
Last updated on 09th Dec 2021| 2110
In easy words, data mining is described as a process employed to extract functional data from a larger set of any raw data. It implies analyzing data practices in large batches of data utilizing one or more software. Data mining applies compelling data collection and warehousing as well as computer processing.
- Introduction of MongoDB
- Platforms of MongoDB
- Features / Characteristics of MongoDB
- MongoDB Data types
- Examples of Design Applications
- Data Mining Process
- Why it is needed and important?
- Data mining applications
- Benefits of MongoDB
- Conclusion
Introduction to Data mining:
Data mining is the process of extracting and obtaining patterns from large data sets that incorporate methods at the intersections of machine learning, mathematics, and website systems. Data mining is part of the subfields of computer science and statistics with the general goal of extracting information (in clever ways) from a data set and transforming information into a comprehensive framework for continuous use. Data mining is a step-by-step analysis of the “on-site data acquisition” process, or KDD. , background analysis of acquired properties, display, and renewals online.
The term “data mining” is a misnomer, because the goal is to extract patterns and information, not the extraction (of mines) of the data itself. [6] It is also a buzzword [7] and is often used in any form of big data or data processing (collection, extraction, storage, analysis, and statistics) as well as any use of computer decision-making systems, including technical intelligence (e.g., machine learning) and intelligence. of business. The Data Mining Handbook: Practical machine learning tools and techniques in Java [8] (which mainly includes machine learning materials) would originally be called Active Machine Learning, and the term data mining was only added for marketing reasons. [9] Common words (large scale) are often data analysis and analysis — or, when referring to real-world, machine-wise and machine learning — are very appropriate.
The actual function of data mining is the automatic or automatic analysis of large amounts of data to extract previously unknown, interesting patterns such as data record groups (cluster analysis), unconventional records (confusing discovery), and dependence (organisational excavation, sequential excavation). This often involves using site strategies as local indicators. These patterns may be seen as a form of summary input data, and may be used in further analysis or, for example, in machine learning and forecasting analysis. For example, a data mining step may identify multiple groups in the data, which can be used to obtain more accurate predictor results with a decision support system. Data collection, data processing, or interpretation of results and reporting is not part of the data mining process, but not the entire KDD process as additional steps.

- Displaying an information table and permitting choosing options
- Data reading
- Training predictions and examination learning algorithms
- Data object views, etc.
- Besides, Orange provides a cohesive and fun atmosphere to create the boring analysis tools. It’s very fun to figure.
Tools for Data mining
Data Mining is a set of strategies that use specific algorithms, mathematical analysis, artificial intelligence, and web-based systems to analyse data from a variety of sizes and perspectives.
Data mining tools aim to find patterns / trends / groups between large data sets and convert data into highly refined information.
It is a framework, the same as Rstudio or Tableau that enables you to perform differing types of knowledge mining analysis.
It will perform varied algorithms like merging or dividing your information set and visualising the results itself. It’s a framework that gives the United States of America higher details of our information and therefore the standing of the information described. Such a framework is named an information mining tool.
Orange could be a complete machine learning software package organisation and mining information. Supports detection and is software package supported Python pc-based elements and developed within the bioinformatics laboratory within the school of computer and knowledge science, Ljubljana University, Slovenia.
As it could be a component-based software package, elements of Orange square measure are referred to as “widgets.” These widgets vary from pre-processing and information show to experimental algorithms and inevitable modelling.
Widgets deliver necessary functions such as:
Why Orange?
Data up to orange is instantly formatted to the required pattern, and moving widgets may be simply transferred once required. Orange is incredibly attention-grabbing for users. Orange permits its users to create good choices in an exceedingly short amount of your time by quickly examining and analysing information.It is an image of fine open supply information and experiments poignant beginners and professionals. data processing may be through a visible system or with Python scripting. Most analyses square measure done via the visual piece of writing interface (drag and drop links and widgets) and plenty of visual tools square measure usually supported like bar charts, scatterplots, trees, dendrograms, and temperature maps. an outsized variety of widgets (over 100) square measure sometimes supported.
DMelt could be a multi-forum tool labelled JAVA. It will work on any JVM compatible package (Java Virtual Machine). Contains scientific and mathematical libraries.
Scientific libraries:
Science libraries square measure accustomed to drawing 2nd / 3D episodes.
Statistical libraries:
Mathematical libraries square measure accustomed to generating random numbers, algorithms, curves, etc. DMelt may be accustomed to analysing massive amounts of knowledge, data processing, and applied maths analysis. It’s widely used in scientific discipline, money markets, and engineering.

Features / Characteristics
Data mining analysis was performed using analytical focus structures. Such structures can be the unique property of the focus part. Sometimes they can be features of a higher level than the level of the focus part. You can use a variety of complex profile features to capture the analytical focus features you want to incorporate into your data mining analysis. All features lead to one column in the output table. Different feature types are associated with different input modification methods so that the required analysis focus elements are calculated.

Learn Advanced Data Science Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch DetailsFocus attribute
Properties that rely solely on a single focal point, for example, store or date, are the simplest because their values are more than the values already contained in the original website tables.
Consolidation
In general, many buildings are the result of merging. Each purchase level is too good to be predictable, so multiple purchase features should be combined with a reasonable level of focus. Typically, integration is performed at all levels of concentration. In the example of predicting individual store sales, this means the final combination with the date.
Combined division
When analysing stores, especially their sales performance, it is customary to include sales that are part of the departments that are important in analysis. You can do this by dividing the daily sales price into sales prices for each department. This is a common way of analysing data in many areas.
Understanding
Some data mining algorithms require phase input instead of numeric input. In this case, the data must be processed in advance so that the values in a particular numerical range are mapped into different values.
Value adjustment
Similarly with the division of numerical elements you can assign new values to get different value values.
Calculation
To calculate the feature in some features, any SQL expression can be tested. The calculation can be as simple as adding or separating two elements, or it can be as complex as the problem requires.
Types of data that can be mined:
1. Data stored on the website
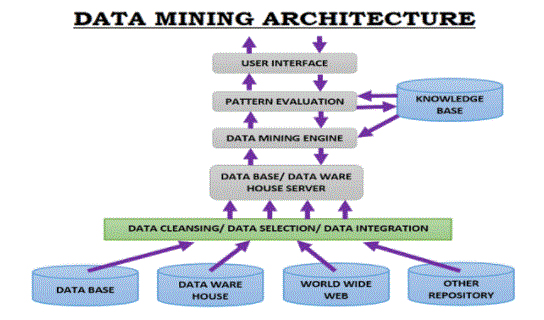
Database management system or DBMS. Every DBMS stores related data in one way or another. It also has a set of software programs used to manage data and provide easy access to it. These software programs have many purposes, including defining a website structure, ensuring that archives remain secure and consistent, and managing different types of data access, such as sharing, distribution, and compliance. Related websites have tables with different names, attributes, and can store lines or records of large data sets. All records stored in a table have a unique key. The business relationship model was created to provide representation of a related website that integrates businesses and the relationships that exist between them.
2. Data repository
A data warehouse is a single data warehouse that collects data from multiple sources and stores it in an integrated system. When data is stored in a database, it is cleaned, compiled, loaded, and updated. The data stored in the database is organised into several parts. If you are looking for information on data stored after 6 or 12 months, you will find it in the form of a summary.
3. Activity data
Activity records keep records that are considered transactions. These functions include flight booking, customer purchases, website clicks, and more. All transaction records have a unique ID. It also lists all those things that made it a transaction.
4. Other types of data
We have many other types of data known for their structure, semantic definitions, and variability. They are used in many varieties. Here are a few of those types of data: streaming data, engineering design data, sequencing data, graph data, location data, multimedia data, and more.
Examples of Design Applications:
The predictive capacity of data mining has changed the structure of business strategies. Now, you can understand the present and anticipate the future. These are just some of the examples of data mining in the current industry.
Marketing
Data mining is used to test growing databases and to improve market fragmentation. By analysing the relationships between parameters such as customer age, gender, preferences, etc., it is possible to guess their behaviour in order to direct personal loyalty campaigns. Data mining in advertising also predicts which users may opt out of the service list, what interests them based on their searches, or what should be included in the mailing list for a higher response rate. For sale. Supermarkets, for example, use collective buying patterns to identify product associations and determine how they are placed in hallways and shelves. Data mining also determines which offers are most important to customers or increasing sales in the exit line.
Banks
Banks use data mining to better understand market risk. It is often used in credit ratings and on fraudulent schemes to analyse transactions, card transactions, purchase patterns and customer financial data. Data mining also allows banks to learn more about their online options or practises in order to improve returns on their marketing campaigns, learn how channel sales work or manage compliance obligations.
The tree
Data mining enables a more accurate diagnosis. Having all patient information, such as medical records, physical examinations, and treatment patterns, allows for more effective treatment to be determined. It also empowers them to manage health services more efficiently, effectively and inexpensively by diagnosing risks, predicting disease in certain segments of the population or predicting length of hospital stay. Detecting fraud and malpractice, and strengthening relationships with patients with advanced knowledge of their needs are also benefits of using medical data mining.
Data Mining Process:
Before actual data mining can take place, there are a few processes involved in starting data mining. Here’s how:
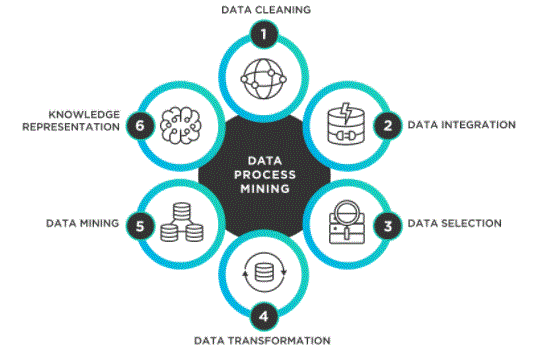
Step 1: Business Research – Before you start, you need to fully understand the purpose of your business, the resources available, and the current situation in line with its needs. This will help to create a detailed data mining system that effectively achieves the objectives of the organisations.
Step 2: Data Quality Assessment – As data is collected from a variety of sources, it needs to be monitored and compared to ensure that there are no restrictions on the data collection process. Quality assurance helps to identify any hidden ambiguities in the data, such as the lack of interpolation of data, to keep the data up to standard before going to the mine.
Step 3: Data Purification – It is believed that 90% of the time is spent on sorting, cleaning, formatting and unfamiliar data before mining.
Step 4: Data Transformation – Comprising five sub-categories, here, the processes involved make the data suitable for the final data sets. Includes:
Data Smoothing: Here, the sound is removed from the data.
Data Summary: The compilation of data sets is used in this process.
Data Execution: Here, data is processed in a standard way by replacing any low-level data with high-quality ideas.
General Data Performance: Here, the data is defined in the default range.
Data Identifier Development: Data sets need to be in the attribute set before data mining.
Step 5: Making a Data Model: For better data identification, a few statistical models are used in the database, based on a few cases. Learn data science to understand and apply the power of data mining.
Why it is important?
Data mining is the process of capturing large data sets to identify the details and ideas of that data. Today, the demand for the data industry is growing rapidly which has increased the demands of data analysts and data scientists.
In this way, we analyse the data and convert that data into useful information. This helps the business to make better and better decisions for the organisation; Data mining helps to develop smart market decisions, drive accurate campaigns, guesses, and more With the help of data mining, we can analyse customer behaviour and their details. This leads to greater success and more data driven business.
Data mining applications:
Below are some of the most useful data mining apps that inform us more about them.
1. Health care
Data mining has the potential to completely transform the health care system. It can be used to identify advanced data-based and statistical processes, which can help health care facilities reduce costs and improve patient outcomes. Data mining, as well as machine learning, statistics, visualisation, and other techniques can be used to make a difference. It can be helpful when predicting patients of different stages. This will help patients to receive intensive care when and where they need it. Data mining can also help health care insurers identify fraudulent activities
2. Education
The use of educational data mining is still in your first phase. It aims to develop strategies that can use data from educational institutions to test information. Expected objectives of these strategies include learning how academic support affects students, supporting students’ future needs, and promoting learning science among other things. Educational institutions can use these strategies to not only predict how students will perform in tests but also to make informed decisions.
3. Market basket analysis
This is a modelling method that uses the hypothesis as a basis. The hypothesis states that if you buy certain products, you are more likely to buy products that do not belong to the same group that you buy from. Vendors can use this process to understand the buying habits of their customers. Retailers can use this information to make changes to their store structure and make purchases much easier and less time consuming for customers.
4. Customer Relationship Management (CRM)
CRM involves customer acquisition and retention, improving trust, and implementing customer-focused strategies. Every business needs customer data to analyse and apply its findings in a way that can build lasting relationships with their customers. Data mining can help them do just that.
5. Production engineering
The manufacturing company relies heavily on data or information from it. Data mining can assist these companies in identifying patterns in processes that are too complex for the human mind to comprehend. They can identify the relationships that exist between different design-level design elements, including customer data requirements, properties, and product portfolio. Data mining can also be useful in predicting all the time required for product development, the costs involved in this process, and what companies might expect from the final product.
6. Finance and banking
The banking system has seen the production of large amounts of data since its digitalization. Banks can use data mining techniques to solve the banking and financial problems that businesses face by finding related links to market costs and business information. This task is very difficult without data mining as the amount of data they face is very large. Managers in the banking and finance sectors can use this information to acquire, store, and care for a customer.
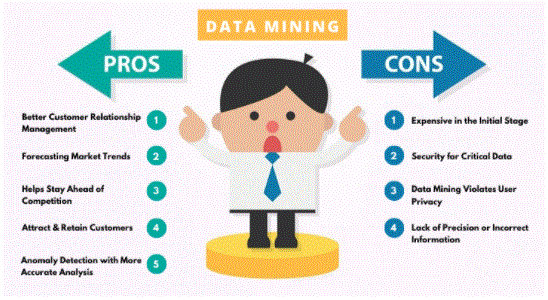
- Helps companies collect reliable information
- It is a practical, inexpensive solution compared to other data applications
- It helps businesses to make profitable production and performance improvements
- Data mining uses both new systems and assets
- It helps businesses make informed decisions
- It helps to identify debt risks and fraud
- It helps data scientists easily analyse large amounts of data quickly
- Data scientists can use the information to detect fraud, create risk models, and improve product security
- It helps data scientists quickly start automated behavioural predictions and trends and discover hidden patterns
Benefits of Data Mining:
As we live and work in a data-centred world, it is important to get as many benefits as possible. Data mining provides us with solutions to problems and problems in this challenging information age. Benefits of data mining include:
Conclusion
Data mining involves a variety of methods from different fields, including data display, machine learning, database management, statistics, and more. These approaches can be developed to work together to deal with complex problems. Typically, data mining software or programs use one or more of these methods to address different data needs, data types, application locations, and mining operations.
It is important to note that it takes time to obtain valid information from the data. Therefore, if you are behind making your business grow faster, there is a need to make informed and quick decisions that can take advantage of the opportunities available over time.
Data mining is a fast-growing industry in this technologically focused world. Everyone these days needs to have their data used correctly and efficiently in order to obtain useful and accurate information.




