
Last updated on 09th Jul 2020| 3269
Data modeling (data modelling) is the process of creating a data model for the data to be stored in a Database. This data model is a conceptual representation of Data objects, the associations between different data objects and the rules. Data modeling helps in the visual representation of data and enforces business rules, regulatory compliances, and government policies on the data. Data Models ensure consistency in naming conventions, default values, semantics, security while ensuring quality of the data.
Types Of Data Models
- There are mainly three different types of data models:
- Conceptual: This Data Model defines WHAT the system contains. This model is typically created by Business stakeholders and Data Architects. The purpose is to organize, scope and define business concepts and rules.
- Logical: Defines HOW the system should be implemented regardless of the DBMS. This model is typically created by Data Architects and Business Analysts. The purpose is to developed technical map of rules and data structures.
- Physical: This Data Model describes HOW the system will be implemented using a specific DBMS system. This model is typically created by DBA and developers. The purpose is actual implementation of the database.
Conceptual Model
- The main aim of this model is to establish the entities, their attributes, and their relationships. In this Data modeling level, there is hardly any detail available of the actual Database structure.
- The 3 basic tenants of Data Model are
Entity: A real-world thing
Attribute: Characteristics or properties of an entity
Relationship: Dependency or association between two entities
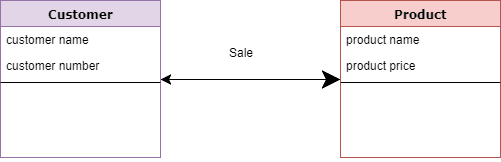
For example:
- Customer and Product are two entities. Customer number and name are attributes of the Customer entity
- Product name and price are attributes of product entity
- Sale is the relationship between the customer and product.
Characteristics of a conceptual data model
- Offers Organisation-wide coverage of the business concepts.
- This type of Data Models are designed and developed for a business audience.
- The conceptual model is developed independently of hardware specifications like data storage capacity, location or software specifications like DBMS vendor and technology. The focus is to represent data as a user will see it in the “real world.”
Conceptual data models known as Domain models create a common vocabulary for all stakeholders by establishing basic concepts and scope.
Logical Data Model
- Logical data models add further information to the conceptual model elements. It defines the structure of the data elements and set the relationships between them.
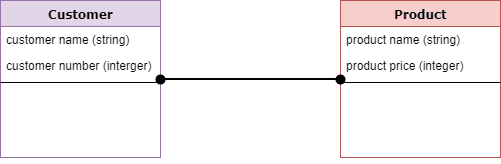
- The advantage of the Logical data model is to provide a foundation to form the base for the Physical model. However, the modeling structure remains generic.
- At this Data Modeling level, no primary or secondary key is defined. At this Data modeling level, you need to verify and adjust the connector details that were set earlier for relationships.
Characteristics of a Logical data model
- Describes data needs for a single project but could integrate with other logical data models based on the scope of the project.
- Designed and developed independently from the DBMS.
- Data attributes will have data types with exact precisions and length.
- Normalization processes to the model is applied typically till 3NF.
Physical Data Model
- A Physical Data Model describes the database specific implementation of the data model. It offers an abstraction of the database and helps generate schema. This is because of the richness of meta-data offered by a Physical Data Model.
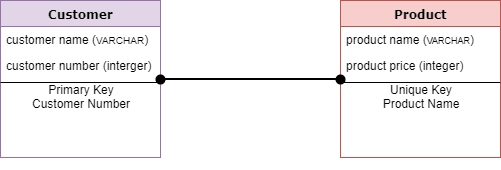
- This type of Data model also helps to visualize database structure. It helps to model database columns keys, constraints, indexes, triggers, and other RDBMS features.
Characteristics Of A Physical Data Model:
- The physical data model describes data need for a single project or application though it maybe integrated with other physical data models based on project scope.
- Data Model contains relationships between tables that which addresses cardinality and nullability of the relationships.
- Developed for a specific version of a DBMS, location, data storage or technology to be used in the project.
- Columns should have exact datatypes, lengths assigned and default values.
- Primary and Foreign keys, views, indexes, access profiles, and authorizations, etc. are defined.
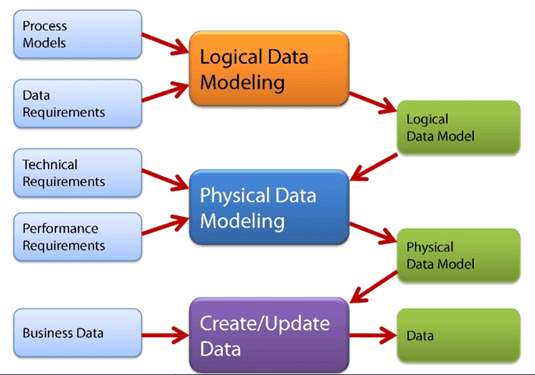
Step-By-Step Guide To Data Modelling
Step 1: Choose A Data Source
- The data source options are displayed in the left-hand panel (blue arrow).
For each data source, the available options are shown on the right hand side. For example, the ability to upload an excel file is provided (green arrow). You can add multiple items from multiple data sources per model.
- The data source options include file-based or local sources, configured sources (ie server databases and cloud sources), BI Office content and packaged sources.

Learn Expert-led Data Modelling Certification Course Taught By Industry Experts
Weekday / Weekend BatchesSee Batch Details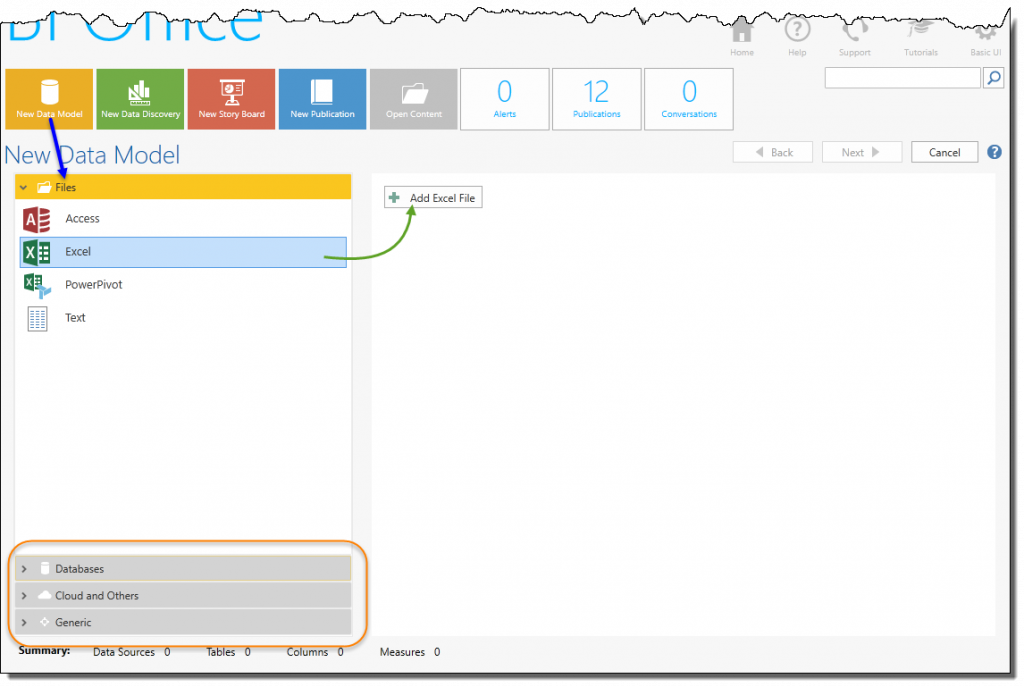
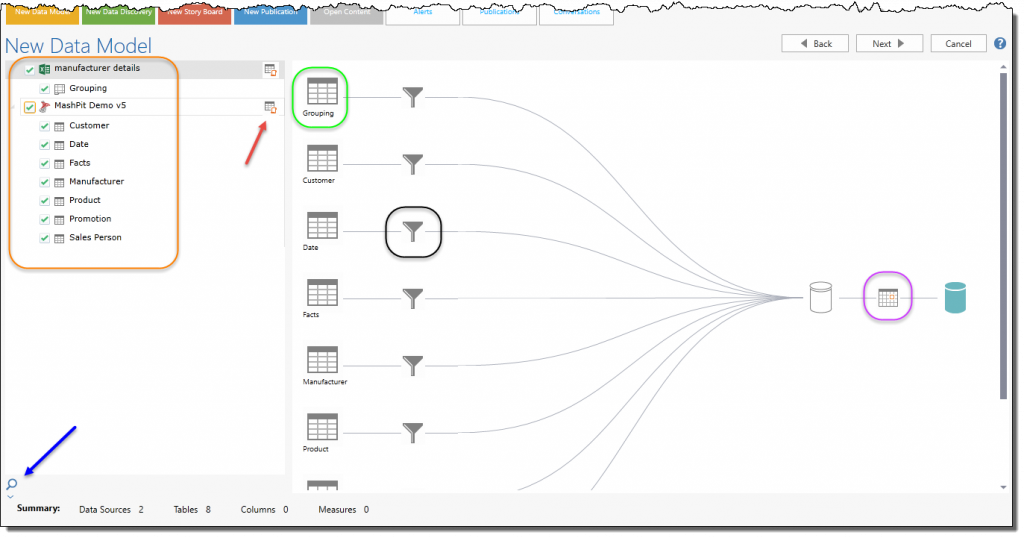
- Select which data sets (orange highlight) that will be included in the final model. As you add new data sets (tables), the data flow graphic on the right will show the movement of the data to the model.
- Clicking a table icon (green highlight) will show a sample of its data (by the blue arrow).
- Clicking a filter (black highlight) will allow you to filter the data set before its added to the model.
- Clicking the schedule icon (purple highlight) will allow you to set a refresh schedule for the raw data import into the model
Step 2: Selection Of Attributes, Columns And Metrics
- For each data set or table selected previously, you can see a list of all its ‘attributes’ or columns (orange highlight). These columns will be used in your data mode to slice and dice your information. They will also be used to generate the metrics or “measures” of the data model (green highlight).
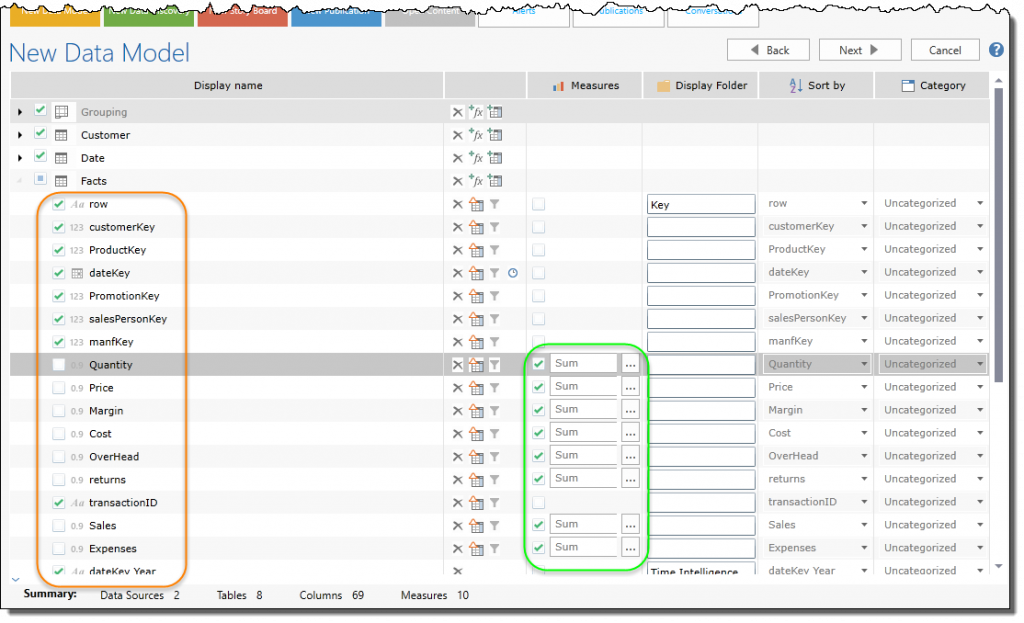
- Beyond selecting which columns will be used and made visible in the data model, there are numerous other settings related to sorting, categorization and folder grouping that can be set for each column in the data set. Other capabilities include merging and splitting of column data to create more useful data constructs in the discovery application. The wizard will also allow users to generate ‘calculated’ columns using formulae to either create column values or derive them from other existing columns in the source data set.
- An important feature of the column selection phase is the ability to define metrics for analysis using data in columns. This includes selecting metric columns, setting their formats and aggregation types. Where needed multiple metrics or measures can be set for each column and new calculated measures can be created from existing column data.
Step 3: Relationship Tool
- The “Relationship” tool provides an opportunity for users to review, edit and add any connections or “relationships” between your different data sets and tables. This critical step allows you to “mash-up” the different data sets and glue them together for analysis.
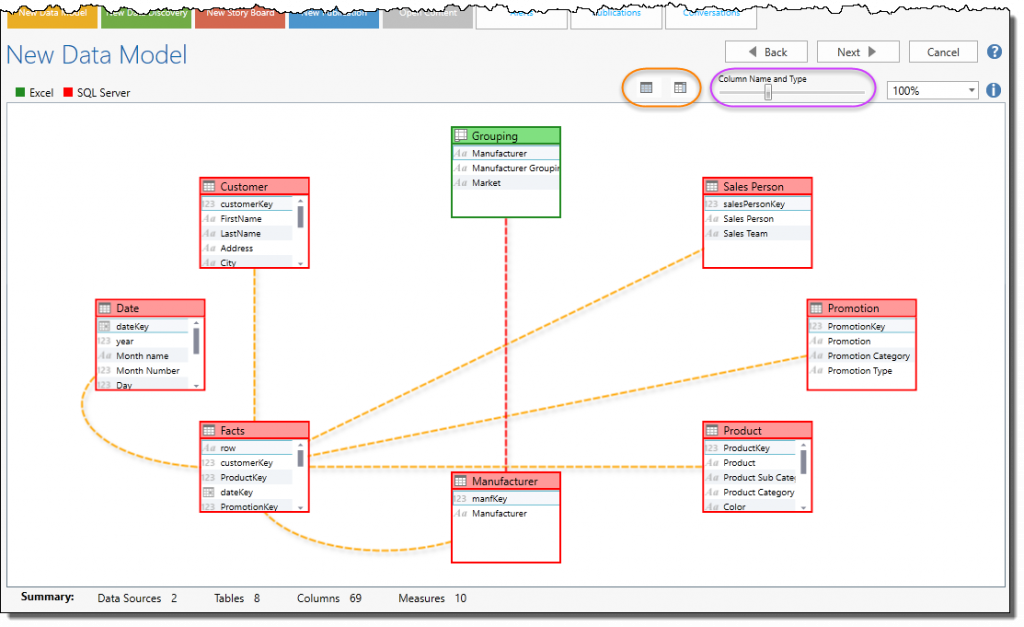
- The Data Model engine will extrapolate any relationships that already exists, and highlight them in orange. Using the heuristics slider (purple highlight), the engine will attempt to auto-match and determine relationships between the tables for you in red. Alternatively, you can drag and drop the relationships using the mouse to manually create the “lines” in between the tables.
Step 4: Hierarchies
- You can optionally add drill-down trees or “hierarchies” to your model to simplify the data navigation in Data Discovery.
Note: Hierarchies can also be added directly from inside the Data Discovery while analyzing the model after the model is built.
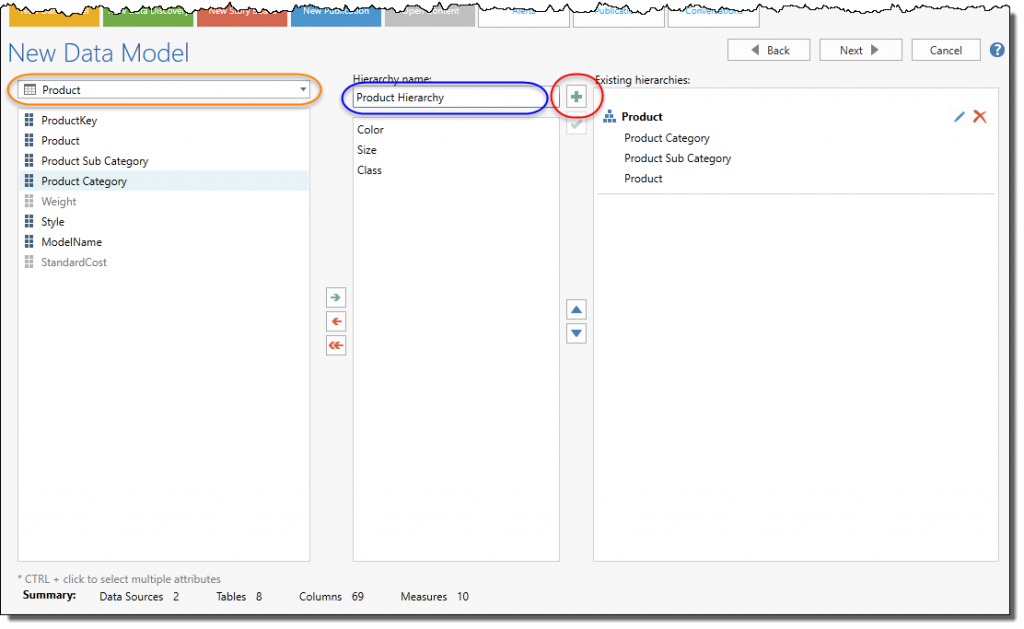
- The hierarchy editor will show you a list of columns per data set (orange highlight) – on the left; that can be combined to create the hierarchy drill path – in the middle.
- Give the hierarchy a name (blue highlight) and then, once you have built the path, click the green add button (red highlight) to add it to the existing hierarchy listing on the right.
- Note: The time intelligence option will automatically create relevant hierarchies for you. You can elect to edit these or remove them.
Step 5: Roles & Permissions
- The wizard displays the roles and permissions for accessing your data model. From here, you can allow which others in your own groupings can manage and see your model (and which ones cannot). By default, you will always be able to see and manage your own model unless the administrator changes them manually on the backend.

Get Practical Oriented Data Modelling Training to UPGRADE Your Knowledge & Skills
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
- Note: The viewable roles reflect the role groupings that you already belong to. Administrators can manually expand this listing through the backend.
Step 6: Finalization And Deployment
- In the last step you need to provide a Model’s Name and Description.
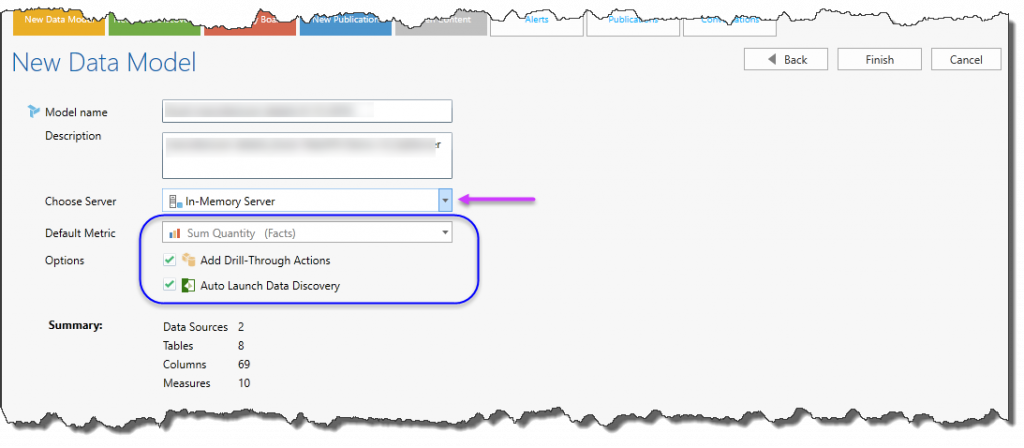
- You also need to make a few elections related to the destination server (purple arrow) that will host your model and other default choices (blue highlight). If you are using packages, there will be other choices related to matching reports for the packaged models.
- Note: Your destination host server list is set from the administrative console.
Model Processing
- Clicking finish will launch your model build and deployment job to the server, which will begin the process of extracting the raw data, transforming it and loading it into the new data model on the host server.
Using data model are:
- Ensures that all data objects required by the database are accurately represented. Omission of data will lead to creation of faulty reports and produce incorrect results.
- A data model helps design the database at the conceptual, physical and logical levels.
- Data Model structure helps to define the relational tables, primary and foreign keys and stored procedures.
- It provides a clear picture of the base data and can be used by database developers to create a physical database.
- It is also helpful to identify missing and redundant data.
- Though the initial creation of data model is labor and time consuming, in the long run, it makes your IT infrastructure upgrade and maintenance cheaper and faster.
Advantages :
- The main goal of a designing data model is to make certain that data objects offered by the functional team are represented accurately.
- The data model should be detailed enough to be used for building the physical database.
- The information in the data model can be used for defining the relationship between tables, primary and foreign keys, and stored procedures.
- Data Model helps business to communicate the within and across organizations.
- Data model helps to documents data mappings in ETL process
- Help to recognize correct sources of data to populate the model
Conclusion
- Data modeling is the process of developing data model for the data to be stored in a Database.
- Data Models ensure consistency in naming conventions, default values, semantics, security while ensuring quality of the data.
- Data Model structure helps to define the relational tables, primary and foreign keys and stored procedures.
- There are three types of conceptual, logical, and physical.
- The main aim of conceptual model is to establish the entities, their attributes, and their relationships.
- Logical data model defines the structure of the data elements and set the relationships between them.
- A Physical Data Model describes the database specific implementation of the data model.
- The main goal of a designing data model is to make certain that data objects offered by the functional team are represented accurately.
- The biggest drawback is that even smaller change made in structure require modification in the entire application.




