
Last updated on 14th Dec 2021| 2640
HDFS is a distributed file system that handles large data sets running on commodity hardware. It is used to scale a single Apache Hadoop cluster to hundreds (and even thousands) of nodes. HDFS is one of the major components of Apache Hadoop, the others being MapReduce and YARN.
- Introduction to HDFS
- The goals of HDFS
- Characteristics of HDFS
- HDFS storage types
- HDFS architecture, NameNodes and DataNodes
- How does HDFS work?
- HDFS data replication
- HDFS use cases and examples
- Benefits Of HDFS
- Conclusion
Introduction to HDFS:
HDFS is a distributed file system that manages large data sets that work on asset hardware. It is used to measure one set of Apache Hadoop into hundreds (even thousands) of nodes. HDFS is one of the major components of Apache Hadoop, the others are MapReduce and YARN. HDFS should not be confused with or replaced by Apache HBase, which is a non-column-based website management system that resides over HDFS and can better support real-time data needs with its memory processing engine.
The goals of HDFS:
Quick detection of hardware failure
Because a single HDFS event can contain thousands of servers, failure of at least one server is inevitable. HDFS is designed to detect errors and recover automatically.
Access to data streaming
HDFS is more intended for cluster processing compared to interoperability, so the emphasis on architecture is for high data output, which allows streaming access to data sets.
Residence of large data sets
HDFS allows applications with data sets usually gigabyte to satellites in size. HDFS provides high integrated data bandwidth and can reach hundreds of nodes in a single batch.
Depression
For easy access, HDFS is designed to be compatible with all multiple hardware platforms and compatible with a wide variety of basic applications.
Characteristics of HDFS:
1. Tolerance of Mistakes
Troubleshooting in Hadoop HDFS is a system operating system under adverse conditions. It is very tolerant of mistakes. Hadoop framework divides data into blocks. Then he made many copies of the blocks on different machines in the collection. Therefore, if any machine in the collection goes down, the client can easily access its data from another machine that contains the same copy of the data blocks.
2. High Availability
Hadoop HDFS is the most widely available file system. In HDFS, data is duplicated between the notes of the Hadoop collection by creating an image of blocks in other slaves present in the HDFS collection. Therefore, whenever a user wants to access this data, he or she can access his or her data on the slaves containing its blocks. During adverse conditions such as node failure, the user can easily access his data on other nodes. Because duplicate copies of blocks are available on other nodes in the HDFS collection.
3. High fidelity
HDFS provides reliable data storage. It can store data within 100 petabytes. HDFS stores data reliably in the collection. Divides data into blocks. The Hadoop framework stores these blocks in the existing nodes in the HDFS collection. HDFS saves data reliably by creating an image of each existing block in the collection. It therefore provides a place for tolerance. If a node in a collection containing data is down, the user can easily access that data from other nodes. HDFS automatically creates 3 metaphors for each block containing data available in nodes. Thus, data is readily available to users. The user is therefore not facing the problem of data loss. Therefore, HDFS is very reliable.
4. Repetition
Data duplication is a distinctive feature of HDFS. Repetition solves the problem of data loss in a bad situation like hardware failure, node crashes etc. HDFS keeps track of the duplication process from time to time. HDFS also continues to perform user data simulations on a separate machine in the collection. Therefore, when any node goes down, the user can access data from other devices. Therefore, there is no possibility of losing user data
5. Strength
Hadoop HDFS stores data in multiple nodes in the collection. Therefore, whenever demand increases you can rate the collection. Two measurement methods are available in HDFS: Vertical and Horizontal Scalability.
6. Distributed Storage
All features in HDFS are available with distributed storage and duplication. HDFS stores data in a widely distributed manner. In Hadoop, data is separated by blocks and stored in nodes available in the HDFS collection. HDFS then creates an image for each block and stores it on other nodes. If one machine in a collection crashes we can easily access our data from other nodes that contain symbols.
HDFS storage types:
HDFS-related storage type identifies sub-media media.
HDFS supports the following final types:
Archive – The last archive is the most dense and useful for rarely accessible data. This last type is cheaper for each TB than regular hard disks.
DISK – Hard disk drives are inexpensive and offer consistent I / O performance. This is the default type of storage.
SSD – Solid drives are useful for storing hot data and I / O-intensive applications.
RAM_DISK – This type of special memory storage is used to accelerate low intensity, writes single-replica.
When you add a Database List, you can specify which type of storage you are using, by first inserting the path by type of storage, in brackets. If you do not specify storage type, it is considered DISK.
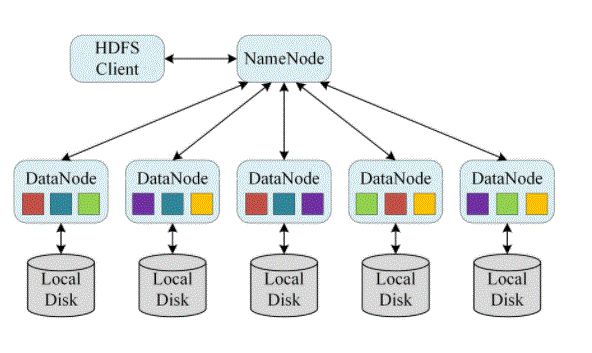
- HDFS uses primary / secondary architecture. The NameNode HDFS collection is the main server that controls the location of the file system name and controls client access to files. As an integral part of the Hadoop Distributed File System, NameNode maintains and manages file system name space and gives customers the appropriate access permissions. System dataNodes control the storage attached to the nodes they operate.
- HDFS exposes file system names and makes user data stored in files. The file is divided into one or more blocks stored in the DataNodes set. NameNode performs the functions of the namespace file system, which includes opening, closing and renaming files and directories. NameNode also controls blocking of blocks in DataNodes. DataNodes provides literacy requests from file system clients. In addition, they do create a block, delete and duplicate when NameNode commands them to do so.
- HDFS supports traditional file history organisations. An application or user can create indexes and save files within these indexes. File system domain name configuration is similar to many other file systems – the user can create, delete, rename or move files from one directory to another.
- NameNode records any changes in the file system namespace or its attributes. The application can specify the number of file templates that HDFS should take care of. NameNode stores a number of copies of a file, called the replication factor of that file.
HDFS architecture, NameNodes and DataNodes:

Develop Your Skills with Advanced Big Data Hadoop Developer Certification Training
Weekday / Weekend BatchesSee Batch Details
- HDFS enables faster data transfer between computer nodes. Originally, it was integrated closely with MapReduce, a data processing framework that filters and classifies work between compound nodes, and organises and summarises results into a coherent answer to a question. Similarly, when HDFS captures data, it splits the data into separate blocks and distributes it across different locations in the collection.
- With HDFS, data is recorded on the server once, and read and reused many times afterwards. HDFS has a main NameNode, which tracks where file data is stored in a collection.
- HDFS also has a lot of DataNodes in the hardware package – usually one node per set. DataNodes are usually organised within the same storage location in the data centre. Data is fragmented into separate blocks and distributed between different DataNodes for storage. Blocks are repeated on all nodes, allowing for highly efficient parallel processing.
- NameNode knows which DataNode contains which blocks and where DataNodes reside within the machine collection. NameNode also controls access to files, including read, write, create, delete and duplicate data block across DataNodes.
- NameNode works in conjunction with DataNodes. As a result, the collection can be adapted flexibly to the server capacity in real time by adding or removing nodes as needed.
- DataNodes are constantly in touch with NameNode to determine if DataNode needs to complete certain tasks. As a result, NameNode always knows the status of each DataNode. If NameNode detects that a single DataNode is not working properly, it may redistribute that DataNode function to a different location containing the same data block. DataNodes also connects, enabling them to collaborate during normal file operations.
- In addition, HDFS is designed to be very tolerant of errors. The file system duplicates – or copies – each piece of data multiple times and distributes copies in individual nodes, placing at least one copy on a separate server than other copies.
How does HDFS work?
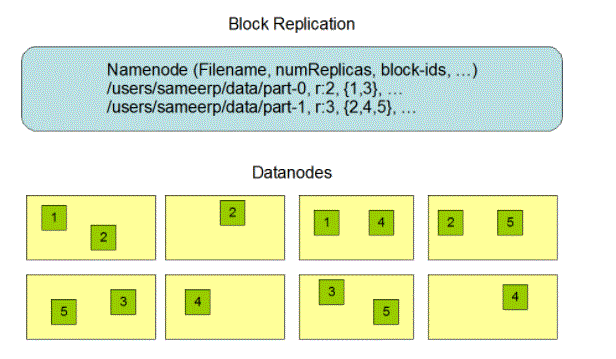
- Data replication is a crucial part of the HDFS format because it ensures that information is often out there within the event of a node or hardware failure.
- As mentioned earlier, information is separated by blocks and duplicated across multiple nodes within the assortment.
- Therefore, once one node goes down, the user will access the info that was in this node from different devices.
- HDFS keeps track of the duplication method from time to time.
- Hadoop Distributed filing system (HDFS) is the main information storage system utilised by Hadoop applications.
- HDFS uses NameNode and DataNode design to implement a distributed filing system that gives access to superior information across all the foremost dangerous Hadoop collections.
- Hadoop itself may be a distributed open supply process platform that controls the processing and storage of huge information applications. HDFS is an integral part of several Hadoop system technologies. Provides reliable information management ways and supports huge information analytics applications.
HDFS data replication:
HDFS use cases and examples:
Hadoop Distributed File System has emerged from Yahoo as part of the company’s online advertising and search engine requirements. Like other web-based companies, Yahoo has integrated many applications that are accessible to a growing number of users, who are creating additional data.
HDFS has found more use than meets ad delivery requirements and search engine requirements. The New York Times has used it as part of major photo editing, Media6Degrees logging and machine learning, LiveBet logging and analysis opportunities, Joost session analysis, and Fox Audience Network logging and data mining. HDFS is also the backbone of many open source data pools.
Typically, companies in several industries use HDFS to manage large data pools, including:
Electricity companies. The energy industry uses phasor measurement units (PMUs) across all of its transmission networks to monitor the health of intelligent grids. These high-speed sensors measure current and voltage by amplitude and phase at selected transmission terminals. These companies analyse PMU data to detect system errors in network components and to correct the grid accordingly. For example, they may switch to a backup power source or perform a load adjustment. PMU networks close thousands of records per second, and as a result, power companies can benefit from less expensive, more accessible file systems, such as HDFS.
Marketing. Targeted marketing campaigns depend on advertisers knowing more about their target audience. Marketers can access this information from a variety of sources, including CRM programs, direct email responses, point trading systems, Facebook and Twitter. Because a large portion of this data is unstructured, the HDFS collection is an inexpensive place to store data before analysing it.
Oil and gas suppliers. Oil and gas companies work with a variety of data formats with very large data sets, including videos, 3D Earth models and sensor machine data. The HDFS collection can provide an appropriate platform for analysing the required large data.
Research. Data analysis is an important part of research, so, here again, HDFS collections provide an inexpensive way to store, process and analyse large amounts of data.
Benefits Of HDFS:
There area unit 5 main advantages of exploitation HDFS, that include:
Cost performance. DataNodes store knowledge that depends on cheap hardware returning off the shelf, reducing storage prices. Also, as a result of HDFS is associate degree open supply, there’s no licence tax.
Large knowledge set storage. HDFS stores a large variety of knowledge of any size – from megabytes to petabytes – and in any format, together with formal and informal knowledge.
Quick detection of hardware failure. HDFS is meant to observe errors and recover itself.
Depression. HDFS is transportable to all or any hardware platforms, and is compatible with a variety of applications, together with Windows, UNIX system and macintosh OS / X.
Stream access to knowledge. HDFS is made for prime knowledge transfer, best for access to knowledge streaming.
Conclusion:
We can say that HDFS is very tolerant of mistakes. It reliably stores large amounts of data despite hardware failures. It also offers Higher ratings and higher availability. HDFS therefore enables Hadoop functionality.
Hadoop is a powerful program built as a platform to support a large number of different data applications. It provides a visual interface for processing both structured and complex data thus helping to integrate various data.




