
Last updated on 08th Jul 2020| 2566
Hadoop is an open-source software framework used for storing and processing Big Data in a distributed manner on large clusters of commodity hardware. … Hadoop was developed, based on the paper written by Google on the MapReduce system and it applies concepts of functional programming.
Hadoop is a framework that allows for the distributed processing of large datasets across clusters of computers using simple programming models. It is inspired by a technical document published by Google.
The word Hadoop does not have any meaning. Doug Cutting, who discovered Hadoop, named it after his son yellow-colored toy elephant.
Let us discuss how Hadoop resolves the three challenges of the distributed system, such as high chances of system failure, the limit on bandwidth, and programming complexity.
The four key characteristics of Hadoop are:
- Economical: Its systems are highly economical as ordinary computers can be used for data processing.
- Reliable: It is reliable as it stores copies of the data on different machines and is resistant to hardware failure.
- Scalable: It is easily scalable both, horizontally and vertically. A few extra nodes help in scaling up the framework.
- Flexible: It is flexible and you can store as much structured and unstructured data as you need to and decide to use them later.
Traditionally, data was stored in a central location, and it was sent to the processor at runtime. This method worked well for limited data.
However, modern systems receive terabytes of data per day, and it is difficult for the traditional computers or Relational Database Management System (RDBMS) to push high volumes of data to the processor.
Hadoop brought a radical approach. In Hadoop, the program goes to the data, not vice versa. It initially distributes the data to multiple systems and later runs the computation wherever the data is located.
Stages of Big Data processing
There are four stages of Big Data processing: Ingest, Processing, Analyze, Access. Let us look at them in detail.
- Ingest: The first stage of Big Data processing is Ingest. The data is ingested or transferred to Hadoop from various sources such as relational databases, systems, or local files. Sqoop transfers data from RDBMS to HDFS, whereas Flume transfers event data.
- Processing: The second stage is Processing. In this stage, the data is stored and processed. The data is stored in the distributed file system, HDFS, and the NoSQL distributed data, HBase. Spark and Map Reduce perform the data processing.
- Analyze: The third stage is Analyze. Here, the data is analyzed by processing frameworks such as Pig, Hive, and Impala.Pig converts the data using a map and reduce and then analyzes it. Hive is also based on the map and reduce programming and is most suitable for structured data.
- Access: The fourth stage is Access, which is performed by tools such as Hue and Cloudera Search. In this stage, the analyzed data can be accessed by users.Hue is the web interface, whereas Cloudera Search provides a text interface for exploring data.
Advantages
- Scalable: Hadoop is a highly scalable storage platform, because it can store and distribute very large data sets across hundreds of inexpensive servers that operate in parallel. Unlike traditional relational database systems (RDBMS) that can’t scale to process large amounts of data, Hadoop enables businesses to run applications on thousands of nodes involving thousands of terabytes of data.
- Cost effective: Hadoop also offers a cost effective storage solution for businesses’ exploding data sets. The problem with traditional relational database management systems is that it is extremely cost prohibitive to scale to such a degree in order to process such massive volumes of data. In an effort to reduce costs, many companies in the past would have had to down-sample data and classify it based on certain assumptions as to which data was the most valuable. The raw data would be deleted, as it would be too cost-prohibitive to keep. While this approach may have worked in the short term, this meant that when business priorities changed, the complete raw data set was not available, as it was too expensive to store. Hadoop, on the other hand, is designed as a scale-out architecture that can affordably store all of a company’s data for later use. The cost savings are staggering: instead of costing thousands to tens of thousands of pounds per terabyte, Hadoop offers computing and storage capabilities for hundreds of pounds per terabyte.
- Flexible: Hadoop enables businesses to easily access new data sources and tap into different types of data (both structured and unstructured) to generate value from that data. This means businesses can use Hadoop to derive valuable business insights from data sources such as social media, email conversations or click stream data. In addition, Hadoop can be used for a wide variety of purposes, such as log processing, recommendation systems, data warehousing, market campaign analysis and fraud detection.
- Fast: Hadoop’s unique storage method is based on a distributed file system that basically ‘maps’ data wherever it is located on a cluster. The tools for data processing are often on the same servers where the data is located, resulting in much faster data processing. If you’re dealing with large volumes of unstructured data, Hadoop is able to efficiently process terabytes of data in just minutes, and petabytes in hours.
- Resilient to failure: A key advantage of using Hadoop is its fault tolerance. When data is sent to an individual node, that data is also replicated to other nodes in the cluster, which means that in the event of failure, there is another copy available for use.
- The MapR distribution goes beyond that by eliminating the NameNode and replacing it with a distributed No NameNode architecture that provides true high availability. Our architecture provides protection from both single and multiple failures.When it comes to handling large data sets in a safe and cost-effective manner, Hadoop has the advantage over relational database management systems, and its value for any size business will continue to increase as unstructured data continues to grow.
DISADVANTAGE
- Issue With Small Files: Hadoop is suitable for a small number of large files but when it comes to the application which deals with a large number of small files, Hadoop fails here. A small file is nothing but a file which is significantly smaller than Hadoop’s block size which can be either 128MB or 256MB by default. These large number of small files overload the Namenode as it stores namespace for the system and makes it difficult for Hadoop to function.
- Vulnerable By Nature: Hadoop is written in Java which is a widely used programming language hence it is easily exploited by cyber criminals which makes Hadoop vulnerable to security breaches.
- Processing Overhead: In Hadoop, the data is read from the disk and written to the disk which makes read/write operations very expensive when we are dealing with tera and petabytes of data. Hadoop cannot do in-memory calculations hence it incurs processing overhead.
- Supports Only Batch Processing: At the core, Hadoop has a batch processing engine which is not efficient in stream processing. It cannot produce output in real-time with low latency. It only works on data which we collect and store in a file in advance before processing.
- Iterative Processing: Hadoop cannot do iterative processing by itself. Machine learning or iterative processing has a cyclic data flow whereas Hadoop has data flowing in a chain of stages where output on one stage becomes the input of another stage.
- Security: For security, Hadoop uses Kerberos authentication which is hard to manage. It is missing encryption at storage and network levels which are a major point of concern.So, this was all about Hadoop Pros and Cons. Hope you liked our explanation.
Prerequisites
- VirtualBox/VMWare/Cloudera: Any of these can be used for installing the operating system on.
- Operating System: You can install Hadoop on Linux-based operating systems. Ubuntu and CentOS are very commonly used among them. In this tutorial, we are using CentOS.
- Java: You need to install the Java 8 package on your system.
- Hadoop: You require the Hadoop 2.7.3 package.
Hadoop Installation on Windows
Note: If you are working on Linux, then skip to Step 9.
Step 1: Installing VMware Workstation
- Download VMware Workstation from this link
- Once downloaded, open the .exe file and set the location as required
- Follow the required steps of installation
Step 2: Installing CentOS
- nstall CentOS from this link
- Save the file in any desired location
Step 3: Setting up CentOS in VMware 12
When you open VMware, the following window pops up:
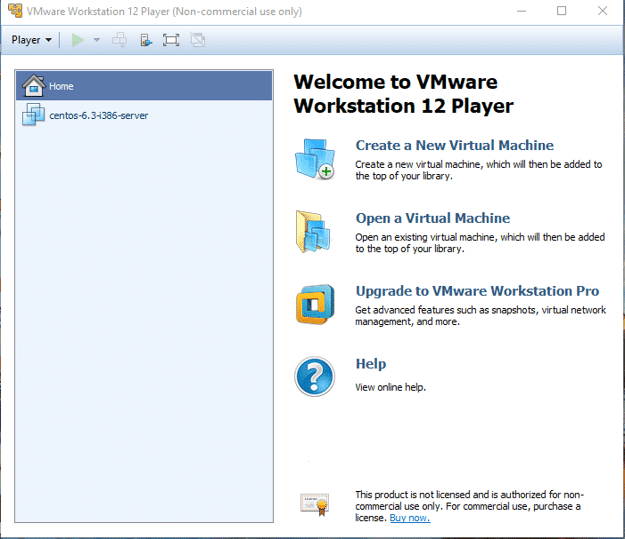
- Click on Create a New Virtual Machine
1. As seen in the screenshot above, browse the location of your CentOS file you downloaded. Note that it should be a disc image file
2. Click on Next
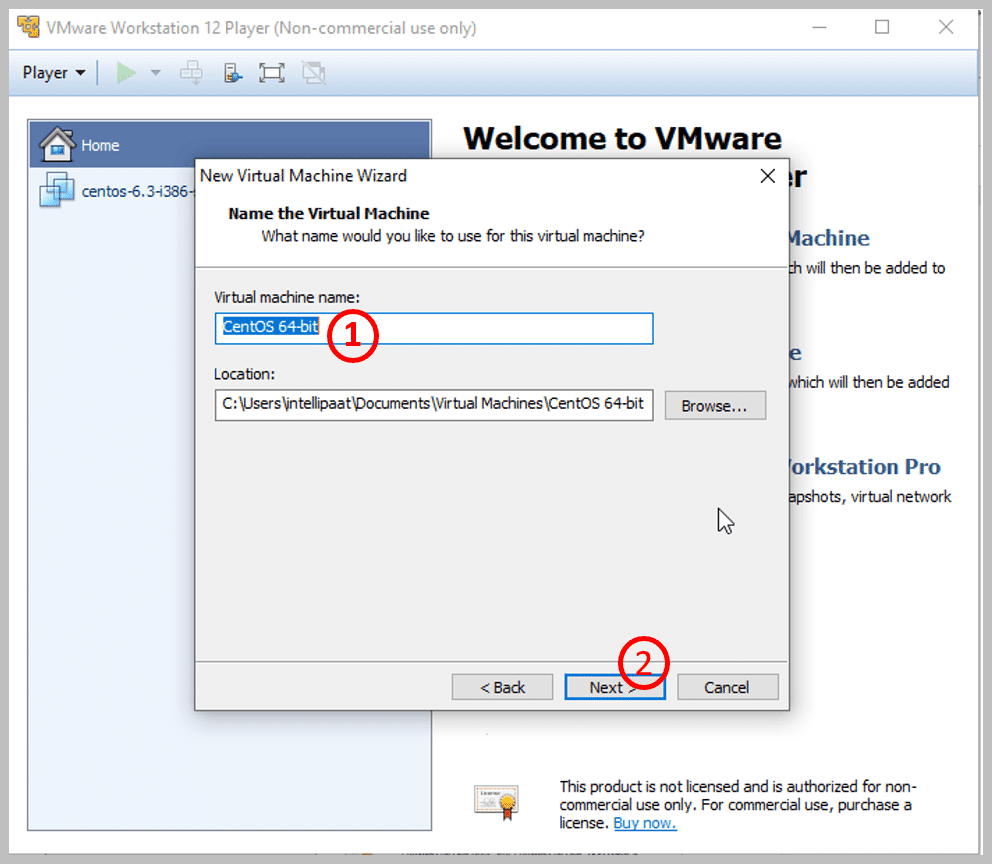
1. Choose the name of your machine. Here, I have given the name as CentOS 64-bit

Get Big Data Hadoop Certification Course By Experts Trainers
Weekday / Weekend BatchesSee Batch Details2. Then, click Next
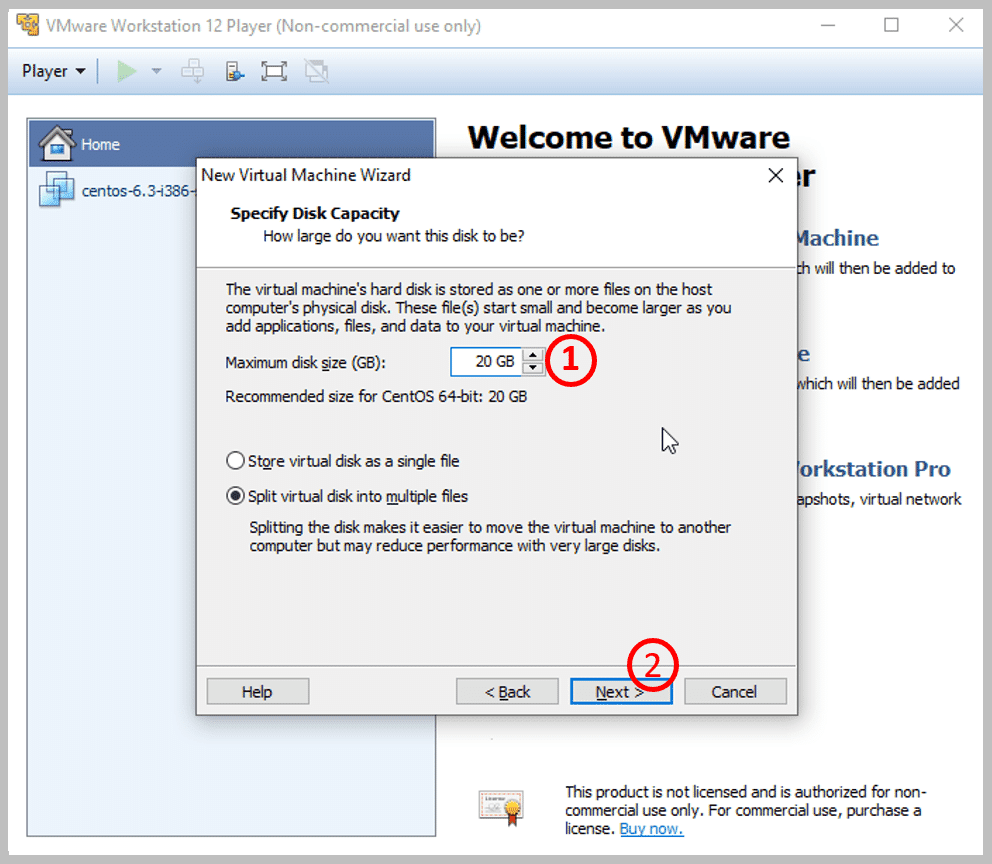
1. Specify the disk capacity. Here, I have specified it to be 20 GB
2. Click Next
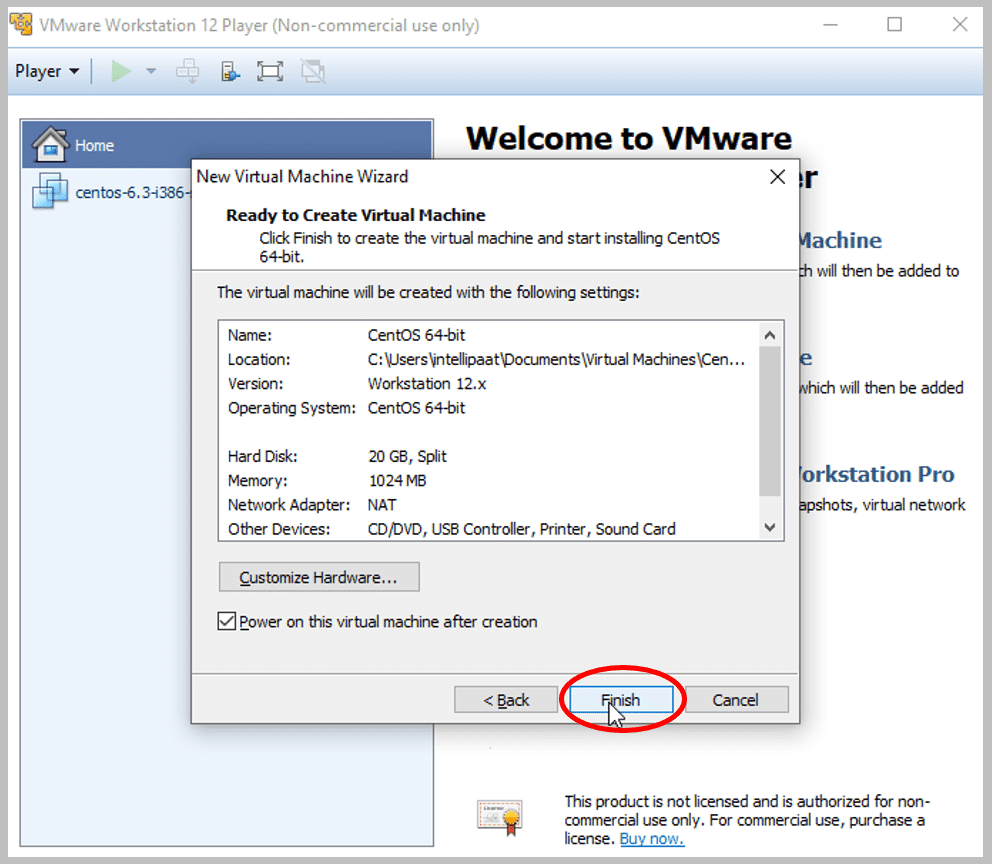
- Click on Finish
- After this, you should be able to see a window as shown below. This screen indicates that you are booting the system and getting it ready for installation. You will be given a time of 60 seconds to change the option from Install CentOS to others. You will need to wait for 60 seconds if you need the option selected to be Install CentOS
Note: In the image above, you can see three options, such as, I Finished Installing, Change Disc, and Help. You don’t need to touch any of these until your CentOS is successfully installed.
- Once the checking percentage reaches 100%, you will be taken to a screen as shown below:
Step 4: Here, you can choose your language. The default language is English, and that is what I have selected
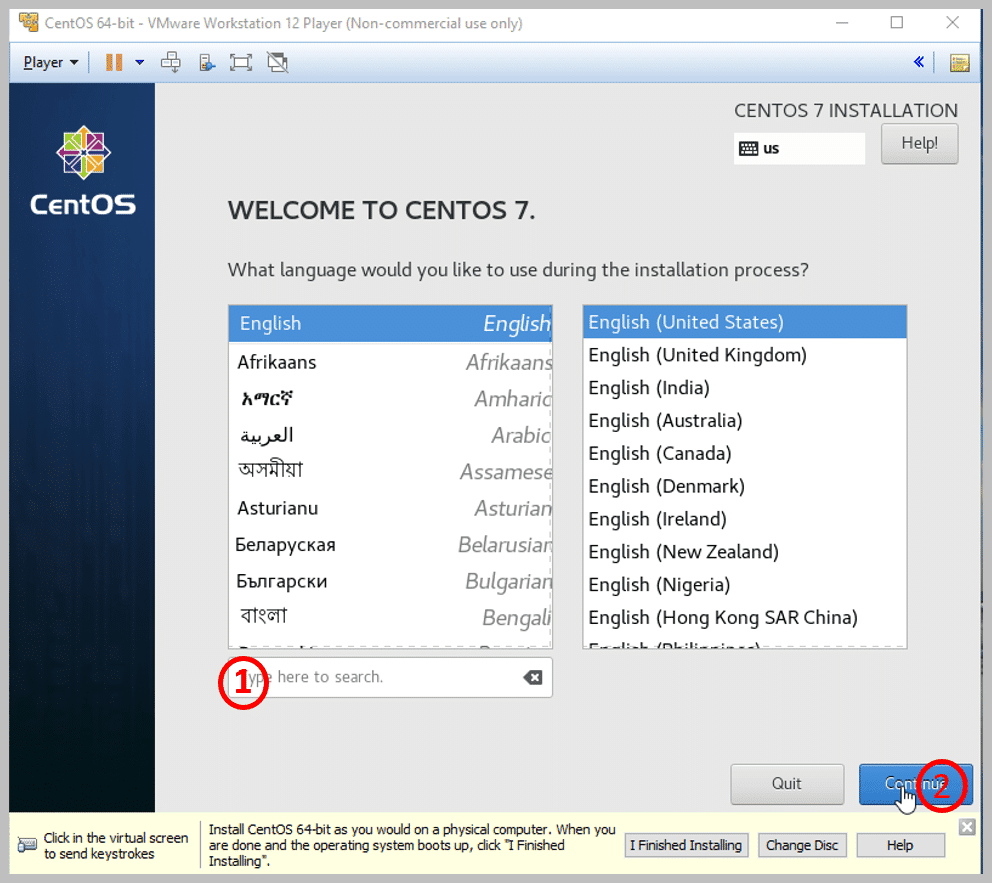
1. If you want any other language to be selected, specify it
2. Click on Continue
Step 5: Setting up the Installation Processes
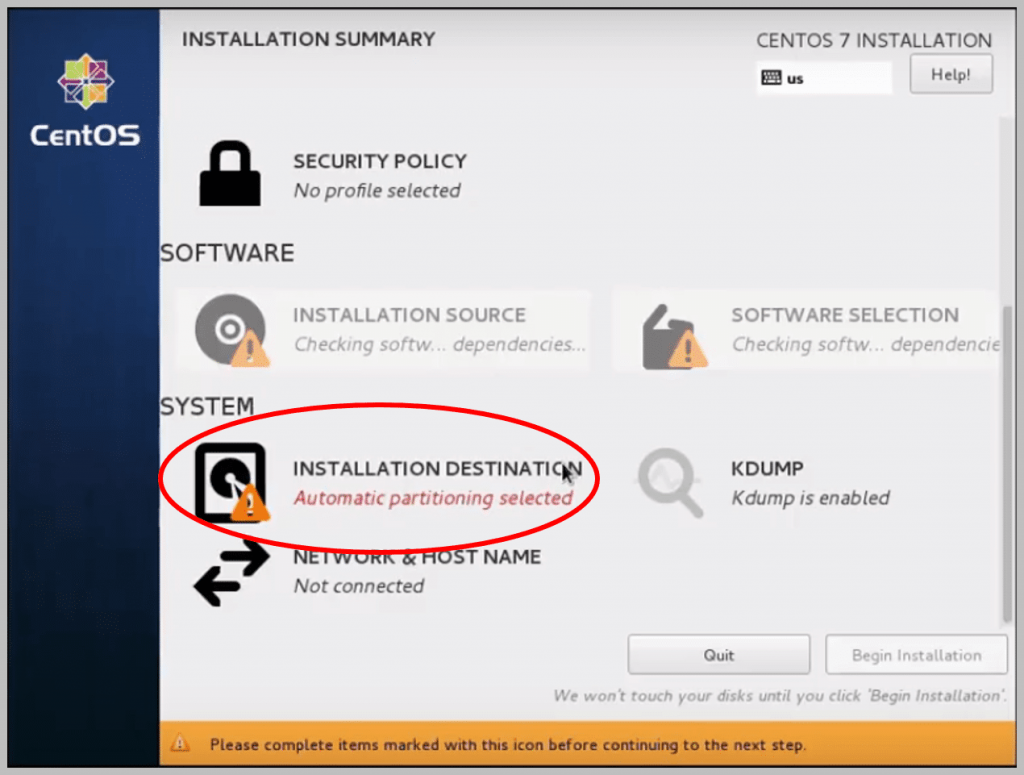
- On clicking this, you will see the following window:1. Under Other Storage Options, select I would like to make additional space available2. Then, select the radio button that says I will configure partitioning3. Then, click on Done
- Next, you’ll be taken to another window as shown below:1. Select the partition scheme here as Standard Partition2. Now, you need to add three mount points here. For doing that, click on ‘+’
a) Select the Mount Point /boot as shown above
b) Next, select the Desired Capacity as 500 MiB as shown below:
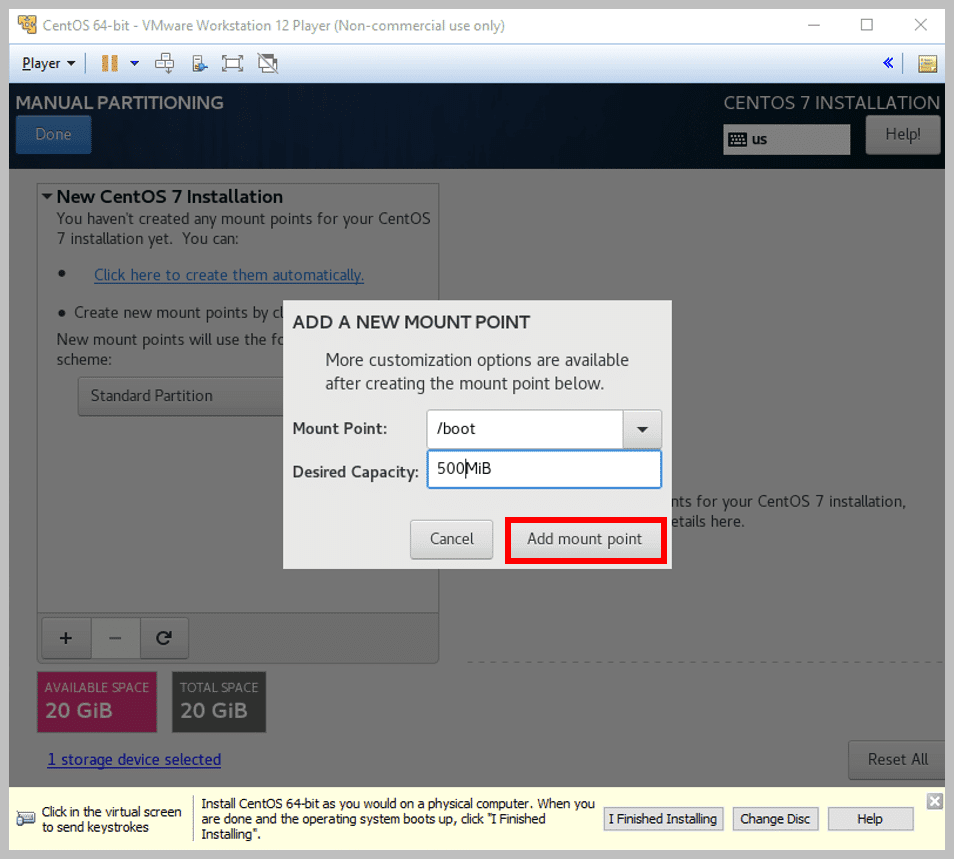
c) Click on Add mount point
d) Again, click on ‘+’ to add another Mount Point
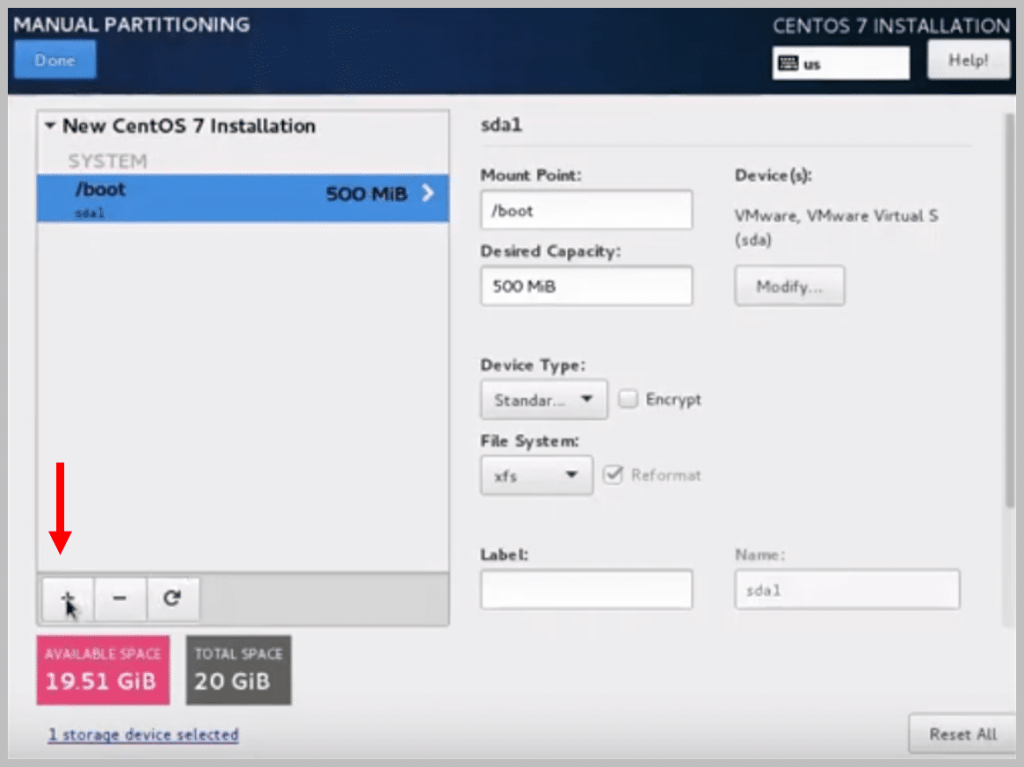
e) This time, select the Mount Point as swap and Desired Capacity as 2 GiB

Learn Experts Curated Big Data Hadoop Training to Build Your Skills & Ability
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
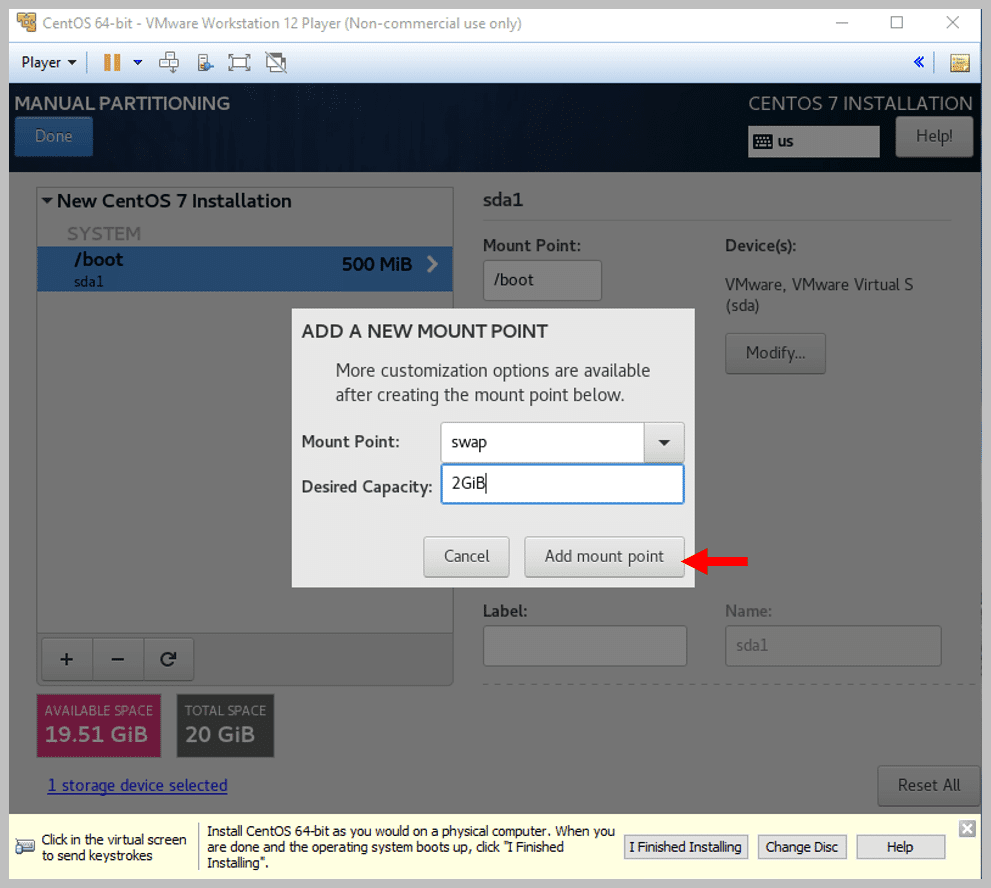
f) Click on Add Mount Point
g) Now, to add the last Mount Point, click on + again
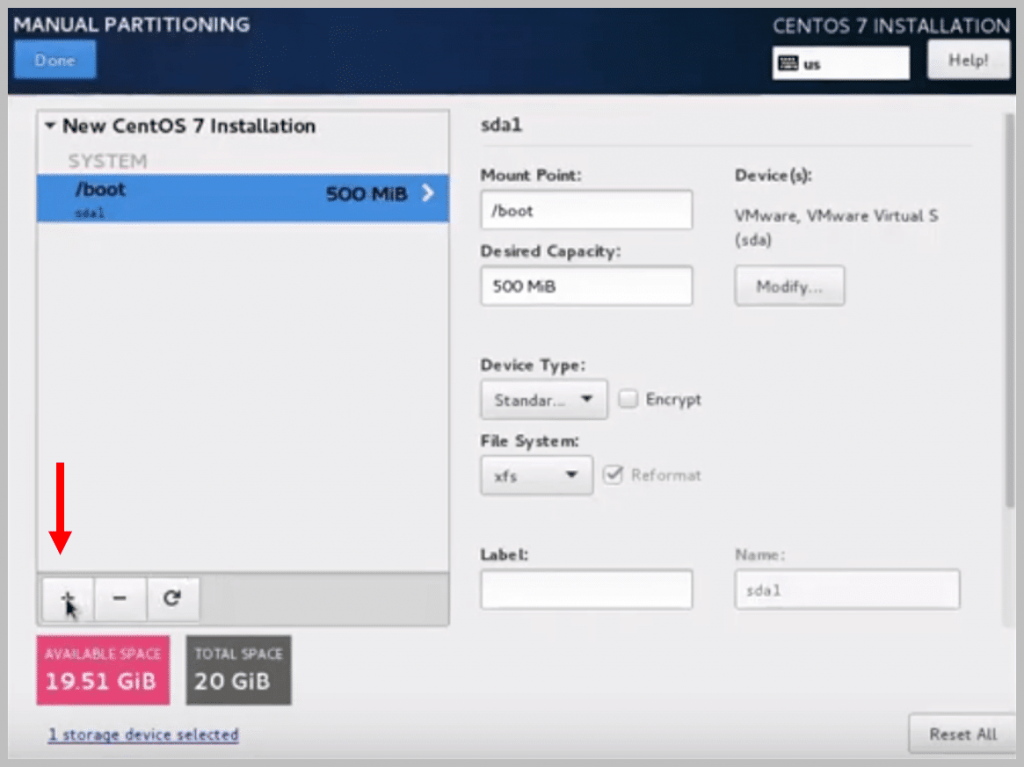
h) Add another Mount Point ‘/’ and click on Add Mount Point
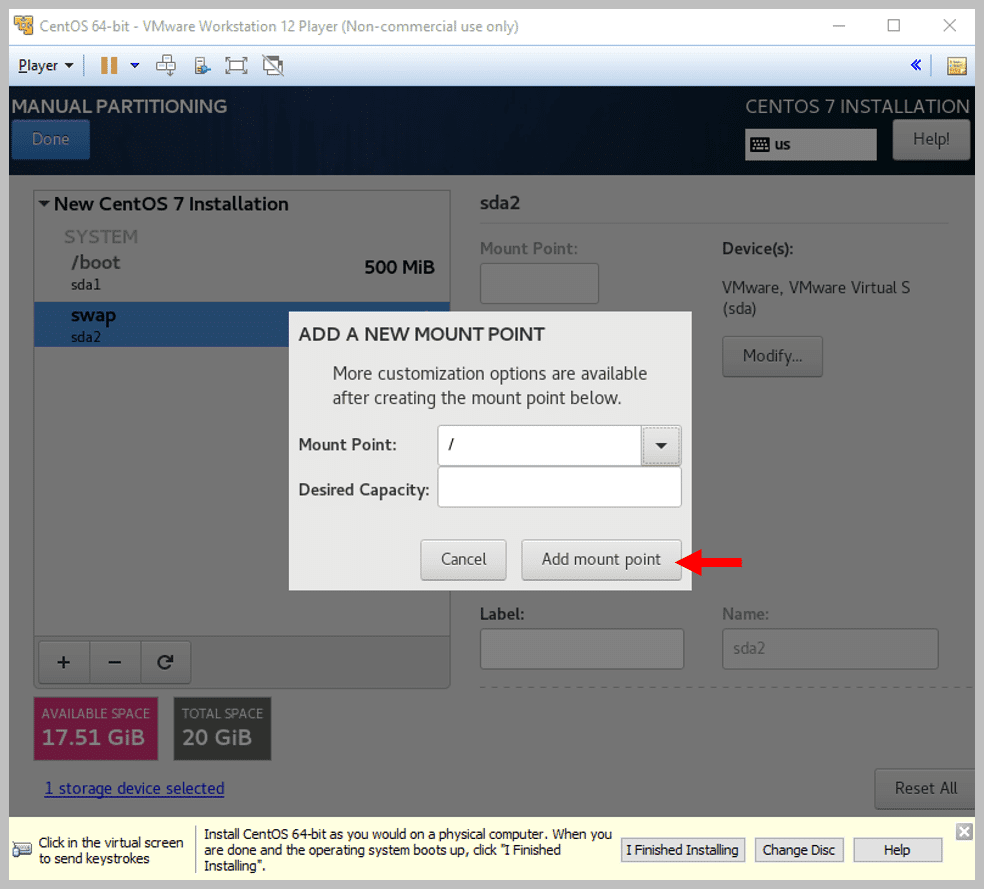
i) Click on Done, and you will see the following window:
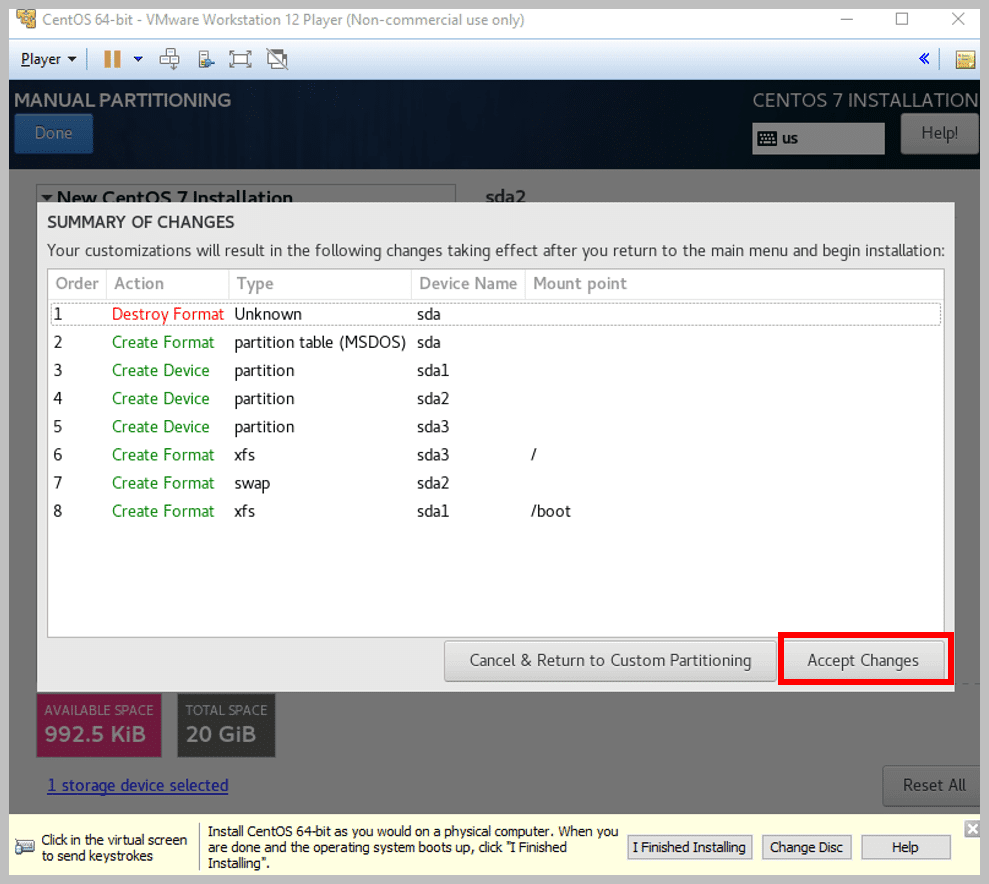
Note: This is just to make you aware of all the changes you had made in the partition of your drive
- Now, click on Accept Changes if you’re sure about the partitions you have made
- Next, select NETWORK & HOST NAME
You’ll be taken to a window as shown below:
1. Set the Ethernet settings as ON2. Change the HOST name if required3. Apply the settings4. Finally, click on Done
- Next, click on Begin Installation.




