
Last updated on 10th Jul 2020| 4485
The Big Data tool, which we use for transferring data between Hadoop and relational database servers is what we call Sqoop. In this Apache Sqoop Tutorial, we will learn the whole concept regarding Sqoop. We will study What is Sqoop, several prerequisites required to learn Sqoop, Sqoop Releases, Sqoop Commands, and Sqoop Tools. Afterward, we will move forward to the basic usage of Sqoop. Moving forward, we will also learn how Sqoop works.
What is Apache Sqoop?
A tool that we use for transferring data between Hadoop and relational database servers is what we call Sqoop. While it comes to import data from a relational database management system (RDBMS) such as MySQL or Oracle into the Hadoop Distributed File System (HDFS), we can use Sqoop. Also, we can use Sqoop to transform the data in Hadoop MapReduce and then export the data back into an RDBMS.
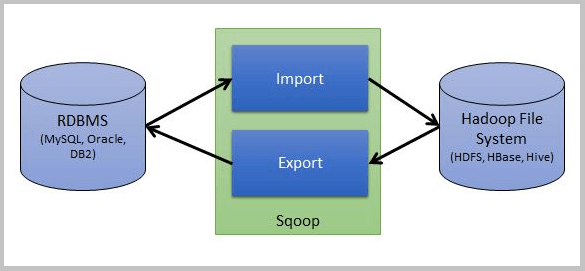
In addition, there are several processes that Apache Sqoop automates, such as relying on the database to describe the schema to import data. Moreover, to import and export the data, Sqoop uses MapReduce. Also, offers parallel operation as well as fault tolerance. Basically, we can say Sqoop is provided by the Apache Software Foundation.
Basically, Sqoop (“SQL-to-Hadoop”) is a straightforward command-line tool. It offers the following capabilities:
- Generally, helps to Import individual tables or entire databases to files in HDFS
- Also can Generate Java classes to allow you to interact with your imported data
- Moreover, it offers the ability to import from SQL databases straight into your Hive data warehouse.
Prerequisites to learn Sqoop
In the Apache Sqoop tutorial, we are going to study prerequisites to learn Sqoop. Such as:
- Basic computer technology and terminology.
- General familiarity with Sqoop command-line interfaces like bash and many more.
- Relational database management systems.
- General familiarity with Hadoop’s purpose and operation.
Basically, an important thing to note that to use Apache Sqoop, we need a release of Hadoop installation and configuration. Although, currently Sqoop is supporting 4 major Hadoop releases. Such as – 0.20, 0.23, 1.0 and 2.0.
In addition, be assured that you are using a Linux or a Linux-like environment. Also, remember that Sqoop is predominantly operated and tested on Linux.
Apache Sqoop – Tools
Basically, Sqoop attains the collection of related tools. We can use Sqoop, by just specifying the tool we want to use but with the arguments that control the tool.
In addition, Since Sqoop is compiled from its own source, by running the bin/sqoop program we can run Sqoop without a formal installation process. Also, users of a packaged deployment of Sqoop will see this program installed as /usr/bin/sqoop. Such as an RPM shipped with Apache Bigtop. Moreover, the remainder of this documentation will refer to this program as sqoop.
Using Command Aliases
We can use alias scripts by typing the sqoop (tool name) syntax. Basically, that specifies the sqoop-(tool name) syntax. Like, the scripts sqoop-import, sqoop-export, and many more. Although, each select a specific tool.
Controlling the Hadoop Installation
To elicit Sqoop we can use the program launch capability provided by Hadoop. To run the bin/hadoop script shipped with Hadoop, we can use the sqoop command-line program wrapper. Since there are multiple installations of Hadoop present on your machine, we can easily select the Hadoop installation just by setting the $HADOOP_COMMON_HOME and $HADOOP_MAPRED_HOME environment variables.
Using Generic and Specific Arguments
Basically, we can use generic and specific arguments to control the operation of each Sqoop tool.
It is essential to supply the generic arguments after the tool name like -conf, -D, and so on. However, it must be before any tool-specific arguments like –connect.
In addition, some arguments control the configuration and Hadoop server settings. Like -conf, -D, -fs and -jt.
Using Options Files to Pass Arguments
For convenience, the Sqoop command line options that do not change from invocation to invocation can be put in options file in Sqoop. Basically, an options file can be defined as a text file. In a text file, each line identifies an option in the order that it appears otherwise on the command line.
Moreover, by using the backslash character at the end of intermediate lines, an options file allows specifying a single option on multiple lines. Although, on a new line, comments must be specified. Also, important that may not be mixed with option text. However, when option files have expanded, all comments and empty lines are ignored.
We can also specify an options file, by simply creating an options file in a convenient location and passing it to the command line. By using –options-file argument.
Sqoop Import
Basically, when it comes to importing tool, it imports individual tables from RDBMS to HDFS. Here, in HDFS each row in a table is treated as a record. Moreover, in Avro and Sequence files all records are stored as text data in text files or as binary data.
Purpose of Sqoop Import
From an RDBMS to HDFS, the import tool imports an individual table. Here, in HDFS each row from a table is represented as a separate record. Moreover, we can store Records as text files (one record per line). However, in binary representation as Avro or SequenceFiles.
Sqoop Export
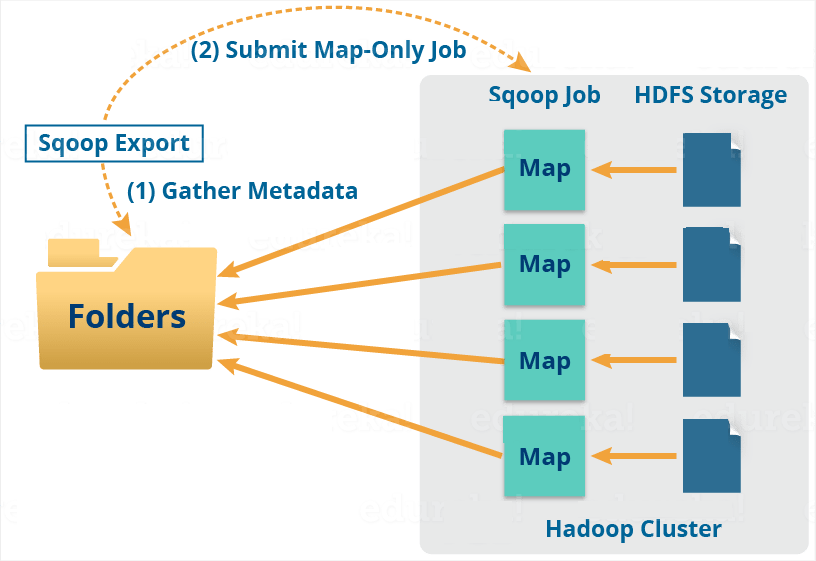
When we want to export a set of files from HDFS back to an RDBMS we use the export tool. Basically, there are rows in the table those are the files that are input to Sqoop those contains records, which we call as rows in the table. Although, those files are read and parsed into a set of records. Also, delimited with the user-specified delimiter.
Purpose of Sqoop export
When we want to export a set of files from HDFS back to an RDBMS we use the export tool. One condition is here, the target table must already exist in the database.
In addition, to transform these into a set of INSERT statements, the default operation is that inject the records into the database. Moreover, Sqoop will generate UPDATE statements in “update mode,” that replace existing records in the database. Whereas, in “call mode” Sqoop will make a stored procedure call for each record.
Inserts vs. Updates
By default, sqoop-export appends new rows to a table; each input record is transformed into an INSERT statement that adds a row to the target database table. If your table has constraints (e.g., a primary key column whose values must be unique) and already contains data, you must take care to avoid inserting records that violate these constraints.
The export process will fail if an INSERT statement fails. This mode is primarily intended for exporting records to a new, empty table intended to receive these results.
If you specify the –update-key argument, Sqoop will instead modify an existing dataset in the database. Each input record is treated as an UPDATE statement that modifies an existing row. The row a statement modifies is determined by the column name(s) specified with –update-key.
Exports and Transactions
Basically, by multiple writers, it performs exports in parallel. Here, to the database each writer uses a separate connection; these have separate transactions from one another. Moreover, Sqoop uses the multi-row INSERT syntax to insert up to 100 records per statement.
Also, every 100 statements commit the current transaction within a writing task, causing a commit every 10,000 rows. Also, it ensures that transaction buffers do not grow without bound, and cause out-of-memory conditions. Therefore, an export is not an atomic process. Partial results from the export will become visible before the export is complete.
Failed Exports
However, there are no. of reasons for which exports may fail such as:
- When there is a loss of connectivity from the Hadoop cluster to the database. It can be for many reasons like due to the hardware fault, or server software crashes.
- While we attempt to INSERT a row that violates a consistency constraint. For example, inserting a duplicate primary key value.
- Also, by attempting to parse an incomplete or malformed record from the HDFS source data
- By using incorrect delimiters while it attempts to parse records
- Due to some capacity issues. For Example, insufficient RAM or disk space.
Due to these or other reasons, if an export map task fails, it may cause the export job to fail. Although, failed exports just have undefined results. Also, we can say each export map task operates in a separate transaction. Moreover, individual map tasks commit their current transaction periodically. However, in the database any previously-committed transactions will remain durable, leading to a partially-complete export.
Usage
In this Sqoop Tutorial, we study Working, import, export, release, and tools now look at usage of sqoop. Basically, by using Sqoop we can easily import data from a relational database system. Also possible from a mainframe to HDFS. Although to import process, the input is either database table or mainframe datasets. However, Sqoop will read the table row-by-row into HDFS for databases. Whereas, Sqoop will read records from each mainframe dataset into HDFS for mainframe datasets. Furthermore, a set of files containing a copy of the imported table or datasets is the output of this import process.

Join Best Apache Sqoop Course with Global Recognised Certification
Weekday / Weekend BatchesSee Batch DetailsTherefore, it performs the import process in parallel. For this reason, the output will be in multiple files.
Moreover, there are some other Sqoop commands. Also, allow us to inspect the database you are working with. For example, you can list the available database schemas and tables within a schema. Sqoop also includes a primitive SQL execution shell (the sqoop-eval tool).
Sqoop Validation
Sqoop Validation is nothing but to validate the data copied. In this article, we will learn the whole concept of validation in Sqoop. After the introduction, we will learn the purpose of validation in sqoop. Moreover, we will also cover sqoop validation interface, Sqoop validation syntax & configuration, examples, and limitations of sqoop validation as well.
Introduction to Sqoop Validation
- Sqoop validation simply means validating the data copied. Basically, either import or Export by comparing the row counts from the source as well as the target post copy.
- Moreover, we use this option to compare the row counts between source as well as the target just after data imported into HDFS.
- While during the imports, all the rows are deleted or added, Sqoop tracks this change. Also updates the log file.
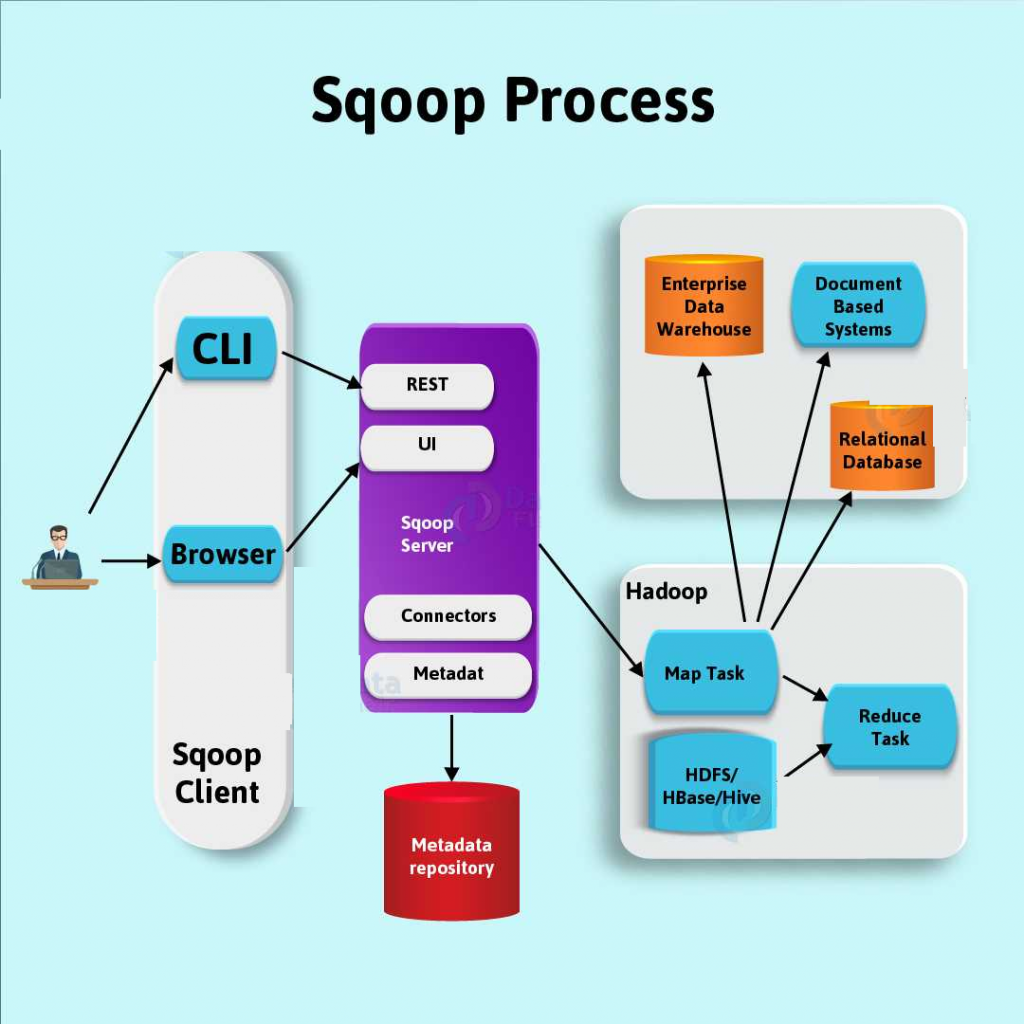
Interfaces of Sqoop Validation
ValidationThreshold
We use the ValidationThreshold to determine whether the error margin between the source and target are acceptable: Absolute, Percentage Tolerant and many more. However, the default implementation is AbsoluteValidationThreshold.
Basically, that ensures that the row counts from source as well as targets are the same.
ValidationFailureHandler
Also, it once interfaced with ValidationFailureHandler, which is responsible for handling failures here. Such as log an error/warning, abort and many more. Although the default implementation is LogOnFailureHandler. Here that logs a warning message to the configured logger.
Validator
Basically, by delegating the decision to ValidationThreshold Validator drives the validation logic. Also delegates failure handling to ValidationFailureHandler. Moreover, the default implementation is RowCountValidator here. That validates the row counts from source as well as the target.
Purpose to Validate in Sqoop
Validation in sqoop’s main purpose is to validate the data copied. Basically, either Sqoop import or Export by comparing the row counts from the source as well as the target post copy.
Sqoop Validation Configuration
We can say that the validation framework is extensible as well as pluggable in nature. However, it comes with default implementations. Yet we can extend the interfaces to allow custom implementations. Basically, it is possible by passing them as part of the command line arguments as shown below.
Limitations of Sqoop Validation
Since it validates only data copied from a single table into HDFS currently. So, there are several limitations in the current implementation. Such as:
- Firstly, the all-tables option.
- Since it is a free-form query option.
- Basically, data is only imported into Hive, HBase or Accumulo.
- Moreover, we use –where argument for table imports.
- Also, incremental imports.
Sqoop Merge
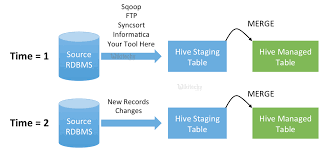
Objective
While it comes to combine two datasets we generally use a merge tool in Sqoop. However, there are many more insights of Sqoop Merge available. So, in this article, we will learn the whole concept of Sqoop Merge. Also, we will see the syntax of Sqoop merge as well as arguments to understand the whole topic in depth.
What is Sqoop Merge?
While it comes to combine two datasets we generally use a merge tool in Sqoop. Especially, where entries in one dataset should overwrite entries of an older dataset. To understand it well, let’s see an example of a sqoop merge.
Here, an incremental import run in last-modified mode will generate multiple datasets in HDFS where successively newer data appears in each dataset. Moreover, this tool will “flatten” two datasets into one, taking the newest available records for each primary key.
In addition, here we assume that there is a unique primary key value in each record when we merge the datasets. Moreover, –merge-key specifies the column for the primary key. Also, make sure that data loss may occur if multiple rows in the same dataset have the same primary key.
Also, we must use the auto-generated class from a previous import to parse the dataset and extract the key column. Moreover, with –class-name and –jar-file we should specify the class name as well as jar file. Although, we can recreate the class using the codegen tool if this is not available.
To be more specific, this tool typically runs after an incremental import with the date-last-modified mode (sqoop import –incremental lastmodified …).
Now let’s suppose that two incremental imports were performed, in an HDFS directory where some older data named older and newer data named newer.
Sqoop Job
Objective
In this Sqoop Tutorial, we discuss what is Sqoop Job. Sqoop Job allows us to create and work with saved jobs in sqoop. First, we will start with a brief introduction to a Sqoop Saved Job. Afterward, we will move forward to the sqoop job, we will learn purpose and syntax of a sqoop job. Also, we will cover the method to create a job in Sqoop and Sqoop Job incremental import.
Saved Jobs in Sqoop
- Basically, by issuing the same command multiple times we can perform imports and exports in sqoop repeatedly. Moreover, we can say it is a most expected scenario while using the incremental import capability.
- In addition, we can define saved jobs by Sqoop. Basically, that makes this process easier. Moreover, to execute a Sqoop command at a later time we need some information that configuration information is recorded by a sqoop saved job.
- Moreover, note that the job descriptions are saved to a private repository stored in $HOME/.sqoop/, by default. Also, we can configure Sqoop to instead use a shared metastore. However, that makes saved jobs available to multiple users across a shared cluster.
What is a Sqoop Job?
- Basically, Sqoop Job allows us to create and work with saved jobs. However, to specify a job, Saved jobs remember the parameters we use. Hence, we can re-execute them by invoking the job by its handle. However, we use this re-calling or re-executing in the incremental import. That can import the updated rows from the RDBMS table to HDFS.
- In other words, to perform an incremental import if a saved job is configured, then state regarding the most recently imported rows is updated in the saved job. Basically, that allows the job to continually import only the newest rows.
Sqoop Saved Jobs and Passwords
- Basically, multiple users can access Sqoop metastore since it is not a secure resource. Hence, Sqoop does not store passwords in the metastore. So, for the security purpose, you will be prompted for that password each time you execute the job if we create a sqoop job that requires a password.
- In addition, by setting sqoop.metastore.client.record.password to true in the configuration we can easily enable passwords in the metastore.
- Note: If we are executing saved jobs via Oozie we have to set sqoop.metastore.client.record.password to true. It is important since when executed as Oozie tasks, Sqoop cannot prompt the user to enter passwords.
Sqoop Job Incremental Imports
Basically, by comparing the values in a check column against a reference value for the most recent import all the sqoop incremental imports are performed.
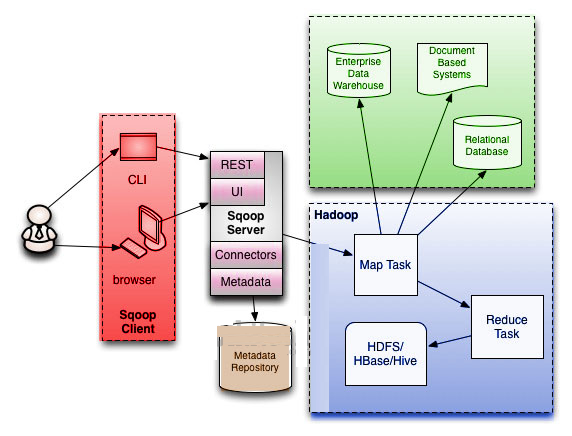
Sqoop Connectors and Drivers
Objective
While it comes to the Hadoop ecosystem, the use of words “connector” and “driver” interchangeably, mean completely different things in the context of Sqoop. For every Sqoop invocation, we need both Sqoop Connectors and drivers. However, there is a lot of confusion about the use and understanding of these Sqoop concepts.
In this article, we will learn the whole concept of Sqoop Connectors and Drivers in Sqoop. Also, we will see an example of Sqoop connector and Sqoop driver to understand both. Moreover, we will see how Sqoop connectors partition, Sqoop connectors format Sqoop connectors extractor and Sqoop connectors loader. Let’s start discussing how we use these concepts in Sqoop to transfer data between Hadoop and other systems.
What is a Sqoop Driver?
Basically, in Sqoop “driver” simply refers to a JDBC Driver. Moreover, JDBC is nothing but a standard Java API for accessing relational databases and some data warehouses. Likewise, the JDK does not have any default implementation also, the Java language prescribes what classes and methods this interface contains. In addition, for writing their own implementation each database vendor is responsible. However, that will communicate with the corresponding database with its native protocol.
What are the Sqoop Connectors?
Basically, for communication with relational database systems, Structured Query Language (SQL) programing language is designed. Almost every database has its own dialect of SQL, there is a standard prescribing how the language should look like. Usually, the basics are working the same across all databases, although, some edge conditions might be implemented differently. However, SQL is a very general query processing language. So, we can say for importing data or exporting data out of the database server, it is not always the optimal way.
Moreover, there is a basic connector that is shipped with Sqoop. That is what we call Generic JDBC Connector in Sqoop. However, by name, it’s using only the JDBC interface for accessing metadata and transferring data. So we can say this may not be the most optimal for your use case still this connector will work on most of the databases out of the box. Also, Sqoop ships with specialized connectors. Like for MySQL, PostgreSQL, Oracle, Microsoft SQL Server, DB2, and Netezza. Hence, we don’t need to download extra connectors to start transferring data. Although, we have special connectors available on the internet which can add support for additional database systems or improve the performance of the built-in connectors.
How to use Sqoop Drivers and Connectors?
Let’s see how Sqoop connects to the database to demonstrate how we use drivers and connectors.
Sqoop will try to load the best performance depending on specified command-line arguments and all available connectors. Basically, with Sqoop scanning this process begins all extra manually downloaded connectors to confirm if we can use one.
Ultimately, we have determined both Sqoop connector and driver. After that, we can establish the connection between the Sqoop client and the target database.
Sqoop Supported Databases
Objective
Basically, we can not use every database out of the box, also some databases may be used in an inefficient manner in Sqoop. So, in this article, we will study Sqoop supported databases. Also, we mention the specific versions of databases for which Sqoop supports.
What are Sqoop Supported Databases?
Basically, JDBC is a compatibility layer. However, that allows a program to access many different databases through a common API. Although slight differences in the SQL language spoken by each database may mean that we can not use every database out of the box, also some databases may be used in an inefficient manner in Sqoop.
Sqoop Troubleshooting
Objective
While working on Sqoop, there is the possibility of many failure encounters. So, to troubleshoot any failure there are several steps we should follow. So, in this article, “Sqoop Troubleshooting” we will learn the Sqoop troubleshooting process or we can say Apache sqoop known issues. Also, we will learn sqoop troubleshooting tips to troubleshoot in a better way.
General Sqoop Troubleshooting Process
While running Sqoop, there are several steps we should follow. Basically, that will help to troubleshoot any failure that we encounter. Such as:
- Generally, we can turn on verbose output by executing the same command again. It will help to identify errors. Also, by specifying the –verbose option. Basically, the Sqoop troubleshooting process produces more debug output on the console. Hence we can easily inspect them.
- Also, to see if there are any specific failures recorded we can look at the task logs from Hadoop. Since failure may occur while task execution is not relayed correctly to the console.
- Basically, Sqoop troubleshooting is just that the necessary input files or input/output tables are present. Moreover, it can be accessed by the user that Sqoop is executing as or connecting to the database as. Since there is a possibility that the necessary files or tables are present. However, it is not necessary that Sqoop connects can access these files.
- Generally, we need to break the job into two separate actions, to see where the problem really occurs. Especially, if you are doing a compound action try breaking them. While compound actions can be like populating a Hive table or partition in a hive.
Conclusion
As a result, we have seen in this Apache Sqoop Tutorial, what is Sqoop. Moreover, we have learned all the tools, working, and Sqoop commands. Also, we have learned the way to Import and Export Sqoop. Afterward, we have learned in Apache Sqoop Tutorial, basic usage of Sqoop.




