
Last updated on 09th Jul 2020| 3243
Teradata is massively parallel open processing system for developing large-scale data warehousing applications. Teradata is an open system. It can run on Unix/Linux/Windows server platform. This tool provides support to multiple data warehouse operations at the same time to different clients.
Teradata Corporation is an American IT firm. It is a vendor of analytic data platforms, application, and other related services. The firm develops a product to consolidate data from the various source and make the data available for analysis.
- Teradata offers a full suite of service which focuses on Data Warehousing
- The system is built on open architecture. So whenever any faster devices are made available, it can be incorporated into the already build architecture.
- Teradata supports 50+ petabytes of data.
- Single operation view for a large Teradata multi-node system using Service Workstation
- Compatible with wide range of BI tool to fetch data.
- It can act as a single point of control for the DBA to manage the database.
- High performance, diverse queries, in-database analytics and sophisticated workload management
- Teradata allows you to get the same data on multiple deployment options
- Linear scalability helps to support more users/data/queries/query complexity without losing performance. When system configuration grows performance increases linearly.
- System is built on open architecture, so whenever any faster chip and device are made available it can be incorporated into the already build architecture.
- Automatic distribution of data across multiple processors (AMP) evenly. Components divide task into approximately equal pieces so all parts of the system are kept busy to accomplish the task faster.
Teradata offers following powerful features:
Linear Scalability: Offers linear scalability when dealing with large volumes of data by adding nodes to increase the performance of the system.
Unlimited Parallelism: Teradata is based on MPP (Massively Parallel Processing Architecture). So, it is designed to be parallel since the beginning. It can divide a large task into smaller tasks and run them in parallel
Mature Optimizer: Tera data Optimizer can handle up to 64 joins in a query.
Low TCO: Tera data has a low total cost of ownership. It is easy to setup, maintain, and administrate.
Load & Unload utilities: Tera data provides load & unload utilities to move data into/from Teradata System.
Connectivity: This MPP system can connect to channel-attached systems like a mainframe or network-attached systems.
SQL: Tera data supports SQL to interact with the data stored in tables. It provides its extension.
Robust Utilities: Tera data provides robust utilities to import/export data from/to Teradata systems like Fast Export, FastLoad, MultiLoad, and TPT.
Automatic Distribution: Teradata can distribute the data to the disks automatically with no manual intervention.
Teradata ArchitectureThe main components of Teradata Architecture are PE(Parsing Engine), BYNET, AMP(Access Module Processor), Virtual Disk. Following is the logical view of the architecture:
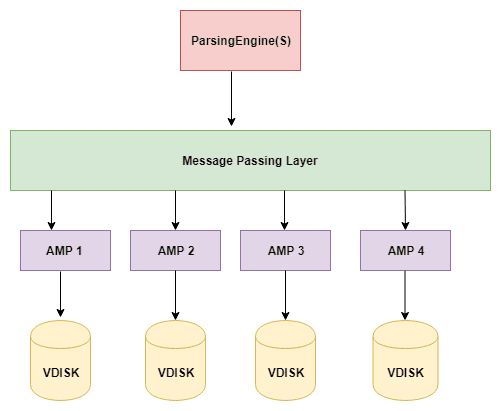
When a user fires an SQL query it first gets connected to the PE (Parsing Engine). The processes such as planning and distributing the data to AMPS are done here. It finds out the best optimal plan for query execution. The following are the processes performed by PE:
- Parser: The Parser checks for the syntax, if true forward the query to Session Handler.
- Session Handler: it does all the security checks, such as checking of logging credentials and whether the user has permission to execute the query or not.
- Optimizer: It finds out the best possible and optimized plan to execute the query.
- Dispatcher: The Dispatcher forwards the query to the AMPs.
BYNET
The BYNET acts as a channel between PE and AMPs. It acts as a communicator between the two. There are two BYNETs in Teradata ‘BYNET 0’ and ‘BYNET 1’. But we refer them as single BYNET system. The reason for having 2 BYNETs is:
- If one BYNET fails, the second one can take its place.
- When data is large, both BYNETs can be made functional which improves the communication between PE and AMPs, thus fastening the process.
AMP
Access Module Processor is a virtual processor which is connected to PE via BYNET. Each AMP has its own disk and is allowed to read and write in its OWN disk. This is called as ‘SHARED NOTHING ARCHITECTURE’. When the query is fired , Teradata distributes the rows of table on all the AMPs and when it calls for any data all AMPs work simultaneously to give back the data. This is called PARALLELISM. The AMP executes any SQL requests in three steps
- Lock the table.
- Execute the operation requested.
- End the transaction.
Disk
Teradata offers a set of Virtual Disks for each AMP. The storage area of each AMP is called as Virtual Disk or Vdisk. The steps for executing the query are below:
- The user fires the query which is sent to PE.
- PE does the security and syntax checks, and finds out the best optimal plan to execute the query.
- The table rows are distributed on the AMP and the data is retrieved from the disk.
- The AMP sends back the data through BYNET to PE.
- PE returns back the data to the user.
Teradata users or any other applications submit a query in the form of SQL (Structure Query Language) and receive the answer. But behind the scene, it has to pass many tests which determine its fate.
Below are the steps which describe the Life Cycle of a Teradata Query:
Query Submit:-The starting point of a Teradata query starts when user submits a query. A call level interface (CLI) prepares parcel from that SQL query. Parcels can be two types –
- Request parcel: contains SQL statement.
- Data parcel: contains any parameter values that may be supplied.

Best Practical Oriented Teradata Training By Experts Trainers
Weekday / Weekend BatchesSee Batch DetailsThen parcels are sent to Micro Teradata Director Program (MTDP) which establish session to the Teradata database. MTDP prepares a request message containing the parcel for transmission to the Teradata database via network. A Micro Operating System Interface (MOSI) is used to accept this request message to the operating system and network protocol like TCP/IP.
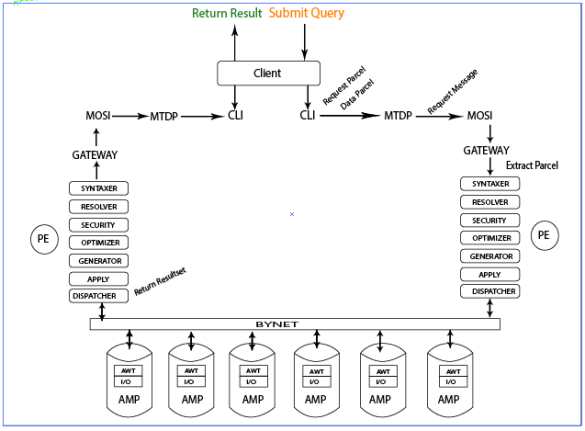
Extract Parcel:
The PE receives the request message via gateway and PE will extract request parcel and data parcel. The PE is composed of several modules: syntaxer, resolver, security, optimizer, generator and dispatcher.
Passes through security:
Syntaxer:
Check the SQL query for proper syntax.
- Resolver:
look up for existence of objects in data dictionary.
- Security:
Determine if the user or database has proper access rights.
- Optimizer:
It creates most optimal plan for a query.
- Generation:
Create steps for the winning plan.
- Dispatcher:
Dispatches the steps to AMP via bynet.
Execute the query:-Each AMP owns a portion of data and manages its own sets of lock and has its own sets of data dictionary. Each one works independently of the other AMPs. Execution steps are received in parallel by all AMPs participating in the step, and an AMP worker task (AWT) on each AMP is assigned to execute the step.
AWT may sort, aggregate and redistribute the data as needed to produce answer set.
Produce result Sets:-Each participating AMP will returns it portion of result to the Bynet which merge all the result set and prepare the final result and pass it to dispatcher.
Return Answer to the user:-
Dispatcher now packages the result into response parcel and dispatch it to the Gateway to deliver over the network connection as response message. The response parcel is then extracted from response message and the answer set is returned to the user.
Applications of Teradata:Customer Data Management: Helps to maintain long-lasting relationships with customers.
Master Data Management: Helps to develop an environment where master data can be used, synchronized, and stored.
Finance and Performance Management: Helps organization to improve the speed and quality of financial reporting. It reduces finance infrastructure costs, and proactively manage enterprise performance.
Supply Chain Management: Improve supply chain operations which help to improved customer service, reduced cycle times, and lower inventories.
Demand Chain Management: Helps to Increase customer service levels and sales. It also helps companies to predict the demand for their store item accurately.
Teradata Data TypesEach column in a table is associated with a data type. Data types specify what kind of values will be stored in the column. Every data value belongs to an SQL data type.
Teradata Database supports the following categories of data types. For a complete list of supported data types and detailed information about each data type, see the below table, such as:
| Data Types | Description |
|---|---|
| Array | An Array data type is used to store and access the multidimensional data. It can store many values of the same specific data type in a sequential or matrix-like format. |
| Byte | Byte data types store raw data as logical bitstreams. These data types are stored in the client system format.Teradata Database does not translate these data types. The data is transmitted directly from the memory of the client system. |
| Character | Character data types represent characters that belong to a given character set. |
| Dataset | A complex data type that represents self-describing data stored in a format conforming to some schema. |
| DateTime | DateTime data types represent a date, time, and timestamp values. |
| Geospatial | Geospatial data types represent geographic information and provide a way for applications that manage, analyze, and display geographic information to interface with Teradata Database. |
| Interval | Interval data types represent a period. For example, an Interval value can represent a period that includes several years, months, days, hours, minutes, or seconds. |
| JSON | The JSON data type represents that data which are in JavaScript Object Notation format. |
| Numeric | Numeric data types represent a numeric value that is an exact numeric number such as integer or decimal or an approximate numeric number such as floating-point. |
| Parameter | Parameter data types are used only with input or result parameters in a function, method, stored procedure, or external stored procedure. |
| Period | A Period data type represents a time period, where a period is a set of contiguous time granules that extends from a beginning bound up to but not including an ending bound. |
| UDT | UDT (User-Defined Type) data types are custom data types that are defined to model the structure and behavior of the data used by the applications. |
| XML | The XML data type represents XML content. The data is stored in a compact binary form that preserves the XML document’s information set, including the hierarchy information and type information derived from XML validation. |
The Teradata Database supports the following core data type attribute, such as:
| Data Type Attributes | Description |
|---|---|
| Not Null | It means the fields of a column must contain a value; they cannot be null. |
| Uppercase | It specifies the character data for a column is stored as uppercase. |
| [NOT] Case-Specific | It specifies the case for character data comparisons and collations. |
| Format | It controls the display of expressions, column data, and conversions between data types. |
| Title | It defines a heading to display or print the different results from the column name, which is used by default. |
| As | It assigns a temporary name to an expression. |
| Named | Named is a Teradata extension to the ANSI standard. For ANSI compliance, use AS instead of Named. |
| Default | It is a user-defined default value that inserts in the field when a value is not specified for a column in an INSERT statement. |
| With Default | It is a system-defined default value that inserts in the field when a value is not specified for a column in an INSERT statement. |
| With Time Zone | It is used with the TIME or TIMESTAMP data type to specify a TIME or TIMESTAMP value with displacement from UTC as defined for the system. |
| Character Set | It specifies the server character set for a character column. |
Relational Database Management System (RDBMS) is a DBMS software that helps to interact with databases. They use Structured Query Language (SQL) to interact with the data stored in tables.
DatabaseDatabase is a collection of logically related data. They are accessed by many users for different purposes. For example, a sales database contains entire information about sales which is stored in many tables.
TablesTables is the basic unit in RDBMS where the data is stored. A table is a collection of rows and columns. Following is an example of employee table.
| EmployeeNo | FirstName | LastName | BirthDate |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 11/6/1984 |
| 102 | Robert | Williams | 3/5/1983 |
| 105 | Robert | James | 12/1/1984 |
| 103 | Peter | Paul | 4/1/1983 |
A column contains similar data. For example, the column BirthDate in Employee table contains birth_date information for all employees.
| BirthDate |
| 1/5/1980 |
| 11/6/1984 |
| 3/5/1983 |
| 12/1/1984 |
| 4/1/1983 |
Row is one instance of all the columns. For example, in employee table one row contains information about single employee.
Teradata Aggregate FunctionsAggregate functions are typically used in arithmetic expressions. Aggregate functions operate on a group of rows and return a single numeric value to each group’s result table.
supports common aggregate functions. They can be used with the SELECT statement.
- COUNT
- SUM
- MAX
- MIN
- AVG
Conclusion:
- Teradata is massively parallel open processing system for developing large-scale data warehousing applications
- Teradata was a division of NCR Corporation. It incorporated in 1979 but parted away from NCR in October 2007
- Teradata offers a full suite of service which focuses on Data Warehousing
- Teradata offers linear scalability when dealing with large volumes of data by adding nodes to increase the performance of the system.
- Three important components of Teradata are 1. Parsing Engine
- 2.MPP 3. Access Module Processors (AMPs
- Teradata offers a complete range of product suite to meet Data warehousing and ETL needs of any organization
- Teradata application mainly used for Supply Chain Management, Master Data Management, Demand Chain Management, etc.




