
Last updated on 09th Jul 2020| 3879
Apache Spark is a world-famous open-source cluster computing framework that is used for processing huge data sets in companies. Processing these huge data sets and distributing these among multiple systems is easy with Apache Spark. It offers simple APIs that make the lives of programmers and developers easy. Spark provides native bindings for programming languages, such as Python, R, Scala, and Java. It supports machine learning, graph processing, and SQL databases. Due to these amazing benefits, Spark is used in banks, tech firms, financial organizations, telecommunication departments, and government agencies.
Architecture of Apache Spark
The run-time architecture of Apache Spark consists of the following components:
Spark driver or master process : This converts programs into tasks and then schedules them for executors (slave processes). The task scheduler distributes these tasks to executors.
Cluster manager : The Spark cluster manager is responsible for launching executors and drivers. It schedules and allocates resources across several host machines for a cluster.
Executors : Executors, also called slave processes, are entities where tasks of a job are executed. After they are launched, they run until the lifecycle of the Spark application ends. The execution of a Spark job does not stop if an executor fails.
Resilient Distributed Datasets (RDD) : This is a collection of datasets that are immutable and are distributed over the nodes of a Spark cluster. Notably, a cluster is a collection of distributed systems where Spark can be installed. RDDs are divided into multiple partitions. And, they are called resilient as they can fix the data issues in case of data failure.
The types of RDDs supported by Spark are:
- Hadoop datasets built from files on Hadoop Distributed File System
- Parallelized collections, which can be based on Scala collections
DAG (Directed Acyclic Graph)
- Spark creates a graph as soon as a code is entered into the Spark console. If some action (an instruction for executing an operation) is triggered, this graph is submitted to the DAGScheduler.
- This graph can be considered as a sequence of data actions. DAG consists of vertices and edges. Vertices represent an RDD and edges represent computations to be performed on that specific RDD. It is called a directed graph as there are no loops or cycles within the graph.
Apache Spark RDD
- RDD stands for “Resilient Distributed Dataset”. It is the fundamental data structure of Apache Spark. RDD in Apache Spark is an immutable collection of objects which computes on the different node of the cluster.
- Decomposing the name RDD:
- Resilient, i.e. fault-tolerant with the help of RDD lineage graph(DAG) and so able to recompute missing or damaged partitions due to node failures.
- Distributed, since Data resides on multiple nodes.
- Dataset represents records of the data you work with. The user can load the data set externally which can be either JSON file, CSV file, text file or database via JDBC with no specific data structure.
Concept of RDD
- Iterative algorithms.
- Interactive data mining tools.
- DSM (Distributed Shared Memory) is a very general abstraction, but this generality makes it harder to implement in an efficient and fault tolerant manner on commodity clusters. Here the need of RDD comes into the picture.
- In distributed computing system data is stored in intermediate stable distributed store such as HDFS or Amazon S3. This makes the computation of job slower since it involves many IO operations, replications, and serializations in the process.
Features of Spark RDD
Several features of Apache Spark RDD are:
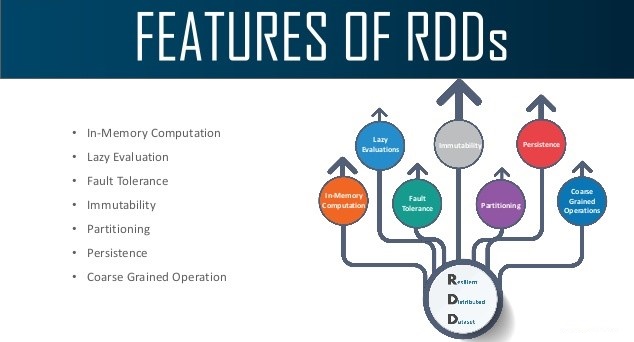
In-memory Computation : Spark RDDs have a provision of in-memory computation. It stores intermediate results in distributed memory(RAM) instead of stable storage(disk).
Lazy Evaluations : All transformations in Apache Spark are lazy, in that they do not compute their results right away. Instead, they just remember the transformations applied to some base data set. Spark computes transformations when an action requires a result for the driver program. Follow this guide for the deep study of Spark Lazy Evaluation.
Fault Tolerance : Spark RDDs are fault tolerant as they track data lineage information to rebuild lost data automatically on failure. They rebuild lost data on failure using lineage, each RDD remembers how it was created from other datasets (by transformations like a map, join or groupBy) to recreate itself. Follow this guide for the deep study of RDD Fault Tolerance.
Immutability : Data is safe to share across processes. It can also be created or retrieved anytime which makes caching, sharing & replication easy. Thus, it is a way to reach consistency in computations.
Partitioning : Partitioning is the fundamental unit of parallelism in Spark RDD. Each partition is one logical division of data which is mutable. One can create a partition through some transformations on existing partitions.
Persistence : Users can state which RDDs they will reuse and choose a storage strategy for them (e.g., in-memory storage or on Disk).
Coarse-grained Operations : It applies to all elements in datasets through maps or filter or group by operation.
Location-Stickiness : RDDs are capable of defining placement preference to compute partitions. Placement preference refers to information about the location of RDD. The DAGScheduler places the partitions in such a way that task is close to data as much as possible.
Create RDDs in Apache Spark : Three ways to create an RDD in Apache Spark
Parallelizing collection (Parallelized) : We take an already existing collection in the program and pass it onto the Spark Context’s parallelized() method. This is an original method which creates RDDs quickly in Spark-shell and also performs operations on them. It is very rarely used, as this requires the entire Data set on one machine.
Referencing External Dataset : In Spark, the RDDs can be formed from any data source supported by the Hadoop, including local file systems, HDFS, Hbase, Cassandra, etc. Here, data is loaded from an external data set. We can use Spark Context’s text File method to create text file RDD. It would URL of the file and read it as a collection of line. URL can be a local path on the machine itself.
Creating RDD from existing RDD : Transformation mutates one RDD into another, and change is the way to create an RDD from an existing RDD. This creates a difference between Apache Spark and Hadoop Map Reduce. Conversion works like one that intakes an RDD and produces one. The input RDD does not change, and as RDDs are immutable, it generates varying RDD by applying operations.
Operation on RDD : There are Two operations of Apache Spark RDDs Transformations and Actions. A Transformation is a function that produces a new RDD from the existing RDDs.
It takes an RDD as input and generates one or more RDD as output. Every time it creates new RDD when we apply any transformation. Thus, all the input RDDs, cannot be changed since RDD are immutable. Some points are :
- No Change to the cluster.
- Produces a DAG which keeps track of which RDD was made when in the Life cycle.
- Example : map(func), filter(func), Reduce(func), intersection(dataset), distinct(), groupByKey(), union(dataset), mapPartitions(fun), flatMap().
Spark RDD Operations :
RDD in Apache Spark supports two types of operations:
- Transformation
- Actions
Transformations :
- Spark RDD Transformations are functions that take an RDD as the input and produce one or many RDDs as the output. They do not change the input RDD (since RDDs are immutable and hence one cannot change it), but always produce one or more new RDDs by applying the computations they represent e.g. Map(), filter(), reduceByKey() etc.
- Transformations are lazy operations on an RDD in Apache Spark. It creates one or many new RDDs, which executes when an Action occurs. Hence, Transformation creates a new dataset from an existing one.
- Certain transformations can be pipelined which is an optimization method, that Spark uses to improve the performance of computations. There are two kinds of transformations: narrow transformation, wide transformation.

Advance Your Skills with Microsoft Business Intelligence Certification Course
Weekday / Weekend BatchesSee Batch Detailsa. Narrow Transformations
It is the result of map, filter and such that the data is from a single partition only, i.e. it is self-sufficient. An output RDD has partitions with records that originate from a single partition in the parent RDD. Only a limited subset of partitions used to calculate the result. Spark groups narrow transformations as a stage known as pipelining.
b. Wide Transformations
It is the result of groupByKey() and reduceByKey() like functions. The data required to compute the records in a single partition may live in many partitions of the parent RDD. Wide transformations are also known as shuffle transformations because they may or may not depend on a shuffle.
ii. Actions
- An Action in Spark returns final result of RDD computations. It triggers execution using lineage graph to load the data into original RDD, carry out all intermediate transformations and return final results to Driver program or write it out to file system. Lineage graph is dependency graph of all parallel RDDs of RDD.
- Actions are RDD operations that produce non-RDD values. They materialize a value in a Spark program. An Action is one of the ways to send result from executors to the driver. First(), take(), reduce(), collect(), the count() is some of the Actions in spark.
- Using transformations, one can create RDD from the existing one. But when we want to work with the actual dataset, at that point we use Action. When the Action occurs it does not create the new RDD, unlike transformation. Thus, actions are RDD operations that give no RDD values. Action stores its value either to drivers or to the external storage system. It brings laziness of RDD into motion.
Spark Optimization Techniques
Spark optimization techniques are used to modify the settings and properties of Spark to ensure that the resources are utilized properly and the jobs are executed quickly. All this ultimately helps in processing data efficiently.
The most popular Spark optimization techniques are listed below:
1. Data Serialization
Here, an in-memory object is converted into another format that can be stored in a file or sent over a network. This improves the performance of distributed applications. The two ways to serialize data are:
- Java serialization – The ObjectOutputStream framework is used for serializing objects. The java.io.Externalizable can be used to control the performance of the serialization. This process offers lightweight persistence.
- Kyro serialization – Spark uses the Kryo Serialization library (v4) for serializing objects that are faster than Java serialization and is a more compact process. To improve the performance, the classes have to be registered using the registerKryoClasses method.
2. Caching
- This is an efficient technique that is used when the data is required more often. Cache() and persist() are the methods used in this technique. These methods are used for storing the computations of an RDD, DataSet, and DataFrame. But, cache() stores it in the memory, and persist() stores it in the user-defined storage level.
- These methods can help in reducing costs and saving time as repeated computations are used.
3. Data Structure Tuning
We can reduce the memory consumption while using Spark, by tweaking certain Java features that might add overhead. This is possible in the following ways:
- Use enumerated objects or numeric IDs in place of strings for keys.
- Avoid using a lot of objects and complicated nested structures.
- Set the JVM flag to xx:+UseCompressedOops if the memory size is less than 32 GB.
4. Garbage collection optimization
- For optimizing garbage collectors, G1 and GC must be used for running Spark applications. The G1 collector manages growing heaps. GC tuning is essential according to the generated logs, to control the unexpected behavior of applications. But before this, you need to modify and optimize the program’s logic and code.
- G1GC helps to decrease the execution time of the jobs by optimizing the pause times between the processes.
5. Memory Management
- The memory used for storing computations, such as joins, shuffles, sorting, and aggregations, is called execution memory. The storage memory is used for caching and handling data stored in clusters. Both memories use a unified region M.
- When the execution memory is not in use, the storage memory can use the space. Similarly, when storage memory is idle, execution memory can utilize the space. This is one of the most efficient Spark optimization techniques.
RDD Operations
- RDD transformations – Transformations are lazy operations, instead of updating an RDD, these operations return another RDD.
- RDD actions – operations that trigger computation and return RDD values.
RDD Transformations with example
- Transformations on Spark RDD returns another RDD and transformations are lazy meaning they don’t execute until you call an action on RDD. Some transformations on RDD’s are flatMap, map, reduceByKey, filter, sortByKey and return new RDD instead of updating the current.
- In this Spark RDD Transformation tutorial, I will explain transformations using the word count example. The below image demonstrates different RDD transformations we going to use.
Word count spark RDD transformations :
First, create an RDD by reading a text file. The text file used here is available at the GitHub project. And, the scala example I am using in this tutorial is available at GitHub project
- val rdd:RDD[String] = spark.sparkContext.textFile(“src/main/scala/test.txt”)
flatMap – flatMap() transformation flattens the RDD after applying the function and returns a new RDD. On the below example, first, it splits each record by space in an RDD and finally flattens it. Resulting RDD consists of a single word on each record.
- val rdd2 = rdd.flatMap(f=>f.split(” “))
map : map() transformation is used the apply any complex operations like adding a column, updating a column e.t.c, the output of map transformations would always have the same number of records as input.
In our word count example, we are adding a new column with value 1 for each word, the result of the RDD is Pair RDD Functions which contains key-value pairs, word of type String as Key and 1 of type Int as value. For your understanding, I’ve defined rdd3 variable with type.
- val rdd3:RDD[(String,Int)]= rdd2.map(m=>(m,1))
filter – filter() transformation is used to filter the records in an RDD. In our example we are filtering all words starts with “a”.
- val rdd4 = rdd3.filter(a=> a._1.startsWith(“a”))
reduceByKey – reduceByKey() merges the values for each key with the function specified. In our example, it reduces the word string by applying the sum function on value. The result of our RDD contains unique words and their count.
- val rdd5 = rdd4.reduceByKey(_ + _)
sortByKey – sortByKey() transformation is used to sort RDD elements on key. In our example, first, we convert RDD[(String,Int]) to RDD[(Int, String]) using map transformation and apply sortByKey which ideally does sort on an integer value. And finally, foreach with println statements returns all words in RDD and their count as key-value pair
- val rdd6 = rdd5.map(a=>(a._2,a._1)).sortByKey()
- //Print rdd6 result to console
- rdd6.foreach(println)
Last statement foreach on rdd print the count of each word. Please refer to this page for the full list of RDD transformations.
RDD Actions with example :
- RDD Action operation returns the raw values from an RDD. In other words, any RDD function that returns non RDD[T] is considered as an action.
- In this Spark RDD Action tutorial, we will continue to use our word count example, the last statement foreach() is an action that returns all data from an RDD and prints on a console. let’s see some more action operations on our word count example.
count – Returns the number of records in an RDD
- //Action – count
- println(“Count : “+rdd6.count())
first – Returns the first record.
- //Action – first
- val firstRec = rdd6.first()
- println(“First Record : “+firstRec._1 + “,”+ firstRec._2)
max – Returns max record.
- //Action – max




