
Last updated on 09th Nov 2021| 5746
NoSQL encompasses a wide variety of different database technologies that were developed in response to a rise in the volume of data stored about users, objects, and products. The frequency in which this data is accessed, and performance and processing needs. Relational databases, on the other hand, were not designed to cope with the scale and agility challenges that face modern applications, nor were they built to take advantage of the cheap storage and processing power available today.
1. What is NoSQL?
Ans:
NoSQL databases are the non-relational databases and store a data differently than relational tables. NoSQL databases come in the variety of types based on data model. NoSQL provides a flexible schemas and scales simply with the large amounts of data and high user loads.
2. What are features of NoSQL?
Ans:
- They have a higher scalability.
- They use for distributed computing.
- They are the cost-effective.
- They support to flexible schema.
- They can process both the unstructured and semi-structured data.
- There are no complex relationships, such as ones between tables in RDBMS.
3. What are different types of NoSQL databases?
Ans:
- Key-value Pair Based
- Column-oriented Graph
- Graphs based
- Document-oriented
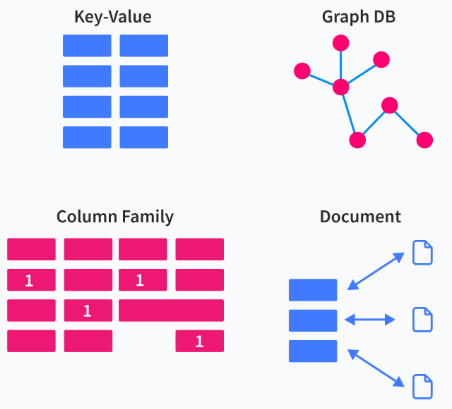
4. When Would Want to Use NoSQL over SQL?
Ans:
The pace of development with the NoSQL databases can be more faster than with SQL database. The structure of more different forms of data is more easily handled and evolved with the NoSQL database. NoSQL databases are better suited to storing and modeling structured, semi-structured, and unstructured data in a one database. The amount of data in applications cannot be served affordably by the SQL database. The scale of traffic and tneed for zero downtime cannot be handled by the SQL. The scalability of NoSQL databases allows the one database to serve both the transactional and analytical workloads from a same database. NoSQL databases often have a superior integration with the real-time streaming technologies.
5. What are Advantages of NoSQL?
Ans:
- Can be used as a Primary or Analytic Data Source
- Big Data Capability
- No Single Point of Failure
- Easy Replication
- No Need for the Separate Caching Layer
- It provides the fast performance and horizontal scalability.
- Can handle the structured, semi-structured, and unstructured data with equal effect
- Object-oriented programming which is simple to use and flexible
- NoSQL databases don’t need dedicated high-performance server
- Support the Key Developer Languages and Platforms
- Simple to implement than using the RDBMS
6. What are Drawbacks of NoSQL?
Ans:
- There is no common, standardized query language as there is in as SQL for relational databases.
- NoSQL databases typically do not enforce a data constraints in the server, leaving to code data constraints in the application. This requires the lot of repetitive work for the developers, and creates the opportunities for dumb bugs.
- NoSQL databases typically do not support the ACID properties. And don’t have transactions. don’t have a consistency enforcement (i.e. constraints). don’t have the atomic changes. And don’t have durability.
- NoSQL databases don’t support the data modeling in traditional sense. There are no normal forms. There are the not logical data models.
7. What does NoSQL Database Interact With Oracle (SQL) Database?
Ans:
NoSQL Database supports the retrieving records through an Oracle Database External Table functions. This made it possible to perform the some queries from the Oracle Database and retrieve a records from the NoSQL Database.
8. When should use NoSQL database instead of SQL Database (relational database)?
Ans:
- A relational database enforces the ACID. So, will have schema-based transaction-oriented data stores. It is proven and suitable for a 99% of real-world applications. And can practically do anything with the relational databases. But, limitations on speed and scaling when it comes to massive high availability of data stores.
- For example, Google and Amazon have the terabytes of data stored in the big data centers. Querying and inserting are not per formant in scenarios because of blocking/schema/transaction nature of the RDBMS.
9. What is DocumentDB?
Ans:
DocumentDB or Document database is completely NoSQL database service that saves the data as schema-free JSON (JavaScript Object Notation) documents.
When working on the some application that needs to be handle data with changing schema or are not sure about data which need to work with and how much data the application needs to be handle. Also not sure about structure of a data. And also need to scalability, low cost, and fast deployment for a data. In all these scenarios consider DocumentDB.
There are more DocumentDB services as below.
- Microsoft Azure Cosmos DB
- Amazon DocumentDB
- MongoDB
10. What is Big SQL?
Ans:
IBM Big SQL is high-performance massively parallel processing (MPP) SQL engine for a Hadoop that makes a querying enterprise data from across an organization an simple and secure experience.
A Big SQL query can access the variety of data sources are including HDFS, RDBMS, NoSQL databases, object stores, and WebHDFS by using single database connection or single query for the best-in-class for analytic capabilities.
11. What does popular SQL Databases and NoSQL Databases?
Ans:
SQL/Relational Databases:
- Oracle
- MySQL
- MS SQL Server
- PostgreSQL
- IBM DB2
NoSQL/Non-Relational Databases:
- A Document-Based NoSQL Databases – A MongoDB, Orient DB, and BaseX
- A Key-Value Databases – DynamoDB, Redis, and Aerospike.
- A Wide Column-Based Databases – Cassandra and HBase.
- A Graph-Based Databases – Neo4j, Amazon Neptune, etc.
12. What is MongoDB?
Ans:
MongoDB is most widely used NoSQL – document-based database. It stores a documents in JSON objects. According to be market survey, more than 3000 companies are using MongoDB in tech stack. The Uber, Google, eBay, Nokia, Coinbase are some of them.
13. When to use MongoDB?
Ans:
In case planning to integrate the hundreds of different data sources, the document-based model of the MongoDB will be a great fit as it will provide the single unified view of the data.
14. What is Cassandra?
Ans:
Apache Cassandra is the open-source NoSQL distributed database system (Wide Column-Based Database) that was initially built by a Facebook (and motivated by Google’s Big Table). It is widely available and scalable. It can handle the petabytes of information and thousands of concurrent requests per second.
15. When to Apache Cassandra?
Ans:
- When use case requires a more writing operations than reading ones
- In situations where need more availability than consistency. For example, can use it for a social network websites but cannot use it for the banking purposes
- require less number of the joins and aggregations in the queries to a database
- Health trackers, weather data, tracking of orders, and time-series data are the some good use cases where can use a Cassandra databases
16. How does column-oriented NoSQL differ from document-oriented?
Ans:
The main difference is document stores (e.g. MongoDB and CouchDB) allow the arbitrarily complex documents, i.e. subdocuments within a subdocuments, lists with documents, etc. whereas a column stores (e.g. Cassandra and HBase) only allow the fixed format, e.g. strict one-level or two-level dictionaries.
17. What do understand by NoSQL in databases?
Ans:
The database management systems which are more scalable and flexible are known as NoSQL databases. These databases allow to store and process unstructured and semi-structured data which is not possible when make use of a Relational database management system. NoSQL can be termed as the solution to all conventional databases which were not able to handle data seamlessly. It also gives the opportunity to companies to store massive amount of structured and unstructured data in a real time. In today’s time, big firms like – Google, Facebook, Amazon, etc. use the NoSQL for providing a cloud-based services for storing data in the real time.
18. How does NoSQL database management system budget memory?
Ans:
The node which manages a data in the NoSQL database store is replication node. It is also main consumer of the memory. The java heap and cache size which are used by a replication node are important factors in terms of the performance. By default, these two things are calculated by the NoSQL in terms of amount of memory available to a storage node. Specification of available memory for the storage node is recommended. The memory will be evenly divided between the all RN’s if the storage node hosts more than a one replication node.
19. Explain Oracle NoSQL database management system.
Ans:
The NoSQL database management system is the distributed key-value database. It is designed so that it can provide the more reliable and scalable data. It can make a data storage available across all configurable set of systems which functions as a storage nodes. In this database system, data is stored as a key-value pairs. This data is written to the particular storage node. These databases provide the mechanism for storage and retrieval of data which is composed in the way other than a tabular method which was used in relational databases.
20. What are pros and cons of graph database under NoSQL databases?
Ans:
Pros of using the graph database:
- These are the tailor-made for the networking applications. A social network is the good example of this.
- They can also be perfect for the object-oriented programming system.
Cons of using the graph database:
- Since degree of interconnection between the nodes is high in graph database, so it is not suitable for a network partitioning.
- Also, graph databases don’t scale out well in the NoSQL databases.
21. List different kinds of NoSQL data stores.
Ans:
Key value store: It is the simple data storage key system which uses the keys to access different values.
Column family store: It is the sparse matrix system. It uses the columns and rows as keys.
Graph store: It is used in case of the relationships-intensive problems.
Document stores: It is used for a storing hierarchical data structures directly in database.
22. What is CAP theorem? How applicable to NoSQL systems?
Ans:
The CAP theorem was proposed by the Eric Brewer in early 2000. In this, three system attributes have discussed within a distributed databases.
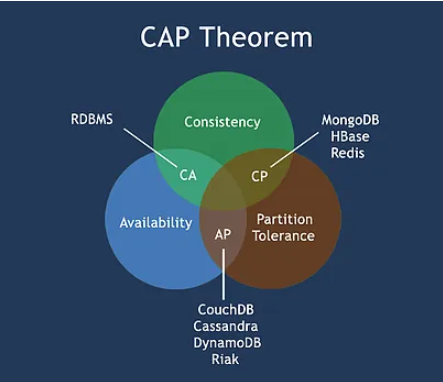
- Consistency: in this, all the nodes see a same data at a same time.
- Availability: it gives us guarantee that there will be the response for every request made to a system about whether it was successful or not.
- Partition tolerance: it is quality of the NoSQL database management system which states that system will work even if part of the system has failed or is not working.
23. What is eventual consistency in NoSQL stores?
Ans:
Eventual consistency in NoSQL means that when all service logic has been executed, the system is left in the consistent state. For achieving the high availability, this is used in the distributed systems. It gives the guarantee that, if new updates are not made to be given data item, then eventually all accesses to item will return a last updated value. In NoSQL, it is provided in terms of the BASE and RDMS are also known as the ACID properties. Present NoSQL databases provide the client applications with guarantee of eventual consistency. Some of the NoSQL databases like- MongoDB and Cassandra are the eventually consistent in some of configurations.
24. What is Polyglot Persistence in NoSQL?
Ans:
While storing a data, it is advisable to choose the multiple data storage systems so that system allows us to store the various data in the future. This is a safer type of data storage system because do not want to risk on a single data storage system. This type of storage is called as the polyglot persistence in NoSQL.
25. Differences between NoSQL and RDBMS.
Ans:
- In terms of a data format, NoSQL does not follow any order for data format. Whereas, RDBMS is a more organized and structured when it comes to the format of its data.
- When it comes to the scalability, NoSQL is more very good and more scalable. Whereas, RDBMS is the average and less scalable than NoSQL.
- For querying of a data, NoSQL is limited in terms of querying because there is a no join clause present in NoSQL. Whereas, querying can be used in RDBMS as it uses a structured query language.
- The difference in storage mechanism of NoSQL and RDBMS is that, NoSQL uses the key value pair, documents, column storage, etc. for storage. Whereas, RDBMS uses the various tables for a storing data and relationships.
26. What is sharding in nosql?
Ans:
Sharding in NOSQL is a process of storing data records across the multiple machines.It is a partitioning pattern in which each shard is held on the separate database server instance, to spread a load and provide the fast data access.
27. How many types of mechanism works in NoSQL?
Ans:
There are the four types of mechanisms:
- Graph database
- Key value calculation
- Document oriented
- Column view presentation
28. When should use NoSQL in place of normal database?
Ans:
If looking for the key-value stores with the massive high-speed performances, can use NoSQL. Because in the relational databases, and use ACID transactions. Once use this kind of transaction, the schema-based process will slow down a database performance.
Suggestive possible situations to use NoSQL are:
- If use the multiple JOIN queries.
- If client needs a high traffic site.
- If using denormalized data.
29. Write down NoSQL’s different features?
Ans:
- It can store the big amount of unstructured, structured, and semi-structured data.
- It is object-oriented programming based, which is the best for the web application.
- It is agile, sprints based, which is the best for a project management.
- It is a cost-effective with the scale-out architecture and efficiency.
30. What is hash table? How does it work in NoSQL?
Ans:
This is like a data structure that provides the associative array of abstract data types. This table uses to function in the complex database. And need to write has code-based queries in this type of a database.
31. What is meaning of document-oriented DB?
Ans:
This is one of the features of NoSQL database. It helps to store a data as schema-free. As result, JavaScript object notation will used, and scalability will be higher. The project will be a developed faster at low cost too. And can use given below DocumentDB:
- MongoDB
- Amazon DocumentDB
- Microsoft Azure CosmosDB
32. How can perform column view data presentation in NoSQL?
Ans:
If looking for highly analytical output,can use this column view data presentation. This NoSQL can store the huge analytical amount of data in columns rather than rows. can also build subgroups by collecting a columns. And don’t need to give any key names to type of database. This is mainly recommended for data belonging to a data science field.
33. How to increase scalability in NoSQL database?
Ans:
All these databases are heavy and need a good server configuration on PC. To increase the scalability, can use a vertical database or horizontal database also. Now on PC, can increase the RAM and SSD hard disk size so that PC will be running faster. This way also, can increase the scalability in NoSQL.
34. What is a Graph database?
Ans:
A graph database is one of the most important of all the databases. It is mainly specific for a storing and navigating data relationships. The concept is entity information, and edges will store a data relationships. This database is used by the banks or social media or new channels etc.
35. Explain CAP theorem in NoSQL.
Ans:
It is the most reliable three guarantees for the database. CAP theorem is an expertise with skills like consistency, availability, and partition tolerance. The nodes will be working in a network seamlessly. As a result, database will work faster.
36. How does NoSQL database control machine price range memory?
Ans:
The replication node that manages NoSQL database save information is a replication node. It is likewise primary client of reminiscence. The java heap and the cache length that replication node can utilize are critical elements in performance phrases. By default, those matters are calculated by way of means of NoSQL in phrases of quantity of memory to be had to storage node. Specification of the to be had reminiscence for the storage node is recommended. The memory can be calmly divided among all of RNs if the garage node hosts the couple of replication node.
37. How is impedance mismatch happening in database?
Ans:
This is a problem statement that happens due to miss-match of database models and programming languages. If want to use a richer memory structure, then have to translated this database to the relational database to store on disk. As a result, impedance mismatch will be occur.
38. What is role of aggregate-oriented database?
Ans:
Actually, this is the collection of data that interacts with the other data as a unit. By using ACID operations and the key-value, all data can be seen as form of an aggregate-oriented database. It helps to manage storage over the cluster. This often reduces the computation.
39. Write down script for NoSQL DB config?
Ans:
If looking forward to building the NoSQL DB connection repeatedly, then need to admin CLI commands. It can be used as a scripted in different ways. For example, can build a file that will store the sequence of commands to run using the any programming language suitable for a particular database.
40. If track data record relations in NoSQL, how will do?
Ans:
- First, can embed all the data in any user object.
- Then, can create a user id credentials.
- By using login id, need to give the comments value with the list of comments.
- Expected data will be found.
41. What is eventual consistency in context of NoSQL?
Ans:
In the database, do use a service logic. Once can execute these service logics, the database system will be left in the constant state. To increase the data availability, can use this concept. It has the distributed database system too.
42. Explain base property of NoSQL database.
Ans:
- Availability of the stored data after even the multiple data search failures.
- In a soft state, all base data will be stored in a ACID model.
- Regularity.
43. Why do use impala in NoSQL database?
Ans:
Once the database administrators handle the big data with the Hadoop system, then this impala provides the parallel processing in database technology. And can also do low latency queries by using the impala. Due to this parallel processing, data fetching time will be more less.
44. How to choose between non-relational and relational databases?
Ans:
NoSQL database is the best for:
- Massive amount, rapidly changing and unstructured data.
- When data is a schema agnostic.
SQL or relational database is the best for:
- When data schema is maintained by the application.
- Relational data that logical structure and requirement can be in identified in advance.
45. What is use of indexes in NoSQL databases?
Ans:
Indexes in NoSQL databases improve the query performance by allowing database to quickly locate and retrieve data. They work similarly to the indexes in SQL databases but are applied to the various data models depending on type of NoSQL database.
46. Explain ACID properties.
Ans:
ACID (Atomicity, Consistency, Isolation, Durability) properties are the guarantees provided by a traditional relational databases. In NoSQL databases, BASE model (Basically Available, Soft state, Eventually consistent) is followed, which prioritizes the high availability and performance over the strong consistency.
47. Differences between horizontal and vertical scaling.
Ans:
| Feature | |||
| Definition | Involves adding more machines or nodes to a database system to distribute the load. | Involves increasing the power or capacity of existing hardware within a single machine. | |
| Granularity | Scales by adding more servers or nodes to the system, often across multiple locations. | Scales by enhancing the resources (CPU, RAM) of a single server or machine. | |
| Flexibility | Offers more flexibility as it can handle increased traffic and data by simply adding more machines. | Limited flexibility, as there’s a practical limit to how much a single machine can be scaled vertically. | |
| Fault Tolerance | Improves fault tolerance since data is distributed across multiple servers; failure of one node has less impact. | Less fault-tolerant, as a failure in a single machine can result in a significant impact. | |
| Examples | Commonly used in NoSQL databases like MongoDB, Cassandra, and HBase. | Frequently seen in traditional relational databases like Oracle, MySQL, and SQL Server. |
48. How does MongoDB achieve high availability?
Ans:
MongoDB achieves the high availability through the replica sets. A replica set consists of the multiple MongoDB servers where one server is a primary, and the others are secondary. If primary fails, one of the secondaries is automatically promoted to a primary role.
49. What is MapReduce? How is it related to NoSQL databases?
Ans:
MapReduce is the programming model and processing technique for a distributed computing, commonly associated with the processing and generating large datasets. Many NoSQL databases, especially those in Hadoop ecosystem, use MapReduce for a parallel data processing.
50. Explain TTL (Time-To-Live) in NoSQL databases.
Ans:
TTL is the feature in some NoSQL databases that allows to set an expiration time for the piece of data. After specified time elapses, the data is automatically deleted. This is useful for the managing cache or temporary data.

Best NoSQL Certification Course with Advanced Concepts from Real Time Experts
Weekday / Weekend BatchesSee Batch Details51. What is denormalization, and why often used in NoSQL databases?
Ans:
Denormalization is a c process of combining multiple tables into the one to reduce the need for a joins and improve read performance. It is often used in NoSQL databases to optimize a read operations, even at expense of increased storage space.
52. Explain concept of column-family store.
Ans:
A column-family store organizes a data into the columns rather than rows, and it is optimized for reading and writing large amounts of a data. Each column family can have different set of columns, allowing for a flexible schema design. Apache Cassandra is example of the column-family store.
53. How does partitioning contribute to scalability of NoSQL databases?
Ans:
Partitioning involves dividing the large dataset into the smaller partitions, and each partition is stored on separate node. This enables the horizontal scaling as new nodes can be added to be handle the increased data volume.
54. How does Cassandra ensure fault tolerance and high availability in distributed environment?\
Ans:
Cassandra achieves the fault tolerance and high availability through its decentralized architecture and peer-to-peer model. Data is a distributed across multiple nodes, and each node in cluster has same role, minimizing the risk of the single point of failure.
55. What is document ID in a document-oriented database?
Ans:
A document ID uniquely identifies the document in a document-oriented database. It is crucial for a quick and efficient retrieval of documents. Using the well-designed document ID can also impact performance of queries.
56. How does Amazon DynamoDB handle scalability and partitioning of data?
Ans:
Amazon DynamDB partitions data across the multiple servers to achieve scalability. Every partition, or shard, can be independently scaled, allowing the DynamoDB to handle the variable workloads efficiently.
57. What is write concern in MongoDB?
Ans:
Write concern in the MongoDB determines a level of acknowledgment of write operation must receive before it is considered successful. A higher write concern level may impact the performance as it requires a more acknowledgment from nodes.
58. How does graph database differ from other types of NoSQL databases?
Ans:
Graph databases are the designed for managing relationships between the entities. They use graph structures to the represent and navigate relationships efficiently. Graph databases are the suitable for scenarios where relationships between the data points are the primary focus, such as social networks or recommendation systems.
59. What is HBase?
Ans:
HBase is the column-family store that is part of Apache Hadoop project. It is designed for a storing and processing large amounts of the sparse data. HBase is commonly used in the scenarios where real-time, random read and write access to the Big Data is required.
60. What is advantage of using NoSQL database in microservices architecture?
Ans:
NoSQL databases are the often preferred in microservices architectures due to flexibility and scalability. They allow every microservice to choose the most suitable data model and database, enabling the independent development and deployment.
61. How does CouchDB achieve fault tolerance and data distribution?
Ans:
CouchDB achieves the fault tolerance through its multi-node architecture and master-master replication model. Every node is independent, and changes are the replicated bidirectionally, providing a redundancy and resilience.
62. Explain secondary indexes in NoSQL databases.
Ans:
Secondary indexes in the NoSQL databases allow for the efficient querying based on the fields other than the primary key. They provide a flexibility in query patterns but may impact the write performance and storage.
63. Difference between wide-column store and column-family store.
Ans:
A wide-column store, like the Apache Cassandra, stores data in tables with the rows and columns, but columns can vary for each row. In contrast, a column-family store, like a HBase, organizes data into the column families, each with the different set of columns.
64. Explain materialized views in NoSQL databases.
Ans:
Materialized views are the precomputed views stored on disk, representing a result of a query. They are used to improve the query performance by avoiding the need to recompute same aggregation or the join operations repeatedly.
65. How does Riak handle conflict resolution in distributed system?
Ans:
Riak uses the vector clock system for conflict resolution. Vector clocks help track the multiple versions of object and determine the causal relationships between them, allowing for the reconciliation in case of conflicts.
66. Explain zone sharding in distributed database.
Ans:
Zone sharding involves the dividing a dataset based on a geographical or logical criteria, with each zone containing a subset of data. It is useful for improving performance and compliance with the data residency requirements in the geographically distributed systems.
67. Explain multi-model databases.
Ans:
Multi-model databases support the multiple data models, allowing the developers to use the most appropriate model for a different parts of their application. ArangoDB is example of multi-model database that supports the document, graph, and key-value models.
68. How does RavenDB achieve high availability and fault tolerance in distributed environment?
Ans:
RavenDB achieves the high availability through its use of distributed architecture with the automatic sharding, replication, and failover mechanisms. Nodes can be added or removed dynamically, ensuring a fault tolerance and scalability.
69. What is compound key in key-value store, and when might use it?
Ans:
A compound key in the key-value store consists of the multiple components. It is useful when need to perform range queries or when natural key is not sufficient for a certain query patterns. The compound key can include the multiple attributes for a more complex data retrieval.
70. Explain eventual consistency and its trade-offs in distributed database.
Ans:
Eventual consistency allows the distributed nodes to reach the consistent state over time. It involves the trade-off between consistency and availability during network partitions. While providing the high availability, eventual consistency may lead to the temporarily divergent states across nodes.

Enroll in NoSQL Certification Training with Advanced Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
71. How does MongoDB support horizontal scaling, and what is role of sharding in this process?
Ans:
MongoDB supports the horizontal scaling through sharding, which involves the dividing a collection into a smaller chunks called shards. Each shard is hosted on the separate server, allowing the MongoDB to distribute data and workload across the multiple machines.
72. Explain MapReduce paradigm in processing data in NoSQL databases.
Ans:
MapReduce is the programming model for processing and generating large datasets in the parallel. It involves the two main steps: the map step, which processes and filters a data, and the reduce step, which aggregates and combines results. Some NoSQL databases, particularly those in Hadoop ecosystem, use MapReduce for a distributed data processing
73. Explain tunable consistency in NoSQL databases.
Ans:
Tunable consistency allows the developers to choose the level of consistency for the each operation. It provides the flexibility, enabling developers to prioritize either strong consistency or high availability based on specific requirements of each use case.
74. How does Amazon Neptune handle graph data?
Ans:
Amazon Neptune is the graph database service that supports both the Property Graph and RDF graph models. It is optimized for astoring and querying highly connected data, making it suitable for the applications like social networking, fraud detection, and knowledge graphs.
75. What is partition keys in NoSQL databases?
Ans:
Partition keys determine how data is distributed across the nodes in a NoSQL database. They impact data retrieval efficiency as the queries that involve the partition key can be directed to the specific node, minimizing a amount of data that needs to be scanned.
76. Explain document embedding in document-oriented databases.
Ans:
Document embedding involves the nesting one document within another in the document-oriented database. This can eliminate need for joins in queries as related data is stored together. However, it also introduces the considerations for a document size and update complexity.
77. Explain schema evolution in NoSQL databases.
Ans:
Schema evolution refers to ability to modify the database schema without requiring the system-wide outage or data migration. NoSQL databases, particularly those with the flexible schemas, support a schema evolution, enabling applications to adapt to changing a data requirements.
78. How does DynamoDB handle hot partition issues?
Ans:
DynamoDB mitigates a hot partition issues by evenly distributing data across partitions. Developers can use the techniques like sharding or randomizing partition keys to prevent the uneven data distribution and hotspots.
79. How does ArangoDB support multi-model capabilities?
Ans:
ArangoDB supports the multiple data models, including document, graph, and key-value models, in single database. This flexibility is advantageous in scenarios where a different parts of an application require the different data models, such as applications with both the transactional and graph-based requirements.
80. Explain JanusGraph database in distributed graph processing.
Ans:
JanusGraph is the distributed graph database that supports storage and processing of highly connected data. It is designed for a scalability and provides features like support for the multiple storage backends, extensibility, and integration with the Apache TinkerPop for graph traversals.
81. How does MongoDB handle write operations and ensure data consistency in sharded cluster?
Ans:
In MongoDB, write operations are the directed to a primary shard, which is responsible for the coordinating writes. The primary shard distributes the write operations to appropriate shards. MongoDB uses the two-phase commit process to ensure a data consistency across sharded cluster.
82. What is a composite key in the context of NoSQL databases?
Ans:
In NoSQL databases, a composite key consists of multiple columns or attributes that uniquely identify a record. It allows for more complex and flexible querying.
83. Explain the concept of replication in NoSQL databases and its purpose.
Ans:
Replication involves maintaining multiple copies of data across different nodes. It enhances fault tolerance, availability, and read performance in NoSQL databases.
84. What is the role of a Bloom filter in a NoSQL database?
Ans:
A Bloom filter is a space-efficient probabilistic data structure used in NoSQL databases for membership testing. It quickly determines whether an element is part of a set.
85. How do NoSQL databases handle unstructured data, and why is this flexibility beneficial?
Ans:
- NoSQL databases accommodate unstructured data due to flexible or dynamic schemas.
- This flexibility is advantageous for handling diverse data types without predefined structures.
86. Explain the concept of Geo-replication in NoSQL databases.
Ans:
Geo-replication involves replicating data across multiple geographical locations to enhance data availability and fault tolerance and reduce latency for users in different regions.
87. Explain the role of denormalization in NoSQL databases and when it’s beneficial.
Ans:
Denormalization involves storing redundant data to improve query performance.
Beneficial in read-heavy scenarios where data retrieval speed is crucial.
88. Discuss the role of full-text search in NoSQL databases.
Ans:
Full-text search in NoSQL databases allows efficient searching and indexing of textual data within documents, enabling powerful search capabilities for applications dealing with large volumes of unstructured text.
89. How does NoSQL handle schema flexibility?
Ans:
NoSQL databases often allow dynamic or flexible schemas, enabling developers to add or modify fields without a predefined schema.
90. Explain the strengths and use cases of a graph-based NoSQL database.
Ans:
Graph databases, like Neo4j, excel in handling relationships between entities, making them suitable for applications with complex graph structures.




