Last updated on 07th Oct 2024| 4685
- Introduction to Apache Solr
- What is it?
- Types of Apache Solr
- Key Features of Apache Solr
- Setting Up Apache Solr
- Creating a New Core
- Process of Solr Apache
- Indexing Documents
- Searching Documents
- Managing Solr Search
- Conclusion
Introduction to Apache Solr
Apache Solr is an open-source search technology based on Apache Lucene that is known for powerful full-text search capabilities. Many choose it because it is scalable, great for faceted search, and supports real-time indexing. Many data types are also excellently supported by Solr search, and it easily interfaces with a high variety of applications and content management systems.
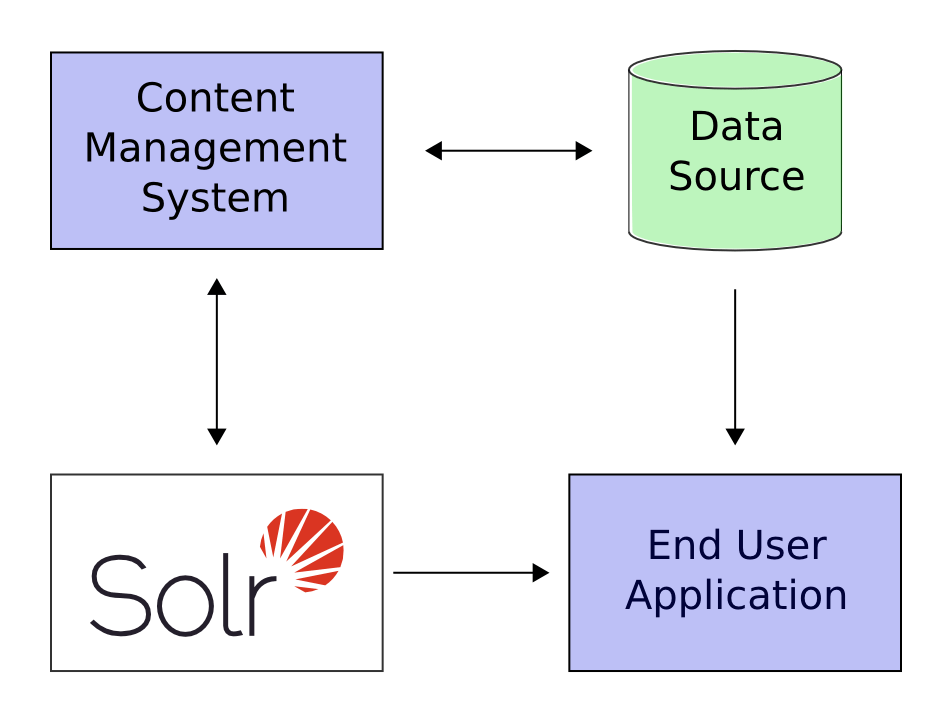
Because of the flexibility of its schema, users can define fields and types appropriate to their own needs for data, thus ensuring effective indexing and retrieval. Developers could also easily develop powerful search features without such heavy overhead because of the use of a RESTful API between the search platform and front-end applications with Solr. In this respect, Solr search is a strong search engine and a useful tool for developing complex data-driven applications because of its flexibility.
What is it?
Apache Solr is the power-packed, open-source search platform built upon the Apache Lucene base, specially designed to provide robust and scalable search capabilities applications that deal with large datasets. It enables organizations to conduct efficient full-text searches, allowing users to retrieve relevant information from vast datasets using a few keywords. Solr’s architecture supports distributed searching and indexing, essential for large-scale data environments. Similarly, Apache Camel aids in integrating various data sources and applications, simplifying data flows in complex systems. This goes hand in hand to mean that organizations can deploy Solr across multiple servers, thus ensuring high availability and fast performance. Another very interesting feature of Solr is its faceted search capability. Therefore, it lets users refine their search results based on various attributes or categories, making it easy to refine further and enhance the user experience. Solr also offers advanced features like relevance ranking, autocomplete, spell-checking, and geospatial search. It indeed comes with a flexible RESTful API, making easy integration into different web-based or mobile applications.
Ready to earn your Apache Solr Professional Certification? Discover the Apache Solr Certification Course now available at ACTE!
Types of Apache Solr
Field Types: You can declare many different types of fields in your schema in Solr. It governs how data is stored and indexed. Some typical field types are listed below:
- String: This applies to any text but does not support full-text searching. It is case-sensitive and relies on an exact match. Supports full-text search with tokenization, stemming, and relevance ranking. Often used for searchable text fields.
- Int/Long: Integer is used to store integer values. It is often used when the data is numeric, like IDs or counts.
- Float/Double: Float and double are used for floating-point numbers in the case of data involved in calculations or within ranges.
- Date: Stores date and time; it performs range queries for specific dates. Boolean: Used to store a true or false value.
Document Types: Data in Solr is stored as documents, which are groups of fields. Each document will represent one entry in the index, such as a blog post, product, or user profile.
Query Types:Supporting types of query that the Solr data retrieval supports include:
- Standard Query:This is the normal keyword search.
- Faceted Query:A faceted query returns counts for specified fields to help generate facets for filtering.
- DisMax Query:This simpler query parser makes it easier to search across multiple fields with good relevancy.
Request Handlers:Solr implements request processing through request handlers, which streamline various search and indexing tasks. This is similar to how Apache NetBeans offers tools for efficiently developing and managing Java applications.
- searchable:The top-level handler for searching documents
- Update:It adds, updates, or deletes the documents
- admin:It manages the Solr cores and configurations
Response Types:Solr responds in several different formats. These are:
- XML:This is the standard format for structured data.
- JSON:Lightweight format typically used in API interactions.
- CSV:Handy for exporting search results to spreadsheet programs.
Faceting Types:There are three types of faceting in Solr:
- Field Faceting:Count occurrences of field values, for example, categories.
- Range Faceting:Count occurrences across specific ranges, for instance, price ranges.
- Query Faceting:Counts based on custom queries.
Analysis Types:Solr comes with the most beautiful set of analysis features for processing text data that includes
- Tokenizers:Breaking text into individual terms (e.g., using a whitespace tokenizer).
- Filter: Transform tokens, for instance, stemming, lowercasing).
- CharFilter: Treat the characters passed to the tokenizer; for instance HTML stripping.
Get Your Apache Solr Certification by Learning from Industry-Leading Experts and Advancing Your Career with ACTE’s Apache Solr Certification Course.
Key Features of Apache Solr
- Full-Text Search: Offers advanced text analysis, such as relevance ranking, for very broad search capabilities.
- Faceted Search: Offers dynamic filtering of results, which makes it easier to navigate.
- Real-Time Indexing: Guarantees that the data is available for search immediately if the index is successful.
- Distributed Search: It provides scaling with the help of sharding and replication.
- REST-like API: Provides an easy HTTP interface for integration with other applications.
Configuring Apache Solr
Step 1: System Requirements
- Java Development Kit (JDK) 8 or above.
- A machine with RAM of 4GB and above.
- At least free disk space of about 1GB. Step 2: Downloading Solr
- solrconfig.xml: This includes configuration for caching, indexing, and request handling.
- schema.xml: This depicts what structure the documents to be indexed will take, including the fields and types. Fields like id, title, and content are a few simple schema examples, taking id as an unique key. Step 3: Reload the Core
- bin/solr reload -c more
- Installation:Download and Install the latest version of Solr from the Apache website and follow the installation process. Solr can run as a stand-alone server or be integrated into existing applications. Configure the Solr configuration files, such as solrconfig.xml and schema. XML defines the behaviour of indexing and searching.
- Data Indexing: Data Preparation Data can be prepared for indexing. Sometimes, it might require transformation into compatible file formats, such as XML, JSON, or CSV. Define the schema that explains which fields are contained, their type, and how they are indexed. This is essential for how data is stored and retrieved. You can index data using Solr’s API or command-line tools, relying on requests to Solr and adding documents for fast retrieval. This approach parallels Data File Partitioning and Hive, which optimize storage and access in large-scale environments.
- Searching: Utilize Solr’s query capabilities using its RESTful API. Complex searches, filters, and faceting can also limit the results. Relevancy Tuning: Adjust the scores and Relevance settings to ensure that the most relevant results are returned to users for their queries.
- Monitoring and Maintenance:Admin Interface Take full advantage of the built-in Solr Admin Dashboard to monitor your index’s performance, check logs, and manage it. Updates and Backups: Always update your index with fresh data and maintain backups against loss.
- Scalability:Sharding and replication For large-sized datasets, one can enable sharding, which splits the index across multiple nodes, and replication, or the process of making copies of data, to make it faster and more reliable. With the above, you can easily and successfully integrate Apache Solr for powerful application search capabilities.
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
- curl ‘http://localhost:8983/solr/mycore/select?q=Solr&sort=title asc’
- curl ‘http://localhost:8983/solr/mycore/select?q=*:*&facet=true&facet.field=title’
- Apache Solr Official Documentation
- Solr Reference Guide
- Community and Support Adding virtually impressive improvements to your search functionality within your application thus enables users directly, and as promptly as possible, to retrieve results – Happy Search!
You log in to get the latest version of the Apache Solr download page.
Step 3: Installing SolrExtract the archive, move into the Solr search directory.
Step 4: Starting SolrNext, to begin the Solr, you run the appropriate command in your terminal. It creates a default core for you also.
Step 5: Accessing the Solr Admin UIOnce the Solr runs, open your web browser and navigate to the Solr Admin UI at http://localhost:8983/solr. From here, you can manage your Solr search instance, create new cores, and monitor performance.

Creating a New Core
Step 1: Create a CoreIn the Apache Solr Admin UI, Click on “Core Admin,” where you will add a new core that will ask for a name and a directory for storing core data.
Step 2: Configuring the CoreThe Core settings in Solr search are implemented using XML configuration files. The ones present here are two:
You would have to reload the core from the Admin UI after modifying the core configuration.
Want to Master Data Science? Explore the Data Science Master Program Offered at ACTE Today!
Process of Solr Apache:

Get JOB Oriented MapReduce Training for Beginners By MNC Experts
Indexing Documents
Step 1: Prepare Your DataYou can index data in multiple formats. The data formats that are available include XML, JSON, and CSV. Here’s a simple document example with fields such as id, title, and content.
Step 2: Index the DocumentTo index a document, use curl to call Solr, ensuring you address the correct core and use the proper document format. This is akin to how Apache HBase manages data storage and retrieval in a distributed environment, highlighting the importance of specifying parameters for efficiency.
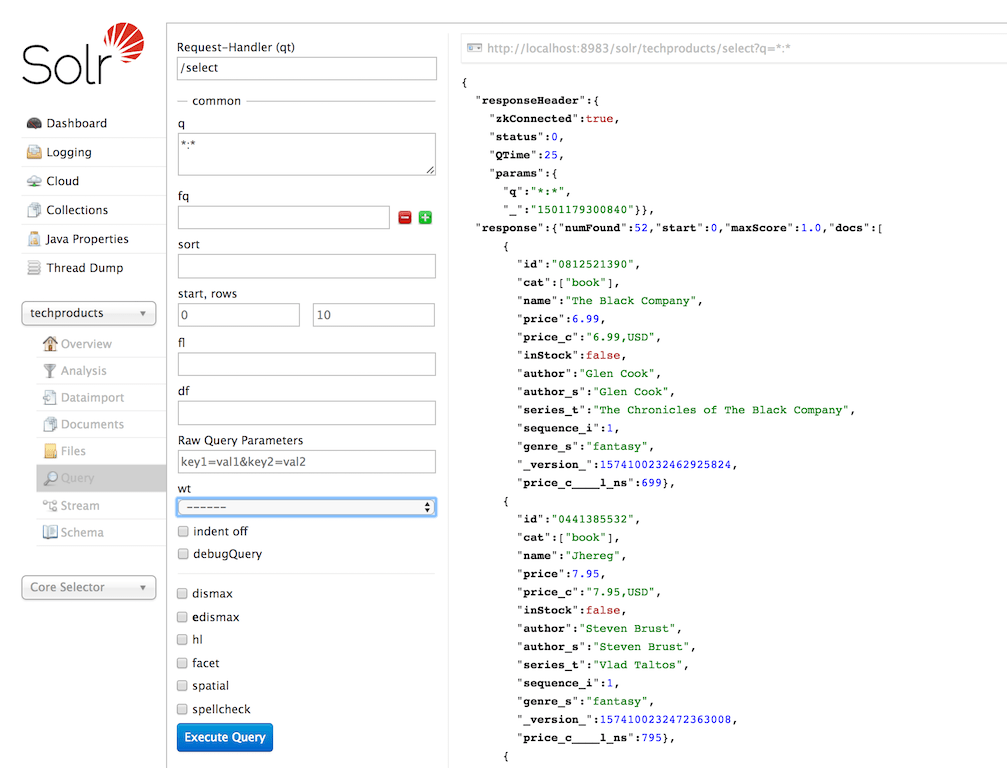
Step 3: Validate IndexingValidate that the document has indeed been indexed by querying the core for all documents. You can make these search queries even richer with additional parameters like sorting and filtering to make the retrieved results even more refined.
A faceted search is mainly helpful in finding counts of specific fields in your returned search result to make it easier to locate or navigate.
All Set for an Apache Solr Job Interview? Take a Look at Our Thorough Collection of Apache Solr Interview Questions to Help You Prepare!
Managing Solr Search
Step 1: MonitoringThe Solr Admin UI presents various metrics by which you can monitor the health and performance of your Solr search instance, such as query performance and cache hit rates.
Step 2: Backup and RecoveryUsing Solr, you may backup your core to ensure safety of your data and restore it when in need.
Step 3: Configuration of ReplicationFor high availability, you can configure master instances and agents for replication in your core settings. This approach is similar to how Amazon Kinesis provides real-time data streaming and processing, ensuring reliability and scalability in handling large data flows.
Conclusion
Apache Solr is a powerful search platform that enhances the ability of your application to search. This tutorial sets up a conceptual base on how to set up, index and search for documents with Solr. Further ahead you might feel the need to dive into some advanced topics like query optimization and integration with web applications. More Information:




