
Last updated on 24th Jan 2022| 4032
- Introduction to File Format in Hadoop
- What is Data Serialization?
- What is Hadoop Input Format?
- What is the arrangement of Hadoop Storage Serialization?
- What is the reason for record designs?
- Kinds of Hadoop File Formats
- Examinations Between Different File Formats
- How quick would you be able to peruse each datum component in a record?
- Scopes of Hadoop
- List the center parts of Hadoop
- Benefits of Hadoop
- Drawbacks of Hadoop
- Conclusion
Introduction to File Format in Hadoop:
Impala upholds various document designs utilized in Apache Hadoop.
Impala can load and inquiry information documents created by other Hadoop parts like Spark, and information records delivered by Impala can be utilized by different parts moreover. The accompanying areas talk about the methodology, limits, and execution contemplations for utilizing each document design with Impala. The document design utilized for an Impala table has huge execution results. Some record designs incorporate pressure support that influences the size of information on the plate and, thusly, how much I/O and CPU assets are needed to deserialize information.
The measures of I/O and CPU assets required can be a restricting component in question execution since questioning frequently starts with moving and de-pressurizing information. To lessen the expected effect of this piece of the interaction, information is regularly packed. By packing information, a more modest complete number of bytes are moved from plate to memory. This decreases how much time is taken to move the information, yet a tradeoff happens when the CPU de-pressurizes the substance.
For the document organizes that Impala can’t write to, make the table from inside Impala sooner rather than later and embed information utilizing another part like Hive or Spark. See the table beneath for explicit document designs.
- Information serialization is a method for addressing information in the capacity of memory as a progression of bytes. It permits you to save information to a plate or send it across the organization.
- For instance, how would you serialize the number 123456789? It tends to be serialized as 4 bytes when put away as a Java int and 9 bytes when put away as a Java String.
- Avro is an effective information serialization structure, generally upheld all through Hadoop and its environment. It additionally upholds Remote Procedure Calls or RPC and offers similarity with programming climate without compromising execution. How about we investigate the information types upheld by Apache Avro and Avro Schemas.
What is Data Serialization?
- The records or different articles that ought to be utilized for input are chosen by the Input Format.
- Input Format characterizes the Data parts, which characterizes both the size of individual Map errands and its potential execution server.
- Input Format characterizes the Record Reader, which is liable for perusing real records from the info documents.
What is Hadoop Input Format?
How the information records are separated and perused in Hadoop is characterized by the Input Format. A Hadoop Input Format is the main part of Map-Reduce, it is liable for making the information parts and partitioning them into records. If you are curious about MapReduce Job Flow, so follow our Hadoop MapReduce Data stream instructional exercise for real understanding.
At first, the information for a MapReduce task is put away in input documents, and info records regularly dwell in HDFS. Albeit these documents design is discretionary, line-based log records and double organization can be utilized. Utilizing Input Format, we characterize how these information records are parted and perused.
The Input Format class is one of the central classes in the Hadoop MapReduce structure which gives the accompanying usefulness:
What is the arrangement of Hadoop Storage Serialization?
Serialization is the method involved with transforming information structure into byte stream either for capacity or transmission over an organization. De serialization is the most common way of changing over byte stream into information structures.
Writable is the principle serialization design utilized by Hadoop. Writable are quick and minimized yet hard to expand or use from dialects other than Java. A few serialization systems are being utilized inside the Hadoop environment.
Frugality:
Developed for executing cross-language points of interaction to administrations. It utilizes an IDL record to produce stub code to use in performing RPC customers and servers that impart consistently across programming dialects. It upholds MapReduce.
Convention Buffers (protobuf):
It gives offices to trade information between administrations written in various dialects. likewise characterized using an IDL-like frugality. It is neither splittable nor compressible and doesn’t uphold MapReduce-like frugality.
Avro Files:
It is a language-impartial information serialization framework. Avro stores the metadata information with information. Avro upholds MapReduce. Avro information records are impeded compressible and splittable. Avro records support the pattern development which improves Avro than succession Sequence Files.
- Word record (DOC and DOCX) …
- Hypertext markup language (HTML and HTM) …
- Microsoft dominates bookkeeping page records (XLS and XLSX) …
- Text record (TXT)
What is the reason for record designs?
A document design is a standard way that data is encoded for capacity in a PC record. It determines how pieces are utilized to encode data in an advanced stockpiling medium. Document organizations might be either restrictive or free and might be either unpublished or open.
Sorts of archive documents:
Portable record design (PDF) A PDF document is a typical record type in many workplaces.

Learn Advanced Hadoop Administration Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details- Text documents
- Arrangement File
- Avro information records
- Parquet document design
Kinds of Hadoop File Formats:
Hive and Impala table in HDFS can be made utilizing four unique Hadoop record designs:
1. Text records:
A text record is the most fundamental and intelligible document. It very well may be perused or written in any programming language and is generally delimited by comma or tab.
The text record design consumes more space when a numeric worth should be put away as a string. It is likewise hard to address double information like a picture.
2. Grouping File:
The sequence file arrangement can be utilized to store a picture in the paired organization. They store key-esteem sets in a twofold holder design and are more effective than a text record. In any case, arrangement documents are not intelligible.
3. Avro Data Files:
The Avro document design has effective capacity because of enhanced double encoding. It is broadly upheld both inside and outside the Hadoop biological system. The Avro record design is great for long-haul stockpiling of significant information. It can peruse from and write in numerous dialects like Java, Scala thus on. Schema metadata can be inserted in the document to guarantee that it will be coherent all the time. Blueprint advancement can oblige changes. The Avro record design is viewed as the most ideal decision for broadly useful capacity in Hadoop.
4. Parquet File Format:
Parquet is a columnar configuration created by Cloudera and Twitter. It is upheld in Spark, MapReduce, Hive, Pig, Impala, Crunch, etc. Like Avro, pattern metadata is implanted in the document.
Parquet document design utilizes progressed improvements depicted in Google’s Dremel paper. These improvements lessen the extra room and increment execution. This Parquet document design is thought of as the most proficient for adding various records all at once. A few enhancements depend on recognizing rehashed designs. We will investigate what information serialization is in the following segment.

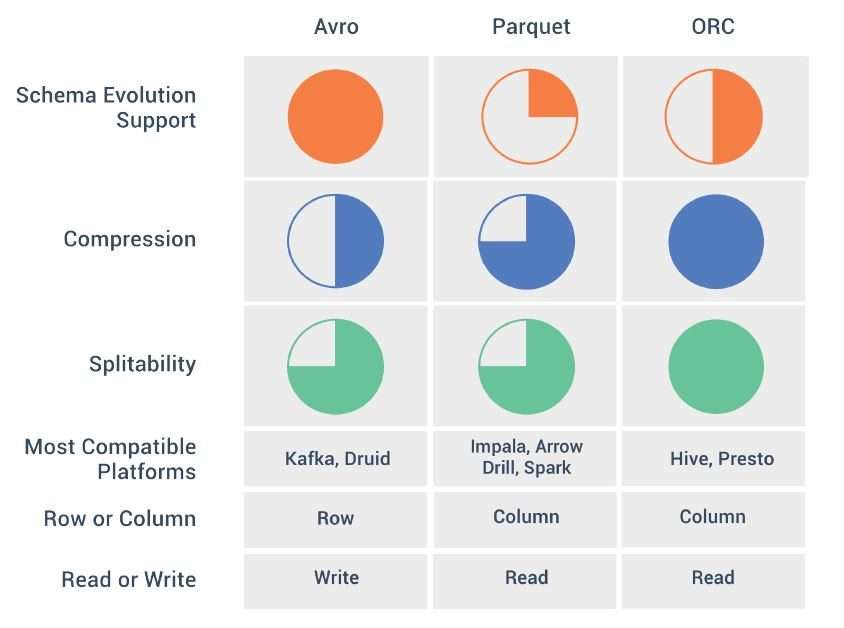
- AVRO is a line-based capacity design, while PARQUET is a columnar-based capacity design.
- PARQUET is vastly improved for insightful questioning, i.e., peruses and questioning is significantly more proficient than composing.
- AVRO is greatly developed than PARQUET with regards to pattern advancement. PARQUET just backings blueprint affix, while AVRO upholds a much-included diagram advancement, i.e., adding or altering sections.
- PARQUET is great for questioning a subset of segments in a multi-segment table. AVRO is ideal on account of ETL tasks, where we want to question every one of the segments.
- PARQUET is more equipped for putting away settled information.
- ORC is more equipped for Predicate Pushdown.
- ORC backings ACID properties.
- ORC is more pressure proficient.
Examinations Between Different File Formats:-
AVRO versus PARQUET:
Writing tasks in AVRO are better compared to PARQUET.
ORC versus PARQUET-
- Elements of HDFS.
How quick would you be able to peruse each datum component in a record?
Key variables to consider while choosing the best record design:
Adaptation to internal failure:
Hadoop structure isolates information into blocks and makes different duplicates of squares on a few machines in the bunch. Thus, when any gadget in the bunch falls flat, customers can in any case get their information from the other machine containing the precise information blocks.
High Availability:
In the HDFS climate, the information is copied by producing a duplicate of the squares. Along these lines, at whatever point a client needs to get this information, or in the event of an appalling circumstance, clients can essentially get to their information from different hubs since copy pictures of squares are now present in different hubs of the HDFS group.
High Reliability:
HDFS divides the information into blocks, these squares are put away by the Hadoop structure on hubs existing in the group. It saves information by producing a copy of each square current in the group. Consequently presents an adaptation to the internal failure office. Naturally, it makes 3 copies of each square containing data present in the hubs. In this way, the information is immediately reachable to the clients. Henceforth the client doesn’t confront the trouble of information misfortune. In this way, HDFS is entirely dependable.
Replication:
Replication settles the issue of information misfortune in unfriendly conditions like gadget disappointment, crashing of hubs, and so on It deals with the course of replication at incessant time frames. Along these lines, there is a low likelihood of a deficiency of client information.
Versatility:
HDFS stocks the information on numerous hubs. Along these lines, in the event of an expansion popular, it can scale the group.
- A record design is only a method for characterizing how data is put away in the HDFS document framework. This is normally determined by the utilization case or the handling calculations for the explicit area, File arrangement ought to be clear cut and expressive.
- It ought to have the option to deal with an assortment of information structures explicitly structs, records, maps, clusters alongside strings, numbers and so on Document configuration ought to be basic, twofold, and compact.
- When managing Hadoop’s filesystem in addition to the fact that you have these customary stockpiling designs accessible to you (like you can store PNG and JPG pictures on HDFS assuming you like), however, you likewise have some Hadoop-centered record organizations to use for organized and unstructured information.
- A tremendous bottleneck for HDFS-empowered applications like MapReduce and Spark is the time it takes to observe important information in a specific area and the time it takes to compose the information back to another area. These issues are exacerbated with the challenges overseeing enormous datasets, for example, advancing constructions, or capacity requirements. The different Hadoop record designs have developed as a method for facilitating these issues across various use cases.
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
- At the point when the need to getting to a main a little subset of segments then, at that point, utilizing a columnar information design.
- At the point when important to acquiring numerous sections then, at that point, utilized a line situated data set rather than a columnar data set.
- If the pattern changes after some time, use Avro rather than ORC or Parquet.
- If needs to perform a question, use ORC or Parquet rather than Avro.
- On the off chance that need to perform segment add an activity, use Parquet rather than ORC.
Scopes of Hadoop:

Get JOB Oriented Hadoop Administration Training for Beginners By MNC Experts
Picking a proper document arrangement can have a few critical advantages:
1. Quicker read times
2. Quicker compose times
3. Splittable documents (so you don’t have to peruse the entire record, simply a piece of it)
4. Composition advancement support (permitting you to change the fields in a dataset)
5. Progressed pressure support (pack the columnar records with a pressure codec without forfeiting these elements) Some document designs are intended for general use (like MapReduce or Spark), others are intended for more explicit use cases (like fueling an information base), and some are planned in light of explicit information attributes. So there truly is a considerable amount of decision.
The conventional characterization of the attributes are Expressive, Simple, Binary, Compressed, Integrity to name not many. Normally text-based, sequential, and columnar sort.
Since Protocol cradles and frugality are serializable but not splittable they are not to a great extent well known on HDFS use cases and consequently, Avro turns into the best option.
Best acts of Hadoop File Storage:
- Uber
- The Bank of Scotland
- Netflix
- The National Security Agency (NSA) of the United States
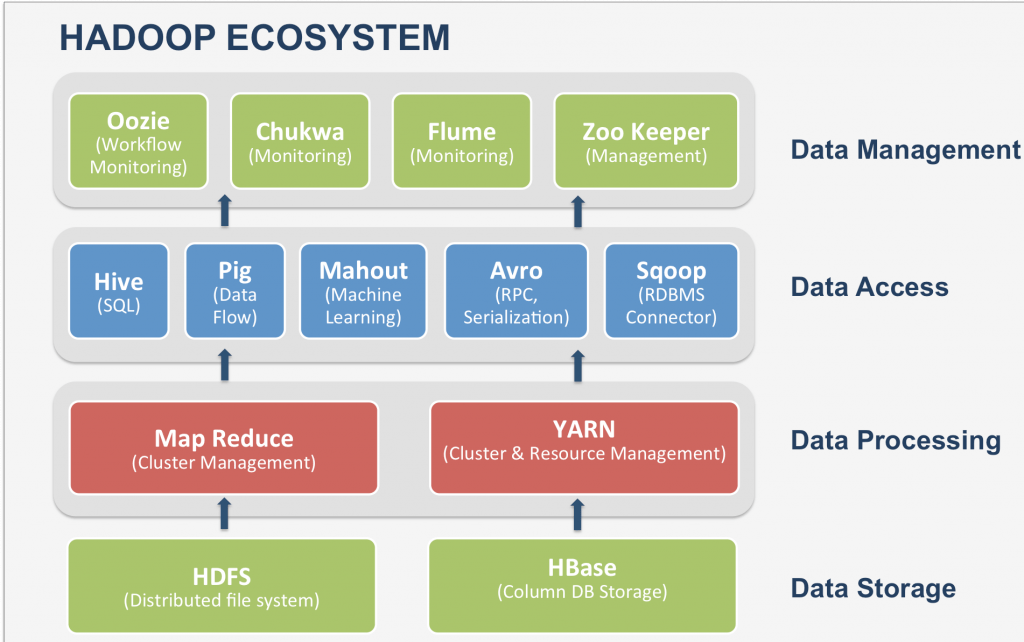
- Hadoop YARN – It is an asset to the board unit of Hadoop.
- Hadoop Distributed File System (HDFS) – It is the capacity unit of Hadoop.
- Hadoop MapReduce – It is the handling unit of Hadoop.
List the center parts of Hadoop:-
Hadoop is a well-known huge information apparatus used by many organizations worldwide. Few fruitful Hadoop clients:
There are three parts of Hadoop are:
Benefits of Hadoop:-
1. Versatile-
Hadoop is an exceptionally versatile capacity stage since it can store and appropriate extremely enormous informational collections across many economical servers that work in equal. In contrast to conventional social information base frameworks (RDBMS) that can’t scale to deal with a lot of information, Hadoop empowers organizations to run applications on a large number of hubs including a huge number of terabytes of information.
2. Practical-
Hadoop additionally offers a savvy stockpiling answer for organizations’ detonating informational indexes. The issue with conventional social information base administration frameworks is that it is amazingly cost restrictive to scale so much to handle such huge volumes of information. With an end goal to decrease costs, many organizations in the past would have needed to down-example information and order it given specific presumptions regarding which information was the most significant. The crude information would be erased, as it would be excessively cost-restrictive to keep. While this approach might have worked, for the time being, this implied that when business needs different, the total crude informational index was not accessible, as it was too costly to even consider putting away.
3. Adaptable-
Hadoop empowers organizations to effectively get to new information sources and tap into various kinds of information (both organized and unstructured) to create esteem from that information. This implies organizations can utilize Hadoop to get important business experiences from information sources like online media, email discussions. Hadoop can be utilized for a wide assortment of purposes, for example, log handling, suggestion frameworks, information warehousing, market crusade investigation, and misrepresentation recognition.
4. Quick-
Hadoop’s special stockpiling strategy depends on a conveyed record framework that fundamentally ‘maps’ information any place it is situated on a group. The apparatuses for information handling are frequently on similar servers where the information is found, bringing about a lot quicker information handling. Assuming that you’re managing enormous volumes of unstructured information, Hadoop can effectively deal with terabytes of information in only minutes, and petabytes in hours.
5. Tough to disappointment-
A critical benefit of utilizing Hadoop is its adaptation to internal failure. At the point when information is shipped off a singular hub, that information is likewise duplicated to different hubs in the group, and that intends that in case of disappointment, there is another duplicate accessible for use.
- Security Concerns
- Helpless By Nature
- Not Fit for Small Data
Drawbacks of Hadoop:-
As the foundation of such countless executions, Hadoop is nearly synonymous with enormous information.
1. Security Concerns
Simply dealing with complicated applications, for example, Hadoop can be tested. A straightforward model should be visible in the Hadoop security model, which is debilitated naturally because of sheer intricacy. If whoever dealing with the stage absences of ability to empower it, your information could be in colossal danger. Hadoop is additionally missing encryption at the capacity and organization levels, which is a significant selling point for government offices and others that like to stay quiet about their information.
2. Helpless By Nature
Talking about security, the actual cosmetics of Hadoop makes running it a dangerous recommendation. The system is composed essentially in Java, one of the most broadly utilized at this point disputable programming dialects in presence. Java has been intensely taken advantage of by cybercriminals and subsequently, involved in various security breaks.
3. Not Fit for Small Data
While huge information isn’t only made for huge organizations, not generally enormous information stages are appropriate for little information needs. Tragically, Hadoop turns out to be one of them. Because of its high limit plan, the Hadoop Distributed File System misses the mark on the capacity to productively uphold the irregular perusing of little documents. Therefore, it isn’t suggested for associations with little amounts of information.
4. Possible Stability Issues
Possible Stability Issues
Like all open-source programming, Hadoop has had its reasonable part of strength issues. To stay away from these issues, associations are unequivocally prescribed to ensure they are running the most recent stable form, or run it under an outsider seller prepared to deal with such issues.
5. General Limitations
The article presents Apache Flume, MillWheel, and Google’s own Cloud Dataflow as potential arrangements. What every one of these stages share practically speaking is the capacity to work on the productivity and dependability of information assortment, accumulation, and incorporation. The primary concern the article stresses is that organizations could be passing up large advantages by utilizing Hadoop alone.
Conclusion:-
The assessment of the well-known stockpiling procedures on the Hadoop biological system Apache Avro has shown to be a quick all-inclusive encoder for organized information.
Because of exceptionally proficient serialization and deserialization, this configuration ensures remarkable execution at whatever point admittance to every one of the traits of a record needed simultaneously – information transportation, arranging regions, and so forth Apache Parquet and Apache Kudu conveyed amazing adaptability between quick Data Ingestion, speedy irregular information query, and Scalable Data Analytics, guaranteeing simultaneously a framework effortlessness – just a single innovation for putting away the information. Kudu dominates quicker irregular query when Parquet dominates quicker information outputs and ingestion.




