
Last updated on 28th Jun 2020| 1776
What is Amazon Redshift?
- Amazon Redshift is a fully-managed petabyte-scale cloud based data warehouse product designed for large scale data set storage and analysis. It is also used to perform large scale database migrations.
- Redshift’s column-oriented database is designed to connect to SQL-based clients and business intelligence tools, making data available to users in real time.
- Based on PostgreSQL 8, Redshift delivers fast performance and efficient querying that help teams make sound business analyses and decisions.
- The Amazon Redshift is defined explicitly as one of the fully managed, fast, pet byte warehouse services which offer the most cost-effective ways to analyze the data by using the intelligence tools.
- This Amazon Redshift is used to optimize the data sets ranges from the hundred GB’s to the pet byte or else more, which will cost less than the TB cost.
- It is considered as one of the top traditional warehousing solutions available in the market. All this process can help your clients and business to acquire new insights according to their unique needs.
Types of nodes in redshift:
A “cluster” is the core infrastructure component for Redshift, which executes workloads coming from external data apps. There are two key components in a cluster:
- Compute Nodes: A cluster contains at least one “compute node”, to store and process data.
- Leader Node: Clusters with two or more compute nodes also have a “leader node”. The leader coordinates the distribution of workloads across the compute nodes. A cluster only has one leader node.
- In our experience, most companies run multi-cluster environments, also called a “fleet” of clusters. For example, at intermix.io we run a fleet of ten clusters.
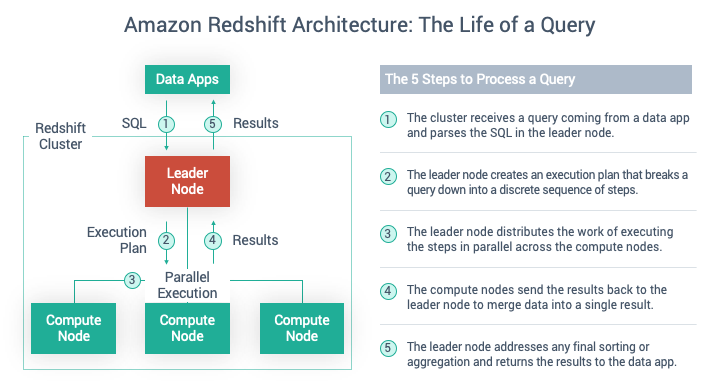
The architecture of Amazon Redshift
- Redshift is meant to work in a Cluster formation. A typical Redshift Cluster has two or more Compute Nodes which are coordinated through a Leader Node.
- All client applications communicate with the cluster only with the Leader Node.
Benefits of Redshift
- As with any cloud computing initiative, the reason to use Amazon Redshift has to do with flexibility. As mentioned previously, companies can choose to create a single node as a starting point, but from there they can create massive clusters containing many nodes for every reporting need they have any for any web application.
- To say the possibilities are endless in terms of database control is not quite true but with cloud computing, it will seem like it.
- Another benefit beyond flexibility in terms of what you can do and the applications you run, there is also an advantage to how it is all managed.
- Your Information Technology staff do not need to manage the cloud computing infrastructure at all, nor do they need to manage the servers, networks, or storage required. Since it is all in the cloud, and it is all part of Amazon Web Services (or AWS), it is all managed remotely and updated automatically.
- One last benefit to consider is that Amazon Redshift provides the framework for a company to go beyond its current limitations. This might be a new application that uses a database in the cloud (and data stored in the cloud), or it might be a new way to analyze company data. Some firms even create brand new divisions and departments based on their newfound capability to understand and process data.
- An example of this might be an automotive manufacturer who has the ability to analyze data in real-time and develop autonomous driving features.
- In the end, the power of Amazon Redshift is only limited by the imagination of the company starting a new initiative, developing a new product, or forming a new division.

Get Amazon RedShift Training with Industry Standard Modules By Experts Trainers
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Amazon Redshift features
- Amazon Redshift extends data warehouse queries to your data lake, with no loading required.
- You can run analytic queries against petabytes of data stored locally in Redshift, and directly against exabytes of data stored in Amazon S3.
Massively parallel
- Amazon Redshift delivers fast query performance on datasets ranging in size from gigabytes to exabytes. Redshift uses columnar storage, data compression, and zone maps to reduce the amount of I/O needed to perform queries.
- It uses a massively parallel processing (MPP) data warehouse architecture to parallelize and distribute SQL operations to take advantage of all available resources.
- The underlying hardware is designed for high performance data processing, using local attached storage to maximize throughput between the CPUs and drives, and a high bandwidth mesh network to maximize throughput between nodes.
Machine learning
- Amazon Redshift uses machine learning to deliver high throughout, irrespective of your workloads or concurrent usage. Redshift utilizes sophisticated algorithms to predict incoming query run times, and assigns them to the optimal queue for the fastest processing.
- For example, queries such as dashboards and reports with high concurrency requirements are routed to an express queue for immediate processing.
- As concurrency increases further, Amazon Redshift predicts when queuing may begin and automatically deploys transient resources with the Concurrency Scaling feature to ensure consistently fast performance, irrespective of variability in demand on the cluster.
Result caching
- Amazon Redshift uses result caching to deliver sub-second response times for repeat queries. Dashboard, visualization, and business intelligence tools that execute repeat queries experience a significant performance boost.
- When a query executes, Redshift searches the cache to see if there is a cached result from a prior run. If a cached result is found and the data has not changed, the cached result is returned immediately instead of re-running the query.
Easy to setup, deploy, & manage Automated provisioning
- Amazon Redshift is simple to set up and operate. You can deploy a new data warehouse with just a few clicks in the AWS Management cConsole, and Redshift automatically provisions the infrastructure for you.
- Most administrative tasks are automated, such as backups and replication, so you can focus on your data, not the administration. When you want control, Redshift provides options to help you make adjustments tuned to your specific workloads. New capabilities are released transparently, eliminating the need to schedule and apply upgrades and patches.
Automated backups
- Amazon Redshift automatically and continuously backs up your data to Amazon S3. Redshift can asynchronously replicate your snapshots to S3 in another region for disaster recovery.
- You can use any system or user snapshot to restore your cluster using the AWS Management Console or the Redshift APIs.
- Your cluster is available as soon as the system metadata has been restored, and you can start running queries while user data is spooled down in the background.
Fault tolerant
- Amazon Redshift has multiple features that enhance the reliability of your data warehouse cluster. Redshift continuously monitors the health of the cluster, and automatically re-replicates data from failed drives and replaces nodes as necessary for fault tolerance.
Flexible querying
- Amazon Redshift gives you the flexibility to execute queries within the console or connect SQL client tools, libraries, or Business Intelligence tools you love.
- Query Editor on the AWS console provides a powerful interface for executing SQL queries on Redshift clusters and viewing the query results and query execution plan (for queries executed on compute nodes) adjacent to your queries.
Integrated with third-party tools
- Enhance Amazon Redshift by working with industry-leading tools and experts for loading, transforming and visualizing data.
Cost-effective
- No upfront costs, pay as you goAmazon Redshift is the most cost-effective data warehouse, and you pay only for the resources you provision.
- Redshift is the only cloud data warehouse that offers On-Demand pricing with no up-front costs, Reserved Instance pricing which can save you up to 75% by committing to a 1- or 3-year term, and per query pricing based on the amount of data scanned in your Amazon S3 data lake. For more information, see the Amazon Redshift pricing page.
- Choose your node type
- You can select from two node types to optimize Redshift for your data warehousing needs. Dense Compute (DC) nodes allow you to create very high performance data warehouses using fast CPUs, large amounts of RAM, and solid-state disks (SSDs). If you want to scale further or reduce costs, you can switch to our more cost-effective Dense Storage (DS) node types that use larger hard disk drives for a very low price point. Scaling your cluster or switching between node types requires a single API call or a few clicks in the AWS Management Console.
Scale quickly to meet your needs
Petabyte-scale data warehousing
- Amazon Redshift is simple and quickly scales as your needs change. With a few clicks in the console or a simple API call, you can easily change the number or type of nodes in your data warehouse, and scale up or down as your needs change.
Exabyte-scale data lake analytics
- Redshift Spectrum, a feature of Redshift, enables you to run queries against exabytes of data in Amazon S3 without having to load or transform any data. You can use S3 as a highly available, secure, and cost-effective data lake to store unlimited data in open data formats.
Limitless concurrency
- Amazon Redshift provides consistently fast performance, even with thousands of concurrent queries – whether they query data in your Amazon Redshift data warehouse, or directly in your Amazon S3 data lake.
Amazon Redshift Pros
Let’s look at some of the advantages of Amazon Redshift.
Exceptionally fast
- Redshift is very fast when it comes to loading data and querying it for analytical and reporting purposes. Redshift has Massively Parallel Processing (MPP) Architecture which allows you to load data at blazing fast speed.
- In addition, using this architecture, Redshift distributes and parallelize your queries across multiple nodes.
- Redshift gives you an option to use Dense Compute nodes which are SSD based data warehouses. Using this you can run most complex queries in very less time.
High Performance –
- As discussed in the previous point, Redshift gains high performance using massive parallelism, efficient data compression, query optimization, and distribution.
MPP enables Redshift to parallelize data loading, backup,
- and restore operation. Furthermore, queries that you execute get distributed across multiple nodes.
- Redshift is a columnar storage database, which is optimized for the huge and repetitive type of data.
- Using columnar storage, reduces the I/O operations on disk drastically, improving performance as a result.
- Redshift gives you an option to define column-based encoding for data compression. If not specified by the user, Redshift automatically assigns compression encoding.
- Data compression helps in reducing memory footprint and significantly improves the I/O speed. To read more about it, check out our blog Understanding Amazon Redshift Architecture.
Horizontally Scalable
- Scalability is a very crucial point for any Data warehousing solution and Redshift does pretty well job in that. Redshift is horizontally scalable.
- Whenever you need to increase the storage or need it to run faster, just add more nodes using AWS console or Cluster API and it will upscale immediately.
- During this process, your existing cluster will remain available for reading operations so your application stays uninterrupted.
- During the scaling operation, Redshift moves data parallelly between compute nodes of old and new clusters.
- Therefore enabling the transition to complete smoothly and as quickly as possible.
Massive Storage capacity
- As expected from a Data warehousing solution, Redshift provides massive storage capacity. A basic setup can give you a petabyte range of data storage.
- In addition, Redshift gives you an option to choose Dense Storage type of compute nodes which can provide large storage space using Hard Disk Drives for a very low price. You can further increase the storage by adding more nodes to your cluster and it can go well beyond a petabyte data range.

Get Practical Oriented Amazon RedShift Training & Certification Course
Weekday / Weekend BatchesSee Batch DetailsAttractive and transparent pricing
- Pricing is a very strong point in favor of Redshift, it is considerably cheaper than alternatives or an on-premise solution. Redshift has 2 pricing models, pay as you go and reserved instance.
- Hence this gives you the flexibility to categorize this expense as an operational expense or capital expense.
- If your use case requires more data storage, then with 3 years reserved instance Dense Storage plan, effective price per terabyte per year can be as low as $935.
- Comparing this to traditional on-premise storage, which roughly costs around $19k-$25k per terabyte, Redshift is significantly cheaper. You can read more on Redshift Pricing here.
SQL interface –
- Redshift Query Engine is based on ParAccel which has the same interface as PostgreSQL If you are already familiar with SQL, you don’t need to learn a lot of new techs to start using query module of Redshift.
- Since Redshift uses SQL, it works with existing Postgres JDBC/ODBC drivers, readily connecting to most of the Business Intelligence tools.
AWS ecosystem
- Many businesses are running their infrastructure on AWS already, EC2 for servers, S3 for long-term storage, RDS for database, and this number is constantly increasing.
- Redshift works very well if the rest of your infra is already on AWS and you get the benefit of data locality and the cost of data transport is comparatively low.
- For a lot of businesses, S3 has become the de-facto destination for cloud storage. Since Redshift is virtually co-located with S3 and it can access formatted data on S3 with single COPY command. When loading or dumping data on S3, Redshift uses Massive Parallel Processing which can move data at a very fast speed.
Security –
- Amazon Redshift comes packed with various security features. There are options like VPC for network isolation, various ways to handle access control, data encryption, etc. The data encryption option is available at multiple places in Redshift.
- To encrypt data stored in your cluster you can enable cluster encryption at the time of launching the cluster. Also, to encrypt data in transit, you can enable SSL encryption.
- When loading data from S3, Redshift allows you to use either server-side encryption or client-side encryption. Finally, at the time of loading data, S3 or Redshift copy command handles the decryption respectively.
- Amazon Redshift clusters can be launched inside your infrastructure Virtual Private Cloud (VPC).
- Hence you can define VPC security groups to restrict inbound or outbound access to your Redshift clusters.
- Using the robust Access Control system of AWS, you can grant privilege to specific users or maintain access on specific database level. Additionally, you can even define users and groups to have access to specific data in tables.
Amazon Redshift Limitations
This section details some of the Amazon Redshift limitations and disadvantages.
Doesn’t enforce uniqueness
- There is no way in Redshift to enforce uniqueness on inserted data. Hence, if you have a distributed system and it writes data on Redshift, you will have to handle the uniqueness yourself either on the application layer or by using some method of data de-duplication.
- Only S3, DynamoDB, and Amazon EMR support for parallel upload – If your data is in Amazon S3 or relational DynamoDB or on Amazon EMR, Redshift can load it using Massively Parallel Processing which is very fast. But for all other sources, parallel loading is not supported. You will either have to use JDBC inserts or some scripts to load data into Redshift. Alternatively, you can use an ETL solution like Hevo which can load your data into Redshift parallelly from 100s of sources.
Requires a good understanding of Sort and Dist keys
- Sort keys and Distribution keys decide how data is stored and indexed across all Redshift nodes.
- Therefore, you need to have a solid understanding of these concepts and you need to properly set them on your tables for optimal performance.
- There can be only one distribution key for a table and that can not be changed later on, which means you have to think carefully and anticipate future workloads before deciding Dist key. You can read our blog discussing Amazon Redshift Distribution Keys and Amazon Redshift Sort Keys in detail.
Can’t be used as a live app database
- While Redshift is very fast when running queries on a huge amount of data or running reporting and analytics, but it is not fast enough for live web apps.
- So you will have to pull data into a caching layer or a vanilla Postgres instance to serve Redshift data to web apps.
Data on Cloud
- Though it is a good thing for most people, in some use cases it could be a point of concern. So if you are concerned with the privacy of data or your data has extremely sensitive content, you may not be comfortable putting it on the cloud.




