
Last updated on 09th Jul 2020| 4919
Oracle Endeca Guided Search allows organizations to help information and influence customers in every step of their search experience.The Endeca Content Acquisition System offers a set of extensible mechanisms to bring both structured information and unstructured content into the MDEX Engine from a variety of source systems. Endeca Assembler dynamically assembles content from any resource and seamlessly combines it with outcomes from the MDEX Engine.
Users want to search, navigate, and analyze all of their data, frequently in large and more than one information sources, “slicing and dicing” throughout any dimension, and drilling down to the best grain of element or zooming out to an aggregate view. At the same time, users want an application that responds intelligently to their current navigation state, guiding them alongside valid paths and removing invalid choices, or “dead ends.”
Users need to experience simple, intuitive navigation even as they function the equivalent of extremely complex, multi-dimensional database intersection queries.
Oracle Endeca Guided Search, primarily based on the Endeca MDEX Engine, is a effective technology designed to assist you construct such effortless and intuitive Guided Navigation applications. This is intended for developers who are new to Oracle Endeca Guided Search, as well as individuals who want to understand the core concepts underlying an Endeca application.
ORACLE ENDECA GUIDED SEARCH COMPONENTS
Oracle Endeca Guided Search has three fundamental components.
These components are:
- Endeca Information Transformation Layer (ITL)
- Endeca MDEX Engine
- Endeca Application Tier
These factors engage with your information sources and application as proven in the following figure.
- Endeca Information Transformation Layer (ITL)
Reads your raw source information and manipulates it into a set of Oracle Endeca MDEX Engine indices.
The ITL consists of the Content Acquisition System (which consists of the Endeca CAS Server and Console, the CAS API and the Endeca Web Crawler), and the Data Foundry (which consists of data-manipulation applications such as Forge).
- Endeca MDEX Engine
The query engine that is the core of Oracle Endeca Commerce which consists of the Indexer (Dgidx), the Dgraph, and the Agraph.The MDEX Engine loads the indices generated by using the indexing component of the Endeca Information Transformation Layer.
Although the Indexer (also known as Dgidx) is mounted as phase of the MDEX Engine package, in effect it is part of the ITL process.
- Endeca Application Tier
Reads your raw source information and manipulates it into a set of Oracle Endeca MDEX Engine indices.
The ITL consists of the Content Acquisition System (which consists of the Endeca
CAS Server and Console, the CAS API and the Endeca Web Crawler), and the Data Foundry (which consists of data-manipulation applications such as Forge).
ENDECA RECORDS, DIMENSIONS, AND PROPERTIES
In order to understand Endeca applications, you should understand three simple constructs:
Endeca records, dimensions, and properties.
Endeca files and dimensions provide the logical structure for the facts in your Endeca application.This structure helps both navigation and search queries.This part introduces these three constructs, and describes their relationships to every other.
Endeca records
Endeca documents are the entities in your records set that you are navigating to or searching for Bottles of wine in a wine store, client documents in a CRM application, and mutual funds in a fund evaluator are all examples of information stored as Endeca records.
Endeca data usually correspond to traditional records in a source database.
Unlike source records, however, Endeca data have been standardized for consistency and categorized with dimension values, which are described below. This classification is a key step towards building the logical structure for your Endeca application. An Endeca record might also correspond to a couple of data in your source data. For example, you could have 4 source information that refer to the same book in a variety of formats: hardcover, paperback, large print, and audio. You can build an Endeca application so that these 4 individual records correspond to a single Endeca record.
Dimensions and dimension values
Dimensions provide the logical structure for organizing the data in your data set.
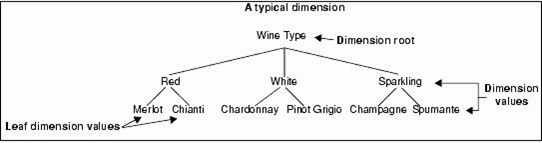
A dimension is a series of associated dimension values, organized into a tree. The top-most dimension value in a dimension tree is recognized as the dimension root. A dimension root always has the same name as its dimension.
The bottom-most dimension values in the tree are referred to as leaf dimension values. You can think of dimension values as “locations” within a dimension tree.
Dimension values are tags, or labels, you use to classify the data in your data set. Tagging a record with a dimension price does the following:
- It organizes the record within the tree structure of the related dimension.
In the example below,
Bottles A and B are prepared under the Red dimension value in the Wine Type dimension, while Bottles C and D are prepared below the White dimension value, and so forth.
- It identifies the record as a valid end result when that dimension value is selected in a navigation query.
Endeca Properties
Endeca properties are the primary attributes of an Endeca record.Are generally generated from a record’s source properties, using source property mapping.
Consist of key/value pairs (property name/property value).
KEYWORD SEARCH
The two kinds of key-word search queries:
Record search and dimension search.
- Record search
A record search query is Endeca’s equal to full-text search.
Record searches return the following:
- A set of data primarily based on a user-defined keyword(s).
- Follow-on query information, based on the returned record set.
Record search queries are carried out against a specific property or dimension, also known as the search key. In order to function a record search, the application’s user:
- Chooses an Endeca property or dimension to act as the search key.
- Specifies a term, or terms, to search for inside the key.
The set of information that a record search returns is made up of all records whose value for the search key consists of the designated term(s). By default, if the record search query specifies multiple terms, a value should include all of the phrases in order for its record to be back (the query is dealt with as an AND query) Record search queries apply to a described record set only (for example, the current record set).
So a record search query is made up of two parts:
- A set of dimension values that discover the presently defined record set (in other words, a navigation query).
- The search key and term(s). In essence, a record search query is a navigation query that is modified by means of a search key and terms.
This is why the two queries, navigation and search, have same information structures for their results: a set of records and follow-on query information.
Only properties or dimensions that have been configured for record search in Endeca Developer Studio can be used as search keys.
- Dimension search
Dimension search queries return dimension values that have names that incorporate search term(s) the end user has specified. Unlike record search, dimension search does no longer require a search key.
Dimension search usually searches any dimension values that have been identified as searchable for the phrases provided. You identify a dimension as searchable in Endeca Developer Studio.
The dimension values that are returned for a dimension search are, via definition, navigable. This means that you can use the statistics in the dimension search results to build navigation queries, providing your customers a seamless transition from a dimension search paradigm to a navigation paradigm.

Enroll in Oracle Endeca Commerce Training Make You Expert in Advanced Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
COMBINING SEARCH QUERIES
You can combine record search and dimension search queries into one consolidated MDEX Engine query. Similarly, you combine search queries to provide your users a little more information as they navigate through your site.
Combining search queries lets you to retrieve not only a subtle record set with follow-on query information, however additionally a separate set of navigable dimension values primarily based on the same keyword(s). You can present this separate set of dimension values to the end user as a more targeted listing of potential follow-on queries (in addition to the standard follow-on queries that accompany a record search).When you pass more than one kinds of search to the MDEX Engine in one query, the Endeca Presentation API treats each search as an individual request to the MDEX Engine. The search queries are completely independent of each other, and the MDEX Engine returns a end result object for each search type. The Presentation API then combines these a couple of result objects into one query result object.
COMPARING DIMENSION SEARCH AND RECORD SEARCH
Dimension search and record search each have their very own strengths.
In general, you should:
- Use dimension search when the search phrases are included in your dimension hierarchy.
- Use record search when you desire to search unstructured information that is no longer part of the dimension hierarchy.
- Dimension search is more suitable than record search when the value for the search key does not consistently include the search terms throughout all records.
- On the other hand, it is inappropriate to create dimension values out of certain types of property values that are long, wordy, or in any other case unsuitable (for example, descriptions or reviews). Because these property values are not covered in the dimension hierarchy, they can’t be searched with dimension search. They need to be searched the usage of record search.
Endeca Commerce Components
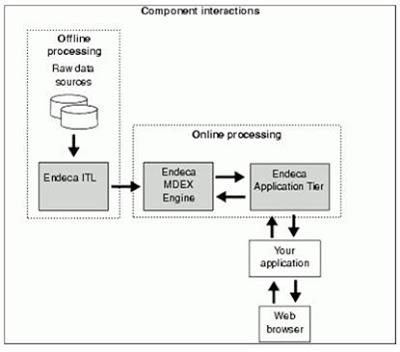
Oracle Endeca Commerce is comprised of three major components.
These components are:
- Endeca Information Transformation Layer (ITL)
- Endeca MDEX Engine
- Endeca Application Tier
Endeca Components
Endeca Information Transformation Layer (ITL)
- Reads your raw source data and manipulates it into a set of Oracle Endeca MDEX Engine indices.
- The ITL consists of the Content Acquisition System (which includes the Endeca CAS Server and Console, the CAS API and the Endeca Web Crawler), and the Data Foundry (which includes data-manipulation programs such as Forge).
Endeca MDEX Engine
- The query engine that is the core of Oracle Endeca Commerce which consists of the Indexer (Dgidx), the Dgraph, and the Agraph.
- The MDEX Engine loads the indices generated by the indexing component of the Endeca Information Transformation Layer.
- Although the Indexer (also known as Dgidx) is installed as part of the MDEX Engine package, in effect it is part of the ITL process.
Endeca Application Tier
- After the indices are loaded, the MDEX Engine receives queries from the Endeca Application Tier, executes them against the loaded indices, and returns the results to the client application.
- The Application Tier provides an interface to the MDEX Engine via the Endeca Assembler. The Assembler acts as a language-agnostic interface for aggregating and sending queries to the MDEX Engine, and executing any necessary post-processing on the results.
Endeca Queries
- Oracle Endeca Commerce uses two types of queries: navigation queries and keyword search queries.
- Navigation queries return a set of records based on application-defined record characteristics (such as wine type or region in an online wine store), plus any follow-on query information.
- Keyword search queries return a set of records or dimensions based on a user-defined keyword, plus any follow-on query information. For more information, see “Using Keyword Search.”
Endeca records
- Endeca records are the entities in your data set that you are navigating to or searching for.
- Records are the fundamental units of data.
- Attributes are the fundamental units of a record schema which describes the data model of Records.
Dimensions and dimension values
- Dimensions provide the logical structure for organizing the records in your data set.
- A dimension is a collection of related dimension values, organized into a tree. The top-most dimension value in a dimension tree is known as the dimension root. A dimension root always has the same name as its dimension.
- A dimension is a collection of related dimension values, organized into a tree.
- The top-most dimension value in a dimension tree is known as the dimension root.
- A dimension root always has the same name as its dimension.
Endeca Properties
- Endeca properties are the basic attributes of an endeca record.
- Are usually generated from a record’s source properties, using source property mapping.
- Consist of key/value pairs (property name/property value).
- Can be searched and displayed.
The next step in creating a pipeline is to create an Oracle Endeca EAC application. To create an EAC application, you can use the deployment template given by Oracle Endeca along with ToolsAndFrameworks. Open a command prompt in admin mode (Check this post if you are not sure how to open a command prompt in admin mode in windows.) and move to ENDECA_HOME/ToolsAndFrameworks/version/deployment_template/bin (in my machine it was in C:\Endeca\ToolsAndFrameworks\3.1.2\deployment_template\bin\deploy.bat) and run deploy.bat. When you execute the batch program it would prompt you to enter the application name and port of EAC, MDEX graphs and so on. Please give the appropriate port numbers as per your local installation. In this example we are using “simplecatalog” as the application name. See the EAC application creation log in the appendix section of this post.
Oracle Endeca Pipeline Creation.Now the time to create the pipeline as the taxonomy we identified in the second step. Start the Oracle Endeca Developer Studio and open the pipeline file simplecatalog.esp file from ENDECA_HOME/Apps/simplecatalog/config/pipeline. (In my machine the .esp file was located in C:\Endeca\Apps\simplecatalog\config\pipeline\simplecatalog.esp) I have captured the whole process of creating pipeline for the above mentioned data and taxonomy in a video. Please check the video given below.
Important steps in creating the pipeline.
- Open the .esp file from the EAC simplecatalog application folder.
- Add two simple properties (id, name).
- Add three dimensions (brand, color, price).
- Configure the source record – Endeca record mapping.
- Add dimension values for price range dimension.
To initialize simplecatalog application open a command prompt in admin mode and move to ENDECA_HOME/Apps/simplecatalog/control folder and run the initialize_services.bat. (In my machine initialize_services.bat was at C:\Endeca\Apps\simplecatalog\control). EAC application initialization log can be found in the appendix section.
Indexing Data into MDEX.Moving data into MDEX is two steps for process for baseline index.
- Run load_baseline_test_data.bat (C:\Endeca\Apps\simplecatalog\control\load_baseline_test_data.bat)
- Run baseline_update.bat (C:\Endeca\Apps\simplecatalog\control\baseline_update.bat)
Console log for both bat programs can be found in the appendix section.
Testing Pipeline and Indexed Data Using jsp Reference Application.You can test the newly created application using jsp reference application. Check the video given below to see the details.
Supported Operating Systems:
Linux 5, Linux RHEL 5 running on x64 processors. Windows Server 2008 R2Enterprise running on x64 processors.
Windows 7 is not supported for production deployment, but operates sufficiently toenable training and small scale development work.Windows XP is not supported.
Disk Space Requirement:
On Windows, the installation process requires a minimum of 400 MB in the systempartition and 200 MB in the target partition. To avoid an “out of drive space” error duringthe installation process, you should allow the minimum of memory required on the systemand target partitions.On Linux, the Oracle Endeca Server unpacks to approximately 430 MB..
Conclusion
Endeca is a powerful scalable dynamic search and browse platform capable of handling even the most difficult of collaborative systems and catalogs, aggregating content from multiple sources in any format. It offers the user several methods of customization and employs its own flavor of artificial intelligence to fill in the gaps where needed. Endeca is paving the way for the future of aggregated content derived from multiple sources created by multiple users adhering to different guidelines, if any guidelines at all. It has become one of the premier solutions for businesses wanting to leverage all of their information resources while having the flexibility of stylized customization.




