
Last updated on 08th Jul 2020| 2580
Hadoop is an Apache open source framework written in java that allows distributed processing of large datasets across clusters of computers using simple programming models. The Hadoop framework application works in an environment that provides distributed storage and computation across clusters of computers. Hadoop is designed to scale up from single server to thousands of machines, each offering local computation and storage.
Hadoop Architecture
At its core, Hadoop has two major layers namely:
- Processing/Computation layer (MapReduce), and
- Storage layer (Hadoop Distributed File System).

MapReduce
MapReduce is a parallel programming model for writing distributed applications devised at Google for efficient processing of large amounts of data (multi-terabyte data-sets), on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner. The MapReduce program runs on Hadoop which is an Apache open-source framework.
Assumptions and Goals
Hardware Failure
Hardware failure is the norm rather than the exception. An HDFS instance may consist of hundreds or thousands of server machines, each storing part of the file system’s data. The fact that there are a huge number of components and that each component has a non-trivial probability of failure means that some component of HDFS is always non-functional. Therefore, detection of faults and quick, automatic recovery from them is a core architectural goal of HDFS.
Streaming Data Access
Applications that run on HDFS need streaming access to their data sets. They are not general purpose applications that typically run on general purpose file systems. HDFS is designed more for batch processing rather than interactive use by users. The emphasis is on high throughput of data access rather than low latency of data access. POSIX imposes many hard requirements that are not needed for applications that are targeted for HDFS. POSIX semantics in a few key areas has been traded to increase data throughput rates.
Large Data Sets
Applications that run on HDFS have large data sets. A typical file in HDFS is gigabytes to terabytes in size. Thus, HDFS is tuned to support large files. It should provide high aggregate data bandwidth and scale to hundreds of nodes in a single cluster. It should support tens of millions of files in a single instance.
Simple Coherency Model
HDFS applications need a write-once-read-many access model for files. A file once created, written, and closed need not be changed. This assumption simplifies data coherency issues and enables high throughput data access. A Map Reduce application or a web crawler application fits perfectly with this model. There is a plan to support appending-writes to files in the future.
“Moving Computation is Cheaper than Moving Data”
A computation requested by an application is much more efficient if it is executed near the data it operates on. This is especially true when the size of the data set is huge. This minimizes network congestion and increases the overall throughput of the system. The assumption is that it is often better to migrate the computation closer to where the data is located rather than moving the data to where the application is running. HDFS provides interfaces for applications to move themselves closer to where the data is located.
Portability Across Heterogeneous Hardware and Software Platforms
HDFS has been designed to be easily portable from one platform to another. This facilitates widespread adoption of HDFS as a platform of choice for a large set of applications.
Hadoop Distributed File System
The Hadoop Distributed File System (HDFS) is based on the Google File System (GFS) and provides a distributed file system that is designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. It is highly fault-tolerant and is designed to be deployed on low-cost hardware. It provides high throughput access to application data and is suitable for applications having large datasets.
Apart from the above-mentioned two core components, Hadoop framework also includes the following two modules:
- Hadoop Common: These are Java libraries and utilities required by other Hadoop modules.
- Hadoop YARN: This is a framework for job scheduling and cluster resource management.
How Does Hadoop Work?
It is quite expensive to build bigger servers with heavy configurations that handle large scale processing, but as an alternative, you can tie together many commodity computers with single-CPU, as a single functional distributed system and practically, the clustered machines can read the dataset in parallel and provide a much higher throughput. Moreover, it is cheaper than one high-end server. So this is the first motivational factor behind using Hadoop that it runs across clustered and low-cost machines.
Hadoop runs code across a cluster of computers. This process includes the following core tasks that Hadoop performs:
- Data is initially divided into directories and files. Files are divided into uniform sized blocks of 128M and 64M (preferably 128M).
- These files are then distributed across various cluster nodes for further processing.
- HDFS, being on top of the local file system, supervises the processing.
- Blocks are replicated for handling hardware failure.
- Checking that the code was executed successfully.
- Performing the sort that takes place between the map and reduce stages.
- Sending the sorted data to a certain computer.
- Writing the debugging logs for each job.
Advantages of Hadoop
- Hadoop framework allows the user to quickly write and test distributed systems. It is efficient, and it automatic distributes the data and work across the machines and in turn, utilizes the underlying parallelism of the CPU cores.
- Hadoop does not rely on hardware to provide fault-tolerance and high availability (FTHA), rather Hadoop library itself has been designed to detect and handle failures at the application layer.
- Servers can be added or removed from the cluster dynamically and Hadoop continues to operate without interruption.
- Another big advantage of Hadoop is that apart from being open source, it is compatible on all the platforms since it is Java based.
Hadoop Installation on Windows
As a beginner, you might feel reluctant in performing cloud computing which requires subscriptions. While you can install a virtual machine as well in your system, it requires allocation of a large amount of RAM for it to function smoothly else it would hang constantly.

Enroll in Best Big Data Hadoop Training & Certification Courses and Get Hired By TOP MNCs
Weekday / Weekend BatchesSee Batch DetailsYou can install Hadoop in your system as well which would be a feasible way to learn Hadoop.
We will be installing single node pseudo-distributed hadoop cluster on windows 10.
Prerequisite: To install Hadoop, you should have Java version 1.8 in your system.
Check your java version through this command on command prompt
java –version
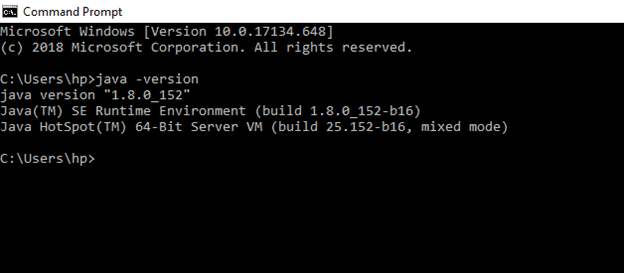
If java is not installed in your system, then:
Go this link- https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl…
Accept the license,
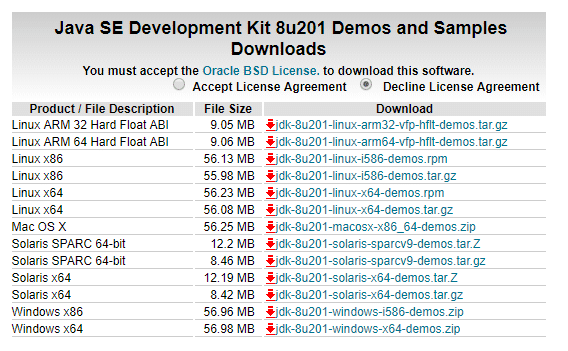
Download the file according to your operating system. Keep the java folder directly under the local disk directory (C:\Java\jdk1.8.0_152) rather than in Program Files (C:\Program Files\Java\jdk1.8.0_152) as it can create errors afterwards.
After downloading java version 1.8, download hadoop version 3.1 from this link :
https://archive.apache.org/dist/hadoop/common/hadoop-3.1.0/hadoop-3…
Extract it to a folder.
Setup System Environment Variables
Open control panel to edit the system environment variable:
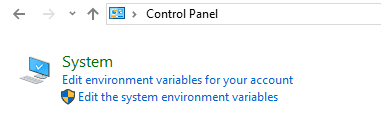
Go to environment variable in system properties:

Get Hands-On Practical Big Data Hadoop Training to Advance Your Career
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
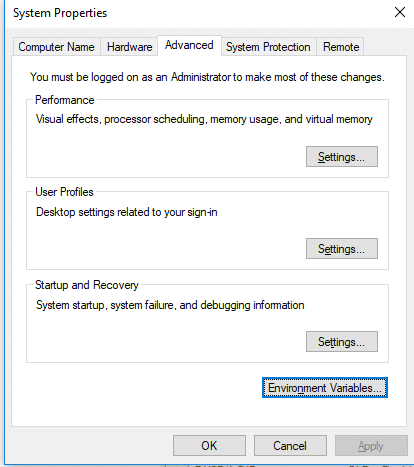
Create a new user variable. Put the Variable_name as HADOOP_HOME and Variable_value as the path of the bin folder where you extracted hadoop.
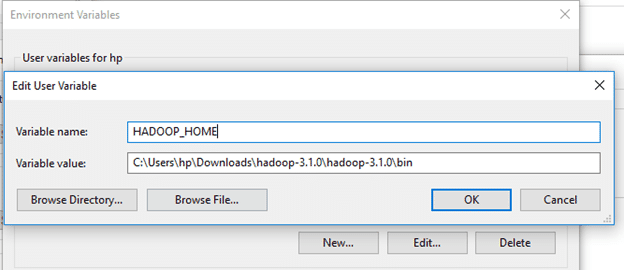
Likewise, create a new user variable with variable name as JAVA_HOME and variable value as the path of the bin folder in the Java directory.
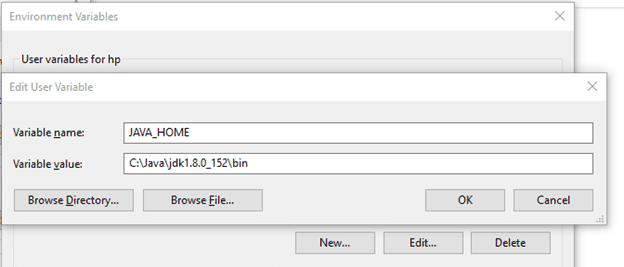
Now we need to set Hadoop bin directory and Java bin directory path in system variable path.
Edit Path in system variable:
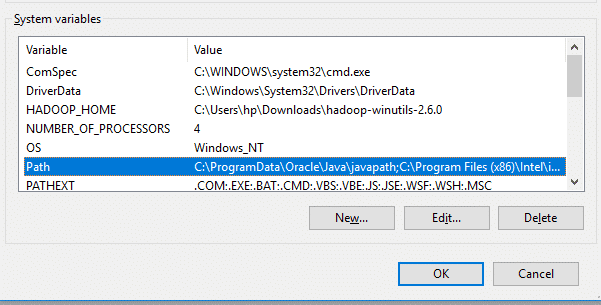
Click on New and add the bin directory path of Hadoop and Java in it.
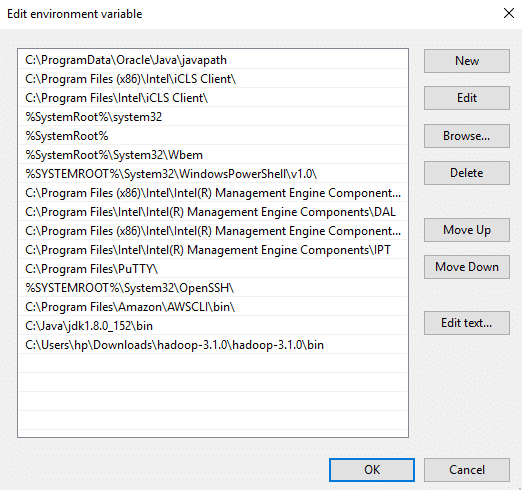
Now, the Hadoop Architecture Tutorial has been installed successfully in Windows.
Conclusion
Hadoop MapReduce can be used to perform data processing activity. However, it possessed limitations due to which frameworks like Spark and Pig emerged and have gained popularity. A 200 lines of MapReduce code can be written with less than 10 lines of Pig code. Hadoop has various other components in its ecosystem like Hive, Sqoop, Oozie, and HBase. You can download this software as well in your windows system to perform data processing operations using cmd.




