
Last updated on 08th Jul 2020| 2336
Cassandra is a fully distributed, masterless database, offering superior scalability and fault tolerance to traditional single master databases. Compared with other popular distributed databases like Riak, HBase, and Voldemort, Cassandra offers a uniquely robust and expressive interface for modeling and querying data. What follows is an overview of several desirable database capabilities, with accompanying discussions of what Cassandra has to offer in each category.
Apache Cassandra is a highly scalable, high-performance distributed database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. It is a type of NoSQL database. Let us first understand what a NoSQL database does.
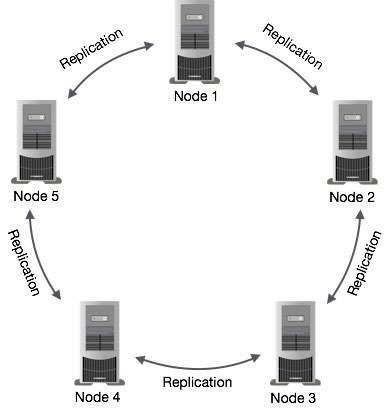
Data Replication in Cassandra
In Cassandra, one or more of the nodes in a cluster act as replicas for a given piece of data. If it is detected that some of the nodes responded with an out-of-date value, Cassandra will return the most recent value to the client. After returning the most recent value, Cassandra performs a read repair in the background to update the stale values.
The following figure shows a schematic view of how Cassandra uses data replication among the nodes in a cluster to ensure no single point of failure.
Components of Cassandra
The key components of Cassandra are as follows:
- Node: It is the place where data is stored.
- Data center: It is a collection of related nodes.
- Cluster: A cluster is a component that contains one or more data centers.
- Commit log: The commit log is a crash-recovery mechanism in Cassandra. Every write operation is written to the commit log.
- Mem-table: A mem-table is a memory-resident data structure. After commit log, the data will be written to the mem-table. Sometimes, for a single-column family, there will be multiple mem-tables.
- SSTable: It is a disk file to which the data is flushed from the mem-table when its contents reach a threshold value.
- Bloom filter: These are nothing but quick, nondeterministic, algorithms for testing whether an element is a member of a set. It is a special kind of cache. Bloom filters are accessed after every query.
Architecture Requirements of Cassandra
Cassandra was designed to address many architecture requirements. The most important requirement is to ensure there is no single point of failure. This means that if there are 100 nodes in a cluster and a node fails, the cluster should continue to operate.
This is in contrast to Hadoop where the namenode failure can cripple the entire system. Another requirement is to have massive scalability so that a cluster can hold hundreds or thousands of nodes. It should be possible to add a new node to the cluster without stopping the cluster.
Further, the architecture should be highly distributed so that both processing and data can be distributed. Also, high performance of read and write of data is expected so that the system can be used in real time.
Cassandra Architecture
Some of the features of Cassandra architecture are as follows:
- Cassandra is designed such that it has no master or slave nodes.
- It has a ring-type architecture, that is, its nodes are logically distributed like a ring.
- Data is automatically distributed across all the nodes.
- Similar to HDFS, data is replicated across the nodes for redundancy.
- Data is kept in memory and lazily written to the disk.
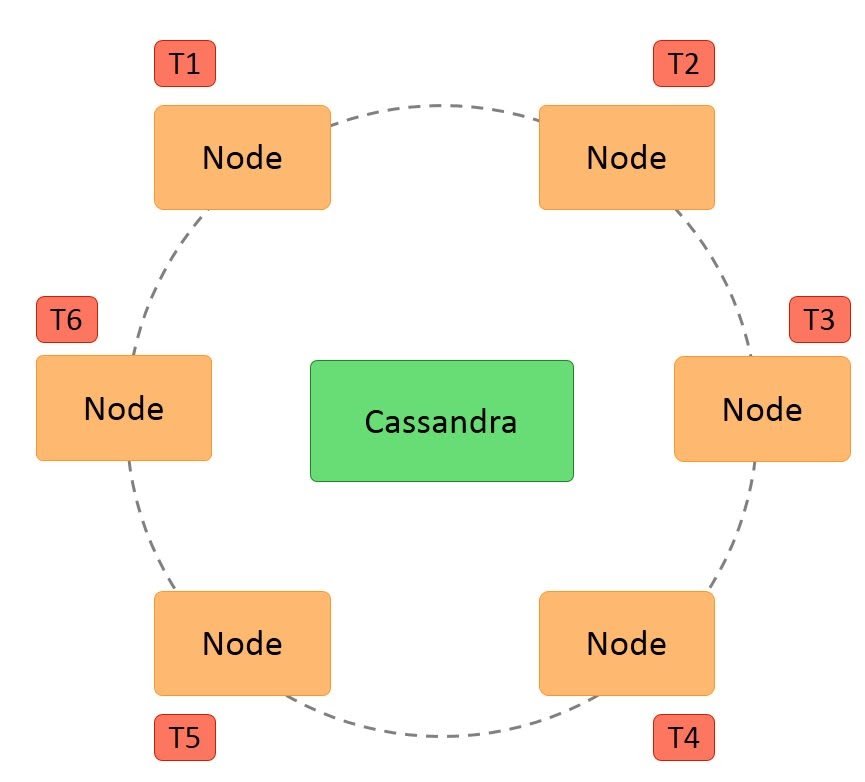
- Hash values of the keys are used to distribute the data among nodes in the cluster.
A hash value is a number that maps any given key to a numeric value.
For example, the string ‘ABC’ may be mapped to 101, and decimal number 25.34 may be mapped to 257. A hash value is generated using an algorithm so that the same value of the key always gives the same hash value. In a ring architecture, each node is assigned a token value, as shown in the image below:
Additional features of Cassandra architecture are:
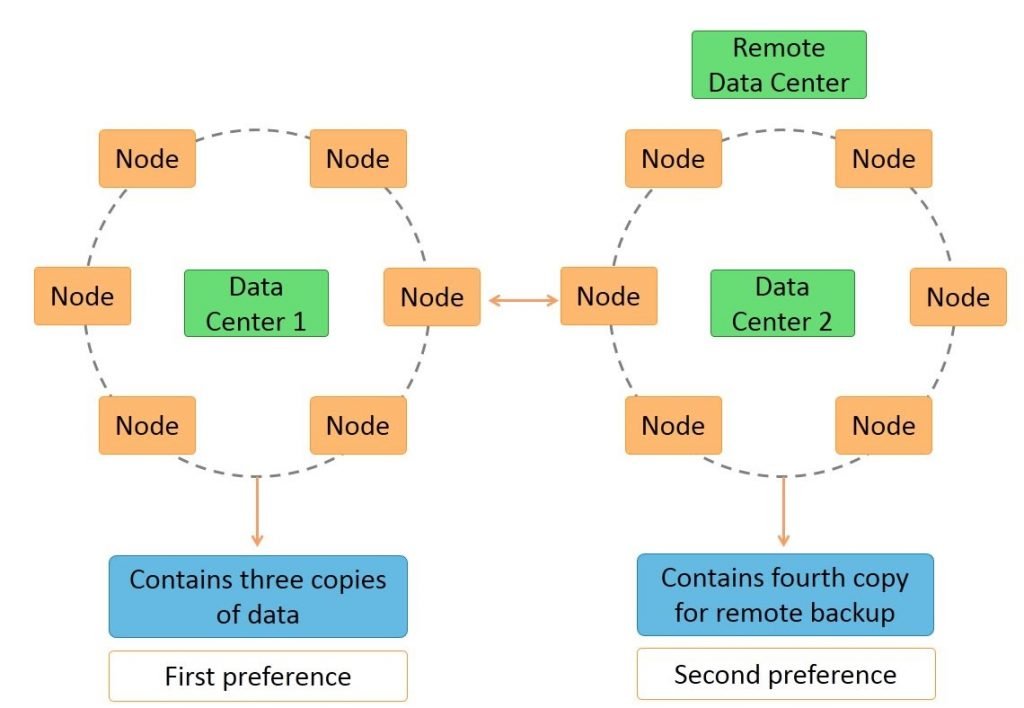
- Cassandra architecture supports multiple data centers.
- Data can be replicated across data centers.
You can keep three copies of data in one data center and the fourth copy in a remote data center for remote backup. Data reads prefer a local data center to a remote data center.
The design goal of Cassandra is to handle big data workloads across multiple nodes without any single point of failure. Cassandra has a peer-to-peer distributed system across its nodes, and data is distributed among all the nodes in a cluster.
- All the nodes in a cluster play the same role. Each node is independent and at the same time interconnected to other nodes.
- Each node in a cluster can accept read and write requests, regardless of where the data is actually located in the cluster.
- When a node goes down, read/write requests can be served from other nodes in the network.
How does Cassandra Work?
Apache Cassandra is a peer-to-peer system. Its distribution design is modeled on Amazon’s Dynamo, and its data model is based on Google’s Big Table. The basic architecture consists of a cluster of nodes, any and all of which can accept a read or write request. This is a key aspect of its architecture, as there are no master nodes. Instead, all nodes communicate equally.
While nodes are the specific location where data lives on a cluster, the cluster is the complete set of data centers where all data is stored for processing. Related nodes are grouped together in data centers. This type of structure is built for scalability and when additional space is needed, nodes can simply be added. The result is that the system is easy to expand, built for volume, and made to handle concurrent users across an entire system.
Its structure also allows for data protection. To help ensure data integrity, Cassandra has a commit log. This is a backup method and all data is written to the commit log to ensure data is not lost. The data is then indexed and written to a memtable. The memtable is simply a data structure in the memory where Cassandra writes. There is one active memtable per table.
When memtables reach their threshold, they are flushed on a disk and become immutable SSTables. More simply, this means that when the commit log is full, it triggers a flush where the contents of memtables are written to SSTables. The commit log is an important aspect of Cassandra’s architecture because it offers a failsafe method to protect data and to provide data integrity.
Various Components of Cassandra Keyspace:
- Strategy: While declaring strategy name in Cassandra. There are two kinds of strategies declared in Cassandra Syntax.
- Simple Strategy: Simple strategy is used when you have just one data center. In this strategy, the first replica is placed on the node selected by the partitioned. Remaining nodes are placed in the clockwise direction in the ring without considering rack or node location.
- Network Topology Strategy: Network topology strategy is used when you have more than one data centers. In this strategy, you have to provide replication factor for each data center separately. Network topology strategy places replicas in nodes in the clockwise direction in the same data center. This strategy attempts to place replicas in different racks.
- Replication Factor: Replication factor is the number of replicas of data placed on different nodes. For no failure, 3 is a good replication factor. More than two replication factors ensures no single point of failure. Sometimes, the server can be down, or network problems can occur, then other replicas provide service with no failure.

Learn Apache Cassandra Certification Course to Build Your Skills
Weekday / Weekend BatchesSee Batch DetailsWho Should Use Cassandra?
If you need to store and manage large amounts of data across many servers, Cassandra could be a good solution for your business. It’s ideal for businesses that can’t afford for data to be lost or that can’t have their database down due to the outage of a single server. Further, it’s also easy to use and easy to scale, making it ideal for businesses that are consistently growing.
At its core, Apache Cassandra’s structure is “built-for-scale” and can handle large amounts of data and concurrent users across a system. It lets major corporations store massive amounts of data in a decentralized system. Yet, despite the decentralization, it still allows users to have control and access to data.
And, data is always accessible. With no single point of failure, the system offers true continuous availability, avoiding downtimes and data loss. Additionally, because it can be scaled by simply adding new nodes, there is constant uptime and no need to shut the system down to accommodate more customers or more data. Given these benefits, it’s not surprising that so many major companies utilize Apache Cassandra.
Cassandra Interfaces
There are many interfaces with which you can access data from Cassandra, such as:
- The command line interface known as Cassandra Query Language shell or cqlsh
- The Java interface called DataStax Driver
- The ODBC
- PHP interface
- Python interface
- Ruby interface
- C# and .Net interface
In this tutorial, you will learn about the command line, Java, and ODBC interfaces for Cassandra. Let us start with the Cassandra command line interface in the next section.
Cassandra Command Line Interface
You have already learned about connecting to Cassandra using the command line interface. The command line interface in Cassandra is called cqlsh. In cqlsh, the host and port connect to Cassandra using the CQLSH_HOST and CQLSH_PORT environment variables respectively.
The default host is localhost or 127.0.0.1, and the default port is 9160. Cqlsh is part of the package installation and installed to a bin directory on Linux. Its working is also similar to that of the Linux shell. Cqlsh supports the Cassandra Query Language or CQL.
Start cqlsh using the command cqlsh. It gives the Cassandra cqlsh prompt as output.
Java Interfaces
In Cassandra, the Java interface is provided by the DataStax Java Driver. It uses CQL binary protocol and provides asynchronous processing so that clients do not have to wait. It also provides automatic nodes discovery.
This means the driver finds and uses all the nodes in the cluster. The Java driver is also fault tolerant. If a Cassandra node processing the request fails, the driver will automatically connect to other nodes in the cluster. Lastly, the Java driver provides Cassandra keyspace schema in a usable manner.
ODBC Interface
DataStax provides the ODBC driver for Cassandra. ODBC is a standard interface used by some database utilities. The ODBC driver for 64-bit windows can be downloaded from the given link.
You can configure the ODBC connection to Cassandra using the above driver. The ODBC driver makes it possible to connect to Cassandra from other languages like PHP, Python, and C#.
Data model
- Cassandra is wide column store, and, as such, essentially a hybrid between a key-value and a tabular database management system. Its data model is a partitioned row store with tunable consistency. Rows are organized into tables; the first component of a table’s primary key is the partition key; within a partition, rows are clustered by the remaining columns of the key. Other columns may be indexed separately from the primary key.
- Tables may be created, dropped, and altered at run-time without blocking updates and queries.
- Cassandra cannot do joins or subqueries. Rather, Cassandra emphasizes demoralization through features like collections.
- A column family (called “table” since CQL 3) resembles a table in an RDBMS (Relational Database Management System). Column families contain rows and columns. Each row is uniquely identified by a row key. Each row has multiple columns, each of which has a name, value, and a timestamp. Unlike a table in an RDBMS, different rows in the same column family do not have to share the same set of columns, and a column may be added to one or multiple rows at any time.
- Each key in Cassandra corresponds to a value which is an object. Each key has values as columns, and columns are grouped together into sets called column families. Thus, each key identifies a row of a variable number of elements. These column families could be considered then as tables. A table in Cassandra is a distributed multi-dimensional map indexed by a key. Furthermore, applications can specify the sort order of columns within a Super Column or Simple Column family.
Cassandra – Cqlsh
Cassandra is a Java-based system that can be managed and monitored via Java Management Extensions (JMX). The JMX-compliant nodetool utility, for instance, can be used to manage a Cassandra cluster (adding nodes to a ring, draining nodes, decommissioning nodes, and so on). Nodetool also offers a number of commands to return Cassandra metrics pertaining to disk usage, latency, compaction, garbage collection, and more.
Since Cassandra 2.0.2 in 2013, measures of several metrics are produced via the Dropwizard metrics framework, and may be queried via JMX using tools such as JConsole or passed to external monitoring systems via Dropwizard-compatible reporter plugins.
By default, Cassandra provides a prompt Cassandra query language shell (cqlsh) that allows users to communicate with it. Using this shell, you can execute Cassandra Query Language (CQL).
Using cqlsh, you can:
- define a schema,
- insert data, and
- execute a query.
Starting cqlsh
Start cqlsh using the command cqlsh as shown below. It gives the Cassandra cqlsh prompt as output.
- [hadoop@linux bin]$ cqlsh
- Connected to Test Cluster at 127.0.0.1:9042.
- [cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]
Use HELP for help.
cqlsh>
Cqlsh: As discussed above, this command is used to start the cqlsh prompt. In addition, it supports a few more options as well. The following table explains all the options of cqlsh and their usage.
| Options | Usage |
|---|---|
| cqlsh –help | Shows help topics about the options of cqlsh commands. |
| cqlsh –version | Provides the version of the cqlsh you are using. |
| cqlsh –color | Directs the shell to use colored output. |
| cqlsh –debug | Shows additional debugging information. |
| cqlsh –executecql_statement | Directs the shell to accept and execute a CQL command. |
| cqlsh –file= “file name” | If you use this option, Cassandra executes the command in the given file and exits. |
| cqlsh –no-color | Directs Cassandra not to use colored output. |
| cqlsh -u “user name” | Using this option, you can authenticate a user. The default user name is: cassandra. |
| cqlsh-p “pass word” | Using this option, you can authenticate a user with a password. The default password is: cassandra. |
Cqlsh Commands
Cqlsh has a few commands that allow users to interact with it. The commands are listed below.
Documented Shell Commands
Given below are the Cqlsh documented shell commands. These are the commands used to perform tasks such as displaying help topics, exit from cqlsh, describe,etc.
- HELP: Displays help topics for all cqlsh commands.
- CAPTURE: Captures the output of a command and adds it to a file.
- CONSISTENCY: Shows the current consistency level, or sets a new consistency level.
- COPY: Copies data to and from Cassandra.
- DESCRIBE: Describes the current cluster of Cassandra and its objects.
- EXPAND: Expands the output of a query vertically.
- EXIT: Using this command, you can terminate cqlsh.
- PAGING: Enables or disables query paging.
- SHOW: Displays the details of current cqlsh session such as Cassandra version, host, or data type assumptions.
- SOURCE: Executes a file that contains CQL statements.
- TRACING: Enables or disables request tracing.
CQL Data Definition Commands
- CREATE KEYSPACE: Creates a KeySpace in Cassandra.
- USE: Connects to a created KeySpace.
- ALTER KEY SPACE: Changes the properties of a KeySpace.
- DROP KEY SPACE: Removes a KeySpace
- CREATE TABLE: Creates a table in a KeySpace.
- ALTER TABLE: Modifies the column properties of a table.
- DROP TABLE: Removes a table.
- TRUNCATE: Removes all the data from a table.
- CREATE INDEX: Defines a new index on a single column of a table.
- DROP INDEX: Deletes a named index.
CQL Data Manipulation Commands
- INSERT: Adds columns for a row in a table.
- UPDATE: Updates a column of a row.
- DELETE: Deletes data from a table.
- BATCH: Executes multiple DML statements at once.
CQL Clauses
- SELECT: This clause reads data from a table
- WHERE: The where clause is used along with select to read a specific data.
- ORDERBY: The orderby clause is used along with select to read a specific data in a specific order.
Cassandra – Shell Commands
Cassandra provides documented shell commands in addition to CQL commands. Given below are the Cassandra documented shell commands.

Get Apache Cassandra Training with Industry Concepts By Experts Trainers
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Help
The HELP command displays a synopsis and a brief description of all cqlsh commands. Given below is the usage of help command.
- cqlsh> help
- Documented shell commands:
- ===========================
- CAPTURE COPY DESCRIBE EXPAND PAGING SOURCE
- CONSISTENCY DESC EXIT HELP SHOW TRACING.
- CQL help topics:
- ================
- ALTER CREATE_TABLE_OPTIONS SELECT
- ALTER_ADD CREATE_TABLE_TYPES SELECT_COLUMNFAMILY
- ALTER_ALTER CREATE_USER SELECT_EXPR
- ALTER_DROP DELETE SELECT_LIMIT
- ALTER_RENAME DELETE_COLUMNS SELECT_TABLE
Capture
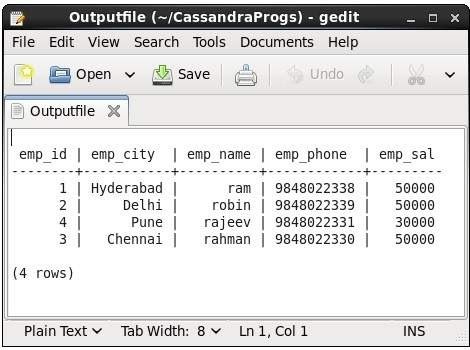
This command captures the output of a command and adds it to a file. For example, take a look at the following code that captures the output to a file named Outputfile.
- cqlsh> CAPTURE ‘/home/hadoop/CassandraProgs/Outputfile’
When we type any command in the terminal, the output will be captured by the file given. Given below is the command used and the snapshot of the output file.
- cqlsh:ACTE> select * from emp;
You can turn capturing off using the following command.
- cqlsh:ACTE> capture off;
Consistency
This command shows the current consistency level, or sets a new consistency level.
- cqlsh:ACTE> CONSISTENCY
Current consistency level is 1.
Copy
This command copies data to and from Cassandra to a file. Given below is an example to copy the table named emp to the file myfile.
- cqlsh:ACTE> COPY emp (emp_id, emp_city, emp_name, emp_phone,emp_sal) TO ‘myfile’;
4 rows exported in 0.034 seconds.
If you open and verify the file given, you can find the copied data as shown below.
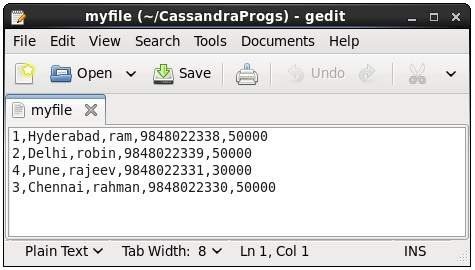
Describe
This command describes the current cluster of Cassandra and its objects. The variants of this command are explained below.
Describe cluster
This command provides information about the cluster.
- cqlsh:ACTE> describe cluster;
Cluster: Test Cluster
Partitioner: Murmur3Partitioner
Range ownership:
-658380912249644557 [127.0.0.1]
-2833890865268921414 [127.0.0.1]
-6792159006375935836 [127.0.0.1]
Describe Keyspaces
This command lists all the keyspaces in a cluster. Given below is the usage of this command.
- cqlsh:ACTE> describe keyspaces;
- system_traces system tp ACTE
Describe tables
This command lists all the tables in a keyspace. Given below is the usage of this command.
- cqlsh:ACTE> describe tables;
- emp
Describe table
This command provides the description of a table. Given below is the usage of this command.
- cqlsh:ACTE> describe table emp;
- CREATE TABLE ACTE.emp (
- emp_id int PRIMARY KEY,
- emp_city text,
- emp_name text,
- emp_phone varint,
- emp_sal varint
- ) WITH bloom_filter_fp_chance = 0.01
- AND caching = ‘{“keys”:”ALL”, “rows_per_partition”:”NONE”}’
- AND comment = ”
- AND compaction = {‘min_threshold’: ‘4’, ‘class’:
- ‘org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy’,
- ‘max_threshold’: ’32’}
- AND compression = {‘sstable_compression’:
- ‘org.apache.cassandra.io.compress.LZ4Compressor’}
- AND dclocal_read_repair_chance = 0.1
- AND default_time_to_live = 0
- AND gc_grace_seconds = 864000
- AND max_index_interval = 2048
- AND memtable_flush_period_in_ms = 0
- AND min_index_interval = 128
- AND read_repair_chance = 0.0
- AND speculative_retry = ‘99.0PERCENTILE’;
- CREATE INDEX emp_emp_sal_idx ON ACTE.emp (emp_sal);
Describe Type
This command is used to describe a user-defined data type. Given below is the usage of this command.
- cqlsh:ACTE> describe type card_details;
- CREATE TYPE ACTE.card_details (
- num int,
- pin int,
- name text,
- cvv int,
- phone set<int>,
- mail text
- );
Describe Types
This command lists all the user-defined data types. Given below is the usage of this command. Assume there are two user-defined data types: card and card_details.
- cqlsh:ACTE> DESCRIBE TYPES;
- card_details card
Expand
This command is used to expand the output. Before using this command, you have to turn the expand command on. Given below is the usage of this command.
- cqlsh:ACTE> expand on;
- cqlsh:ACTE> select * from emp;
- @ Row 1
- ———–+————
- emp_id | 1
- emp_city | Hyderabad
- emp_name | ram
- emp_phone | 9848022338
- emp_sal | 50000
- @ Row 2
- ———–+————
- emp_id | 2
- emp_city | Delhi
- emp_name | robin
- emp_phone | 9848022339
- emp_sal | 50000
- @ Row 3
- ———–+————
- emp_id | 4
- emp_city | Pune
- emp_name | rajeev
- emp_phone | 9848022331
- emp_sal | 30000
- @ Row 4
- ———–+————
- emp_id | 3
- emp_city | Chennai
- emp_name | rahman
- emp_phone | 9848022330
- emp_sal | 50000
- (4 rows)
Note: You can turn the expand option off using the following command.
- cqlsh:ACTE> expand off;
Disabled Expanded output.
Exit
This command is used to terminate the cql shell.
Show
This command displays the details of current cqlsh session such as Cassandra version, host, or data type assumptions. Given below is the usage of this command.
- cqlsh:ACTE> show host;
- Connected to Test Cluster at 127.0.0.1:9042.
- cqlsh:ACTE> show version;
- [cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]
Source
Using this command, you can execute the commands in a file. Suppose our input file is as follows :
Then you can execute the file containing the commands as shown below.
- cqlsh:ACTE> source ‘/home/hadoop/CassandraProgs/inputfile’;
- emp_id | emp_city | emp_name | emp_phone | emp_sal
- ——–+———–+———-+————+———
- 1 | Hyderabad | ram | 9848022338 | 50000
- 2 | Delhi | robin | 9848022339 | 50000
- 3 | Pune | rajeev | 9848022331 | 30000
- 4 | Chennai | rahman | 9848022330 | 50000
(4 rows)
Management and monitoring
Cassandra Data Model Rules
In Cassandra, writes are not expensive. Cassandra does not support joins, group by, OR clause, aggregations, etc. So you have to store your data in such a way that it should be completely retrievable. So these rules must be kept in mind while modelling data in Cassandra.
Maximize the number of writesIn Cassandra, writes are very cheap. Cassandra is optimized for high write performance. So try to maximize your writes for better read performance and data availability. There is a tradeoff between data write and data read. So, optimize your data read performance by maximizing the number of data writes.
Maximize Data DuplicationData denormalization and data duplication are the defacto of Cassandra. Disk space is not more expensive than memory, CPU processing and IOs operation. As Cassandra is a distributed database, so data duplication provides instant data availability and no single point of failure.
Data Modeling Goals
You should have the following goals while modelling data in Cassandra.
- Spread Data Evenly Around the ClusterYou want an equal amount of data on each node of the Cassandra cluster. Data is spread to different nodes based on partition keys that is the first part of the primary key. So, try to choose integers as a primary key for spreading data evenly around the cluster.
- Minimize number of partitions read while querying dataPartitions are a group of records with the same partition key. When the read query is issued, it collects data from different nodes from different partitions.If there will be many partitions, then all these partitions need to be visited for collecting the query data. It does not mean that partitions should not be created. If your data is very large, you can’t keep that huge amount of data on the single partition. The single partition will be slowed down.
Main features:
- Distributed: Every node in the cluster has the same role. There is no single point of failure. Data is distributed across the cluster (so each node contains different data), but there is no master as every node can service any request.
- Supports replication and multi data center replication: Replication strategies are configurable. Cassandra is designed as a distributed system, for deployment of large numbers of nodes across multiple data centers. Key features of Cassandra’s distributed architecture are specifically tailored for multiple-data center deployment, for redundancy, for failover and disaster recovery.
- Scalability: Designed to have read and write throughput both increase linearly as new machines are added, with the aim of no downtime or interruption to applications.
- Fault-tolerant: Data is automatically replicated to multiple nodes for fault-tolerance. Replication across multiple data centers is supported. Failed nodes can be replaced with no downtime.
- Tunable consistency: Cassandra is typically classified as an AP system, meaning that availability and partition tolerance are generally considered to be more important than consistency in Cassandra, Writes and reads offer a tunable level of consistency, all the way from “writes never fail” to “block for all replicas to be readable”, with the quorum level in the middle.
- MapReduce support: Cassandra has Hadoop integration, with MapReduce support. There is support also for Apache Pig and Apache Hive.
- Query language: Cassandra introduced the Cassandra Query Language (CQL). CQL is a simple interface for accessing Cassandra, as an alternative to the traditional Structured Query Language (SQL).
- Eventual Consistency: Cassandra manages eventual consistency of reads, upserts and deletes through Tombstones.
- Cassandra Use Cases/Application: Cassandra is a non-relational database that can be used for different types of applications. Here are some use cases where Cassandra should be preferred.
- Messaging: Cassandra is a great database for the companies that provide Mobile phones and messaging services. These companies have a huge amount of data, so Cassandra is best for them.
- Internet of things Application: Cassandra is a great database for the applications where data is coming at very high speed from different devices or sensors.
- Product Catalogs and retail apps: Cassandra is used by many retailers for durable shopping cart protection and fast product catalog input and output.
- Social Media Analytics and recommendation engine: Cassandra is a great database for many online companies and social media providers for analysis and recommendation to their customers.
Conclusion:
Apache Cassandra is used for community purposes. This tutorial shows the Apache Cassandra installation step by step. Also discussed what are the pre -requisites to access Cassandra. Cassandra is designed to handle big data. Cassandra’s main feature is to store data on multiple nodes with no single point of failure.
The reason for this kind of Cassandra’s architecture was that the hardware failure can occur at any time. Any node can be down. In case of failure data stored in another node can be used. Hence, Cassandra is designed with its distributed architecture.




