
Last updated on 04th Jul 2020| 4210
In this comprehensive set of advanced TensorFlow interview questions, we aim to delve into the intricacies of the TensorFlow library, spanning both foundational and advanced concepts. Our interview questions extend beyond theoretical knowledge, delving into practical applications and real-world scenarios, examining candidates’ proficiency in optimizing models, implementing transfer learning, deploying models using TensorFlow Serving, and leveraging TensorFlow Extended (TFX) for comprehensive machine learning lifecycle management. Whether you’re a fresher seeking to establish a strong foundation or an experienced practitioner looking to showcase your depth of expertise, these interview questions cover a spectrum of scenarios to challenge and evaluate your TensorFlow prowess. With detailed answers, this compilation aims to prepare you for common questions and equip you to tackle advanced challenges that may arise during your TensorFlow interview.
1. TensorFlow: What Is It?
Ans:
The Google Brain team created the open-source machine learning framework TensorFlow. It is widely used for building and training various machine learning and deep learning models. TensorFlow offers an extensive network of tools, libraries, and community resources. making it a well-liked option for developers and academics studying artificial intelligence applications.
2. What are TensorFlow’s main characteristics?
Ans:
- The primary features of TensorFlow include its flexibility, scalability, and portability.
- It supports CPU and GPU computing, making it suitable for various hardware configurations.
- TensorFlow offers high-level APIs for easy model development and lower-level APIs for greater control and customization.
- Its ability to deploy models across different platforms and devices contributes to its versatility in several fields, including natural language processing and computer vision.
3. Describe the TensorFlow idea of tensors.
Ans:
Tensors are the essential building pieces of TensorFlow. A multi-dimensional array called a tensor is comparable to a mathematical tensor but with the added capability of handling computations on GPUs. Tensors can be constants or variables, and they flow through a computational graph, capturing the dependencies between operations during model training and inference.
4. Describe the distinctions between PyTorch and TensorFlow.
Ans:
TensorFlow and PyTorch are popular deep learning frameworks, but their design philosophies and APIs differ. TensorFlow tends to be more explicit and requires users to define the entire computational graph before execution. In contrast, PyTorch follows a dynamic computation graph approach, allowing for more flexibility and easier debugging during model development.
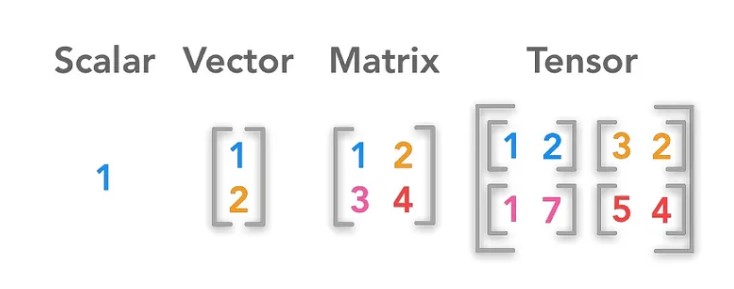
5. In TensorFlow, what kinds of tensors are there?
Ans:
TensorFlow supports various types of tensors, including,
- Scalar (0-dimensional)
- Vector (1-dimensional)
- Matrix (2-dimensional)
- Higher-dimensional tensors
6. Describe the TensorFlow execution model.
Ans:
The TensorFlow execution model creates a computational graph defining the operations and their dependencies. The graph is then executed within a session, where tensors flow through the graph, and the model parameters are updated during training through backpropagation. This static graph approach allows for optimization and parallelization, contributing to TensorFlow’s efficiency.
7. Mention the external TensorFlow APIs.
Ans:
TensorFlow offers multiple APIs to interact with the framework. Besides the core TensorFlow API, popular high-level APIs such as Keras provide a more user-friendly interface for building and training neural networks. Additionally, TensorFlow Lite is designed for mobile and embedded devices, while TensorFlow.js enables machine learning in the browser.
8. What is a TensorFlow graph?
Ans:
- A TensorFlow graph is a representation of the computational operations and their dependencies.
- It defines the structure of the model without executing the computations.
- This static graph allows for optimizations and efficient execution on various hardware architectures.
9. What is a TensorFlow session?
Ans:
In TensorFlow, a session is a runtime environment where the computational graph is executed. Sessions manage the allocation of resources, such as memory and GPU devices, and enable data flow through the graph. During training, a session updates the model parameters based on the defined optimization algorithm.
10. What is TensorBoard, and what are its uses?
Ans:
- TensorBoard is a visualization tool provided by TensorFlow for monitoring and analyzing the training process.
- It displays various metrics, such as loss and accuracy, over time. TensorBoard helps users understand the model’s performance, identify potential issues, and optimize hyperparameters, providing valuable insights during the development and debugging of machine learning models.
11. What is TensorFlow serving?
Ans:
TensorFlow Serving is a dedicated system for deploying machine learning models in production environments. It simplifies the process of taking a trained TensorFlow model and making it available for serving predictions in a scalable and efficient manner. TensorFlow Serving supports versioning, model rollback, and flexible model deployment configurations. It is suitable for deployment scenarios such as serving models through REST APIs or integrating with other production systems.
12. How do placeholders function in TensorFlow?
Ans:
Placeholders in TensorFlow are used to feed input data into the computational graph during model training. They act as empty nodes later filled with actual data during the execution phase. Placeholders are particularly useful when building dynamic models where the input size may vary, and they Permit developers to specify the framework of the model without specifying the actual data until runtime.
13. What is an embedding projector?
Ans:
An embedding projector is a visualization tool in TensorFlow that allows users to explore and understand high-dimensional data representations. It is often used for visualizing word embeddings in natural language processing tasks. It provides an interactive interface to inspect relationships between different embeddings, aiding in interpreting learned representations within a model.
14. Explain TensorFlow variables and their importance.
Ans:
TensorFlow variables are special tensors used to hold and update parameters during training. Unlike constants, variables can be modified, making them suitable for storing weights and biases in a neural network. TensorFlow variables play a crucial role in optimization algorithms, as they are updated during backpropagation to decrease the loss function and enhance the model’s performance.
15. How are TensorFlow variables created and initialised?
Ans:
You typically use the tf – variable class to create and initialize TensorFlow variables. The initialization process involves specifying an initial value for the variable, and TensorFlow provides various methods for initialization, such as random initialization or using pre-trained weights. Once created, variables can be updated during training using gradient descent or other optimization algorithms.
16. Which are the main elements of the architecture of TensorFlow?
Ans:
- The primary components of TensorFlow architecture include the computational graph, which defines the model structure, and the execution environment, managed by sessions, where the actual computations take place.
- TensorFlow also incorporates a flexible API hierarchy, allowing users to interact with the framework at different levels, from high-level APIs like Keras to lower-level APIs for advanced customization.
- Additionally, TensorFlow includes tools like TensorBoard for visualization and monitoring.
17. What is the use of the tf. Data module?
Ans:
TensorFlow’s tf. The data module is designed for efficient input pipeline construction during model training. It provides tools and classes to handle data loading, preprocessing, and batching, optimising the data input process for improved training performance. The tf. data API is particularly beneficial when working with large datasets or complex data transformations.
18. Describe TensorFlow’s eager execution idea.
Ans:
Eager execution is a feature in TensorFlow that allows for immediate operations evaluation, making the framework more intuitive and interactive. Unlike the traditional static graph approach, eager execution enables users to evaluate TensorFlow operations on the fly, facilitating easier debugging and a more dynamic development experience. This model is beneficial for small-scale experimentation and prototyping.
19. Describe the TensorFlow API hierarchy.
Ans:
The TensorFlow API hierarchy is organised into different levels of abstraction, ranging from high-level APIs like Keras for quick model development to lower-level APIs like tf. Layers and tf. nn for more granular control over model components. This hierarchy allows users to choose the level of abstraction that best suits their needs, balancing simplicity and customization.
20. What are TensorFlow constants?
Ans:
- TensorFlow constants are tensors with fixed values that do not change during the execution of a computational graph. The tf. constant function is utilised in their creation.
- Often used for storing hyperparameters or other fixed values within a model. Constants cannot be modified during training, making them suitable for storing values that remain constant throughout the execution of a model.
21. How to create TensorFlow constants?
Ans:
TensorFlow constants can be created using the tf. Constant function. This function takes a Python scalar, list, or NumPy array as input and converts it into a constant tensor. For example, to create a constant with the value 5, you can use tf. constant(5). Constants are immutable, meaning their values cannot be changed during the execution of a computational graph, making them suitable for storing fixed values like hyperparameters or configuration settings.
22. In TensorFlow, how are operations defined?
Ans:
- In TensorFlow, operations are defined as computational graph nodes representing mathematical operations or transformations on tensors.
- Operations can range from simple arithmetic operations to complex neural network layers. Users can define operations using various functions provided by the TensorFlow API, such as tf.
- Add for addition or tf. matmul for matrix multiplication. These operations define the flow of tensors through the graph, capturing the dependencies between different computations.
23. What are the advantages of machine learning using TensorFlow?
Ans:
TensorFlow offers several benefits for machine learning, including a flexible and scalable framework that supports many models. Its extensive ecosystem provides tools for data preprocessing, model development, and deployment. TensorFlow’s compatibility with CPU and GPU computing allows for efficient training on various hardware configurations. Additionally, TensorFlow’s community support and documentation make it a well-liked option for developers and researchers working on diverse machine learning applications.
24. Describe the function of GPUs in TensorFlow processing.
Ans:
Graphics Processing Units, or GPUs, are essential components of TensorFlow computation by accelerating the training and inference processes. TensorFlow leverages GPU parallelism to perform matrix operations and other computations simultaneously, significantly speeding up the training of deep learning models. This is especially advantageous when working with large datasets and complex neural network architectures, as GPUs can handle heavy computational work more efficiently than traditional CPUs.
25. How does TensorFlow’s automated differentiation function?
Ans:
- Automatic differentiation is a critical feature in TensorFlow that enables the computation of gradients automatically during the training process.
- Gradients are essential for optimizing model parameters through techniques like gradient descent.
- TensorFlow’s dynamic computational graph and automatic differentiation capabilities are handy for building and training complex models, as developers can focus on model architecture. At the same time, TensorFlow handles the computation of gradients.
26. What is GradientTape in TensorFlow?
Ans:
Tf.GradientTape is a context manager in TensorFlow that is used for automatic differentiation. When operations are executed within the context of a tf.GradientTape and TensorFlow keep track of the operations to compute gradients later. This is essential for implementing custom training loops and advanced optimization techniques using tf.In GradientTape, developers can access and manipulate gradients for model parameters during the training process.
27. Describe basic TensorFlow mathematical operations.
Ans:
Basic TensorFlow mathematical operations include functions like tf. Add for addition, tf. Subtract for subtraction, tf. Multiply for multiplication and tf. Divide for division. Additionally, TensorFlow provides operations for matrix operations (tf. mammal), element-wise operations (tf. square, tf. sqrt), and different activation functions that neural networks frequently employ (tf. Sigmoid, tf. relu). These operations form the building blocks for constructing complex mathematical expressions within a TensorFlow computational graph.
28. How can you use TensorFlow to display graphs?
Ans:
- TensorFlow provides the TensorBoard tool for visualizing computational graphs.
- By using the tf. Summary.FileWriter and tf. Summary.tensor_summary functions, users can log relevant Information, such as loss values or accuracy metrics, during model training.
- TensorBoard then allows for the interactive exploration of the computational graph, along with visualizations of metrics over time, helping users gain insights into model performance and behaviour.
29. What is TensorFlow Lite?
Ans:
A more portable version of TensorFlow, TensorFlow Lite, is intended for mobile and edge devices. It makes machine learning models deployable. It is suitable for applications like mobile apps, IoT devices, and embedded systems on resource-constrained platforms. TensorFlow Lite provides model conversion and optimization tools, allowing developers to run models efficiently on devices with limited computational resources.
30. Define the tf. Function.
Ans:
Tf.function is a decorator in TensorFlow used to convert a Python function into a TensorFlow graph. This graph can be optimized and executed more efficiently, mainly when applied to functions that will be repeatedly called, such as during model training. I am using the tf. Function improves the performance of TensorFlow code by leveraging graph optimizations and is particularly beneficial in scenarios where runtime performance is crucial, such as in production deployments.
31. Explain the purpose of TensorFlow Datasets.
Ans:
- TensorFlow Datasets (TFDS) is a library in TensorFlow that simplifies loading and managing datasets for machine learning.
- It provides a collection of preprocessed datasets with standardized formats, making it easy for researchers and developers to experiment with various datasets without extensive preprocessing.
- TensorFlow Datasets offers a consistent API for accessing datasets, allowing users to focus on building and training models rather than spending time on data preparation.
32. What role do tf.SavedModel & tf.Checkpoint play in model management?
Ans:
The tf.SavedModel and tf.Checkpoint functionalities in TensorFlow play crucial roles in model management. Tf.SavedModel is a format for saving and serializing TensorFlow models, ensuring compatibility for model deployment across different platforms. On the other hand, tf.Checkpoint provides a mechanism for saving and restoring model parameters during training, allowing users to checkpoint their models at different stages and resume training or perform inference later.
33. What are some common uses for TensorFlow in deep learning and machine learning?
Ans:
TensorFlow has applications in a variety of machine learning and deep learning domains. TensorFlow is widely used in computer vision for image classification, object detection, and image segmentation. TensorFlow powers applications like language translation, sentiment analysis, and text summarization in natural language processing. Additionally, TensorFlow is applied in speech recognition, recommendation systems, and reinforcement learning, showcasing its versatility and impact in diverse fields.
34. How do you install TensorFlow on your system?
Ans:
Installing TensorFlow on your system can be done using Python’s package manager, pip. The command pip install tensorflow instals the latest stable version of TensorFlow. You can install the GPU version using pip install tensorflow-gpu for GPU support. Additionally, users can specify a particular version or install TensorFlow with specific hardware support based on their requirements.
35. How does TensorFlow load a dataset?
Ans:
Loading a dataset using TensorFlow typically involves using the tf.data API. Users can leverage functions like tf. Data.Dataset.from_tensor_slices or tf. Data.Dataset.from_generator to create a TensorFlow dataset from existing data structures or generators. TensorFlow Datasets (TFDS) also provides preprocessed datasets that can be quickly loaded using the tfds.load function, simplifying the process of accessing and experimenting with various datasets.
36. What is a TensorFlow optimizer?
Ans:
A TensorFlow optimizer is a crucial component in training machine learning models. Optimizers, such as tf. Keras. Optimizers.Adam or tf. Keras. Optimizers.SGD defines the update rules for model parameters during the training process. These updated rules are based on the gradients computed during backpropagation, helping to minimize the model’s loss function and improve its performance over time.
37. How can a TensorFlow model be saved and restored?
Ans:
Saving and restoring a TensorFlow model can be achieved using the tf.keras.models.save_model and tf. Keras. Models – load_model functions. Alternatively, users can use the tf. Train.Checkpoint API to save and restore specific variables or the entire model. These mechanisms are essential for model persistence, enabling users to save the model’s state, share it with others, or deploy it in production.
38. How does TensorFlow implement backpropagation?
Ans:
- Through its dynamic computation graph, TensorFlow implements backpropagation, a key component of training neural networks.
- During the forward pass, TensorFlow records operations on tensors within a tf.GradientTape context.
- Subsequently, the recorded operations compute gradients during the backward pass. These gradients guide the optimization process, updating the model parameters to minimize the loss function.
39. What is tf. KerasKeras, how does it relate to TensorFlow?
Ans:
Tf.keras is a high-level neural networks API within TensorFlow that provides an easy-to-use interface for building, training, and deploying deep learning models. It is tightly integrated with TensorFlow and is the default high-level API for model development. Tf.keras includes modules for building neural network layers, defining optimizers, and managing model training. It simplifies the development process while allowing users to customize lower-level TensorFlow functionalities.
40. Explain custom training loops in TensorFlow.
Ans:
Custom training loops in TensorFlow allow developers to have finer control over the training process than high-level APIs like tf. Keras. Instead of relying on the built-in training routines, developers can explicitly define the forward pass and compute gradients using tf.GradientTape, and apply custom update rules to the model parameters. Custom training loops provide flexibility for advanced model architectures, specialized optimization techniques, and unique training requirements. This level of control is beneficial for researchers and developers seeking to experiment with unconventional or highly customized models.
41. What is the difference between TensorFlow Estimators and Keras?
Ans:
- TensorFlow Estimators and Keras are high-level APIs within TensorFlow, but they have different purposes and distinct design philosophies.
- Keras is a user-friendly, high-level neural networks API allowing easy and quick model prototyping and development.
- On the other hand, TensorFlow Estimators provide a higher-level interface for distributed training and model deployment, focusing on scalability and production use.
- While Keras is often used for its simplicity in building and training models, TensorFlow Estimators are preferred for more complex scenarios involving distributed computing and deployment.
42. What are TensorFlow Recommenders?
Ans:
- TensorFlow Recommenders is an extension of TensorFlow explicitly designed for building recommendation systems. It offers pre-built parts and a collection of tools.
- To simplify the development of recommendation models. TensorFlow Recommenders includes functionalities for efficiently handling sparse input features, building embedding layers, and training recommendation models. It is beneficial for developers engaged in personalized recommendation applications where understanding user preferences is crucial.
43. What is TensorFlow.js?
Ans:
TensorFlow.js is a JavaScript library developed by TensorFlow for machine learning model deployment and training in web browsers and Node.js. With TensorFlow.js, developers can build and train models directly in the browser, enabling the creation of interactive machine-learning applications. It supports training and running pre-trained models from scratch, making it versatile. It has several uses, such as natural language processing and computer vision in the browser.
44. How do you implement transfer learning in TensorFlow?
Ans:
Transfer learning in TensorFlow involves leveraging pre-trained models to enhance a model’s performance on a particular job.
The process typically involves:
- Taking a pre-trained model.
- Removing its final layers.
- Incorporating fresh layers according to the intended job.
- By reusing the knowledge gained from the pre-trained model, transfer learning allows for improved performance, especially when the task at hand has similarities to the original training task.
- TensorFlow provides tools and APIs to facilitate transfer learning, such as the tf – Keras – applications module, which includes pre-trained models like VGG16 and ResNet.
45. Explain tensor manipulation techniques using TensorFlow.
Ans:
Tensor manipulation in TensorFlow involves various techniques to reshape, slice, concatenate, and transform tensors. TensorFlow offers an extensive range of functions for tensor manipulation, such as tf. Reshape, tf. Slice, and tf. Concat. These operations enable users to modify the shape and content of tensors, which is crucial for tasks like data preprocessing and building complex neural network architectures. Understanding tensor manipulation is essential for effectively working with input data and designing models in TensorFlow.
46. How do you use TensorFlow to build an autoencoder?
Ans:
- Building an autoencoder in TensorFlow involves defining an architecture with a decoder and an encoder.
- The encoder compresses the incoming data and converts it into a smaller dimension (latent space) while the decoder reconstructs the original data from this representation.
- TensorFlow provides tools for implementing autoencoders, such as the tf—keras—layers module for building the encoder and decoder layers.
- Training involves minimizing the reconstruction loss, typically using mean squared error, and TensorFlow’s automatic differentiation simplifies the optimization process.
47. Explain the purpose of TensorFlow Hub.
Ans:
TensorFlow Hub is a database of previously taught machine learning models that can be readily reused for various tasks. It is a hub for sharing and discovering machine learning components, including models, embeddings, and modules. TensorFlow Hub simplifies integrating pre-trained models into new applications, promoting code reuse and accelerating development. Users can access TensorFlow Hub models directly using the library, making it a valuable resource for the machine learning community.
48. How do you use pre-trained models in TensorFlow?
Ans:
Using pre-trained models in TensorFlow involves loading the pre-trained weights and architecture into a new transfer learning or fine-tuning model. TensorFlow provides the tf. Keras. The applications module includes popular pre-trained models like MobileNet, ResNet, and Inception. By instantiating these models and specifying the weights parameter as ‘imagine’ (indicating pre-trained weights on ImageNet), users can benefit from the knowledge encoded in these models for various computer vision tasks.
49. What is k-means clustering in TensorFlow?
Ans:
- K-means clustering in TensorFlow is an unsupervised machine learning technique for partitioning a dataset into k clusters.
- TensorFlow implements k-means clustering through the tf.compat.v1.estimator.experimental – KMeans class
- Users can define the number of clusters (k), input features, and other parameters to perform clustering. This is useful for tasks like customer segmentation, image compression, or any scenario where grouping similar data points is desired.
50. What is TensorFlow Federated?
Ans:
TensorFlow Federated (TFF) is an extension of TensorFlow designed for decentralised machine learning. It enables the training of models across multiple devices or servers without exchanging raw data. Instead, only model updates are communicated between devices, preserving privacy and reducing the need for centralized data storage. TFF is particularly relevant for applications like federated learning, where models are trained collaboratively across a network of devices while keeping data localized. It provides tools for expressing federated computations and integrating them with TensorFlow models.

Best TensorFlow Certification Course with Advanced Concepts from Real Time Experts
Weekday / Weekend BatchesSee Batch Details51. What are the applications of TensorFlow Federated?
Ans:
- TensorFlow Federated (TFF) finds applications in various scenarios where decentralized machine learning is advantageous.
- One critical application is federated learning, where models are trained across a network of devices without centralizing sensitive data.
- This is particularly useful in privacy-preserving applications, such as personalized recommendation systems or healthcare analytics, where user data remains on local devices.
- TFF is also applied in edge computing scenarios, enabling on-device model training for Internet of Things (IoT) devices.
- Additionally, TFF is relevant for collaborative learning environments, allowing multiple organizations to jointly train models without sharing raw data.
52. Explain model evaluation and validation using TensorFlow.
Ans:
Model evaluation and validation in TensorFlow involve evaluating a trained model’s performance with unknown data to ensure generalization. TensorFlow provides tools like the tf-Keras-metrics module for evaluating the accuracy, precision, recall, and F1 score. The process typically includes splitting the dataset into training and validation sets, using the validation set to help validate the model and the training set to assess its performance. This helps identify issues like overfitting and guides further model optimization and tuning.
53. How do you build a neural network using TensorFlow?
Ans:
- Building a neural network using TensorFlow involves defining the architecture, specifying layers, and configuring parameters.
- TensorFlow’s high-level APIs, like Keras, simplify this process. Users can use the Sequential API to stack layers or the more flexible Functional API for complex architectures.
- Layers, activation functions, and optimizers are selected based on the task.
- The model is then compiled with a loss function and an optimizer before being trained on data using the fit method.
- This straightforward process makes it easy to construct neural networks for various tasks.
54. Detail the process of transforming unstructured data in TensorFlow.
Ans:
Transforming unstructured data in TensorFlow, such as text or images, often involves preprocessing steps specific to the data type. For text data, tokenization, padding, and embedding techniques can be applied using TensorFlow’s text preprocessing functions. For images, resizing, normalization, and augmentation methods are commonly used. TensorFlow provides a versatile set of tools, including the tf: image and tf. Text modules facilitate the preprocessing of unstructured data before feeding it into a neural network for training.
55. Describe the usage of TensorFlow in natural language processing (NLP).
Ans:
TensorFlow is widely used in natural language processing (NLP) for jobs including sentiment analysis, machine translation, and text categorization—TensorFlow’s tf.keras.layers.The embedding layer is often employed to represent words as dense vectors, while recurrent neural networks (RNNs) or transformer architectures are used for sequence modelling. Pre-trained language models like BERT and GPT-3, available through TensorFlow Hub or the transformers library, enhance the capabilities of NLP applications, allowing developers to leverage powerful language representations.
56. How do you work with audio data in TensorFlow?
Ans:
- Working with audio data in TensorFlow involves preprocessing and modelling techniques tailored to the nature of sound signals.
- Audio signals can be represented as spectrograms or mel-frequency cepstral coefficients (MFCCs), and TensorFlow provides functions in the tf. Signal module for signal processing. Neural networks that are convolutional (CNNs) and recurrent (RNNs)
- Architectures are commonly used for audio tasks like speech recognition or environmental sound classification. TensorFlow’s flexibility allows developers to effectively design audio processing pipelines and train models.
57. Explain the utilization of TensorFlow in reinforcement learning.
Ans:
TensorFlow plays a significant role in reinforcement learning, a machine learning paradigm where agents learn to make decisions by interacting with an environment. TensorFlow’s tf. Keras and tf. Agent modules provide tools for building reinforcement learning models, and algorithms like deep Q-networks (DQN), or proximal policy optimization (PPO) can be implemented using these tools. TensorFlow’s computational efficiency and GPU support make it suitable for training complex reinforcement learning models that involve decision-making in dynamic environments.
58. What are sparse tensors in TensorFlow?
Ans:
Sparse tensors in TensorFlow are representations of tensors where many elements are zero. This is common in scenarios where data is sparse, such as in natural language processing or collaborative filtering—TensorFlow’s tf. Sparse module provides functions for efficiently creating, manipulating, and performing operations on sparse tensors. Using sparse tensors helps optimize memory usage and computational efficiency for tasks involving large, sparse datasets.
59. What is the purpose of TensorFlow Privacy?
Ans:
TensorFlow Privacy is a framework within TensorFlow that addresses privacy concerns in machine learning, particularly in scenarios where individual data privacy is a priority. It provides tools and mechanisms to enable differential privacy, which increases the noise in the training process to protect against the inference of individual data points. TensorFlow Privacy is valuable in applications like healthcare and finance, where sensitive data must be handled carefully to ensure compliance with privacy regulations.
60. What are some optimization techniques in TensorFlow?
Ans:
- TensorFlow incorporates various optimization techniques to enhance training and model performance.
- Some standard optimization algorithms in TensorFlow include stochastic gradient descent (SGD), Adam, and RMSprop.
- Learning rate schedules, weight decay, and gradient clipping are additional techniques to stabilize and accelerate training.
- TensorFlow’s flexibility allows users to experiment with different optimization strategies to find the most effective approach for their specific machine-learning tasks.
61. Explain the concept of data augmentation in TensorFlow.
Ans:
Data augmentation is a technique used in TensorFlow to artificially increase the diversity of a training dataset by applying several modifications to the current data. These transformations can include random rotations, flips, zooms, shifts, or changes in brightness and contrast. Data augmentation aims to expose the model to different variations of the input data during training, preventing overfitting and improving the model’s generalization to unseen data. TensorFlow provides functionalities like tf. Image for efficiently implementing data augmentation within the training pipeline, ensuring the model becomes more robust by learning from a broader range of input variations.
62. What are the differences between feedforward and feedback networks in TensorFlow?
Ans:
| Feature | |||
| Architecture | Acyclic graph (no loops or cycles) | Cyclic graph with loops (recurrent connections) | |
| Information Flow | Limited memory (no explicit memory of past inputs) | Explicit memory of past inputs (ability to retain information) | |
| Use Cases | Image classification, language translation, etc. | Time-series prediction, natural language processing, etc. | |
| Parallelization | Easier to parallelize training | More challenging to parallelize due to sequential nature | |
| Example | tf.keras.layers.Dense | tf.keras.layers.SimpleRNN |
63. What is GRU in TensorFlow?
Ans:
GRU, or Gated Recurrent Unit, is a type of recurrent neural network (RNN) cell in TensorFlow. It is designed to address some of the limitations of traditional RNNs, such as learning long-term dependencies. GRU introduces gating mechanisms, which regulate information flow inside the network and enable selective updating and forgetting of Information. TensorFlow provides the tf.keras.layers.The GRU layer for implementing GRU cells is beneficial in sequential data tasks where capturing dependencies over varying intervals is essential.
64. What are TensorFlow’s different types of convolutional neural networks (CNNs)?
Ans:
TensorFlow offers various convolutional neural networks (CNNs) for different computer vision tasks. Some common CNN architectures include LeNet, AlexNet, VGGNet, GoogLeNet (Inception), ResNet, and MobileNet. Each architecture has unique characteristics, such as the number of layers, skip connections, or depth wise separable convolutions, making them suitable for specific applications. TensorFlow provides pre-trained models and implementation details for these architectures through the tf. Keras. Applications module, enabling users to leverage these powerful CNNs for object recognition and picture categorization applications.
65. How can you handle skewed data distributions in TensorFlow?
Ans:
Handling skewed data distributions in TensorFlow is crucial for training models that perform well across all classes or categories, especially in scenarios where one class is significantly more prevalent than others. Techniques to address class imbalance include either the dominant class is under or oversampled, or both, or utilising methods like the Synthetic Minority Over-sampling Technique (SMOTE)—TensorFlow’s tf. Data API and class_weight parameter in model training provide mechanisms to balance the impact of different classes during training, ensuring fair representation and preventing the model from being biased towards the majority class.
66. How can you handle time series data in TensorFlow?
Ans:
- Handling time series data in TensorFlow involves preprocessing techniques specific to sequential data.
- Sequences are often represented as input features, and recurrent neural networks (RNNs) or extended short-term memory networks (LSTMs) are commonly used architectures for capturing temporal dependencies.
- TensorFlow’s tf.keras.layers.LSTM and tf.keras.layers. Superficial RNN layers facilitate the implementation of these networks.
- Additionally, users can leverage the tf—data API to efficiently handle time series data and create data pipelines for training recurrent models.
67. Explain the concept of graph neural networks in TensorFlow.
Ans:
Graph neural networks (GNNs) in TensorFlow are designed for tasks involving graph-structured data, such as social network analysis or molecular structure prediction. GNNs operate on graph-structured data by considering both node and edge features, allowing them to capture relationships between entities in the graph. TensorFlow’s tf. Experimental.GraphsTuple and tf.keras.layers.GraphConv is an example of functionalities and layers that support the implementation of graph neural networks. GNNs are particularly useful when modelling complex relationships within interconnected data.
68. Explain the concept of gradient clipping in TensorFlow.
Ans:
Gradient clipping in TensorFlow is a regularization technique applied during training to prevent exploding gradients, a common issue in deep learning. It involves scaling gradients when their magnitude exceeds a predefined threshold. This helps stabilize the training process, especially when dealing with deep neural networks or recurrent architectures. TensorFlow provides the tf.clip_by_norm function to clip gradients during optimization, ensuring that the model parameters are controlled and preventing extensive updates that could destabilize the learning process.
69. What is TensorFlow Probability?
Ans:
- TensorFlow Probability is an extension of TensorFlow that focuses on probabilistic modelling and uncertainty estimation.
- It provides tools for building probabilistic models using probabilistic layers, distributions, and probabilistic programming constructs.
- TensorFlow Probability is valuable in scenarios where uncertainty quantification is essential, such as Bayesian modelling, probabilistic time series forecasting, or uncertainty-aware machine learning.
- It seamlessly integrates with TensorFlow, allowing users to combine probabilistic and deterministic components in their models.
70. What are the different activation functions in TensorFlow?
Ans:
TensorFlow supports various activation functions, allowing users to introduce non-linearities into neural network architectures. Common activation functions include the rectified linear unit (ReLU), sigmoid, hyperbolic tangent (tanh), and softmax. ReLU is famous for hidden layers due to its simplicity and effectiveness in combating the vanishing gradient problem. Sigmoid and tanh are often used in binary or scaled output output layers. Softmax is applied in multi-class classification tasks to convert raw logits into probability distributions. TensorFlow’s tf. Keras. The Activations module provides convenient access to these functions during model construction.

Enroll in TensorFlow Certification Training with Advanced Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
71. Explain the concept of custom layers in TensorFlow.
Ans:
Custom layers in TensorFlow allow users to create specialized neural network components tailored to their specific requirements by subclassing the tf.keras.layers.In the layer class, developers can define custom operations and parameters within the layer. This flexibility benefits tasks where standard layers may not suffice, such as implementing custom activation functions, incorporating non-traditional operations, or building complex neural network architectures. Custom layers seamlessly integrate with TensorFlow’s high-level APIs, providing a modular and extensible way to design models that meet specific needs while leveraging the efficiency of TensorFlow’s computational graph.
72. What is the purpose of batch normalisation in TensorFlow?
Ans:
- TensorFlow batch normalisation is used to quicken and stabilise deep neural network training.
- It involves normalising the input of each layer by dividing it by the standard deviation of the mean after subtracting it from the mini-batch during training.
- This helps mitigate the internal covariate shift problem, diminishing the possibility of gradients disappearing or blowing out.
- Batch normalisation is implemented in TensorFlow through the tf.keras.layers.
- BatchNormalization layer is widely used for improving the convergence speed and performance of deep neural networks.
73. How can you implement attention mechanisms in TensorFlow?
Ans:
Attention mechanisms in TensorFlow are essential for capturing context or relevant Information in sequential data, such as natural language or time series. Popular attention mechanisms include the self-attention mechanism found in transformers, enabling the model to weigh different parts of the input sequence differently during processing. TensorFlow provides tools for implementing attention mechanisms, such as the tf.keras.layers.Attention layers can be added to recurrent neural networks or transformer architectures to enhance their ability to focus on specific elements within the input sequence.
74. How can you optimize TensorFlow models for mobile devices?
Ans:
Optimizing TensorFlow models for mobile devices involves techniques to lower the computing demands and size of the model while maintaining performance. TensorFlow provides tools like TensorFlow Lite for model quantization, which reduces the precision of model weights, and post-training quantization, which shrinks the model size. Additionally, techniques like model pruning, where less important weights are removed, and knowledge distillation, where a smaller model is trained to mimic the larger one, are valuable for deploying efficient models on resource-constrained mobile devices.
75. What are the advantages of using TensorFlow Extended (TFX) for production pipelines?
Ans:
TensorFlow Extended (TFX) is a platform for deploying end-to-end machine learning models in production pipelines. TFX provides a comprehensive set of tools for overseeing the entire lifespan of machine learning, starting with data ingestion and preprocessing to model training, serving, and monitoring. The advantages of using TFX for production pipelines include:
- Seamless integration with TensorFlow.
- Built-in support for versioning and tracking.
- The ability to manage and deploy machine learning models at scale.
- TFX’s modular architecture and compatibility with popular orchestration tools make it a powerful framework for building and maintaining robust production-grade machine-learning systems.
76. What are TensorFlow’s different types of gradient descent optimization algorithms?
Ans:
- TensorFlow offers several gradient descent optimization algorithms, each with distinct characteristics suitable for different scenarios.
- Standard optimization algorithms include Stochastic Gradient Descent (SGD), Adagrad, RMSprop, and Adam.
- SGD updates model parameters based on the loss function’s gradient about the parameters.
- Adagrad adapts the learning rates for each parameter individually, while RMSprop and Adam introduce mechanisms to adjust the learning rates dynamically.
- The optimization algorithm selected is determined by the particular task, dataset, and model characteristics being trained in TensorFlow.
77. How can you implement early stopping in TensorFlow?
Ans:
Early stopping in TensorFlow is a regularisation technique used during model training to prevent overfitting and improve generalisation performance. It involves monitoring a validation metric, such as validation loss or accuracy, and stopping training when the metric no longer improves or starts to degrade. TensorFlow provides the tf.keras.callbacks.EarlyStopping callback, which can be integrated into the training process. This callback allows users to set parameters like patience and delta to control when to stop training based on the validation metric, providing an effective way to prevent models from training for too long and overfitting.
78. What is the purpose of TensorFlow’s tf. Distribute. Strategy API?
Ans:
TensorFlow’s tf. Distribute. Strategy API is designed to facilitate distributed training across multiple GPUs or devices. It allows users to parallelize the training process, improving computation efficiency and reducing training times for large-scale models. Tf.distribute.The strategy supports various strategies, including MirroredStrategy for synchronous training on multiple GPUs, MultiWorkerMirroredStrategy for distributed training across multiple workers, and TPUStrategy for training on Google’s Tensor Processing Units. This strategy API enables users to scale their TensorFlow models effectively by seamlessly integrating with high-level APIs like Keras.
79. What is the purpose of the tf.data.experimental.CsvDataset API in TensorFlow?
Ans:
The tf.data.experimental.CsvDataset API in TensorFlow is designed to read efficiently and parse CSV (Comma-Separated Values) files. It provides a way to create a dataset from one or more CSV files, allowing users to work efficiently with structured data for machine learning tasks. CsvDataset supports various parsing options, such as specifying column names and data types and handling missing values, providing a flexible and performant solution for working with CSV data in TensorFlow.
80. Explain the concept of weight regularisation in TensorFlow.
Ans:
Weight regularisation in TensorFlow is a technique used to prevent overfitting by penalising large weights in a neural network. It enhances the loss function with a regularisation term, encouraging the model to learn more straightforward and generalizable representations. L2 regularization penalizes the squared magnitude of weights, while L1 regularization penalizes the absolute magnitude. TensorFlow provides the kernel_regularizer and bias_regularizer parameters in layer constructors to apply weight regularization. This technique is valuable for improving the generalization performance of models, especially in scenarios with limited training data or complex architectures.
81. How can you handle missing data in TensorFlow?
Ans:
Handling missing data in TensorFlow involves preprocessing techniques to address the absence of values within a dataset. TensorFlow provides tools such as the tf. Data.Dataset API for data preprocessing, where users can filter out or impute missing values. Techniques like mean or median imputation, where missing values are replaced with the mean or median of the available data, can be applied using TensorFlow’s mathematical operations. Additionally, TensorFlow’s tf. where function allows users to replace missing values conditionally. Proper handling of missing data is crucial for preventing biased model training and ensuring the robustness of machine learning models.
82. What is TensorFlow Data Validation (TFDV)?
Ans:
- TensorFlow Data Validation (TFDV) is a library that assists in analyzing and validating input data for machine learning models.
- TFDV helps identify missing values, data anomalies, or schema inconsistencies within datasets, providing a comprehensive view of the data’s quality.
- It integrates with TensorFlow’s broader ecosystem, facilitating seamless integration into the machine learning workflow.
- TFDV is particularly valuable during the data preprocessing phase, ensuring that the input data meets the model’s expectations and minimizing the risk of training on flawed or incomplete datasets.
83. Explain the concept of word embeddings in TensorFlow.
Ans:
Word embeddings in TensorFlow are vector representations of words in a continuous vector space. These representations capture semantic relationships between words, allowing a framework for comprehending word meaning and context based on their spatial proximity in the embedding space. TensorFlow provides pre-trained word embeddings, such as Word2Vec or GloVe, and also allows users to train custom embeddings using neural network architectures like Word Embedding Layers in Keras. Word embeddings are essential in natural language processing tasks, enabling models to learn from the contextual meanings of words and improve performance on tasks like sentiment analysis or machine translation.
84. What is the purpose of the tf.data.experimental.SqlDataset API in TensorFlow?
Ans:
The tf.data.experimental.SqlDataset API in TensorFlow enables users to create datasets directly from SQL databases. This functionality streamlines integrating SQL databases with TensorFlow pipelines, allowing efficient and scalable data retrieval. Users can leverage SQL queries to filter, aggregate, and preprocess data directly within the TensorFlow data pipeline. This API is handy in scenarios where the data of interest resides in relational databases, providing a seamless connection between the rich capabilities of SQL and the powerful machine-learning tools in TensorFlow.
85. What is TensorFlow Extended Metadata?
Ans:
TensorFlow Extended Metadata is a TensorFlow Extended (TFX) component designed for managing and tracking metadata throughout the machine learning lifecycle. It captures data about datasets, models, and experiments, providing a unified and organised view of the machine learning workflow. TensorFlow Extended Metadata facilitates versioning, lineage tracking, and collaboration among different stages of the machine learning pipeline. It is an integral part of the TFX ecosystem, ensuring transparency, reproducibility, and accountability in production machine learning systems.
86. How do you use TensorFlow for time series analysis?
Ans:
Using TensorFlow for time series analysis involves leveraging neural network architectures tailored to handle sequential data. Extended short-term memory networks (LSTMs) and recurrent neural networks (RNNs) are common choices for capturing temporal dependencies. TensorFlow provides the tf.keras.layers.LSTM and tf.keras.layers. Superficial RNN layers for building such models. Additionally, attention mechanisms are available through the tf.keras.layers.The attention in l enhances the model’s ability to focus on relevant temporal information. Time series analysis in TensorFlow often involves preprocessing techniques like scaling, windowing, and feature engineering to extract patterns and make accurate predictions effectively.
87. How does TensorFlow support distributed training?
Ans:
TensorFlow supports distributed training, enabling the parallelization of model training across multiple devices or machines. Distributed training in TensorFlow is achieved through the tf. Distribute. Strategy API, which provides different strategies like MirroredStrategy for synchronous training on multiple GPUs, MultiWorkerMirroredStrategy for distributed training across multiple workers, and TPUStrategy for training on Google’s Tensor Processing Units. These strategies allow users to seamlessly scale their TensorFlow models, improving computation efficiency and reducing training times for large-scale deep learning models.
88. What is the purpose of dropout in TensorFlow?
Ans:
- Dropout in TensorFlow is a regularization technique commonly applied during training to prevent overfitting.
- It involves randomly setting a fraction of input units to 0 after every training update, effectively “dropping out” those units.
- This lessens the likelihood that the model will rely too much on specific features or neurons, improving generalization to unseen data.
- TensorFlow implements dropout through the tf.keras.layers.Dropout layer, allowing users to specify the dropout rate.
- Dropout is a valuable tool for enhancing the robustness of deep neural networks, mainly when dealing with complex architectures and limited training data.
89. Explain the concept of regularization loss in TensorFlow.
Ans:
Regularization loss in TensorFlow is a component of the total loss function that penalizes complex or large model parameters. Such L1 or L2 regularization strategies are applied to the loss function to prevent overfitting by discouraging the model from fitting noise in the training data. TensorFlow allows users to incorporate regularization loss through the kernel_regularizer and bias_regularizer parameters in layer constructors, allowing for fine-tuning the balance between fitting the training data and maintaining a simple and generalizable model.
90. How do you perform image classification using TensorFlow?
Ans:
Performing image classification using TensorFlow involves constructing and training convolutional neural networks (CNNs). TensorFlow provides tools like the tf.keras.layers.Conv2D layer for convolutional operations, the tf.keras.layers.MaxPooling2D layer for downsampling, and the tf.keras.layers.Flatten layer for transforming the feature maps into a flat vector. The model is trained using labelled image data with the output layer’s softmax activation function for classification. TensorFlow’s high-level APIs, like Keras, simplify the implementation of image classification models, making it accessible for beginners and experienced developers. Image classification tasks include identifying objects within images, facial recognition, or even medical image analysis.
91. What are the use cases for TensorFlow Recommenders?
Ans:
TensorFlow Recommenders is designed for building recommendation systems, making it particularly useful in various use cases related to personalized content recommendations. Typical applications include recommending products in e-commerce platforms based on user preferences, suggesting movies or music based on viewing history, or enhancing user experience on content streaming services. TensorFlow Recommenders simplifies the development of recommendation models by providing pre-built components and tools tailored to handle sparse input features and efficiently train large-scale recommendation systems.
92. How can you evaluate regression models in TensorFlow?
Ans:
Evaluating regression models in TensorFlow involves assessing the model’s performance in predicting continuous numerical outcomes. Standard metrics for regression evaluation include R-squared, Mean Absolute Error (MAE) and Mean Squared Error (MSE). TensorFlow provides these metrics through the tf. Keras. Metrics module. During the evaluation phase, the model is presented with a separate dataset not used for training, and its predictions are compared against the ground truth to calculate the chosen evaluation metric. This process ensures that the regression model’s generalization performance is thoroughly assessed.
93. How do you perform image segmentation using TensorFlow?
Ans:
- Image segmentation using TensorFlow involves partitioning an image into distinct regions based on semantic or structural characteristics.
- Convolutional neural networks (CNNs) are commonly employed for image segmentation tasks.
- TensorFlow provides tools like the tf. Keras. Layers—conv2D layer for convolutional operations and the tf. Image module for image manipulation. Models for image segmentation often utilize architectures like U-Net or DeepLab.
- The model is trained on annotated images, where each pixel is labelled with the corresponding class or region.
- TensorFlow’s flexibility and high-level APIs make it accessible to implement image segmentation for various applications, including medical imaging and object recognition.
94. Explain a dynamic computation graph in TensorFlow.
Ans:
A dynamic computation graph in TensorFlow is a graph structure that can change during runtime. In contrast to static computation graphs, where the graph structure is fixed before execution, dynamic computation graphs allow for flexibility in handling varying input shapes or sizes. TensorFlow 2. x primarily utilizes eager execution, a dynamic approach where operations are executed immediately as they are called, allowing for dynamic graph construction. This provides advantages in debugging, readability, and handling dynamic inputs, making TensorFlow more intuitive and accessible for developers.
95. Describe the challenges and best practices for deploying TensorFlow models on mobile devices.
Ans:
Deploying TensorFlow models on mobile devices presents both challenges and best practices. Challenges include managing limited computational resources, optimizing model size, and adapting to different hardware architectures. Best practices involve leveraging TensorFlow Lite for model conversion and quantization to reduce model size and improve inference speed. Model pruning, knowledge distillation, and selecting efficient model architectures contribute to addressing resource constraints. Additionally, TensorFlow Lite supports hardware accelerators, such as Android Neural Networks API (NNAPI) and Edge TPU, to enhance performance on mobile devices. Optimizing and deploying TensorFlow models on mobile devices requires a thoughtful balance between model complexity and computational efficiency.
96. How can you implement sequence models in TensorFlow?
Ans:
Implementing sequence models in TensorFlow involves designing neural network architectures capable of handling sequential data. RNNs, recurrent neural networks, LSTMs, or extended short-term memory networks are frequently employed for jobs involving sequence modelling, including natural language processing or time series analysis. TensorFlow provides the tf.keras.layers.LSTM and tf.keras.layers. Superficial RNN layers for building such models. Attention mechanisms are available through the tf.keras.layers.The attentiontion l enhancesnces the model’s ability to focus on relevant information within the sequence. Training sequence models involves processing input data in sequential order and optimizing the model parameters to capture temporal dependencies effectively.
97. How can you handle imbalanced datasets in TensorFlow?
Ans:
Handling imbalanced datasets in TensorFlow is crucial to prevent biased model training.
- Oversampling the minority class.
- Undersampling the majority class.
- Using methods like the Synthetic Minority Over-sampling Technique (SMOTE).
98. How can you perform hyperparameter tuning in TensorFlow?
Ans:
Hyperparameter tuning in TensorFlow involves optimizing the model’s hyperparameters to achieve better performance. Techniques include grid search, random search, or more sophisticated methods like Bayesian optimization—TensorFlow’s tf. Keras. The Tuner module provides tools for implementing hyperparameter tuning. Users can define a hyperparameter search space and employ tuners like RandomSearch or Bayesian Optimization to explore and optimize the hyperparameter combinations. Efficient hyperparameter tuning enhances the model’s performance and generalization across different datasets.
99. How is the Python API used in TensorFlow?
Ans:
- The Python API in TensorFlow is the primary interface for developing machine learning models using the TensorFlow framework.
- Users leverage Python to define model architectures, preprocess data, train models, and perform evaluations.
- TensorFlow’s Python API provides high-level abstractions through modules like tf. Keras for building neural networks, tf.
- Data for efficient data input pipelines, and tf. Train for model training and optimization. Python’s simplicity and extensive ecosystem make TensorFlow accessible to a broad community of developers and researchers.
100. What is the role of learning rate scheduling in TensorFlow?
Ans:
Learning rate scheduling in TensorFlow involves dynamically adjusting the learning rate during model training to optimize convergence and improve performance. Adaptive learning rate methods, such as learning rate decay or schedules like exponential decay or step decay, gradually decrease the learning rate over time. TensorFlow provides learning rate schedulers through callbacks, such as tf.keras.callbacks.LearningRateScheduler. Learning rate scheduling helps prevent oscillations during optimization, accelerates convergence, and enhances the stability of training deep neural networks, particularly in scenarios with complex loss landscapes or varying gradients.




