
Last updated on 05th Jan 2022| 3530
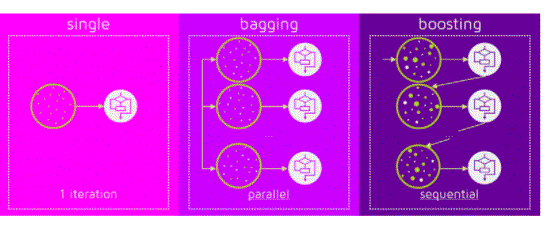
Bagging Vs Boosting:
We all use decision tree techniques in daily life to make decisions. Organisations use these supervised machine learning techniques such as decision trees to make better decisions and generate more surplus and profit.
Ensemble methods combine different decision trees to produce better predictive results, the latter using a single decision tree. The primary principle behind the ensemble model is that a group of weak learners come together to form an active learner. Given below are the two techniques that are used to do the Ensemble Decision Tree.
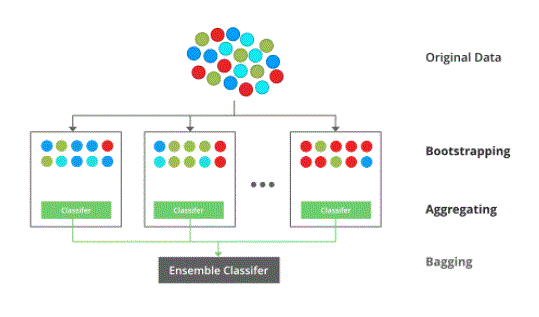
- Several subsets are created from the original dataset, selecting the observations with replacement.
- A base model (weak model) is built on each of these subsets.
- Models run in parallel and are independent of each other.
- The final predictions are determined by combining the predictions of all the models.
Bagging:
Bagging is used when our objective is to reduce the variance of a decision tree. The concept here is to create some subset of data from the training sample, which is randomly selected with replacement. Now each collection of subset data is used to prepare their decision trees, thus, we end up with a bunch of different models. The average of all estimates from multiple branches is used, which is more powerful than a decision tree.
There is an extension on Random Forest Bagging. An additional step has to be taken to predict a random subset of the data. It also does random selection of features instead of using all the features to grow the tree. When we have many random trees, it is called a random forest. Let us consider X observation Y features in the training data set. First, a model from the training data set is taken at random with replacement. The tree is the largest developed.
The given steps are repeated, and a prediction is given, which is based on a collection of predictions from a number of trees.
- It handles high dimension data sets very well.
- It manages missing quantities and maintains accuracy for missing data.
- Disadvantages of using random forest technique:
- Since the final prediction depends on the mean predictions from the subset trees, it will not give accurate values for the regression model.
- It supports various loss functions.
- It works well with conversation.
Advantages of using Random Forest technique & Advantages of using Gradient Boosting methods:
Advantages of using the Random Forest Technique:
Benefits of using gradient boosting methods:
- Boosting is another ensemble process to produce a collection of predictions. In other words, we fit consecutive trees, usually random samples, and at each step, the objective is to resolve the net error from the previous trees.
- If a given input is misclassified by the theory, its weight is increased so that the ensuing hypothesis is more likely to classify it correctly, eventually outperforming the weaker learners by integrating the whole set. be converted into a model.
- Gradient boosting is an extension of the boosting process.
- Gradient Boosting = Gradient Descent + Boosting.
- It uses a gradient descent algorithm that can optimise any differentiable loss function. A group of trees is built individually, and the individual trees are summed up sequentially. The next three tries to restore the loss (this is the difference between the actual and predicted values).
- A subset is created from the original dataset.
- Initially, equal weighting is given to all data points.
- A base model is built on this subset.
- This model is used to make predictions on the entire dataset.
- Errors are calculated using actual values and estimated values.
- Observations that are wrongly predicted are given more weight. (Here, the three misclassified blue-plus points will be given more importance)
- Another model is built and predictions are made on the dataset. (This model attempts to correct the errors of the previous model)
- Similarly, several models are created, each of which corrects the errors of the previous model.
- The final model (strong learners) is the weighted mean of all models (weak learners).
- Thus, the boosting algorithm combines several weak learners to form a strong learner.
- Individual models will not perform well on the whole dataset, but they work well for some part of the dataset.
- Thus, each model actually enhances the performance of the ensemble.
Boosting::
Let us understand how Boosting works in the steps given below.

- Different training data subsets are randomly generated with replacements from the entire training dataset. Each new subset contains components that were misclassified by previous models.
- Bagging attempts to tackle the over-fitting issue. Boosting tries to reduce bias.
- If the classifier is unstable (high variance), we need to apply bagging. If the classifier is stable and straight (high bias), we need to apply boosting.
- Each model receives an equal weight. Models are weighted by their performance.
- Aim to reduce variance, not bias. Aim to reduce bias, not variation.
- This is the easiest way to combine predictions of the same type. It is a way to combine predicates belonging to different types.
- Each model is manufactured independently. New models are affected by the performance of previously developed models.
Difference between Bagging and Boosting:
Bagging boosting
- Bagging and boosting obtain N learners by generating additional data in the training phase.
- N new training data sets are generated by random sampling with replacement from the original set.
- Some observations can be replicated in each new training data set by sampling with replacement.
- In the case of bagging, any element has an equal probability of appearing in the new data set.
- However, observations are valued for boosting and so some of them will participate more frequently in new sets.
- These multiple sets are used to train the same Learner algorithm and hence different classifiers are created.
Getting N learners for Bagging and Boosting:

Develop Your Skills with Advanced Machine Learning Certification Training
Weekday / Weekend BatchesSee Batch Details- The result in bagging is obtained by averaging the responses of n learners (or majority votes).
- However, boosting provides a second set of weights, this time for N classifiers, to take a weighted average of their estimates.
- Classification stage in action
- In the boosting training phase, the algorithm assigns weights to each resulting model.
- The learner with good classification results on the training data will be assigned a higher weight than the poor one.
- So while evaluating a new learner, boosting needs to keep track of the learners’ errors as well.
- Difference in processes
- Some boosting techniques include an additional condition to keep or discard a single learner.
- For example, the most famous, AdaBoost, requires less than 50% error to maintain the model; Otherwise, the iteration is repeated until a better learner is obtained from a random guess.
- The previous image shows the general process of a boosting method, but several options exist for determining the weights to be used in the next training phase and in the classification phase.
Classification stage in action:
We only need to apply N learners to the new observations to predict the class of the new data.
It is shown diagrammatically below:
Let’s look at the difference in procedures:
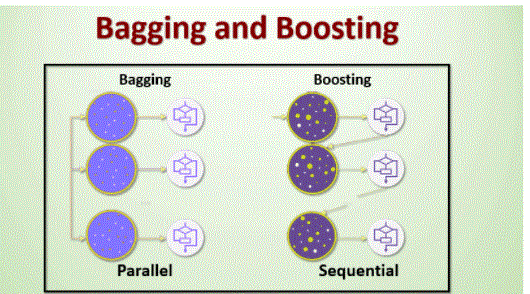
- Now, the question that may come to our mind is whether to choose bagging or boosting for a particular problem.
- It depends on the data, simulation and circumstances.
- Bagging and boosting reduce the variance of your single estimate because they combine multiple estimates from different models. So the result can be a model with high stability.
- If the problem is that a single model gets very little performance, then bagging will rarely get better bias. However, boosting can generate a combined model with fewer errors because it optimises the advantages and minimises the disadvantages of a single model.
- Conversely, if the difficulty of a single model is overfitting, then bagging is the best option. Boosting for its part doesn’t help avoid over-fitting.
- Actually, this technology is struggling with this problem itself. For this reason, bagging is more often effective than boosting.
- Similarities Between Bagging and Boosting
- Back to Notebook Contents
- Both are collective methods for getting from 1 learner to N learners.
- Both generate multiple training data sets by random sampling.
- Both take the final decision taking the average of N learners (or majority of them i.e. majority voting).
- Both are good at reducing variance and provide high stability.
Selecting the best technique- Bagging or Boosting:
The similarities between Bagging and Boosting are as follows:-
- Bagging is the simplest way to combine predictions of the same type whereas boosting is a way to combine predictions belonging to different types.
- The aim of bagging is to reduce the variance, not the bias whereas the aim of boosting is to reduce the bias, not the variance.
- In bagging each model gets equal weighting whereas in boosting the models are weighted according to their performance.
- In bagging each model is created independently whereas in boosting new models are affected by the performance of the already built model.
- In bagging different training data subsets are randomly generated with replacement from the entire training dataset. Boosting each new subset includes elements that were misclassified by the previous model.
- Bagging tries to solve the over-fitting problem while boosting tries to reduce the bias.
- If the classifier is unstable (high variance), we should apply bagging. If the classifier is stable and simple (high bias) then we should apply boosting.
- Bagging has been extended to the Random Forest model while boosting has been extended to Gradient Boosting.
Which one to choose either bagging or Boosting :
- In this kernel, we discuss two very important ensemble learning techniques – bagging and boosting.
- We have discussed Bootstrapping, Bagging and Boosting in detail.
- We have discussed the classification step in action.
- Then, we’ve shown how to choose the best technique – bagging or boosting – for a particular problem.
- Finally, we have discussed the similarities and differences between bagging and boosting.
- I hope this article has given you a solid understanding of Bagging and Boosting.
- Bagging (or Bootstrap aggregation), is a simple and very powerful ensemble method. Bagging is the application of a bootstrap process to a high-variance machine learning algorithm, typically a decision tree.
- The idea behind bagging is to combine the results of multiple models (for example, all decision trees) to obtain a generalised result. Now, bootstrapping comes into the picture.
- The bagging (or bootstrap aggregating) technique uses these subsets (bags) to get a fair idea of the distribution (the complete set). The size of the subset created for bagging may be less than the original set.Boosting is a gradual process, where each subsequent model tries to correct the errors of the previous model. Successful models are dependent on previous models.
- In this technique, learners are learned sequentially in which early learners fit simple models to the data and then analyse the data for errors. In other words, we fit a consecutive tree (random sample) and at every step, the goal is to solve the net error from the previous tree.
- When an input is misclassified by one hypothesis, its weight is increased so that the next hypothesis is more likely to classify it correctly. Finally, combining the entire set, converts the weaker learners into better performing models.
Conclusion:




