
Last updated on 10th Jul 2020| 3398
HBase is an open-source, column-oriented distributed database system in a Hadoop environment. Initially, it was Google Big Table, afterward, it was re-named as HBase and is primarily written in Java. Apache HBase is needed for real-time Big Data applications. Hbase is an open source framework provided by Apache. It is a sorted map data built on Hadoop. It is column oriented and horizontally salable.
Our HBase tutorial includes all topics of Apache HBase with HBase Data model, HBase Read, HBase Write, HBase MemStore, HBase Installation, RDBMS vs HBase, HBase Commands, HBase Example etc.
HBase can store massive amounts of data from terabytes to petabytes. The tables present in HBase consists of billions of rows having millions of columns. HBase is built for low latency operations, which is having some specific features compared to traditional relational models.
HBase Unique Features:
- HBase is built for low latency operations
- HBase is used extensively for random read and write operations
- HBase stores a large amount of data in terms of tables
- Provides linear and modular scalability over cluster environment
- Strictly consistent to read and write operations
- Automatic and configurable sharding of tables
- Automatic failover supports between Region Servers
- Convenient base classes for backing Hadoop MapReduce jobs in HBase tables
- Easy to use Java API for client access
- Block cache and Bloom Filters for real-time queries
- Query predicate pushes down via server-side filters.
When Not to use HBase?
HBase is not useful if:
- You only have a few thousand/million rows, then using a traditional RDBMS might be a better choice due to the fact that all of your data might wind up on a single node (or two) and the rest of the cluster may be sitting idle.
- You cannot live without RDBMS commands.
- You have hardware less than 5 Data Nodes when replication factor is 3.
Software
This can range from the operating system itself to files ystem choices and configuration of various auxiliary services.
Operating system
It is work on different versions of linux that are redhat, Ubuntu, Fedora, Debian etc. and run on those OS which supports Java.
Java
We need java for Hbase. Not just any version of Java, but version 6, a.k.a. 1.6, or later. You also should make sure the java binary is executable and can be found on your path. Try entering java -version on the command line and verify that it works and that it prints out the version number indicating it is version 1.6 or later—for example, java version “1.6.0_22”.
If you do not have Java on the command-line path or if HBase fails to start with a warning that it was not able to find it, edit the conf/hbase-env.sh file by commenting out the JAVA_HOME line and changing its value to where your Java is installed.
Hadoop
HBase depends on Hadoop, it bundles an instance of the Hadoop JAR under its lib directory. The bundled Hadoop was made from the Apache branch-0.20-append branch at the time of HBase’s release. It is critical that the version of Hadoop that is in use on your cluster matches what is used by HBase. Replace the Hadoop JAR found in the HBase lib directory with the hadoop-xyz.jar you are running on your cluster to avoid version mismatch issues. Make sure you replace the JAR on all servers in your cluster that run HBase. Version mismatch issues have various manifestations, but often the result is the same: HBase does not throw an error, but simply blocks indefinitely.
SSH
ssh must be installed and sshd must be running if you want to use the supplied scripts to manage remote Hadoop and HBase daemons. A commonly used software package providing these commands is OpenSSH. The supplied shell scripts make use of SSH to send commands to each server in the cluster.
Domain Name Service
HBase uses the local hostname to self-report its IP address. Both forward and reverse DNS resolving should work. You can verify if the setup is correct for forward DNS lookups.
Synchronized time
The clocks on cluster nodes should be in basic alignment. Some skew is tolerable, but wild skew can generate odd behaviors. Even differences of only one minute can cause explainable behavior. Run NTP on your cluster, or an equivalent application, to synchronize the time on all servers.
File handles and process limits
HBase is a database, so it uses a lot of files at the same time. The default ulimit -n of 1024 on most Unix or other Unix-like systems is insufficient. Any significant amount of loading will lead to I/O errors stating the obvious: java.io.IOException: Too many open files.
File systems for HBase
The most common filesystem used with HBase is HDFS. But you are not locked into HDFS because the FileSystem used by HBase has a pluggable architecture and can be used to replace HDFS with any other supported system. The primary reason HDFS is so popular is its built-in replication, fault tolerance, and scalability.
Local
The local filesystem actually bypasses Hadoop entirely, that is, you do not need to have an HDFS or any other cluster at all. It is handled all in the FileSystem class used by HBase to connect to the filesystem implementation. The supplied Checksum class is loaded by the client and uses local disk paths to store all the data.
HDFS
The Hadoop Distributed File System (HDFS) is the default filesystem when deploying a fully distributed cluster. For HBase, HDFS is the filesystem of choice, as it has all the required features. HDFS is built to work with MapReduce, taking full advantage of its parallel, streaming access support. The scalability, fail safety, and automatic replication functionality is ideal for storing files reliably. HBase adds the random access layer missing from HDFS and ideally complements Hadoop. Using MapReduce, you can do bulk imports, creating the storage files at disk-transfer speeds.
S3
Amazon’s Simple Storage Service (S3)# is a storage system that is primarily used in combination with dynamic servers running on Amazon’s complementary service named Elastic Compute Cloud (EC2). S3 can be used directly and without EC2, but the bandwidth used to transfer data in and out of S3 is going to be cost-prohibitive in practice.
Run modes
HBase has two run modes: standalone and distributed. This is the default mode. In standalone mode, HBase does not use HDFS—it uses the local file system instead—and it runs all HBase daemons and a local Zoo Keeper in the same JVM process. Zoo Keeper binds to a well-known port so that clients may talk to HBase.
The distributed mode can be further subdivided into pseudo distributed—all daemons run on a single node—and fully distributed—where the daemons are spread across multiple, physical servers in the cluster. Distributed modes require an instance of the Hadoop Distributed File System (HDFS).
Why Choose HBase?
A table for a popular web application may consist of billions of rows. If we want to search particular row from such a huge amount of data, HBase is the ideal choice as query fetch time in less. Most of the online analytics applications use HBase.
In HBase, tables are split into regions and are served by the region servers. Regions are vertically divided by column families into “Stores”. Stores are saved as files in HDFS. Shown below is the architecture of HBase.
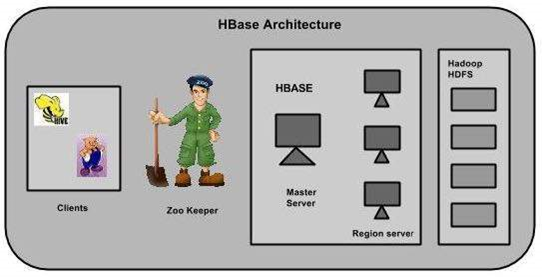
HBase has three major components: the client library, a master server, and region servers. Region servers can be added or removed as per requirement.
Master Server
The master server
- Assigns regions to the region servers and takes the help of Apache ZooKeeper for this task.
- Handles load balancing of the regions across region servers. It unloads the busy servers and shifts the regions to less occupied servers.
- Maintains the state of the cluster by negotiating the load balancing.
- Is responsible for schema changes and other metadata operations such as creation of tables and column families.
Regions
Regions are nothing but tables that are split up and spread across the region servers.
Region server
The region servers have regions that :
- Communicate with the client and handle data-related operations.
- Handle read and write requests for all the regions under it.
- Decide the size of the region by following the region size thresholds.
When we take a deeper look into the region server, it contain regions and stores as shown below:
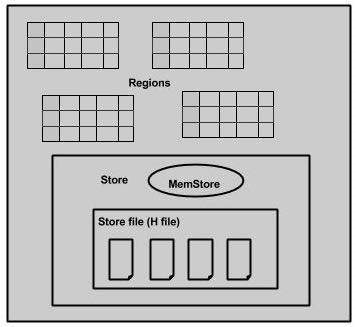
The store contains memory store and HFiles. Memstore is just like a cache memory. Anything that is entered into the HBase is stored here initially. Later, the data is transferred and saved in Hfiles as blocks and the memstore is flushed.
Zookeeper
- Zookeeper is an open-source project that provides services like maintaining configuration information, naming, providing distributed synchronization, etc.
- Zookeeper has ephemeral nodes representing different region servers. Master servers use these nodes to discover available servers.
- In addition to availability, the nodes are also used to track server failures or network partitions.
- Clients communicate with region servers via zookeeper.
- In pseudo and standalone modes, HBase itself will take care of zookeeper.
Non relational Database Systems, Not-Only SQL or NoSQL?
NoSQL encompasses a wide variety of different database technologies that were developed in response to a rise in the volume of data stored about users, objects and products, the frequency in which this data is accessed, and performance and processing needs. Relational databases, on the other hand, were not designed to cope with the scale and agility challenges that face modern applications, nor were they built to take advantage of the cheap storage and processing power available today.
Building Blocks
It provides you with an overview of the architecture behind HBase. It provides the general concepts of the data model and the available storage API, and presents a high level overview on implementation.
Tables, Rows, Columns, and Cells
The most basic unit is a column. One or more columns form a row that is addressed uniquely by a row key. A number of rows, in turn, form a table, and there can be many of them. Each column may have multiple versions, with each distinct value contained in a separate cell. All rows are always sorted lexicographic ally by their row key.
Auto-Sharding
The basic unit of scalability and load balancing in HBase is called a region. Regions are essentially contiguous ranges of rows stored together. They are dynamically split by the system when they become too large. Alternatively, they may also be merged to reduce their number and required storage files. Each region is served by exactly one region server, and each of these servers can serve many regions at any time.Splitting and serving regions can be thought of as autographing, as offered by other systems. The regions allow for fast recovery when a server fails, and fine-grained load balancing since they can be moved between servers when the load of the server currently serving the region is under pressure, or if that server becomes unavailable because of a failure or because it is being decommissioned.Splitting is also very fast—close to instantaneous—because the split regions simply read from the original storage files until a compaction rewrites them into separate ones asynchronously.

Get Enroll in Apache HBase Training with Instructor-led Classes
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Importance of NoSQL Databases in Hadoop
In big data analytics, Hadoop plays a vital role in solving typical business problems by managing large data sets and gives the best solutions in analytics domain.In the Hadoop ecosystem, each component plays its unique role for the Data processing Data validation Data storing .In terms of storing unstructured, semi-structured data storage as well as retrieval of such data’s, relational databases are less useful. Also, fetching results by applying query on huge data sets that are stored in Hadoop storage is a challenging task. NoSQL storage technologies provide the best solution for faster querying on huge datasets.
Other NoSQL storage type Databases
Some of the NoSQL models present in the market are Cassandra, MongoDB, and Couch DB. Each of these models has different ways of storage mechanism.For example, MongoDB is a document-oriented database from the NoSQL family tree. Compared to traditional databases it provides the best features in terms of performance, availability, and scalability. It is an open source document-oriented database, and it’s written in C++.Cassandra is also a distributed database from open source Apache software which is designed to handle a huge amount of data stored across commodity servers. Cassandra provides high availability with no single point of failure.While Couch Db is a document-oriented database in which each document fields are stored in key-value maps.
How HBase different from other NoSQL model
storage model is different from other NoSQL models discussed above. This can be stated as follow HBase stores data in the form of key/value pairs in a columnar model. In this model, all the columns are grouped together as Column families. HBase provides a flexible data model and low latency access to small amounts of data stored in large data sets HBase on top of Hadoop will increase the throughput and performance of distributed cluster set up. In turn, it provides faster random reads and writes operations.
HBase Read
A read against HBase must be reconciled between the H Files, MemStore & BLOCK CACHE. The Block Cache is designed to keep frequently accessed data from the HFiles in memory so as to avoid disk reads.Each column family has its own Block Cache. Block Cache contains data in form of ‘block’, as unit of data that HBase reads from disk in a single pass.The HFile is physically laid out as a sequence of blocks plus an index over those blocks. This means reading a block from HBase requires only looking up that block’s location in the index and retrieving it from disk.
Block
It is the smallest indexed unit of data and is the smallest unit of data that can be read from disk. default size 64KB.
Scenario, when smaller block size is preferred:
To perform random look ups. Having smaller blocks creates a larger index and thereby consumes more memory.
Scenario, when larger block size is preferred:
To perform sequential scans frequently. This allows you to save on memory because larger blocks mean fewer index entries and thus a smaller index.
Reading a row from HBase requires first checking the MemStore, then the BlockCache, Finally, HFiles on disk are accessed.
HBase Write
When a write is made, by default, it goes into two places:
- write-ahead log (WAL), HLog, and
- in-memory write buffer, MemStore.
Clients don’t interact directly with the underlying HFiles during writes, rather writes goes to WAL & MemStore in parallel. Every write to HBase requires confirmation from both the WAL and the MemStore.
HBase MemStore
The MemStore is a write buffer where HBase accumulates data in memory before a permanent write.Its contents are flushed to disk to form an H File when the MemStore fills up.It doesn’t write to an existing H File but instead forms a new file on every flush.The H File is the underlying storage format for HBase. H Files belong to a column family(one MemStore per column family). A column family can have multiple H Files, but the reverse isn’t true.size of the MemStore is defined in base-sitemap called h base region memstore flush size. Every server in HBase cluster keeps a WAL to record changes as they happen. The WAL is a file on the underlying file system.A write isn’t considered successful until the new WAL entry is successfully written, this guarantees durability.If HBase goes down, the data that was not yet flushed from the MemStore to the H File can be recovered by replaying the WAL, taken care by H base framework.
HBase Commands
A list of HBase commands are given below.Create: Creates a new table identified by ‘table 1’ and Column Family identified by ‘cold’.Put: Inserts a new record into the table with row identified by ‘row..’Scan: returns the data stored in table
Get: Returns the records matching the row identifier provided in the table Help: Get a list of commands
HBase Shell
HBase contains a shell using which you can communicate with HBase. HBase uses the Hadoop File System to store its data. It will have a master server and region servers. The data storage will be in the form of regions (tables). These regions will be split up and stored in region servers.The master server manages these region servers and all these tasks take place on HDFS. Given below are some of the commands supported by HBase Shell.
General Commands status
Provides the status of HBase, for example, the number of servers.version
Provides the version of HBase being used.table_help Provides help for table-reference commands.whoami Provides information about the user.
Data Definition Language
These are the commands that operate on the tables in HBase.create – Creates a table.list – Lists all the tables in HBase.disable – Disables a table.is_disabled – Verifies whether a table is disabled.enable – Enables a table.is_enabled – Verifies whether a table is enabled.describe – Provides the description of a table.alter – Alters a table.exists – Verifies whether a table exists.drop – Drops a table from HBase.drop_all – Drops the tables matching the ‘regex’ given in the command.Java Admin API – Prior to all the above commands, Java provides an Admin API to achieve DDL functionalities through programming. Under org.apache.hadoop.hbase.client package, HBaseAdmin and HTableDescriptor are the two important classes in this package that provide DDL functionalities.
Data Manipulation Language put
Puts a cell value at a specified column in a specified row in a particular table.get – Fetches the contents of row or a cell.delete – Deletes a cell value in a delectable . Deletes all the cells in a given row.scan – Scans and returns the table data.count – Counts and returns the number of rows in a table.truncate – Disables, drops, and recreates a specified table.Java client API – Prior to all the above commands, Java provides a client API to achieve DML functionalities, CRUD (Create Retrieve Update Delete) operations and more through programming, under Admin API HBase is written in java, therefore it provides java API to communicate with HBase. Java API is the fastest way to communicate with HBase. Given below is the referenced java Admin API that covers the tasks used to manage tables.
Class HBaseAdmin
HBaseAdmin is a class representing the Admin. This class belongs to the org.apache.hadoop.hbase.client package. Using this class, you can perform the tasks of an administrator. You can get the instance of Admin using Connection.getAdmin() method.
Class Descriptor
This class contains the details about an HBase table such as:the descriptors of all the column families,if the table is a catalog table,if the table is read only,the maximum size of the mem store,when the region split should occur,co-processors associated with it, etc.
Security
We can grant and revoke permissions to users in HBase. There are three commands for security purpose: grant, revoke, and user_permission.
Grant
The grant command grants specific rights such as read, write, execute, and admin on a table to a certain user.
revoke
The revoke command is used to revoke a user’s access rights of a table.
user_permission
This command is used to list all the permissions for a particular table.
describe
This command returns the description of the table .
Alter
Alter is the command used to make changes to an existing table. Using this command, you can change the maximum number of cells of a column family, set and delete table scope operators, and delete a column family from a table.
Conclusion
HBase provides unique features and will solve typical industrial use cases. As column-oriented storage, it provides fast querying, fetching of results and high amount of data storage. This course is a complete step by step introduction to HBase.




