
Last updated on 08th Jul 2020| 3854
- Service operation coordinates and carries out the activities and processes required to deliver and manage services at agreed levels to business users and customers. Service operation also manages the technology that is used to deliver and support services.
- Service operation includes the processes of event management, incident management, request fulfillment, problem management, and access management. Service operation also includes the functions of service desk, technical management, IT operations management, and application management.
Different type of functions in service operation:
Strategic objectives are ultimately realized through service operation. ITIL Service Operation provides guidance on how to maintain stability in service operation, allowing for changes in design, scale, scope and service levels.
Organizations are provided with detailed process guidelines, methods and tools for use in two major control perspectives:
- Reactive
- proactive
New models and architectures such as shared services, utility computing, web services and mobile commerce to support service operation are described.
Service Operation Goals & Objectives
- The purpose of the service operation stage of the service life cycle is to coordinate and carry out. The activities and processes required to deliver and manage services at agreed levels to business users and customers. Service operation is also responsible for the ongoing management of the technology that is used to deliver and support services. It is a critical stage of the service life cycle.
- Well-planned and well-implemented processes will be to no avail if the day-to-day operation of those processes is not properly conducted, controlled and managed. Nor will service improvements be possible if day-to-day activities to monitor performance, assess metrics and gather operational data are not systematically conducted during service operation.
- Staff involved in the service operation stage of the service life cycle should have processes and support tools in place, that allow them to have an overall view of service operation and delivery. Rather than just the separate components, such as hardware, software applications and networks, that make up the end-to-end service from a business perspective.
- These processes and tools should also detect any threats or failures to service quality. As services may be provided, in whole or in part, by one or more partner/supplier organizations, the service operation view of the end-to-end. Service should be extended to encompass external aspects of service provision. When necessary, shared or interfacing processes and tools should be deployed to manage cross-organizational work flows.
The objectives of service operation are to:
- Maintain business satisfaction and confidence in IT through effective and efficient delivery and support of agreed IT services.
- Minimize the impact of service outages on day- to-day business activities.
- Ensure that access to agreed IT services is only provided to those authorized to receive those services.
- Select and adopt the best practice as recommended in this publication will assist organizations in delivering significant benefits.
Adopting and implementing standard and consistent approaches for service operation will :
- Reduce an unplanned labor and costs for both the business and IT through optimized handling of service outages and identification of their root causes
- Reduce the duration and frequency of service outages which will allow the business to take full advantage of the value created by the services they are receiving
- Provide operational results and data that can be used by other ITIL processes to improve services continually and provide
- Justification for investing in ongoing service improvement activities and supporting technologies
- Meet the goals and objectives of the organization’s security policy by ensuring that IT services will be accessed only by those authorized to use them
- Provide quick and effective access to standard services which business staff can use to improve their productivity or the quality of business services and products
- Provide a basis for automated operations, thus increasing efficiencies and allowing expensive human resources to be used for more innovative work, such as designing new or improved functionality, Defining new ways in which the business can exploit technology for increased competitive advantage
- Service Operation key Terminology Impact is the Measure of effect of an Incident, Problem or Change on Business Processes. Impact is often based on how Service Levels will be affected. Urgency is the measure of business criticality of an Incident, Problem or Change where there is an effect upon business deadlines.
- -Time required for actions to be taken is known as Priority.(Priority is a function of Impact & Urgency.)Priority = Impact X Urgency
- Service Request is the user requesting information for a change or access to an IT Service
- An Event is a notification created by a service, CI or monitoring tool.
- An Alert is a warning or notice about threshold, change or failure that has occurred.
- An Incident unexpected interruption or reduction in quality of an IT service.
- A Problem is a cause of one or more Incidents.
- A Workaround is a temporary means to resolve issues or difficulties.
- A Known Error is a Problem that has a documented Root Cause & a Workaround.
- A Known Error Database (KEDB) is a storage for previous knowledge on requests and known errors.
Balance Internal IT view versus external business view
- The most fundamental conflict in all stages of the service life cycle is between the views of IT as a set of IT services (External view) and the view of IT as a set of technology components (Internal view). The external view of IT is the way in which services are experienced by its users and customers.
- They do not always understand, nor do they wish to care about the details of what technology is used to manage those services. All they are concerned about is that the services are delivered as required and agreed. The internal view of IT is the way in which IT components and systems are managed to deliver the services. Because IT systems are complex and diverse, this often means that the technology is managed by several different teams or departments.
- Each of which is focused on achieving good performance and availability of ‘its’ systems. The whole point of service management is to balance these views to meet the objectives of the organization as a whole. It is critical to structure services around customers.
- At the same time, it is possible to compromise the quality of services by not thinking about how they will be delivered. Both views are necessary when delivering services. The organization that focuses only on business requirements without thinking about how they are going to deliver will end up making promises that cannot be kept.
- The organization that focuses only on internal systems without thinking about what services they support, will end up with expensive services that deliver little value. The potential for role conflict between the external and internal views is the result of many variables, including the maturity of the organization, its management culture, its history etc.
- This makes a balance difficult to achieve, and most organizations tend more towards one role than the other. Of course, no organization will be totally internally or externally focused, but will find itself in a position along a spectrum between the two.

Get In-Depth Service Operations Processes On ITIL Certification Course
Weekday / Weekend BatchesSee Batch DetailsBalance Stability vs. Responsiveness
- No matter how well IT service has been designed & no matter how good is the functionality of an IT service, it is worth nothing if their individual IT components are not performing as per their agreed levels and not delivering the desired value.
- Stability is to: Develop & refine standard IT management techniques & processes. Service components needs to be available & perform consistently. Responsiveness is the: Ability to respond to changes without impact to other services. Ability to take care when agreeing to required changes – Consider all requirements and impact of delivering change.
- Example: A Business Unit requires additional IT Services, more capacity and faster response times. To respond to this type of change without impacting other services is a significant challenge. Many IT organizations are unable to achieve this balance and tend to focus on firefighting! Building an IT organization that achieves a balance between stability and responsiveness in service operation will require the following actions:
- Ensure investment in processes and technologies that are adaptive rather than rigid.
- Build a strong service level management (SLM) process which is active from the service design stage to the CSI stage of the service lifecycle.
- Ensure proper mapping of business requirements to IT operational activities and components of the IT infrastructure by integration between SLM and the other service design. This will ensure that both business and (IT operational requirements can be assessed and built or changed together.
Balance Quality of service vs. Cost of service
- Service Operation is required to consistently deliver the agreed level of IT service to its customers and users, while at the same time keeping costs and resource utilization at an optimal level. Achieving an optimal balance between cost and quality is a key role of service management. Every organization will have different range of optimization, depending on the nature of the service and the type of business.
- Determining the appropriate balance of cost and quality should be done during the service strategy and service design life cycle stages. Although in many organizations it is left to the service operation teams. Unfortunately, it is also common to find organizations that are spending vast quantities of money without achieving any clear improvements in quality. Again, CSI will be able to identify the cause of the inefficiency, evaluate the optimal balance for that service and formulate a corrective plan. Achieving the correct balance is important. Too much focus on quality will result in IT services that deliver more than necessary, at a higher cost, and could lead to a discussion on reducing the price of services.
- Too much focus on cost will result in IT delivering on or under budget, but putting the business at risk through substandard IT services. There is no simple calculation to determine when costs have been cut too far, but good SLM is crucial to making customers aware of. The impact of cutting too far, so recognizing these warning signs and symptoms can greatly enhance an organization’s ability to correct this situation.
Reactive vs. Proactive
- Action which takes place when prompted by external driver is known as Reactive. Proactive is always looking for ways to improve current situation- Continually looking for potentially impacting changes,can be expensive, better to manage proactively.
- A reactive organization is one which does not act unless it is prompted to do so by an external driver, e.g. a new business requirement. An application that has been developed or escalation in complaints made by users and customers. An unfortunate reality in many organizations is the focus on reactive management mistakenly as the sole means to ensure services that are highly consistent and stable. Actively discouraging proactive behavior from operational staff. The unfortunate irony of this approach is that discouraging effort investment in proactive service management can ultimately increase.
To achieve balance between reactive and proactive we require:
- Formal, Integrated Problem and Incident Management processes
- Ability to prioritize technical faults and demands. Data from Configuration and Asset Management.
- Ongoing involvement from Service Level Management in Service Operations.
While proactive behavior in service operation is generally good, there are also times where reactive behavior is needed. The role of service operation is to achieve a balance between being reactive and proactive.
Service Operation – Processes
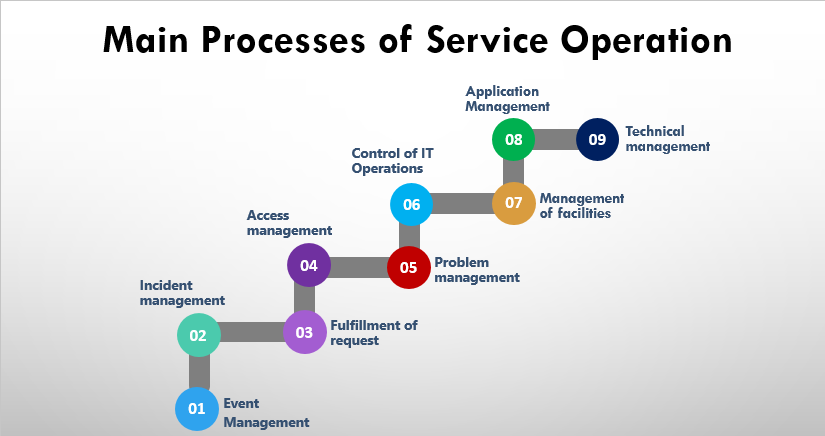
There are a number of key service operation processes that must link together to provide an effective overall IT support structure. Service Operation has following 5 processes:
- Event Management
- Incident Management
- Problem management
- Request fulfillment
- Access management
Event management: Event management manages events throughout their life cycle. This life cycle includes coordination activities to detect events. Make sense of them and determine the appropriate control action.
Incident management: Incident management concentrates on restoring unexpectedly degraded or disrupted services to users as quickly as possible, in order to minimize business impact.
Problem management: Problem management involves root cause analysis to determine and resolve the underlying causes of incidents, and proactive activities to detect and prevent future problems/incidents. This also includes the creation of known error records, that document root causes and workarounds to allow quicker diagnosis, and Resolution should further incidents occur.
Request fulfillment: Request fulfillement is the process for managing the life cycle of all service requests. Service requests are managed throughout their life cycle from initial request to fulfillment using separate request fulfillment records/tables to record and track their status. They are the mechanism by which users formally request something from an IT service provider.
Service requests are transactional and associated with the standard services that a provider is delivering and is associated with a request model that defines any prerequisites, authorizations needed and standard work steps and activities to fulfill it. As part of that request model, standard changes and other types of requests for change (RFC5) may be needed to complete fulfillment actions.
Access management: Access management is the process of granting authorized users the rights to use a service while restricting access to non-authorized users. It is based on being able accurately to identify authorized users and then manage their ability to. Access services as required for their specific organizational role or job function. Access management has also been called identity or rights management in some organizations.
Event Management
- Purpose to manage events throughout their lifecycle is the purpose of event management. This life cycle of activities to detect events, make sense of them and determine the appropriate control action, which is coordinated by the event management process. Event management is therefore the basis for operational monitoring and control.
- If events are programmed to communicate operational information as well as warnings and exceptions, they can be used as a basis for automating many routine operations management activities.
- Example: Executing scripts on remote devices, or submitting jobs for processing, or even dynamically balancing the demand for a service across multiple devices to enhance performance.
Incident Management
- In ITIL terminology, an ‘incident’ is defined as an unplanned interruption to an IT service, or reduction in the quality of an IT service, or a failure of a CI that has not yet impacted an IT service (for example failure of one disk from a mirror set).
- It is the process responsible for managing the life cycle of all incidents. Incidents may be recognized by technical staff, detected and reported by event monitoring tools, communications from users usually via a telephone call to the service desk, or reported by third-party suppliers and partners.
- The purpose of incident management is to restore normal service operation as quickly as possible, and minimize the adverse impact on business operations. Thus, ensuring that agreed levels of service quality are maintained.
- ‘Normal service operation’ is defined as an operational state, where services and CIs are performing within their agreed service and operational levels. Incident management includes any event which disrupts, or which could disrupt, a service. This includes events which are communicated directly by users, either through the service desk or through an interface from event management to incident management tools.
- Incidents can also be reported and/or logged by technical staff. For example, they notice something untoward with a hardware or network component they may report or log an incident and refer it to the service desk).This does not mean, however, that all events are incidents. Many classes of events are not related to disruptions at all, but are indicators of normal operation or are simply informational. Although both incidents and service requests are reported to the service desk, this does not mean that they are the same.
- Service requests do not represent a disruption to agreed service, but are a way of meeting the customer’s needs and may be addressing an agreed target in an SLA. Service requests are dealt with by the request fulfillment process.
Problem Management
- Problem management is the process which is responsible to manage the lifecycle of all problems. ITIL defines a ‘problem’ as an underlying cause of one or more incidents. The purpose of problem management is to manage the lifecycle of all problems from first identification through further investigation, documentation and eventual removal.
- Problem management seeks to minimize the adverse impact of incidents and problems on the business that are caused by underlying errors within the IT Infrastructure and to proactively prevent recurrence of incidents related to these errors. In order to achieve this, problem management seeks to get the root cause of incidents, document and communicate the known errors and initiate actions to improve or correct the situation.

Best Service Operations Processes On ITIL Training from Real-Time Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Request Fulfillment
Purpose
- The term ‘service request’ is used as a generic description for many different types of demands that are placed upon the IT organization by the users. Many of these are typically requests for small changes that are low risk, frequently performed, low cost etc.
- E.g, a request to change a password, a request to install an additional software application onto a particular workstation, a request to relocate some items of desktop equipment) or may be just a request for information.
- Request fulfillment is the process responsible for managing the life cycle of all service requests from the users. It is the process for dealing with service requests, many of them are actually smaller, or low risk. The purpose needed to fulfill a request will vary depending upon exactly what is being requested. Some organizations will be comfortable to let the service requests be handled through their incident management processes.
Access Management
Purpose
- Access management is the process of granting authorized users the right to use a service, while preventing access to non-authorized users. It has also been referred to as rights management or identity management in different organizations.
- The purpose of access management is to provide the right for users to be able to use a service or group of services. It is therefore the execution of policies and actions that are defined in the information security management.
Service Providers
Types
There are three types of service providers:
- Internal Service Provider
- Shared Services Unit
- External Service Provider
Internal Service Provider
- ISPs are service providers that are dedicated and often embedded within, an individual business unit. The business units themselves may be part of a larger enterprise or parent organization. Business functions such as finance, administration, logistics, human resources and IT provide services required by various parts of the business. They are funded by overheads and are required to operate strictly within the mandates of the business.
- ISPs have the benefit of tight coupling with their owner- customers, avoiding certain costs and risks associated with conducting business with external parties. Since ISPs are dedicated to specific business units they are required to have an in-depth knowledge of the business and its goals, plans and operations. They are usually highly specialized, often focusing on designing, customizing and supporting specific applications or on supporting a specific type of business process.
- ISPs operate within internal market spaces. Their growth is limited by the growth of the business unit they belong to. Each business unit (BU) may have its own ISP
- The success of ISPs is not measured in terms of revenues or profits because they tend to operate on a cost-recovery basis with internal funding. All costs are borne by the owning business unit or enterprise.
Shared Services Unit
- Functions such as finance, IT, human resources and logistics are not always at the core of an organization’s competitive advantage. Hence, they need not be maintained at the corporate level where they demand the attention of the chief executive’s team.
- Instead, the services of such shared functions are consolidated into an autonomous special unit called a shared services unit (SSU). The model allows a more devolved governing structure under which SSUs can focus on serving business units as direct customers.
- SSUs can create, grow and sustain an internal market for their services and model themselves along the lines of service providers in the open market. Like corporate business functions, they can leverage opportunities across the enterprise and spread their costs and risks across a wider base. Unlike corporate business functions, they have fewer protections under the banner of strategic value and core competence.
- They are subject to comparisons with external service providers whose business practices, operating models and strategies they must emulate and whose performance they should approximate, if not exceed. Customers of Type II are business units under a corporate parent, common stakeholders and an enterprise-level strategy. What may be sub-optimal for a particular business unit may be justified by advantages reaped at the corporate level for which the business unit may be compensated.
- Type II can offer lower prices compared to external service providers by leveraging corporate advantage, internal the autonomy to function like a business unit, Type II providers can make decisions outside the constraints of business unit level policies. They can standardize their service offerings across business units and use market-based pricing to influence demand patterns.
- A successful Type II service provider can find itself in a position where it is able to provide its services externally as well as internally. In these cases they are both Type II and Type III service providers.
- In these cases it is important to make a strategic decision to provide services both externally and internally and to set up the appropriate governance and management structures. This is not just a case of delivering existing services externally.
External Service Provider
- ESP is a service provider that provides IT services to external customers. The business strategies of customers sometimes require capabilities readily available from a Type lll provider. The additional risks that Type lll providers assume over Type I and Type II are justified by increased flexibility and freedom to pursue opportunities.
- ESPs can offer competitive prices and drive down unit costs by consolidating demand. Certain business strategies are not adequately served by internal service providers such as Type I and Type II. Customers may pursue sourcing strategies requiring services from external providers.
- The motivation may be access to knowledge, experience, scale, scope, capabilities and resources that are either beyond the reach of the organization or outside the scope of a carefully considered investment portfolio. Business strategies often require reductions in the asset base, fixed costs and operational risks, or the redeployment of financial assets.
- The experience of ESPs is often not limited to any one enterprise or market. The breadth and depth of such experience is often the single most distinctive source of value for customers. The breadth comes from serving multiple types of customer or market. The depth comes from serving multiples of the same type.
- From a certain perspective, ESPs are operating under an extended large-scale shared services model. They assume a greater level of risk from their customers compared to ISPs and SSUs. But their capabilities and resources are shared by their customers – some of whom may be rivals. This means that rival customers have access to the same bundle of assets, thereby diminishing any competitive advantage those assets bestowed.




