
Last updated on 15th Feb 2024| 2905
It is necessary to have a thorough understanding of data warehousing ideas, be proficient in SQL, and be familiar with Teradata tools and utilities in order to prepare for Teradata interviews. Applicants should be prepared to go over Teradata architecture, query optimisation strategies, database design concepts, and real-world problem-solving scenarios. To impress prospective employers and land a job in Teradata development, administration, or analytics, you need to have strong communication skills, critical thinking abilities, and a love for using data for business insights.
1. Explain the Teradata architecture.
Ans:
Teradata follows a shared-nothing architecture, where each node operates independently. The parsing engine receives SQL queries, dispatches them to AMPs, and orchestrates the execution. Access Module Processors (AMPs) manage data storage and retrieval on each node, ensuring parallel processing for improved performance. BYNET facilitates communication between nodes, while the disk arrays store data. This architecture provides scalability and high-performance data processing.
2. What is the primary function of the Parsing Engine in Teradata?
Ans:
The Parsing Engine in Teradata is responsible for receiving SQL queries, parsing them, and creating an execution plan. It breaks down the query into steps, determining the optimal way to retrieve or manipulate data. The Parsing Engine then dispatches these steps to the relevant AMPs for parallel processing. This orchestration ensures efficient query execution and optimal resource utilization across the Teradata system.
3. Explain the importance of Access Module Processors (AMPs) in Teradata.
Ans:
AMPs play a crucial role in Teradata’s shared-nothing architecture.
Each AMP manages a portion of the data on a node and handles data storage and retrieval operations.
This parallel processing approach allows multiple AMPs to work simultaneously on different subsets of data, optimizing performance.
AMPs ensure data distribution, availability, and retrieval efficiency, contributing to Teradata’s scalability and ability to handle large datasets.
4. How does Teradata handle data distribution and storage?
Ans:
Teradata uses a hashing algorithm to distribute data evenly across AMPs. This ensures that each AMP is responsible for a specific range of data, preventing hotspots and balancing the workload. Data is stored in disk arrays on each node, allowing for parallel access.
The combination of hashing and parallel storage contributes to efficient data distribution and retrieval in Teradata.
5. What is the purpose of BYNET in Teradata?
Ans:
BYNET is the communication layer in Teradata that enables inter-node communication. It facilitates the exchange of data and messages between Parsing Engines and AMPs across different nodes. BYNET ensures coordination and synchronization of parallel processing activities, contributing to the overall efficiency and reliability of Teradata’s shared-nothing architecture
6. How does Teradata achieve parallel processing and scalability?
Ans:
Teradata uses AMPs to process queries concurrently and data distribution across numerous nodes to achieve parallel processing. Teradata can effectively handle large datasets and intricate queries thanks to its parallelism. Because extra nodes can be added to the system to handle increasing data quantities and better processing demands, the shared-nothing architecture enables smooth scaling. Teradata is a robust and scalable data warehousing and analytics solution because of this design.
7. What is Teradata, and how does it differ from other database management systems?
Ans:
| Aspect | Teradata | Other DBMS |
|---|---|---|
| Architecture | Massively Parallel Processing (MPP) (MVC) architecture. | Varies based on specific DBMS |
| Query Optimization | Advanced optimization capabilities | Optimization varies among DBMS |
| Enterprise Focus | Widely used in large enterprises | Adoption varies across industries |
Teradata is a relational database management system made for massive analytics and data warehousing.
Teradata, unlike traditional databases, excels in parallel processing and scalability, making it perfect for managing massive amounts of data and complicated queries.
Its unique architecture, with separate parsing and execution engines, sets it apart from the other systems, enabling efficient query optimization and performance.
8. Explain the concept of AMPs in Teradata.
Ans:
AMPs, or Access Module Processors, are the fundamental processing units in Teradata. They handle data storage and retrieval within the system. Each AMP is responsible for a portion of the data, and parallel processing across multiple AMPs enables Teradata to distribute and process queries efficiently. AMPs contribute to Teradata’s scalability and performance by dividing the workload among various processors.
9. How does Teradata handle data distribution, and why is it important?
Ans:
Teradata uses a hash-based mechanism to distribute data evenly across AMPs. This ensures a balanced workload and prevents hotspots where one AMP becomes a bottleneck. Even data distribution improves parallel processing performance by allowing queries to be processed simultaneously across different AMPs. This strategy is critical for optimizing performance in large-scale data warehousing settings.
10. What is a primary index in Teradata, and why is it essential?
Ans:
- A primary index is a crucial feature in Teradata that determines the distribution of rows across AMPs.
- It helps in evenly spreading the data, facilitating efficient retrieval.
- Primary indexes can be unique or non-unique and play a vital role in query performance.
- A well-designed primary index is essential for optimizing data distribution and minimizing data movement during query execution.
11. Explain Teradata’s locking mechanism and its significance.
Ans:
Teradata employs a sophisticated locking mechanism to manage concurrent access to data by multiple users. It uses various lock types, such as read, write, and access locks, to control data access at different levels. This ensured data consistency and integrity in the multi-user environment. The flexibility of Teradata’s locking mechanism allows for a balance between data concurrency and system performance.
12. What are fallback and permanent journals in Teradata?
Ans:
Fallback and permanent journals are Teradata features that provide data protection and fault tolerance.
Fallback ensures data availability in case of an AMP failure by storing a duplicate copy on another AMP. Permanent journals capture changes to the database, offering point-in-time recovery and audit capabilities.
Together, these features enhance data reliability, ensuring data integrity and recoverability in the event of hardware or software failures.
13. How does Teradata achieve query optimization?
Ans:
Teradata accomplishes query optimization using its Parallel Database Extension (PDE), which allows it to split SQL queries into smaller jobs that may be completed concurrently across a lot of AMPs. The optimizer evaluates various execution plans and selects the most efficient one based on statistics and cost estimates. This process is vital because it ensures that resources are used effectively, reducing query execution times and improving overall system performance. Optimal query execution is essential for supporting complex analytics on large datasets.
14. Explain the concept of secondary indexes in Teradata.
Ans:
Secondary indexes in Teradata are optional structures that provide an alternative path to access data besides the primary index. They are handy for improving access speed to rows that are not evenly distributed by the primary index. While secondary indexes can significantly enhance query performance by reducing the amount of data scanned, they also require additional storage and maintenance, which could impact system performance. Hence, their use should be carefully considered and balanced against the benefits they provide.
15. Describe Teradata’s MultiLoad utility and its use cases.
Ans:
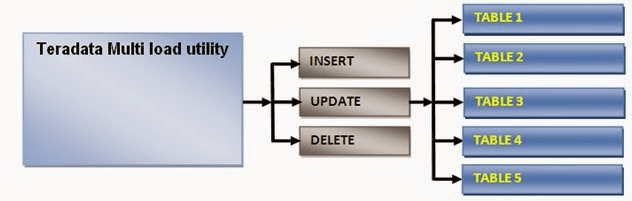
- MultiLoad is a high-speed data loading utility in Teradata designed for batch processing of large volumes of data.
- It is capable of loading, updating, deleting, and updating data across multiple tables simultaneously.
- MultiLoad is especially useful in environments where large datasets need to be quickly integrated into the database for analysis.
- Its efficiency stems from its ability to load data in parallel across multiple sessions, significantly reducing the time required for data ingestion compared to traditional methods.
16. What is the difference between a volatile table, a global temporary table, and a permanent table in Teradata?
Ans:
In Teradata, volatile tables are temporary tables that exist only during the session and are stored in the session user’s spool space. They are helpful for temporary computations and data manipulations within a session. Global temporary tables, while also session-specific, persist across sessions in terms of structure but not data and are stored in temporary space. Permanent tables are stored in the database permanently and hold data persistently across sessions. The choice between these table types depends on the specific requirements of data persistence, visibility, and storage location.
17: Explain how Teradata handles transaction management.
Ans:
Teradata manages transactions using a locking mechanism and write-ahead logging to ensure data consistency and integrity. When a transaction begins, Teradata locks the affected rows or tables to prevent conflicting operations. Changes are first recorded in a log, ensuring that, in case of a failure, the system can recover to a consistent state. This approach guarantees that all parts of a transaction are completed successfully before changes are made permanent, thereby maintaining data consistency across the database. Transaction management in Teradata is designed to support high concurrency while ensuring data reliability.
18. What is Teradata’s Parallel Data Pump (TPump)?
Ans:
- Teradata’s TPump is a data-loading utility specifically designed for continuous data streams and real-time updates.
- It operates with lower system impact compared to MultiLoad, making it suitable for environments requiring near real-time data integration.
- TPump utilizes the concept of “packs” to efficiently update or insert rows into tables, providing faster processing of data changes.
- Its incremental and low-latency approach makes it a preferred choice for scenarios where timely data updates are critical.
19. Explain Teradata’s role in supporting a data lake architecture.
Ans:
Integration with a data lake architecture is straightforward because of Teradata’s SQL access to data kept in the Hadoop Distributed File System or other external data sources. Users may query data from both the Teradata warehouse and the data lake in a single step with Teradata QueryGrid, for instance. This feature enables enterprises to use the characteristics of both platforms, allowing for powerful analytics on varied and dispersed datasets while preserving centralized management and governance.
20. How does Teradata ensure data security?
Ans:
Teradata implements robust security measures, including role-based access control, encryption, and authentication mechanisms. By assigning specific roles to users, organizations can control access to tables, databases, and functions. Teradata supports encryption of data in transit and at rest, providing a secure environment for sensitive information. Authentication options include LDAP and Kerberos integration, enhancing the overall security posture of the system.
21. What is Teradata’s Viewpoint?
Ans:
The web-based management and monitoring tool Teradata Viewpoint offers a consolidated view of the whole Teradata ecosystem. It provides information on the functionality, health, and use of resources within the system. Administrators may control workload, track query performance, and get alerts about any problems with Viewpoint. This instrument is essential for maximizing system performance, guaranteeing effective resource distribution, and locating and resolving possible bottlenecks.
22. Discuss Teradata’s support for temporal data and its significance.
Ans:
- Teradata’s temporal feature allows the tracking of changes to data over time, enabling the systematic storage of historical information.
- This is particularly valuable for scenarios such as auditing, compliance, and trend analysis.
- By associating a period with each row, organizations can reconstruct the state of the data at any given point, providing a comprehensive historical view.
- This temporal support enhances data governance and supports analytical requirements involving time-based analysis.
23. How does Teradata handle workload management?
Ans:
Teradata’s workload management ensures that system resources are efficiently allocated to different types of queries and users. By defining workload priorities, organizations can optimize resource utilization, provide fair access to system resources, and meet performance objectives
24. What is the significance of the skew factor in Teradata?
Ans:
The skew factor in Teradata measures the uneven distribution of data across AMPs, which can significantly impact system performance. A high skew factor indicates a less-than-ideal distribution, leading to some AMPs being overburdened with data while others need to be more utilized. This imbalance can cause delays in query processing because the system must wait for the slowest AMP to complete its task. Managing skew effectively is crucial for optimizing parallel efficiency and ensuring that the workload is evenly distributed, thereby improving overall system performance and query response times.
25. Explain the concept of joining indexes in Teradata
Ans:
Teradata’s join indexes are a significant tool that optimizes query efficiency by pre joining tables and storing the results in a separate structure. This can significantly reduce the time required to execute complicated queries that include joins by avoiding the requirement to conduct these joins at query time. Instead, queries may immediately access the pre-joined data, resulting in speedier response times. However, because join indexes demand more storage and maintenance, their use must be carefully planned and managed to balance performance advantages against resource costs.
26. Describe the process of collecting statistics in Teradata.
Ans:
- Collecting statistics in Teradata involves gathering data about the distribution of values within columns, the number of rows in tables, and other critical information that the optimizer uses to make informed decisions about the best way to execute queries.
- Accurate statistics allow the optimizer to estimate the cost of different query plans more accurately, leading to the selection of the most efficient execution path.
- Regularly updating statistics is essential for maintaining optimal query performance, especially as data volume and distribution change over time.
27. How does Teradata’s columnar feature enhance its analytical capabilities?
Ans:
- Teradata’s columnar feature enhances its analytical capabilities by allowing data to be stored in a column-wise fashion, in addition to the traditional row-oriented storage.
- This columnar storage is particularly beneficial for analytical queries that typically access only a subset of columns in a table, as it enables more efficient data retrieval and reduces I/O operations.
- By storing data by column, Teradata can compress data more effectively and perform columnar operations like aggregation and filtering more efficiently, improving performance for analytical workloads.
28. Discuss the role of Teradata Studio in the ecosystem.
Ans:
An integrated development environment (IDE) called Teradata Studio was created to make database administration and application development in Teradata easier. Database administrators and developers provide an extensive toolkit that includes features for querying, managing objects, loading data, and assessing query performance. A user-friendly interface, support for SQL programming, and integrated visualization tools are some of its essential characteristics. By offering a consolidated platform for controlling every part of the Teradata ecosystem, Teradata Studio increases productivity.
29. What strategies can be employed in Teradata to optimize space usage and manage data growth effectively?
Ans:
To optimize space usage and manage data growth effectively in Teradata, several strategies can be employed, including proper use of compression techniques, regular archiving or purging of old or unnecessary data, and careful design of tables and indexes to minimize space consumption.
Partitioning can also help by enabling more efficient data access and reducing the amount of data scanned for queries.
Additionally, monitoring and managing skew factors can prevent uneven data distribution, ensuring optimal use of available space and maintaining system performance.
30. What is the Teradata Index Wizard?
Ans:
The Teradata Index Wizard is a tool that helps automate the creation and recommendation of indexes based on query patterns and workload analysis. It analyzes historical query performance, identifies frequently accessed columns, and suggests optimal index configurations. By automating the index creation process, the Index Wizard contributes to improved query performance and resource utilization, ensuring that indexes align with the specific needs of the workload.
31. Explain the importance of fallback protection in Teradata.
Ans:
Fallback protection in Teradata involves storing a duplicate copy of data on a different AMP for increased fault tolerance. In the event of an AMP failure, the system can seamlessly switch to the fallback copy, ensuring continuous data availability. This redundancy enhances system reliability and safeguards against potential hardware failures, contributing to high data availability and minimal disruption in data access.
32. How does Teradata handle concurrency control, and what mechanisms are in place to manage simultaneous data access?
Ans:
Teradata uses a number of concurrency management techniques, including table- and row-level locks. When many users try to access or alter the same data at the same time, these locks avoid disputes. Teradata makes sure that data integrity and consistency are maintained in multi-user environments by combining read and write locks. Performance and concurrency may be balanced thanks to the system’s adaptability in handling locks.
33. Discuss the concept of Teradata Active System Management (TASM).
Ans:
- A workload management tool called Teradata Active System Management (TASM) distributes and ranks system resources according to predetermined criteria and priorities.
- By ensuring that vital tasks have the resources they require, TASM helps to maximize system performance.
- It enables administrators to control query execution times, prioritize workloads, and dynamically assign resources, all of which help to ensure equitable and effective resource use across various workloads.
34. What are the advantages of using Teradata Temporal Tables for tracking historical data changes?
Ans:
Teradata Temporal Tables enable the tracking of changes to data over time, providing a historical perspective on data evolution. This feature is valuable for compliance, auditing, and trend analysis, allowing organizations to reconstruct the state of data at any given point. By associating periods with rows, Temporal Tables support accurate reporting and analytics on historical data changes, enhancing data governance and decision-making processes.
35: How does Teradata ensure data integrity through constraints?
Ans:
Teradata ensures data integrity by supporting various types of constraints, including primary key, unique, foreign key, and check constraints. Primary key and unique constraints enforce uniqueness in columns, while foreign key constraints maintain referential integrity between tables. Check constraints allow the definition of specific conditions that data must meet for insertion or update. By enforcing these constraints, Teradata guarantees the accuracy and consistency of data, preventing the introduction of invalid or conflicting information into the database.
36. Explain Teradata’s Geospatial data capabilities.
Ans:
Teradata provides robust Geospatial data features for handling spatial data types and performing location-based analytics.
With support for spatial indexing and functions, Teradata enables users to analyze and visualize data based on geographical information.
This functionality is especially useful in applications such as retail site selection, logistics optimization, and geographic trend analysis, where comprehending spatial linkages within data is critical for making sound judgments.
37. How does Teradata handle data distribution in a Multi-Cluster environment?
Ans:
In a Multi-Cluster environment, Teradata uses the BYNET to facilitate communication between clusters and distributes data across them for parallel processing. This approach allows organizations to scale their Teradata environment horizontally, adding clusters as data volumes grow. Multi-cluster Teradata deployments enhance system scalability, performance, and fault tolerance by distributing workloads across multiple clusters while maintaining a unified and coherent data warehouse.
38. Discuss Teradata’s support for JSON data.
Ans:
Teradata supports JSON data types and provides functions for querying and processing JSON documents, making it suitable for handling semi-structured data. This capability is crucial in contemporary data architectures where unstructured and semi-structured data sources, such as web logs and API responses, are prevalent. Teradata’s ability to integrate JSON data seamlessly allows organizations to leverage the benefits of a multi-modal database system that can handle diverse data formats.
39. What is the Teradata Unity product?
Ans:
Teradata Unity is a data integration tool that allows for seamless data access and analytics across several data platforms. It supports data transfer between Teradata systems and other databases, data warehouses, or data lakes. Teradata Unity facilitates sophisticated analytics on varied datasets by offering a unified view of data across several settings. This integration feature is helpful in situations when firms use different data platforms and need to combine information for complete analysis.
40. How does Teradata support workload isolation?
Ans:
- Teradata ensures workload isolation in a multi-tenant environment by allowing administrators to define and allocate system resources to different workloads and users.
- Through features like workload management, query throttling, and resource allocation, Teradata prevents resource contention and ensures fair access to system resources.
- This capability is essential for maintaining predictable performance in shared environments, where multiple users and workloads coexist, preventing any single workload from monopolizing system resources and impacting others adversely.

41. Discuss the advantages and use cases of Teradata’s Advanced SQL Engine
Ans:
- Teradata’s Advanced SQL Engine (ASE) is designed for high-performance analytics and supports features like machine learning, temporal analytics, and advanced SQL functions.
- It is optimized for complex queries and analytical workloads, making it well-suited for data exploration and deep analysis.
- ASE’s parallel processing capabilities and support for advanced analytics algorithms enhance its effectiveness in scenarios where organizations require sophisticated analytical processing on large datasets, such as predictive modeling or advanced statistical analysis.
42. What exactly is performance tuning, and what makes it crucial?
Ans:
Performance tuning in the context of Teradata involves optimizing the system to enhance its efficiency, responsiveness, and overall throughput. It includes activities such as query optimization, index creation, workload management, and system configuration adjustments. Performance tuning is crucial as it ensures that the Teradata system operates at its peak, delivering optimal performance for data processing and analytical tasks.
43. In the event that the MLOAD Client System fails, how would you restart it?
Ans:
If the MLOAD Client System fails, you can restore it by figuring out which job went wrong, fixing any problems that led to it, and then resubmitting the MLOAD job with the correct command or script.
Before restarting, it’s critical to examine error messages and logs in order to identify and fix any problems and stop recurrent failures.
44. Describe how to restart the MLOAD Teradata Server following its execution.
Ans:
Restarting an MLOAD Teradata Server: After execution, you must release the MLOAD lock on the target table and make sure the error tables are empty in order to restart an MLOAD Teradata Server.
The MLOAD process can then be resumed by resubmitting the job with the relevant script or command, enabling it to carry out the loading procedure where it left off.
45. Spool space: what is it? Describe how to use it.
Ans:
Spool space in Teradata is a temporary storage area used during query processing. It holds intermediate results, sorts and joins data, and other temporary structures required for query execution. Properly managing spool space is crucial for preventing performance issues and query failures. Users can monitor and allocate spool space for their queries, and system administrators can configure and optimize system resources to ensure efficient spool space utilization.
46. What do Teradata nodes mean?
Ans:
- Teradata nodes refer to individual servers or processing units within a Teradata system.
- Each node is generally made up of one or more Access Module Processors (AMPs), which store and process data.
- Nodes work together in parallel to handle queries, and the number of nodes determines the system’s scalability and processing power.
47. Which tools fall under Teradata’s ETL (Extract, Transform, and Load) category?
Ans:
- Teradata offers various ETL (Extract, Transform, and Load) tools, including Teradata Parallel Transporter (TPT) and Teradata PT (Parallel Transport) API. These tools facilitate the extraction, transformation, and loading of data into Teradata databases, supporting efficient and parallel processing for large datasets.
- List the advantages of ETL tools compared to Teradata.
- ETL tools provide a platform-agnostic solution for data integration, supporting various data sources, not just Teradata.
- ETL tools often offer graphical interfaces, making them user-friendly for designing complex data workflows.
- ETL tools support transformations and data cleansing, providing a comprehensive solution for data integration tasks.
48. What does Teradata caching entail?
Ans:
Teradata caching involves storing frequently accessed data in memory for faster retrieval. The system intelligently manages the cache, prioritizing frequently used data to reduce disk I/O and improve query performance. Caching helps optimize data access times and is an integral part of Teradata’s strategy to enhance overall system performance.
49. A channel driver: what is it?
Ans:
A channel driver in Teradata is a component responsible for managing the communication between Teradata systems and external data sources during the ETL process. It facilitates the movement of data between different systems and ensures efficient and secure data transfer. Channel drivers play a crucial role in maintaining data integrity and reliability during the extraction and loading phases of the ETL process.
50. Teradata utilities: what are they? Describe the many kinds of Teradata utilities.
Ans:
Teradata utilities are specialized tools designed for various data management tasks.
These include FastLoad for high-speed data loading, MultiLoad for batch maintenance of tables, Teradata Parallel Transporter (TPT) for ETL processes, BTEQ for batch processing and query execution, and FastExport for exporting large volumes of data efficiently.
Each utility addresses specific aspects of data handling, enabling optimal performance and efficiency in Teradata environments.
51. On a UNIX platform, how would Teradata jobs be executed?
Ans:
Teradata jobs on a UNIX platform are typically executed through command-line utilities or job scheduling tools like cron. The Teradata utilities such as BTEQ, FastLoad, and MultiLoad are invoked by executing scripts containing SQL commands or Teradata commands. These scripts can be scheduled as part of batch processes to automate data loading, extraction, and transformation tasks on the UNIX server.
52. What distinguishes Teradata from Oracle?
Ans:
Teradata and Oracle are both relational database management systems, but Teradata is specifically designed for large-scale data warehousing and analytics. Teradata’s parallel processing architecture, scalability, and focus on analytical workloads distinguish it from Oracle, which is more commonly used for transactional processing. Teradata’s strength lies in its ability to efficiently handle complex queries on massive datasets in a parallel and distributed environment.
53. What steps will you take in the event that the Fast Load Script is unreliable?
Ans:
In the event of an unreliable FastLoad script, the first step is to thoroughly review the script for errors, ensuring that the syntax is correct and the script aligns with Teradata’s requirements.
Verify the data source and target, addressing any issues with file paths or permissions.
If issues persist, consider rewriting the script, checking for data integrity, and running in smaller batches for troubleshooting.
54. How are you going to verify that Teradata is up to date?
Ans:
To verify if Teradata is up-to-date, one can query the Data Dictionary tables like DBC. Indices or DBC.Tables to check the last modified timestamp. Additionally, reviewing the Teradata logs and system alerts and using the Viewpoint tool for monitoring can provide insights into recent system activities. Regularly checking for updates and patches from Teradata’s official resources ensures the system is running the latest software versions.
55. Which table types are supported by Teradata?
Ans:
Teradata supports various table types, including Set tables, MultiSet tables, Global Temporary Tables, and Volatile Tables.
Set tables enforce uniqueness on primary index columns, while MultiSet tables allow duplicate rows. Global Temporary Tables and Volatile Tables are session-specific and temporary, with the former preserving structure across sessions and the latter existing only during the session.
56. List the BTEQ scripts that are most often used.
Ans:
Frequently used BTEQ scripts include those for executing SQL queries, exporting/importing data, and performing administrative tasks.
Scripts for data validation, error handling, and session control are also standard.
BTEQ provides a versatile command-line interface for Teradata, making it widely employed in scripting scenarios for managing and querying data.
57. Regarding PDE (Parallel Data Extension), what do you know?
Ans:
Teradata is known for its Parallel Data Processing architecture, where data processing tasks are distributed and executed in parallel across multiple nodes or AMPs (Access Module Processors). The architecture is designed to provide high performance and scalability for large-scale data warehousing and analytics.
If “Parallel Data Extension” is a new or specific feature introduced after my last update, I recommend checking the latest Teradata documentation and release notes or contacting Teradata support for the most accurate and up-to-date information on this component and its functionalities.
58. What is a Partitioned Primary Index, or PPI?
Ans:
A Partitioned Primary Index (PPI) in Teradata is a table indexing mechanism where data is physically organized based on specified partitioning columns. This enhances query performance, as it restricts the search space for queries to relevant partitions, reducing I/O and improving efficiency. PPI is particularly beneficial for large tables where subsets of data are frequently queried or manipulated.
59. Locks: What are they? Describe the various Teradata lock types.
Ans:
Locks in Teradata are mechanisms used to control access to data during concurrent operations. Various lock types exist, including read locks, write locks, and access locks. Read locks allow multiple users to read data concurrently, write locks prevent conflicting updates, and access locks control data access for specific operations. Teradata’s flexible locking mechanism ensures data consistency and integrity in multi-user environments. Understanding and managing locks are essential for optimizing performance and avoiding contention in shared environments

Get JOB Oriented Teradata Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
60. A fallback is what?
Ans:
Fallback in Teradata refers to a system-level redundancy mechanism where a duplicate copy of data is stored on another AMP (Access Module Processor).
This ensures data availability in the event of an AMP failure, as queries can seamlessly switch to the fallback copy.
Fallback provides fault tolerance and safeguards against data loss, contributing to high availability and reliability in Teradata systems.
It’s a critical feature for maintaining continuous data access and system resilience.
61. What do you know about Teradata’s FAST EXPORT feature?
Ans:
FAST EXPORT in Teradata is a utility designed for the high-speed export of large volumes of data from Teradata databases to external systems. It leverages parallel processing capabilities to transfer data, thereby minimizing the export time efficiently. This utility breaks down the data into multiple streams, allowing it to be exported simultaneously through different sessions. FAST EXPORT is particularly useful in data warehousing scenarios where data needs to be moved to other platforms for analysis or backup purposes.
62. How many tables with data do you think Teradata MultiLoad can handle?
Ans:
Teradata MultiLoad supports the loading of up to five populated target tables in a single job execution. This utility is optimized for high-volume batch maintenance of large databases, allowing for the insertion, updating, deletion, and upserting of data across multiple tables efficiently. MultiLoad takes advantage of Teradata’s parallel processing architecture, significantly reducing the time required for large-scale data loading operations compared to traditional row-by-row methods.
63. Describe Teradata’s temporary journaling and database rights.
Ans:
Transient journaling in Teradata is a mechanism for ensuring data recovery in the event of a failure during data modification operations. It temporarily records changes made to the database, allowing for rollback if necessary.
These privileges ensure that users can only perform actions for which they have explicitly been granted permission, thereby protecting the integrity and security of the database.
64. Which privilege levels are present in Teradata?
Ans:
Teradata contains multiple levels of privileges, including object-level privileges (such as SELECT, INSERT, UPDATE, DELETE on tables), database-level privileges (such as CREATE TABLE, DROP TABLE within a database), and system-level privileges (such as CREATE USER, DROP USER). These levels allow for granular control over database access, enabling administrators to finely tune what actions individual users or roles can perform within the Teradata environment.
65. What distinguishes Teradata’s GIVE and GRANT statements from one another?
Ans:
Teradata contains multiple levels of privileges, including object-level privileges (such as SELECT, INSERT, UPDATE, DELETE on tables), database-level privileges (such as CREATE TABLE, DROP TABLE within a database), and system-level privileges (such as CREATE USER, DROP USER). These levels allow for granular control over database access, enabling administrators to finely tune what actions individual users or roles can perform within the Teradata environment.
66. Describe the various GRANT forms found in Teradata.
Ans:
- In Teradata, the GRANT statement has several forms, enabling the assignment of various types of privileges.
- These include GRANTing permissions for SQL operations such as SELECT, INSERT, UPDATE and DELETE on database objects, as well as GRANTing roles that bundle multiple privileges together.
- Additionally, there are system-level GRANTs, such as the ability to GRANT logon rights or the ability to CREATE users. Each Form specifies the action a user is allowed to perform, ensuring that access control can be tailored to meet specific security and operational needs.
67. In what ways would you apply for GRANT (MONITOR Form) and GRANT (SQL Form)?
Ans:
The GRANT (SQL Form) in Teradata is used to provide SQL privileges to users or roles, such as SELECT, INSERT, UPDATE, or DELETE on a table. It specifies what operations the grantee is permitted to perform on database objects. The GRANT (MONITOR Form), on the other hand, is used to grant monitoring privileges, allowing users to view system performance data, query information, and other operational metrics. This Form is crucial for database administrators and analysts responsible for maintaining system health and optimizing performance.
68. What does Teradata utilize the REVOKE statement for?
Ans:
The REVOKE statement in Teradata is used to withdraw previously granted privileges from a user or role. It ensures that database administrators can manage and restrict access to database objects as necessary, enhancing security and compliance whether revoking object-level privileges (like SELECT on a table) or system-level privileges (such as the ability to CREATE tables), the REVOKE statement is an essential tool for maintaining appropriate access controls within the Teradata database environment.
69. What function does the SHOW statement serve?
Ans:
The SHOW statement in Teradata is a powerful tool for obtaining information about the database objects, configurations, and system settings. It allows users and administrators to query metadata, view the structure of tables, assess system performance, and retrieve details about various database entities. The SHOW statement is crucial for monitoring and optimizing the Teradata environment by providing insights into its current state.
70. What do Teradata’s Hot Standby Nodes, or HSNs, mean?
Ans:
- Hot Standby Nodes (HSN) in Teradata represent standby nodes that are ready to assume the processing responsibilities of a failed node in a Multi-System environment.
- These nodes stay in a hot standby mode, ready to take over smoothly to ensure uninterrupted operations in the case of a node failure.
- HSNs enhance the fault tolerance and availability of the Teradata system by providing a rapid and automated failover mechanism.
71. Explain Teradata’s volatile tables.
Ans:
- Volatile tables in Teradata are temporary structures designed for session-specific data storage and manipulation.
- They persist for the duration of a session and are immediately removed when it expires. Volatile tables are excellent for storing intermediate or temporary data for a given user or application session.
- Their temporary nature makes them ideal for scenarios where temporary storage is needed for on-the-fly data processing without the need for persistent storage.
72. Describe the distinction between Teradata’s LOG and NO LOG.
Ans:
In Teradata, the LOG and NO LOG options pertain to the logging of operations on a table. LOG signifies that changes made to the table are logged, providing a record for recovery purposes in case of a system failure. On the other hand, NO LOG indicates that the operations are not logged, offering improved performance by skipping the logging process. However, choosing NO LOG sacrifices the ability to recover changes in the event of a system failure.
73. What does it mean to keep a permanent journal?
Ans:
Permanent journaling in Teradata involves the continuous logging of all changes made to a table over time. This journaling mechanism creates a historical record of data modifications, capturing INSERTs, UPDATEs, and DELETEs. Permanent journaling supports data recovery, audit trails, and compliance requirements, providing a comprehensive historical perspective on data changes within the database.
74. In Teradata, what does MERGEBLOCKRATIO mean?
Ans:
MERGEBLOCKRATIO is a parameter within the Teradata Index Wizard that influences the decision-making process for merging or splitting index sub-blocks. It sets a threshold ratio that determines when to merge sub-blocks, optimizing the storage and access efficiency of indexes.
Adjusting the MERGEBLOCKRATIO parameter allows for fine-tuning the balance between storage optimization and query performance within the Teradata database.
75. What do you know about Teradata’s DATA BLOCK SIZE?
Ans:
DATA BLOCK SIZE in Teradata refers to the size of a data block within a table. It represents the fundamental unit of storage for rows within a table and has a direct impact on I/O efficiency during data retrieval and manipulation operations. Larger DATA BLOCK SIZE values can enhance the performance of specific queries by reducing the number of I/O operations needed to access and process data. However, selecting an appropriate DATA BLOCK SIZE involves a trade-off between storage efficiency and query performance based on the specific characteristics of the workload and system architecture.
76. Which Block Compression Is It?
Ans:
- Block compression in Teradata involves compressing data at the block level, reducing storage requirements, and improving query performance. It optimizes storage space by compressing similar data within a block, minimizing the amount of disk space needed to store the data.
- BLOCK COMPRESSION contributes to efficient data storage and retrieval, particularly in large-scale data warehouse environments.
77. In Teradata, what are surrogate keys?
Ans:
Surrogate keys in Teradata are artificially generated unique identifiers assigned to tables to serve as primary or unique keys. They are system-generated and independent of the actual data, providing stable and efficient references for relational integrity. Surrogate keys are especially useful in data warehousing scenarios, facilitating data integration, ensuring uniqueness, and simplifying the maintenance of relationships between tables
78. What is Columnar in Teradata?
Ans:
In Teradata, the Columnar feature involves organizing and storing data in a column-wise fashion rather than the traditional row-wise method. This means that instead of storing entire rows together, the values of each column are stored together. This approach improves analytical query performance as only the relevant columns are accessed, reducing I/O overhead and increasing compression efficiency. It is particularly beneficial for data warehousing and analytics workloads.
79. What data protection features does Teradata offer?
Ans:
Teradata focuses on data security and offers a variety of features. Role-based access restrictions guarantee that only authorized users may access particular data, hence increasing data confidentiality. Teradata offers data encryption at rest and in transit, providing an additional degree of security for sensitive information. Furthermore, sophisticated auditing tools track user activity, giving transparency for compliance and security audits and aiding in the identification of possible security breaches.
80. What do you understand about RAID in Teradata?
Ans:
Teradata describes RAID (Redundant Array of Independent Disks) as a storage system that unites several physical hard drives into a single logical unit. This technology is crucial for improving performance and fault tolerance. Teradata typically employs RAID configurations to distribute data across several disks, improving data dependability, availability, and access times. Different RAID levels offer varying amounts of speed and redundancy, allowing for personalization based on specific needs.
81. What are cliques?
Ans:
Cliques in Teradata refer to groups of nodes within a Teradata Multi-node system that share standard sets of disks. These cliques enhance fault tolerance and data redundancy. In the event of a node failure, data stored on the failed node can be accessed from other nodes within the same clique, promoting high availability. Cliques play a vital role in maintaining system integrity and ensuring continuous access to data.
82. What are the different set operators in Teradata?
Ans:
Teradata supports several set operators in SQL queries, providing flexibility in manipulating query results. The UNION operator combines the results of two or more SELECT statements, removing duplicates. INTERSECT returns standard rows between two SELECT statements, while MINUS (or EXCEPT) returns rows from the first query but not the second. These set operators empower analysts to perform complex queries and aggregations efficiently.
83. What is the role of CASE Expression?
Ans:
The CASE expression in Teradata is a powerful tool for incorporating conditional logic into SQL queries. Similar to a switch or IF-THEN-ELSE statement, it allows for the creation of custom conditions within queries.
This expression is valuable for data transformation, allowing users to create calculated columns or modify data based on specific conditions.
It enhances the readability and maintainability of SQL queries by encapsulating complex logic.
84. State the significance of the UPSERT command in Teradata.
Ans:
- The UPSERT command in Teradata is significant for simplifying the process of updating existing records or inserting new records into a table. Combining the actions of UPDATE and INSERT into a single operation, UPSERT streamlines data maintenance.
- It is beneficial when dealing with instances in which data must be synced or when it is unclear whether a record already exists.
85. What is Teradata’s use of hashing in data distribution?
Ans:
Teradata uses hashing algorithms to distribute rows evenly across AMPs based on the Primary Index. Hashing ensures uniform data distribution, preventing hotspots and facilitating efficient parallel processing. It plays a crucial role in optimizing query performance by distributing data evenly for parallel retrieval.
86. Explain the difference between a Full Table Scan and an Index Scan in Teradata.
Ans:
In Teradata, a Full Table Scan involves scanning the entire table to retrieve data, which is suitable for queries with no WHERE clause. An Index Scan, on the other hand, utilizes an index to directly locate and retrieve specific rows, optimizing performance for queries with selective criteria. Index Scans are more efficient for targeted data retrieval.
87. What is the purpose of Teradata Viewpoint?
Ans:
Teradata Viewpoint is a web-based administration and monitoring platform.
It offers administrators a consolidated interface for monitoring system health, managing resources, and analyzing performance.
Viewpoint improves Teradata system management by providing visual insight into system parameters and enabling proactive maintenance.
88. What is the purpose of the Teradata TPump utility
Ans:
Teradata TPump (Table Pump) is a real-time data loading utility designed for continuous and efficient streaming of updates and inserts into Teradata tables. It operates in a constant mode, processing data changes as they occur, making it suitable for near real-time data integration scenarios. TPump utilizes multiple sessions to process data concurrently, optimizing throughput and minimizing latency in data updates. It is precious for applications with rapidly changing data, ensuring timely updates to the Teradata database.
89. Explain the difference between a View and a Macro in Teradata.
Ans:
In Teradata, a View is a virtual table created through a SELECT query, providing a way to encapsulate complex SQL logic into a single named entity. Views simplify query syntax, enhance data security by restricting direct access to underlying tables, and offer a layer of abstraction. They don’t store data but dynamically retrieve it when queried, promoting data consistency.
On the other hand, a Macro is a pre-processed set of SQL statements defined by the user and executed at runtime. Macros allow for the creation of reusable SQL code, incorporating parameterized queries and providing flexibility in adapting to changing requirements. Unlike Views, Macros involve text substitution during execution, contributing to performance efficiency. They are handy for repetitive or standardized query patterns, facilitating code maintenance.
90. Explain the role of Teradata Query Banding.
Ans:
Teradata Query Banding is a feature that allows users to attach metadata or labels to their SQL queries. This information can be helpful in tracking and analyzing query performance and resource consumption or for identifying specific application sessions. Query Banding enhances query management and helps in optimizing resource allocation based on query characteristics.




