
Last updated on 31st May 2024| 7533
SQL Joins are used to retrieve data from multiple tables based on a related column between them. By specifying the columns to join on, such as primary and foreign keys, SQL Joins allow for the combination of data from different tables into a single result set. They enable complex queries that fetch relevant information from various tables simultaneously, facilitating comprehensive data analysis and reporting.
1. What is a SQL JOIN?
Ans:
A SQL JOIN is a technique employed to merge rows from two or more tables based on a common column between them. It permits the retrieval of data from multiple tables simultaneously by defining the relationship between them and the criteria for their merging. JOIN operations facilitate the querying and analysis of data across various tables, simplifying complex data retrieval and analysis tasks within relational databases.
2. Explain the different types of SQL JOINs.
Ans:
SQL JOINs include INNER JOIN (returns rows with matching values in both tables), LEFT JOIN (returns all rows from the left table and matching rows from the right table), RIGHT JOIN (returns all rows from the right table and matching rows from the left table), FULL JOIN (returns rows when there is a match in either table), and CROSS JOIN (returns the Cartesian product of the sets of rows from the joined tables).
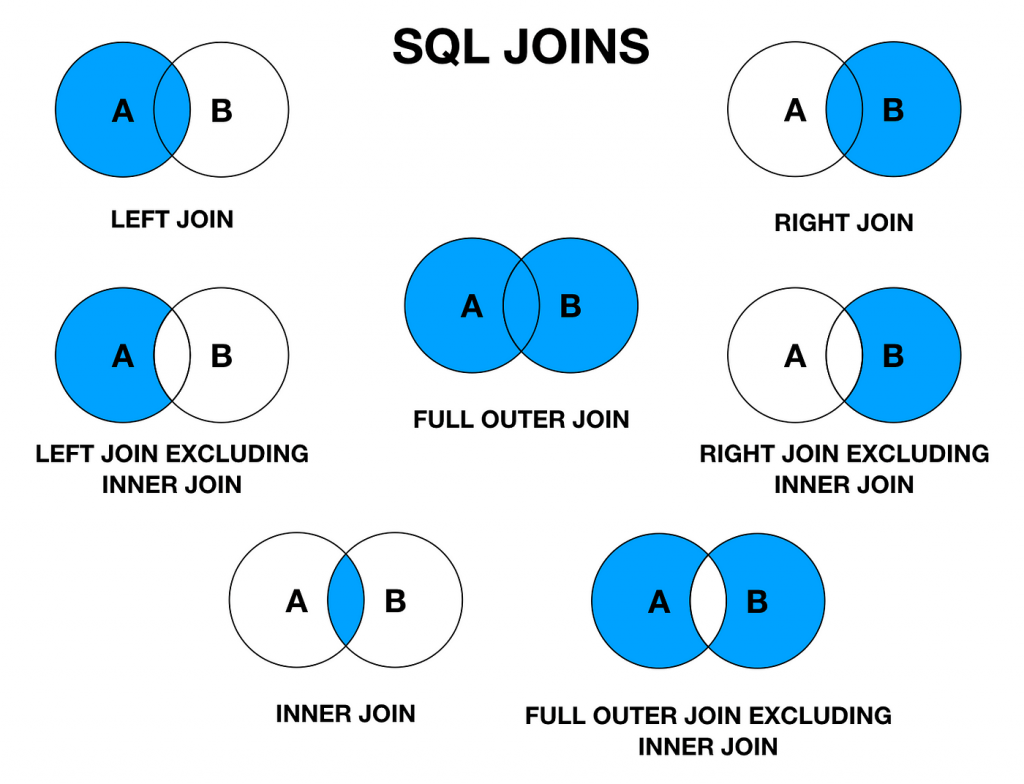
3. What is an INNER JOIN?
Ans:
- An INNER JOIN in SQL is a join operation that retrieves rows from two tables where there is a match based on a specified condition.
- It combines rows from both tables only if there is a corresponding value in the related columns.
- Rows from either table that do not meet the matching condition are excluded from the result set.
- This join type is typically employed to extract data present in both tables and to discard rows without corresponding entries in the other table.
4. What is a LEFT JOIN (or LEFT OUTER JOIN)?
Ans:
- A LEFT JOIN, or LEFT OUTER JOIN, retrieves all records from the left table and matching records from the right table.
- If no match is found, it returns NULL values for the columns from the right table.
- This type of join ensures that all rows from the left table are included in the result set, regardless of whether there is a matching row in the right table.
5. What is a RIGHT JOIN or (RIGHT OUTER JOIN)?
Ans:
A RIGHT JOIN includes all rows from the right table and the matched rows from the left table. If there are no matches in the left table, NULLs fill the columns from the left table. This join is useful for ensuring all records from the right table are included, even without corresponding matches in the left table. Additionally, RIGHT JOINs are particularly beneficial in scenarios where the focus is on the right table’s data, such as when analyzing the relationships between tables where one table is a complete set of information.
6. What is a FULL JOIN (or FULL OUTER JOIN)?
Ans:
A FULL JOIN, or FULL OUTER JOIN, retrieves all rows from both tables involved in the join operation, regardless of whether there is a match between the columns being joined. It includes rows from both tables even if no corresponding rows exist in the other table, resulting in a combination of matched and unmatched rows from both tables. This type of join ensures that no data is excluded from either table, making it useful for comparing and analyzing data across multiple datasets comprehensively.
7. What is a CROSS JOIN?
Ans:
- A CROSS JOIN in SQL combines each row from one table with every row from another table, resulting in a Cartesian product.
- It generates a result set where the number of rows is the product of the number of rows in each table being joined.
- It does not require any matching conditions like other joins. CROSS JOINs can lead to large result sets if used with tables containing many rows.
8. What is a SELF JOIN?
Ans:
- A SELF JOIN is a SQL operation where a table is joined with itself. It’s useful for querying hierarchical data or comparing rows within the same table.
- It involves referencing the same table twice in the query, typically using aliases to distinguish between the two instances.
- This allows for comparisons or combinations of data within the same table, enabling complex queries without the need for additional tables.
9. What is the difference between INNER JOIN and OUTER JOIN?
Ans:
| Aspect | INNER JOIN | OUTER JOIN |
|---|---|---|
| Matching | Returns rows with matching values in both tables. | Returns all rows from both tables. |
| Unmatched Rows | Discards rows with no matching values. | Includes unmatched rows, filling in NULLs. |
| Result Set | Contains only common records between tables. | Contains all records from both tables. |
| Types | N/A | LEFT, RIGHT, and FULL OUTER JOIN. |
10. How can a simple INNER JOIN query be written?
Ans:
- SELECT employees. Name, departments.department_name
- FROM employees
- INNER JOIN departments ON employees.department_id = departments.department_id;
This query selects employee names and their department names by matching the `department_id` in the `employees` table with the `department_id` in the `departments` table.
11. Give an example of a LEFT JOIN query.
Ans:
An example of a LEFT JOIN query is: `SELECT employees—name, departments.department_name FROM employees LEFT JOIN departments ON employees. department_id = departments. department_id;. This query retrieves the names of all employees along with their department names. If an employee does not belong to any department, the query will return the employee’s name with a NULL for the department name.
12. What is the default type of JOIN when no type is specified in an SQL query?
Ans:
- The default type of JOIN in SQL when not specified is an INNER JOIN.
- This means only the rows with matching values in both tables are included in the result set.
- Other types of joins, such as LEFT JOIN or RIGHT JOIN, require explicit declaration to be used.
- Therefore, if the JOIN type is omitted, an INNER JOIN is assumed by default.
13. What does a JOIN operation do in SQL?
Ans:
- A JOIN operation in SQL combines rows from two or more tables based on a related column between them.
- It allows querying data across multiple tables simultaneously, linking rows with matching values.
- JOINs enable complex data retrieval by merging data from different sources according to specified conditions, such as equality between columns.
14. How can more than two tables be joined in an SQL query?
Ans:
Yes, you can JOIN more than two tables in a SQL query by chaining multiple JOIN operations together. For example: `SELECT employees.name, departments.department_name, projects.project_name FROM employees INNER JOIN departments ON employees.department_id = departments.department_id INNER JOIN projects ON employees.project_id = projects.project_id;` This query joins the employees, departments, and projects tables to retrieve employee names, department names, and project names.
15. Explain the concept of a natural join.
Ans:
- A natural join is a type of JOIN that automatically matches columns between two tables based on column names and data types, combining rows with the same values in the columns that share the same names.
- For example: `SELECT * FROM employees NATURAL JOIN departments;` This query joins the employees and departments tables based on columns with the same names in both tables.
16. How can a FULL JOIN be simulated using UNION?
Ans:
You can simulate a FULL JOIN using UNION by combining the results of a LEFT JOIN and a RIGHT JOIN. For example: `SELECT employees.name, departments.department_name FROM employees LEFT JOIN departments ON employees.department_id = departments.department_id UNION SELECT employees.name, departments.department_name FROM employees RIGHT JOIN departments ON employees.department_id = departments.department_id;` This query retrieves all rows from both tables, including rows with no matches, with NULLs for missing data.
17. When is a CROSS JOIN typically used?
Ans:
- A CROSS JOIN is used to combine each row from one table with every row from another table, resulting in a Cartesian product.
- It’s typically employed when you want to generate all possible combinations of rows from both tables.
- However, it should be used cautiously as it can lead to a large number of rows, potentially impacting performance.
- CROSS JOINs are commonly used in scenarios such as generating test data or when explicit relationships between tables are not defined.
18. What occurs when tables are joined without a condition?
Ans:
- It results in a Cartesian product.
- Each row from the first table combines with every row from the second table.
- The resulting dataset can be significantly larger.
- It may lead to performance issues and incorrect results.
- It’s generally avoided unless intentional for specific use cases.
19. How do NULL values affect JOINs?
Ans:
NULL values affect JOINs by potentially excluding rows in INNER JOINs, as INNER JOINs only return rows with matching values in both tables. In OUTER JOINs (LEFT, RIGHT, FULL), NULL values appear in columns from the table that do not have matching rows, ensuring all rows from one or both tables are included, even if there is no match. Furthermore, handling NULL values may require specific functions or conditions, such as using COALESCE or IS NULL, to manage data effectively.
20. How can a JOIN be performed on multiple columns?
Ans:
Yes, you can perform a JOIN on multiple columns by specifying multiple conditions in the ON clause. For example: `SELECT * FROM table1 INNER JOIN table2 ON table1.column1 = table2.column1 AND table1.column2 = table2.column2;` This query joins table1 and table2 where both column1 and column2 match in both tables, allowing for more complex and specific data relationships to be queried.
21. What is an equi-join?
Ans:
An equi-join is a type of SQL join that combines tables based on equality between specified columns using the equality operator (`=`). For example, in the query `SELECT employees.name, departments.department_name FROM employees INNER JOIN departments ON employees.department_id = departments.department_id;`, the `employees` and `departments` tables are joined where the `department_id` values match.
22. What is a non-equi join? Provide an example.
Ans:
A non-equi join is a type of join that uses conditions other than equality to combine rows from two tables, often employing operators such as `<, “>,` `<=,` `>=,` or `!=`. For instance, the query `SELECT employees.name, salaries. Salary FROM employees INNER JOIN salaries ON employees.experience_level > salaries.min_experience_level;` joins the `employees` and `salaries` tables where the `experience_level` of employees exceeds the `min_experience_level` in the salaries table.
23. Explain how LEFT JOIN can be used to find unmatched records.
Ans:
- A LEFT JOIN can be utilized to find records in the left table that do not have matching records in the right table by checking for NULL values in the columns from the right table.
- For example, the query `SELECT employees.name FROM employees LEFT JOIN departments ON employees.department_id = departments.department_id WHERE departments.department_id IS NULL;` fetches the names of employees who are not assigned to any department.
24. What is the difference between USING and ON in JOINs?
Ans:
- The `USING` clause simplifies join conditions when both tables share a column with the same name.
- The `ON` clause is more flexible and allows for complex conditions, including joins on columns with different names.
- For example, they are using `ON` in `SELECT employees—name, departments.department_name FROM employees INNER JOIN departments ON employees.department_id = departments.department_id;` specifies the join condition explicitly.
- In contrast, they are using `USING` in `SELECT employees. name, departments.department_name FROM employees INNER JOIN departments USING (department_id);` assumes the shared column name.
25. What are Cartesian products, and how can they be avoided?
Ans:
A Cartesian product occurs when a join operation combines all rows of one table with all rows of another table without any join condition, resulting in every possible combination of rows. This can be avoided by always specifying a join condition in the `ON` clause. For instance, the query `SELECT * FROM table1 CROSS JOIN table2;` results in a Cartesian product, which can be avoided by using a query such as `SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.id;` that includes a join condition.
26. What is the result of an OUTER JOIN if there are no matching records in the joined table?
Ans:
In an OUTER JOIN, if there are no matching records in the joined table, the result includes the row from the main table with NULLs in place of the missing data from the joined table. For example, in a LEFT JOIN, unmatched rows from the left table still appear with NULL values for columns from the right table. This behavior ensures that all records from the main table are represented, providing a complete view of the data. Similarly, in a RIGHT JOIN, unmatched rows from the right table are included, with NULLs for columns from the left table.
27. How can a JOIN be performed on columns with different data types?
Ans:
Yes, you can perform a JOIN on columns with different data types by casting the columns to the same data type using functions like `CAST` or `CONVERT.` For example, the query `SELECT * FROM table1 INNER JOIN table2 ON CAST(table1.column1 AS VARCHAR) = table2.column2;` joins `table1` and `table2` where `column1` from `table1` (cast to VARCHAR) matches `column2` from `table2`.
28. What is the difference between INNER JOIN and CROSS JOIN?
Ans:
- An INNER JOIN returns rows that have matching values in both tables based on a specified condition.
- A CROSS JOIN, on the other hand, returns the Cartesian product of two tables, combining each row of the first table with all rows of the second table.
- INNER JOIN is used for combining related data, whereas CROSS JOIN is used for generating combinations of rows without a specific relationship.
- INNER JOIN typically has a condition in the `ON` clause, while CROSS JOIN does not. CROSS JOIN can produce significantly more rows than INNER JOIN.
29. Explain how to use a correlated subquery with a JOIN.
Ans:
A correlated subquery is a subquery that refers to columns from the outer query. It can be used with a JOIN for more complex data retrieval. For instance, the query `SELECT employees.name, employees.salary FROM employees INNER JOIN (SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id) AS dept_avg ON employees.department_id = dept_avg.department_id WHERE employees.salary > dept_avg.avg_salary;` joins employees with their department’s average salary and selects employees whose salary is above the average.
30. How can a JOIN be performed on a JSON column?
Ans:
To perform a JOIN on a JSON column, you can use JSON functions to extract and compare the necessary values. For instance, using MySQL, the query `SELECT a.name, b.details FROM table1 a JOIN table2 b ON JSON_EXTRACT(a.json_column, ‘$.id’) = JSON_EXTRACT(b.json_column, ‘$.id’);` extracts the `id` field from the JSON columns and joins the tables based on these extracted values.
31. How can tables be joined based on a range of values?
Ans:
To join tables based on a range of values, you can use non-equi join conditions with operators like `<, “>,` `<=,` `>=,` or `BETWEEN` in the `ON` clause. For example, the query `SELECT employees.name, salary_ranges.range_name FROM employees INNER JOIN salary_ranges ON employees.salary BETWEEN salary_ranges.min_salary AND salary_ranges.max_salary;` joins the `employees` table with the `salary_ranges` table where the `salary` of employees falls within the range defined by `min_salary` and `max_salary.`
32. Explain the difference between LEFT JOIN and LEFT SEMI JOIN.
Ans:
- A LEFT JOIN returns all rows from the left table along with matching rows from the right table and NULLs for non-matching rows from the right table.
- A LEFT SEMI JOIN, on the other hand, returns only the rows from the left table that have a match in the right table.
- The main difference is that LEFT SEMI JOIN does not return columns from the right table; it only checks for the existence of matching rows.
- LEFT SEMI JOIN is often used in analytical queries and can be simulated in SQL using `EXISTS` or `IN.`
33. What are the best practices for writing JOINs in SQL?
Ans:
- Use explicit join syntax (e.g., `INNER JOIN,` `LEFT JOIN`) rather than implicit join syntax (e.g., comma-separated tables in the `FROM` clause).
- Ensure join conditions are clear and precise to avoid Cartesian products.
- Use table aliases to simplify queries and improve readability.
- Filter data in the `WHERE` clause after the join to improve performance.
- Avoid using `SELECT *`; explicitly list columns to improve performance and clarity.
34. Write a query to perform an INNER JOIN on three tables.
Ans:
Here is a query to perform an INNER JOIN on three tables:
- SELECT a.column1, b.column2, c.column3
- FROM table1 a
- INNER JOIN table2 b ON a.common_column = b.common_column
- INNER JOIN table3 c ON b.another_common_column = c.another_common_column
- WHERE a.some_column = ‘some_value’;
This query retrieves the names of employees, their department names, and their project names by joining the three tables on matching columns.
35. Explain the concept of self-join with an example.
Ans:
A self-join is a join where a table is joined with itself. This is useful for comparing rows within the same table. For example, in an “Employees” table, a self-join can help find pairs of employees who work in the same department. The query might look like:
- SELECT A.EmployeeID, A.Name, B.EmployeeID, B.Name
- FROM Employees A, Employees B
- WHERE A.DepartmentID = B.DepartmentID AND A.EmployeeID <> B.EmployeeID;
This matches employees within the same department but excludes matching the same employee.
36. What are the potential pitfalls of using OUTER JOINs?
Ans:
- Performance issues due to the retrieval of large amounts of data, especially with FULL OUTER JOINs.
- Unexpected NULL values in the result set, which can complicate data processing and analysis.
- Increased complexity in query logic and interpretation, mainly when dealing with multiple tables and conditions.
- Potential for misunderstanding the results, especially if the user needs to be more transparent on how unmatched rows are handled.
37. How should JOINs be handled in SQL with multiple relationships between tables?
Ans:
- Use table aliases to distinguish different instances of the same table clearly.
- Specify all necessary join conditions in the `ON` clause to ensure correct matching.
- Consider breaking complex queries into smaller, simpler parts or using subqueries for clarity.
- Use appropriate join types (e.g., INNER JOIN, LEFT JOIN) based on the specific relationships and requirements.
38. Write an SQL query to join two tables and return the top N results.
Ans:
To join two tables and return the top N results, you can use the `LIMIT` clause (MySQL) or `FETCH FIRST N ROWS ONLY` (SQL Server, PostgreSQL). For example, in MySQL:
- SELECT employees. Name, departments.department_name
- FROM employees
- INNER JOIN departments ON employees.department_id = departments.department_id
- ORDER BY employees.name
- LIMIT 10;
This query joins the `employees` and `departments` tables and returns the top 10 results ordered by employee name.
39. How can ambiguous column names be managed in JOINs?
Ans:
To handle ambiguous column names in JOINs, use table aliases or fully qualify the column names with the table name or alias. For example:
- SELECT e.name, d.department_name
- FROM employees e
- INNER JOIN departments d ON e.department_id = d.department_id;
Using aliases `e` and `d` helps distinguish the columns from the `employees` and `departments` tables, respectively.
40. What is the purpose of table aliases in JOINs?
Ans:
The purpose of table aliases in JOINs is to simplify and clarify SQL queries, especially when dealing with multiple tables or self-joins. Aliases provide a shorthand notation for table names, making the query more readable and reducing the chance of errors due to prolonged or complex table names. For example:
- SELECT e.name, d.department_name
- FROM employees e
- INNER JOIN departments d ON e.department_id = d.department_id;
In this query, `e` and `d` are aliases for the `employees` and `departments` tables, respectively, making the query more concise and easier to understand.

Get JOB SQL Joins Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. Explain the difference between JOIN and UNION.
Ans:
- A `JOIN` merges columns from two or more tables based on a related column, creating a result set with columns from each table where the join condition is met.
- Examples include `INNER JOIN,` `LEFT JOIN,` and `RIGHT JOIN.` In contrast, `UNION` combines the result sets of two or more `SELECT` queries into one result set by stacking the rows.
- Each `SELECT` statement in a `UNION` must have the same number of columns with compatible data types.
42. How can a JOIN be used in a subquery? Provide an example.
Ans:
- SELECT e.name, e.department_id
- FROM employees e
- WHERE e.department_id IN (
- SELECT d.department_id
- FROM departments d
- INNER JOIN locations l ON d.location_id = l.location_id
- WHERE l.city = ‘New York’
- );
This query selects employees working in departments located in New York by using a subquery that joins `departments` and `locations.`
43. Explain the difference between an INNER JOIN and a WHERE clause for combining tables.
Ans:
An `INNER JOIN` explicitly combines tables based on a specified condition, returning rows where the condition is met. Using a `WHERE` clause for combining tables involves listing multiple tables in the `FROM` clause and applying the join condition in the `WHERE` clause. However, using `INNER JOIN` is more precise and more explicit. For example:
With `INNER JOIN`:
- SELECT e.name, d.department_name
- FROM employees e
- INNER JOIN departments d ON e.department_id = d.department_id;
With `WHERE` clause:
- SELECT e.name, d.department_name
- FROM employees e, departments d
- WHERE e.department_id = d.department_id;
44. How can PIVOT be used with JOINs in SQL?
Ans:
Using `PIVOT` with `JOINs` can transform rows into columns. For example, in SQL Server:
- SELECT *
- FROM (
- SELECT e.name, d.department_name, e.salary
- FROM employees e
- INNER JOIN departments d ON e.department_id = d.department_id
- ) src
- PIVOT (
- MAX(salary) FOR department_name IN ([HR], [IT], [Sales])
- ) Pvt;
This query joins `employees` and `departments,` and then pivots the data to show maximum salaries per department.
45. How can a LEFT JOIN be performed with multiple conditions?
Ans:
To perform a `LEFT JOIN` with multiple conditions, include all conditions in the `ON` clause using logical operators. For example:
- SELECT e.name, d.department_name
- FROM employees e
- LEFT JOIN departments d ON e.department_id = d.department_id AND e.hire_date > ‘2020-01-01’ AND e.status = ‘active’;
This query joins `employees` and `departments` with additional conditions on `hire_date` and `status.`
46. How can a many-to-many relationship be handled with JOINs?
Ans:
Handling a many-to-many relationship typically involves using an intermediary (junction) table. For example, with `students,` `courses,` and a `student_courses` table to represent the many-to-many relationship:
- SELECT s.name, c.course_name
- FROM students s
- INNER JOIN student_courses sc ON s.student_id = sc.student_id
- INNER JOIN courses c ON sc.course_id = c.course_id;
This query retrieves student names and the courses they are enrolled in by joining the three tables.
47. What are common table expressions (CTEs), and how are they used in JOINs?
Ans:
Common Table Expressions (CTEs) are temporary result sets referenced within a `SELECT,` `INSERT,` `UPDATE,` or `DELETE` statement, defined using the `WITH` keyword.
For example:
- WITH DepartmentCTE AS (
- SELECT department_id, department_name
- FROM departments
- )
- SELECT e.name, d.department_name
- FROM employees e
- INNER JOIN DepartmentCTE d ON e.department_id = d.department_id;
This query uses a CTE to simplify joining `employees` with `departments.`
48. How can a self-join be written with conditions?
Ans:
A self-join joins a table with itself. For example, to find employees and their managers:
- SELECT e1.name AS employee, e2.name AS manager
- FROM employees e1
- LEFT JOIN employees e2 ON e1.manager_id = e2.employee_id
- WHERE e1.department_id = 10;
This query joins the `employees` table with itself to list employees and their managers within a specific department.
49. Explain the impact of JOIN order in execution plans.
Ans:
- The order of `JOINs can impact query performance because the database optimizer determines the sequence of table access based on cost estimates.
- Different join orders can lead to different execution plans, affecting efficiency.
- Optimizers minimize intermediate result set sizes and use indices where available.
- Understanding data distribution and indices helps write more efficient join queries.
50. How can indexing be utilized to speed up JOIN operations?
Ans:
Indexing can significantly speed up `JOIN` operations by enabling the database to locate and retrieve rows quickly. Indexes should be created on columns used in join conditions.
For example:
- CREATE INDEX idx_employee_department_id ON employees(department_id);
- CREATE INDEX idx_department_department_id ON departments(department_id);
These indexes help the database efficiently perform the join operation between `employees` and `departments` by quickly finding matching `department_id` values.
51. What are the advantages and disadvantages of using JOINs compared to subqueries?
Ans:
- JOINs and subqueries each have their benefits and drawbacks. JOINs typically offer greater efficiency and clarity when combining data from multiple tables, as they directly link related tables and can take advantage of indexing to improve performance.
- However, JOINs can become complex and more challenging to manage when dealing with numerous tables or intricate relationships.
- On the other hand, subqueries can simplify complex queries by breaking them down into smaller, more manageable parts, making them helpful in isolating specific data manipulations.
52. Write a query to find records that exist in one table but not in another using JOINs.
Ans:
To find records that exist in one table but not in another using `JOIN`s, you can use a `LEFT JOIN` and check for `NULL` in the second table:
- SELECT a.*
- FROM table a
- LEFT JOIN table b ON a.id = b.id
- WHERE b.id IS NULL;
This query selects records from `table` that do not have a corresponding record in `table.`
53. Explain the use of OUTER APPLY and CROSS APPLY.
Ans:
`OUTER APPLY` and `CROSS APPLY` are used in SQL Server to join a table with a table-valued function. `CROSS APPLY` operates like an `INNER JOIN,` returning only rows where the function returns results, whereas `OUTER APPLY` works like a `LEFT JOIN,` returning all rows from the left table and `Nulls for rows where the function does not return results.
For Example:
- SELECT e.name, f.*
- FROM employees e
- CROSS APPLY dbo.GetEmployeeDetails(e.id) f;
This query joins the `employees` table with the results from the `GetEmployeeDetails` function.
54. How can NULLs be handled in JOIN conditions?
Ans:
Handling `NULLs in join conditions can be managed by ensuring that the columns involved in the join do not contain `NULL` values, or by using functions like `COALESCE` to substitute `NULL` values.
For instance:
- SELECT a.*, b.*
- FROM table a
- LEFT JOIN table b ON COALESCE(a.id, 0) = COALESCE(b.id, 0);
This ensures that `NULL` values are replaced with a default value before performing the join.
55. Explain how window functions can be used with JOINs.
Ans:
Window functions can be used with `JOINs to perform calculations across a set of table rows related to the current row. These functions allow for operations such as ranking, running totals, and moving averages.
For Example:
- SELECT e.name, d.department_name,
- ROW_NUMBER() OVER (PARTITION BY d.department_id ORDER BY e.hire_date) AS row_num
- FROM employees e
- INNER JOIN departments d ON e.department_id = d.department_id;
This query joins `employees` with `departments` and uses the `ROW_NUMBER` window function to assign a row number to each employee within their department, ordered by hire date.
56. How can JOINs be used with aggregate functions?
Ans:
`JOIN`s can be combined with aggregate functions to calculate summary statistics on joined data.
For Example:
- SELECT d.department_name, COUNT(e.id) AS employee_count, AVG(e.salary) AS average_salary
- FROM departments d
- LEFT JOIN employees e ON d.department_id = e.department_id
- GROUP BY d.department_name;
This query joins `departments` with `employees` and calculates the number of employees and the average salary per department.
57. What are composite keys, and how do they affect JOINs?
Ans:
Composite keys consist of two or more columns that together uniquely identify a row in a table. When joining tables using composite keys, all columns of the composite key must be included in the join condition.
For Example:
- SELECT a.*, b.*
- FROM table a
- INNER JOIN table b ON a.key1 = b.key1 AND a.key2 = b.key2;
This ensures the join is based on all parts of the composite key, ensuring accurate matching of rows.
58. Write a query using JOINs to find duplicate records in a table.
Ans:
To find duplicate records, you can use a self-join. For example, to find duplicates based on the `name` column:
- SELECT a.*
- FROM employees a
- INNER JOIN employees b ON a.name = b.name AND a.id <> b.id;
This query finds all records in the `employees` table where the `name` is duplicated.
59. How can hierarchical data be managed with JOINs?
Ans:
Handling hierarchical data with `JOINs involves using self-joins or recursive Common Table Expressions (CTEs). For example, to find all subordinates of a manager using a self-join:
- WITH Hierarchy AS (
- SELECT id, name, manager_id
- FROM employees
- WHERE manager_id IS NULL
- UNION ALL
- SELECT e.id, e.name, e.manager_id
- FROM employees e
- INNER JOIN Hierarchy h ON e.manager_id = h.id
- )
- SELECT * FROM Hierarchy;
This CTE recursively joins employees to build a hierarchy starting from the top-level managers.
60. What is a partitioned join, and when is it used?
Ans:
- A partitioned join involves dividing a large join operation into smaller, more manageable pieces, often based on some partitioning criteria like range or hash.
- This technique is helpful in distributed databases or parallel processing environments to improve performance and manageability.
- For example, you might partition data by year and perform within each partition, reducing the amount of data processed at a time and improving efficiency.

Develop Your Skills with SQL Joins Certification Training
Weekday / Weekend BatchesSee Batch Details61. How can tables from different databases or servers be joined?
Ans:
To join tables from different databases on the same server, you can reference the tables with their respective database names.
For Example:
- SELECT a.*, b.*
- FROM database1.schema1.tableA a
- JOIN database2.schema2.tableB b ON a.id = b.id;
For joining tables from different servers, you need to configure linked servers in SQL Server. Once set up, you can use the `four-part name` convention to join the tables:
- SELECT a.*, b.*
- FROM localDatabase.schema1.tableA a
- JOIN [LinkedServerName].[RemoteDatabase].[schema2].tableB b ON a.id = b.id;
62. What are the implications of using JOINs with large text or BLOB columns?
Ans:
- Using `JOINs with large text or BLOB columns can significantly affect performance due to the increased data size that needs to be transferred and processed.
- Large columns can also reduce the efficiency of indexing and caching, leading to slower query execution times.
- To mitigate these issues, avoid selecting large text or BLOB columns unless necessary, and consider fetching them in a separate query if needed.
63. Describe how to use recursive CTEs with JOINs.
Ans:
Recursive CTEs (Common Table Expressions) are helpful in handling hierarchical data. They can be combined with `JOINs to traverse and query hierarchical relationships.
For Example:
- WITH EmployeeHierarchy AS (
- SELECT id, name, manager_id
- FROM employees
- WHERE manager_id IS NULL
- UNION ALL
- SELECT e.id, e.name, e.manager_id
- FROM employees e
- INNER JOIN EmployeeHierarchy eh ON e.manager_id = eh.id
- )
- SELECT * FROM EmployeeHierarchy;
This query recursively joins the `employees` table to itself to build a hierarchy of employees starting from the top-level managers.
64. How can updates involving JOINed tables be handled?
Ans:
To handle updates involving `JOIN`ed tables, you can use the `UPDATE` statement with a `JOIN.` This allows you to update columns in one table based on conditions in another.
For Example:
- UPDATE a
- SET a.status = ‘Active’
- FROM table a
- INNER JOIN table b ON a.id = b.id
- WHERE b.is_active = 1;
This query updates the `status` column in `tableA` for all rows where there is a matching row in `tableB` with `is_active` set to 1.
65. What is the impact of data normalization on JOIN operations?
Ans:
- Data normalization, which involves organizing data into separate, related tables to reduce redundancy and improve data integrity, typically results in more `JOIN` operations.
- While normalized databases are more efficient in terms of storage and consistency, they often require more complex queries with multiple `JOINs to reassemble related data.
- This can impact performance, making indexing and query optimization crucial in normalized databases.
66. Explain the concept of a star schema and its impact on JOINs.
Ans:
- A star schema is a type of database schema commonly used in data warehousing.
- It consists of a central fact table surrounded by dimension tables.
- The fact table contains measurable data, while dimension tables store descriptive attributes.
- `JOINs in a star schema typically involve linking the fact table to dimension tables using foreign keys.
- This structure simplifies queries and improves performance for analytical queries by minimizing the number of `JOINs and optimizing indexing.
67. How can performance issues in JOINs be debugged?
Ans:
- To debug performance issues in `JOIN`s, you can use several techniques.
- First, examine the execution plan to identify bottlenecks and understand how the query is being processed.
- Look for operations like table scans, which can indicate missing indexes. Use indexing on the join columns to improve performance.
- Also, consider breaking down complex queries into simpler parts to isolate the issue.
68. What are bridge tables, and how are they used in JOINs?
Ans:
Bridge tables, also known as associative or junction tables, are used to handle many-to-many relationships between tables in a relational database. They contain foreign keys that reference the primary keys of the related tables. For example, to manage a many-to-many relationship between `students` and `courses,` you can use a `student_courses` bridge table:
- SELECT s.name, c.course_name
- FROM students s
- JOIN student_courses sc ON s.student_id = sc.student_id
- JOIN courses c ON sc.course_id = c.course_id;
This query joins the `students` table with the `courses` table through the `student_courses` bridge table.
69. Explain the use of EXISTS and NOT EXISTS with JOINs.
Ans:
The `EXISTS` and `NOT EXISTS` clauses are used to check for the existence of rows in a subquery. They can be combined with `JOINs to filter results. For example, to find all employees who have assigned projects:
- SELECT e.*
- FROM employees e
- WHERE EXISTS (
- SELECT 1
- FROM projects p
- WHERE p.employee_id = e.id
- );
To find employees without assigned projects:
- SELECT e.*
- FROM employees e
- WHERE NOT EXIST (
- SELECT 1
- FROM projects p
- WHERE p.employee_id = e.id
- );
These queries use `EXISTS` and `NOT EXISTS` to filter employees based on their presence in the `projects` table.
70. How can tables be joined with composite foreign keys?
Ans:
To join tables with composite foreign keys, you must include all columns of the composite key in the join condition.
For Example:
- SELECT a.*, b.*
- FROM table a
- INNER JOIN table b ON a.key1 = b.key1 AND a.key2 = b.key2;
This ensures the join is based on all parts of the composite key, accurately matching rows from both tables.
71. What are the challenges of performing JOINs on distributed databases?
Ans:
- Performing `JOINs on distributed databases involves several challenges, such as network latency, data partitioning, and maintaining consistency.
- Network latency can slow down `JOIN` operations due to the need for data transfer between different nodes.
- Data partitioning can complicate `JOINs if the required data is spread across multiple nodes, increasing retrieval and combination overhead.
- Ensuring data consistency across distributed systems can be difficult, particularly in environments with eventual consistency, leading to potential issues with stale or inconsistent data being joined.
72. Explain how to perform joins in a NoSQL database that supports SQL-like queries.
Ans:
In NoSQL databases that support SQL-like queries, such as Apache Cassandra with CQL (Cassandra Query Language), direct `JOINs are often not supported due to the schema-less nature and distributed architecture. Instead, data denormalization is used to store related data together and avoid the need for `JOIN`s. However, some NoSQL databases like MongoDB allow limited join-like functionality using the `$lookup` operator in aggregation pipelines.
For Example, in MongoDB:
- db. Orders.aggregate([
- {
- $lookup: {
- from: “customers”,
- local field: “customerId,”
- foreign field: “customerId,”
- as: “customerDetails”
- }
- }
- ]);
This command performs a join between the `orders` and `customers` collections on the `customerId` field.
73. How can dynamic joins be handled based on user input?
Ans:
Handling dynamic joins based on user input involves constructing SQL queries at runtime. This can be achieved using parameterized queries to prevent SQL injection. For example, in Python, you can use string formatting or ORM tools like SQLAlchemy to build queries dynamically:
- def dynamic_join_query(table1, table2, join_condition):
- query = f”
- SELECT *
- FROM {table1}
- JOIN {table2} ON {join_condition}
- return execute_query(query)
This function takes table names and join conditions as inputs and constructs the appropriate SQL query dynamically.
74. What are materialized views, and how do they relate to JOINs?
Ans:
Materialized views are database objects that store the results of a query physically, unlike regular views, which are virtual and computed on demand. They are handy for complex queries involving `JOINs, as they precompute and store the join results, enhancing query performance.
For Instance:
- CREATE MATERIALIZED VIEW mv_sales AS
- SELECT s.*, p.*
- FROM sales s
- JOIN products p ON s.product_id = p.product_id;
This materialized view stores the join result, allowing for faster retrieval without recomputing the join each time the query is executed.
75. Explain how JOINs work in different SQL database systems (e.g., MySQL, PostgreSQL, SQL Server).
Ans:
`JOIN`s work similarly across various SQL database systems, though there are differences in syntax, optimization techniques, and performance. Basic join syntax (`INNER JOIN,` `LEFT JOIN,` etc.) is consistent across MySQL, PostgreSQL, and SQL Server. However, each system has unique optimizations and execution plans. For instance, PostgreSQL offers advanced join types like `LATERAL JOIN,` while SQL Server includes `MERGE JOIN` and `HASH JOIN` optimizations.
76. How can JOIN queries be optimized in large databases?
Ans:
- Optimizing `JOIN` queries in large databases involves several strategies.
- Ensure appropriate indexes are in place on the columns used in join conditions, with composite indexes for multiple columns.
- Regularly analyze and update statistics to help the query optimizer make better decisions.
- Break down complex queries into simpler parts or use Common Table Expressions (CTEs) to simplify logic.
- Avoid selecting unnecessary columns to reduce data transfer. Additionally, consider query rewriting or denormalization strategies to facilitate the join logic.
77. Explain the concept of hash joins.
Ans:
- A hash join is a join operation that uses a hash table to find matching rows quickly. It involves two phases: the build phase and the probe phase.
- In the build phase, the smaller table is scanned and a hash table is created based on the join key.
- In the probe phase, the larger table is scanned, and the hash table is used to find matching rows.
- Hash joins are efficient for large, unsorted datasets and can handle inequality conditions, making them suitable when indexes are not available or when joining large tables.
78. What are merge joins, and when are they used?
Ans:
Merge joins, also known as sort-merge joins, are used when both input tables are sorted on the join key. The algorithm involves scanning both tables simultaneously and merging rows based on the join condition. Merge joins are efficient for sorted data and large datasets because they require only a single pass through each table. They are instrumental when the tables are already sorted or when sorting can be performed efficiently. Merge joins are preferred for large, pre-sorted datasets or when other join algorithms are less efficient.
79. What is a nested loop join?
Ans:
A nested loop join is a join algorithm where, for each row in the outer table, the inner table is scanned to find matching rows. It involves an outer loop that iterates over each row of the first table and an inner loop that iterates over each row of the second table for each row in the outer loop. Nested loop joins are simple and versatile but can be inefficient for large tables due to their O(n*m) complexity. They are typically used for small datasets or when the join condition is highly selective and indexed.
80. How can JOINs with complex conditions be managed?
Ans:
Handling `JOINs with complex conditions involves combining multiple conditions using logical operators such as `AND` and `OR.`
For Example:
- SELECT a.*, b.*
- FROM table a
- JOIN tableB b ON a.id = b.id AND a.status = ‘active’ AND (a.date = b.date OR a.type = b.type);
In this query, the join condition includes multiple criteria using `AND` and `OR.` To ensure clarity and performance, use parentheses to group conditions appropriately and leverage indexes on columns involved in the conditions. Additionally, breaking down complex joins into simpler parts using subqueries or Common Table Expressions (CTEs) can improve readability and maintainability.
81. What are semi-joins and anti-joins?
Ans:
- Semi-joins are SQL operations that return only the rows from the first table where a match is found in the second table.
- Anti-joins, on the other hand, return rows from the first table where no match is found in the second table.
- Both operations are useful for filtering data based on relationships between tables without merging them.
82. Describe a scenario where a CROSS APPLY join is beneficial.
Ans:
- A `CROSS APPLY` join is beneficial when you need to enter each row from the left table with a set of rows produced by a table-valued function or a subquery in the right table.
- This can be useful in scenarios where you want to apply a function or subquery to each row of the left table individually.
83. How can a FULL OUTER JOIN be used to combine data from three tables?
Ans:
- Use a FULL OUTER JOIN between the first two tables.
- Then, use another FULL OUTER JOIN with the third table.
- This ensures all rows from each table are included.
- Rows without matches in any table will have NULL values.
- Resulting in a comprehensive combination of data from all three tables.
84. What are key-preserved tables in joins?
Ans:
Key-preserved tables in joins are those where all the columns from the primary table are preserved in the result set. They maintain the integrity of the primary table’s data, ensuring that all rows from the primary table are retained in the output, even if they don’t match any rows in the joined table. This is crucial for maintaining consistency and accuracy in the joined data.
85. What are the different strategies to perform efficient JOIN operations?
Ans:
Strategies for efficient JOIN operations include:
- Proper indexing.
- Using the appropriate join type.
- Optimizing query execution.
- Partitioning large tables.
- Denormalizing data where appropriate.
- Using subqueries or Common Table Expressions (CTEs) to simplify complex joins.
86. Explain the concept of join elimination.
Ans:
Join elimination is a database optimization technique that aims to reduce the number of join operations required to execute a query. It identifies redundant join operations by analyzing query conditions and eliminates unnecessary joins, thus improving query performance and reducing resource consumption. By eliminating joins that don’t contribute to the final result, join elimination reduces query complexity and enhances execution efficiency.
87. How can the number of joins be minimized for complex queries?
Ans:
- Utilize denormalization techniques to reduce the need for joins.
- Break down complex queries into simpler, smaller ones.
- Use indexed views or materialized views for pre-aggregated data.
- Opt for NoSQL databases that support document-oriented storage.
- Consider data partitioning strategies to distribute queries across smaller datasets.
88. What is join partitioning, and how does it improve performance?
Ans:
Join partitioning is a technique in Apache Camel where large data sets are divided into partitions to be processed concurrently. By distributing the workload across multiple threads or processors, join partitioning reduces processing time and improves overall system performance. It enhances parallelism and resource utilization, allowing for more efficient handling of complex integration scenarios.
89. How can time-based JOINs be handled?
Ans:
Time-based joins in Apache Camel can be handled using the `Aggregate` EIP (Enterprise Integration Pattern). By setting a correlation expression based on time, messages within a specified time window can be aggregated together. This allows synchronization of messages from different sources arriving within the defined time frame, enabling coordinated processing or correlation based on time intervals.
90. What are the best practices for writing SQL JOINs in a data warehousing environment?
Ans:
- Optimize JOIN conditions for performance by utilizing indexed columns.
- Utilize INNER JOINs for precise matches and LEFT/RIGHT JOINs for inclusive results.
- Minimize JOINs by denormalizing data where appropriate to reduce complexity.
- Use JOIN hints judiciously to guide the query optimizer in selecting efficient execution plans.
- Regularly review and fine-tune JOIN queries to maintain optimal performance as data volumes grow.




