
Last updated on 11th Jan 2022| 3748
- Introduction to Kafka Configuration Tutorial:
- What is event streaming?
- Top 10 Apache Kafka Features
- Kafka Architecture – Component Relationship Examples
- Prerequisites
- Conclusion
Introduction to Kafka Configuration Tutorial:
First, allow us to start implementing single node-single broker configuration, and that we will then migrate our setup to single node-multiple brokers configuration.
Hopefully, you’d have installed Java, ZooKeeper, and Kafka on your machine by now. Before moving to the Kafka Cluster Setup, first, you’d got to start your ZooKeeper because Kafka Cluster uses ZooKeeper.
What is event streaming?:
Event streaming is that the digital equivalent of the human body’s central systema nervosum. it’s the technological foundation for the ‘always-on’ world where businesses are increasingly software-defined and automatic, and where the user of the software is more software.
Technically speaking, event streaming is that the practice of capturing data in real-time from event sources like databases, sensors, mobile devices, cloud services, and software applications within the sort of streams of events; storing these event streams durably for later retrieval; manipulating, processing, and reacting to the event streams in real-time also as retrospectively; and routing the event streams to different destination technologies as required. Event streaming thus ensures endless flow and interpretation of knowledge so that the proper information is at the proper place, at the proper time.
Top 10 Apache Kafka Features:
Here, is that the list of most vital Apache Kafka features:
Scalability
Apache Kafka can handle scalability altogether in the four dimensions, i.e. event producers, event processors, event consumers, and event connectors. In other words, Kafka scales easily without downtime.
High-Volume
Kafka can work with a large volume of knowledge streams, easily.
Data Transformations
Kafka offers provision for deriving new data streams using the info streams from producers.
Fault Tolerance
Failures with masters and databases can be handled by the Kafka cluster.
Reliability
Kafka is extremely dependable because it is distributed, partitioned, replicated, and fault-tolerant.
Durability
It is long-lasting because Kafka employs a Distributed commit log, which ensures that messages are stored on the disc as quickly as possible. Kafka has high throughput for both publishing and subscribing to messages. Even though many TB of messages is stored, it maintains stable performance.
There is no downtime.
Kafka is extremely fast and ensures no downtime or data loss.
Extensibility
There are some ways by which applications can connect and make use of Kafka. additionally, offers ways by which to write down new connectors as required.
Replication
By using down channels, it can copy the circumstances.
Kafka Architecture – Component Relationship Examples:
Let’s study out the connections among the key features within Kafka’s architecture. Note the subsequent when it involves brokers, replicas, and sections:
- Kafka groups may have one or more agents.
- Kafka brokers are ready to host multiple partitions.
- Topics are ready to include one or more partitions.
- Brokers are ready to host either one or zero replicas for every partition.
- Each partition includes one leader replica, and 0 or greater follower replicas.
- Each of a partition’s replicas has got to get on a special broker.
- Each partition replica has got to fit completely on a broker, and can’t be split onto quite one broker.
- Each broker is often the leader for zero or more topic/partition pairs.

Learn Advanced Kafka Certification Training Course to Build Your Skills
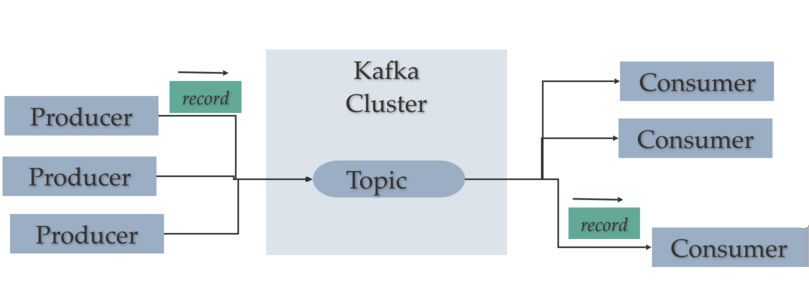
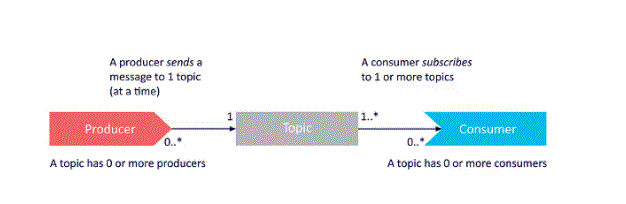
Weekday / Weekend BatchesSee Batch DetailsNow let’s check out a couple of samples of how producers, topics, and consumers relate to at least one another:
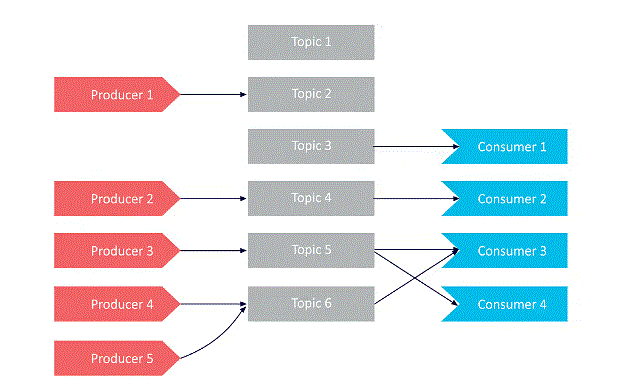
- Here we see an easy example of a producer sending a message to a subject, and a consumer that’s subscribed thereto topic reading the message. The following chart shows how producers can send letters to singular cases:
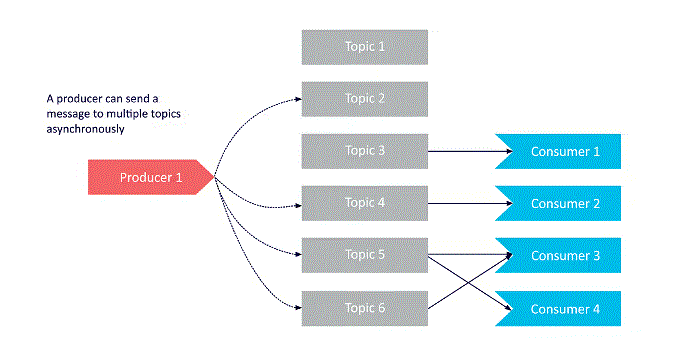
- Consumers can subscribe to multiple topics directly and receive messages from them during a single poll (Consumer 3 within the diagram shows an example of this). The messages that buyers receive are often checked and filtered by topic when needed (using the technique of adding keys to messages, described above). Now let’s check out a producer that’s sending messages to multiple topics directly, in an asynchronistic manner:
- Technically, a producer may only be ready to send messages to one topic directly. However, by sending messages asynchronously, producers can functionally deliver multiple messages to multiple topics as required.
- Kafka architecture is made around emphasizing the performance and scalability of brokers. This goes producers to take the burden of managing which section receives which notes. A hashing function on the message key defines the default section where a message will find itself. If no key’s defined, the message lands in partitions during a round-robin series.
- These methods can cause issues or sub-optimal outcomes, however, in scenarios that include message ordering or a good message distribution across consumers. To unravel such issues, it’s possible to regulate the way producers send messages and direct those messages to specific partitions. Doing so requires employing a customer partitioner, or the default partitions alongside available manual or hashing options.
Start ZooKeeper:
- Open a replacement terminal and sort the subsequent command −
- bin/zookeeper-server-start.sh config/zookeeper.properties
- To start Kafka Broker, type the subsequent command −
- bin/Kafka-server-start.sh config/server.properties
- After creating Kafka Broker, type the base jps on the ZooKeeper terminal and you’d see the following reaction −
- 821 QuorumPeerMain
- 928 Kafka
- 931 Jps
- Now you’ll see two daemons running on the terminal where QuorumPeerMain may be a ZooKeeper daemon and another one is Kafka daemon.
- Single Node-Single Broker Configuration
- In this configuration, you’ve got one ZooKeeper and broker id instance. Heeding are the actions to configure it −
- Creating a Kafka Topic − Kafka delivers a command-line utility called Kafka-topics. sh to make topics on the server. Spread a replacement terminal and sort the below example.
- Syntax
- bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1
- –partitions 1 –topic topic-name
- Example
- bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1
- –partitions 1 –topic Hello-Kafka
- We just created a subject named Hello-Kafka with one partition and one replica factor. The above-created output is going to be almost like the subsequent output −
- Output − Created topic Hello-Kafka
- Once the issue has been created, you’ll get the information within the Kafka broker airport window and therefore the log for the completed case laid out in “/tmp/
- Kafka-logs/“ within the config/server.properties file.
- List of Subjects
- To get an inventory of topics in Kafka server, you’ll use the subsequent command −
- Syntax
- bin/Kafka-topics.sh –list –zookeeper localhost:2181
- Output
- Hello-Kafka
- Since we’ve created a subject, it’ll list out Hello-Kafka only. Suppose, if you create quite one topic, you’ll get the subject names within the output.
Start Producer to Send Messages:
- Syntax
- bin/Kafka-console-producer.sh –broker-list localhost:9092 –topic topic-name
- From the overhead syntax, two major parameters are needed for the producer command-line client −
- Broker-list − The list of brokers that we would like to send the messages to. during this case, we only have one broker. The Config/server.properties file contains
- broker port id, since we all know our broker is listening on port 9092, so you’ll specify it directly.
- Topic name − Here is an example of the subject name.
- Example
- bin/Kafka-console-producer.sh –broker-list localhost:9092 –topic Hello-Kafka
- The producer will serve input from stdin and publish it to the Kafka cluster. By default, every printing operation is published as a replacement message then the default producer properties are laid out in the config/producer.properties file. Now you’ll A few lines of messages within the terminal as shown below.
- Output
- $ bin/kafka-console-producer.sh –broker-list localhost:9092
- –topic Hello-Kafka[2016-01-16 13:50:45,931]
- WARN property topic isn’t valid (kafka.utils.Verifia-bleProperties)
- Hello
- My first message
- My second message
Start Consumer to Receive Messages:
Similar to the producer, the default consumer properties are laid out in the config/consumer.proper-ties file. Open a replacement terminal and sort the below syntax for consuming messages.
- Syntax
- bin/kafka-console-consumer.sh –zookeeper localhost:2181 —topic topic-name
- –from-beginning
- Example
- bin/kafka-console-consumer.sh –zookeeper localhost:2181 —topic Hello-Kafka
- –from-beginning
- Output
- Hello
- My first message
- My second message
Eventually, you’ll enter notes from the producer’s airport and see them occurring within the consumer’s terminal. As of now, you’ve got a really good arrangement of the only node cluster with one broker. Allow us to now advance to the multiple broker configurations.

Get JOB Oriented Kafka Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Single Node-Multiple Brokers Configuration:
Before proceeding on to the numerous broker’s cluster configurations, first, create your ZooKeeper server. Create Multiple Kafka Brokers − we’ve one Kafka broker instance already in con-fig/server.properties. Now we’d like numerous proxy models, so copy the prevailing server.properties file into two new config files and rename it as server-one. properties and server-two. properties. Then edit both new files and assign the subsequent changes −
- config/server-one.properties
- # The id of the broker. This must be set to a singular integer for every broker.
- broker.id=1
- # The dock the socket server hears on
- port=9093
- # A comma-separated list of guides under which to store log files
- log.dirs=/tmp/kafka-logs-1
- config/server-two.properties
- # The id of the broker. This must be set to a singular integer for every broker.
- broker.id=2
- # The port the socket server listens on
- port=9094
- # A comma-separated list of directories under which to store log files
- log.dirs=/tmp/kafka-logs-2
- Start Multiple Brokers− in any case, the changes are made on three servers then open three new terminals to start each broker one by one.
- Broker1
- bin/Kafka-server-start.sh config/server.properties
- Broker2
- bin/Kafka-server-start.sh config/server-one.properties
- Broker3
- bin/Kafka-server-start.sh config/server-two.properties
- Now we’ve three different brokers running on the machine. Try it by yourself to see all the daemons by typing jps on the ZooKeeper terminal, then you’d see the response.
- Creating a subject
- Let us set the replication factor weight as three for this issue because we’ve three different brokers operating. If you’ve got two brokers, then the designated replica value is going to be two.
- Syntax
- bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 3
- -partitions 1 –topic topic-name
- Example
- bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 3 –
- partitions 1 –topic Multi-Broker application
- Output
- created topic “Multi Brokerapplication”
- The Describe command is employed to see which broker is listening on the present created topic as shown below −
- bin/kafka-topics.sh –describe –zookeeper localhost:2181
- –topic Multibrokerappli-cation
- Output
- bin/kafka-topics.sh –describe –zookeeper localhost:2181
- –topic Multibrokerappli-cation
- Topic:Multi Brokerapplication PartitionCount:1
- ReplicationFactor:3 Configs:
- Topic:Multi Brokerapplication Partition:0 Leader:0
- Replicas:0,2,1 Isr:0,2,1
From the above output, we will conclude that the primary line gives a summary of all the partitions, showing the subject name, partition count, and therefore the replication factor that we’ve chosen already. Within the second line, each node is going to be the leader for a randomly selected portion of the partitions. In our case, we see our first broker (with a broker. id 0) is that the leader. Then Replicas:0,2,1 means all the brokers replicate the subject, finally, Isr is that the set of in-sync replicas. Well, this is often the subset of replicas that are currently alive and trapped by the leader.
Prerequisites:
- At least 8 GB RAM.
- At least 500 GB Storage.
- Ubuntu 14.04 or later, RHEL 6, RHEL 7, or equivalent.
- Access to Kafka (specifically, the ability to consume messages and to communicate with Zookeeper)
- Access to Kafka Connect instances (if you want to configure Kafka Connect)

Conclusion:
The performance depends on the delivery of each message to its consumer correctly, on time without more lag of your time. The message delivery has got to be done at an ideal time and if not received within that specific time, alerts start to boost.




