come with utilizing data modeling?
Ans:
- Its structural independence is lower.
- It might add complexity to the system.
- To create a data model, you need the recorded properties of the physical data.
- Complex application development and administration are used in navigational systems, requiring highly skilled personnel. A complete application must be modified for minor structural adjustments.
49. Describe an index.
Ans:
For a column or set of columns, an index serves as a quick reference to retrieve data efficiently. It’s a numerical value that acts as a gauge or indicator derived from multiple observations. In another context, an index can also refer to the ratio of one dimension of an object, such as an anatomical structure, compared to a reference or alternate reality. This dual usage underscores its utility in both data management and comparative analysis across various fields.
50. What is a foreign key constraint?
Ans:
A foreign key constraint is a rule in a relational database that links a column in one table to the primary key in another, ensuring data integrity between the tables. It enforces that the foreign key value must correspond to an existing primary key value in the related table. This helps prevent the insertion of invalid data and ensures consistency across tables. Foreign keys also allow for cascading actions, such as updates or deletions, to maintain data integrity.
51. What qualities distinguish a logical data model?
Ans:
- Describes the data requirements for a particular project, but depending on the project’s scope, it may integrate with other logical data models.
- The DBMS did not influence them during their design or development.
- Data types with precise lengths and precisions will be assigned to data attributes.
- The model’s normalization procedures are typically applied up until 3NF.
52. What features distinguish a physical data model?
Ans:
- The physical data model lists the information required for a specific project or use case.
- The project’s scope will determine whether it is integrated with other physical data models.
- Relationships between tables in the data model address the cardinality, and A visual modelling language called Modeling Language aids in the visualization and building of new systems by software developers.
- It’s a collection of guidelines designed especially for creating diagrams, not a programming language.
53. Describe the concept of an object-oriented database.
Ans:
An object collection is the foundation of the object-oriented database model. There may be related properties and operations for these items. A database system that supports complex data objects—i.e., objects that resemble those found in object-oriented programming languages (OOP)—is known as an object-oriented database (OOD). Everything is an object when programming is object-oriented (OOP).
54. What is a model of a network?
Ans:
- The model is predicated on hierarchical models.
- It has numerous records since it permits multiple relationships to link records.
- One can create a collection of documents for parents and children. You can conduct sophisticated table associations by assigning each entry to one of several sets.
55. Describe hashing.
Ans:
Utilizing a technique called hashing, one can search across all index values and obtain the needed data. It is helpful in figuring out the precise location of data that is stored on disk without utilizing the index’s structure. The method of hashing involves changing any given key or character string into a different value. This is typically denoted by a key or shorter, fixed-length value that indicates and facilitates finding and using the original string.
56. What are natural or business keys?
Ans:
Fields that uniquely identify an entity, such as client IDs, employee numbers, email addresses, etc., are known as business or natural keys. Etc. Natural keys in data warehouse tables are meaningful variables that uniquely identify entries, like SKU numbers in a product dimension, calendar dates in a time dimension, or social security numbers that uniquely identify specific customers. Natural keys can act as primary keys in specific situations since they are distinctive identifiers.
57. Describe a compound key.
Ans:
- A compound key has more than one field used to represent it.
- Similar to a composite key, a compound key requires the input of two or more fields in order to produce a unique value.
- On the other hand, when two or more primary keys from distinct tables exist inside an entity as foreign keys, a compound key is generated. Together, the foreign keys are utilized to give each record a different identity.
58. What is the first form of a standard?
Ans:
- One attribute of a relation in a relational database management system is the first normal form (1NF). If there are atomic values in each attribute’s domain, then any relation is referred to as being in the first normal form.
- In addition to atomicity, a relation in 1NF ensures that each attribute contains only a single value from its domain, and there are no repeating groups or arrays within any attribute. This structure promotes data integrity and simplifies database design.
59. What distinguishes NoSQL data modeling from SQL data modeling?
Ans:
The key objectives of NoSQL data modeling are managing many data formats, scalability, and flexibility. Schemaless designs and Denormalization are widely utilized because they make it simple to adjust to changing requirements. However, SQL data modeling, which uses certain schemas and normalization, places more emphasis on relational consistency and data integrity. NoSQL models are tailored for specific use cases and include document, key-value, column-family, and graph databases.
60. How do extensive data impact data modeling?
Ans:
Big data creates new challenges in terms of volume, diversity, and velocity, which calls for the application of flexible and scalable data models. Traditional modelling techniques may need to be adapted to handle unstructured and semistructured data. Schema on read and distributed processing are stressed in the efficient management of large data through the use of techniques such as data lakes and NoSQL databases.

Develop Your Skills with Data Modeling Certification Training
Weekday / Weekend BatchesSee Batch Details61. How does the third standard form work?
Ans:
- The second standard form is what it should be.
- It is not dependent on any transitive functions.
- The idea of transitive dependency serves as the foundation for the third standard form. If A, B, and C are relation R attributes, meaning that A → B and B → C, then C depends on A transitively unless B or C is a candidate key or a subset of a candidate key.
62. What is the significance of crucial usage?
Ans:
- Any row of data in a table can be identified using the keys. In a practical setting, a table could hold thousands of records.
- Despite these difficulties, keys guarantee that a table record can be uniquely identified.
- It makes it possible to define and determine the link between tables.
- Assist in enforcing integrity and identity in the partnership.
63. What’s a Stand-In Key?
Ans:
A surrogate key is a synthetic identifier used in databases to uniquely identify records when a natural primary key is absent or inadequate. Unlike natural keys derived from data attributes, surrogate keys are internally generated and have no meaningful context within the table’s data. They ensure uniqueness by being exclusively generated for the purpose of identification. Surrogate keys are typically integers, sequentially or randomly generated, and do not carry any inherent information about the data they identify.
64. Describe the alternate key.
Ans:
A column or set of columns in a database that uniquely identifies each row in a table is referred to as a primary key. A table can potentially have multiple candidate keys, but only one of these can be designated as the primary key. Alternate keys, therefore, encompass any candidate keys within the table that are not selected as the primary key. These alternate keys provide additional options for uniquely identifying rows and are crucial in database design to ensure data integrity and support efficient querying and indexing operations.
65. How is data redundancy dealt with in data modeling?
Ans:
- By organizing data and eliminating redundant information, normalization is a strategy for reducing data redundancy.
- Normal forms (1NF, 2NF, 3NF, etc.) that ensure minimal redundancy and maintain data integrity serve as the procedure’s guidelines.
- Achieving a balance between normalization and performance considerations is crucial since excessive normalization may have an impact on query performance.
66. What function do composite keys serve in data modeling?
Ans:
- Primary keys with two or more columns are called composite keys. They make it possible for records to be individually recognized in circumstances where one column is insufficient.
- For data uniqueness to be guaranteed and complex relationships to be expressed, composite keys are essential. In numerous-to-many partnerships, junction tables commonly use them to maintain referential integrity.
67. What is the fifth standard form’s rule?
Ans:
A table must first be in Fourth Normal Form (4NF) to achieve Fifth Normal Form (5NF). In 5NF, the table can be split into smaller tables without losing data, ensuring data integrity. It eliminates all join dependencies, and any joins performed on these smaller tables must be lossless. 5NF is met when tables are divided into as many subtables as possible to eliminate redundancy. This form focuses on reducing duplication and ensuring that relationships between data are maintained correctly.
68. What does normalcy entail?
Ans:
It’s a method of database design that arranges tables to lessen data reliance and redundancy. It separates more extensive tables into smaller ones. Tables and create relationships between them. By removing redundant information and inconsistent dependencies, normalization entails building tables and the links between them in accordance with standards intended to safeguard the data and increase the flexibility of the database.
69. Describe the attributes of an information management system.
Ans:
- It eliminates redundancy and offers security.
- The self-explanatory nature of the database
- Data abstraction and program insulation
- support for many data views.
- Data sharing and processing transactions for several users
- Entities and the relationships between them can create tables in DBMSs.
70. What role do ER diagrams play in data modeling?
Ans:
- Visual Representation: ER diagrams provide a graphical representation of entities, attributes, and relationships within a database.
- Database Structure Design: They help in designing the logical structure of a database by outlining how entities relate to each other.
- Clarifying Relationships: ER diagrams define and illustrate the cardinality (one-to-one, one-to-many) between entities.
71. How are data warehouses distinct from regular databases in terms of data modeling?
Ans:
The primary objectives of data warehouse architecture, which concentrates on read-optimized schema designs like snowflake and star schemas, are large-scale data analysis and reporting. Schemas that are normalized and optimized for transaction processing (OLTP). They are often employed in conventional databases. In order to facilitate analytical handling (OLAP), Denormalization and efficient query design are given top priority in data modeling for data warehouses.
72. What benefits does a data model offer?
Ans:
Making sure that the data items provided by the functional team are appropriately represented is the primary objective of creating a data model. The physical database should be constructed using the data model, which should have sufficient detail. Table relationships, primary and foreign key relationships, and stored procedures can all be defined using the information found in the data model.
73. What drawbacks does the Data Model have?
Ans:
- Understanding the properties of the physical data storage is necessary to create a data model.
- This navigation system generates sophisticated application development and administration. As a result, familiarity with the biographical reality is necessary.
- Even more minor structural alterations necessitate alterations to the entire application.
- In DBMS, there isn’t a set of languages for manipulating data.
74. Describe the different kinds of fact tables.
Ans:
Three different kinds of fact tables exist:
- Measures that are added to any dimension are called additive measures.
- A measure that cannot be added to any dimension is said to be non-additive.
- A measure that can be added to a few dimensions is called semi-additive.
75. What are some widely used DBMS programs?
Ans:
Entity-relationship (ER) diagrams are visual aids for data modeling that show the entities in a system and their connections. They help in understanding the structure and data requirements of a database. An ER diagram’s components—entities (tables), attributes (columns), and relationships (foreign keys)—assist in database architecture and ensure adherence to business requirements.
76. How do denormalization and normalization impact data modeling?
Ans:
The process of organizing data to minimize duplication and improve data integrity is known as normalization. It involves dividing large tables into smaller ones and determining how to connect them. Denormalization, on the other hand, merges tables to improve read performance and decrease redundancy. Through equating the data modeling is impacted by storage, performance, and data integrity requirements.
77. What is a primary key in data modeling, and why is it important?
Ans:
- The primary key of a database table acts as a unique identifier for each record.
- It ensures that each record can be found and explicitly recognised. Primary keys are required to establish associations between tables and maintain data integrity.
- They are necessary for indexing, which increases query efficiency, and for preventing duplicate records.
78. How do a data mart and a data warehouse vary from one another?
Ans:
- Structured data is kept in a data warehouse. It serves as a central storehouse for preprocessed data used in business intelligence and analytics.
- A data mart is a kind of data warehouse created to satisfy a specific business unit’s needs, such as an organization’s finance, marketing, or sales departments.
79. Describe XMLA.
Ans:
XML for Analysis (XMLA) is a widely used standard for accessing OLAP data, enabling communication between client applications and OLAP servers. SQL Server Analysis Services (SSAS) is a powerful OLAP server and analytics engine designed for data mining and multidimensional analysis. SSAS allows IT specialists to process large volumes of data and divide them into manageable segments for more efficient analysis.
80. Describe the garbage dimension.
Ans:
A garbage dimension is useful for storing data. When data is improperly stored in a schema, it is used. A valuable combination of generally low-cardinality flags and indicators is called a trash dimension. These indicators and flags are shifted into a practical dimensional framework and taken out of the fact table by adding an abstract dimension.
81. Explain the replication of chained data.
Ans:
Chained data replication occurs when a secondary node chooses a target based on ping time or when the closest node is also a secondary. When a secondary member replicates from another secondary member rather than the primary, this is known as chained replication. For instance, this could occur if a secondary chooses its replication target based on the ping time and whether the nearest member is a secondary.
82. Describe what virtual data warehousing is.
Ans:
- The completed data can be viewed collectively using a virtual data warehouse. There are no historical statistics about it.
- It is regarded as a metadata-enabled logical data model.
- Cloud computing and other technologies that store, manage, and analyze massive volumes of data without having to maintain their physical space or equipment are known as virtual data warehousing.
83. Describe the data warehouse snapshot.
Ans:
A snapshot is the entire data visualization at the start of the data extraction process. With the use of data snapshot technology, companies may take a snapshot of their data at a particular moment in time and save it in a static format. It offers a trustworthy and uniform perspective of data, allowing businesses to monitor modifications and conduct data analysis on a historical dataset.
84. What is an extract that is bi-directional?
Ans:
- Directional extract refers to a system’s capacity to extract, clean, and transport data in two directions.
- To facilitate the replication of transactional changes from one system to the other, bidirectional configurations include Extract and Replicat processes on both the source and target systems.
- This ensures real-time synchronization between databases, allowing for seamless data consistency across different platforms. Additionally, bidirectional extraction enhances system resilience by providing backup capabilities in case of failure in one system.
85. What are the differences between conceptual, logical, and physical data models?
Ans:
A conceptual data model, to put it briefly, depicts high-level business entities and interactions without delving into technical details. More details can be found in a logical data model that emphasizes business principles and has associations, attributes, and primary keys. The conceptual model is the source of the physical model. One. Data model. an actual database schema, including tables, columns, indexes, and details about storage.
86. What does data modeling serve as in business intelligence (BI)?
Ans:
data modeling is crucial to business intelligence (BI) since it organizes data to enable efficient querying and reporting. It ensures the quality, consistency, and integrity of data—all essential for accurate analytics. Providing a defined data structure helps BI tools aggregate, slice, and dice data, allowing for intelligent and valuable business decisions.
87. What standard data modeling techniques do experts use?
Ans:
- Standard data modeling tools include ER/Studio, IBM InfoSphere Data Architect, Microsoft Visio, Oracle SQL Developer Data Modeler, and Toad Data Modeler.
- These technologies support the development, maintenance, and visualization of data models and provide tools to ensure appropriate database architecture, such as reverse engineering, model validation, and diagramming.
88. How are many-to-many links managed in data modeling?
Ans:
- They are connecting or associating. How many-to-many relationships are managed is displayed in the table.
- This table contains foreign keys that reference the primary keys of the related tables.
- The junction table divides the many-to-many relationship into two one-to-many relationships to improve query efficiency and data organization.
89. What is the purpose of a surrogate key, and when is it suitable to employ one?
Ans:
A surrogate key is a system-generated identifier, typically numeric or alphanumeric, used as a primary key in databases. Unlike natural keys, which are inherent to business entities and may be complex, flexible, or non-unique, surrogate keys are specifically designed to provide a reliable and unique identifier for each record. They enhance efficiency by simplifying database operations, especially in scenarios where natural keys might change or are not consistently reliable.
90. How can data modeling ensure data security?
Ans:
Data modeling plays a crucial role in ensuring data security by defining user roles, encryption methods, and access controls at the schema level. It involves segregating sensitive data into tables with restricted access, thereby preventing unauthorized users from accessing critical information. By implementing stringent rules and limitations through data modeling, organizations can enforce compliance with regulations such as GDPR and HIPAA, as well as other data privacy standards.




